2025 NineData 第三届数据库编程大赛圆满举办!本次大赛由 NineData 和云数据库技术社区主办,并联合佰晟智算、达梦数据、 ITPUB、CSDN、IFclub、开源中国、DataFun、墨天轮等技术社区共同举办。1 月 12 日晚决赛答辩,超 6 万在线观众围观巅峰对决,八位编程大师过招比拼,最终排名正式揭晓!
赛题回顾
本届大赛延续 "一条 SQL" 的核心挑战 ,设置题目为「用一条 SQL」解数独问题 。查看赛题详情
本次大赛的评委,均是数据库领域的领军人物,通过主办方 NineData 的邀请,组成2025年《第三届数据库编程大赛》强大的评审嘉宾团。

《第三届数据库编程大赛》评审嘉宾团在将近两周的赛程报名中,共有数百位数据库爱好者积极参与。以下是本次入围决赛的前 8 强选手决赛最终排名:
八强SQL编程大师诞生
经过大赛组委会对参赛数百份 SQL 代码的初步验证和确认,确保其正确性。在接下来的百万级别性能评测中,我们选出了最强的8位选手,成功晋级到决赛答辩环节。本次大赛由 5 位权威评委+ AI 评委组成的专家团队,对选手的 SQL 参赛代码和答辩解读进行评分。评委们将着重考察代码的创新性和易读性,并将分别对这两个方面进行打分。最终,大赛组委会将根据综合得分,确定选手的最终排名。
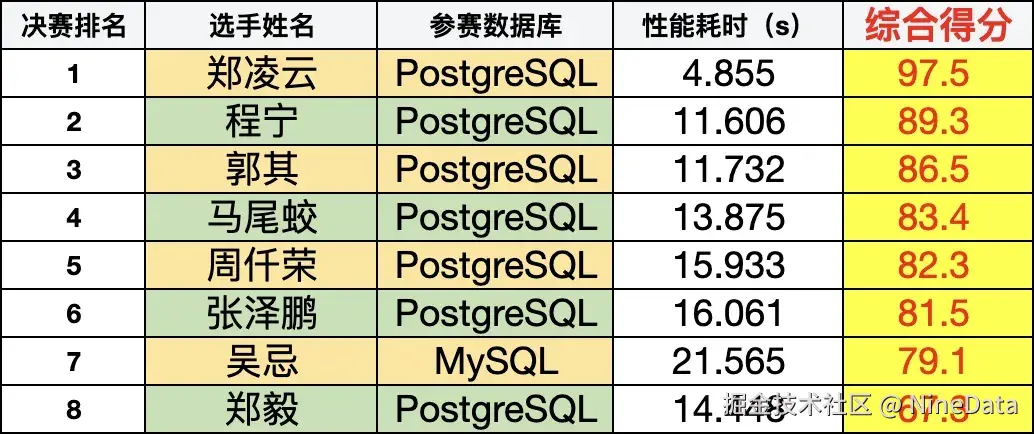
👇👇以下是本次大赛 8 位选手简介和 SQL 说明概要:
第8名:郑毅

参赛选手:郑毅
个人简介:数据库新手,从事算法工作
参赛数据库:PostgreSQL
性能评测:1万级数据代码性能评测 14.448 秒
综合得分:67.3以下是郑毅的代码说明思路:
SQL 代码通过三步核心逻辑实现数独自动化求解,核心是利用递归 CTE 完成深度优先搜索(DFS),同时兼顾求解效率和结果格式:
- 预处理筛选先清理数独题目字符串(移除空白,转为 81 字符紧凑格式),计算待填空格数,仅保留空格数≤50 的简单题目(降低求解复杂度),按空格数(难度)和 ID 排序后取前 10000 行;
- 递归回溯求解 以递归 CTE 实现 DFS,从第一个待填位置(?)开始,尝试填入 1-9 的数字,实时校验行、列、3×3 宫的唯一性(不重复则保留,否则剪枝),满足约束则继续填充下一个空格,直至无待填位置(pos=0)即得到解,且通过
DISTINCT ON (id)确保每个题目仅返回首个有效解; - 格式化输出将 81 字符的解字符串按每 9 字符切分并插入换行符,还原为标准 9 行数独格式,通过左连接和 ID 排序,保证输出顺序与原题目一致(未解出的题目也保留)。
第7名:吴斯琪

