文章目录
- 前言
- 问题介绍
- 指标分析
- 诊断过程
- 原因分析
-
- 有可能报错的就是我添加的5列吗
- 为什么刚好只有我添加5列以前的Partition报错,而添加5列以后的Partition均不报错?
- 为什么我添加这5列以前,那些partition都不出错
- [ClickHouse会对part中不存在但是表中存在的列进行Vertical Merge吗](#ClickHouse会对part中不存在但是表中存在的列进行Vertical Merge吗)
- MergeTreeSequentialSource的构造和依赖列的添加
- IMergeTreeReader的构造和子流的添加
- [第一次补列: IMergeTreeReader::fillMissingColumns()方法对缺失列进行填充](#第一次补列: IMergeTreeReader::fillMissingColumns()方法对缺失列进行填充)
-
- IMergeTreeReader::fillMissingColumns()填充类型默认值
- DB::fillMissingColumns()中的默认值填充
- IDataType::forEachSubcolumn()收集获取所有的subcolumn列
- [举例说明复合类型的 offsets 复用与默认值补齐](#举例说明复合类型的 offsets 复用与默认值补齐)
- [第二次补列: 通过IMergeTreeReader::evaluateMissingDefaults()来评估默认值计算](#第二次补列: 通过IMergeTreeReader::evaluateMissingDefaults()来评估默认值计算)
-
- IMergeTreeReader::evaluateMissingDefaults()的基本流程
- 构造基列数据时为Map构造默认数据,产生ColumnNothing类型
- [getSubcolumnData: 通过构造出来的基列数据来获取子列数据并发生转换错误](#getSubcolumnData: 通过构造出来的基列数据来获取子列数据并发生转换错误)
- SELECT失败的原因分析
- 添加日志解释疑惑并找到整个异常发生的原因
前言
我们经常对ClickHouse中的表的字段进行修改,其中最常进行的是增加列,因为列的增加在逻辑上是没有impact的。
在我们的一次增加列操作完成以后,ClickHouse看起来正常,但是随后,ClickHouse的Mutate操作被阻塞,Merge操作大量失败,ClickHouse负载逐渐恶化,重启ClickHouse Server无法解决问题。
本文详细讲述了我们遇到问题、尝试解决问题并无效、然后分析日志和堆栈、重新解决问题的整个过程,以及在问题被解决以后,通过添加日志、重新编译ClickHouse从而最终找到问题根因的基本过程。然后,我们以此过程为基础,在代码层面介绍了ClickHouse的Merge的基本概念以及Substream的基本概念,对默认值进行填充的基本原理。
希望读者能从本文中看到我们对一个分布式系统进行监控分析、日志分析、堆栈分析的基本过程,通过添加日志和重新编译进而让问题重新并找到根本原因的过程,以及我们理解ClickHouse在代码层面实现Merge、缺省值补充、复杂类型解析的基本原理。
从这个问题的解决过程中,我们总结到:
- 发生问题时先解决问题以降低影响,事后再分析原因;
- 问题发生时尽量保存现场,尤其是重启以前需要先打印堆栈,以便进行事后分析;
- 一个异常问题的发生,往往是环环相扣的各种因果相互串联导致的最后结果;
- 复杂问题的发生从触发到最后发生,要想理解整个过程,需要大量的知识准备,比如,本文中需要理解Merge的调度,需要理解Vertical Merge的机制,需要理解复杂类型(Array, Map, Tuple等等)的Substream的处理机制,需要理解默认值表达式和类型默认值的处理机制,需要理解Block的概念等等。
- 很多问题无法根据当时的现场就直接找到根本原因,因此最好是能够重现问题。只要问题能够重现,我们就可以添加日志并重新编译运行,那么根本原因就一定能找到。
问题介绍
我们对表进行的修改操作如下所示:
sql
ALTER TABLE {{ DATABASE NAME PLACEHOLDER }}.emo_mdm_flowwork_pt1m_local ON CLUSTER {{ CLUSTER NAME PLACEHOLDER FOR ALL HOSTS }}
ADD COLUMN IF NOT EXISTS `host` String DEFAULT '' CODEC(ZSTD(1)) AFTER connType,
ADD COLUMN IF NOT EXISTS `path` String DEFAULT '' CODEC(ZSTD(1)) AFTER host,
ADD COLUMN IF NOT EXISTS `referrer` String DEFAULT '' CODEC(ZSTD(1)) AFTER path,
ADD COLUMN IF NOT EXISTS `title` String DEFAULT '' CODEC(ZSTD(1)) AFTER referrer,
ADD COLUMN IF NOT EXISTS `referrerHost` String DEFAULT '' CODEC(ZSTD(1)) AFTER title;可以看到:
- 我们新增的列的类型都是简单类型String,同时也不是LowCardinarity
- 我们后面在堆栈中看到的Merge失败全是LowCardinaltity类型相关,这说明,堆栈中所抛出的LowCardinaltity异常的列(堆栈中并没有指出具体列名)根本不是我们新增的这5列,但是,这并不代表这个异常不是因为我们新增这5列所间接导致的。
- 我们新增的类型都显式提供了默认值,这意味着,对于缺少这些列的Part,ClickHouse不需要根据类型默认值去设置这些列的实际值,而只需要根据默认值表达式(即我们设置的
'')来设置他们的值。 - 我们后面看堆栈可以看出来,堆栈的入口
evaluateMissingDefaults()正是在进行默认值推断,即对缺少这些新增的5列的part进行默认值的计算(尽管我们的默认值设置为'',但其实也是一个表达式,一个最简单的表达式)以设置这些新增列的值
Mutation被阻塞
我们最初发现问题既不是从Dashboard上看到Merge的暴增,也不是从日志中看到了Merge的异常,而是,我们突然发现,我们的一些Regular Mutation Job的Mutation操作总是长期被Block住。
我们(Team B)的ETL Pipeline是将HDFS中存放的Parquet文件(由Team A生成)转换成ClickHouse的格式,每分钟一个batch的数据。这样,我们对于每分钟的数据,会通过attach的方式,bulkload到ClickHouse中,这种Bulkload的方式可以以极小的代价实现大量数据的插入,避免对查询造成影响。
当上游的Parquet文件出现问题,Team A会重新生成Parquet文件,然后我们会负责对数据进行修复。Repair过程和Regular Ingestion的过程的唯一区别是,Repair需要再Regular Ingestion以前先进行数据的删除。
这种删除我们采用的是异步软删除的方式,即异步删除,然后阻塞等待删除完成(即显式查询到数据量为0)。我们发现,在由7*2的物理架构下(7个Shard,每个Shard有两个Replica),只有两个Shard能完成数据的删除,其余5个Shard的数据删除全部被block住,并且看起来是永久阻塞,没有恢复的迹象。
在很多情况下,数据删除超时是由于Pool的大小不足导致的,这个不足不仅仅是延迟了删除的进行,因为根据ClickHouse的设计动机,Merge的优先级是高于Mutate的,因此,在Pool不足的情况下,如果Merge长期占有系统Pool,那么Mutate的确可能无法进行,但是不至于永久无法进行。
所以,我们经过代码分析并结合Metrics监控,增大了Merge/Mutate Pool的大小(Merge和Mutate共享一个Pool),但是并没有解决问题,Mutate操作依然处于被block的装填。
排除Pool资源限制导致阻塞
在ClickHouse里面,这个MergeAndMutatePool是通过background_pool_size参数在Server级别调整的,并且,这个调整如果是增大,则不需要重启ClickHouse,ClickHouse会动态加载这个变更,然后根据增大的值去创建新的Pool。如果是减小,则是需要重启ClickHouse的。
我们将background_pool_size的大小从当前的32设置到了48。
下图显示的是ClickHouse中对应的Gauge Metrics ClickHouseMetrics_BackgroundMergesAndMutationsPoolSize的值,可以看到,当我们将 background_pool_size的值从32调整到48以后,对应的ClickHouseMetrics_BackgroundMergesAndMutationsPoolSize的值从64变成了96,具体为什么 ClickHouseMetrics_BackgroundMergesAndMutationsPoolSize的值是background_pool_size的4倍,在我的另外一篇文章会具体讲解。
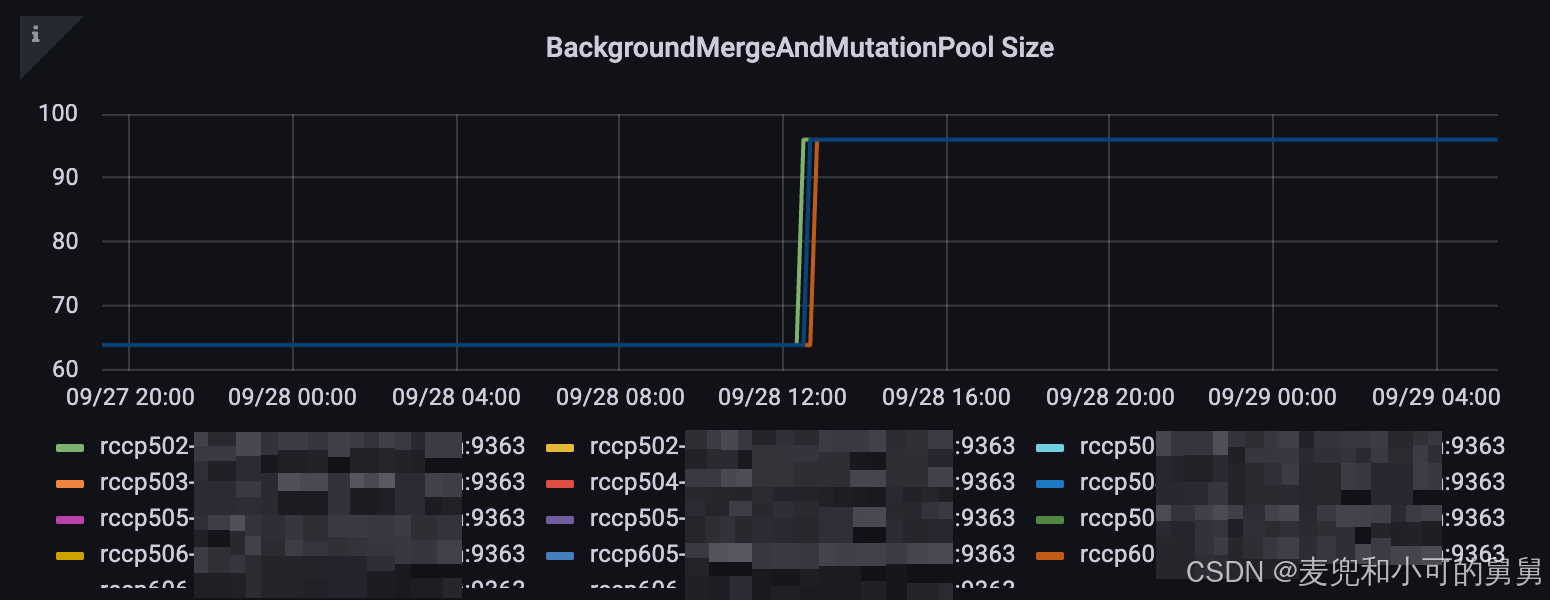
在增大了Pool的大小以后,效果很明显,又有好几个Shard的删除操作完成了(但是依然用了一些时间,只是在我们设置的超时发生以前完成)。但是也很遗憾,居然还有一个Shard的删除操作始终无法完成。
发现Merge操作大量报错
我们看到,无法进行删除的表正好是我们加了列的表,其它所有表都没有发生这个问题。这说明这个删除问题和我们添加列有关。
mutation操作无法顺利完成,我们查询system.mutations表,查看对应mutation操作的详细信息:
sql
SELECT *
FROM system.mutations
WHERE is_done = '0'结果如下:
shell
rcmp501-1.iad7.prod.corp.com :) select * from system.mutations where is_done = '0'
Query id: 75f439d6-0ab4-4a3b-916a-30e66adb0126
┌─database───┬─table───────────────────────────┬─mutation_id─┬─command─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─────────create_time─┬─block_numbers.partition_id─┬─block_numbers.number─┬─parts_to_do_names─────────┬─parts_to_do─┬─is_done─┬─is_killed─┬─latest_failed_part─┬────latest_fail_time─┬─latest_fail_reason─┐
1. │ dsi_iad_c2 │ emo_mdm_flowwork_pt1m_local │ 0000000012 │ UPDATE _row_exists = 0 IN PARTITION 20250925 WHERE (timestampMs >= '2025-09-25 05:00:00') AND (timestampMs < '2025-09-25 05:01:00') │ 2025-09-30 03:23:58 │ ['20250925'] │ [1441] │ ['20250925_0_667_10_204'] │ 1 │ 0 │ 0 │ │ 1970-01-01 00:00:00 │ │注意, system.mutations中的parts_to_do_names 指的是进行merge或者mutate生成的目标part,而不是source part。
由于我们的所有表都是ReplicatedMergeTree,因此,我们希望查询system.replication_queue表,看看当前有哪些正在执行的RepliatedMergeTree任务,即,我们hang住的mutate操作到底现在什么状态:
sql
SELECT
database,
`table`,
replica_name,
position,
node_name,
create_time,
source_replica,
new_part_name,
parts_to_merge,
is_currently_executing
FROM system.replication_queue
WHERE last_exception LIKE '%Bad cast from type DB%'
ORDER BY create_time DESC
LIMIT 20我们看到 system.replication_queue中有一些正在进行的并且抛出异常的replication任务。
我们看到,在system.mutations表里面无法完成的这个mutation的parts_to_do_names 20250925_0_667_10_204,正好出现在system.replication_queue表中的new_part_name字段中:
shell
rcmp501-1.iad7.prod.corp.com :) SELECT database, table, replica_name, position, node_name, create_time, source_replica, new_part_name, parts_to_merge, is_currently_executing
FROM system.replication_queue
WHERE last_exception like '%Bad cast from type DB%' -- get the replication_queue which has exception like Bad cast from type DB::ColumnNothing to DB::ColumnLowCardinality:
ORDER BY create_time desc
LIMIT 20;
Query id: 51564cfb-1e90-4d8d-a9a7-02cecf63e130
┌─database───┬─table──────────────────────────────┬─replica_name────────────────────┬─position─┬─node_name────────┬─────────create_time─┬─source_replica──────────────────┬─new_part_name───────────────────────────────┬─parts_to_merge─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─is_currently_executing─┐
1. │ dsi_iad_c1 │ emo_mdm_flowwork_pt30m_local │ rcmp501-1.iad7.prod.corp.com │ 6 │ queue-0000009389 │ 2025-09-29 15:45:13 │ rcmp501-1.iad7.prod.corp.com │ 20250924_46_47_1 │ ['20250924_46_46_0','20250924_47_47_0'] │ 1 │
.....
12. │ dsi_iad_c2 │ emo_mdm_flowwork_pt1m_local │ rcmp501-1.iad7.prod.corp.com │ 2 │ queue-0000042457 │ 2025-09-25 11:12:38 │ rcmp501-2.iad7.prod.corp.com │ 20250925_0_667_10_204 │ ['20250925_0_148_9_204','20250925_149_345_8_204','20250925_346_524_8','20250925_525_583_6','20250925_584_657_7','20250925_658_667_2'] │ 1 │ └────────────┴────────────────────────────────────┴─────────────────────────────────┴──────────┴──────────────────┴─────────────────────┴─────────────────────────────────┴─────────────────────────────────────────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴────────────────────────┘
12 rows in set. Elapsed: 0.002 sec.从 system.replication_queue中可以看到,这里的mutate的source part是['20250925_0_148_9_204','20250925_149_345_8_204','20250925_346_524_8','20250925_525_583_6','20250925_584_657_7','20250925_658_667_2'],目标part是20250925_0_667_10_204,这个目标part正好就是我们的mutate操作的目标part。
所以我们初步怀疑,这个mutation无法完成的原因,就是底层的Merge操作无法完成,而底层的Merge操作无法完成的原因,就体现在堆栈中。我们需要分析堆栈,来试图找到原因。
的确,我们检查日志,发现日志在大量报类似以下的错误:
shell
2025.09.28 11:29:54.720651 [ 1885500 ] {} <Error> MergeTreeBackgroundExecutor: Exception while executing background task {196977f5-53bc-43eb-b79b-e54898814be5::20250831_4221_4390_4}: Code: 49. DB::Exception: Bad cast from type DB::ColumnNothing to DB::ColumnLowCardinality: (while reading from part /mycorp/data/nvme2/clickhouse/store/196/196977f5-53bc-43eb-b79b-e54898814be5/20250831_4221_4248_3/ located on disk disk2 of type local): While executing MergeTreeSequentialSource. (LOGICAL_ERROR), Stack trace (when copying this message, always include the lines below):
0. DB::Exception::Exception(DB::Exception::MessageMasked&&, int, bool) @ 0x000000000daffc3b
1. DB::Exception::Exception(PreformattedMessage&&, int) @ 0x0000000007e59fcc
2. DB::Exception::Exception<String, String>(int, FormatStringHelperImpl<std::type_identity<String>::type, std::type_identity<String>::type>, String&&, String&&) @ 0x0000000007e5bdcb
3. _Z11typeid_castIRKN2DB20ColumnLowCardinalityEKNS0_7IColumnEQsr3stdE14is_reference_vIT_EES6_RT0_ @ 0x00000000081b10c4
4. DB::SerializationLowCardinality::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111abbb0
5. DB::SerializationNamed::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111b7bba
6. DB::SerializationTuple::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111f5f02
7. DB::SerializationArray::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x000000001117f49d
8. DB::SerializationMap::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111b70e7
9. DB::IDataType::getSubcolumnData(std::basic_string_view<char, std::char_traits<char>>, DB::ISerialization::SubstreamData const&, bool) @ 0x0000000011140e8e
10. DB::IDataType::getSubcolumn(std::basic_string_view<char, std::char_traits<char>>, COW<DB::IColumn>::immutable_ptr<DB::IColumn> const&) const @ 0x0000000011141a88
11. DB::IMergeTreeReader::evaluateMissingDefaults(DB::Block, std::vector<COW<DB::IColumn>::immutable_ptr<DB::IColumn>, std::allocator<COW<DB::IColumn>::immutable_ptr<DB::IColumn>>>&) const @ 0x0000000012b403e8
12. DB::MergeTreeSequentialSource::generate() @ 0x0000000012b601ec
13. DB::ISource::tryGenerate() @ 0x000000001303219b
14. DB::ISource::work() @ 0x0000000013031ea7
15. DB::ExecutionThreadContext::executeTask() @ 0x000000001304b0e7
16. DB::PipelineExecutor::executeStepImpl(unsigned long, std::atomic<bool>*) @ 0x000000001303f9b0
17. DB::PipelineExecutor::executeStep(std::atomic<bool>*) @ 0x000000001303f3c8
18. DB::PullingPipelineExecutor::pull(DB::Chunk&) @ 0x000000001304f437
19. DB::PullingPipelineExecutor::pull(DB::Block&) @ 0x000000001304f639
20. DB::MergeTask::VerticalMergeStage::executeVerticalMergeForAllColumns() const @ 0x000000001298615f
21. DB::MergeTask::VerticalMergeStage::execute() @ 0x000000001298596e
22. DB::MergeTask::execute() @ 0x0000000012985122
23. DB::ReplicatedMergeMutateTaskBase::executeStep() @ 0x0000000012c47640
24. DB::MergeTreeBackgroundExecutor<DB::DynamicRuntimeQueue>::threadFunction() @ 0x000000001299d7bd
25. ThreadPoolImpl<ThreadFromGlobalPoolImpl<false, true>>::worker(std::__list_iterator<ThreadFromGlobalPoolImpl<false, true>, void*>) @ 0x000000000dbd4649
26. void std::__function::__policy_invoker<void ()>::__call_impl<std::__function::__default_alloc_func<ThreadFromGlobalPoolImpl<false, true>::ThreadFromGlobalPoolImpl<void ThreadPoolImpl<ThreadFromGlobalPoolImpl<false, true>>::scheduleImpl<void>(std::function<void ()>, Priority, std::optional<unsigned long>, bool)::'lambda0'()>(void&&)::'lambda'(), void ()>>(std::__function::__policy_storage const*) @ 0x000000000dbd8791
27. void* std::__thread_proxy[abi:v15007]<std::tuple<std::unique_ptr<std::__thread_struct, std::default_delete<std::__thread_struct>>, void ThreadPoolImpl<std::thread>::scheduleImpl<void>(std::function<void ()>, Priority, std::optional<unsigned long>, bool)::'lambda0'()>>(void*) @ 0x000000000dbd7509这个堆栈的含义是
-
试图将source part
20250831_4221_4248_3进行merge操作生成一个target part20250831_4221_4390_4。我们根据ClickHouse中part的命名规则可以知道,这个part的partition是20250831, block index的范围是[4221,4248],这个source part的version是3,合并以后即将生成的part的version是4,会加1 -
出问题的Merge Stage是
VerticalMergeStage。这个从堆栈片段上可以看到:shell20. DB::MergeTask::VerticalMergeStage::executeVerticalMergeForAllColumns() const @ 0x000000001298615f 21. DB::MergeTask::VerticalMergeStage::execute() @ 0x000000001298596e 22. DB::MergeTask::execute() @ 0x0000000012985122在我的另外一篇文章中讲到,无论是
HorizontalMerge还是VerticalMerge都会经历的3个Stage,ExecuteAndFinalizeHorizontalPart,VerticalMergeStage和MergeProjectionsStage。其中-
到底是使用Vertical还是Horizontal Merge的决策发生在第一个Stage即
ExecuteAndFinalizeHorizontalPart的准备(prepare())阶段; -
无论决策出来的是Horizontal Merge还是Vertical Merge,都会走完这三个阶段;
-
但是,如果决策出来的是
Horizontal Merge,第二个Stage(VerticalMergeStage)没有实质性的执行代码。比如,如果是HorizontalMerge,那么在执行第二个Stage的3个Task的时候,都会首先检查当前的Merge Algorithm, 如果是Horizontal Merge,直接返回成功:bool MergeTask::VerticalMergeStage::executeVerticalMergeForAllColumns() const { /// No need to execute this part if it is horizontal merge. if (global_ctx->chosen_merge_algorithm != MergeAlgorithm::Vertical) return false; // 返回false,代表执行完成,无需再次调用 .... } -
所以,堆栈里面的
VerticalMergeStage在进行实质性的执行,说明这里决策出来的是Vertical Merge
-
-
这个merge失败了,失败的原因似乎是,在原始数据里面看到的是
DB::ColumnNothing,但是在进行merge操作的时候,发现目标的type居然是DB::ColumnLowCardinality,类型不匹配,因此失败。
查询也发生了问题
同时,我们后来发现,query也有问题:
shell
2025.10.21 09:14:27.151626 [ 3560516 ] {1a5dc00f-bd2f-414e-a73b-20e8e439058f} <Error> TCPHandler: Code: 49. DB::Exception: Bad cast from type DB::ColumnNothing to DB::ColumnLowCardinality: (while reading from part /nvme6n1/clickhouse/store/95c/95c035af-e614-4fca-9fba-ab871235e324/20250925_0_201_3_2847/ located on disk disk5 of type local): While executing MergeTreeSelect(pool: ReadPool, algorithm: Thread). (LOGICAL_ERROR), Stack trace (when copying this message, always include the lines below):
0. DB::Exception::Exception(DB::Exception::MessageMasked&&, int, bool) @ 0x000000000daffc3b
1. DB::Exception::Exception(PreformattedMessage&&, int) @ 0x0000000007e59fcc
2. DB::Exception::Exception<String, String>(int, FormatStringHelperImpl<std::type_identity<String>::type, std::type_identity<String>::type>, String&&, String&&) @ 0x0000000007e5bdcb
3. _Z11typeid_castIRKN2DB20ColumnLowCardinalityEKNS0_7IColumnEQsr3stdE14is_reference_vIT_EES6_RT0_ @ 0x00000000081b10c4
4. DB::SerializationLowCardinality::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111abbb0
5. DB::SerializationNamed::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111b7bba
6. DB::SerializationTuple::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111f5f02
7. DB::SerializationArray::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x000000001117f49d
8. DB::SerializationMap::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111b70e7
9. DB::IDataType::getSubcolumnData(std::basic_string_view<char, std::char_traits<char>>, DB::ISerialization::SubstreamData const&, bool) @ 0x0000000011140e8e
10. DB::IDataType::getSubcolumn(std::basic_string_view<char, std::char_traits<char>>, COW<DB::IColumn>::immutable_ptr<DB::IColumn> const&) const @ 0x0000000011141a88
11. DB::IMergeTreeReader::evaluateMissingDefaults(DB::Block, std::vector<COW<DB::IColumn>::immutable_ptr<DB::IColumn>, std::allocator<COW<DB::IColumn>::immutable_ptr<DB::IColumn>>>&) const @ 0x0000000012b403e8
12. DB::MergeTreeRangeReader::read(unsigned long, DB::MarkRanges&) @ 0x0000000012b4d96a
13. DB::MergeTreeRangeReader::read(unsigned long, DB::MarkRanges&) @ 0x0000000012b4c5ec
14. DB::MergeTreeRangeReader::read(unsigned long, DB::MarkRanges&) @ 0x0000000012b4c5ec
15. DB::MergeTreeRangeReader::read(unsigned long, DB::MarkRanges&) @ 0x0000000012b4c5ec
16. DB::MergeTreeReadTask::read(DB::MergeTreeReadTask::BlockSizeParams const&) @ 0x0000000012b6dfa8
17. DB::MergeTreeThreadSelectAlgorithm::readFromTask(DB::MergeTreeReadTask&, DB::MergeTreeReadTask::BlockSizeParams const&) @ 0x000000001346c28f
18. DB::MergeTreeSelectProcessor::read() @ 0x0000000012b6af7d
19. DB::MergeTreeSource::tryGenerate() @ 0x00000000134a2ca8
20. DB::ISource::work() @ 0x0000000013031ea7
21. DB::ExecutionThreadContext::executeTask() @ 0x000000001304b0e7
22. DB::PipelineExecutor::executeStepImpl(unsigned long, std::atomic<bool>*) @ 0x000000001303f9b0
23. void std::__function::__policy_invoker<void ()>::__call_impl<std::__function::__default_alloc_func<DB::PipelineExecutor::spawnThreads()::$_0, void ()>>(std::__function::__policy_storage const*) @ 0x000000001304106e
24. ThreadPoolImpl<ThreadFromGlobalPoolImpl<false, true>>::worker(std::__list_iterator<ThreadFromGlobalPoolImpl<false, true>, void*>) @ 0x000000000dbd4649
25. void std::__function::__policy_invoker<void ()>::__call_impl<std::__function::__default_alloc_func<ThreadFromGlobalPoolImpl<false, true>::ThreadFromGlobalPoolImpl<void ThreadPoolImpl<ThreadFromGlobalPoolImpl<false, true>>::scheduleImpl<void>(std::function<void ()>, Priority, std::optional<unsigned long>, bool)::'lambda0'()>(void&&)::'lambda'(), void ()>>(std::__function::__policy_storage const*) @ 0x000000000dbd8791
26. void* std::__thread_proxy[abi:v15007]<std::tuple<std::unique_ptr<std::__thread_struct, std::default_delete<std::__thread_struct>>, void ThreadPoolImpl<std::thread>::scheduleImpl<void>(std::function<void ()>, Priority, std::optional<unsigned long>, bool)::'lambda0'()>>(void*) @ 0x000000000dbd7509
27. ? @ 0x00007f962f528609
28. ? @ 0x00007f962f44d353我们发现,如果查询条件中有新增的这5列,那么会报和Merge一样的错误,错误本身不是发生在新增的列上,而是发生在复合列上(Map -> Array -> Tuple -> Named, 参考上面的堆栈),而如果查询条件中没有我们新增的这5列,则不会报错。
比如,当查询条件中不包含我们新增的5列的时候,查询没有问题:
select count(1)
FROM emo_mdm_flowwork_pt30m_dist AS mdm_flowwork
WHERE mdm_flowwork.customerId = 343821232 AND
mdm_flowwork.timestampMs >= '2025-09-25 00:00:00' AND
mdm_flowwork.timestampMs < '2025-10-25 00:00:00' AND
mdm_flowwork.platform = 'web' and
mdm_flowwork.flowId IN('f_5333_5842') AND
mdm_flowwork.platform = 'web' and mdm_flowwork.appBuild = 'ddd'
SELECT count(1)
FROM emo_mdm_flowwork_pt30m_dist AS mdm_flowwork
WHERE (mdm_flowwork.customerId = 343821232) AND (mdm_flowwork.timestampMs >= '2025-09-25 00:00:00') AND (mdm_flowwork.timestampMs < '2025-10-25 00:00:00') AND (mdm_flowwork.platform = 'web') AND (mdm_flowwork.flowId IN ('f_5333_5842')) AND (mdm_flowwork.platform = 'web') AND (mdm_flowwork.appBuild = 'ddd')
Query id: 1c2402fe-7bcd-4741-9074-3c32e5f196ec
┌─count()─┐
1. │ 0 │
└─────────┘但是,当查询条件中包含了我们新增的5列(mdm_flowwork.referrer = 'ddd')的时候,查询报错,且报错和我们的Merge报错一模一样:
sql
rcmp502-2.iad7.prod.corp.com :) select count(1)
FROM emo_mdm_flowwork_pt30m_dist AS mdm_flowwork
WHERE mdm_flowwork.customerId = 343821232 AND
mdm_flowwork.timestampMs >= '2025-09-25 00:00:00' AND
mdm_flowwork.timestampMs < '2025-10-25 00:00:00' AND
mdm_flowwork.platform = 'web' and
mdm_flowwork.flowId IN('f_5333_5842') AND
mdm_flowwork.platform = 'web' and mdm_flowwork.referrer = 'ddd'
SELECT count(1)
FROM emo_mdm_flowwork_pt30m_dist AS mdm_flowwork
WHERE (mdm_flowwork.customerId = 343821232) AND (mdm_flowwork.timestampMs >= '2025-09-25 00:00:00') AND (mdm_flowwork.timestampMs < '2025-10-25 00:00:00') AND (mdm_flowwork.platform = 'web') AND (mdm_flowwork.flowId IN ('f_5333_5842')) AND (mdm_flowwork.platform = 'web') AND (mdm_flowwork.referrer = 'ddd')
Query id: f2db63ff-db3a-48e5-bbca-54f70c0983d1
Elapsed: 0.057 sec.
