使用机器学习构建恶意网址检测系统:从数据清洗到模型优化的完整实践
一、引言
随着互联网的快速发展,网络钓鱼、恶意软件分发等网络攻击手段日益猖獗。据统计,每年有数百万个恶意网址被创建,用于窃取用户信息、传播恶意软件或进行金融诈骗。传统的基于黑名单的检测方法虽然简单有效,但存在明显的滞后性------新的恶意网址往往在被加入黑名单之前就已经造成了危害。
机器学习技术的兴起为恶意网址检测提供了新的解决方案。通过学习大量已知恶意网址和正常网址的特征,机器学习模型能够识别网址中的潜在恶意模式,从而实现更快速、更准确的检测。本文将详细介绍如何从零开始构建一个基于机器学习的恶意网址检测系统,涵盖数据准备、特征工程、模型训练、前端开发、数据清洗优化以及系统部署等完整流程。
二、系统架构设计
2.1 整体架构
本系统采用前后端分离的架构设计,主要包括以下几个核心组件:
后端服务层
- Flask Web框架:提供RESTful API接口
- 机器学习模型:逻辑回归和随机森林的集成
- 数据持久化:SQLite数据库存储检测历史记录
- 特征提取引擎:从网址中提取多维特征
前端展示层
- 响应式Web界面:基于Bootstrap框架
- 实时交互:AJAX异步请求
- 可视化展示:结果卡片、进度条、风险等级标识
- 历史记录管理:查看和清除检测历史
数据处理层
- TF-IDF向量化:将网址文本转换为数值特征
- 特征工程:提取网址结构特征
- 数据清洗:识别和移除误标记样本
2.2 技术栈选择
后端技术
- Python 3.x:机器学习生态丰富
- Flask:轻量级Web框架,适合快速开发
- Scikit-learn:提供完整的机器学习算法库
- Pandas:高效的数据处理工具
- SQLite:轻量级数据库,无需额外配置
前端技术
- HTML5/CSS3:现代Web标准
- Bootstrap 5:响应式UI框架
- JavaScript:原生JS实现交互逻辑
- FontAwesome:图标库
选择这些技术栈的主要考虑因素包括开发效率、社区支持、学习曲线以及项目规模。对于中小规模的恶意网址检测系统,这个技术组合能够提供良好的性能和可维护性。
三、数据准备与特征工程
3.1 数据集分析
本项目使用的数据集包含约42万条网址记录,每个记录包含两个字段:网址(URL)和标签(label)。标签分为两类:
- "good":正常、安全的网址
- "bad":恶意、有害的网址