参赛选手:吴斯琪
个人简介:吴斯琪,参赛昵称吴忌,来自广东交通集团,从事IT系统运维多年。
参赛数据库:MySQL
性能评测:1 万级数据代码性能评测 21.565 秒
综合得分:79.1
以下是吴忌选手的代码说明思路简介:
代码核心逻辑是依托递归模拟回溯算法,结合位运算优化状态存储,采用MRV(最小剩余值)启发式搜索算法,有效减少搜索分支。整体思路可分为四步核心逻辑:
1. 预处理:构建基础计算维度
先生成数独求解的基础数据 ------ 数字 1-9(用于填充尝试)、81 个格子的行列宫坐标;同时通过高低位偏移量设计,解决 64 位整数存储 9 行 ×9 位(81 位)约束信息的溢出问题,为后续位运算铺路。
2. 初始化:位掩码压缩存储初始状态
将输入的 81 字符数独字符串清洗后,通过位运算构建 6 个 64 位整数掩码(行 / 列 / 宫的高低位掩码、已填位置掩码),把 "某行 / 列 / 宫已占用的数字""棋盘已填位置" 等约束信息压缩存储,这是整个求解器的核心状态表示方式。
3. 递归求解:DFS+MRV 启发式回溯(核心)
以递归 CTE 实现深度优先搜索,核心优化是 MRV 启发式策略:
- 选格:计算所有空格的 "禁止数字掩码"(行 + 列 + 宫约束的并集),优先选禁止数字最多的格子(减少搜索分支);
- 填数:遍历 1-9,仅筛选掩码允许的合法数字;
- 递归:通过位运算快速更新掩码状态,递归填充下一格;无解时自动回溯(无合法数字则分支断裂),填满 81 格即终止。
4. 结果输出:格式化与多解处理
筛选出填满 81 格的解,用行号处理多解情况,再将 81 字符的字符串格式化为 9×9 的网格形式,直观输出数独结果。
第6名:张泽鹏

参赛选手:张泽鹏
个人简介:杭州隐函科技有限公司联创,技术负责人
参赛数据库:PostgreSQL
性能评测:1 万级数据代码性能评测 16.061秒
综合得分:81.5
以下是张泽鹏选手的代码说明思路简介:
数独是典型的约束满足问题(Constraint satisfaction problem,CSPs),因此我采用了启发式的深度优先搜索算法来求解。
代码的核心推理逻辑是约束传播(Constraint Propagation),9x9的数独包含81个格子,所以我定义了 81×9=729 位的 Bit String 作为『约束特征向量』。假设第一个格子那填了2,约束就传播至同行、同列、同宫的20个格子,即特征向量中第11位(第二个格子数字2)、第20位(第三个格子数字2)等20个特征位都会被标记为1。利用约束特征向量,数独中所有已填的数字可以快速传播至所有未填的格子,然后通过位运算"非"(bitnot)操作,可快速获得所有未填格子的可填候选值。
代码还借鉴了 DLX 算法的约束特征向量思想,把前文长729的『约束特征向量』按格子拆分成81个长36的『候选特征向量』,并且只保留未填(即值是?)的格子;为了减少空间使用量,特征向量不拘泥于严格的精确一次(Exactly Once)语义,而是保留了所有候选值都压缩在一个向量内的方式。例如 b'010010000010000000000010000010000000',由以下四部分组成:
-
第01-09位【
b'010010000'】:所有可填的候选值,来自上一步约束传播运算结果。若当前格子能填数字N(1-9),则第N位为1否则为0。本例中第二位和第五位为1,即当前格子能填2或5。 -
第10-18位【
b'010000000'】:行号。若当前格子属于第N(1-9)行,则第N位为1,其他位为0。本例中第二位是1,即当前格子在第2行。 -
第19-27位【
b'000010000'】:列号。若当前格子属于第N(1-9)列,则第N位为1,其他位为0。本例中第五位是1,即当前格子在第5列。 -
第28-36位【
b'010000000'】:宫号。若当前格子属于第N(1-9)宫,则第N位为1,其他位为0。本例中第二位是1,即当前各自在第2宫。
获得所有『候选特征向量』后,再按以下步骤执行广度优先搜索:
-
每个数独的候选特征向量按候选值数量排序。
-
取出候选值数量最少的候选特征向量。
-
为每个候选值创建一个搜索分支。
-
把当前候选值追加到当前分支的解集内。
-
在剩余的特征向量中,剔除所有冲突的候选值。即把同行、同列、同宫中相同的候选值剔除。
-
若还有剩余的特征向量,并且所有向量的候选值数量都大于
0,则重复第一步,直到结束。
因为每个数独问题都至少有一个解,并且在最终结果里每个问题只需要返回一个解即可,因此我在代码中使用 distinct on (id) 随机选择一个解。
因为搜索是按照剩余候选值的顺序执行,所以生成最终结果前,需要把结果集先按照格子顺序重新排序,然后按照 ? 的顺序依次填充。这里我用了一个技巧:先把原始数独中 ? 替换成 %s,作为 format 函数的模板;再使用 PostgreSQL 的 variadic 关键词把结果集数组展开成 format 函数的参数,就能快速生成结果了。
第5名:周仟荣