Received exception from server (version 24.8.4):
Code: 49. DB::Exception: Received from localhost:9000. DB::Exception: Bad cast from type DB::ColumnNothing to DB::ColumnLowCardinality: (while reading from part /nvme6n1/clickhouse/store/95c/95c035af-e614-4fca-9fba-ab871235e324/20250925_0_201_3_2847/ located on disk disk5 of type local): While executing MergeTreeSelect(pool: ReadPool, algorithm: Thread). (LOGICAL_ERROR)为了让Merge成功进行,并且考虑到出问题的Merge都是Vertical Merge,因此,在将这个表的Merge方法设置为Hoizontal Merge以后,我们对这个出问题的partition进行OPTIMIZE操作。我们预计Merge完成以后的Part会为这些新增的5列生成对应的Column。这样,基于OPTIMIZE完成的Parts进行查询,就根本不会走到evaluateMissingDefaults()的code path。
所以,我们对这张表的Partition 20250925进行OPTIMIZE操作(对应的OPTIMIZE SQL这里不展示),然后查询system.merges表查看进度:
sql
rcmp502-2.iad7.prod.corp.com :) SELECT database,
table,
partition,
merge_algorithm,
source_part_names,
result_part_name,
progress,
result_part_path,
FROM system.merges
WHERE partition = '20250925' format vertical
Query id: 11c09536-f4dc-4a7a-844b-f6d15be01c02
Row 1:
──────
database: default
table: emo_mdm_flowwork_pt30m_local
partition: 20250925
merge_algorithm: Horizontal
source_part_names: ['20250925_0_201_3_2847','20250925_202_383_3_2847','20250925_384_542_3_2847','20250925_543_549_1_2847','20250925_550_1767_4_2847','20250925_1768_1986_3_2847','20250925_1987_2194_3_2847','20250925_2195_2442_3_2847','20250925_2443_2588_3_2847','20250925_2589_2846_81_2847']
result_part_name: 20250925_0_2846_82_2847
progress: 0.34351304050416925
result_part_path: /nvme2n1/clickhouse/store/95c/95c035af-e614-4fca-9fba-ab871235e324/20250925_0_2846_82_2847/
1 row in set. Elapsed: 0.001 sec.可以看到,由于我们设置了以下参数导致Merge的确开始走Horizontal Merge而不是Vertical Merge, 当前Merge正在进行:
vertical_merge_algorithm_min_rows_to_activate = 2000000000, vertical_merge_algorithm_min_bytes_to_activate = '536870912000'同时,我们查看Merge对应的Target Part,已经含有了新增的这五列:
root@rcmp502-2:/data/log/clickhouse-server# ls -lh /nvme2n1/clickhouse/store/95c/95c035af-e614-4fca-9fba-ab871235e324/tmp_merge_20250925_0_2846_82_2847|grep refer
-rw-r----- 1 clickhouse clickhouse 0 Oct 21 09:19 referrer.bin
-rw-r----- 1 clickhouse clickhouse 16K Oct 21 10:10 referrer.cmrk2
-rw-r----- 1 clickhouse clickhouse 0 Oct 21 09:19 referrerHost.bin
-rw-r----- 1 clickhouse clickhouse 16K Oct 21 10:10 referrerHost.cmrk2
-rw-r----- 1 clickhouse clickhouse 0 Oct 21 09:19 referrerHost.sparse.idx.bin
-rw-r----- 1 clickhouse clickhouse 60K Oct 21 10:10 referrerHost.sparse.idx.cmrk2
-rw-r----- 1 clickhouse clickhouse 0 Oct 21 09:19 referrer.sparse.idx.bin
-rw-r----- 1 clickhouse clickhouse 60K Oct 21 10:10 referrer.sparse.idx.cmrk2而在出问题的这个source part 20250925_0_201_3_2847上,的确不包含我们新增的这5列,因此,如果读取操作touch到这个source part,并且查询条件包含了我们新增的这5列中的任意一列,就会触发到evaluateMissingColumns的代码:
shell
root@rcmp502-2:/data/log/clickhouse-server# ls -lh /nvme6n1/clickhouse/store/95c/95c035af-e614-4fca-9fba-ab871235e324/20250925_0_201_3_2847/|grep refer
root@rcmp502-2:/data/log/clickhouse-server#我们需要查看这些有问题的Parts是否有一些共同特征。
首先,我们需要知道受到影响的表是哪些,比如,这些表是否的确是我们运行了ALTER TABLE ADD COLUMN的那些表。
shell
root@rcmp501-3:~# zgrep -h "Bad cast from type DB::ColumnNothing to DB::ColumnLowCardinality" /var/log/clickhouse-server/clickhouse-server.log 2>/dev/null | sed -nE 's#^([0-9]{4}\.[0-9]{2}\.[0-9]{2}) ([0-9:.]+).* \{[^:]+::([^}]+)\}.*reading from part .*/([0-9]{8}_[0-9]+_[0-9]+_[0-9]+)/.*#\1 \2 \3 <- \4#p'
2025.09.29 01:08:22.922473 20250925_6_11_1 <- 20250925_6_6_0
2025.09.29 01:08:22.926772 20250925_202_272_6 <- 20250925_202_232_5
2025.09.29 01:08:22.998776 20250924_45_47_1 <- 20250924_45_45_0
2025.09.29 01:08:23.105324 20250925_202_272_6 <- 20250925_202_232_5
2025.09.29 01:08:23.195743 20250924_45_47_1 <- 20250924_45_45_0
2025.09.29 01:08:23.252058 20250919_28_47_2 <- 20250919_28_33_1
2025.09.29 01:08:23.379854 20250925_6_11_1 <- 20250925_6_6_0
.......然后,我们针对这些part,搜索system.parts表,看看他们是否都属于某些或者某一张表:
shell
rcmp504-3.iad7.prod.corp.com :) WITH '
20250904_0_2877_5
20250904_0_801_4
20250905_0_2247_5
...
20250925_811_811_0
20250925_811_819_1
' AS parts_str
SELECT
names.part_name,
ap.source,
ap.database,
ap.`table`,
ap.active,
ap.partition_id,
ap.min_block_number,
ap.max_block_number,
ap.level,
ap.path
FROM
(SELECT arrayJoin(splitByChar('\n', parts_str)) AS part_name) AS names
LEFT JOIN
(
SELECT 'active' AS source, database, `table`, name AS part_name, active, partition_id, min_block_number, max_block_number, level, path
FROM system.parts
UNION ALL
SELECT 'detached' AS source, database, `table`, name AS part_name, 0 AS active, partition_id, min_block_number, max_block_number, level, path
FROM system.detached_parts
) AS ap USING part_name
WHERE names.part_name != ''
ORDER BY names.part_name, ap.source, ap.database, ap.`table`;
......
Query id: 680585fa-32f9-4545-b996-dd83808fa088
┌─part_name────────────┬─source─┬─database─┬─table───────────────────────────┬─active─┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─path───────────────────────────────────────────────────────────────────────────────────────────────────┐
1. │ 20250904_0_2877_5 │ │ │ │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ │
2. │ 20250904_0_801_4 │ active │ default │ emo_mdm_flowwork_pt1m_local │ 1 │ 20250904 │ 0 │ 801 │ 4 │ /nvme7n1/clickhouse/store/03b/03b9bab7-a53b-416d-94a5-02e2a211f5db/20250904_0_801_4/ │
3. │ 20250905_0_2247_5 │ │ │ │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ │
4. │ 20250905_0_829_4 │ active │ default │ emo_mdm_flowwork_pt1m_local │ 1 │ 20250905 │ 0 │ 829 │ 4 │ /nvme2n1/clickhouse/store/03b/03b9bab7-a53b-416d-94a5-02e2a211f5db/20250905_0_829_4/ │
5. │ 20250909_2015_2057_2 │ active │ default │ emo_mdm_flowwork_pt30m_local │ 1 │ 20250909 │ 2015 │ 2057 │ 2 │ /nvme12n1/clickhouse/store/95c/95c035af-e614-4fca-9fba-ab871235e324/20250909_2015_2057_2/ │
6. │ 20250909_2015_2129_3 │ │ │ │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ │
7. │ 20250911_0_2758_5 │ │ │ │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │我们确认,这些出问题的表都发生在以emo_mdm_flowwork*开头的表中,而在25/Sep的时候,我们的确专门针对这几张表做过变更,但是变更很简单,就是加了几个Column而已:
sql
ALTER TABLE {{ DATABASE NAME PLACEHOLDER }}.emo_mdm_flowwork_pt1m_local ON CLUSTER {{ CLUSTER NAME PLACEHOLDER FOR ALL HOSTS }}
ADD COLUMN IF NOT EXISTS `host` String DEFAULT '' CODEC(ZSTD(1)) AFTER connType,
ADD COLUMN IF NOT EXISTS `path` String DEFAULT '' CODEC(ZSTD(1)) AFTER host,
ADD COLUMN IF NOT EXISTS `referrer` String DEFAULT '' CODEC(ZSTD(1)) AFTER path,
ADD COLUMN IF NOT EXISTS `title` String DEFAULT '' CODEC(ZSTD(1)) AFTER referrer,
ADD COLUMN IF NOT EXISTS `referrerHost` String DEFAULT '' CODEC(ZSTD(1)) AFTER title;同时,我们从part的partition信息可以看到,所有出问题的part的partition都是25/Sep和以前,所有在这个日期以后的part都没有发生问题。所以,我们在25/Sep的变更行为影响到了已有的旧part,没有影响后来新ingest的part。
我们的pt1m的表的retention大概是1个星期,这意味着这些出问题的part其实已经快要被drop了。但是我们的pt30m的表的retention是1年左右,离被drop的时间还远。按照我们随后看到的系统恶化的速度,我们不可能不处理这个问题。
从我们添加column的语句可以看到,新添加的这几个column都不是LowCardinality的Column,这些Column都是普通的String类型,都有一个空字符串作为默认值。
既然是这样,说明堆栈中所报的错误的Column并不是我们新添加的这5个Column,但是这不能排除异常发生的原因是我们添加Column的行为所间接导致的。
同时,我们查询system.columns,可以看到表的所有的列。我们可以看到,我们的表的确是有大量的LowCardinality列,有一部分的LowCardinality存在于复杂类型(注意区分复杂类型和嵌套列Nested Column),比如Map(LowCardinality(String), String),我们从堆栈里面看到报错的就是这种复合类型的报错,而不是简单类型的LowCardinality报错。
rcmp504-3.iad7.prod.corp.com :) SELECT
c.name,
c.type AS table_type,
p.type AS part_type,
p.serialization_kind,
p.default_kind
FROM system.columns c
LEFT JOIN system.parts_columns p
ON p.database=c.database AND p.table=c.table AND p.column=c.name
AND p.active AND p.path LIKE '%/20250911_0_863_4/%'
WHERE c.database='default' AND c.table='emo_mdm_flowwork_pt1m_local'
ORDER BY c.name;
SELECT
c.name,
c.type AS table_type,
p.type AS part_type,
p.serialization_kind,
p.default_kind
FROM system.columns AS c
LEFT JOIN system.parts_columns AS p ON (p.database = c.database) AND (p.`table` = c.`table`) AND (p.column = c.name) AND p.active AND (p.path LIKE '%/20250911_0_863_4/%')
WHERE (c.database = 'default') AND (c.`table` = 'emo_mdm_flowwork_pt1m_local')
ORDER BY c.name ASC
Query id: 3701d30c-45d2-435d-8645-a2363e388ec8
┌─name─────────────────────────┬─table_type───────────────────────────┬─part_type────────────────────────────┬─serialization_kind─┬─p.default_kind─┐
1. │ appBuild │ LowCardinality(String) │ LowCardinality(String) │ Default │ │
5. │ asn │ Int32 │ Int32 │ Default │ DEFAULT │
6. │ browserName │ LowCardinality(String) │ LowCardinality(String) │ Default │ DEFAULT │
...
27. │ host │ String │ │ │ │
28. │ inSession │ UInt8 │ UInt8 │ Default │ │
29. │ inUserSession │ UInt8 │ UInt8 │ Default │ │
....
....
77. │ tagGroup11 │ Map(LowCardinality(String), String) │ ....
90. │ timestampMs │ DateTime64(3) │ DateTime64(3) │ Default │ │
....
95. │ watermarkMs │ DateTime64(3) │ DateTime64(3) │ Sparse │ │
└─name─────────────────────────┴─table_type───────────────────────────┴─part_type────────────────────────────┴─serialization_kind─┴─p.default_kind─┘指标分析
我们从25/Sep开始对系统做了以上变更以后,尽管查询和数据插入目前都能正常进行,但是系统的多项指标都显示整个系统处于不健康状态,并且该状态在逐渐恶化,如果不进行处理,系统将有崩溃的风险。
-
CPU使用率和CPU Load逐渐升高
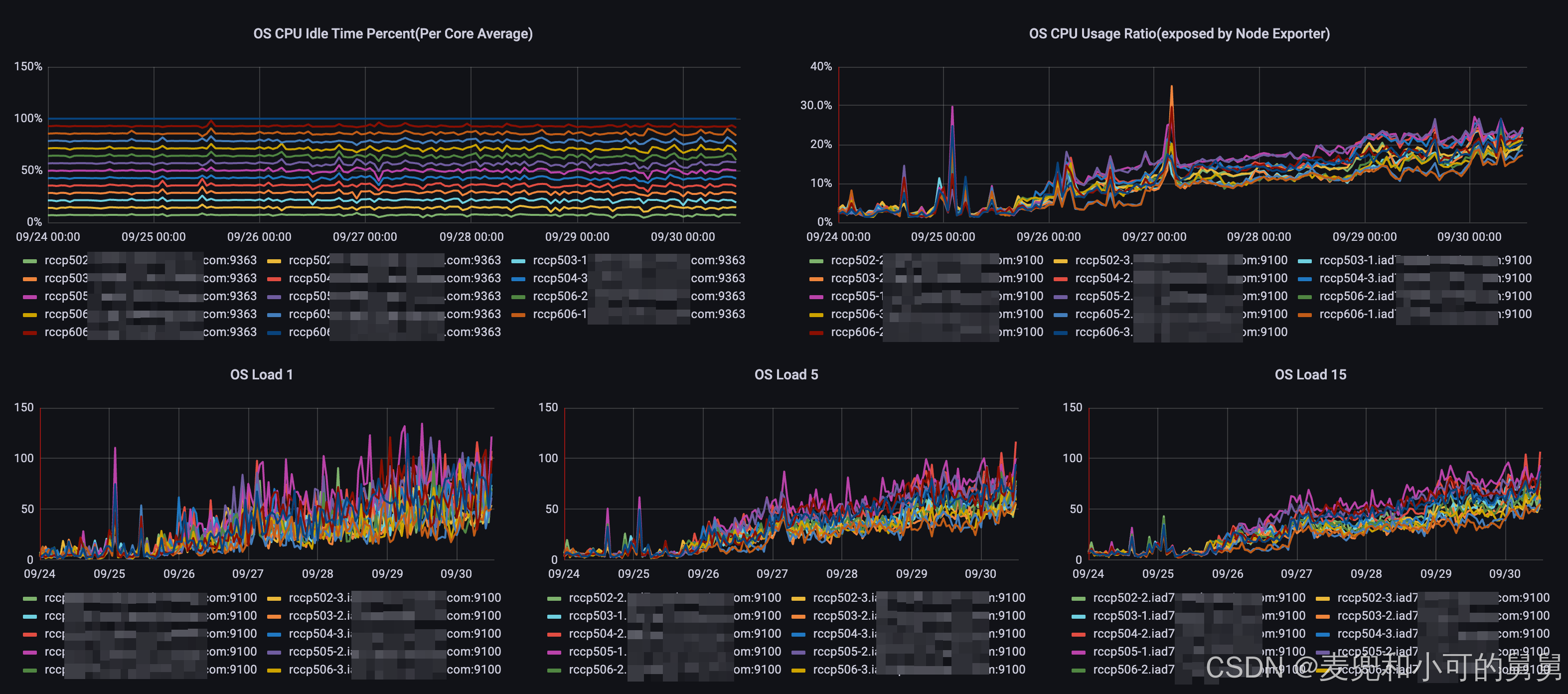
-
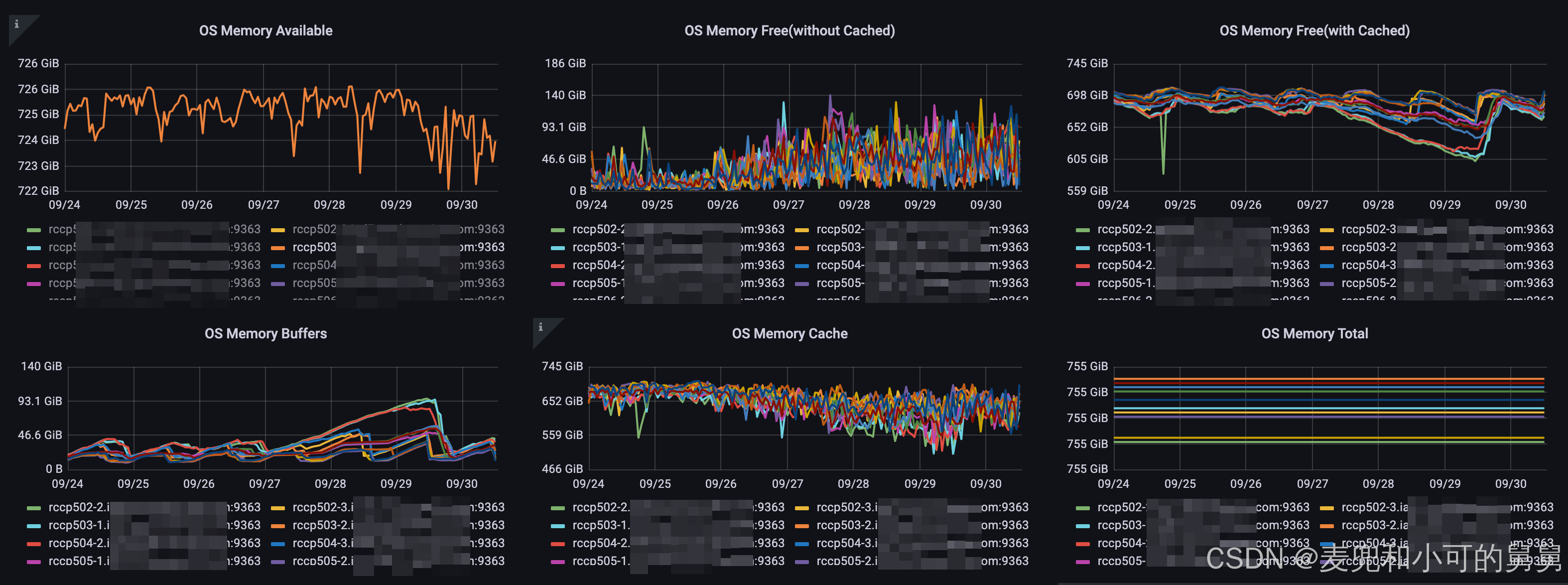
操作系统内存
我们的每台机器是被ClickHouse服务器独占,因此操作系统的内存使用情况就是ClickHouse进程的内存使用情况。可以看到,内存层面没有发生明显变化,整个的Cached Memory在增加,说明系统在发生大量的数据读取操作,但是整个的available memory没有呈现明显变化,说明实际的内存使用(不包含cache)没有明显变化。
-
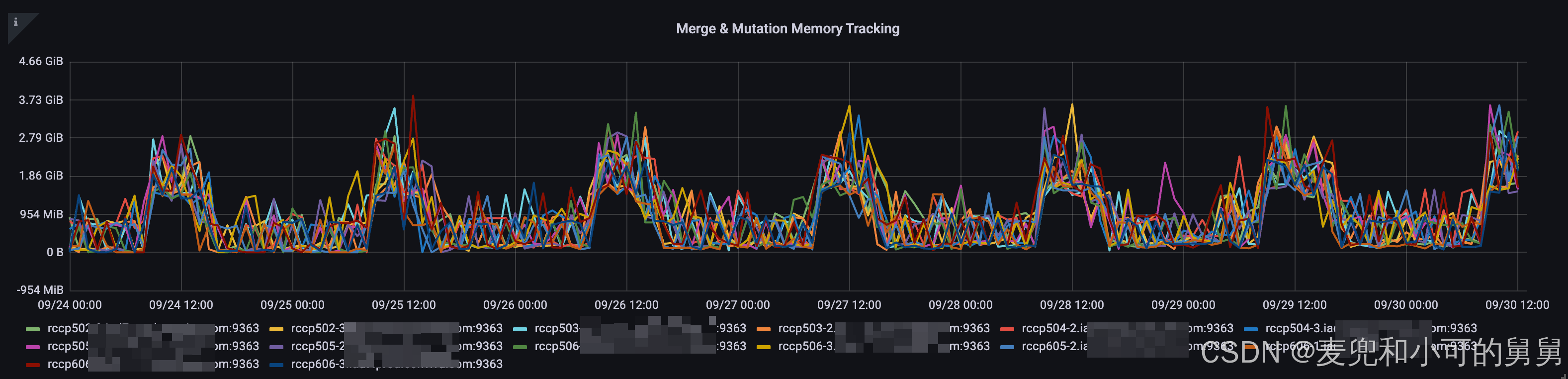
MergeAndMutation Memory Tracking
我们知道,在ClickHouse里面,有一个针对Merge和Mutation总的内存使用量的Metrics信息,因为Merge和Mutation是一起做的,所以并没有对他们分开进行track。
我们可以看到,整个Merge Mutate Memory在每天的一定时段出现高峰,这主要是由于数据输入量的变化导致的,与我们的系统问题无关。但是,我们横向对比每一天的高峰时段可以看到,在25/Sep以后,整个MergeMutate的Memory使用量是稍微高于25/Sep以前的同一时段的MergeMutate的Memory的。但是总的说来,Merge & Mutate Memory的使用量不大,高峰时段也就3GB左右。
-
Merge的输入数据量
我们可以看到,自从25/Sep以后,整个Merge的输入数据量在明显升高,行数和数据大小都随着时间升高在不断上升。
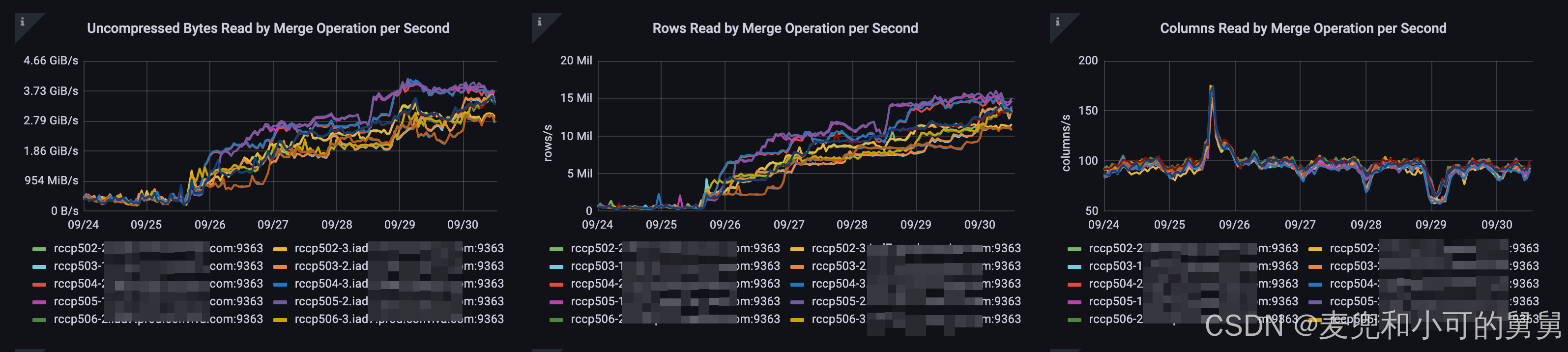 这可能是由于失败的Merge在反复重试导致的。
这可能是由于失败的Merge在反复重试导致的。 -
后台正在运行的Merge Task的数量
我们可以看到,自从25/Sep以后,整个并行运行的Merge Task的数量也在不断升高:
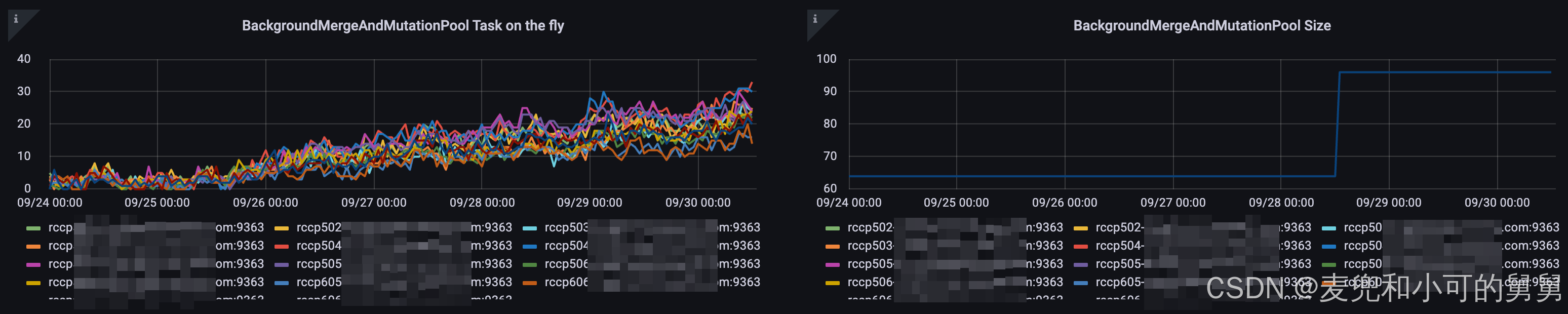 这可能是由于失败的Merge在反复重试导致的。
这可能是由于失败的Merge在反复重试导致的。 -
启动的Merge任务的频率
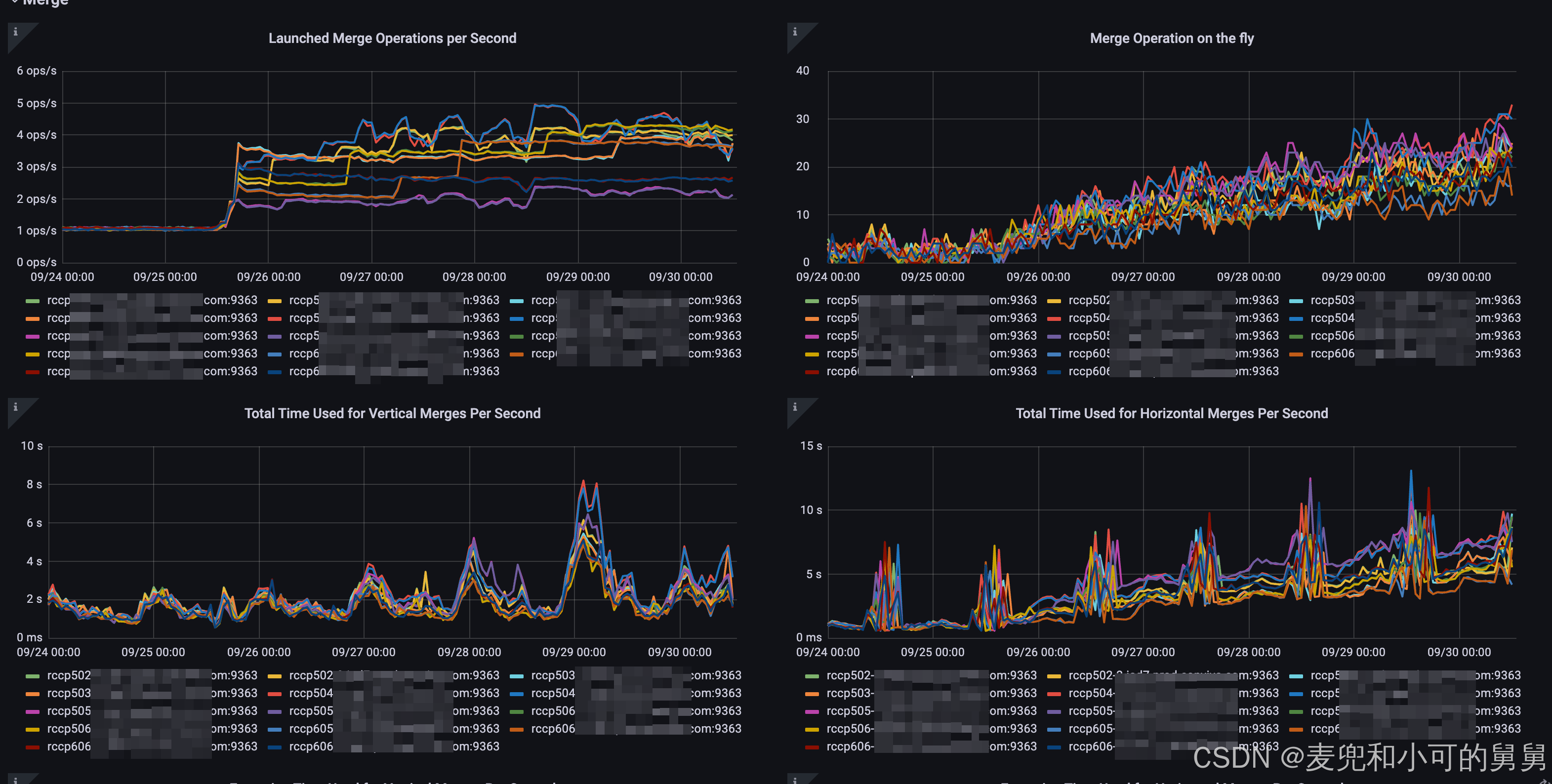 这可能是由于失败的Merge在反复重试导致的。
这可能是由于失败的Merge在反复重试导致的。
诊断过程
由于是ReplicatedMergeTree,因此所有的Merge 任务都会进入到replicaion_queue,因此,我们查询replication_queue,可以看到大量的发生了异常的replication任务。
例如,我们在上面说过,我们可以搜索到带有%Bad cast from type DB%'异常信息的replication任务。
由于我们已经可以从日志中知道具体发生问题的part,因此,我们专门基于这些问题part进行查询,看看基本的查询是否正常(其实已经基本可以预测到查询不会受影响,否则我们早就收到来自上游业务方的报警了):
rcmp504-3.iad7.prod.corp.com :) SELECT *
FROM default.emo_mdm_flowwork_pt1m_local
WHERE _part='20250911_0_863_4'
LIMIT 1;
SELECT *
FROM default.emo_mdm_flowwork_pt1m_local
WHERE _part = '20250911_0_863_4'
LIMIT 1
Query id: eb3141b3-79a0-47bb-865c-09a281da09d0
┌─────────────timestampMs─┬─flowId───┬─────────flowStartTimeMs─┬─customerId─┬─clientId──────────────────────────────┬─more_columns─┐
│ 2025-09-11 05:09:59.999 │ life_min │ 2025-09-11 00:40:25.446 │ 1960181845 │ 1494324132.198588879.1376786135.1431512500 │ ... │
└──────────────────────────┴──────────┴──────────────────────────┴────────────┴──────────────────────────────────────┴──────────────┘读这个 part 的大部分的"普通查询路径"没触发异常,但是上文讲过,假如我们的查询条件中含有我们新增的5列,那么查询会抛出和Merge一模一样的异常。异常只在 Vertical merge/mutate 的写入路径里出现(堆栈在 VerticalMergeStage 和SerializationLowCardinality)
原因分析
有可能报错的就是我添加的5列吗
上文已经说过了: 不可能。我们新增的5列都不是LowCardinality列,也不是复合列,而报错显然跟LowCardinality相关,并且是复合列。
为什么刚好只有我添加5列以前的Partition报错,而添加5列以后的Partition均不报错?
对于这个问题,我们首先想到的最简单的可能性是,有没有可能我们添加这5列以前,表都是进行HorizontalMerge,而在添加了这5列以后,表都是进行Vertical Merge,因此触发了VerticalMerge 的bug呢?