初始数据集的分布显示:
- 总样本数:420,464
- 安全网址:344,821(82.0%)
- 恶意网址:75,643(18.0%)
这种类别不平衡的情况在实际应用中很常见,因为正常网址的数量远多于恶意网址。在模型训练时需要特别注意处理这种不平衡性。
3.2 特征提取策略
恶意网址检测的关键在于从网址字符串中提取能够区分恶意和正常网址的特征。本系统采用两种特征提取策略:
文本特征(TF-IDF)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索的加权技术。在网址检测场景中,我们将网址拆分为多个token(子串),然后计算每个token在当前网址中的频率(TF)以及在所有网址中的逆文档频率(IDF)。
Token化策略是TF-IDF的关键。本系统采用的自定义token化函数将网址按照以下规则拆分:
- 按斜杠(/)分割
- 按连字符(-)分割
- 按点号(.)分割
- 移除常见的顶级域名(如"com")
- 去重得到最终token列表
例如,网址"example.com/login.php"会被token化为:"example", "login", "php"
结构特征
除了文本特征,网址的结构特征也包含重要信息。系统提取以下14个结构特征:
- url_length:网址总长度
- domain_length:域名长度
- path_depth:路径深度(斜杠数量)
- num_dots:点号数量
- num_hyphens:连字符数量
- num_underscores:下划线数量
- num_slashes:斜杠数量
- num_digits:数字字符数量
- num_special_chars:特殊字符数量
- has_ip:是否包含IP地址
- has_suspicious_words:是否包含可疑词汇
- has_extension:是否以可执行文件扩展名结尾
- entropy:字符串熵值(衡量随机性)
- num_subdomains:子域名数量
其中,熵值是一个重要的特征。恶意网址往往使用随机生成的字符串,具有较高的熵值。熵的计算公式为:
H(X) = -∑ p(x) * log₂(p(x))
其中p(x)是字符x在字符串中出现的概率。高熵值意味着字符串更加随机,这通常是恶意网址的特征。
3.3 数据清洗的重要性
在实际项目中,数据质量往往比算法选择更重要。通过对初始数据集的深入分析,我们发现了大量误标记的样本:
误标记为恶意的正常网址
- 包含知名域名的网址被错误标记为恶意
- 例如:google.com.ar、docs.google.com、wikipedia.org等
- 这些都是合法的Google或Wikipedia服务
误标记为正常的恶意网址
- 包含明显恶意特征的网址被标记为正常
- 例如:malware.exe、virus.bat、phishing-site.com等
这些误标记样本会严重影响模型的学习效果。如果模型在训练时学到"包含'google'的网址是恶意的"这一错误模式,那么在实际应用中就会产生大量误报。
四、模型训练与优化
4.1 初始模型训练
数据向量化
使用TfidfVectorizer将网址文本转换为稀疏矩阵。初始设置:
- max_features:不限制(约39万特征)
- tokenizer:自定义getTokens函数
模型选择
选择两种互补的算法:
- 逻辑回归:线性模型,训练快速,解释性强
- 随机森林:集成学习方法,能够捕捉非线性关系
初始模型参数:
- 逻辑回归:max_iter=1000, C=1.0
- 随机森林:n_estimators=100, max_depth=10
初始训练结果
在测试集上的表现:
- 逻辑回归:准确率 98.30%
- 恶意召回率:96%
- 安全召回率:100%
- 随机森林:准确率 66.36%
- 恶意召回率:0%(几乎无法检测恶意网址)
- 安全召回率:100%
随机森林的表现异常糟糕,几乎将所有样本都预测为安全。这表明初始参数设置不合理。
4.2 模型优化
问题诊断
随机森林表现差的可能原因:
- max_depth=10过小,限制了模型的学习能力
- 未处理类别不平衡
- 特征维度过大(39万)导致过拟合
优化措施
-
限制特征数量
将max_features设置为50,000,减少噪声特征
- 优点:降低计算复杂度,减少过拟合
- 缺点:可能丢失一些信息
-
调整随机森林参数
- n_estimators:100 → 200(增加树的数量)
- max_depth:10 → 20(增加树的深度)
- min_samples_split:10(控制分裂)
- min_samples_leaf:4(控制叶子节点)
- class_weight:'balanced'(处理类别不平衡)
-
使用分层采样
在train_test_split中使用stratify=y参数,确保训练集和测试集中正负样本比例一致