参赛选手:周仟荣
选手简介:数据分析师,来自东风日产数据服务有限公司
参赛数据库:PostgreSQL
性能评测:1 万级数据代码性能评测 15.933 秒
综合得分:82.3
以下是周仟荣选手的代码说明思路简介:
- 算法概括
本算法采用 "分而治之" 的策略,结合了 确定性贪心推理 与 启发式深度优先回溯。 算法核心通过 PostgreSQL 的 递归公用表表达式实现,利用 位运算掩码 (Bitmask) 替代集合运算,并针对大规模数据处理场景,通过 内存压缩 (Smallint) 与 延迟物化 (Late Materialization) 极致压榨单核执行效率。
- 分段说明
第一阶段:预处理与掩码初始化
健壮解析: 利用正则清洗和 translate 函数,将多种输入格式(如带空格、问号或点的字符串)统一标准化为长度 81 的 smallint 数组。使用 2字节内存 存储数字,显著降低了递归过程中的内存带宽压力。
位掩码聚合: 不使用逐行扫描,而是通过一次性全量聚合,将行、列、九宫格的约束直接转化为位向量。1 代表该数字已存在,0 代表可选。这使得后续冲突检测仅需一次 按位或 (OR) 运算即可完成。
第二阶段:确定性求解流
贪心推理: 此 CTE 处理所有 "唯一候选数" 情况。算法会持续搜寻仅剩一个可选数字的空格并直接填充。由于该阶段不产生搜索分支,执行效率极高,能瞬间完成约 95% 的中低难度题目。
第三阶段:逻辑分流与回溯补刀
逻辑分流: 通过 ID 过滤,将已解完和未解完的题目分离。仅对未解完的难题进行排序去重(DISTINCT ON)。这种分流机制彻底消除了 10,000 行级别数据在全量排序时可能触发的 磁盘溢出 (Disk Spill) 风险。
solve_backtracking (启发式回溯): 针对难题,采用 最小剩余值优先 (MRV) 策略。算法优先选择候选数最少的格子进行尝试,极大程度收缩了搜索树的深度与广度。
第四阶段:格式化输出
延迟物化: 在整个解题循环中,代码仅携带 ID 和数字状态,完全剥离了冗长的原题字符串。仅在最后输出阶段才通过 ID 关联取回题面,最大限度优化了递归缓存(Work Table)的利用率。
- 技术亮点总结
- 空间效率:smallint 数组比 int 数组节省 50% 内存。
- 运算效率:位运算掩码使冲突检测耗时几乎降至 CPU 周期级。
- 架构稳健性:分流逻辑确保了在大规模数据量(1万行+)下,性能依然保持线性扩展,不因排序内存不足而大幅衰减。
- FILTER、DISTINCT ON 等 PostgreSQL 特有语法的应用对性能有一定提升
第4名****马尾蛟