于是,我们看了一下chooseMergeAlgorithm()的选择算法:
cpp
MergeAlgorithm MergeTask::ExecuteAndFinalizeHorizontalPart::chooseMergeAlgorithm() const
{
.....
bool enough_ordinary_cols = global_ctx->gathering_columns.size() >= data_settings->vertical_merge_algorithm_min_columns_to_activate;
bool enough_total_rows = total_rows_count >= data_settings->vertical_merge_algorithm_min_rows_to_activate;
bool enough_total_bytes = total_size_bytes_uncompressed >= data_settings->vertical_merge_algorithm_min_bytes_to_activate;
bool no_parts_overflow = global_ctx->future_part->parts.size() <= RowSourcePart::MAX_PARTS;
auto merge_alg = (is_supported_storage && enough_total_rows && enough_total_bytes && enough_ordinary_cols && no_parts_overflow) ?
MergeAlgorithm::Vertical : MergeAlgorithm::Horizontal;
return merge_alg;
}可以看到,Vertical/Horizontal Merge的决策与数据的行数(vertical_merge_algorithm_min_rows_to_activate)、与数据的大小(vertical_merge_algorithm_min_bytes_to_activate)以及列的数量(vertical_merge_algorithm_min_columns_to_activate)有关:
总之,Horizontal Merge 是默认的"稳妥通用路径",Vertical Merge是在特定情况下为了降低 merge 成本才启用的"优化路径"。
它用一组条件去判断 Vertical 是否"值得且安全":
- merge 的规模足够大(行数大、数据量大),才有可能抵消 Vertical 自身带来的额外流程成本;如果 merge 很小,用 Vertical 反而可能更慢,所以直接用 Horizontal。
- 待处理的普通列足够多(宽表),Vertical 才能通过"先处理少量关键列、再补齐其它列"的方式显著减少无谓的 IO/CPU;列不多时 Vertical 收益不明显。
- 存储实现本身支持 Vertical;不支持就只能走 Horizontal。
- 参与 merge 的 part 数量不能太多,因为 Vertical Merge 需要记录"每行来自哪个 source part"的来源信息,part 太多会超出它能承载/编码的范围,因此必须回退 Horizontal
Vertical Merge:
在一次 merge 里,Merge的输入不是一份数据,而是 多份 source part(比如 part A、part B、part C)按顺序合成一个新 part。
Vertical merge 的过程通常是"两阶段"的:
第一阶段只读/处理"关键列"(主要是排序键相关列),并决定输出新 part 的行顺序以及哪些行会被保留/丢弃(例如在 Collapsing / Replacing 等场景会影响)。
第二阶段需要把其它列(非关键列)也写进新 part。为了做到这一点,它必须知道:新 part 的第 N 行,原本是来自哪一个 source part 的哪一行,这样才能回到对应的 source part 去把那一行的其它列取出来并写入。
所以,对新生成 part 的每一行,Vertial Merge需要记录一个"来源标记",至少包含:
这一行的来源 part 的编号/索引(A/B/C 中的哪一个)
这一行在该 part 内的行位置(或等价的定位信息)
我们添加列的行为根本没有改变数据的行数和数据的大小,因此如果是Horizontal/Vertical Merge导致的,那只有可能跟vertical_merge_algorithm_min_columns_to_activate有关,即,当列的数量增多的时候,ClickHouse的确开始倾向于进行Vertical Merge: 当gathering_columns列的数量增加到超过 vertical_merge_algorithm_min_columns_to_activate的时候,就开始倾向于使用Vertical Merge。
cpp
M(UInt64, vertical_merge_algorithm_min_rows_to_activate, 16 * 8192, "Minimal (approximate) sum of rows in merging parts to activate Vertical merge algorithm.", 0) \
M(UInt64, vertical_merge_algorithm_min_bytes_to_activate, 0, "Minimal (approximate) uncompressed size in bytes in merging parts to activate Vertical merge algorithm.", 0) \
M(UInt64, vertical_merge_algorithm_min_columns_to_activate, 11, "Minimal amount of non-PK columns to activate Vertical merge algorithm.", 0) \可是,我们清楚的看到,即使在添加这一列以前,我们表中的gathering_column的数量也在30+,所以,不可能是由于添加了列导致chooseMergeAlgorithm()的决策结果变化导致的。我们查看监控也可以看到,历史上也都是进行的Vertical Merge。
为什么我添加这5列以前,那些partition都不出错
后面我们会讲解,我们的加列行为导致了加列以前的partition的part中缺失这些列,即这些列在part中存在但是在表中不存在,正是因为在part中这些列不存在,才导injectRequiredColumns()对Map(LowCardinality(String), String)列的添加,进而导致在evaluateMissingColumns()这个堆栈的过程中发生了LowCardinality(String)到String的转换异常。
ClickHouse会对part中不存在但是表中存在的列进行Vertical Merge吗
答案是,会。
我们本身的例子就证明(后面添加日志会证明),问题发生的时候正是因为对host列进行merge的时候发生的,而发生类型转换错误正是因为host在part中不存在。
我们在讲解Merge的时候会专门讲解,ClickHouse在进行Vertical Merge的时候,会对Merging Column(比如,sorting column)进行Horizontal Merge,而对Gather Column(普通的非排序键)进行逐列的vertical merge。所以,回答Vertial Merge是否会对host进行merge,其实就是回答Vertical Merge是否会对那种在表中存在但是在part中不存在的列进行merge?
我们看一下生成Merging Column和生成Gathering Column的方法MergeTask::ExecuteAndFinalizeHorizontalPart::extractMergingAndGatheringColumns()进行分析:
cpp
/// PK columns are sorted and merged, ordinary columns are gathered using info from merge step
void MergeTask::ExecuteAndFinalizeHorizontalPart::extractMergingAndGatheringColumns() const
{
.....
/// TODO: also force "summing" and "aggregating" columns to make Horizontal merge only for such columns
for (const auto & column : global_ctx->storage_columns)
{
// 如果这个列是Sorting Column
if (key_columns.contains(column.name))
{
// 加入到merging_columns中去
global_ctx->merging_columns.emplace_back(column);
/// If column is in horizontal stage we need to calculate its indexes on horizontal stage as well
auto it = global_ctx->skip_indexes_by_column.find(column.name);
// 如果这个column同时也是被某一个二级索引所独立依赖(即这个二级索引独立依赖这个column)
if (it != global_ctx->skip_indexes_by_column.end())
{
// 遍历 独立依赖这个column的所有的 index(即可能我们为这个column创建了多个index,每个index都独立依赖这个column), 把这个index都加入到merging_skip_indexes中,这样,这个index就不会延迟到vertical merge阶段处理了
for (auto & index : it->second) //
global_ctx->merging_skip_indexes.push_back(std::move(index));
// 把这个column从skip_indexes_by_column这个map中删除,这样,所有独立依赖这个column的index都不会被延迟到vertical处理了,因为这个column是一个merging_column,不会被延迟处理
global_ctx->skip_indexes_by_column.erase(it);
}
}
else
{
// gathering_columns,会在vertical merge阶段处理
global_ctx->gathering_columns.emplace_back(column);
}
}
}我们可以清楚的看到,这里的for循环的列来源是global_ctx->storage_columns,熟悉ClickHouse代码的就会明白,在ClickHouse中,Storrage Column指的就是表的Column定义,与Part中的定义无关 。global_ctx->storage_columns 就是表结构里的完整列描述(StorageSnapshot::metadata->getColumns().getAllPhysical())。它反映的是"表里有哪些物理列",跟当前 part 是否实际有这些文件无关,因此列表里当然包含那些"在表里定义、但在某些 part 上缺失"的列。后续 merging_columns/gathering_columns 的划分,是在这个完整列表的基础上按排序键、延迟读取等规则拆分;真正判断某列在 part 上有没有文件,是在 Reader 层通过 hasColumnFiles()、tryGetColumnOrSubcolumn() 等接口去做的。
而Vertical Merge会以协程的方式,反复调用prepareVerticalMergeForAllColumns()方法,不断从gathering_columns中获取列,进行一列一列的merge:
cpp
bool MergeTask::VerticalMergeStage::prepareVerticalMergeForAllColumns() const
{
....
if (ctx->use_prefetch && ctx->it_name_and_type != global_ctx->gathering_columns.end())
ctx->prepared_pipe = createPipeForReadingOneColumn(ctx->it_name_and_type->name);
return false;
}MergeTreeSequentialSource的构造和依赖列的添加
构造的基本过程
在我的关于Merge的文章中讲解过,对于一个VerticalMerge,它其实会对Sorting Key进行Horizontal Merge,即对Sorting Key进行同时读取,而对非Sorting Key(ClickHouse叫做Gathering Columns)进行Vertical Merge,即一列一列进行单独的Merge。
Merge的读取过程是通过MergeTreeSequentialSource类来封装的,即,**一个MergeTreeSequentialSource对象封装了对某一个Part中的一列(比如Gathering Column)或者多列(比如Merging Columns)的读取,而对这个Part中的某一列的真正读取,则是由IMergeTreeReader对象负责的,下文会讲解:
-
如果是进行Horizontal Merge,那么会创建
MergeTreeSequentialSource这个ISource实现,负责读取一个Part中这个Horizontal Merge所负责的所有列。可以看到,这个发生在Merge的三个Stage中的 第一个Stage即ExecuteAndFinalizeHorizontalPart的prepare()中的:cpp// 在 ExecuteAndFinalizeHorizontalPart::prepare()中被调用 void MergeTask::ExecuteAndFinalizeHorizontalPart::createMergedStream() { ...... for (const auto & part : global_ctx->future_part->parts) { Pipe pipe = createMergeTreeSequentialSource( MergeTreeSequentialSourceType::Merge, *global_ctx->data, global_ctx->storage_snapshot, part, global_ctx->merging_columns.getNames(), // 对应的merging_columns,对于Vertical Merge,这个merging column仅仅是索引列,而对于horizontal merge,这个merging_column就是所有的Physical Columns .....); pipes.emplace_back(std::move(pipe)); } -
如果是进行Vertical Merge,那么会创建
MergeTreeSequentialSource这个ISource实现并进一步封装成Pipeline,这个MergeTreeSequentialSource对象就负责读取一个Part中的HorizontalMerge所对应的某一列。可以看到,这里是在 Merge的第二个Stage 即VerticalMergeStage中进行的:cppPipe MergeTask::VerticalMergeStage::createPipeForReadingOneColumn(const String & column_name) const { Pipes pipes; for (size_t part_num = 0; part_num < global_ctx->future_part->parts.size(); ++part_num) { Pipe pipe = createMergeTreeSequentialSource( MergeTreeSequentialSourceType::Merge, *global_ctx->data, global_ctx->storage_snapshot, global_ctx->future_part->parts[part_num], // 需要读取的part Names{column_name}, // 对于Vertical Merge, ....); pipes.emplace_back(std::move(pipe)); } return Pipe::unitePipes(std::move(pipes)); }由于
createPipeForReadingOneColumn()是对gathering column进行vertical merge所触发的。上文我们讲到过,这里的Gathering Column就是非Sorting Key的column,并且,这个Column包含我们新增的那5列,即那种在表中存在但是Part中不存在Column。
下文我们会通过日志证明,在我们的失败场景下,这里传入的Column就是我们通过ALTER TABLE .. ADD COLUMN所添加的host列,由于host列在当前part中不存在,才导致了后续的evaluateMissingDefault()调用链的触发,以及随后的异常的发生。
我们看一下createMergeTreeSequentialSource(...)方法中构造MergeTreeSequentialSource的过程:
```cpp
Pipe createMergeTreeSequentialSource(
MergeTreeSequentialSourceType type,
const MergeTreeData & storage,
const StorageSnapshotPtr & storage_snapshot,
MergeTreeData::DataPartPtr data_part, // 需要读取的part
Names columns_to_read, // 需要读取的列,可以看到,在Vertical Merge中,这个列是merging_columns,而不是gathering_columns
std::optional<MarkRanges> mark_ranges,
std::shared_ptr<std::atomic<size_t>> filtered_rows_count,
bool apply_deleted_mask,
bool read_with_direct_io,
bool prefetch)
{
/// The part might have some rows masked by lightweight deletes
const bool need_to_filter_deleted_rows = apply_deleted_mask && data_part->hasLightweightDelete();
const bool has_filter_column = std::ranges::find(columns_to_read, RowExistsColumn::name) != columns_to_read.end();
if (need_to_filter_deleted_rows && !has_filter_column)
columns_to_read.emplace_back(RowExistsColumn::name);
auto column_part_source = std::make_shared<MergeTreeSequentialSource>(type,
storage, storage_snapshot, data_part, columns_to_read, std::move(mark_ranges),
/*apply_deleted_mask=*/ false, read_with_direct_io, prefetch);
Pipe pipe(std::move(column_part_source));
....
return pipe;
}
```我们可以看到,MergeTreeSequentialSource 是一个ISource的实现(关于ClickHouse的ISource接口的作用,参考我的另外一篇文章),
cpp
/// Lightweight (in terms of logic) stream for reading single part from
/// MergeTree, used for merges and mutations.
///
/// NOTE:
/// It doesn't filter out rows that are deleted with lightweight deletes.
/// Use createMergeTreeSequentialSource filter out those rows.
class MergeTreeSequentialSource : public ISource在Merge/Mutate的时候,会构造对应每一个part的读取流到整个Pipeline中,其中每一个Part的读取被封装成一个ISource的实例MergeTreeSequentialSource。
在构造MergeTreeSequentialSource实例的时候,传入了它所负责读取的source part MergeTreeData::DataPartPtr data_part_:
cpp
MergeTreeSequentialSource::MergeTreeSequentialSource(
MergeTreeSequentialSourceType type,
const MergeTreeData & storage_,
const StorageSnapshotPtr & storage_snapshot_,
MergeTreeData::DataPartPtr data_part_,
Names columns_to_read_, // 在Vertical Merge的场景下,这个columns_to_read_是当前需要进行merge的一个单独列,只有horizontal merge才会是多个列
std::optional<MarkRanges> mark_ranges_,
bool apply_deleted_mask,
bool read_with_direct_io_,
bool prefetch)
: ISource(storage_snapshot_->getSampleBlockForColumns(columns_to_read_))
, storage(storage_)
, storage_snapshot(storage_snapshot_)
, data_part(std::move(data_part_))
, columns_to_read(std::move(columns_to_read_)) // 需要进行处理的列
, read_with_direct_io(read_with_direct_io_)
, mark_ranges(std::move(mark_ranges_))
, mark_cache(storage.getContext()->getMarkCache())
{
auto options = GetColumnsOptions(GetColumnsOptions::AllPhysical) // 只考虑真正定义的列,不考虑alias这种表达式
.withExtendedObjects()
.withVirtuals() // 允许虚拟列,比如_part, _partition_id等
.withSubcolumns(storage.supportsSubcolumns()); // 允许子列,比如允许a.b这类子列名作为合法列来解析
// 设置此次需要请求读取的列,这些列不一定在当前的Part中存在,如果不存在,最后就会导致
// 设置此次需要请求读取的列,这些列不一定在当前的Part中存在,如果不存在,最后就会导致
auto columns_for_reader = storage_snapshot->getColumnsByNames(options, columns_to_read);
....
MergeTreeReaderSettings reader_settings =
{
.read_settings = read_settings,
.save_marks_in_cache = false,
.apply_deleted_mask = apply_deleted_mask,
.can_read_part_without_marks = true,
};
if (!mark_ranges)
mark_ranges.emplace(MarkRanges{MarkRange(0, data_part->getMarksCount())});
// 构造一个IMergeTreeReader对象,用来对特定的一个Part进行读取。
// IMergeTreeReader实现了一部分功能,但是有些功能放在了它的子类MergeTreeReaderWide和MergeTreeReaderCompact中
reader = data_part->getReader(
columns_for_reader, // 需要请求进行读取的列,这些列不一定真的就在part中存在
storage_snapshot,
*mark_ranges,
/*virtual_fields=*/ {},
/*uncompressed_cache=*/ {},
mark_cache.get(),
alter_conversions,
reader_settings,
/*avg_value_size_hints=*/ {},
/*profile_callback=*/ {});
if (prefetch)
reader->prefetchBeginOfRange(Priority{});
}我们从构造方法MergeTreeSequentialSource::MergeTreeSequentialSource()中可以看到
-
一个
MergeTreeSequentialSource对象是针对某一个part的ISource实现类,即针对某一个Part的读取操作; -
columns_to_read是在构造MergeTreeSequentialSource的时候由调用者传入。我们在下文会详细讲到,在VerticalMergeStage(所有Merge的3个Stage中的第二个Stage)中构造MergeTreeSequentialSource的时候,传入的是针对这个Part的Gathering Colum中的某一个Column,columns_to_read此时仅仅是一个Column。我们在讲解Merge的文章中会详细讲解,这是Gathering Columns中的某一个Column! -
根据传入的
columns_to_read,转换成一个NamesAndTypesList columns_for_reader对象,即为当前的Column赋予了对应的类型信息:auto columns_for_reader = storage_snapshot->getColumnsByNames(options, columns_to_read); -
然后,针对这个Part的这个Column,调用了
IMergeTreeDataPart::getReader()方法,该方法返回了用来读取这个Part的IMergeTreeReader,具体的,会根据part是wide还是compact类型,调用IMergeTreeReaderWide::getReader()或者IMergeTreeReaderCompact::getReader()方法:cppusing MergeTreeReaderPtr = std::unique_ptr<IMergeTreeReader>; virtual MergeTreeReaderPtr getReader( const NamesAndTypesList & columns_, // column的list const StorageSnapshotPtr & storage_snapshot, const MarkRanges & mark_ranges, const VirtualFields & virtual_fields, UncompressedCache * uncompressed_cache, MarkCache * mark_cache, const AlterConversionsPtr & alter_conversions, const MergeTreeReaderSettings & reader_settings_, const ValueSizeMap & avg_value_size_hints_, const ReadBufferFromFileBase::ProfileCallback & profile_callback_) const = 0;
所以,问题的关键是从evaluateMissingDefaults()开始的。我们根据堆栈,看一下它的调用者MergeTreeSequentialSource::generate()对DB::IMergeTreeReader::evaluateMissingDefaults()方法的调用逻辑:
cpp
Chunk MergeTreeSequentialSource::generate()
try
{
.....
bool should_evaluate_missing_defaults = false;
reader->fillMissingColumns(columns, should_evaluate_missing_defaults, rows_read);
reader->performRequiredConversions(columns);
if (should_evaluate_missing_defaults)
reader->evaluateMissingDefaults({}, columns);从代码中可以看到:
是否调用 evaluateMissingDefaults() 由 IMergeTreeReader::fillMissingColumns(...) 返回的 should_evaluate_missing_defaults 决定: should_evaluate_missing_defaults在"请求列中有缺失列/子列"时为 true,没有缺失列或者缺失子列的时候为false。
在我们新增 5 个列后,如果在merge的时候发现有缺失列,就会把 should_evaluate_missing_defaults 置为 true,从而进入 evaluateMissingDefaults()。
我们下文以及我们在专门讲解Merge的文章中会讲到,对于一个Vertical Merge ,它在第一个Stage(ExecuteAndFinalizeHorizontalPart)其实是针对所有的Merging Columns的Horizontal Merge,这时候构造的IMergeTreeReader中的columns_就是所有的Merging Columns的集合,而在第二个Merge Stage(VerticalMergeStarge),它会对GatheringColumn一个一个读取,这时候IMergeTreeReader的columns_就是当前正在处理的某一个Gathering Column。
我们看一下IMergeTreeReader::fillMissingColumns()方法的具体实现:
cpp
/// Add columns from ordered_names that are not present in the block.
/// Missing columns are added in the order specified by ordered_names.
/// num_rows is needed in case if all res_columns are nullptr.
void IMergeTreeReader::fillMissingColumns(Columns & res_columns, bool & should_evaluate_missing_defaults, size_t num_rows) const
{
// 将columns_to_read这个列的列表封装成NamesAndTypesList,即 列名+类型的列表
NamesAndTypesList available_columns(columns_to_read.begin(), columns_to_read.end());
// 调用 DB::fillMissingColumns,将列信息写入到res_columns中,缺失的列以nullptr进行占位
DB::fillMissingColumns(
res_columns, num_rows,
Nested::convertToSubcolumns(requested_columns), // 请求的列
Nested::convertToSubcolumns(available_columns), // 当前Part中的列
partially_read_columns, storage_snapshot->metadata);
// 判断 返回的res_columns中是否有缺失列
should_evaluate_missing_defaults = std::any_of(
res_columns.begin(), res_columns.end(), [](const auto & column) { return column == nullptr; });对于该方法,我们可以看到这涉及到了IMergeTreeReader中的两个成员变量:
cpp
/// Actual column names and types of columns in part,
/// which may differ from table metadata.
/// 将传入的original_requested_columns解析为在Part中实际的Column信息,这是因为
/// 传入的Column名字也许和Part中的有所不同,因此这里需要进行转换
NamesAndTypes columns_to_read;
/// Columns that are requested to read.
/// 调用者请求读取的Column
NamesAndTypesList original_requested_columns;
/// The same as above but with converted Arrays to subcolumns of Nested.
/// 调用者请求读取的Column,但是已经将Arrays的展开类型转换成subcolumns,
/// 从而可以时候后面对offsets的共享,并维护了子列和基列之间的关系
NamesAndTypesList requested_columns;即:
requested_columns:Query/Merge需要使用的Column List(按存储层名字,子列已展开)。columns_to_read:从当前 part 实际能读到的列(同样按子列展开)。
所以,IMergeTreeReader::fillMissingColumns()方法的基本逻辑为:
- 调用
DB::fillMissingColumns(...),对已经请求但是在当前part中不存在(即,在requested_columns中存在但是在available_columns中不存在)的列,就在引用res_columns放入"空占位"(这里用 nullptr 表示;下游会把它理解为ColumnNothing) - 设置
should_evaluate_missing_defaults:如果res_columns中存在任何nullptr,即存在缺列,需要后续执行 DEFAULT 表达式补值
既然是因为缺列,那么我们需要知道预期的列是什么和实际的列又是什么。显然,实际的列就是part中实际存在的列。那么,我们来看一下预期的列requested_columns是什么来的。
IMergeTreeReader设置requested_columns的过程是:
-
在
MergeTreeSequentialSource::MergeTreeSequentialSource()构造方法中,会设置需要请求进行读取的列:cppauto options = GetColumnsOptions(GetColumnsOptions::AllPhysical) // 只考虑真正定义的列,不考虑alias这种表达式 .withExtendedObjects() .withVirtuals() // 允许虚拟列,比如_part, _partition_id等 .withSubcolumns(storage.supportsSubcolumns()); // 允许子列,比如允许a.b这类子列名作为合法列来解析 // 设置此次需要请求读取的列,这些列不一定在当前的Part中存在,如果不存在,最后就会导致 auto columns_for_reader = storage_snapshot->getColumnsByNames(options, columns_to_read);columns_for_reader是"本次Merge/Mutate在读取的时候所需要的列名集合",而不一定是这个表的全部列。getColumnsByNames(...)会把这些列名解析成NamesAndTypesList,并按需要展开子列/虚拟列;这段
GetColumnsOptions的作用是:告诉 storage_snapshot->getColumnsByNames(...) 在"按列名取列定义"时,允许把哪些类别的列也一起纳入考虑范围,从而保证 merge/mutation 这种后台读 part 的场景不会因为"列类型特殊"而漏读或拿不到正确的列描述。 -
然后,调用
IMergeTreeDataPart::getReader()来构造对应的IMergeTreeReader对象,具体实现可能是MergeTreeReaderWide或者MergeTreeReaderCompact。我们看一下MergeTreeDataPartWide::getReader()的具体实现:cppIMergeTreeDataPart::MergeTreeReaderPtr MergeTreeDataPartWide::getReader( const NamesAndTypesList & columns_to_read, const StorageSnapshotPtr & storage_snapshot, const MarkRanges & mark_ranges, const VirtualFields & virtual_fields, UncompressedCache * uncompressed_cache, MarkCache * mark_cache, const AlterConversionsPtr & alter_conversions, const MergeTreeReaderSettings & reader_settings, const ValueSizeMap & avg_value_size_hints, const ReadBufferFromFileBase::ProfileCallback & profile_callback) const { auto read_info = std::make_shared<LoadedMergeTreeDataPartInfoForReader>(shared_from_this(), alter_conversions); return std::make_unique<MergeTreeReaderWide>( read_info, columns_to_read, // 请求读取的列 virtual_fields, storage_snapshot, uncompressed_cache, mark_cache, mark_ranges, reader_settings, avg_value_size_hints, profile_callback); }其中,
MergeTreeReaderWide和MergeTreeReaderCompact都是IMergeTreeReader的子类。所以,我们看一下IMergeTreeReader的构造方法:cppIMergeTreeReader::IMergeTreeReader( MergeTreeDataPartInfoForReaderPtr data_part_info_for_read_, const NamesAndTypesList & columns_, // 这次merge需要读取的Column,显然,对于Vertical Merge的VerticalMergeStage阶段,这个columns就是gathering_columns 中的某一个Column const VirtualFields & virtual_fields_, const StorageSnapshotPtr & storage_snapshot_, UncompressedCache * uncompressed_cache_, MarkCache * mark_cache_, const MarkRanges & all_mark_ranges_, const MergeTreeReaderSettings & settings_, const ValueSizeMap & avg_value_size_hints_) : data_part_info_for_read(data_part_info_for_read_) , avg_value_size_hints(avg_value_size_hints_) , uncompressed_cache(uncompressed_cache_) , mark_cache(mark_cache_) , settings(settings_) , storage_snapshot(storage_snapshot_) , all_mark_ranges(all_mark_ranges_) , alter_conversions(data_part_info_for_read->getAlterConversions()) /// For wide parts convert plain arrays of Nested to subcolumns /// to allow to use shared offset column from cache. , original_requested_columns(columns_) // 原始的请求的Column,一个 NamesAndTypesList , requested_columns(data_part_info_for_read->isWidePart() // 如果是Wide Part,那么如果是复合列,还需要对复合列进行拆分,拆分以后放到requested_columns中 ? Nested::convertToSubcolumns(columns_) // 对columns_中的列进行规范化处理,返回 NamesAndTypesList : columns_) , part_columns(data_part_info_for_read->isWidePart() // 设置这个part的column信息,如果是wide part,那么就收集包含Nested Column的 ? data_part_info_for_read->getColumnsDescriptionWithCollectedNested() // 对这个Part中的所有列进行规范化处理,返回ColumnDescription,ColumnDescription其实就是封装了规范化以后的NamesAndTypesList : data_part_info_for_read->getColumnsDescription()) , virtual_fields(virtual_fields_) { columns_to_read.reserve(requested_columns.size()); serializations.reserve(requested_columns.size()); for (const auto & column : requested_columns) { columns_to_read.emplace_back(getColumnInPart(column)); serializations.emplace_back(getSerializationInPart(column)); } }可以看到,
IMergeTreeReader在构造的时候(其实是通过子类MergeTreeReaderWide和MergeTreeReaderCompact的构造函数中进行间接构造的),传入了以下重要参数:-
MergeTreeDataPartInfoForReaderPtr data_part_info_for_read_: 当前正在处理的这个Part的信息cppusing MergeTreeDataPartInfoForReaderPtr = std::shared_ptr<IMergeTreeDataPartInfoForReader>; -
const NamesAndTypesList & columns_: 当前需要读取的part的column。我们已经说过多次,对于Vertical Merge的三个Merge Stage,第一个Stage是Horizontal Merge,这时候的columns_就是这个Stage的所有merging_columns(一般是对应的sorting key),第二个Stage(VerticalMergeStage),由于是对gathering_column进行逐列读取,因此此时这里的columns_就仅仅是当前正在读取的这一列。
在
IMergeTreeReader构造的时候:-
将原始传入进来的
columns_保存在original_requested_columns中,即未做任何转换的列信息cpp/// For wide parts convert plain arrays of Nested to subcolumns /// to allow to use shared offset column from cache. , original_requested_columns(columns_) // 原始的请求的Column,一个 NamesAndTypesList -
既然有original,那么就有转换后的column,这就是转换的动机主要是针对嵌套列(Nested Columns,下文会举例讲解Nested Columns的相关使用方法):
cpprequested_columns(data_part_info_for_read->isWidePart() // 如果是Wide Part,那么如果是复合列,还需要对复合列进行拆分,拆分以后放到requested_columns中 ? Nested::convertToSubcolumns(columns_) // 对columns_中的列进行规范化处理,返回 NamesAndTypesList : columns_)可以看到,对于普通的Wide Part,这里的
requested_columns是通过调用Nested::convertToSubcolumns(columns_)来将原始的columns_处理得到的,这里主要是针对Nested Columns的原始列转换成子列的结构,便于通过子列 获取对应的基列 信息,以及让不同的子列都共享同一份offsets信息:cpp/** * class NamesAndTypesList : public std::list<NameAndTypePair> * 对 Nested 来说,它的子字段是以 Array(T) 形式出现(Nested 物理上拆成多列的 Array),convertToSubcolumns方法 利用这一点把像 "n.a: Array(T)","n.b: Array(T)" * 规范化为"子列表示"(基名 n + 子列 a),以便共享 offsets、精确到子列读取。 * 它不会把任意复合类型"转成 Array";只在检测到 type 是 Array 且名字形如 base.child(Nested 场景)时做规范化。 * @param names_and_types std::list<NameAndTypePair>,这里的列是没有拆解的列,即加入是复合列,那么这里还没有拆解 * @return */ NamesAndTypesList convertToSubcolumns(const NamesAndTypesList & names_and_types) { // using NameToDataType = std::map<String, DataTypePtr>; // 在names_and_types中 收集每个 Nested 基名对应的 Nested 类型,形成一个map,如 n -> DataTypeNested(n). auto nested_types = getSubcolumnsOfNested(names_and_types); auto res = names_and_types; for (auto & name_type : res) // 对于参数中的列(基列,是对Nested已经拆解成多个Array以后的列) { // 若该项类型不是 Array,跳过(Nested 的每个字段物理上是 Array(...))。 if (!isArray(name_type.type)) continue; // 把名字拆成 (基名, 子列名),如 "n.a" -> ("n","a") auto split = splitName(name_type.name); // 已是子列表示(isSubcolumn())或没有子列名(split.second 为空),跳过 if (name_type.isSubcolumn() || split.second.empty()) continue; // 查找基名信息 auto it = nested_types.find(split.first); if (it != nested_types.end()) // 找到了这个基名信息 // 把当前的NameAndTypePair替换成一个新的NameAndTypePair,包含 name_type = NameAndTypePair{split.first, // 基名 split.second, // 子列名 it->second, // 这个基名对应的 DataTypeNested it->second->getSubcolumnType(split.second) // 这个基名对应的子列名的类型 }; } return res; }可以看到,
convertToSubcolumns(...)方法的参数就是传入到IReaderMergeTree中的原始列,我们说过,这里的原始列中对于Nested是平铺的,即n.a: Array(T),n.b: Array(T)分别作为不同的列。convertToSubcolumns()会 :-
通过
getSubcolumnsOfNested(...)对平铺以后的n.a: Array(T),n.b: Array(T)进行信息聚合,返回一个std::map<String, DataTypePtr>,这里的map key就是复合列的基名,value就是对这个基列下面所有的子列的描述信息,包含每一个子列的名字和类型:cppusing NameToDataType = std::map<String, DataTypePtr>; /** * 传入普通的NamesAndTypesList,筛选出对应的Nested列,并以 unordered_map<String, NamesAndTypesList>返回 * @param names_and_types * @return unordered_map<String, NamesAndTypesList>,这个key是对应的Nested的基列的名字,value是多个子列的类型信息 */ NameToDataType getSubcolumnsOfNested(const NamesAndTypesList & names_and_types) { // nested是一个map,map的key是父列的基名,NamesAndTypesList是对应的子列的列表 std::unordered_map<String, NamesAndTypesList> nested; for (const auto & name_type : names_and_types) { const auto * type_arr = typeid_cast<const DataTypeArray *>(name_type.type.get()); /// Ignore true Nested type, but try to unite flatten arrays to Nested type. if (!isNested(name_type.type) && type_arr) { // 对复合子列进行拆分,比如, n.a 拆分成("n", "a"), // 这样,split.first = "n"(基列名称), split.second = "a"(子列名称) auto split = splitName(name_type.name); if (!split.second.empty()) // 如果有子列, 则保存到 unordered_map<String, NamesAndTypesList> nested 中去 nested[split.first].emplace_back(split.second, type_arr->getNestedType()); } } // 构造nested,key是基列的名称,value是createNested(...)的返回值, // 即类似一个DataTypeNestedCustomName的封装,描述了每一个Array列的列名和类型 for (const auto & [name, elems] : nested) nested_types.emplace(name, createNested(elems.getTypes(), elems.getNames())); return nested_types; } -
然后开始遍历参数中传入的所有列,即原始列(前面说过,对于Vertical Merge,这里的列就是
ExecuteAndFinalizeHorizontalPart中的merging_columns,以及VerticalMergeStage中的gathering_columns中的某一列 ),试图将其中的原始的子列n.a: Array(T),n.b: Array(T)进行转换,转换以后,每一个子列的信息都被替换成了更加规范的NameAndTypePair信息:cpp// 把当前的NameAndTypePair替换成一个新的NameAndTypePair,包含了这个子列的等价规范的信息 name_type = NameAndTypePair{split.first, // 基名字符串 n split.second, // 子列名字符串 a it->second, // 这个基列对应的 DataTypeNested,DataTypeNested中是包含了这个基列的所有子列信息的 it->second->getSubcolumnType(split.second) // 这个基名对应的子列名的类型 };
这样,经过
convertToSubcolumns(...)->getSubcolumnsOfNested(...)处理,就将原始的列转换成了更加规范的列信息,主要做的其实是针对Nested Column进行规范化处理,形成了subcolumn的层级结构,以便多个子列识别其Nested 父列,以及共享 offsets 等共享对应的offset信息。 -
-
-
在构造
IMergeTreeReader的时候,还有对part_columns的处理:cpp, part_columns(data_part_info_for_read->isWidePart() // 设置这个part的column信息,如果是wide part,那么就收集包含Nested Column的 ? data_part_info_for_read->getColumnsDescriptionWithCollectedNested() // 对这个Part中的所有列进行规范化处理,返回ColumnDescription,ColumnDescription其实就是封装了规范化以后的NamesAndTypesList : data_part_info_for_read->getColumnsDescription())显然,这里
IMergeTreeReader的part_columns是当前part的所有columns,而不是构造函数传入的参数columns_。columns_表达的是当前正在进行Vertical Merge的Column信息。我们看一下
IMergeTreeDataPart::getColumnsDescriptionWithCollectedNested(...)方法:// 在 IMergeTreeDataPart::setColumns 中设置 const ColumnsDescription & getColumnsDescriptionWithCollectedNested() const { return columns_description_with_collected_nested; }可以看到,
columns_description_with_collected_nested是在IMergeTreeDataPart::setColumns中通过调用Nested::collect(columns)将原始的平铺的column信息转换成subcolumn信息,然后封装成为ColumnsDescription形成的,其基本过程和convertToSubcolumns(...)基本一致:cppvoid IMergeTreeDataPart::setColumns(const NamesAndTypesList & new_columns, const SerializationInfoByName & new_infos, int32_t metadata_version_) { .... columns_description_with_collected_nested = ColumnsDescription(Nested::collect(columns)); }可以看到,这里是调用
Nested::collect(...)来实现对原始的part columns进行转换成subcolumn的结构并设置到columns_description_with_collected_nested中:cppNamesAndTypesList collect(const NamesAndTypesList & names_and_types) { NamesAndTypesList res; // 按基名聚合出每个 Nested 父列的 DataTypeNested(子字段列表) 映射:n -> Nested(a T, b U)。 auto nested_types = getSubcolumnsOfNested(names_and_types); // 对每个 name_type for (const auto & name_type : names_and_types) { auto split = splitName(name_type.name); // 如果不是 Array,或没有子名,或基名不在 nested_types,则保留该列到 res。 // 否则(这是 Nested 的子列,如 n.a Array(T)),跳过,不放进 res。 if (!isArray(name_type.type) || split.second.empty() || !nested_types.contains(split.first)) res.push_back(name_type); // 普通列,直接放到res中 } /** * 把 nested_types 里收集到的每个父列(n, DataTypeNested(...)) 追加进 res * name_type.first: Nested 父列的基名(例如 "n") * name_type.second: 对应的 DataTypeNested 类型(包含该 Nested 的子字段定义,如 a T, b U)。 */ for (const auto & name_type : nested_types) res.emplace_back(name_type.first, name_type.second); /** * 非 Nested 的列保持原样 * 属于 Nested 的子列不再单独出现,转而以一个父列 n: Nested(a T, b U) 出现在列表中。 * 常用于 Wide part 的"逻辑视图"重建(配合 GetColumnsOptions::All),便于识别 Nested 父列、共享 offsets 等。 */ return res; }
嵌套列
Nested 是用来表达"数组的结构体"的语法糖,比如 n Nested(a T1, b T2) 等价于多列 Array(Ti),要求每行里这些数组长度一致。
物理上,ClickHouse会把这个Nested列n拆成多列:n.a Array(T1), n.b Array(T2)(T1, T2是对应的数组的元素类型),由于长度必须相同,因此他们其实共享同一套偏移子流 n.size0(数组边界)。
所以,n.a和n.b 各自有自己的数据子流,但是两列共享n.size0偏移子流,读取任一子列需要偏移信息,同时读多个子列的时候偏移信息可以被复用,即只需要读取一次偏移信息。
Nested 列的典型用法
- 建表
sql
CREATE TABLE t
(
id UInt64,
n Nested(
a Int32,
b String
)
) ENGINE=MergeTree ORDER BY id;- 写入(同一行 n.a 与 n.b 的数组长度必须一致)
sql
INSERT INTO t VALUES (1, [10,20], ['x','y']);- 读取与展开
sql
-- 直接访问子列
SELECT n.a, n.b FROM t;
-- 展开为多行
SELECT id, arrayJoin(n.a) AS a, arrayJoin(n.b) AS b FROM t;- 偏移子列
sql
SELECT n.size0 FROM t; -- 每行数组的累计偏移(内部共享用,一般不直接查)总之:
- Nested = 多个 Array 列 + 共享偏移;每行各数组等长是不变式。
- Reader 会把 Nested 子列规范化,自动处理并复用 n.size0。
- Map/Tuple/LowCardinality 的子流拆解在序列化层;Nested 的"子列规范化"仅用于共享偏移与精细读取。
那么, 在我们的vertical merge发生异常的时候,对应的IMergeTreeReader的requested_column到底是什么呢?
