在不少 iOS 项目里,代码混淆并不是一开始就被纳入开发计划的事情。更多时候,它是在某个阶段被迫提上日程:包被拆过、资源被直接复用、或者在第三方市场看到一个熟悉得有点过分的 App。
我第一次系统性地处理 iOS 代码混淆,并不是在源码阶段,而是在已经拿到 IPA 的情况下。那次经历也让我意识到,很多关于iOS 安全的讨论,和真实项目的距离其实不小。
这篇文章更多是一次实践回顾,聊聊在 IPA 层面做代码混淆 时,实际可行的方案组合,以及工具在流程中应该扮演什么角色。
为什么不是所有项目都从源码层开始混淆
理想状态下,混淆当然越早越好。但在现实项目里,经常会遇到一些限制条件:
- 项目是外包或合作方交付,只给 IPA
- 项目历史较长,源码改动风险大
- 使用 Flutter、Unity、Cocos2dx 等方案,源码层混淆维护成本高
- 需要对已上线版本做补救,而不是重构
在这些情况下,直接处理 IPA 文件反而成了一种更可控的方式。至少不会影响原有工程结构,也不会打断已有的开发节奏。
iOS 逆向分析通常是从哪些信息入手的
从防护角度看,先理解对方怎么看你会更有帮助。 在没有任何处理的情况下,一个 IPA 往往暴露出:
- 可读性很高的类名和方法名
- 清晰的模块划分
- 命名有规律的资源文件
- 未清理的符号和调试信息
很多分析并不需要深入到汇编级别,只要靠符号和资源就能判断出核心逻辑位置。这也是为什么混淆的重点不在于隐藏算法,而在于破坏可读性。
几种常见保护手段在项目中的配合方式
在实际项目中,我并没有只依赖某一种方案,而是根据阶段组合使用:
- 源码阶段:基础命名规范、避免暴露关键逻辑
- 网络与业务层:接口加签、服务端校验
- IPA 阶段:代码与资源混淆,作为最后一道门槛
其中,IPA 层的混淆更多是针对已成型产物的防护,目标很明确: 让拆包、分析、复用的成本明显上升。
在 IPA 层面做代码混淆,关注点其实很具体
真正落地时,关注的并不是支持多少技术名词,而是几件很实际的事:
- 能不能只混淆我关心的类和方法
- 混淆后是否还能正常签名和安装
- 对 OC、Swift 以及跨平台产物是否兼容
- 配置是否可复用,避免每次重来