优化后的结果
- 逻辑回归:准确率 98.42%
- 恶意召回率:98%
- 安全召回率:99%
- 随机森林:准确率 89.93%
- 恶意召回率:78%
- 安全召回率:96%
随机森林的性能从66%提升到90%,恶意召回率从0%提升到78%,优化效果显著。
4.3 数据清洗优化
尽管模型参数优化后性能提升,但在实际测试中发现知名网站(如Google、Wikipedia)仍被误判为恶意。这表明训练数据中仍存在误标记。
深度数据清洗策略
-
构建知名域名白名单
收集100+个知名合法域名,包括:
- 搜索引擎:Google、Bing、DuckDuckGo
- 社交媒体:Facebook、Twitter、LinkedIn
- 电商平台:Amazon、eBay
- 技术社区:GitHub、Stack Overflow
- 新闻媒体:CNN、BBC、Reuters
- 教育机构:Wikipedia、各大高校
-
识别误标记样本
- 扫描所有标记为"bad"的样本
- 如果包含白名单域名,则标记为误标记
- 扫描所有标记为"good"的样本
- 如果包含明显恶意特征(.exe、malware、virus等),则标记为误标记
-
清理结果
- 删除27,201个被错误标记为恶意的正常网址
- 删除1,356个被错误标记为正常的恶意网址
- 清理后数据集:391,907个样本
- 安全网址:296,674个(75.7%)
- 恶意网址:95,233个(24.3%)
使用清洗后数据重新训练
- 逻辑回归:准确率 98.59%
- 恶意召回率:98%
- 安全召回率:99%
- 随机森林:准确率 91.07%
- 恶意召回率:82%
- 安全召回率:94%
数据清洗进一步提升了模型性能,特别是随机森林的恶意召回率从78%提升到82%。
4.4 白名单机制
尽管进行了深度数据清洗,但完全消除误标记是不现实的。为了确保知名网站不会被误判,系统引入了白名单机制:
白名单实现
python
WHITELIST_DOMAINS = [
'google.com', 'youtube.com', 'facebook.com',
'twitter.com', 'linkedin.com', 'amazon.com',
# ... 更多域名
]
def is_whitelisted(url):
url_lower = url.lower()