参赛选手:马尾蛟
选手简介:就职于某大型国际物流公司,从事数据科学多年
参赛数据库:PostgreSQL
性能评测:1 万级数据代码性能评测 13.875 秒
综合得分:83.4
以下是马尾蛟选手的代码说明思路简介:
- 输入清洗
使用 translate(g.puzzle, E'\r\n\t ', '') 去除原题内的换行/空格,generate_series(0,80) 展开 81 个格子,计算每个格子的行 r、列 c、宫 b 以及原始字符。
- 约束掩码
行、列、宫分别聚合成 9 个 bit(9) 段:对每个已填数字调用 set_bit,最终得到 81bit 的串,其中每 9bit 表示某一行(或列/宫)中已经出现过的数字。这样每次只需 substring(... for 9)::bit(9)::int 就能得到该行/列/宫的占位情况。
- 候选格列表
把所有 ? 的位置按顺序收集到 todo 数组,递归过程中用 array_remove 删除已填位置。这保证候选数少的格子更"靠前",减少回溯树的分支。
- digits CTE
预生成 1~9 的文本和值以及 (1 << (n-1)),递归时无需重复计算。
- 递归搜索
solver CTE 保存当前字符串、三类掩码和剩余 todo。每一层先 unnest(todo),计算 mask_int = row_mask | col_mask | box_mask,用 bit_count(((~mask_int) & 511)::bit(9)) 统计可用数字个数,并选择候选数最少的格子(经典 MRV 策略),大幅剪枝。
- 状态更新
对于满足 (mask_int & d.bit)=0 的数字 d,使用 overlay 在字符串中写入,set_bit 更新对应行/列/宫掩码,再把该格从 todo 中剔除即可得到下一状态。
- 终止条件
当 array_length(todo, 1) 为空时输出当前字符串,该字符即完整解。整个过程严格遵守"一条 SQL + 递归 CTE"的比赛限制,无需自定义函数。
- 性能/输出
在比赛给定的 PG17(表 sudoku9_9)上,默认设置下 1000 条样本约 1.20~1.25 秒。SQL 最终返回 (id, puzzle, result) 三列,其中 puzzle/result 均为 81 位字符串,便于和原始题库对照。
第3名:郭其

参赛选手:郭其
选手简介:中国移动设计院网研中心,数据库技术专家负责人
参赛数据库:PostgreSQL
性能评测:1万级数据代码性能评测 11.732 秒
综合得分:86.5
以下是郭其选手的代码说明思路简介:
基于 MRV 启发式的多级位掩码递归搜索
- 核心数据结构:三维位掩码 (Triple Bitmasking)
- 舍弃了传统的字符串或数组处理,将数独状态映射为三个 81 位的位图 (bit(81)) :
r_mask(行)、c_mask(列)、b_mask(宫)。 - 空间压缩:每个格子的状态通过
substring提取 9 位 bit,利用位或运算|瞬间计算出该格子的"禁手"(已填数字)。 - 计算加速:通过
bit_count(计算 1 的个数)快速评估格子的填充约束,这比循环遍历判断快了几个数量级。
- 第一级:线性传播层 (Propagate - "预制菜")
利用唯一余数定理 (Naked Single)启动搜索。
- 逻辑:如果一个格子在行、列、宫的约束下,只剩下唯一的一个数字可选(
bit_count = 8),则直接填充。 - 作用:在进入高开销的递归搜索前,尽可能地填充已知信息,极大地缩小了搜索树的规模。
- 核心启发式策略:MRV (最小剩余值) + 频率热度
在递归层,算法不再盲目选择格子,而是应用了 MRV 策略:
- 格位选择:通过
ORDER BY bit_count(...) DESC LIMIT 1永远选择"最难"的格子(即剩余可选数字最少的格子)进行填入。 - 热度增强:引入
freq_weight(周围区域的填充密度),在多个格子候选数相同时,优先处理"拥挤区域",从而引发搜索空间的连锁坍塌。
- 第二级:极速冲刺层 (Solver - "贪心分支")
这是执行效率的保障。
- 有限回溯:通过
res.rank <= 2限制分支因子。它只尝试每个格子的前两个最可能的候选数。 - 效果:3-4s左右的速度解决 99% 的数独题目,通过剪掉 90% 以上的深层无效分支来换取极高的执行速度。
- 第三级:终极保险层 (Final Insurance - "暴力兜底")
这是保证"全量不丢题"的核心。
- 精准拦截:利用
NOT EXISTS逻辑,仅让Solver层处理失败的 ID 进入此层。 - 无限制回溯:彻底移除
rank限制,回归标准的深度优先搜索 (DFS)。 - 设计哲学:主逻辑负责"快",保险层负责"稳"。即使主逻辑因为贪心策略导致漏题,保险层也会不计代价地死磕到底,确保 10,000 条数据 100% 产出。
- 结果去重
- 自动验证:通过
WHERE bit_count(f_mask) = 81确保输出的必须是完整的解。
该算法巧妙地解决了数据库递归 CTE 容易产生的"空间爆炸"问题。它像一个漏斗,让简单的题目在极短时间内流出,而将计算资源集中在极个别的复杂题目上,实现了性能与准确率(100%)的完美统一。
第2名
程宁 **
参赛选手:程宁
个人简介:嘉兴市第二医院信息科,从事信息化工作多年
参赛数据库:PostgreSQL
性能评测:1 万级数据代码性能评测 11.606 秒
综合得分:89.3
以下是程宁选手的代码说明思路简介:
【功能】
基于 SQL 递归 CTE 实现 9 宫格数独自动求解,支持处理含空格 / 换行、以?表示空单元格的输入数据。
【核心减枝策略】
本题核心在于如何有效减枝,降低计算量,核心策略有三:
- 唯一数冲突算法:显性唯一数(单元格仅 1 个候选数)、隐形唯一数(行 / 列 / 宫格某数仅 1 个可填位置)不可能在同一单元格存在2个不同的数,利用此规则避免再次计算错题,实现减枝;
- 候选数MPV算法:优选候选数最少的单元格填充,是最常见且有效的算法;
- 贪心算法:基于本题存在大量多解的情况,在MPV基础上,仅尝试填充一个数,单路径实现99.7%的题目一次性出结果
【输出】
输出数独 ID、原始谜题(格式化后)、求解结果(每 9 字符换行,符合数独展示格式),每个数独仅返回 1 个有效解。
第1名:郑凌云

