在合同审核、金融尽调或法律证据比对等场景中,专业人员常常需要面对堆积如山的文件。传统的文档比对依赖人工逐字逐句核对,不仅效率低下,而且容易因疲劳导致关键信息遗漏或误判。面对版式各异、结构复杂的海量文件,如何快速、精准地提取并比对核心信息,已成为制约众多行业数字化转型的关键瓶颈。
一种基于大语言模型与高精度光学字符识别技术深度融合的文档抽取技术应运而生,构建了一套能够理解文档语义、洞察逻辑结构的智能处理系统。它不仅仅是在"阅读"文档,更是在"理解"文档。
技术架构:大模型 + 高精度OCR 的深度融合
文档抽取技术的核心在于将前沿的大语言模型(LLM)微调能力与自研的高精度光学字符识别(OCR)引擎进行深度耦合,形成端到端的智能文档理解与结构化信息抽取平台。该系统具备以下关键技术优势:
- 高精度OCR引擎
采用基于CNN-Transformer混合架构的先进OCR模型,支持:
- 多语言、多字体、手写体识别;
- 表格结构重建(Table Structure Recognition);
- 版面分析(Layout Analysis):识别标题、段落、表格、图例等区域;
- 输出富文本格式(含坐标、字体、行高、段落关系等元信息)。
OCR模块不仅输出纯文本,还保留空间布局与视觉语义线索,为后续大模型提供上下文感知的输入。
- 大语言模型微调训练
采用具备强大上下文理解能力的大模型作为基础,进行领域自适应微调(Domain-adaptive Fine-tuning):
- 输入构造:将OCR输出的文本按阅读顺序拼接,并注入布局标记;
- 指令微调(Instruction Tuning):设计统一的抽取指令模板,例如:"请从以下文档中提取:发票编号、开票日期、总金额。"
- 结构化输出约束:通过Schema-guided decoding或JSON格式强制输出,确保结果可直接用于下游系统;
- 多任务学习:联合训练字段抽取、关系识别、分类判断等子任务,提升泛化能力。
微调数据涵盖数百种真实业务文档,覆盖金融、医疗、物流、政务等多个垂直领域。
- 版式无关的通用抽取能力
传统规则或模板方法难以应对文档版式的多样性。文档抽取技术通过"视觉-语义联合建模",将文档的布局信息(如坐标、字体、段落层级)与文本语义融合输入大模型,实现对PDF、Word、扫描图像、网页截图等异构格式的统一处理,真正做到"一模型适配千种版式"。
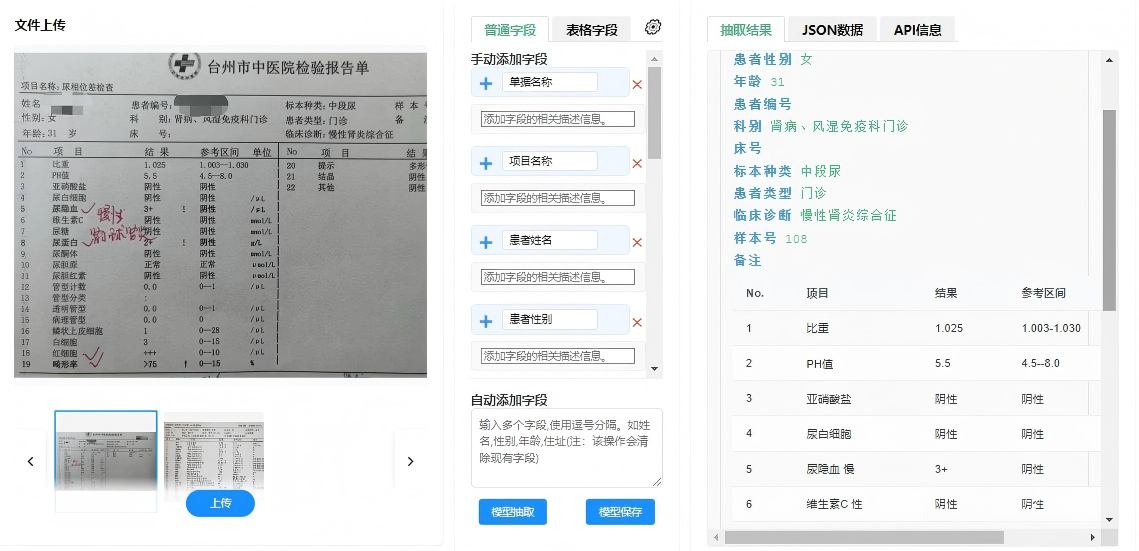
关键创新点
- 端到端语义增强OCR:OCR不再是孤立的预处理步骤,其输出被大模型动态修正与语义补全;
- 零样本/少样本迁移能力:得益于大模型先验知识,新文档类型仅需少量标注即可快速适配;
- 结构保持抽取:不仅能提取字段值,还能还原字段间的逻辑关系(如"买方"与"卖方"配对);
- 可解释性增强:通过注意力可视化,展示模型关注的文本区域,便于审计与调试。
在文档比对中的应用场景
基于上述高精度抽取能力,文档抽取系统可广泛应用于以下典型场景:
- 合同版本差异比对
在法务或采购流程中,常需比对不同版本的合同草案。文档抽取系统可自动抽取各版本中的关键条款(如付款方式、交付周期、违约责任),并以结构化形式呈现差异点,显著提升审核效率与准确性,避免人工疏漏。
- 财报/审计报告一致性校验
金融机构需对上市公司披露的多份财报(如年报、季报、公告)进行交叉验证。系统可精准抽取财务指标(如营收、净利润、资产负债率),自动比对同一指标在不同文档中的数值是否一致,并生成差异报告。
- 政策文件合规性审查
政府或监管机构发布的政策文件常存在更新迭代。系统可对新旧政策文本进行语义级比对,识别新增、删除或修改的条款内容,并标注其影响范围,辅助合规团队快速响应。
- 发票与订单信息核验
在供应链管理中,文档抽取系统可同时解析供应商发票与内部采购订单,自动比对商品名称、数量、单价、税号等关键字段,实现"三单匹配"(订单、收货单、发票)的自动化,大幅降低财务对账成本。
通过将大模型微调训练与高精度OCR技术深度融合而诞生的智能文档抽取系统,不仅解决了多版式文档高精度信息抽取的行业难题,更在文档比对这一高价值场景中展现出强大的落地能力。未来,随着大模型技术的持续演进与垂直领域数据的不断积累,将持续推动文档智能处理向更高精度、更强语义、更广应用的方向发展,助力各行业实现真正的"文档即数据"转型。