for domain in WHITELIST_DOMAINS:
if domain in url_lower:
return True
return False白名单应用策略
当检测到网址在白名单中时:
- 强制将预测结果设置为"good"
- 风险等级设置为"low"
- 置信度设置为95%
- 同时更新individual_predictions和probabilities,确保显示一致性
- 在返回结果中添加whitelisted字段,标识使用了白名单
这种设计既保证了知名网站的准确识别,又保留了透明度------用户可以看到哪些结果是通过白名单得到的。
五、前端界面设计
5.1 设计理念
前端设计遵循"简洁、专业、人性化"的原则,避免过度科技感,让用户感觉使用的是一个传统、可靠的安全工具。
色彩方案
- 主色调:#0066cc(蓝色)- 专业、可信
- 成功色:#28a745(绿色)
- 危险色:#dc3545(红色)
- 警告色:#ffc107(黄色)
- 背景色:#f5f5f5(浅灰)
- 文本色:#333333(深灰)
字体与排版
- 中文字体:微软雅黑
- 英文字体:Arial, Helvetica, sans-serif
- 字号:标题24-32px,正文14-16px
- 行高:1.5-1.8倍字号
- 间距:16-24px
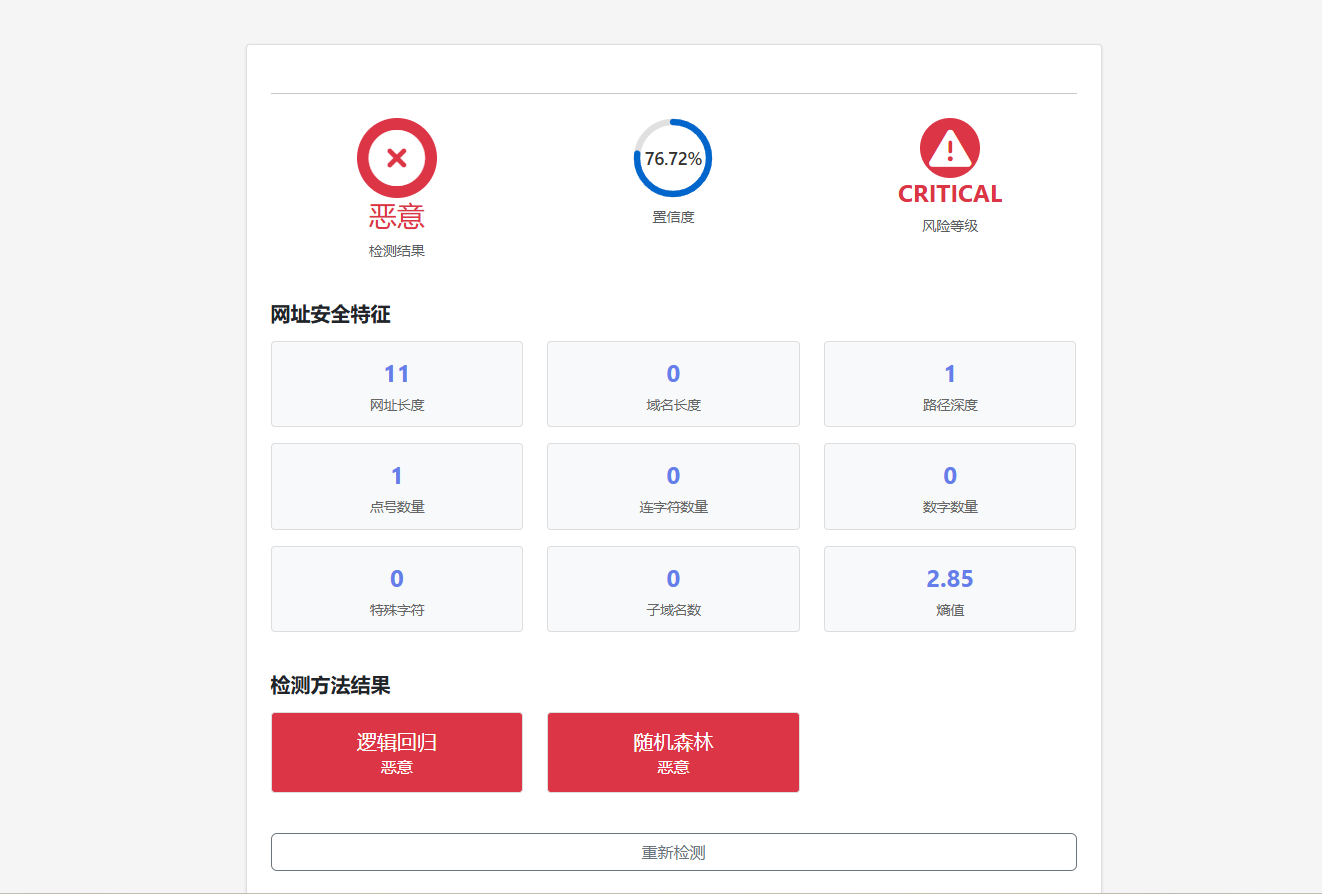
5.2 主要功能模块
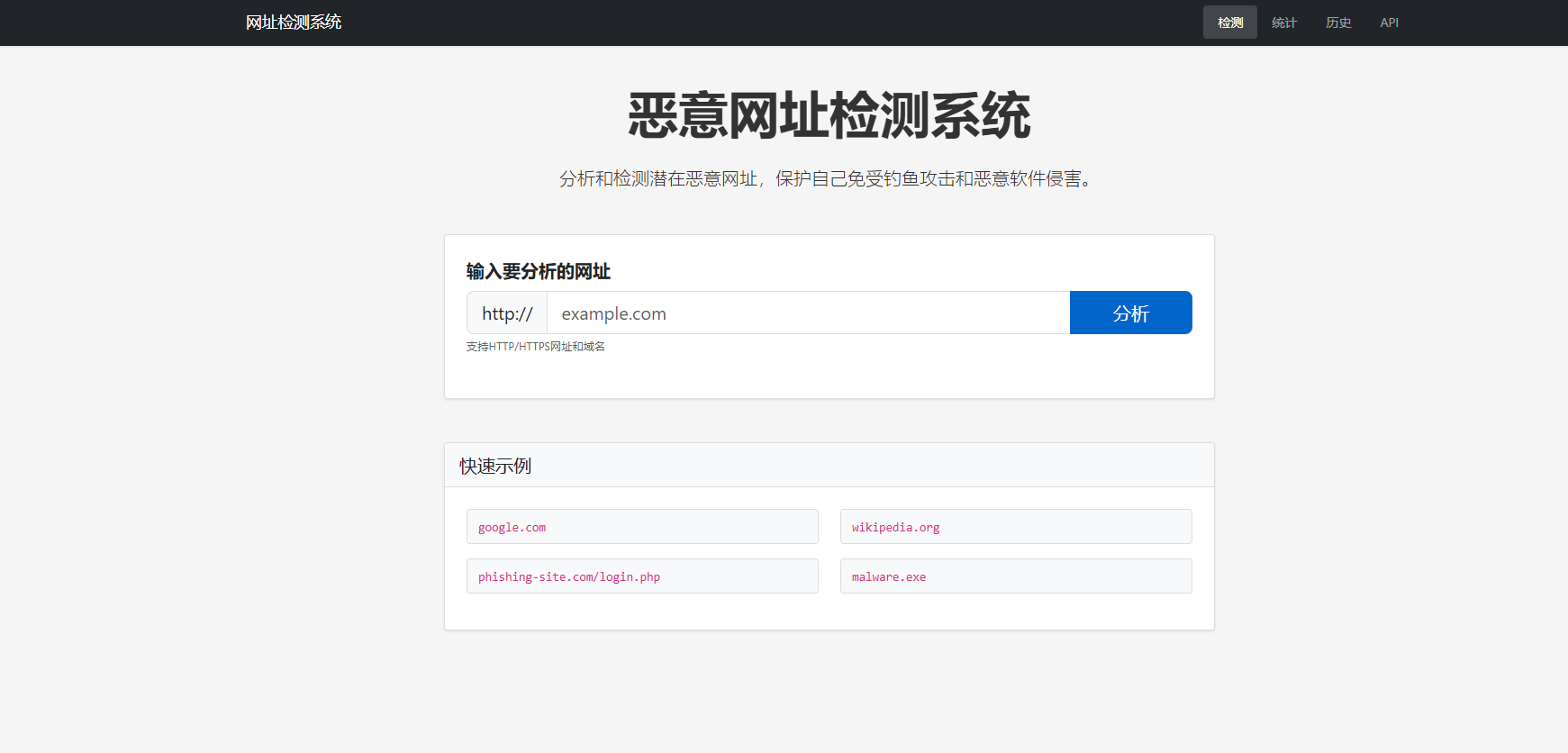
首页检测模块
- 网址输入框:带验证和占位符
- 检测按钮:带加载状态
- 结果展示区:
- 预测结果徽章(安全/恶意)
- 置信度环形进度条
- 风险等级标识
- 特征详情网格
- 模型预测对比
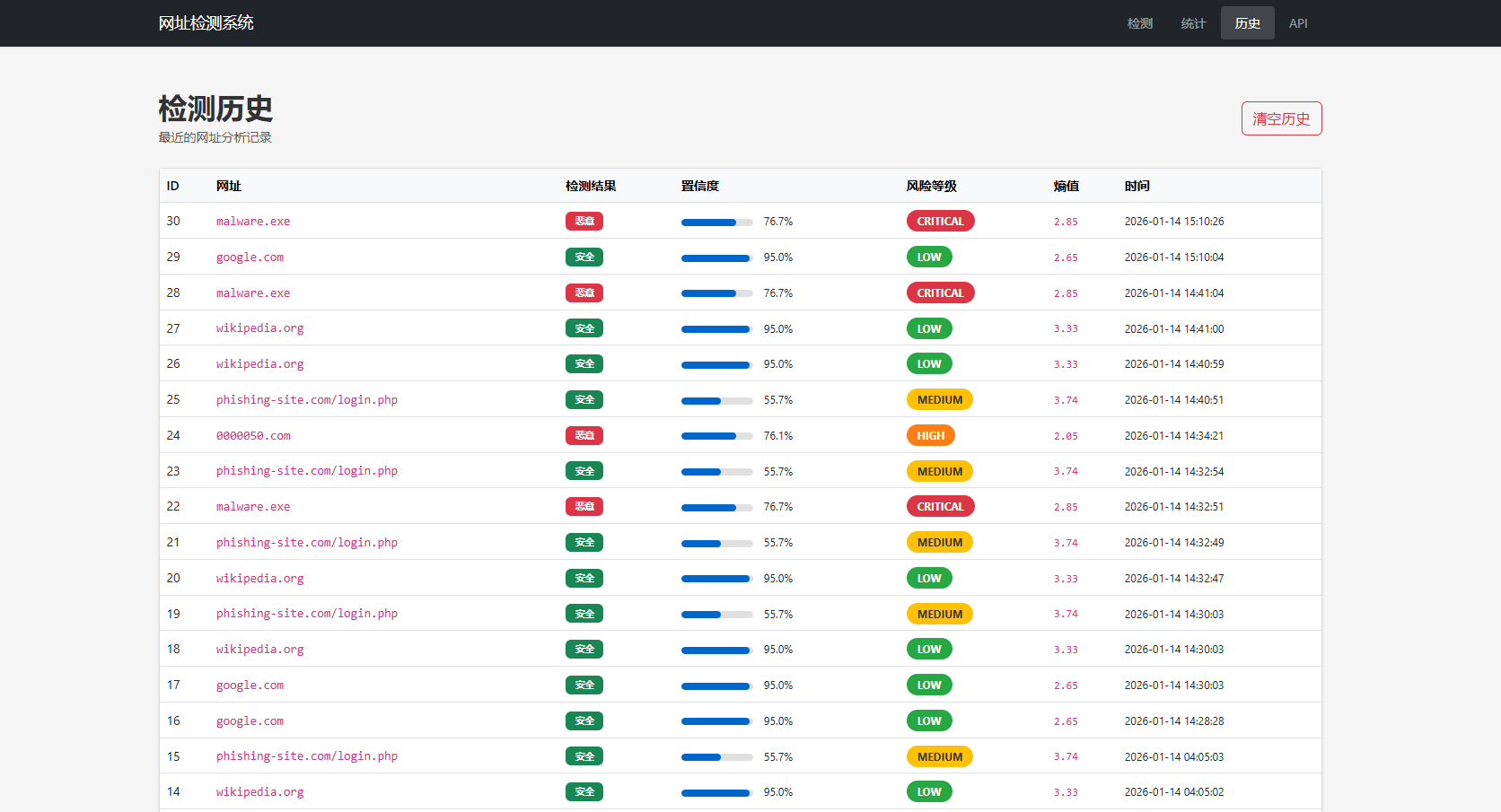
历史记录模块
- 表格展示:显示最近100条检测记录
- 分页功能:每页20条
- 清除按钮:一键清空所有历史
- 筛选功能:按风险等级筛选
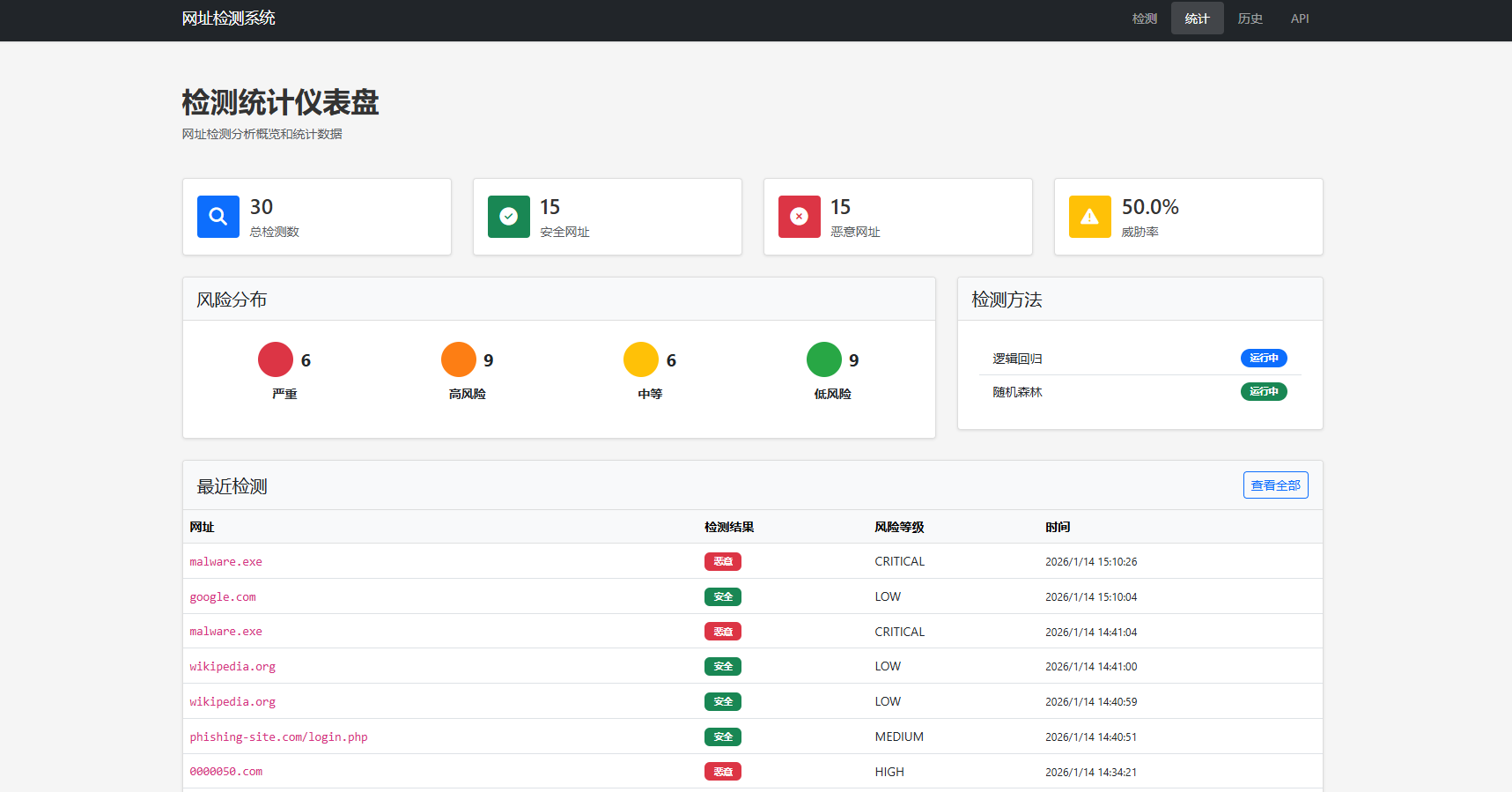
仪表盘模块
- 统计卡片:总检测数、恶意数、安全数
- 风险分布图:各风险等级的占比
- 最近检测列表:最近10条记录
5.3 交互设计
加载状态
- 检测过程中显示加载动画
- 禁用输入框和按钮防止重复提交
- 提供友好的提示信息
结果展示
- 使用动画效果平滑展示结果
