在大数据场景中,数据高可用是核心需求之一。ClickHouse作为高性能列式数据库,虽默认具备优异的查询性能,但需通过副本机制实现数据冗余与故障转移------这一点与MySQL主从架构思路相似,但ClickHouse副本无主从之分,配置更依赖ZooKeeper集群协调。本文将从架构解析、ZooKeeper搭建到ClickHouse副本配置,带你完整实现高可用部署。
一、ClickHouse副本架构解析
ClickHouse副本的核心目标是将数据冗余到多台机器,避免单点故障。其架构有两个关键特性:
- 无主从设计:任意副本节点均可写入数据,写入后会通过ZooKeeper自动同步至其他副本,无需指定"主节点"或"从节点"。
- ZooKeeper依赖:副本间的元数据同步、写入协调、节点状态管理均由ZooKeeper集群负责,确保各副本数据一致性。
下图为ClickHouse副本典型架构:

注:副本配置需针对表级实现,核心是使用
ReplicatedMergeTree引擎(属于MergeTree家族),官方文档可参考ClickHouse Replication。
二、前置准备:ZooKeeper集群搭建
ClickHouse副本依赖ZooKeeper协调,因此需先搭建3节点ZooKeeper集群(生产环境建议奇数节点,确保选举机制正常)。本次搭建使用机器IP为192.168.184.155、192.168.184.156、192.168.184.157,操作需在三台机器上同步执行。
2.1 下载并解压ZooKeeper
-
创建ZooKeeper数据目录并进入:
bashmkdir /data/zookeeper cd /data/zookeeper -
下载指定版本(3.9.4)并解压:
bashwget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.4/apache-zookeeper-3.9.4-bin.tar.gz tar zxvf apache-zookeeper-3.9.4-bin.tar.gz cd apache-zookeeper-3.9.4-bin/conf -
复制默认配置文件并重命名:
bashcp zoo_sample.cfg zoo.cfg
2.2 修改ZooKeeper配置文件
-
编辑
zoo.cfg,添加集群节点信息:bashvim /data/zookeeper/apache-zookeeper-3.9.4-bin/conf/zoo.cfg -
在文件末尾加入以下内容(指定各节点IP与端口):
bashserver.1=192.168.184.155:2888:3888 server.2=192.168.184.156:2888:3888 server.3=192.168.184.157:2888:38882888:节点间通信端口(Leader与Follower交互);3888:选举端口(节点选举Leader时使用)。
2.3 配置节点唯一标识(myid)
-
创建
myid存储目录:bashmkdir /tmp/zookeeper/ -
为不同节点写入唯一标识(每台机器需单独执行,值对应
server.N中的N):- 192.168.184.155:
echo 1 > /tmp/zookeeper/myid - 192.168.184.156:
echo 2 > /tmp/zookeeper/myid - 192.168.184.157:
echo 3 > /tmp/zookeeper/myid