我们知道,vertical merge在VerticalMergeStage(即所有的Merge的三个Stage中的第二个Stage)的merge是一个Column一个Column进行处理的。
我们看一下createMergeTreeSequentialSource()的调用链,从而获知在构造MergeTreeSequentialSource的时候传入的列的信息:
java
(调度/挑任务:把"队列/选择结果"变成 IExecutableTask 并投递到执行器)
SchedulePool (周期性触发)
└─ BackgroundJobsAssignee::threadFunc()
└─ data.scheduleDataProcessingJob(assignee) // data 是具体 Storage 的 MergeTreeData
├─ [非 Replicated 路径] StorageMergeTree::scheduleDataProcessingJob()
│ ├─ selectPartsToMerge()/selectPartsToMutate()
│ └─ assignee.scheduleMergeMutateTask(
│ std::make_shared<MergePlainMergeTreeTask / MutatePlainMergeTreeTask>(...)
│ )
│ └─ Context::getMergeMutateExecutor()->trySchedule(task) // MergeTreeBackgroundExecutor 入队
│
└─ [Replicated 路径] StorageReplicatedMergeTree::scheduleDataProcessingJob()
├─ selected_entry = queue.selectEntryToProcess(...) // 来自 replication queue(system.replication_queue)
└─ 按 entry.type 包装成 IExecutableTask 并投递:
├─ MERGE_PARTS → assignee.scheduleMergeMutateTask(std::make_shared<MergeFromLogEntryTask>(selected_entry,...))
├─ MUTATE_PART → assignee.scheduleMergeMutateTask(std::make_shared<MutateFromLogEntryTask>(selected_entry,...))
└─ (GET_PART/ATTACH_PART 走 fetches executor,这里略)
--------------------------------------------------------------------------------
(执行器背景线程) MergeTreeBackgroundExecutor::routine
└─ task->executeStep() // 虚派发:后台执行器只推进 IExecutableTask,不关心具体是 merge 还是 replicate/mutate
├─ MergePlainMergeTreeTask::executeStep() // 本地执行 OPTIMIZE,或非 Replicated 表的后台 merge
│ └─ merge_task->execute() // MergeTask:一次"合并若干 source parts → 生成一个新 part"的执行体
│ ├─ Stage1 ExecuteAndFinalizeHorizontalPart::createMergedStream()
│ │ └─ createMergeTreeSequentialSource(...) ← 构造点(一):横向阶段为每个源 part 构建顺序读取源(一次读多列)
│ │ └─ MergeTreeSequentialSource::MergeTreeSequentialSource(...)
│ └─ Stage2 VerticalMergeStage // 仅当选择 Vertical merge 时才进入
│ ├─ prepareVerticalMergeForOneColumn() // Vertical 的第一个 subtask:为单列建立读取/处理管道
│ │ └─ createPipeForReadingOneColumn(col)
│ │ └─ createMergeTreeSequentialSource(Names{col}) ← 构造点(二):垂直阶段逐列读取(每次只读一个列)
│ │ └─ MergeTreeSequentialSource::MergeTreeSequentialSource(...)
│ └─ (对 gathering_columns 逐列重复上面构造)
└─ ReplicatedMergeMutateTaskBase::executeStep() // Replicated merges/mutates 的统一基类:队列条目状态机 + 重试/记录异常/收尾
├─ MergeFromLogEntryTask::executeInnerTask() // 子类(1):处理 replication queue 的 MERGE_PARTS 条目
│ └─ merge_task->execute() // 仍然复用同一个 MergeTask → 同上两处构造点(一)/(二)
└─ MutateFromLogEntryTask::executeInnerTask() // 子类(2):处理 replication queue 的 MUTATE_PART 条目
└─ mutate_task->execute() // MutateTask:一次"读取 source part → 应用 mutation → 写临时 part → replace"的执行体
└─ (读取源 part 时同样会调用 createMergeTreeSequentialSource(...))
(区别在于:读出来之后接的是 mutation 的执行管道,而不是 merge 的合并逻辑)上面这张图的含义是:
- 后台 merge/mutate 的执行分成两层:一层"挑选并创建任务",一层"只负责推进任务"。
BackgroundJobsAssignee是上层调度器,它是"挑选并创建任务"这一层的入口。它本身不执行 merge,也不执行 mutation;它周期性地调用storage.scheduleDataProcessingJob(),让具体的 Storage 决定"此刻有没有需要做的后台工作"。如果 Storage 选出了工作,就会在scheduleDataProcessingJob()里创建一个实现了IExecutableTask的任务对象,并通过assignee.scheduleXXXTask(...)把这个任务投递到对应的后台执行器队列里。- 上层调度器/队列逻辑(
BackgroundJobsAssignee)产生一个具体任务对象会根据表的类型(Storage不同,比如StorageReplicatedMergeTree/StorageMergeTree)来产生不同的IMergeTreeTask(例如非 Replicated 的MergePlainMergeTreeTask,或Replicated的MergeFromLogEntryTask/MutateFromLogEntryTask)。
- 上层调度器/队列逻辑(
MergeTreeBackgroundExecutor是任务执行器,它是"只负责推进任务"这一层,它会被后台线程反复调用,调用的时候,他会从内部队列取出一个IExecutableTask,调用task->executeStep()推进任务:executeStep()返回"未完成" → 之后继续推进(下一轮再执行一步);executeStep()返回"已完成" → 任务结束,并触发对应的完成回调/状态更新
其中:- 如果是简单的本地Merge,那么
IExecutableTask的实现类是MergePlainMergeTreeTask,对应executeStep()方法是MergePlainMergeTreeTask::executeStep(), - 如果这个merge是后台线程在
scheduleDataProcessingJob()里从system.replication_queue对应的 ZooKeeper 队列里选出一条待执行任务(selectQueueEntry()),那么IExecutableTask的实现类就是ReplicatedMergeMutateTaskBase,从而调用对应的ReplicatedMergeMutateTaskBase::executeStep()- 对应的
ReplicatedMergeMutateTaskBase::executeStep()内部会调用具体的自己的子类MergeFromLogEntryTask/MutateFromLogEntryTask的executeInnerTask()来执行具体的工作
- 对应的
可以看到,对于Vertical Merge,createMergeTreeSequentialSource()的调用发生在两个地方:
-
在第一个Stage即
ExecuteAndFinalizeHorizontalPart会调用。我们在讲解Merge的文章中介绍过,对于Vertical Merge,第一个Stage其实是针对Merging Columns的Horizontal Merge。创建对应的Stream是通过方法createMergedStream()完成的:cppvoid MergeTask::ExecuteAndFinalizeHorizontalPart::createMergedStream() { /** Read from all parts, merge and write into a new one. * In passing, we calculate expression for sorting. */ Pipes pipes; ..... for (const auto & part : global_ctx->future_part->parts) { Pipe pipe = createMergeTreeSequentialSource( MergeTreeSequentialSourceType::Merge, *global_ctx->data, global_ctx->storage_snapshot, part, global_ctx->merging_columns.getNames(), // 对应的merging_columns,对于Vertical Merge,这个merging column仅仅是索引列,而对于horizontal merge,这个merging_column就是所有的Physical Columns /*mark_ranges=*/ {}, global_ctx->input_rows_filtered, /*apply_deleted_mask=*/ true, ctx->read_with_direct_io, /*prefetch=*/ false); ... pipes.emplace_back(std::move(pipe)); }可以看到,此时
createMergeTreeSequentialSource()方法传入的是merging_columns。我们在讲解Merge的文章中介绍过,对于Vertical Merge,那么merging_columns指的是这张表的Sorting Keys组成的Column,而剩下的Columns就是Gathering Columns -
在第二个Stage即
VerticalMergeStage中会调用。我们在讲解Merge的文章中介绍过,对于Vertical Merge,第二个Stage其实是针对Gathering Columns的逐个Merge。如上所示,这里的调用链条是prepareVerticalMergeForOneColumn(...)->createPipeForReadingOneColumn(col)->createMergeTreeSequentialSource(Names{col}):cpp// 处理当前正在处理的Column Pipe MergeTask::VerticalMergeStage::createPipeForReadingOneColumn(const String & column_name) const { Pipes pipes; for (size_t part_num = 0; part_num < global_ctx->future_part->parts.size(); ++part_num) // 遍历future_part中的所有part,为这些part的当前的Column建立 MergeTreeSequentialSource 对象 { Pipe pipe = createMergeTreeSequentialSource( MergeTreeSequentialSourceType::Merge, *global_ctx->data, global_ctx->storage_snapshot, global_ctx->future_part->parts[part_num], Names{column_name}, // 传入对应的column /*mark_ranges=*/ {}, global_ctx->input_rows_filtered, /*apply_deleted_mask=*/ true, ctx->read_with_direct_io, ctx->use_prefetch); pipes.emplace_back(std::move(pipe)); } return Pipe::unitePipes(std::move(pipes)); }所以,可以看到,
VerticalMergeStage中通过VerticalMergeStage::createPipeForReadingOneColumn()来构造MergeTreeSequentialSource对象的时候,是对某一个单独的part的某一个单独的Column 创建对应的MergeTreeSequentialSource对象,即此时,requested_column是某一个Part的某一个单独的列 ,而不是多个列,即MergeTreeSequentialSource是Per Part Per Column的。由于我们添加的列不是LowCardinality列,但是报错中显示的是LowCardinality转换问题,所以,我们之前的推断是这样的:
- 由于异常堆栈中有默认值推测,而part中缺失的只有可能是我们新增的5列,因此,Merge发生异常的时候,一定有我们新增的列参与进来
- 由于异常信息中有Map(LowCardinality, String)类型,而我们新增的5列都是简单列,因此,Merge发生异常的时候,一定有Map(LowCardinality, String)类型的列参与进来
- 无论是我们新增的5列,还是Map(LowCardinality, String),都不是sorting columns,因此,异常一定发生在第二个Stage即
VerticalMergeStage中
但是,根据我们上文对
VerticalMergeStage的理解,如果是VerticalMerge,那么每一次merge的一定是一个Column,不可能是两个column。所以,代码看到的行为与我们异常日志和堆栈反印出来的信息完全相互矛盾。所以,缺失的这一列不是我们新增的5列中的列,即还有其他的列缺失,缺失的原因可能是:
由于我们从堆栈里已经能确定这次 merge 读取会启用"缺失列用默认值补齐"的路径(should_evaluate_missing_defaults = true),在这个模式下,只要 ClickHouse 判断"某一列在某个 part 上读不到",就会先把它当成缺失处理,后面再用默认值或默认结构把它补出来,保证 merge 能继续往下走。
在 merge 过程中,一个列之所以会被判断为"在这个 part 上缺失",常见原因主要有下面几类:
- 这个 part 生成时本来就没有写这个列(或这个复杂类型的某个分量)。复杂类型在不同 part 里可能只落盘了一部分子数据流,所以某些 part 里确实可能找不到对应的物理文件。在我们的case下,part中的列缺失的确是由于我们新增了5列导致的,因此part中的确不含有这5列。
- 这个列在这个 part 里全是默认值/空值,写入阶段为了节省空间把对应的列文件省略了,磁盘上就表现为"文件为空或大小为 0"(你在
system.parts_columns.column_bytes_on_disk = 0里经常能看到这种情况),LowCardinality、Map 相关列更容易遇到。 - 表做过 ALTER,读取时会按当前表结构去找列;如果这个列名在旧 part 里经过映射/重命名之后对不上当前的物理列文件,就会出现"按名字找不到",于是被当成缺失,靠默认补齐来兼容旧 part。
- 对于 Array/Nested 这类复杂类型,除了主数据文件外,还依赖一些内部配套的结构数据文件(用来描述元素边界等结构信息)。如果这些配套文件在某些 part 里缺失或不可用,读取阶段也会把相关数据视为缺失,然后由默认补齐逻辑生成一份合理的默认结构,使 merge 不至于因为结构数据缺失而中断。
下文中,我们将会详细讲解,为什么Part中缺失了我们新增的5列(预期之内),会导致看起来完全与之无关的DB::ColumnNothing to DB::ColumnLowCardinality的类型转换错误的发生。
因为列缺失因此添加外部列
我们看一下 injectRequiredColumns()方法的具体实现:
cpp
NameSet injectRequiredColumns(
const IMergeTreeDataPartInfoForReader & data_part_info_for_reader,
const StorageSnapshotPtr & storage_snapshot,
bool with_subcolumns,
Names & columns // columns 是上层给出的"本轮需要的列名单",在我的抛出异常的例子中,它是host列
)
{
/**
* 这一行是用 columns 里当前已有的列名初始化集合,所以会把列表里的内容拷贝进去(不是空集)。
* NameSet 构造函数接受两个迭代器,std::begin(columns) 到 std::end(columns) 之间的元素都会被插入,起到"已经被请求的列"基线集合的作用。
*/
NameSet required_columns{std::begin(columns), std::end(columns)};
NameSet injected_columns;
bool have_at_least_one_physical_column = false;
AlterConversionsPtr alter_conversions;
if (!data_part_info_for_reader.isProjectionPart())
alter_conversions = data_part_info_for_reader.getAlterConversions();
auto options = GetColumnsOptions(GetColumnsOptions::AllPhysical)
.withExtendedObjects()
.withVirtuals()
.withSubcolumns(with_subcolumns);
/**
* 逐个把初始需要进行merge的column喂给 injectRequiredColumnsRecursively,在Vertical Merge的场景下,这个column只有tagGroup1.value
*/
for (size_t i = 0; i < columns.size(); ++i)
{
/// We are going to fetch physical columns and system columns first
if (!storage_snapshot->tryGetColumn(options, columns[i]))
throw Exception(ErrorCodes::NO_SUCH_COLUMN_IN_TABLE, "There is no column or subcolumn {} in table", columns[i]);
/**
* 会去 storage_snapshot 查看列定义,再看这个 part 是否包含对应的物理列。
* 如果列存在,则返回true
* 如果列缺失,但在表定义里有 DEFAULT/MATERIALIZED, 那就继续递归它 default 表达式依赖的列,把这些依赖列都塞进 columns,同时记录到 injected_columns。
* 只要在上层的for循环中有一次injectRequiredColumnsRecursively返回true,那么have_at_least_one_physical_column就返回true
*/
have_at_least_one_physical_column |= injectRequiredColumnsRecursively(
columns[i], storage_snapshot, alter_conversions,
data_part_info_for_reader, options, columns, required_columns, injected_columns);
}
/** Add a column of the minimum size.
* Used in case when no column is needed or files are missing, but at least you need to know number of rows.
* Adds to the columns.
*/
if (!have_at_least_one_physical_column)
{
/**
* 虽然当前这个 Merge 阶段并没有直接请求它,但表结构中 host 有 DEFAULT '',而这个 part 上完全没有 host 的物理数据,
* 所以只有靠 "补列" 才能在后面 evaluateMissingDefaults 阶段算出默认值。
* injectRequiredColumns 在扫描列定义时发现 host 符合"缺物理列但有 default"的条件,
* 就把 host 这个名字插入到 columns(以及返回值 injected_columns)里
*/
auto available_columns = storage_snapshot->metadata->getColumns().get(options);
const auto minimum_size_column_name = data_part_info_for_reader.getColumnNameWithMinimumCompressedSize(available_columns);
columns.push_back(minimum_size_column_name); // 添加一列
/// correctly report added column
injected_columns.insert(columns.back()); //把MinimumCompressedSize的column添加到columns中,也添加到injected_columns中
}
return injected_columns; // injected_columns中包含的就是新注入的这一列,而columns也被修改了,新注入的这一列也被添加进来了
}总之, injectRequiredColumns(...) 负责"补全这轮读取所需的列",这就大概解释了为什么Vertical Merge的时候会出现两列。
injectRequiredColumns(...)的参数含义如下所示:
-
data_part_info_for_reader:当前 part 的元信息,能判断某列在这个 part 里是否存在/被重命名等。 -
storage_snapshot:表的列定义快照,可以拿到 DEFAULT/MATERIALIZED 表达式。 -
with_subcolumns:是否允许补进子列。 -
columns:上层传入的"本轮需要处理的列"的列表。我们可以这样解释,VerticalMerge在调用injectRequiredColumns(...)的时候,会传入当前正在处理的列(host),但是经过injectRequiredColumns(...)调用以后,新增了另外的列(tagGroup1.values)。
-
把现有的 columns 复制到
required_columns(避免重复注入),并初始化一个空的数组injected_columns,用来记录新注入的列:cppNameSet required_columns{std::begin(columns), std::end(columns)}; NameSet injected_columns; -
遍历传入所有的columns,对每列调用
injectRequiredColumnsRecursively()。这个递归会检查这个请求列(可能是基列,可能是子列,在我们的case下面,是简单列host)是否存在于 part 中;若存在,则返回true,若缺失,但有DEFAULT/MATERIALIZED表达式,这个表达式有可能依赖其他列,那么就沿着表达式递归往下遍历,把它依赖的列加进columns,并在injected_columns中记录下来。have_at_least_one_physical_column用来判断"最终有没有至少一列真实存在"的标志。cppfor (size_t i = 0; i < columns.size(); ++i) { ...... have_at_least_one_physical_column |= injectRequiredColumnsRecursively( columns[i], storage_snapshot, alter_conversions, data_part_info_for_reader, options, columns, required_columns, injected_columns); }可以看到,只要在遍历的过程中有一列的
injectRequiredColumnsRecursively()返回true,就会导致have_at_least_one_physical_column为true。 -
如果所有列(其实
Vertical Merge只有一列传进来)都不存在于此 part(后面我们会证明,在我们的异常中,是因为Vertical Merge只处理host,而这个 part 没有host),就走 fallback:在表定义里挑"压缩体积最小的物理列"来充数,使读取流程至少能读到一列真实数据。我们后面的日志会证明这个过程:cppif (!have_at_least_one_physical_column) // 如果没有任何一列物理存在 { // 获取表中的所有列, auto available_columns = storage_snapshot->metadata->getColumns().get(options); // 获取size最小的列 const auto minimum_size_column_name = data_part_info_for_reader.getColumnNameWithMinimumCompressedSize(available_columns); columns.push_back(minimum_size_column_name); // 把这一列添加到columns中 injected_columns.insert(columns.back()); }
从上面可以看到,对columns中进行遍历,然后对每一列调用injectRequiredColumnsRecursively()进行递归遍历,最终获得了所依赖的所有列。由于列与列之间的依赖关系是可以递归的,比如,我们要收集列A所依赖的列,依赖关系是A -> B -> C,因此必须递归进行,最终获取到B和C。
injectRequiredColumnsRecursively(...) 的目标是,对于"缺失但又必须可用"的列,递归地把它们的物理依赖列加入读取列表,从而确保 IMergeTreeReader在执行默认值/物化表达式时,手头有足够的数据。它还会检查 part 是否真的拥有某个列,从而避免读不到任何实际数据。
怎么理解"缺失但是又必须可用"? 我们举一个简单例子:
sql
CREATE TABLE demo_deps
(
ts DateTime,
x Int32,
y Int32 DEFAULT x + 1
) ENGINE = MergeTree
ORDER BY ts;可以看到,列y有default值,并且,default值是一个表达式,并且,表达式依赖其他列,所以:
- 当写入数据时,如果没有显式提供
y,ClickHouse 会在写入阶段计算x + 1,把结果直接存进 part 的y数据文件里。也就是说每个 data part 上都持有y的实际数值。 - 查询或后续 merge/mutation 时,
y不需要再次按表达式求值,只需像普通列一样读取它的值; - 但是,如果某个旧的 part 在
y列建立前就存在(比如,列y是我们后续添加进去的),那么那类 part 上y物理数据就是缺失的,这时候如果VerticalMerge 开始对这一个y进行merge的时候,得依靠方法injectRequiredColumns()配合 DEFAULT 表达式去补值,因此就需要把依赖的x也注入进来。
所以,我们看一下方法injectRequiredColumnsRecursively()的具体实现:
cpp
/// Columns absent in part may depend on other absent columns so we are
/// searching all required physical columns recursively. Return true if found at
/// least one existing (physical) column in part.
bool injectRequiredColumnsRecursively(
const String & column_name, // 当前的Merge所请求的某一列
const StorageSnapshotPtr & storage_snapshot, // 表结构快照,用来查询列定义及 DEFAULT/MATERIALIZED 表达式
const AlterConversionsPtr & alter_conversions,
const IMergeTreeDataPartInfoForReader & data_part_info_for_reader, // 当前读取的 part 信息(含 getColumns(),判定这个 part 是否有某列或某子列)。
const GetColumnsOptions & options, // 指定查列时要包含物理列/虚拟列/子列等。
Names & columns, // 本轮merge/select所请求的列集合
NameSet & required_columns,
NameSet & injected_columns // 在上层循环调用的时候,不断将需要注入的列存进来
)
{
/// This is needed to prevent stack overflow in case of cyclic defaults or
/// huge AST which for some reason was not validated on parsing/interpreter
/// stages.
checkStackSize();
// 传入的column_name的NameAndTypePair,可能是父列,可能是子列
auto column_in_storage = storage_snapshot->tryGetColumn(options, column_name);
if (column_in_storage) // 这个column在表定义中存在
{
// 获取这一列在表中的名字(存储名),一定是基列名
auto column_name_in_part = column_in_storage->getNameInStorage();
if (alter_conversions && alter_conversions->isColumnRenamed(column_name_in_part)) // 如果这个column曾经被rename过,那么就要使用在part中的名字(part中的名字在alter的时候没有被修改)
column_name_in_part = alter_conversions->getColumnOldName(column_name_in_part);
// 获取这个基列column(如果这个column之前被renmame过,那么这个column_in_part就是rename以前在part中的名字)在part中的NameAndValuePair
auto column_in_part = data_part_info_for_reader.getColumns().tryGetByName(column_name_in_part);
if (column_in_part // 如果这个column在part中存在 , 并且
&& (!column_in_storage->isSubcolumn() // 请求的column不是子列,或者虽然是子列,但是在part中的这个列的确有这个子列的信息
|| column_in_part->type->tryGetSubcolumnType(column_in_storage->getSubcolumnName())))
{
/// 如果required_columns中没有这个请求的column_name,就加进来
if (!required_columns.contains(column_name))
{
columns.emplace_back(column_name);
required_columns.emplace(column_name);
injected_columns.emplace(column_name); // 只把required_columns中不存在的列添加到injected_columns中
}
return true; // 这列在表中和part中都存在,返回true,即使它还有默认值表达式,也不需要再递归评估默认值了
}
}
//如果这个column在表中不存在,或者在表中存在,但是在part中不存在,那么就需要进行默认值和默认值表达式的推断
/// Column doesn't have default value and don't exist in part
/// don't need to add to required set.