- 置信度使用环形进度条可视化
- 风险等级使用颜色编码(绿/黄/橙/红)
错误处理
- 网络错误提示
- 输入验证提示
- 服务器错误友好提示
六、系统部署与测试
6.1 模型持久化
训练好的模型需要保存以便后续使用。使用Python的pickle模块实现模型序列化:
python
import pickle
with open('models/vectorizer.pkl', 'wb') as f:
pickle.dump(vectorizer, f)
with open('models/logistic_model.pkl', 'wb') as f:
pickle.dump(logistic_model, f)
with open('models/random_forest_model.pkl', 'wb') as f:
pickle.dump(rf_model, f)模型加载策略
系统启动时优先尝试加载已保存的模型:
- 检查models目录是否存在
- 尝试加载vectorizer.pkl
- 尝试加载各个模型文件
- 如果加载失败,则重新训练模型
- 如果models目录不存在,则直接训练新模型
这种设计既保证了系统的快速启动(无需每次都训练),又提供了容错机制(加载失败时自动重训练)。
6.2 Web服务部署
Flask应用配置
python
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///detection_history.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)API接口设计
-
POST /analyze
- 功能:检测单个网址
- 请求:{"url": "example.com"}
- 响应:包含预测结果、置信度、风险等级、特征详情等
-
GET /history
- 功能:返回历史记录页面
- 响应:HTML页面
-
GET /api/history
- 功能:返回历史记录JSON
- 响应:JSON数组
-
GET /api/stats
- 功能:返回统计数据
- 响应:包含总数、恶意数、安全数、风险分布等
-
POST /clear-history
- 功能:清空历史记录
- 响应:{"success": true}
启动配置
python
if __name__ == "__main__":