- 192.168.184.155:
2.4 启动ZooKeeper集群
在三台机器上分别执行启动命令:
bash
/data/zookeeper/apache-zookeeper-3.9.4-bin/bin/zkServer.sh start- 可通过
zkServer.sh status查看节点状态(会显示Leader或Follower,确认集群正常运行)。
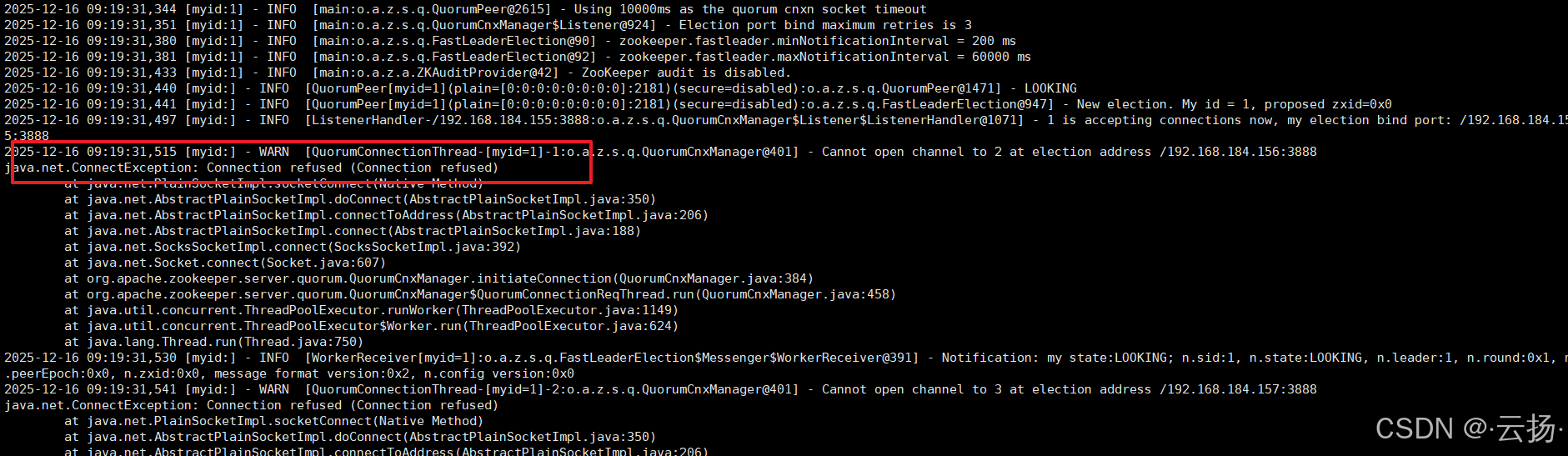
ZooKeeper 集群状态查看报错处理步骤:
- 报错查看 :执行
/data/zookeeper/apache-zookeeper-3.9.4-bin/bin/zkServer.sh status查看 ZooKeeper 节点状态,若出现 "Error contacting service. It is probably not running" 报错,通过tail -f /data/zookeeper/apache-zookeeper-3.9.4-bin/logs/zookeeper-root-server-maria-05.out查看日志文件
- 故障排除 :若日志显示类似
java.net.AbstractPlainSocketImpl.connect的连接相关报错,在三台机器上执行iptables -F清除防火墙规则
- 重启验证:执行
/data/zookeeper/apache-zookeeper-3.9.4-bin/bin/zkServer.sh restart重启 ZooKeeper,再运行状态查看命令,此时应显示正常状态(leader或follower)


三、ClickHouse副本配置与测试
完成ZooKeeper集群搭建后,开始配置ClickHouse副本。本次选择192.168.184.155和192.168.184.156作为两个ClickHouse副本节点。
3.1 修改ClickHouse配置文件
-
编辑ClickHouse主配置文件
config.xml:bashvim /etc/clickhouse-server/config.xml -
搜索并修改
zookeeper节点,指向已搭建的ZooKeeper集群(使用域名maria-01/maria-02/maria-03简化配置):xml<zookeeper> <node> <host>maria-05</host> <port>2181</port> </node> <node> <host>maria-06</host> <port>2181</port> </node> <node> <host>maria-07</host> <port>2181</port> </node> </zookeeper> -
配置域名解析(若系统无法识别
maria-05等域名,需在三台机器 的/etc/hosts中添加映射):bashvim /etc/hosts # 加入以下内容 192.168.184.155 maria-05 192.168.184.156 maria-06 192.168.184.157 maria-07 -
重启ClickHouse服务(两台副本节点均需执行):
bash/etc/init.d/clickhouse-server restart
3.2 创建副本表(ReplicatedMergeTree引擎)
ClickHouse副本通过表级配置实现,需在两个副本节点上分别创建表,核心是确保ReplicatedMergeTree引擎的ZooKeeper路径一致。