const auto column_default = storage_snapshot->metadata->getColumns().getDefault(column_name);
if (!column_default) // 列本身不在part中,并且没有默认表达式,那么就返回false,代表没有任何一个存在的physical column
return false;
// 这个column在表中或者part中不存在,并且有默认值表达式,那么就需要递归解析依赖列(如果仅仅是默认值,就不存在依赖列)
/// collect identifiers required for evaluation
IdentifierNameSet identifiers;
// 收集默认值表达式中的Identifier
column_default->expression->collectIdentifierNames(identifiers);
bool result = false;
// 对于默认值表达式中的identifier
for (const auto & identifier : identifiers)
result |= injectRequiredColumnsRecursively(
identifier, storage_snapshot, alter_conversions, data_part_info_for_reader,
options, columns, required_columns, injected_columns);
return result; // 只要有一个是true,就返回true。当所有都是false的时候返回false
}
}方法
- 递归入口:
column_name是当前需要递归检查的列(来自 columns)。 storage_snapshot用来拿到该列在表中的定义;alter_conversions用来应对重命名,当发生过重命名,那么part中的列名和表中的列名不一致,这时候需要进行转换injected_columns递归遍历过程中的全局变量,收集需要注入进来的列。很显然,需要注入进来的列,都是在part中的确存在的列,我们从injectRequiredColumnsRecursively()的实现也可以看到。
在了解该递归方法的具体细节以前,我们先需要理解该方法所完成的功能,以及返回值含义。
-
在功能上,该方法会对输入列的默认值表达式进行遍历,以**(递归)收集该列所依赖的全部列**,即计算该默认值所需要的全部列。当然,该列的默认值也许不是一个表达式,而是一个不依赖任何其他列的常量,或者,该列根本就没有默认值,这时候,就没有其他依赖列被添加进来。
-
该方法的返回值是一个布尔值,如果该列或者该列的默认值表达式所依赖(直接或者间接)依赖的任何一列在part中存在,那么就返回true,否则(没有任何一列存在),就返回false。
-
这个返回值的作用是,ClickHouse在本轮读取的时候,需要至少知道行的数量,因此,它不允许本轮读取居然读不到任何一个列,否则就无法得知至少行号信息;
-
即使当前列不存在(比如,我们新添加的
host列),那么,如果它有默认值表达式并且默认值表达式依赖其他列,那么正好就收集到它依赖的列,这样,既可以计算这一列的值,同时又能知道行数。 -
可是,如果当前列不存在,并且也没有默认值,或者尽管有默认值但是是常量而依赖其他列的表达式 (这就是我们遇到的case,当前正在进行VerticalMerge的列
host在part中不存在,虽然它有默认值表达式'',但是这个表达式不依赖其他列),因此本轮读取似乎不需要其它列了,那怎么知道行数呢?只好随机选择其他一列了:cppif (!have_at_least_one_physical_column) { /** * 虽然当前这个 Merge 阶段并没有直接请求它,但表结构中 host 有 DEFAULT '',而这个 part 上完全没有 host 的物理数据, * 所以只有靠 "补列" 才能在后面 evaluateMissingDefaults 阶段算出默认值。 * injectRequiredColumns 在扫描列定义时发现 host 符合"缺物理列但有 default"的条件, * 就把 host 这个名字插入到 columns(以及返回值 injected_columns)里 */ auto available_columns = storage_snapshot->metadata->getColumns().get(options); const auto minimum_size_column_name = data_part_info_for_reader.getColumnNameWithMinimumCompressedSize(available_columns); columns.push_back(minimum_size_column_name); /// correctly report added column injected_columns.insert(columns.back()); //把MinimumCompressedSize的column添加到columns中,也添加到injected_columns中 }
所以,
injectRequiredColumnsRecursively()的功能细节为: -
-
如果 part 中确实有这列(或子列),就把它加进 columns(避免重复)并返回 true,表示至少找到了一列物理可读的数据
cppauto column_in_storage = storage_snapshot->tryGetColumn(options, column_name); if (column_in_storage) { // getNameInStorage()返回的一定是基列名(如果是复合列的话) auto column_name_in_part = column_in_storage->getNameInStorage(); if (alter_conversions && alter_conversions->isColumnRenamed(column_name_in_part)) column_name_in_part = alter_conversions->getColumnOldName(column_name_in_part); // 返回对应基列的column的NameAndTypePair auto column_in_part = data_part_info_for_reader.getColumns().tryGetByName(column_name_in_part); if (column_in_part // 如果这个column在part中存在 并且 (column不是subcolumn) && (!column_in_storage->isSubcolumn() // 如果这个列是一个子列,比如带点号请求 tagGroup1.values || column_in_part->type->tryGetSubcolumnType(column_in_storage->getSubcolumnName()))) // part中的这一列包含这个子列的信息 { /// ensure each column is added only once if (!required_columns.contains(column_name)) { columns.emplace_back(column_name); required_columns.emplace(column_name); injected_columns.emplace(column_name); } return true; // 这列在表中和part中都存在,返回true,即使它还有默认值表达式,也不需要再递归评估默认值了 } }这里的含义是,如果当前列(注意,该方法是递归方法,所以当前列不一定是
injectRequiredColumns()调用的时候的列,而可能是依赖链条中的某一列)已经在part中存在,那么就不需要再关心它的默认值表达式了,也不需要读取默认值表达式中涉及到的列了,因为根本不需要,默认值是在列不存在的时候起作用的。所以,这一列会被放到injected_columns中。所以,可以看到,在递归方法运行过程中,injected_columns中一定是在依赖链中并且一定在part中存在的列,因为如果这一列不存在,收集上来也无法读取,因此不必要注入进来。注意,如果
column_in_storage是一个子列比如tagGroup1.values,getNameInStorage()返回的是对应的基列名,不是子列名:cppString NameAndTypePair::getNameInStorage() const { if (!subcolumn_delimiter_position) return name; return name.substr(0, *subcolumn_delimiter_position); // 以子列的点号为分割点进行了分割 } -
如果这个column在part中不存在,并且这一列没有default值,那么直接返回false,代表我们没有为当前列找到任何(包含当前列)有依赖关系的列 ,这时候,上层的调用者
injectRequiredColumns()就会尝试自行选择其它与当前列无关的列,至少保证这次读取能至少读到一列存在的列:cppconst auto column_default = storage_snapshot->metadata->getColumns().getDefault(column_name); if (!column_default) return false; -
如果这个column在part中不存在,但是它有默认值,那么就开始递归收集其默认值表达式依赖的列:
cppIdentifierNameSet identifiers; column_default->expression->collectIdentifierNames(identifiers); bool result = false; for (const auto & identifier : identifiers) result |= injectRequiredColumnsRecursively( identifier, storage_snapshot, alter_conversions, data_part_info_for_reader, options, columns, required_columns, injected_columns); return result; }这里result的含义是,当前column的所有identifier(可以理解为依赖的子列)是否至少有一个identifier在part中是存在的。
这里可以看到,只要当前列的默认值表达式的identifier中至少有一个identifier存在,那么result就是true。但是,我们必须看到,这里的for循环没有break逻辑,这意味着,即使发现了一个idenfier返回true,也还是继续遍历完所有的identifier,以便收集到所有的默认值表达式的依赖到injected_columns。
针对以上方法,我们列举了几种不同的默认值场景,来理解这个方法的功能和返回值:
-
当前列已经在part中存在,那么,就不需要关心它的默认值了(默认值是用来在列不存在的时候推测它的值)
对应表结构:
CREATE TABLE t_exist ( ts DateTime, x Int32, y Int 32 ) ENGINE = MergeTree ORDER BY ts;场景:请求读取列
[y],part 中也有y文件。injectRequiredColumnsRecursively()会直接返回 true,表示这一列y完全可读,不需要关心它的默认值和默认值表达式。 -
列缺失且 DEFAULT 依赖其他列,但依赖的列存在
表结构:
CREATE TABLE t_dep ( ts DateTime, x Int32, k Int32, y Int32 DEFAULT x + k + 1 ) ENGINE = MergeTree ORDER BY ts;场景:某个老 part 没有
y,只请求[y]。递归发现y缺失,解析 DEFAULT 得到y需要依赖x和k,并且x和k在 part 中存在,于是把x和k注入读取列表,凭借x+k+1补出y -
列缺失、默认值表达式依赖的列也缺失
表结构同上,但 part 太老,既没有 y 也没有
x和k。请求[y]时,递归链上所有列都返回 false,最终injectRequiredColumns()触发 fallback:cppconst auto fallback = data_part_info_for_reader.getColumnNameWithMinimumCompressedSize(...);例如挑到 ts 作为"最小列"去读,以便仍能驱动读流程。
-
列缺失但 DEFAULT 是常量
表结构:
CREATE TABLE t_const ( ts DateTime, host String DEFAULT '' ) ENGINE = MergeTree ORDER BY ts;场景:某个 part 没有 host,你请求
[host]。递归检查 host,发现没有依赖,只能返回 false。最终也走 fallback,注入压缩体积最小的列(可能是其他列,比如 url),来保证有至少一列实际读取,随后再用默认值 '' 补齐 host。--- 这正是我当前遇到的情况:fallback 挑中了
tagGroup1.values,用于让读取工作能继续。
为什么需要补充一列外部列tagGroup1.value?
当这个 part 中 host(或其它真实请求列)完全不存在时,Reader 仍然需要至少读一根物理列来确定行数、驱动后续的缺列填补流程;否则 fillMissingColumns() & evaluateMissingDefaults() 根本没法知道"应该补多少行"。injectRequiredColumns() 就是在这种场景下,从表结构里挑一根"肯定存在的"列(你体现在日志里的是 tagGroup1.values)临时代替,被称作 fallback。它不改变上层真正需要的列,但确保本轮有实际数据读入、能把行数和 offsets 带出来,后面才好给 host 这类缺列补默认值。
我们在下文中讲解IMergeTreeReader::fillMissingColumns()的时候会看到,当 host 这样的目标列在某个 part 里完全不存在时,如果 Reader 连一列真实数据都不读,下游就拿不到关键的"行数"和 Nested/Map 所需的 offsets 信息,fillMissingColumns() & evaluateMissingDefaults() 也就无法知道"要补多少行""数组长度是什么"
换句话说,补充 tagGroup1.values 的目的不是为了返回它本身,而是为了保证这一轮读取至少有一根真实的物理列提供"行数 + offsets + 数据驱动"。只有这样,fillMissingColumns() 才能利用 rows_read 创建相同行数的默认列,evaluateMissingDefaults() 才能在 Block 中插入默认值或执行 DEFAULT 表达式。缺少这个外部列,整个补列/默认值链条都无从运转。
我们下文在讲解 evaluateMissingDefaults() 的时候,我们会看到,在构造用来评估默认值的dag的时候,会用读到的tagGroup1.values的行数来设置整个Block additional_columns的行数的,随后,把host和tagGroup1这两列插入到Block中来,那么host和tagGroup1的行数就是tagGroup1.values的行数。
IMergeTreeReader的构造和子流的添加
什么是子流
一个表中的一个如下类型如下的Column,在对应的Part的存储文件如下所示:
shell
`tagGroup15` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
可以看到,其实一个Map(LowCardinality(String), String)在物理存储层面包含了4个子流,这4个子流包括:
M.size0: Array 的 offsets 子流,从上面的截图我们看到,对应的文件是tagGroup9.size0.bin和tagGroup9.size0.cmrk2两个文件。其中,我们在下文讲SerializationArray.enumerateStreams()的时候会讲到,这里的0代表的是这个索引对应的数组的维度,如果有二维三维,那么会有size1,size2等等M.key: LowCardinality 的索引(行级 codes)子流,tagGroup9%2Ekeys.bin和tagGroup9%2Ekeys.cmrk2两个文件;M.key.dict: LowCardinality 的字典 keys 子流(底层为 String),对应的文件是tagGroup9%2Ekeys.dict.bin和tagGroup9%2Ekeys.dict.cmrk2两个文件;M.value: value 的数据子流(String),对应的文件是tagGroup9%2Evalues.bin和tagGroup9%2Evalues.cmrk2两个文件
所以,可以看到,我们讲的逻辑上的Stream,每一个Stream都包含了两个文件,.bin的数据文件和.cmrk2的标记文件,.bin文件中存放了这个Stream具体的数据,而.cmrk2存放了.bin文件的具体索引方式。
对于LowCardinality,即低基数据类型,需要两个Stream来表达:
-
字典子流,因为对于低基数类型的Count(Distinct *)很少,因此可以用一些很简单的短数字聊存储数据,而不用把这些数据直接存储,这时候,就需要字典来翻译从code 到 数据的解释过程;
-
代码子流,即不直接存放数据本身,而是存放数据的对应代码;
-
所以,读取一个LowCardinality的过程,是先读代码子流
c.bin(需要通过c.cmrk2来读取c.bin) 得到每行的数据(以代码code的形式),再用 code 去c.dict.bin(也需要依赖c.dict.cmrk2来辅助读取c.dict.bin) 获取到code所对应的实际值。textLowCardinality(T) 的落盘结构(以列 c: LowCardinality(String) 为例) ┌───────────────────────────────────────────────┐ │ 列 c (LC(String)) │ └───────────────────────────────────────────────┘ │ │ │ │ 索引/代码子流 (.bin/.mrk2) 字典子流 (.dict.bin/.dict.mrk2) │ │ ▼ ▼ c.bin c.mrk2 c.dict.bin c.dict.mrk2 [row→code] ["US","CN","DE", ...] 0 0 1 2 1 ... ^ ^ ^ │ │ │ │ │ │ │ │ └─┴─┴─┴─┴───→ 通过 code 映射到字典位置(key_id),在转换成实际的低基数的字符串值
压缩和解压:
- ClickHouse中数据压缩的基本单位是Block,一个.bin文件就是由多个Block从内存中进行追加写入形成的。
- 写入Block的时候,Block Header中含有对应的压缩算法、compressed_size、decompressed_size、checksum 等信息。
- 所以,理论上,一个bin文件中的Block完全可能是由不同的压缩算法进行压缩的
在 MergeTree 里,数据按列存储,每列的数据在磁盘上被切分成一系列连续的 granule,即granule 是按行分组的"读取最小单位",即,即使我只需要读一行数据,也需要读取整个granule。
在mark文件中,一个mark行对应一个数据行太浪费,因此,一个mark行往往对应多行数据(比如对应64行数据), 这64行数据就是一个granule,因此,granule是数据读写的最小单位。
相比之下,一个Block则是压缩和解压的最小单位,一个Block中往往含有多个granule,比如,一个Block是8096行数据,因此含有8192/64=128个granule。
由于Block存放在磁盘上是以压缩格式存放,而在内存中肯定是解压的,因此为了准确定位一个granule,知道两个信息即可:这个granule所在的Block在.bin文件中的偏移(compressed_offset,用来精确地定位这个Block并把Block解压到内存)以及这个granule在它所属的Block中的偏移(decompressed_offset,精确地从内存中的Block中读取出这个granule)。
compressed_offset(压缩偏移): 该子流对应的.bin文件中,目标granule所在的"压缩块(Block)"的文件字节偏移(从.bin开头算起的绝对偏移)。读取时据此fseek到块头,整块读取并解压。- 所以,这里必须理解,这里的offset一定指的是block的起始位置的偏移量
- 既然
compressed_offset指的是granule所在Block的起始位置在.bin中的偏移,那么很显然,一个Block中的多个granule的compressed_offset相同(但是decompressed_offset不同)
decompressed_offset(解压内偏移): 把上述压缩块解压到内存后,granule在这块"解压后的字节缓冲"(decompressed block)里,距离缓冲起点起始字节的偏移量(字节数,块内相对偏移,用来在Block内部定位当前的granule)。读取时先丢弃该偏移,再从该位置开始按行解码。
所以,.bin和.mrk2文件的示意图如下所示:
text
某一个 substream 的文件对(.bin + .mrk2)
.bin:存的是一串 compressed block(每个 block 解压后是一段连续原始字节)
┌───────────────────────────────────────────────────────────────────────┐
│ compressed block #0 │ compressed block #1 │ compressed block #2 │ ... │
└───────────────────────────────────────────────────────────────────────┘
↑ ↑
│ └─ 某个 granule 的起点落在这个 compressed block 里
└─ 某个 granule 的起点落在这个 compressed block 里
.mrk2:每个 granule 一条 mark(每条 = {compressed_offset, decompressed_offset})
┌──────────────────────────────────────────────────────────────────────────────┐
│ mark[0]: {compressed_offset, decompressed_offset} // granule #0 的起点 │
│ mark[1]: {compressed_offset, decompressed_offset} // granule #1 的起点 │
│ mark[2]: {compressed_offset, decompressed_offset} // granule #2 的起点 │
│ ... │
└──────────────────────────────────────────────────────────────────────────────┘
两个 offset 的含义:
- compressed_offset:
指向 .bin 文件里某个 compressed block 的起始位置(从 .bin 开头算起的字节偏移)。
读取时先 seek 到这个位置,把整个 compressed block 读出来再 decompress。
- decompressed_offset:
把上述 compressed block decompress 到内存后,在"解压后的字节缓冲"里,
granule 的起点距离缓冲起点的字节偏移(block 内相对偏移)。
读取时先跳过这段字节,从该位置开始做 deserialize(解码/反序列化)。
读取第 [L .. R) 个 granule 的最简流程:
1) 读 .mrk2 的 mark[L] → 得到 (compressed_offset, decompressed_offset)
2) 打开 .bin:seek 到 compressed_offset,读取对应 compressed block,decompress
3) 在解压缓冲里跳过 decompressed_offset,然后按类型的 deserializer 按行 deserialize;
通常读满这个 granule 的行数(常见约为 index_granularity 行),不够再读下一个 mark所以,一个最简单的读取过程是:
- 从
mrk(2)文件中读取当前granule对应的compressed_offset和decompressed_offset; - 基于压缩块文件(
.bin)和目标的压缩偏移量(compressed_offset),seek到对应位置,读取整个对应的block数据; - 将对应的Block数据解压到内存;
- 在内存中,根据提供的
granule的解压后偏移量(decompressed_offset),跳过这个block中的不关心的位置,直接到达目标granule,然后对这个granule进行解码。需要区别这里的解码和解压:- 解压只是把一个压缩块还原成原始字节;
- 解码是用该列的数据类型**(反)序列化器**把这些字节按行解析成内存里的列对象。不同数据类型的反序列化器deserializer是不同的(但是压缩的时候是没有区别的,压缩算法看到的仅仅是二进制)
SerializationString、SerializationLowCardinality、SerializationArray、SerializationNullable、SerializationTuple/Map等)的deserialize*接口,按需要的行数把字节重建为列。比如,下面这些数据类型的deserialization是:Array: 读 offsets 子流(size0/size1...) + 元素子流,拼成ColumnArrayTuple/Map: 对每个元素/命名成员各自解码;Map 即Array(Tuple(key,value))Nullable: 先读 null-map,再读嵌套值LowCardinality: 读索引(codes)子流;按需加载/读取字典子流(dict);codes→字典值映射成结果列
边界:解码至本次请求的行数或该 granule 结束;不够则跳到下一条 mark 继续
子流的递归添加和收集
在ClickHouse中,IMergeTreeReader针对Wide Part和Compact Part对应的实现类是 MergeTreeReaderWide和MergeTreeReaderCompact。以Wide Part为例,在构造一个Wide Part的MergeTreeReaderWide对象的时候,会在父类中设置每一个column的ISerializa实现类:
cpp
IMergeTreeReader::IMergeTreeReader(
.......
{
columns_to_read.reserve(requested_columns.size());
serializations.reserve(requested_columns.size());
for (const auto & column : requested_columns)
{
columns_to_read.emplace_back(getColumnInPart(column));
serializations.emplace_back(getSerializationInPart(column)); // 每一个Column的序列化实现类ISerialization存放在serializations中
}
}然后,在MergeTreeReaderWide中,会为每一个Column设置对应的Stream,这是通过MergeTreeReaderWide::addStreams()方法完成的:
cpp
MergeTreeReaderWide::MergeTreeReaderWide(
MergeTreeDataPartInfoForReaderPtr data_part_info_,
NamesAndTypesList columns_,
......
clockid_t clock_type_)
: IMergeTreeReader(
data_part_info_,
columns_,
....))
{
try
{
// 为每一个column添加对应的Stream
for (size_t i = 0; i < columns_to_read.size(); ++i)
addStreams(columns_to_read[i], serializations[i]);
}总之
MergeTreeReaderWide::addStreams()方法会针对"要读的某个列/子列",用该列的数据类型的序列化器 serialization->enumerateStreams(...) 枚举出该列所有必须的物理子流(每个子流都会对应一对文件:.bin数据、.mrk/.mrk2标记;同时可能还有共享 offsets、Nullable 的 null-mask、LC 的 dictionary/indices 等等)MergeTreeReaderWide::MergeTreeReaderWide()会在构造的时候通过MergeTreeReaderWide::addStreams()逐个Colun去发现其全部子流,并尝试读取子流对应的.bin文件和.cmrk2文件(这是通过方法IMergeTreeDataPart::getStreamNameForColumn()完成的),如果发现对应子流的文件缺失,那么就设置这个子流所对应的Column的has_all_streams为false,has_all_streams=false的column会被添加到partially_read_columns中
cpp
void MergeTreeReaderWide::addStreams(
const NameAndTypePair & name_and_type,
const SerializationPtr & serialization)
{
bool has_any_stream = false; // 这个Column是否有子流(至少有一个子流)
bool has_all_streams = true; // 如果这个Column至少有子流,那是否所有子流都成功读取到了
ISerialization::StreamCallback callback = [&] (const ISerialization::SubstreamPath & substream_path)
{
/// Don't create streams for ephemeral subcolumns that don't store any real data.
if (ISerialization::isEphemeralSubcolumn(substream_path, substream_path.size()))
return;
// 获取这个column的对应的stream,如果stream不存在,那么意味着stream 缺失,对应的column就会被添加到partially_read_columns中
auto stream_name = IMergeTreeDataPart::getStreamNameForColumn(name_and_type, substream_path, data_part_info_for_read->getChecksums());
/** If data file is missing then we will not try to open it.
* It is necessary since it allows to add new column to structure of the table without creating new files for old parts.
*/
if (!stream_name)
{
has_all_streams = false; // 发现了stream 缺失
return;
}
// 这个streams已经收集过,跳过
if (streams.contains(*stream_name))
{
has_any_stream = true;
return;
}
// 将这个stream添加到MergeTreeReaderWide对象中
addStream(substream_path, *stream_name);
has_any_stream = true;
};
// 针对这个column,开始进行stream的枚举,如果这个column是复合类型,这个枚举可能是递归进行的
serialization->enumerateStreams(callback);
// 如果这个column的stream 枚举结果显示这个column有stream暗示不是有全部stream,那么就将这个column添加到partially_read_columns中
if (has_any_stream && !has_all_streams)
partially_read_columns.insert(name_and_type.name);
}Substream和SubstreamPath
可以看到,StreamCallback就是一个自定义的function,这个functon的参数就是一个SubstreamPath,而ISerialization::SubstreamPath 是一个std::vector<Substream>,记录"从基列到当前子流"的层级轨迹
cpp
using StreamCallback = std::function<void(const SubstreamPath &)>;
cpp
struct SubstreamPath : public std::vector<Substream>
{
String toString() const;
};ISerialization::Substream 是描述"子流节点"的轻量结构,每个节点包含以下信息:
-
type(枚举,取值如
ArraySizes、ArrayElements、TupleElement、NullMap、VariantElement、DictionaryKeys等)、 -
附加信息(比如 tuple 元素名
name_of_substream、数组层级array_level、是否已访问visited等)cppstruct Substream { enum Type { ArrayElements, // 对应数组的实际数据流,也就是元素本身(arr.values)。这是对元素序列的遍历,本身不是一个独立子列(需要配合 offsets 才能还原数组) ArraySizes, // 对应数组的 offset 流(size0, size1 等)。它记录每行累计元素数量,用来恢复每个数组的长度,属于 metadata 流。是可以单独访问的子列(例如 arr.size0)。 .... TupleElement, // 这是一个独立子列,比如tag.values, tag.keys NamedOffsets, NamedNullMap, DictionaryKeys, // 这是一个给LowCardinality用的独立子列 DictionaryIndexes, // 这是一个给LowCardinality用的,不是独立子列 ..... Regular, }; /// Types of substreams that can have arbitrary name. static const std::set<Type> named_types; Type type = Type::Regular; /// The name of a variant element type. String variant_element_name; /// Name of substream for type from 'named_types'. String name_of_substream; /// Path name for Object type elements. String object_path_name; /// Data for current substream. SubstreamData data; /// Creator of subcolumn for current substream. // Substream::creator 是在各个具体 Serialization 的 enumerateStreams 实现中设置的 SubcolumnCreatorPtr creator = nullptr; /// Flag, that may help to traverse substream paths. mutable bool visited = false; Substream() = default; Substream(Type type_) : type(type_) {} /// NOLINT String toString() const; }; -
我们还可以看到一个变量
Substream::creator, 这个Substream::creator是在各个具体ISerialization的enumerateStreams()实现中设置的,即在我们递归调用ISerialization::enumerateStreams()的过程中,会往settings.path里 push 一个新的Substream(例如数组的元素流、tuple 元素、nullable 的 null-map 等),就顺带附上一个SubcolumnCreator实现类 用来告诉上层:如果要把当前子流提升回上一层,需要怎么构造IDataType/IColumn/Serialization。例如:
在 SerializationArray::enumerateStreams() 中,进入元素流时会 settings.path.back().creator = std::make_shared(offsets),这样当 createFromPath 逆向回溯时,就知道如何把子列重新包裹成 ColumnArray(利用那份 offsets)。
在 SerializationNamed(Tuple 元素)里也会 settings.path.back().creator = ...,把字段名和类型封装进去,以便回溯时恢复 TupleElement 的上下文。
Nullable、Variant、Object 等复杂类型的 Serialization 也各自设置了不同的 Creator,逻辑类似。
这些 creator 都是在执行 enumerateStreams 时临时附加到 Substream 节点上的,供 ISerialization::createFromPath 或 IDataType::getSubcolumn 逆向重建父层结构使用。
所以,遍历序列化树时,我们把这些节点依次堆栈起来,就得到一条 ISerialization::SubstreamPath------它精确描述了"正在处理的这段流"在整个复合结构里的位置信息,就好像我们一个文件的绝对路径一样:。
里面的每个元素(Substream)描述了这一层的类型(例如 ArraySizes、TupleElement、DictionaryKeys、VariantElement 等)以及附加信息(数组层级、tuple 元素名等)。遍历序列化树时,path 会按顺序堆叠这些节点,像文件系统路径一样精确定位到某条子流。
可以看到,每一个Substream中都有一个ISerialization::SubstreamData的引用, 但是SubstreamData 不是某个 Substream 节点本身的属性,而是跟随整条 SubstreamPath(或其中某个前缀)一起使用的上下文 。你可以把它理解成"沿着这条路径走到某个位置时,需要的序列化/列数据/类型信息 "。因此它与"路径上的当前前缀 "绑定,而不是独立属于单个 Substream 节点。
总之,ISerialization::SubstreamData携带"如何处理这段流"的上下文:
- serialization:指向当前列类型的序列化对象(SerializationArray、SerializationLowCardinality 等)。
- column:当前子流对应的列指针(IColumn *),有些分支会把它替换成子列的列对象。
- type:当前子流的逻辑类型(IDataType *)。
- serialization_info / deserialize_state:用于序列化信息共享、批量反序列化的额外状态。
Substream/SubstreamPath和SubstreamData 二者配合使用:Substream/SubstreamPath 提供"结构定位",SubstreamData 提供"数据与序列化的具体处理对象"。
SubstreamData的作用
SubstreamData 就是一份"当前这层 Substream 对应的数据上下文",它包含了当前层的以下这些信息:
- serialization:这一层用哪个 ISerialization
- type:这一层的 IDataType
- column:这一层已有的 IColumn(可能为空,用于推导结构/offsets 等)
- serialization_info:序列化信息(稀疏/默认等)
- deserialize_state:反序列化状态(动态子列相关)
我们从它的定义就可以看出来它包含了哪些信息:
cpp
struct SubstreamData
{
explicit SubstreamData(SerializationPtr serialization_) : serialization(std::move(serialization_)) {}
SubstreamData & withType(DataTypePtr type_) { type = std::move(type_); return *this; }
SubstreamData & withColumn(ColumnPtr column_) { column = std::move(column_); return *this; }
SubstreamData & withSerializationInfo(SerializationInfoPtr serialization_info_) { serialization_info = std::move(serialization_info_); return *this; }
SubstreamData & withDeserializeState(DeserializeBinaryBulkStatePtr deserialize_state_) { deserialize_state = std::move(deserialize_state_); return *this; }
SerializationPtr serialization;
DataTypePtr type;
ColumnPtr column;
SerializationInfoPtr serialization_info;
DeserializeBinaryBulkStatePtr deserialize_state;
};首先,我们还是以SerializationArray为例子,看一下SubstreamData是怎么被构造出来的。
可以看到,SubstreamData在在enumerateStreams()调用过程中构造的。我们看enumerateStreams()方法,可以看到,enumerateStreams(..., data) 调用的时候会携带调用者的Substream的SubstreamData,然后,在方法内部,会根据调用者传入进来的SubstreamData中的信息来构造下层的Substream的SubstreamData。
比如,在 SerializationArray::enumerateStreams()中,就首先从调用者传入进来的SubstreamData中拿到了调用者准备好的ColumnArray(IColumn)和offsets信息
cpp
const auto * type_array = data.type ? &assert_cast<const DataTypeArray &>(*data.type) : nullptr;
const auto * column_array = data.column ? &assert_cast<const ColumnArray &>(*data.column) : nullptr;
auto offsets = column_array ? column_array->getOffsetsPtr() : nullptr;然后,在构造子流(ArraySizes和ArrayElements)的时候,以及调用者传入的Callback在处理子流的时候,都需要使用SubstreamData中封装好的、关于这个这个Substream的各种信息,比如:
-
对于当前可以独立访问的子流(
ArraySizes),调用者定义的callback()会对这个子流进行处理(ISerialization::enumerateStreams()本身就是这样定义的),这时候,需要将这个独立访问的子流的信息封装成SubstreamData,供callback使用:cppauto offsets_serialization = std::make_shared<SerializationNamed>( std::make_shared<SerializationNumber<UInt64>>(), subcolumn_name, SubstreamType::NamedOffsets); settings.path.push_back(Substream::ArraySizes); settings.path.back().data = SubstreamData(offsets_serialization) // 把 这个子流的 serialization 放进去(这里是 offsets 用的 SerializationNamed(SerializationNumber<UInt64>, "size0")) .withType(std::make_shared<DataTypeUInt64>()) // offset这个子流的 type 是 UInt64 .withColumn(std::move(offsets_column)); // offsets(或 sizes)列 callback(settings.path); -
同时,假如这一层还有下一层Substream(比如
ArrayElements),那么,需要在递归调用前,准备好下一层需要的SubstreamData:cppsettings.path.back() = Substream::ArrayElements; settings.path.back().data = data; settings.path.back().creator = std::make_shared<SubcolumnCreator>(offsets); auto next_data = SubstreamData(nested) // ISerialization, nested 是 SerializationArray 持有的"元素序列化器"。对 Array(String) 它就是 SerializationString(元素怎么 encode/decode 由它负责)。 .withType(type_array ? type_array->getNestedType() : nullptr) // IDataType, 对 DataTypeArray(String),getNestedType() 就是 String 类型对象(DataTypeString)。 .withColumn(column_array ? column_array->getDataPtr() : nullptr); // IColumn, 把 elements 列(ColumnString) 作为"下一层要处理的 column"。 nested->enumerateStreams(settings, callback, next_data); // 携带构造好的SubstreamData, 往下递归
下图展示了SerializationArray在enumerateStreams()的时候,SubstreamData, 用户定义的callback,以及Substream之间交互的过程:
text
Array(String) 的 enumerateStreams:callback 与 SubstreamData 的交互(一次遍历)
调用方(上层,比如 addStreams / getSubcolumnData)
|
| 传入:callback(path)
| 传入:data = SubstreamData(SerializationArray)
| .withType(DataTypeArray(String))
| .withColumn(ColumnArray(elements=ColumnString, offsets=...))