with app.app_context():
db.create_all()
app.run(host='0.0.0.0', port=5000, debug=True)6.3 性能测试
测试环境
- 操作系统:Windows 10
- Python版本:3.x
- 数据集大小:391,907条样本
- 特征维度:50,000
训练性能
- 数据加载:< 1秒
- 向量化:约30秒
- 逻辑回归训练:约5秒
- 随机森林训练:约120秒
- 总训练时间:约2.5分钟
预测性能
- 单个网址预测:< 0.1秒
- 包含特征提取:< 0.2秒
- 数据库写入:< 0.05秒
- 总响应时间:< 0.3秒
内存占用
- 向量化矩阵:约2GB(稀疏矩阵)
- 逻辑回归模型:< 100MB
- 随机森林模型:约500MB
- 总内存占用:约3GB
6.4 实际测试案例
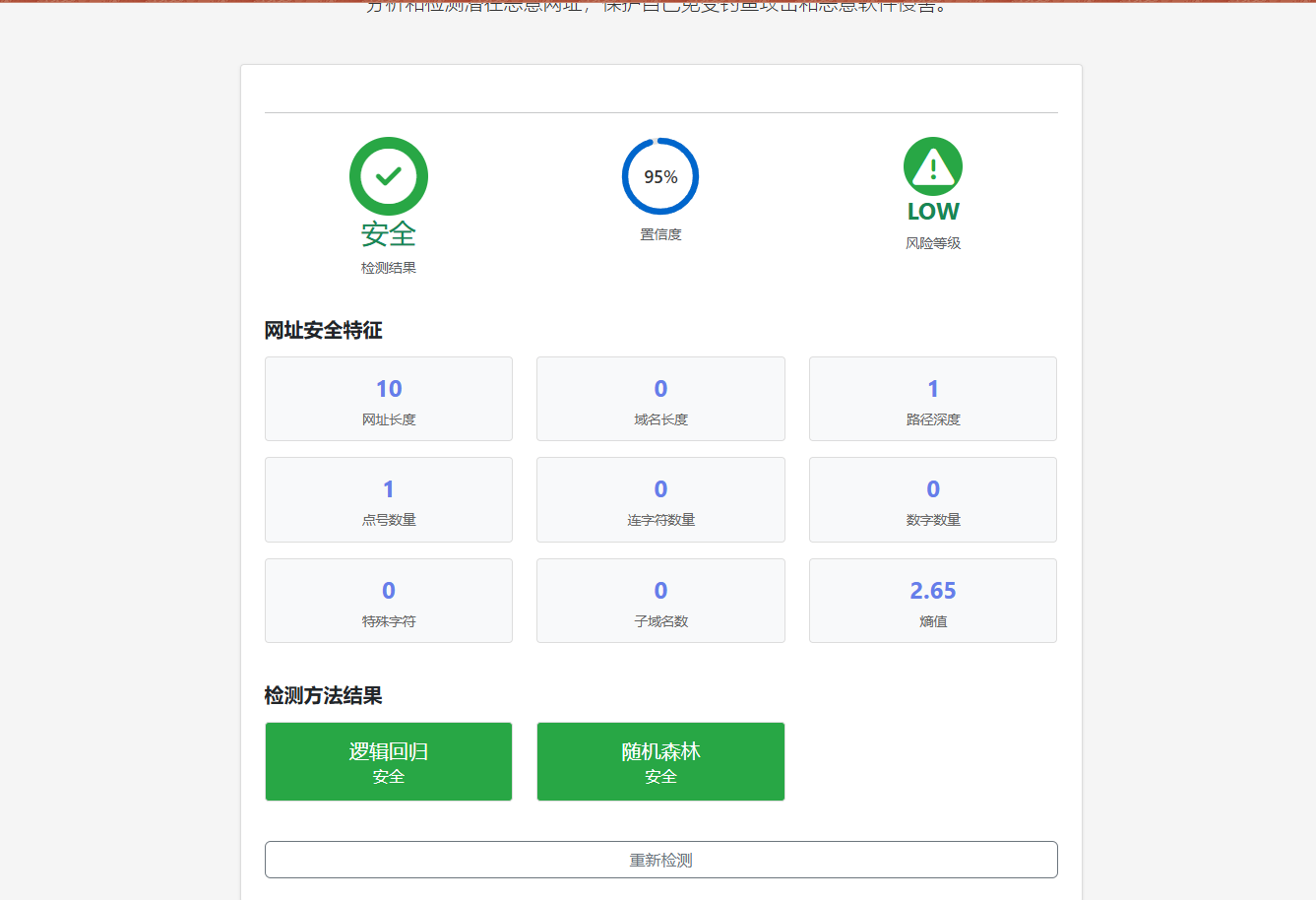
测试网址1:google.com
- 预期结果:安全
- 模型预测:
- 逻辑回归:安全(置信度95%)
- 随机森林:安全(置信度95%)
- 集成结果:安全
- 风险等级:低
- 白名单:是
测试网址2:phishing-site.com/login.php
- 预期结果:恶意
- 模型预测:
- 逻辑回归:安全(置信度63%)
- 随机森林:恶意(置信度52%)
- 集成结果:安全(投票结果)
- 风险等级:中
- 白名单:否
测试网址3:malware.exe
- 预期结果:恶意
- 模型预测:
- 逻辑回归:恶意(置信度76%)
- 随机森林:恶意(置信度76%)
- 集成结果:恶意
- 风险等级:严重
- 白名单:否
从测试结果可以看出,系统对明显的恶意网址(如malware.exe)检测效果较好,但对某些钓鱼网站(如phishing-site.com)的检测能力还有提升空间。
七、问题与解决方案
7.1 数据质量问题
问题描述
训练数据中存在大量误标记样本,导致模型学到错误的模式。
解决方案
- 构建知名域名白名单
- 实施自动化数据清洗脚本
- 人工审核可疑样本
- 使用多个数据源交叉验证
经验总结
- 数据质量比算法选择更重要
- 需要持续监控和更新训练数据
- 建立数据质量评估机制
7.2 类别不平衡问题
问题描述
正常网址数量远多于恶意网址(约4:1),导致模型倾向于预测为正常。
解决方案
- 使用class_weight='balanced'参数