步骤1:在192.168.184.155(副本1)创建表
-
进入ClickHouse客户端:
clickhouse-client -m -
执行建库与建表语句:
sql-- 创建数据库 create database db_repl; -- 创建副本表 CREATE TABLE db_repl.repl_test ( EventDate DateTime, -- 时间字段 CounterID UInt32, -- 计数器ID UserID UInt32 -- 用户ID ) ENGINE = ReplicatedMergeTree( '/clickhouse/tables/repl_test', -- ZooKeeper中存储表元数据的路径(需一致) 'maria01' -- 副本名称(每个副本唯一,如maria01、maria02) ) PARTITION BY toYYYYMM(EventDate) -- 按年月分区 ORDER BY (CounterID, EventDate, intHash32(UserID)) -- 排序键 SAMPLE BY intHash32(UserID); -- 采样键(用于近似查询)
步骤2:在192.168.184.156(副本2)创建表
与副本1语句基本一致,仅需修改副本名称 为maria02:
sql
create database db_repl;
CREATE TABLE db_repl.repl_test
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
)
ENGINE = ReplicatedMergeTree(
'/clickhouse/tables/repl_test', -- 路径与副本1完全一致
'maria02' -- 副本名称唯一
)
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);关键原则:只要两个表在ZooKeeper中的路径(第一个参数)一致,即可自动同步数据。
3.3 测试副本数据同步
-
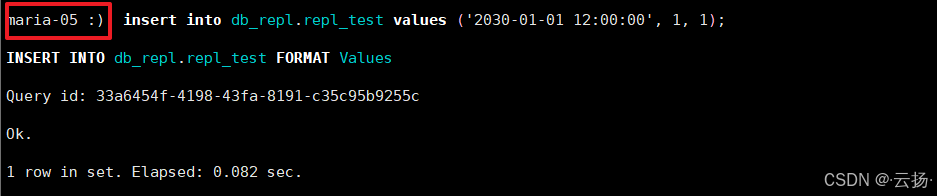
在副本1(192.168.184.155)插入测试数据:
sqlinsert into db_repl.repl_test values ('2030-01-01 12:00:00', 1, 1); -
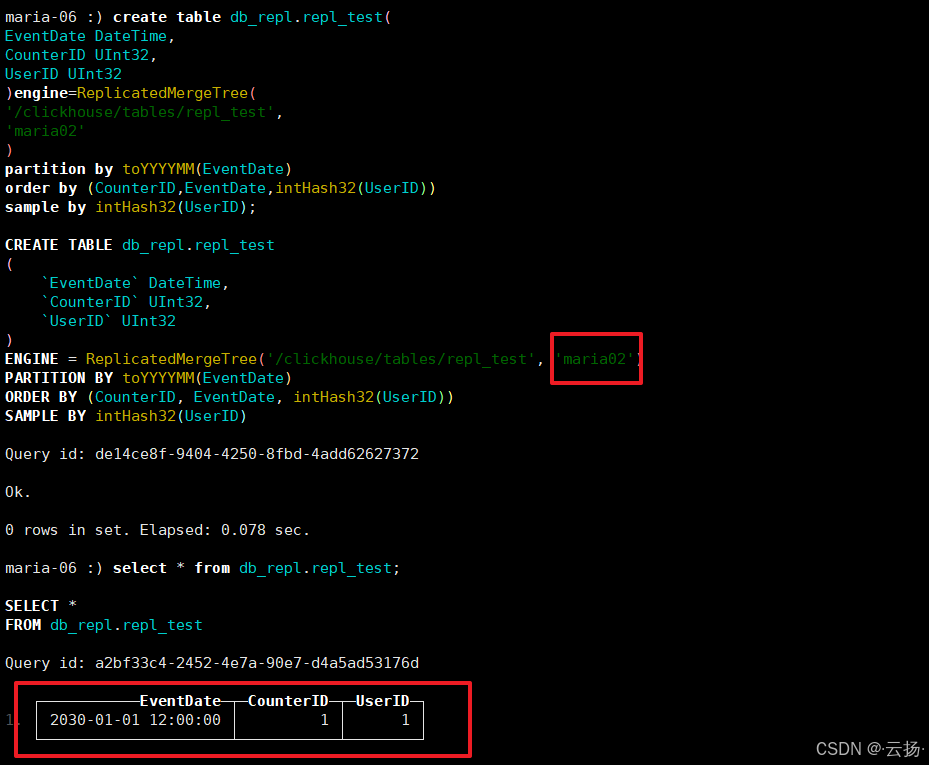
在副本2(192.168.184.156)查询数据,验证同步结果:
sqlselect * from db_repl.repl_test;若查询结果显示插入的
(2030-01-01 12:00:00, 1, 1),则说明副本同步正常。
同步测试效果示意图:
四、总结
ClickHouse副本配置的核心是"ZooKeeper协调+ReplicatedMergeTree引擎",关键要点可归纳为三点:
- ZooKeeper集群需确保奇数节点,配置
myid与server.N对应,保证选举与通信正常; - ClickHouse副本表的
ReplicatedMergeTree引擎,需统一ZooKeeper路径、区分副本名称; - 数据同步无需手动触发,写入任意副本后,ZooKeeper会自动协调其他副本拉取数据。
通过以上步骤,即可实现ClickHouse数据的高可用冗余,应对单点故障风险,适合生产环境部署使用。