v
SerializationArray::enumerateStreams(settings, callback, data)
|
| (1) 先构造 offsets 子流(ArraySizes),把"这个子流对应的 SubstreamData"挂到 path.back().data
|
| settings.path.push_back(ArraySizes)
| settings.path.back().data =
| SubstreamData(offsets_serialization)
| .withType(UInt64)
| .withColumn(offsets_column or sizes_column)
| .withSerializationInfo(data.serialization_info)
|
+-------------------------------> callback(path=[ArraySizes])
| ^
| | callback 看到:
| | - path.back().type == ArraySizes
| | - path.back().data.type == UInt64
| | - path.back().data.serialization == offsets_serialization
| | - path.back().data.column == offsets_column
|
|
| (2) 再进入元素子树(ArrayElements),此时不直接 callback,而是继续递归到 nested=SerializationString
| 并把"下一层递归要用的 SubstreamData(next_data)"构造好传下去
|
| settings.path.back() = ArrayElements
| settings.path.back().data = data (父层 data 保留在节点上)
| settings.path.back().creator = SubcolumnCreator(offsets) // 供回溯包装用
|
| next_data =
| SubstreamData(SerializationString)
| .withType(String)
| .withColumn(elements_column = ColumnString)
| .withSerializationInfo(data.serialization_info)
| .withDeserializeState(data.deserialize_state)
v
SerializationString::enumerateStreams(settings, callback, next_data)
|
| String 是叶子:不会再 push 新的 Substream::Type(没有 NullMap/ArraySizes/TupleElement 等)
| 直接把"当前 path(仍以 ArrayElements 结尾)"作为一个最终可读写的流交给 callback
|
+-------------------------------> callback(path=[ArrayElements])
^
| callback 看到:
| - path.back().type == ArrayElements
| - path.back().data 仍是 Array 的 data(可用于 creator/结构信息)
| - 但叶子要处理的实际 leaf 数据在 next_data:
| next_data.type == String
| next_data.serialization == SerializationString
| next_data.column == ColumnString(elements)
|
|(上层通常用 path 来生成文件名/子流名,
| 再结合"当前层/叶子层的 SubstreamData"决定如何读写/反序列化)ISubcolumnCreator的作用
ISubcolumnCreator对应的create(...)方法主要有下面三种功能:
- 根据下层的
DataType去还原上层的DataType, - 根据下层的序列化方式
ISerialization还原出上层的序列化方式ISerialization - 根据下层的
IColumn还原出上层的IColumn
ISubcolumnCreator接口定义如下:
cpp
struct ISubcolumnCreator
{
virtual DataTypePtr create(const DataTypePtr & prev) const = 0;
virtual SerializationPtr create(const SerializationPtr & prev) const = 0;
virtual ColumnPtr create(const ColumnPtr & prev) const = 0;
virtual ~ISubcolumnCreator() = default;
};ISubcolumnCreator 是用来"沿着子流路径回溯"时,动态重建更高层上下文的,即自底向上来进行列(IColumn)、数据类型(IDataType)和序列化方式(ISerialization)重建的构造器和包装器。
枚举子流(比如SerializationArray::enumerateStreams())时,我们通常只持有最末端 SubstreamData(比如某个 Tuple(String)或者String元素的 序列化器ISerialization和列指针IColumn),但当我们想把这段路径缩短(回溯)到某个前缀时,就需要把子列(ColumnString)的类型、序列化器、列数据重新包装成上一级(ColumnArray)的对象------这正是 ISubcolumnCreator 的任务。
比如,对于一个Array(String),会形成这样一个SubstreamPath: ArrayElements → ColumnString , 然后,如果我们在更深处已经拿到了元素列(在ISubcolumnCreator接口中叫做prefv)
它提供三个 create 接口:
DataTypePtr create(const DataTypePtr & prev): 给定下一级的类型(如 String),构造上一层对应的类型(如 Tuple(keys String, ...) 中 keys 的视角)SerializationPtr create(const SerializationPtr & prev): 把子序列化器升级成上一级序列化器(例如把SerializationString包装成SerializationNamed,再包装成SerializationArray)。ColumnPtr create(const ColumnPtr & prev): 把子列的IColumn指针包装成上一层对应的列(例如把ColumnString装入 ColumnTuple 的某个元素,或者装入 ColumnArray 的元素列)
我们以最常见的SerializationArray为例,来解释这件事情:
先看一下SerializationArray的enumerateStreams()方法中,是怎么为ArrayElements来设置creator的:
cpp
void SerializationArray::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
..... 对ArraySizes调用callback
// 处理ArrayElements
settings.path.back() = Substream::ArrayElements;
settings.path.back().data = data; // 设置这个Array Substream的data
settings.path.back().creator = std::make_shared<SubcolumnCreator>(offsets); // 设置这个Array Substream的SerializationArray::SubcolumnCreator
// 构造下一层的SubstreamData
auto next_data = SubstreamData(nested) // 对应的序列化器
.withType(type_array ? type_array->getNestedType() : nullptr) // 如果是一个array,那么下一层的类型就是 type_array->getNestedType(),对于Map这种array,nestType就是一个TupleType
.withColumn(column_array ? column_array->getDataPtr() : nullptr) // Column就是对应的TupleColumn
.withSerializationInfo(data.serialization_info) // SerializationTuple
.withDeserializeState(data.deserialize_state);
....
}对 Array(String) 来说
ISerialization nested对应了SerializationString,SubstreamData next_data中的IColumn对应了就是ColumnString,type_array->getNestedType()对应了对应的DataTypeString- 而
offsets则是记录的偏移量信息,下文会详细讲解队offset的理解;
所以,对于SerializationArray, 它的ISubcolumnCreator 实现类是SerializationArray::SubcolumnCreator。
我们可以看一下SerializationArray::SubcolumnCreator所实现的3个重载的create()方法,分别用来根据下层的IDataType,ISerialization和IColumn构造上层的IDataType,ISerialization和IColumn:
cpp
// 类型包装器
DataTypePtr SerializationArray::SubcolumnCreator::create(const DataTypePtr & prev) const
{
// 根据下层的DataTypeString,封装为当前Array层的DataTypeArray
return std::make_shared<DataTypeArray>(prev);
}
// 序列化方式包装器
SerializationPtr SerializationArray::SubcolumnCreator::create(const SerializationPtr & prev) const
{
// 根据下层的SerializationString,封装为当前Array层的SerializationArray
return std::make_shared<SerializationArray>(prev);
}
// 列信息包装器
ColumnPtr SerializationArray::SubcolumnCreator::create(const ColumnPtr & prev) const
{
// 根据下层的elements(ColumnString),结合当前Array的offset信息,准确还原处Array的ColumnArray
return ColumnArray::create(prev, offsets);
}可以看到,这个包装器完成了下面三件事情的自底向上的包装:
- 类型包装(IDataType): :
T->Array(T) - 序列化方式的包装(ISerialization): :
Serialization(T)->Serialization(Array(T)) - 列信息的包装(IColumn): :
Column(T) + offsets->ColumnArray。- Array 的上层结构(
ColumnArray)必须同时有elements列 和offsets列,而元素的substream往下递归时只携带elements,所以需要creator(offsets)在回溯时把elements + offsets重新拼成ColumnArray。
- Array 的上层结构(
关于怎么使用creator来自底向上还原对应的类型、序列化方式和列信息,我们可以参考方法ISerialization::createFromPath(),下文会详细讲解这个方法。
怎么理解Array的offset?
比如,对于下面一张含有一个Array(String)列的表:
sql
CREATE TABLE t_arr
(
id UInt64,
tags Array(String)
)
ENGINE = MergeTree
ORDER BY id;我们往其中插入了4条数据
sql
INSERT INTO t_arr VALUES
(1, ['a','b','c']),
(2, []),
(3, ['x']),
(4, ['p','q']);我们把 tags Array(String) 想成"把所有字符串拼成一条长的 elements 流",但每一行数组长度不一样,所以必须有 offsets 来划分边界,这样,我们才知道整个elements流中的每一个elements到底属于哪一行.
所以,ColumnArray 的真实存储形态是elements + offsets,即ClickHouse 内存里 Array(String) 的列对象(IColumn)是 ColumnArray,它由两部分组成:
-
elements(元素列):把所有行的所有元素按顺序"摊平"成一列ColumnString -
offsets(偏移列):长度等于行数,每个offsets[i]表示 到第 i 行为止,一共累积了多少个元素(前缀和)
对上面的 4 行数据:
elements(摊平后):
['a','b','c','x','p','q'](总 6 个元素)
offsets则记录了每一行数据的累计结束位置:第1行 ['a','b','c'] 结束 → 3 第2行 [] 结束 → 3 第3行 ['x'] 结束 → 4 第4行 ['p','q'] 结束 → 6
所以 offsets = [3, 3, 4, 6]
ISerialization::enumerateStreams()在各个类型上的实现
对于一个复合类型比如Map<LowCardinality<String>, String>,由于 Map(K,V) 就是 Array(Tuple(K,V))的语法糖,所以,准确表达Map<LowCardinality<String>, String>的子流需要有用来表达Array的Stream,用来表达LowCardinatlity的Stream(一个LowCardinality(String)需要两个子流来表达,字典子流和索引子流)和用来表达Tuple的Stream,这是通过开始对Map进行递归逐渐获取的。
我们为了简单起见,忽略LowCardinality类型,直接以tag Map(String, String)为例,讲解整个子流的枚举过程:
SerializationMap
cpp
/**
* Map 是语法糖:Map(K,V) ≡ Array(Tuple(K,V))。因此 Map 自己不产出子流,Map 层只负责"把 Map 换成 Array(Tuple)"的 next_data 转交;
* 只是把"嵌套类型/列"改写为 nested(=SerializationArray(SerializationTuple(...))),
* 然后把"新的 data"(指向嵌套的类型/列/状态)转交给 nested->enumerateStreams。
* @param settings
* @param callback
* @param data
*/
void SerializationMap::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
auto next_data = SubstreamData(nested)
.withType(data.type ? assert_cast<const DataTypeMap &>(*data.type).getNestedType() : nullptr)
.withColumn(data.column ? assert_cast<const ColumnMap &>(*data.column).getNestedColumnPtr() : nullptr)
.withSerializationInfo(data.serialization_info)
.withDeserializeState(data.deserialize_state);
// 把工作完全交给 Array 层
nested->enumerateStreams(settings, callback, next_data);
}对应参数的含义是:
- settings: 枚举时的"上下文",最重要的是 path(一个栈,记录当前走到的子流路径),这个path起始是一个栈,在比如对一个复合类型比如Map进行enumerateStreams的时候会进行递归操作,这时候会把一条物理子流表示成一个
SubstreamPath, 即一个path=vector<Substream>。枚举时通过对SubstreamPath调用push_back()/pop_back()来进行从顶向下的遍历;回调拿到整条 path 后据此生成文件名并打开对应.bin/.mrk2 - callback(SubstreamPath): 上面讲过,一个SubstreamPath就是一个
std::vector<Substream>,这个callback(...)被调用一次就表示"发现一个物理子流";上层据 SubstreamPath 生成文件名并建流; - data: SubstreamData,携带"当前节点(SubstreamPath)"的上下文:
- data.serialization: 当前节点的序列化器对象(决定如何继续往下枚举)。
- data.type / data.column: 若已知类型/已有列数据,提供给子节点(便于命名、常量折叠、偏移再用等)。
- data.serialization_info / data.deserialize_state: 存放附加序列化信息与反序列化临时状态(有的复合类型会把一整套 state 分发给各子元素)
我们可以看到,由于Map仅仅是Array的语法糖,因此,SerializationMap::enumerateStreams(...)中没有调用callback方法。
SerializationArray
cpp
/**
* 会产生两类路径,ArraySizes(offsets子流)和ArrayElements(元素子流)
* Array 层必产出 sizeN(M.size0, ArraySizes),并把元素分支交给 Tuple;
* @param settings
* @param callback
* @param data
*/
void SerializationArray::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
const auto * type_array = data.type ? &assert_cast<const DataTypeArray &>(*data.type) : nullptr;
const auto * column_array = data.column ? &assert_cast<const ColumnArray &>(*data.column) : nullptr;
auto offsets = column_array ? column_array->getOffsetsPtr() : nullptr;
// getArrayLevel(path) = 当前数组深度(外层 size0,内层 size1 ...)。
// 所以对于普通的Map,数组的深度是1,因此getArrayLevel(settings.path)=0
auto subcolumn_name = "size" + std::to_string(getArrayLevel(settings.path));
auto offsets_serialization = std::make_shared<SerializationNamed>(
std::make_shared<SerializationNumber<UInt64>>(),
subcolumn_name, SubstreamType::NamedOffsets);
auto offsets_column = offsets && !settings.position_independent_encoding
? arrayOffsetsToSizes(*offsets)
: offsets;
// 把以ArraySizes为Type构造一个Substream对象,并添加到SubstreamPath中
settings.path.push_back(Substream::ArraySizes);
// 构造新的SubstreamData
settings.path.back().data = SubstreamData(offsets_serialization) // 设置这个offset子流的SubstreamData,可以看到,对应的ISerialization是offsets_serialization
.withType(type_array ? std::make_shared<DataTypeUInt64>() : nullptr)
.withColumn(std::move(offsets_column))
.withSerializationInfo(data.serialization_info);
// callback定义在 MergeTreeReaderWide::addStreams
// 每调用一次 callback,就生成了一个substream。这里可以看到,在SerializationMap::enumerateStreams中并没有调用callback
// 说您在Map层没有对应子流,在Array层有一个子流,这是Map的第一个子流,是对应Array的size信息流
callback(settings.path);
/**
* 刚刚已经通过调用callback来生成了ArraySizes的子流,此时,对于这个Array的元素,需要继续递归进行,因此,
* 把刚刚push进来的ArraySizes(即以ArraySizes为Type的Substream添加进来)进行替换
* ,替换成ArrayElements子流(但是并没有调用callback来生成这个子流)
* 把 path 的尾元素改成 ArrayElements,并附带 creator(SubcolumnCreator(offsets),给下层在需要时复原子列用)。
*/
settings.path.back() = Substream::ArrayElements;
settings.path.back().data = data; // 设置这个Array Substream的data
settings.path.back().creator = std::make_shared<SubcolumnCreator>(offsets); // 设置这个Array Substream的SerializationArray::SubcolumnCreator
// 构造下一层的SubstreamData
auto next_data = SubstreamData(nested) // 对应的序列化器
.withType(type_array ? type_array->getNestedType() : nullptr) // 如果是一个array,那么下一层的类型就是 type_array->getNestedType(),对于Map这种array,nestType就是一个TupleType
.withColumn(column_array ? column_array->getDataPtr() : nullptr) // Column就是对应的TupleColumn
.withSerializationInfo(data.serialization_info) // SerializationTuple
.withDeserializeState(data.deserialize_state);
// Map转换成的Array的下层是Tuple,因此,这里的nested是SerializationTuple::enumerateStreams方法
// 注意,只有Map的实现是Array(Tuple(K,V)),普通Array比如Array(String),它的下层就不一定是Tuple
nested->enumerateStreams(settings, callback, next_data);
settings.path.pop_back(); // 将刚刚push进来的
}从上面的代码可以看到,Array 会枚举两种类型的Substream(Substream Type):
ArraySizes(offsets子流),这个子流会调用callback,因为它是一个实实在在的、落地成文件的、可独立访问的子列(如size0)。ArrayElements(元素子流),这个Substream Type不会调用callback,而是继续往下递归枚举元素(String/Tuple/...),因为这个Type根本就是一个从Array到下层的Substream的过渡类型
这里,会生成如下子流:
-
会生成offset子流,并调用对应的callback:
path = [ArraySizes(level=0)]→ 对应tags.size0。cpp// 设置这个刚加进来的Substream的data数据 settings.path.back().data = SubstreamData(offsets_serialization) .withType(type_array ? std::make_shared<DataTypeUInt64>() : nullptr) .withColumn(std::move(offsets_column)) .withSerializationInfo(data.serialization_info); // callback定义在 MergeTreeReaderWide::addStreams // 每调用一次 callback,就生成了一个substream。这里可以看到,在SerializationMap::enumerateStreams中并没有调用callback // 说您在Map层没有对应子流,在Array层有一个子流,这是Map的第一个子流,是对应Array的size信息流 callback(settings.path);这里,
settings.path是一个SubstreamPath(Vector<Substream>),因此这里其实会调用Substream的带参构造函数(Substream(Type type_) : type(type_) {}),该构造方法只是设置了Substream的type为枚举值Substream::ArraySizes,其它参数全部使用默认。 -
在处理完了offset以后,就将对应的
Substream::ArraySizes替换成Substream::ArrayElements,即,需要对tag.keys和tag.values进行处理了:cppsettings.path.back() = Substream::ArrayElements; settings.path.back().data = data; // 设置这个Array Substream的data settings.path.back().creator = std::make_shared<SubcolumnCreator>(offsets); // 设置这个Array Substream的SerializationArray::SubcolumnCreator // 构造下一层的SubstreamData auto next_data = SubstreamData(nested) // 对应的序列化器 .withType(type_array ? type_array->getNestedType() : nullptr) // 如果是一个array,那么下一层的类型就是 type_array->getNestedType(),对于Map这种array,nestType就是一个TupleType .withColumn(column_array ? column_array->getDataPtr() : nullptr) // Column就是对应的TupleColumn .withSerializationInfo(data.serialization_info) // SerializationTuple .withDeserializeState(data.deserialize_state);可以看到,这里创建了一个
SubcolumnCreator对象,挂载在了Substream::ArraySizes这个Substream下面。在构造SubcolumnCreator的时候,传入了当前的offsets。这里,这个含有offsets信息的Creator对象的功能是:- 如果元素的数据流缺失(比如tags.key缺失)但是共享offsets仍然可用,ClickHouse 需要"凭空"构造这个子列以满足查询,显然,由于数据缺失,这里的构造只能根据默认值去凭空构造。
- 比如列结构
tags Map(String,String)在磁盘上拆成三条流:tags.size0(array sizes)、tags.keys、tags.values。若tags.keys文件损坏/丢失,但tags.size0仍在,MergeTreeReader在collectOffsetsColumns()中会找到tags.size0的ColumnUInt64并按subpath [ArraySizes(level=0)]存入offsets map。 - 随后
fillMissingColumns()尝试恢复tags.keys:根据其SubstreamPath = [ArrayElements(level=0), TupleElement(name="keys")]逆向找到共享的offsets。 - 这时候,tags.keys对应的Substream中封装的Creator会基于
ColumnString(全空)这个扁平数据,调用 creator->create(prev) 把这个扁平数据包装成 ColumnArray(ColumnString, offsets),最终得到一个与tags.size0对齐的数组列。这样即使原来的 keys 数据缺失,也能生成一个正确形状的列填入结果(默认值字符串)
我们在上文讲解ISubcolumnCreator的时候详细讲解了Array的ISubcolumnCreator以及offsets的含义,这里不做赘述。
同时,这一层也创建了对应的SubstreamData对象用来传给下一层(nested)。每个Serialization*::enumerateStreams()调自己下一层之前,会基于当前 的SubstreamData构造一个新的SubstreamData,动机是让序列化器在递归遍历复合类型结构时,携带/传递包括这一层的真实数据指针、类型信息、序列化器 等元数据。在递归遍历过程中,调用层不断为下层准备好SubstreamData,比如-
SerializationArray::enumerateStreams在生成 offsets 子流时,把当前的SubstreamData换成SubstreamData(offsets_serialization).withType(UInt64).withColumn(offsets_column),这样 callback 能拿到"这个子流写的是 UInt64 的 offsets 数据"这样的关键信息;cppsettings.path.back().data = SubstreamData(offsets_serialization) // 设置这个offset子流的SubstreamData,可以看到,对应的ISerialization是offsets_serialization .withType(type_array ? std::make_shared<DataTypeUInt64>() : nullptr) .withColumn(std::move(offsets_column)) .withSerializationInfo(data.serialization_info); -
随后它把 path 设成
ArrayElements,把 data 改回原始的SubstreamData:cppsettings.path.back().data = data; // 设置这个Array Substream的data -
然后,它会构造新的SubstreamData,
withType(nested type)、withColumn(array data), 这个SubstreamData是传给下一层(Tuple等)的元数据信息:cpp// 构造下一层的SubstreamData auto next_data = SubstreamData(nested) // 对应的序列化器 .withType(type_array ? type_array->getNestedType() : nullptr) // 如果是一个array,那么下一层的类型就是 type_array->getNestedType(),对于Map这种array,nestType就是一个TupleType .withColumn(column_array ? column_array->getDataPtr() : nullptr) // Column就是对应的TupleColumn .withSerializationInfo(data.serialization_info) // SerializationTuple .withDeserializeState(data.deserialize_state);
-
-
在
SerializationArray::enumerateStreams()这一层不会直接为keys和values生成数据子流,生成keys和values的数组子流还需要继续往下递归,因此SerializationArray::enumerateStreams()会生成keys和values的SubstreamPath的第一个元素,即往SubstreamPath数组中pushArrayElements(level=0);,但是随着下层SerializationTuple::enumerateStreams()的进一步递归,还会进一步生成第二层,即针对keys和values的TupleElement(name="keys")和TupleElement(name="values");。下文会讲解。总之,这里,将path的最后一个节点从刚刚的
ArraySizes更新为ArrayElements,准备继续对下层进行递归,ArrayElements不是最终子流:cppsettings.path.back() = Substream::ArrayElements; -
在处理完了
ArraySizes子流,并且现在在SubstreamPath中推入了当前的ArrayElements,并准备好了SubstreamData以后,就递归调用对应的callback:cppnested->enumerateStreams(settings, callback, next_data);显然,这里的
nested是SerializationArray的下一层,即SerializationTyple。下文会讲解SerializationTuple
SerializationTuple
cpp
/**
* 为Tuple生成stream
* 从方法 中可以看到,在Tuple本身这一层并没有通过调用callback生成对应的子流,而是在下层生成子流
* @param settings
* @param callback
* @param data
*/
void SerializationTuple::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
if (elems.empty()) // 如果这个Tuple没有任何一个元素
{
ISerialization::enumerateStreams(settings, callback, data);
return;
}
const auto * type_tuple = data.type ? &assert_cast<const DataTypeTuple &>(*data.type) : nullptr;
const auto * column_tuple = data.column ? &assert_cast<const ColumnTuple &>(*data.column) : nullptr;
const auto * info_tuple = data.serialization_info ? &assert_cast<const SerializationInfoTuple &>(*data.serialization_info) : nullptr;
const auto * tuple_deserialize_state = data.deserialize_state ? checkAndGetState<DeserializeBinaryBulkStateTuple>(data.deserialize_state) : nullptr;
// 遍历tuple的每一个元素(注意,一个tuple并不一定是二元tuple,有可能是多元tuple。只有Map(String, String) -> Array(Tuple(String, String))所
// 对应的Tuple才是二元tuple,即elems[0]就是key, elems[1]就是value)
for (size_t i = 0; i < elems.size(); ++i)
{
auto next_data = SubstreamData(elems[i]) // 基于子元素的ISerialization构造对应的位置i的元素的SubstreamData对象
.withType(type_tuple ? type_tuple->getElement(i) : nullptr) // 这个Tuple中位置i的元素的具体类型
.withColumn(column_tuple ? column_tuple->getColumnPtr(i) : nullptr) // 这个Tuple中位置i的元素的IColumn
.withSerializationInfo(info_tuple ? info_tuple->getElementInfo(i) : nullptr) // 这个Tuple中位置i的元素的SerializationInfo
.withDeserializeState(tuple_deserialize_state ? tuple_deserialize_state->states[i] : nullptr);
// 对Tuple中的每一个元素调用 enumerateStreams
// 每一个elems[i]是一个 SerializationNamed,因此这里的enumeratStreams都是调用 SerializationNamed::enumerateStreams
// SerializationTuple::enumerateStreams 本身不直接 push "TupleElement" 节点,
// 因为它把这项工作交给包裹每个 tuple 元素的 SerializationNamed。在遍历 tuple 的时候:
elems[i]->enumerateStreams(settings, callback, next_data);
}
}可以看到,SerializationTuple并没有往SubstreamPath中添加任何一个Substream,也没有调用callback,因为tuple这一层只不过是Tuple中的元素的组合层,其本身没有任何需要进行索引的数据,而是一个中间层一样,直接遍历自己Tuple中的每一个元素,在准备好了每一个元素的SubstreamData以后,直接进行每一个Element的enumerateStreams()的递归调用。
往SubstreamPath中继续推入一个Substream是下层每一个元素对应的ISerialization::enumerateStreams()实现的,在我们的例子中,SerializationTuple的下一层是SerializationNamed。
SerializationNamed
凡是"给某个子流起一个可读名字"的场景(Array 的 sizeN、Nullable 的 null、Tuple 的元素名等),都会通过 SerializationNamed(nested, name, substream_type) 来做。
SerializationNamed::enumerateStreams()的实现如下所示:
cpp
/**
* 是一个封装类型,本层并不产生一个直接落地磁盘的Substream,而是依赖下层的nested_serialization
* @param settings
* @param callback
* @param data
*/
void SerializationNamed::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
addToPath(settings.path); // 往SubstreamPath中推入新的Substream,即对应的TupleElement
settings.path.back().data = data;
settings.path.back().creator = std::make_shared<SubcolumnCreator>(name, substream_type);
/**
* 如果是一个LowCardinality(String),那么这里就是 SerializationLowCardinality::enumerateStreams()
* 如果是普通的String,那么就是 SerializationString::enumerateStreams()
*/
nested_serialization->enumerateStreams(settings, callback, data);
settings.path.pop_back();
}可以看到,这里首先往SubstreamPaths中塞入了一个TupleElement, 然后准备好SubstreamData和ISubcolumnCreator,然后进行递归调用。所以,SerializationNamed并没有一个直接落地到磁盘的Substream,因此没有callback进行调用。
SerializationNamed::addToPath()方法会把当前的Substream给append到SubstreamPath的末尾,同时这是对应的Substream的名字(这是SerializationTuple所特有的,因为SerializationTuple本来就是用来表达一个带名字的Substream的)
cpp
void SerializationNamed::addToPath(SubstreamPath & path) const
{
path.push_back(substream_type); // 这里的substream_type就是 TupleElement这个Substream type
path.back().name_of_substream = name; // 设置这个TupleElement Substream的名字,把这个Substream的名字设置为当前SerializationNamed的名字,这个名字其实就是Tuple中这个元素的名字,比如,对于Map<>引起的SerializationArray -> SerializationNamed, 这个名字就是固定的keys 或者 values
}由于在构造SerializationTuple的默认序列化器的时候,明确写死了,其Tuple的每一个元素(SerializationNamed)的substream_type肯定是TupleElement:
cpp
SerializationPtr DataTypeTuple::doGetDefaultSerialization() const
{
SerializationTuple::ElementSerializations serializations(elems.size());
for (size_t i = 0; i < elems.size(); ++i)
{
String elem_name = have_explicit_names ? names[i] : toString(i + 1);
auto serialization = elems[i]->getDefaultSerialization();
// 构造SerializationTuple的时候,会先准备好SerializationNamed,而构造SerializationNamed的时候传入的type明确为TupleElement
serializations[i] = std::make_shared<SerializationNamed>(serialization, elem_name, SubstreamType::TupleElement);
}
return std::make_shared<SerializationTuple>(std::move(serializations), have_explicit_names);
}基于Map(LowCardinality(String), String),到了SerializationArray::enumerateStreams() -> SerializationTuple::enumerateStreams() -> SerializationNamed::enumerateStreams()这个深度,这里的nested_serialization应该是SerializationLowCardinality,因为对应的keys是LowCardinality(String)
所以,,无论是keys还是values,目前都形成了如下的SubstreamPath:
- keys的
SubstreamPath是[ArrayElements(level=0), TupleElement(name="keys")]→ 对应tags.keys的数据流。 - values的
SubstreamPath是[ArrayElements(level=0), TupleElement(name="values")]→ 对应tags.values的数据里
我们在删
上文在讲解ISubcolumnCreator的时候,拿SerializationArray::SubcolumnCreator进行了具体的讲解。这个SerializationNamed的ISubcolumnCreator实现类是SerializationNamed::SubcolumnCreator,代码如下所示:
cpp
struct SubcolumnCreator : public ISubcolumnCreator
{
const String name;
SubstreamType substream_type;
SubcolumnCreator(const String & name_, SubstreamType substream_type_)
: name(name_), substream_type(substream_type_)
{
}
DataTypePtr create(const DataTypePtr & prev) const override { return prev; }
ColumnPtr create(const ColumnPtr & prev) const override { return prev; }
SerializationPtr create(const SerializationPtr & prev) const override
{
return std::make_shared<SerializationNamed>(prev, name, substream_type);
}
};从SerializationNamed::SubcolumnCreator的构造方法可以看到,SerializationNamed::SubcolumnCreator只需要知道的是这个SerializationNamed的名字,还有对应的SubstreamType即可, 比如:
- 在SerializationArray中的offsets的ISerialization就是SerializationNamed
name = "size" + std::to_string(getArrayLevel(settings.path))(例如最外层就是size0)substream_type = SubstreamType::NamedOffsets(对应enum里的NamedOffsets)
- 在
Map(String, String)(其实是Array(Tuple(String, String)))中- name只有两个固定值,
keys或者values substream_type = SubstreamType::TupleElement(TupleElement)
- name只有两个固定值,
- 在
Tuple(a String, b String)中:- name就是对饮的Tuple元素的名字,
a或者b substream_type = SubstreamType::TupleElement(TupleElement)
- name就是对饮的Tuple元素的名字,
SerializationLowCardinality
从堆栈我们可以看到,对于Map<LowCardinality<String>, String>,其真实结构是Array(Tuple(LowCardinality(keys), values))。
所以:
-
对于
keys,它的调用路径是SerializationMap->SerializationArray->SerializationTuple->SerializationNamed->SerializationLowCardinality->SerializationString -
对于
values,它的path中则没有SerializationLowCardinality,其它元素及其顺序与keys相同:cppvoid SerializationLowCardinality::enumerateStreams( EnumerateStreamsSettings & settings, const StreamCallback & callback, const SubstreamData & data) const { const auto * column_lc = data.column ? &getColumnLowCardinality(*data.column) : nullptr; settings.path.push_back(Substream::DictionaryKeys); // 非独立子列,因为字典元素本身可能是复合类型 auto dict_data = SubstreamData(dict_inner_serialization) .withType(data.type ? dictionary_type : nullptr) .withColumn(column_lc ? column_lc->getDictionary().getNestedColumn() : nullptr) .withSerializationInfo(data.serialization_info); settings.path.back().data = dict_data; dict_inner_serialization->enumerateStreams(settings, callback, dict_data); // 对DictionaryKeys进行递归调用enumereateStreams settings.path.back() = Substream::DictionaryIndexes; // 独立子列,落地的Substrema settings.path.back().data = data; callback(settings.path); // 对DictionalIndexes调用callback,因为它是物理落地的stream settings.path.pop_back(); }