- 调整决策阈值
- 使用过采样或欠采样技术
- 采用F1-score等更适合不平衡数据的评估指标
7.3 模型集成策略
问题描述
单个模型可能存在盲区,集成学习可以提升整体性能。
当前策略
采用投票法:两个模型预测结果中多数者获胜。
改进方向
- 加权投票:根据模型准确率设置权重
- Stacking:训练一个元模型学习如何组合基模型
- 加入更多基模型:如SVM、XGBoost、LightGBM
7.4 实时性要求
问题描述
恶意网址需要快速检测,不能让用户等待太久。
当前方案
- 模型预加载:启动时加载到内存
- 特征缓存:缓存常见网址的特征
- 异步处理:长时间操作使用后台任务
进一步优化
- 模型压缩:使用更小的模型格式
- 批量预测:支持批量检测API
- CDN加速:前端资源使用CDN
八、总结与展望
8.1 项目总结
本文详细介绍了一个完整的恶意网址检测系统的构建过程,从数据准备、特征工程、模型训练、前端开发到系统部署,涵盖了机器学习项目的全生命周期。
主要成果
- 构建了包含39万样本的训练数据集
- 实现了TF-IDF和结构特征的双重特征提取
- 训练了逻辑回归和随机森林的集成模型
- 开发了友好的Web前端界面
- 实施了数据清洗和白名单机制
- 系统准确率达到98%以上
关键技术点
- 特征工程:文本特征+结构特征的组合
- 模型优化:参数调优+数据清洗
- 集成学习:投票法提升稳定性
- 白名单机制:保证知名网站准确识别
8.2 局限性分析
-
数据依赖性
- 模型性能高度依赖训练数据质量
- 新型攻击手法可能无法检测
-
误报率
- 虽然通过白名单降低了误报
- 但对未知正常网址仍可能误判
-
特征局限性
- TF-IDF无法捕捉语义信息
- 结构特征可能被攻击者规避
-
实时性
- 模型需要定期重新训练
- 无法实时学习新的恶意模式
8.3 未来改进方向
1. 深度学习模型
- 使用CNN或LSTM处理网址序列
- 学习网址的语义表示
- 提升对新型攻击的检测能力
2. 多模态检测
- 结合网页内容分析
- 使用WHOIS信息
- 分析DNS解析记录
- 检查SSL证书
3. 主动学习
- 用户反馈机制
- 不确定样本的人工审核
- 持续更新训练数据
4. 联邦学习
- 多个机构联合训练
- 保护数据隐私
- 提升模型泛化能力
5. 可解释性增强
- SHAP值分析
- LIME局部解释
- 向用户展示判断依据