这也是我后来在项目中引入 Ipa Guard 的原因之一。
基于 Ipa Guard 的一次完整混淆流程记录
这次使用 Ipa Guard,是在一个已经发布过多个版本的 App 上进行的补充保护,流程基本如下。
选择 IPA 并加载结构
直接选择需要处理的 IPA 文件,工具会解析其中的可执行文件和资源结构。 这一阶段主要确认目标二进制是否正确,避免误操作到不相关的模块。 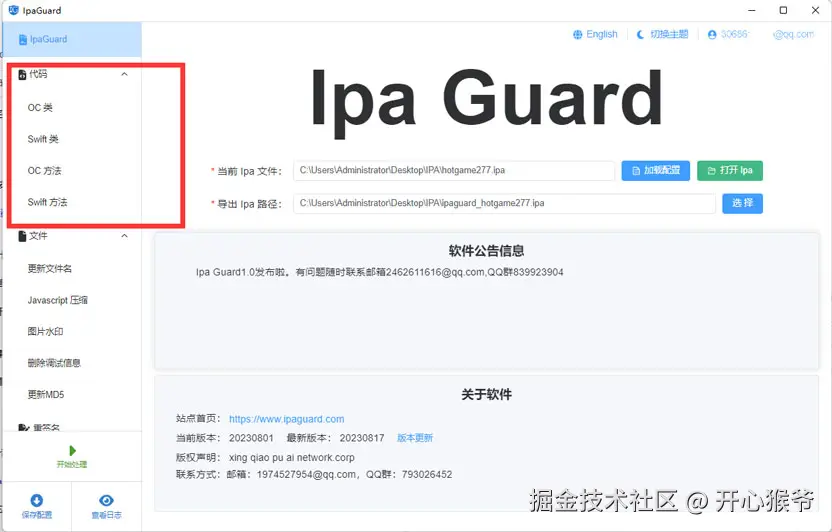
配置需要混淆的类
在代码模块中,可以分别查看 OC 类或 Swift 类列表。 我一般会:
- 先通过搜索定位业务核心类
- 再结合风险等级筛选
- 避免对系统或第三方 SDK 的类动手
这种按需选择的方式,比全量混淆更稳妥。 
选择方法与函数进行混淆
方法级别的混淆是影响最大的部分。 在这里可以按类名、方法名过滤,逐步确认哪些函数值得处理。 混淆后,符号名称会变成无意义字符串,对静态分析的干扰非常明显。 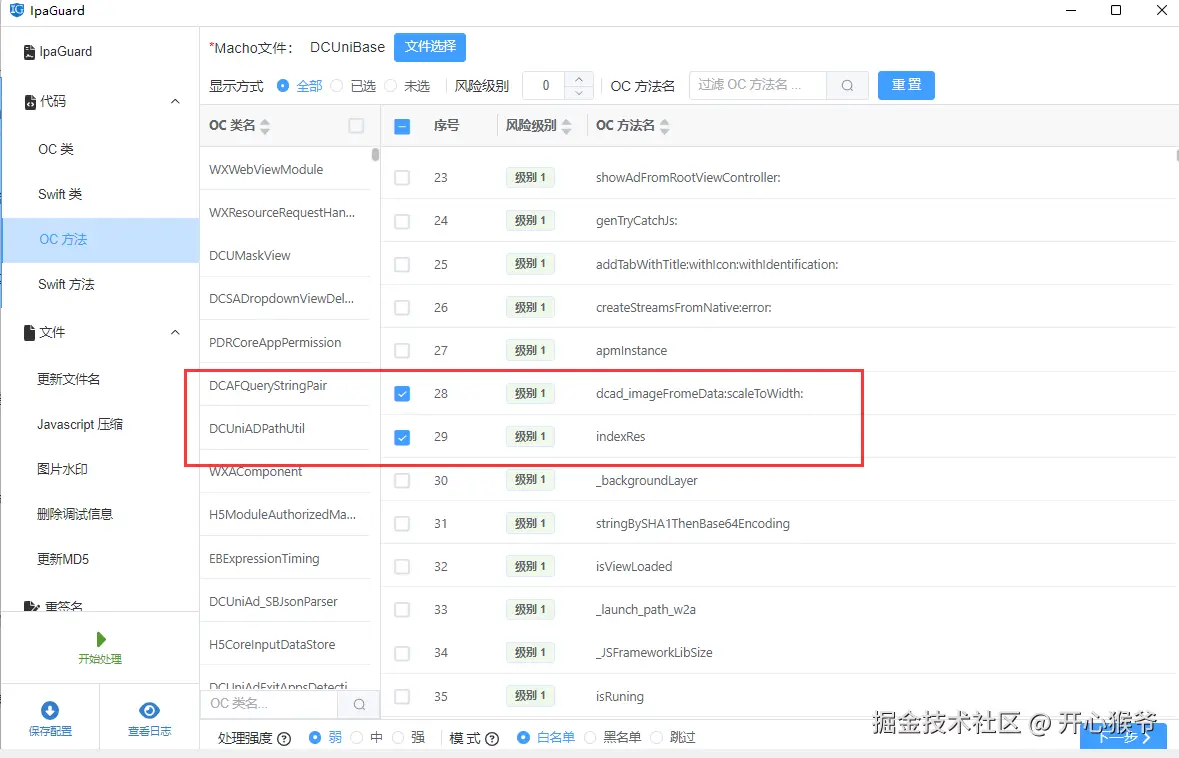
资源文件的处理
除了代码,资源也是经常被忽视的一环。 Ipa Guard 支持对图片、JSON、HTML、JS 等资源重命名,并可修改 MD5。 在一些项目中,这一步对防止资源直接复用非常有效。
配置签名并测试
混淆完成后,直接配置证书进行重签名。 测试阶段我一般使用开发证书安装到真机,重点验证:
- 启动是否正常
- 核心功能是否受影响
- 资源加载是否异常
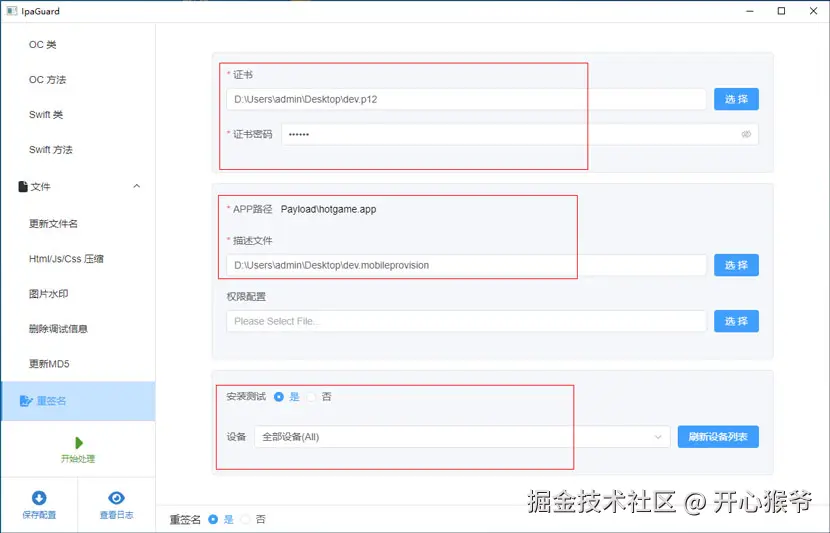
确认无问题后,再保存配置,后续版本可以直接复用。
混淆之后,并不是就安全了
需要明确的一点是: 混淆不是为了让 App 无法被分析,而是让分析变得不划算。
在项目中,我通常会把 IPA 混淆作为安全链路中的一环,而不是终点。 它解决的是快速看懂和低成本复用的问题,这一点本身就很有价值。
一些适合使用这类方案的场景
从经验来看,这类工具更适合:
- 已上线项目的补救保护
- 无法直接改源码的交付场景
- 多技术栈混合的 App
- 对源码外泄有顾虑的团队
如果一开始就明确这一定位,使用体验会更符合预期。