比如,原列是一个LowCardinality(String)列,我们举例说明:
- 其数据是
[ "apple", "banana", "apple", "durian", "banana", ... ],共10000行,但只有10个不同的字符串。 LowCardinality(String)会把这10个不同值写到DictionaryKeys(顺序可能是["apple","banana","durian",...]),只需要存10行即可,因为只有10个不同的值;- 随后整列数据则用
DictionaryIndexes表示成[0, 1, 0, 2, 1, ...],每个数字表示该行在字典里的下标。所以,DictionaryIndexes代表的是将数据进行低基编码以后的数据本身。 - 读取时,先把
DictionaryKeys加载成数组,再用DictionaryIndexes去字典里取字符串,就恢复回原10000行。
从上面的SerializationLowCardinality::enumerateStreams()代码可以看到
- 这里针对
Substream::DictionaryKeys进行了递归调用,这是因为字典元素本身有可能是复合类型,比如,LowCardinality(Tuple(a UInt32, b String)), 那么,SerializationLowCardianlity->SerializationTuple->SerializationNamed会在该 path 下再 pushTupleElement("a")、TupleElement("b")等 - 对于
Substream::DictionaryIndexes则直接调用callback(),这是因为Substream::DictionaryIndexes是直接落地的Substream,而不是一个衔接性的Substream。比如,如下图所示,keys.dict.bin/keys.dict.cmrk2就是Substream::DictionaryIndexes文件。
shell
`tagGroup15` Map(LowCardinality(String), String) CODEC(ZSTD(1)),SerializationString
我们可以看到,SerializationString没有实现自己的ISerialization::enumerateStreams()方法,它直接使用了父类的ISerialization的enumerateStreams()方法。ISerialization::enumerateStreams()的实现如下所示:
cpp
void ISerialization::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
settings.path.push_back(Substream::Regular);
settings.path.back().data = data;
callback(settings.path);
settings.path.pop_back();
}第一次补列: IMergeTreeReader::fillMissingColumns()方法对缺失列进行填充
IMergeTreeReader::fillMissingColumns()填充类型默认值
所以,此时,我们已经构造了 MergeTreeSequentialSource对象,并且在为每一个part构造其对应的IMergeTreeReader中已经构造了所需要读取的列的子流。 在构造的过程中,由于host列缺失,ClickHouse不得已添加了另外一个列tagGroup1.key来伴随进行读取,这一列不是一个平常的列,而是一个复合列的子列。很明显,我们异常的发生就是这个新添加的子列所在的基列中的另外一个子列tagGroup1.key导致的。我们会详细讲解。
我们知道,ISource::generate()是负责对数据的生成的,因此,我们看一下,MergeTreeSequentialSource::generate()方法的具体实现。这里,每次 MergeTreeSequentialSource::generate()的调用都会读取执行行的数据,显然,part中没有host列:
cpp
Chunk MergeTreeSequentialSource::generate()
try
{
const auto & header = getPort().getHeader();
/// Part level is useful for next step for merging non-merge tree table
bool add_part_level = storage.merging_params.mode != MergeTreeData::MergingParams::Ordinary;
// 当前 part(data_part)总共有多少 "mark"(稀疏索引点),用于 readRows 控制读取尾部
size_t num_marks_in_part = data_part->getMarksCount();
// 如果当前读到的行数小于这个part的总行数,那么意味着还没有读完,继续读取
if (!isCancelled() && current_row < data_part->rows_count)
{
// 获取当前Mark对应的可读的数据行数
size_t rows_to_read = data_part->index_granularity.getMarkRows(current_mark);
// 首个 mark 不需要"延续",之后的 mark 需告知 Reader "接着读",即如果current_mark=0,不存在接着读,而如果current_mark!=0,需要从前面读的位置接着读
bool continue_reading = (current_mark != 0);
// IMergeTreeReader 给出的 header(NamesAndTypesList);我的 case 中 sample 对应 [host String, tagGroup1.values Array(LowCardinality(String))]
const auto & sample = reader->getColumns();
Columns columns(sample.size()); // 构造需要读取的Column的Vector,即为每个请求的列分配槽位(初始全 nullptr), std::vector<ColumnPtr>;
// 使用IMergeTreeReader从指定的part读取指定行数的数据, 从 part 读取真实数据,填进 columns。
// 由于host在part中不存在,这一步只把 tagGroup1.values 读出来,host 保持 nullptr;返回值 rows_read 等于实际读到的行数
size_t rows_read = reader->readRows(current_mark, num_marks_in_part, continue_reading, rows_to_read, columns);
if (rows_read) // 如果的确读到了数据
{
// 填充诸如 _part, _part_index 的虚拟列(查 storage_snapshot->virtual_columns)。
fillBlockNumberColumns(columns, sample, data_part->info.min_block, current_row, rows_read);
reader->fillVirtualColumns(columns, rows_read);
// 更新 current_row、current_mark:推进游标,下一轮知道从哪继续。
current_row += rows_read; // 更新读取的总行数
current_mark += (rows_to_read == rows_read);
bool should_evaluate_missing_defaults = false;
reader->fillMissingColumns(columns, should_evaluate_missing_defaults, rows_read);从这里的调用可以看到,在通过一次 reader->readRows(...)完成了对一个granula的读取以后,ClickHouse会通过调用IMergeTreeReader::fillMissingColumns()把读不到的列位置(Columns &res_columns 中的 nullptr)填成"类型默认值"或标记为需执行 DEFAULT 表达式的列。
这里可以看到,如果在MergeTreeSequentialSource进行读取的时候遇到了缺列host,并且没有额外增加一列,那么这里reader->readRows(...)就读取不到任何的实际数据。在这种情况下,如果这个缺列的host有默认值表达式并且默认值表达式依赖其他列,那么,就根本无法进行默认值表达式的计算,因为没有行信息。
在我的场景里,这一轮要处理的列集是 [host, tagGroup1.values](上文讲过,这两个列是MergeTreeSequentialSource构造的时候生成的),但是实际上从Part中读到的只有第二项,所以, res_columns[0]为nullptr,所以,会将should_evaluate_missing_defaults设置为true,设置为true的含义是: 有些列并没有读取到,并且,这些里有默认值或者默认值表达式,需要后面(通过方法IMergeTreeReader::evaluateMissingDefault()进行计算)。
我们先看一下 IMergeTreeReader::fillMissingColumns的具体实现:
cpp
void IMergeTreeReader::fillMissingColumns(Columns & res_columns, bool & should_evaluate_missing_defaults, size_t num_rows) const
{
try
{
/**
* requested_columns
* 新增的 host(基列,有 DEFAULT),res_columns 对应位置是 nullptr,因为 part 里没这列。
* 子列 tagGroup1.values(Map 的 value),res_columns 对应位置是已读到的子列数据指针。
*/
NamesAndTypesList available_columns(columns_to_read.begin(), columns_to_read.end());
DB::fillMissingColumns(
res_columns, // 带出返回值
num_rows, // 总行数
Nested::convertToSubcolumns(requested_columns), // 请求的列
Nested::convertToSubcolumns(available_columns), // part中实际的column
partially_read_columns,
storage_snapshot->metadata);
// should_eval_defaults=true, cols=[host=null;tagGroup1.values(values)=set], partially_read=[]
// 只要res_columns中有任何一个Column是nullptr,那么 should_evaluate_missing_defaults = true
// 这里可以看到, res_columns的size就是请求的列的数量,但是有的位置会有nullptr
should_evaluate_missing_defaults = std::any_of(
res_columns.begin(), res_columns.end(), [](const auto & column) { return column == nullptr; });
}我们看一下 ,传入的参数如下:
Columns &res_columns:与requested_columns同顺序的列指针数组,本轮读到的列放在对应槽位:res_columns[0] == nullptr(host 缺失)、res_columns1 != nullptr(tagGroup1.values 有数据);bool &should_evaluate_missing_defaults:函数内只负责根据res_columns是否还有nullptr来设置这个标记;你这轮结束时因为 host 缺失 →should_evaluate_missing_defaults设为 true,上层会继续调用evaluateMissingDefaults()方法;size_t num_rows:本次reader->readRows实际读到的行数(rows_read),用于创建默认列时作为行数;Nested::convertToSubcolumns(requested_columns):把 reader 的请求列规范化成"可独立读取的子列"。我的 case 中仍是[host, tagGroup1.values];Nested::convertToSubcolumns(available_columns):available_columns来源于columns_to_read,代表当前 part 实际尝试读取的列;在我们这次调用里也是[host, tagGroup1.values],后者(tagGroup1.values)有数据,前者(host)没有;
可以看到, IMergeTreeReader::fillMissingColumns()的核心功能在自由方法DB::fillMissingColumns(...)中。
DB::fillMissingColumns(...)会在内部对res_columns进行修正和重新设置。当自由方法DB::fillMissingColumns(...)返回以后,IMergeTreeReader::fillMissingColumns()就根据res_columns中是否依然有nullptr位置来设置should_evaluate_missing_defaults:
cpp
should_evaluate_missing_defaults = std::any_of(
res_columns.begin(), res_columns.end(), [](const auto & column) { return column == nullptr; });DB::fillMissingColumns()中的默认值填充
简单类型的默认值填充处理
所以,补列的核心实现在自由方法void fillMissingColumns(...)中:
cpp
void fillMissingColumns(
Columns & res_columns, // res_columns = [nullptr, ColumnArray(...)] ,包含了host和tagGroup1.valuel两列
size_t num_rows, // fillMissingColumns 用它来在需要时创建"默认列"的行数, 比如,一列没有默认值,并且也在part中缺失,那么需要按照行数去构造对应的占位符,并设置"类型默认值"
const NamesAndTypesList & requested_columns, // [host String, tagGroup1.values MapValueSubcolumn],顺序和 res_columns 一一对应
const NamesAndTypesList & available_columns, // columns_to_read 由构造 IMergeTreeReader 时的 requested_columns 直接转换而来, 包含两项:host(虽然 part 里没有物理流,但仍按请求列记在 columns_to_read)以及 tagGroup1.values(真实从 part 读取的 Map value 子列)
const NameSet & partially_read_columns, // 在MergeTreeReaderWide::addStreams中被设置,主要是看这一列是否缺少stream
StorageMetadataPtr metadata_snapshot)
{
size_t num_columns = requested_columns.size();
.......
/// First, collect offset columns for all arrays in the block.
auto offsets_columns = collectOffsetsColumns(available_columns, res_columns);
/// Insert default values only for columns without default expressions.
auto requested_column = requested_columns.begin(); // 对于vertical merge,这里的requested_columns其实仅仅是当前正在进行merge的列,比如,当前的host和tagGroup1.values
for (size_t i = 0; i < num_columns; ++i, ++requested_column)
{
if (res_columns[i] && partially_read_columns.contains(requested_column->name))
res_columns[i] = nullptr; // 该列不为空却有 missing stream,那么就先把res_columns[i]置为nullptr,后面怎么补,下面负责,总之,目前为止,这一列不算有数据
/// Nothing to fill or default should be filled in evaluateMissingDefaults
/**
* 如果 hasDefault(metadata_snapshot, requested_column) 为 true,
* 直接 continue,不在 fillMissingColumns 内生成任何数据,保持 res_columns[i] 为 nullptr
* 目的:让 evaluateMissingDefaults 去按 DEFAULT 表达式计算,可能依赖其它列
*/
if (res_columns[i] || hasDefault(metadata_snapshot, *requested_column))
continue; // 如果 res_columns[i] 不为空(这一列在part中存在),或者,虽然不存在,但是有default值,那么直接跳过,因为下面可以进行处理
// 执行到这里,说明 res_columns[i] 为空,并且目前没有default值,那么在方法内部"就地"补上类型默认值
// 所以,tagGroup1不会执行到这里(因为它对应的res_columns[i]不是空),host也不在这里(因为它有默认值,会在evaluateMissingDefault中进行默认值评估)
std::vector<ColumnPtr> current_offsets;
size_t num_dimensions = 0;
const auto * array_type = typeid_cast<const DataTypeArray *>(requested_column->type.get());
if (array_type && !offsets_columns.empty()) // 只处理array类型
{
.. // 为这个复合列准备offset信息
}
/**
* 如果current_offsets不是空的(current_offsets.empty() != true)
* 这个多维(可能是一维)数组至少有一层是不缺失offset的
*/
if (!current_offsets.empty())
{
..// 为这个复合列构造数据
}
else
{ // 这个多维(可能是一维)数组(或者简单类型)全部的offset都缺失或者根本就是简单类型,因此没有offset(current_offsets.empty() == true),因此
// 直接基于类型默认值创建默认数据,
// 在当前 Block 的行数范围(num_rows)内生成一个默认列。对数组来说,"默认值"就是空数组,
// 所以它会给每一行放一个空数组,并不会再去额外生成"扁平元素"。换句话说,如果 offsets 全缺,只能得到"每行都是空数组"的列,而不是还原出元素个数;只有复用到共享 offsets 才能补出真正长度的数组结构。
res_columns[i] = createColumnWithDefaultValue(*requested_column->getTypeInStorage(), requested_column->getSubcolumnName(), num_rows);
}
}
}void fillMissingColumns(...)方法的具体过程是:
-
遍历所有"已读成功的列"(
res_columns[i] != nullptr),通过它们的ISerialization::enumerateStreams()收集ArraySizes类型的子流(如tagGroup1.size0)。 这里的动机是:当某个数组/Map 子列缺失时,我们必须用同一批 offsets 复建它的形状,否则补出来的列要么全是空数组,要么长度不等。collectOffsetsColumns()就是把已有列的 offsets 保存下来,供后续 Missing 列共享。cppauto offsets_columns = collectOffsetsColumns(available_columns, res_columns);这里会用来进行复合类型的默认值填充处理,我们在下文中会详细讲解。
-
遍历传入的待读取列(这里是
[host, tagGroup1.values])逐列决定是否补值、以及如何补值:cppfor (size_t i = 0; i < num_columns; ++i, ++requested_column) { if (res_columns[i] && partially_read_columns.contains(requested_column->name)) res_columns[i] = nullptr; // 对于确实了部分stream的列,在res_columns[i]中标记为空 /** * 如果 hasDefault(metadata_snapshot, requested_column) 为 true, * 直接 continue,不在 fillMissingColumns 内生成任何数据,保持 res_columns[i] 为 nullptr * 目的:让 evaluateMissingDefaults 去按 DEFAULT 表达式计算,可能依赖其它列 */ if (res_columns[i] || hasDefault(metadata_snapshot, *requested_column)) continue; // 不再这里补 // 需要补类型默认值 if (array_type && !offsets_columns.empty()) { ... // 收集这个请求列的当前可用的offset信息存放到current_offsets里面,后面会根据这个current_offsets进行默认值填充 } if (!current_offsets.empty()) { // 的确收集到了offset信息(当然,比如对于多层array,有可能只收集到上层,下层的的确丢失) } else { // 完全没能够为这个request_column收集到任何可用的offset,那么就完全平铺 } }这里的基本动机是:
-
如果
res_columns[i]非空,但该列被标记为partially_read(比如只读到了 Array 的offsets,没读 data),先把它清零,让后续的补列逻辑重新生成。cppif (res_columns[i] && partially_read_columns.contains(requested_column->name)) res_columns[i] = nullptr; // 只要该列不为空,并且有 missing stream,那么就先把res_columns[i]置为nullptr,但是这不是最终设置,后面会尝试进行类型默认值的推断这可以避免上层误以为 "这列已经完整",但是其实这一列的数据有问题,因此,在这里置为
nullptr,后面的逻辑就当这一列没有任何数据,然后进行处理(直接填充类型默认值,或者通过IMergeTreeReader::evaluateMissingDefaults()去计算)。 我们在讲构建子流的时候已经讲过,当一个列的流文件存在缺失(即使该列在part和表中存在),就会把这个列添加到partially_read_columns中; -
若现在槽位已有数据,或表结构里对这列有
DEFAULT/MATERIALIZED表达式,直接 continue。这里的动机是:- 如果有数据,就显然不用补;
- 如果有 DEFAULT,则留给后面的
IMergeTreeReader::evaluateMissingDefaults()去计算,因为 DEFAULT 可能依赖其它列,不能在这里拍脑袋生成。这里只负责简单的生成类型默认值而不是根据默认值表达式去计算默认值。
cppif (res_columns[i] || hasDefault(metadata_snapshot, *requested_column)) continue; // 如果 res_columns[i] 不为空(这一列在part中存在),或者,虽然不存在,但是有default值,那么直接返回我们看一下
hasDefault()方法的具体实现,非常清晰易懂:cppstatic bool hasDefault(const StorageMetadataPtr & metadata_snapshot, const NameAndTypePair & column) { if (!metadata_snapshot) return false; const auto & columns = metadata_snapshot->getColumns(); if (columns.has(column.name)) return columns.hasDefault(column.name); auto name_in_storage = column.getNameInStorage(); return columns.hasDefault(name_in_storage); }这个函数就是"给定 NameAndTypePair,看元数据里面它本身或者它的基列是否含有默认值或者默认值表达式:
- 如果当前就没有这张表的metadata,那么具体这个列的默认值就无从谈起,因此返回false;
- 然后,看看表的metadata中是否直接记录了这个列的元数据信息(比如,这个列本身就是一个基列),如果记录了,那么就判断这个列在表的定义中是否有默认值(表达式);
- 否则说明这是某个子列(比如
n.a.x),因此,先退回到这个子列对应的基列名column.getNameInStorage(),然后去查这个基列是否定义了默认值。这里的意思是,即使子列没有直接定义默认值,基列定义了默认值也可以。
-
只有当"既没有数据、也没有 DEFAULT"时,才会进入真正的填补逻辑,即"按类型默认值就地补齐"(区别按类型默认值补列 和按默认值表达式补列 )。
在为当前request_column处理完了offset信息以后,就可以为当前的request_column去构造数据了。- 假如的确是复合类型(
!current_offsets.empty()),那么就可以尝试去进行数据恢复了。 - 但是假如
current_offsets为空,可能是因为这个Array类型没有找到任何可用的offset,也可能是因为当前的类型就是一个简单类型而已,这时候就按照行数构造一个最简单的类型默认值.
cppif (!current_offsets.empty()){ // 这是复合类型的处理逻辑,我们下文会具体讲解 .... } else { res_columns[i] = createColumnWithDefaultValue( *requested_column->getTypeInStorage(), requested_column->getSubcolumnName(), num_rows); } - 假如的确是复合类型(
-
总之,自由函数 fillMissingColumns() 的外层函数(IMergeTreeReader::fillMissingColumns())只是一个壳;真正的补列逻辑在这个自由函数里完成。它的设计目标是:
- 对已有 DEFAULT 的列不做手脚,留给表达式引擎,因此这里先不做处理;
- 对没有 DEFAULT 的缺列,尽量复用共享 offsets,以结构一致的方式补全数据,补数据使用这个列的类型默认值;
- 在无法复用 offsets 时,至少根据
num_rows造出一个类型默认列,保证res_columns中不再出现"既缺数据又缺 DEFAULT"的 nullptr。在我们的具体 case 里,res_columns = [nullptr, ColumnArray(...)],host因为有 DEFAULT 被留到后面;tagGroup1.values早已读到数据,也被跳过。整段函数最终只是标记"仍需evaluateMissingDefaults",并保证一旦出现其它无 DEFAULT 的缺列,也能按上述逻辑补上。
NOTE: 对Mark和Bin的读取
我们需要准确理解ClickHouse在读取的过程中对Mark文件的使用:
我们从
MergeTreeSequentialSource::generate()方法中看到:
cppsize_t rows_to_read = data_part->index_granularity.getMarkRows(current_mark);
index_granularity是一个MergeTreeIndexGranularity对象,封装在IMergeTreeDataPart对象中,是 MergeTree Part 上的稀疏索引(mark)信息;每个 mark 覆盖一批连续的行,其大小由建表时的index_granularity设置(默认8192)和写入时的压缩/合并决定。
getMarkRows(current_mark)返回"当前 mark(用 current_mark 下标)还能提供多少行数据"。对大多数组集来说,每个 mark 覆盖8192行;如果遇到 part 尾巴或写入过程中 mark 被拆分,返回值可能更小 。
rows_to_read因此表示"这一轮从当前 mark 里最多读多少行"。reader->readRows()会尽量读满这批行数,如果正好读完一个 mark,就把current_mark加一,下一轮换到下一个granule继续读取。这是 ClickHouse 的存储/读取机制:通过 mark 把大文件切分成granule,只在需要时读取对应granule,避免对原始数据进行逐行扫描和读取。
所以,我们这里再回头看,为什么在读取host并且发现part中不存在这一列的时候,需要再添加一列存在的列作为参照呢?
问题的关键就在于default值的填充,因为default如果有表达式,那么表达式是根据当前这一行的其他列的值进行计算的:
- 如果从 part 里一列都没读到,
reader->readRows()返回的rows_read就是 0,Columns columns 里全部nullptr,接下来IMergeTreeReader::fillMissingColumns()和IMergeTreeReader::evaluateMissingDefaults()根本不知道要补多少行------num_rows 为 0,缺列只能补一堆空列,DEFAULT 也无处可算,最后这个 chunk 等同于"什么都没输出"。 - MergeTree 的读取链路是"照着实际读到的行数来补默认值"。哪怕请求列本身最终只是 DEFAULT,也需要一根真实的物理列来提供
rows_read(以及 Nested/Map 的 offsets),否则整个缺列填补流程不会启动,查询结果就是空。
复合类型的默认值填充处理
在第一次补默认值的过程中,对简单类型的处理相对好理解,上文已经讲过。
我们这里看看对复合类型的类型默认值补充。
从这个补充的过程,我们可以更加具体地看到对子流的枚举过程,更加具体的理解SubstreamData, Substream,ISubcolumnCreator, SubstreamPath等等。
但是,必须清楚地知道,在我们的异常事故中,Map列并没有缺失,所以这段逻辑在我们的事故中其实并没有发生。但是这段代码的理解有助于我们理解ClickHouse对子流的处理和遍历过程,因此我们还是具体讲解。
当 fillMissingColumns()遇到 Nested/Map/Array 这种复合列缺失时,不能随便补一堆"空数组",而必须保持和其余子列(其余子列指的是,同一 Nested/Map 结构下、已经成功读到或补出的其他字段)完全一致的结构------每一行的数组长度、每层嵌套的 offsets 都要匹配,否则同一 Nested 里的其它子列(或 Map 的 keys/values)就无法按行对齐,最终 evaluateMissingDefaults()、performRequiredConversions() 等阶段都会失去上下文,甚至直接崩溃。
比如: 即使 tagGroup1.values 这一列在某个 part 里缺失,我们在 fillMissingColumns() 里补出的就是它本身;但是补的时候必须用与 tagGroup1.keys 相同的 offsets,保持同一层结构的行数和数组长度一致。 "补出来的那一列" 是指用默认值生成的缺失列本身,而不是别的列。
举例:
tags Map(String,String)在磁盘上会拆成tags.keys,tags.values两个子列,和共享的共享的tags.size0offsets- 如果一个 part 里只读到了
tags.values,collectOffsetsColumns()仍会把tags.size0这条 offsets 流记录下来; - 当我们要补
tags.keys时,就可以把tags.size0拿来复用,保证 keys 和 values 对应的每行数组长度一致。 - 同理,一个
Nested(col Nested(a UInt64, b Array(String)))里的col.a、col.b也共享col.size0 offsets,填补缺列时必须用这份 offsets 才能保持结构一致。这就是"共享 offsets"的含义:同一 Nested/Map 下的兄弟子列共用同一套 array-size 流,缺失列复原时直接复用它,从而保证所有子列在行数和数组长度上保持一致。
为复合类型准备好offset信息
所以 DB::fillMissingColumns() 在发现某个复合列缺失时(注意,在我们的例子中,复合列并没有缺失,缺失的是简单列host),会尝试位这个复合列进行数据重建,这里,首先就需要对这个复合列对应的Substream进行遍历,以尽可能获取到这个复合列的完整的offset信息,有了复合列的每一层的offset信息,又有了每一层的默认值,那么就可以基于默认值来构造这个复合列了:
cpp
std::vector<ColumnPtr> current_offsets;
size_t num_dimensions = 0;
const auto * array_type = typeid_cast<const DataTypeArray *>(requested_column->type.get());
if (array_type && !offsets_columns.empty())
{
// 当前的缺失列是一个数组列
// 获取数组的维度,即,这是几维数组,比如 一维数组的num_dimensions=1,二维数组的num_dimensions=2
num_dimensions = getNumberOfDimensions(*array_type);
// current_offsets 的大小设置成这个array的dimension的大小,即 预留了每一维度的槽位
// 由于数组存在多维,有可能从顶向下并不是每一维度都缺失,比如,size0存在,但是size1和size2缺失,
// 因此,我们需要基于size0进行默认值补齐,下层由于缺失了size1和size2,因此只能通过默认值进行平铺补齐
current_offsets.resize(num_dimensions);
auto serialization = IDataType::getSerialization(*requested_column);
serialization->enumerateStreams([&](const auto & subpath)
{
// 遍历这个复合结构,收集所有可用的offset,放到current_offset中
......
});
// 对于数组的每一个维度,裁剪出从顶向下完整的offset数组
for (size_t j = 0; j < num_dimensions; ++j)
{
// 从第0层开始向下层遍历,如果多维数组里有某一层 offset 缺失,就把 current_offsets 缩短(截止)到那一层之前,避免使用不完整的 offsets。
// 一旦发现有一层是缺失的(current_offsets[j]==nullptr),就直接break
if (!current_offsets[j])
{
// 一旦发现有一层是缺失的(current_offsets[j]==nullptr),就直接break
current_offsets.resize(j);
break;
}
}具体流程如下所示:
-
先通过
collectOffsetsColumns(...)把当前 Block 里已经读到的Array/Nested/Map列的offsets(*.size0, *.size1 ...)收集起来,形成一个stream_name->ColumnUInt64的 map(offsets_columns)cpp// 构造对应的stream_name和IColumn的映射关系, 返回值是 std::unordered_map<String, ColumnPtr> // 这里会收集这个block中的所有array的offset column auto offsets_columns = collectOffsetsColumns(available_columns, res_columns);之后当某个同属同一嵌套结构的列缺失时,就能直接复用这份 offsets 而不是重新生成。 再用
ColumnArray::create(..., offsets)把默认值列包装回正确长度,保证补出来的列只是内容为空,结构完全相同。
collectOffsetsColumns()会把当前 Block 里已经读到的Array/Nested/Map列的offsets(*.size0, *.size1 ...)收集起来,形成一个stream_name -> offset(ColumnUInt64)的 map。之后当某个同属同一嵌套结构的列缺失时,就能直接复用这份offsets而不是重新生成 -
然后,开始对缺失的数组列的重建做准备,这里准备的,是offset信息, 即一个存放了
COW<IColumn>的数组:cppusing ColumnPtr = COW<IColumn>::Ptr; // ColumnPtr其实就是一个COW<IColumn> ..... std::vector<ColumnPtr> current_offsets;我在另外一篇文章中会详细讲解基于
CRTP(Curiously Recurring Template Pattern)对IColumn的扩展和相关动机,这里直接忽略其细节,总之,current_offsets就是一个存放了IColumn信息的数组。-
找到还能重用的offset。这里的还能重用,肯定指的是还能被当前的请求列重用的
offset,比如,当前的请求列是[host, tagGroup1.values],那么就寻找还还能被tagGroup1.values重用的offset,即tagGroup1.size0 -
array_type判定缺失列是否为DataTypeArray;没有的话就没必要看 offsets,因为我们只处理Array复合类型的、基于共享offset的默认值填充:cppif (array_type && !offsets_columns.empty()) { .... } -
算一下这个数组嵌套了多少层(层指的就是dimension,比如,嵌套数据的
dimensionArray(Array(...))会大于 1),然后创建一个current_offsets数组,数组的大小等于计算出来的Array的层数(dimension数量),这样current_offsets会给每层预留一个slot,但是后面会讲,current_offsets目前只是根据数据的定义预留了槽位,但是具体的槽位是否真的有offset数据,还需要根据刚刚根据collectOffsetsColumns(...)收集的offset信息来决定:cpp// 当前的缺失列是一个数组列 // 获取数组的维度,即,这是几维数组,比如 一维数组的num_dimensions=1,二维数组的num_dimensions=2 num_dimensions = getNumberOfDimensions(*array_type); // current_offsets 的大小设置成这个array的dimension的大小,即 预留了每一维度的槽位 // 由于数组存在多维,有可能从顶向下并不是每一维度都缺失,比如,size0存在,但是size1和size2缺失, // 因此,我们需要基于size0进行默认值补齐,下层由于缺失了size1和size2,因此只能通过默认值进行平铺补齐 current_offsets.resize(num_dimensions); -
遍历这个列的所有子流(
SubstreamPath),我们只关心Substream::ArraySizes(即*.size0/size1...那些 offsets 流)。对于每一层的ArraySizes(size0, size1...),先算出处于哪一层,再拼出物理流名ISerialization::getFileNameForStream(...),去offsets_columns(之前收集自所有可用列的 offsets map)里找是否有这条 offsets。找到就记到current_offsets[level],代表这一层的offest信息未缺失。这样我们就知道这一层能用别的列共享的 offsets 来填补cppserialization->enumerateStreams([&](const auto & subpath) { // 取出这个SubstreamPath(记住,SubstreamPath是一个Vector<Substream>)的最后的一个Substream // 遍历这个数组序列化下所有子流,筛选出只要 ArraySizes(即 *.size0/size1...)的流 if (subpath.empty() || subpath.back().type != ISerialization::Substream::ArraySizes) return; // ArraySizes说明这是一个数组子流,先获取这个数组的层级 size_t level = ISerialization::getArrayLevel(subpath); /// It can happen if element of Array is Map. if (level >= num_dimensions) return; // // 拼出真实的 stream 名,比如, tagGroup1.size0、tagGroup1.values.size0 等 auto stream_name = ISerialization::getFileNameForStream(*requested_column, subpath); auto it = offsets_columns.find(stream_name); // offsets_columns中已经存放了available_columns中每一个类型为ArraySizes的stream_name的IColumn信息 // 如果找到了,就把对应的 ColumnUInt64 指针放到 current_offsets[level],level 由 ISerialization::getArrayLevel 给出。 if (it != offsets_columns.end()) current_offsets[level] = it->second; // current_offsets[level]保存了对应的ColumnPtr });- 我们上文已经讲过子流的遍历和callback的定义,callback只会对落地的Substream上被调用,比如
ArraySizes(SerializationArray::enumerateStreams()),Substream::DictionaryIndexes(SerializationLowCardinality::enumereateStreams())等,而对于不落地的Substream不会调用,比如ArrayElements(SerializationArray::enumerateStreams()),Substream::DictionaryKeys(SerializationLowCardinality::enumereateStreams()); - 并且,在调用的时候,我们只可以定义一个
callback(),不可以针对每一个Substream各自定义不同的callback(),因此在callbak function内部,需要自己完成逻辑,比如,只处理自己关心的Substream。比如,上面定义的callback,只关心Substream::ArraySizes;
- 我们上文已经讲过子流的遍历和callback的定义,callback只会对落地的Substream上被调用,比如
-
-
在通过
enumerateStreams()并将有offset信息的stream放到了current_offset中以后,我们需要检查此时current_offset的数据连续性,因为可能比如在多维数组中,level=0和level=2的offset存在,但是level=1的offset是缺失的。因为,外层(上层,比如level = 0) offsets 必须从最顶层连续存在才能使用;一旦中间某层(current_offsets[j] == nullptr)缺失(level = 1),就说明从这一层往下(level >= 1)全都无法依赖共享offsets了,只能后续用默认值去平铺补齐。所以,在得到了最长连续前缀 以后,我们就将current_offsets压缩到最长连续前缀的长度,后面的不连续部分直接抛弃,无法使用:cpp// 对于数组的每一个维度,这里的遍历是从上层维度遍历到下层维度 for (size_t j = 0; j < num_dimensions; ++j) { // 从第0层开始向下层遍历,如果多维数组里有某一层 offset 缺失,就把 current_offsets 缩短(截止)到那一层之前,避免使用不完整的 offsets。 // 一旦发现有一层是缺失的(current_offsets[j]==nullptr),就直接break if (!current_offsets[j]) { // 一旦发现有一层是缺失的(current_offsets[j]==nullptr),就直接break current_offsets.resize(j); break; } }下图的4种case显示了
current_offset在各种不同的dimension缺失的情况下,截取以后获取的最终offset结果:text------------------------------------------------------ case 1: 所有dimension的offset均存在 ------- current_offsets(初始收集到): index: 0 1 2 ┌───────┐ ┌──────┐ ┌──────┐ value: │ null │ │ off1 │ │ off2 │ └───────┘ └──────┘ └──────┘ 扫描 j=0..2: - j=0 是 null ❌ => resize(0) 截断后: current_offsets = [] (空) ------------------------------------------------------ case 2: 中间某个dimension的offset不存在 ------- current_offsets(初始收集到的结果): index: 0 1 2 ┌──────┐ ┌───────┐ ┌──────┐ value: │ off0 │ │ null │ │ off2 │ └──────┘ └───────┘ └──────┘ 扫描 j=0..2: - j=0 有 off0 ✅ - j=1 是 null ❌ => 立刻截断:resize(1) 截断后(只保留最长连续前缀): index: 0 ┌──────┐ value: │ off0 │ └──────┘ 解释: - 因为少了 level1 的 offsets,你就无法用 off2 正确表达"内层数组"的行边界; - 仅靠 off0 只能恢复最外层一维数组的边界; - 更内层(从 level1 开始)只能退化为"用默认值平铺/空数组"等方式补齐。 ------------------------------------------------------ case 3: 后面的某个dimension的offset不存在 ------- current_offsets(初始收集到): index: 0 1 2 ┌──────┐ ┌──────┐ ┌───────┐ value: │ off0 │ │ off1 │ │ null │ └──────┘ └──────┘ └───────┘ 扫描 j=0..2: - j=0 ✅ - j=1 ✅ - j=2 ❌ => resize(2) 截断后: index: 0 1 ┌──────┐ ┌──────┐ value: │ off0 │ │ off1 │ └──────┘ └──────┘ 解释: - 你至少还能正确恢复到 2 维结构(level0 和 level1 的边界); - 但更深层(level2)开始就只能退化补齐。 ------------------------------------------------------ case 4: 第一个dimension的offset不存在,剩下的都存在 ------- current_offsets(初始收集到): index: 0 1 2 ┌───────┐ ┌──────┐ ┌──────┐ value: │ null │ │ off1 │ │ off2 │ └───────┘ └──────┘ └──────┘ 扫描 j=0..2: - j=0 是 null ❌ => resize(0) 截断后: current_offsets = [] (空) 解释: - 最外层 offsets(level0)都没有,说明你连"每一行外层数组长度是多少"都不知道; - 那就无法用 offsets 方式构造结构,只能走退化路径:按 num_rows 生成默认值(例如每行空数组)。 -
如果在抛弃了不连续部分以后,这个
current_offset依然不是空的,说明这个多维数组从顶向下至少有一层是不缺失offset的,因此默认值的填充和结构的补齐至少可以在从顶层截止到这一层进行,至于这一层的下面的更多层,只能平铺补齐(下文会举例子说明什么是平铺和扁平)。因此,开始基于
current_offset进行缺失数组列的重建。
基于复合类型的offset信息和类型默认值进行数据重建
所以,到了这里,我们已经获取了current_offset信息,它经过上文描述的裁剪,此时记录了从顶向下连续的offset信息。下面,就开始根据这个offset信息进行数据重建了
cpp
if (!current_offsets.empty())
{
Names tuple_elements; // std::vector<std::string>
auto serialization = IDataType::getSerialization(*requested_column);
/// For Nested columns collect names of tuple elements and skip them while getting the base type of array.