参赛选手:郑凌云
个人简介 :淘宝,从事推荐系统开发参赛数据库 :PostgreSQL性能评测 :1 万级数据代码性能评测 4.855 秒综合得分:97.5以下是郑凌云选手的代码说明思路简介:
创新点:通过一个非常巧妙的设计,基于数组模拟出一个栈结构,在递归CTE中实现回溯算法,极大降低搜索空间,尽最大可能避免行数爆炸。
通用性:4x4 数独和 9x9 数独的代码结构完全一致,仅一些常数项有分别对应值。
算法分为3个阶段:
-
初始化阶段,生成init_t表,位编码方式,记录关键约束数据row_can/col_can/box_can,并生成待填数字的位置列表放在todo中。
-
推理阶段,生成infer_t表,把确定性能推理出来的所有位置都填好,降低后续搜索量。
-
搜索阶段,生成search_t表,针对位置上有多选的情况,通过深度优先搜索加回溯加MRV策略,高效完成检索。
- 正常SQL很难做深度优先搜索,在这个阶段我设计了一个很巧妙的栈结构,让SQL也可以进行深度优先搜索。这是本方案最有创造力的地方,极大降低了无效搜索量。
- 因为数独问题是NP问题,可能存在需要极大搜索深度的题,需要保护一下程序别被这种题拖垮,设计有最大搜索深度deep限制,超限不解。
- 当前设定的最大搜索深度deep=65000,样例数据其实只需459就够了。如果难度很高的题,可以上调该深度。
- 输出阶段,最终的result数据,其实是在前面推理阶段和搜索阶段已经逐步填入了,所以输出阶段直接输出即可。
大赛奖品
本次数据库编程大赛的奖项安排:一等奖(1人)、二等奖(2人)、三等奖(3人)、阳光普照纪念奖(50人)。
-
一等奖(1人) :大疆无人机 DJI NEO 2 畅飞套装 1 组 + 奖杯
-
二等奖(2人):Fuzozo 芙崽AI情感陪伴机器人 1 个 + 奖杯
-
三等奖(3人) :华为蓝牙耳机 1 个 + 奖杯
-
阳光普照纪念****奖(50人):办公养生壶 1 个

《数据库编程大赛》下一次再聚!
本次《数据库编程大赛》前50名完成普通挑战并通过正确性验证的选手,也是会获得一份精美礼品,感谢大家对本次大赛的关注和支持,我们下次再相聚!