// 把 tuple 元素的名字(如 keys/values)收集起来,后面计算 base type 时要去掉它们。
// 搜索 IDataType::forEachSubcolumn
IDataType::forEachSubcolumn([&](const auto & path, const auto &, const auto &)
{
// 如果当前的SubstreamPath(记住,SubstreamPath是一个Vector<Substream>)的最后的一个Substream是一个TupleElement
// 比如,一个Map<String, String>在递归的时候就是
if (path.back().type == ISerialization::Substream::TupleElement)
tuple_elements.push_back(path.back().name_of_substream); // 收集所有的tuple_elements
}, ISerialization::SubstreamData(serialization));
/// The number of dimensions that belongs to the array itself but not shared in Nested column.
/// For example for column "n Nested(a UInt64, b Array(UInt64))" this value is 0 for `n.a` and 1 for `n.b`.
// 计算一下这个数组还有几层是空的,num_dimensions是预期的dimension数量,current_offsets是实际有的dimension的数量
size_t num_empty_dimensions = num_dimensions - current_offsets.size();
// 找出真正的元素类型(Map value/keys),比如, Array(Array(String)) 的基础数据类型是String
auto base_type = getBaseTypeOfArray(requested_column->getTypeInStorage(), tuple_elements);
// 如果还有空dimension(num_empty_dimensions > 0),就为底层这些缺失的Array继续包一层 Array,Array的元素类型是base_type
auto scalar_type = createArrayOfType(base_type, num_empty_dimensions);
// current_offsets.back() 存的是最内层 offsets(一个 ColumnUInt64),它的最后一个值就是扁平数据列的元素总数。
// 我们据此创建一个长度为 data_size 的"扁平默认列"------所有元素都是类型默认值,但数量和真实列完全匹配。
size_t data_size = assert_cast<const ColumnUInt64 &>(*current_offsets.back()).getData().back();
/// Remove names of tuple elements because they are already processed by 'getBaseTypeOfArray'.
auto subcolumn_name = removeTupleElementsFromSubcolumn(requested_column->getSubcolumnName(), tuple_elements);
res_columns[i] = createColumnWithDefaultValue(*scalar_type, subcolumn_name, data_size);
// 这里的 *it 从尾部元素开始,逐个到开头
// current_offsets 存的是每个维度对应的 offsets 列(ColumnUInt64)。rbegin() 先拿最深层(比如 Map 元素层),
// 把基础列用 ColumnArray::create(data_column, offsets) 包裹起来,得到一个 ColumnArray。
for (auto it = current_offsets.rbegin(); it != current_offsets.rend(); ++it)
res_columns[i] = ColumnArray::create(res_columns[i], *it); // 从后往前,直到使用current_offsets[0]拼接出res_columns
}具体过程如下:
-
首先获取对应的
requested_columns的序列化器,一个ISerialization对象:cppauto serialization = IDataType::getSerialization(*requested_column);我们这里必须注意,这里获取的是对应子列requested_column的序列化器,而不是子列所对应的存储列(父列,storage_in_column)的序列化器。 。我们可以通过详细分析
IDataType::getSerialization的代码获得:cpp// static SerializationPtr IDataType::getSerialization(const NameAndTypePair & column) { if (column.isSubcolumn()) { const auto & type_in_storage = column.getTypeInStorage(); auto serialization = type_in_storage->getDefaultSerialization(); return type_in_storage->getSubcolumnSerialization(column.getSubcolumnName(), serialization); } return column.type->getDefaultSerialization(); }可以看到,这里的
IDataType::getSerialization()方法,先拿基列type_in_storage的默认序列化,再调用type_in_storage->getSubcolumnSerialization(subcolumn_name, serialization)沿子列路径下沉,返回的对象只描述那条子列(例如 n.a.x)的流结构,不再包含兄弟分支比如n.b, n.b.y 。了解清楚这里得到的
ISerialization的层级,才能知道下面基于这个ISerialization调用forEachSubcolumn()方法的时候,底层进行enumerateStreams()的方法的时候,是从哪个Substream开始的。 -
通过
forEachSubcolumn()来收集tuple_elements:这里实际上从requested_column的ISerialization对象,遍历所有SubstreamPath,把类型为TupleElement的substream名字都记录下来:cppIDataType::forEachSubcolumn([&](const auto & path, const auto &, const auto &) { // 如果当前的SubstreamPath(记住,SubstreamPath是一个Vector<Substream>)的最后的一个Substream是一个TupleElement // 比如,一个Map<String, String>在递归的时候就是 if (path.back().type == ISerialization::Substream::TupleElement) tuple_elements.push_back(path.back().name_of_substream); // 收集所有的tuple_elements }, ISerialization::SubstreamData(serialization));我们下文会详细讲解
IDataType::forEachSubcolumn(...)方法的执行细节。这里不做赘述。主要需要注意,这里的serialization所在的层级,是当前的请求列
requested_column所在的基列对应的层级,而不是request_column本身的层级。比如,请求列是tags.values,那么对应的serialization是这个tags Map(String, String)所在的层级:总之,举一个简单例子:表中有一个复合列
tags Map(String, Tuple(x UInt64, y UInt64)), 而对应的请求列是tags.values.x:- 首先通过
IDataType::getSerialization()获取tags.values.x的对应的序列化器: forEachSubcolumn()遍历这列的存储结构时,会按路径顺序遇到TupleElement:- 走到
ArrayElements→TupleElement("keys"),把 "keys" 加入tuple_elements; - 同一层还有
TupleElement("values"),继续加 "values"; - 进入 value 的类型
Tuple(x, y)后,又依次遇到TupleElement("x")、TupleElement("y"),列表变成["keys", "values", "x", "y"]。
- 走到
- 首先通过
-
计算需要用类型默认值去填补的维度个数:
cpp// 计算一下这个数组还有几层是空的,num_dimensions是预期的dimension数量,current_offsets是实际有的dimension的数量 size_t num_empty_dimensions = num_dimensions - current_offsets.size();这里,计算
num_empty_dimensions对后面进行补默认数据的作用是:- 我知道,现在剩下的
num_empty_dimensions是2, 即缺了2个维度,这两个维度一定是从最底层往上层数,两个维度 - 我知道,这剩下的2个维度的数据量是
1000条数据 - 我不知道,这2个维度的具体结构,比如,这缺失的2个dimension的结构可能是
40 * 50,也可能是50 * 40,但是由于数据丢失,这个具体结构根本无从得知 - 所以,基于
num_empty_dimensions和总的数据条数,我就构造一个扁平的下层结构,只确保维度数量和数据总条数正确,具体结构就随意做(具体结构是什么,需要参考createArrayOfType()方法和createColumnWithDefaultValue()方法)
- 我知道,现在剩下的
-
获取这个复合结构的真正的数据类型,即剥掉所有数组/tuple/nested 外壳后得到真正的底层元素类型(例:Map 的 keys 是 String)。
cpp// 找出真正的元素类型(Map value/keys),比如, Array(Array(String)) 的基础数据类型是String auto base_type = getBaseTypeOfArray(requested_column->getTypeInStorage(), tuple_elements);getBaseTypeOfArray()方法基于提供的目前的上层类型type,对tuple_elements数组进行遍历,直到找到一个不是Array/Tuple 的基础元素,然后返回这个基础元素的数据类型。cppDataTypePtr getBaseTypeOfArray(DataTypePtr type, const Names & tuple_elements) { auto it = tuple_elements.begin(); while (true) { if (const auto * type_array = typeid_cast<const DataTypeArray *>(type.get())) { type = type_array->getNestedType(); // 获取Array的嵌套类型,有可能是String(比如Array(String)), Tuple(比如Map, Nested) } else if (const auto * type_tuple = typeid_cast<const DataTypeTuple *>(type.get())) // 当前的类型是一个Tuple,那么看看当前的element在这个tuple中的什么位置 { if (it == tuple_elements.end()) // 已经全部遍历完成了 break; // it是当前正在处理的element,在上一个type(类型一定是Tuple)中查找当前的element auto pos = type_tuple->tryGetPositionByName(*it); if (!pos) // 在当前的tuple中没有找到这个element break; // 退出循环,使用当前已经找到的type // 在type(类型一定是Tuple)中找到了当前的element ++it; // 准备处理下一个element type = type_tuple->getElement(*pos); // 将当前的type更新为这个Tuple中这个element所对应的类型 } else // 如果既不是Array,也不是Tuple,那么break,使用刚刚设置的Type。所以,这里的逻辑是,只要递归到了非Array/Tuple 的类型,就可以返回了 { break; } } return type; } -
为底层缺失的Array创建数据数组,即如果缺了 N 个维度,就把
base_type向外包 N 层 Array,这样我们接下来创建的"扁平列"结构与实际缺失部分一致。但是,此时还没有定下来数据的行数,只是所创建的数组的维度确定下来了:cpp// 如果还有空dimension(num_empty_dimensions > 0),就为底层这些缺失的Array继续包一层 Array,Array的元素类型是base_type auto scalar_type = createArrayOfType(base_type, num_empty_dimensions);比如,列类型
Array(Array(String)),只找到了最外层 offsets(current_offsets.size()==1),那么缺失的维度数量是num_empty_dimensions=1,scalar_type 就是Array(String)------这正是内层需要补齐的形状。 -
删除掉
tuple_elements前缀:cpp/// Remove names of tuple elements because they are already processed by 'getBaseTypeOfArray'. auto subcolumn_name = removeTupleElementsFromSubcolumn(requested_column->getSubcolumnName(), tuple_elements);这里相对不好理解。这里的动机是,由于
scalar_type是为了缺失的维度num_empty_dimensions所创建的默认扁平数组,维度的缺失和数组的扁平,我们需要从当前的请求列中删掉tuple_elements,保证列的名字和当前基于缺失维度创建的扁平数组所在的层级一致。cppif (!current_offsets.empty()) { ... // 收集 tuple 元素名称、计算空维度 // 计算一下这个数组还有几层是空的,num_dimensions是预期的dimension数量,current_offsets是实际有的dimension的数量 size_t num_empty_dimensions = num_dimensions - current_offsets.size(); // 找出真正的元素类型(Map value/keys),比如, Array(Array(String)) 的基础数据类型是String auto base_type = getBaseTypeOfArray(requested_column->getTypeInStorage(), tuple_elements); // 如果还有空dimension(num_empty_dimensions > 0),就为底层这些缺失的Array继续包一层 Array,Array的元素类型是base_type auto scalar_type = createArrayOfType(base_type, num_empty_dimensions); // current_offsets.back() 存的是最内层 offsets(一个 ColumnUInt64),它的最后一个值就是扁平数据列的元素总数。 // 我们据此创建一个长度为 data_size 的"扁平默认列"------所有元素都是类型默认值,但数量和真实列完全匹配。 size_t data_size = assert_cast<const ColumnUInt64 &>(*current_offsets.back()).getData().back(); /// Remove names of tuple elements because they are already processed by 'getBaseTypeOfArray'. auto subcolumn_name = removeTupleElementsFromSubcolumn(requested_column->getSubcolumnName(), tuple_elements); res_columns[i] = createColumnWithDefaultValue(*scalar_type, subcolumn_name, data_size); // 这里的 *it 从尾部元素开始,逐个到开头 // current_offsets 存的是每个维度对应的 offsets 列(ColumnUInt64)。rbegin() 先拿最深层(比如 Map 元素层), // 把基础列用 ColumnArray::create(data_column, offsets) 包裹起来,得到一个 ColumnArray。 for (auto it = current_offsets.rbegin(); it != current_offsets.rend(); ++it) res_columns[i] = ColumnArray::create(res_columns[i], *it); // 从后往前,直到使用current_offsets[0]拼接出res_columns }- 先从
current_offsets.back()拿到总元素数 data_size,据此创建长度匹配的基础列(scalar_type),填充默认值。 - 之后从内向外把基础列包裹成 ColumnArray,每一层都使用共享 offsets,最终得到结构正确、但内容为类型默认值的数组/Map 子列。
- 动机:这样补出来的列行数、数组长度都与真实列一致,上游可以无缝拼接。
- 先从
IDataType::forEachSubcolumn()收集获取所有的subcolumn列
上文讲过,fillMissingColumns()会通过方法IDataType::forEachSubcolumn()来收集出TupleElement列。我们可以这样简单理解这个收集出来的TupleElement的作用:
tuple_elements中存放了在路径上所有TupleElement名的名字的列表;- 后面,
removeTupleElementsFromSubcolumn()会把这些名字逐个从subcolumn_name中删掉(每次都连同后面的 . 一起删除)
IDataType::forEachSubcolumn()方法
cpp
/**
* 在void fillMissingColumns 中被调用
*/
void IDataType::forEachSubcolumn(
const SubcolumnCallback & callback, // 这个callback会封装在进行substream遍历的callback中
const SubstreamData & data) // 传入的是这个Substream的数据SubstreamData
{
// 这里的callback_with_data是enumerateStreams的回调,在回调的时候,传入当前的subpath。
// 在对树进行遍历的过程中,subpath 被不断插入当前节点
ISerialization::StreamCallback callback_with_data = [&](const auto & subpath)
{
/**
* for 循环逐层检查 subpath 的前缀(prefix_len = i+1)。
* 如果这一段路径代表一个"可以单独访问的子列"(hasSubcolumnForPath(...) 返回 true)且之前还没处理过(!visited),就生成子列名、子列数据
* 然后把 path_copy(截止到这个前缀的子路径)连同 name/subdata 交给用户回调。
*/
for (size_t i = 0; i < subpath.size(); ++i)
{
size_t prefix_len = i + 1; // prefix_len从1开始
// 如果这个subpath在prefix_len的位置还有子列,那么会调用callback对这个subpath的subdata
// 即第一次遇到这个子流的时候,调用用户提供的SubcolumnCallback
if (!subpath[i].visited && ISerialization::hasSubcolumnForPath(subpath, prefix_len))
{
// subpath[prefix_len - 1]是一个独立子列,因此,获取subpath[prefix_len-1]位置的column
auto name = ISerialization::getSubcolumnNameForStream(subpath, prefix_len);
auto subdata = ISerialization::createFromPath(subpath, prefix_len);
auto path_copy = subpath;
path_copy.resize(prefix_len); // 截取掉prefix_len的后面,只需要从root到prefix_len截止的部分
/**
* 这里的callback是通过参数传入进来的,定义如下:
* if (path.back().type == ISerialization::Substream::TupleElement)
tuple_elements.push_back(path.back().name_of_substream); // 收集所有的tuple_elements
*/
callback(path_copy, name, subdata);
}
subpath[i].visited = true;
}
};
ISerialization::EnumerateStreamsSettings settings;
settings.position_independent_encoding = false;
// 对于这个SubstreamData,使用callback_with_data回调进行遍历
data.serialization->enumerateStreams(settings, callback_with_data, data);
}IDataType::forEachSubcolumn()方法会被传入一个 SubcolumnCallback (注意,这里的SubcolumnCallback不是用来进行ISerialization::enumerateStreams(...)的StreamCallback和 SubstreamData(描述当前类型/列/序列化器)。它的目的是遍历该类型的全部子流,把"每个可单独访问的子列"包装对应的SubstreamData和Name交给 StreamCallback callback_with_data进行处理
然后,其具体执行步骤为:
-
内部首先设置
SubstreamCallback callback_with_data,这是传给ISerialization::enumerateStreams(...)的回调。每当序列化器通过ISerialization::enumerateStreams()递归到某个节点时,就会给我们一个SubstreamPath subpath(std::vector<ISerialization::Substream>,按层级记录路径)。我们逐层看这个路径:-
prefix_len = i + 1表示"从根到第 i 层"的前缀,通过调用hasSubcolumnForPath(subpath, prefix_len)(下文会详细讲解) 判断这条前缀是否代表一个可单独取出的子列(例如TupleElement、ArraySizes,DictionaryIndexes等都是可以单独访问的子列,而不是从某一个Serialization到下一层Serialization的过渡列比如ArrayElements,DictionaryKeys等),cppISerialization::StreamCallback callback_with_data = [&](const auto & subpath) { /** * for 循环逐层检查 subpath 的前缀(prefix_len = i+1)。 * 如果这一段路径代表一个"可以单独访问的子列"(hasSubcolumnForPath(...) 返回 true)且之前还没处理过(!visited),就生成子列名、子列数据 * 然后把 path_copy(截止到这个前缀的子路径)连同 name/subdata 交给用户回调。 */ for (size_t i = 0; i < subpath.size(); ++i) { size_t prefix_len = i + 1; // prefix_len从1开始 // 如果这个subpath在prefix_len的位置还有子列,那么会调用callback对这个subpath的subdata // 即第一次遇到这个子流的时候,调用用户提供的SubcolumnCallback if (!subpath[i].visited && ISerialization::hasSubcolumnForPath(subpath, prefix_len)) { ... callback(path_copy, name, subdata); } subpath[i].visited = true; // 只要访问过这个节点,无论是不是hasSubcolumnForPath(),都不再访问 } }; -
必须注意到这里的一个问题,那就是
callback_with_data本身就是一个基于递归的回调,但是,在每一个回调里面,还会有一个for循环来遍历当前递归的整个路径。这就好像我们在递归遍历一个二叉树的时候,每访问到一个节点,都把根节点到这个节点的路径给访问一遍。所以,即使fillMissingColumns()中调用IDataType::forEachSubcolumn()的时候传入的ISerialization是n.a.x,但是由于这个callbak中会对当前的SubstreamPath(vector<Substream>)进行遍历,因此,比如,当前enumerateStreams()的路径是ArrayElements → TupleElement("a") → ArrayElements → TupleElement("x"),那么for循环会遍历整个路径以收集TupleElement,从而,尽管在调用IDataType::forEachSubcolumn()的时候传入的ISerialization是n.a.x,但是TupleElement("a")也会被收集到。 -
subpath[i].visited用来保证同一个路径节点Substream只处理一次,如果第一次遇到一个可访问的子列且该子列没有被处理过,那么就会:-
生成对应的子列名(例:
tags.keys、tags.size0); -
根据当前的
SubstreamPath路径推导出这段子列自己的SubstreamData(类型、列、序列化器等):cpp// subpath[prefix_len - 1]是一个独立子列,因此,获取subpath[prefix_len-1]位置的column auto name = ISerialization::getSubcolumnNameForStream(subpath, prefix_len); auto subdata = ISerialization::createFromPath(subpath, prefix_len); -
调用外层传进来的
SubcolumnCallback callback(path_copy, name, subdata)。结合fillMissingColumns(...)的代码细节,它在调用forEachSubcolumn()时所传入的回调,是判断这个SubstreamPath的最后一个Substream对应的类型是否是TupleElement。如果的确是TupleElement,就收集名字"。cppcallback(path_copy, name, subdata);cpp// 把 tuple 元素的名字(如 keys/values)收集起来,后面计算 base type 时要去掉它们。 // 搜索 IDataType::forEachSubcolumn IDataType::forEachSubcolumn([&](const auto & path, const auto &, const auto &) { // 如果当前的SubstreamPath(记住,SubstreamPath是一个Vector<Substream>)的最后的一个Substream是一个TupleElement // 比如,一个Map<String, String>在递归的时候就是 if (path.back().type == ISerialization::Substream::TupleElement) tuple_elements.push_back(path.back().name_of_substream); // 收集所有的tuple_elements }, ISerialization::SubstreamData(serialization));可以看到,通过回调的方式,整个过程不用自己写遍历逻辑,遍历逻辑交给对应的
ISerialization::enumerateStreams()方法,调用者只需要定义想对哪些子列做什么。所以,forEachSubcolumn()方法中定义的SubstreamCallback 会帮我们根据SubstreamPath识别、生成对应的SubstreamData,确保拿到正确的类型/列信息。
-
-
无论是否触发
SubcolumnCallback,都把当前位置标记为visited,避免同一路径多次触发:cppsubpath[i].visited = true;
-
-
在定义了
SubstreamCallback callback_with_data以后,开始使用这个SubstreamCallback callback_with_data来递归遍整个类型的子流,从而在遍历的过程中触发SubstreamCallback callback_with_data。cpp// 对于这个SubstreamData,使用callback_with_data回调进行遍历 data.serialization->enumerateStreams(settings, callback_with_data, data);
举例说明:
-
假设
tagGroup1是Map(String, String),底层存储等价于Array(Tuple(keys String, values String)),其SubstreamPath的结构如下所示:texttagGroup1 : Map(String, String) | `-- (Map -> nested serialization) = Array(Tuple(keys String, values String)) | +-- Full Path = [ArraySizes(level=0)] | Subcolumn name: tagGroup1.size0 | Data: ColumnUInt64 (offsets) | `-- Full Path = [ArrayElements(level=0)] | +-- Full Path = [ArrayElements(level=0), TupleElement("keys")] | Subcolumn name: tagGroup1.keys | Data: ColumnString (keys) | `-- Full Path = [ArrayElements(level=0), TupleElement("values")] Subcolumn name: tagGroup1.values Data: ColumnString (values) -
调用
IDataType::forEachSubcolumn()时,顶层的SubstreamData包含:serialization = SerializationMap、type = DataTypeMap、column = ColumnMap(如果有的话)。
在IDataType::forEachSubcolumn()中,最开始会通过ISerializationMap::enumerateStreams()进行调用,最初,subpath的值会按照下面的顺序依次出现:- 首先出现的是
[{ArraySizes(level=0)}], 它表示tagGroup1.size0这个SubstreamPath。 针对这个Substream,hasSubcolumnForPath()返回 true,表示,于是 callback 得到(path=['ArraySizes'], name='tagGroup1.size0', subdata=<UInt64 offsets>)。- 但是由于我们在
callback_with_data中传入的SubcolumnCallback callback其实只关心TupleElement,因此这里会忽略这个[{ArraySizes(level=0)}]
- 但是由于我们在
- 然后,
ISerializationMap::enumerateStreams()会在TupleSerializationMap::enumerateStreams()中产生[{ArrayElements(level=0)}, {TupleElement(name="keys")}],这时候,hasSubcolumnForPath()会返回True,把路径裁剪成ArrayElements → TupleElement(keys),生成name='tagGroup1.keys',SubstreamData subdata的type=String、serialization=SerializationString、column=ColumnStringKeys。 - 同理
[{ArrayElements}, {TupleElement(values)}]→ 回调(path=..., name='tagGroup1.values', subdata=<String values>)
- 首先出现的是
-
forEachSubcolumn()就是在这次遍历中,把tagGroup1的每个"独立子列"都一次性交给用户定义的 callback。用户可以在 callback 里对特定类型做操作,比如收集 keys/values 的名字、获取 size0 的 offsets 等,无需自己手写遍历逻辑。
必须准确理解 ISerialization::hasSubcolumnForPath()方法。它的方法名字中极易造成歧义。
它的准确含义是: 以这段 SubstreamPath(Vector(Substream)) 前缀为界,目前能不能把它视作一个对外可访问的子列?",也就是,它有没有对应的 subcolumn,可以单独命名、读取或写入?该方法返回一个bool值,表示有或者没有。
在 ISerialization::enumerateStreams() 时,每到一个节点都会往 SubstreamPath(Vector(Substream)) 里 push Substream(ArraySizes、ArrayElements、TupleElement、NullableElements ....)。但这些Substream不是每种节点都对应一个实际的"Subcolumn":
- 有与之对应的subcolumn的那些Substream举例:
ArraySizes:对应 col.size0/size1... 的 offsets 列,独立落盘,需要单独读写,它会落盘位实际的.bin和.mrk2文件。TupleElement(name):Tuple/Map/Nested 的某个字段(如 tags.keys),它有自己的类型、列和序列化逻辑,可以独立访问,它会落盘位实际的.bin和.mrk2文件。NullMap、VariantDiscriminators等类似结构,同理。
- 没有与之对应的subcolumn的那些
Substream举例:- ArrayElements:只是"进入数组元素"的路径标记,真正的列在下一层(
TupleElement或叶子类型)才出现。详细原理我们可以查看SerializationArray::enumerateStreams(...)->SerializationTuple::enumerateStreams(...)->SerializationNamed::enumerateStreams(...)的执行逻辑。 NullableElements:仅表示"剥掉Nullable包装";只有NullMap那层才算子列。
所以,没有对应subcolumn的那些Substream,指的是一些内部辅助路径(如 Regular、VariantElement 的中间节点)只有结构意义,不对应实际的存储流。
- ArrayElements:只是"进入数组元素"的路径标记,真正的列在下一层(
所以,从下面的ISerialization::hasSubcolumnForPath()实现可以看到,该方法只是判断"到目前为止的路径前缀"是不是一个对外可访问的子列,而不是一个在enumerateStreams()过程中的一个过渡列。
prefix_len 表示我们截取 path 的前 prefix_len 个节点,如果这段路径的最后一个节点是某些特定类型(有对应的subcolumn),就返回 true。
cpp
bool ISerialization::hasSubcolumnForPath(const SubstreamPath & path, size_t prefix_len)
{
// prefix_len必须大于0
if (prefix_len == 0 || prefix_len > path.size())
return false;
// 因为 Array 的 offsets(ArraySizes)是单独存储的一条流,可以独立读取/补齐,例如 arr.size0 就是一个合法的"子列";
// 但 ArrayElements 表示的只是数组内部的值流,它需要配合 offsets 才能还原出数组形状,
// 单独拿出来没有明确的"子列"意义,所以 hasSubcolumnForPath 只把 ArraySizes 视为可独立访问的子列,而不会把 ArrayElements 判定为子列。
size_t last_elem = prefix_len - 1; // 获取当前的SubstreamPath的最后一个元素(一个Substream)的类型
return path[last_elem].type == Substream::NullMap
|| path[last_elem].type == Substream::TupleElement
|| path[last_elem].type == Substream::ArraySizes
|| path[last_elem].type == Substream::VariantElement
|| path[last_elem].type == Substream::VariantElementNullMap
|| path[last_elem].type == Substream::ObjectTypedPath;
}我们看到,StreamCallback callback_with_data会通过方法ISerialization::createFromPath()来为一个SubstreamPath(Vector<String> Substream)所在的prefix_len前面的元素,创建对应的SubstreamData:
cpp
/**
* 给定一条子流路径 SubstreamPath path(由若干 Substream 节点构成),
* 取它的前 prefix_len 段,重建一份与这段路径对应的 SubstreamData(序列化对象、列指针、类型等上下文)。
* @param path
* @param prefix_len
* @return
*/
ISerialization::SubstreamData ISerialization::createFromPath(const SubstreamPath & path, size_t prefix_len)
{
assert(prefix_len <= path.size());
if (prefix_len == 0)
return {};
ssize_t last_elem = prefix_len - 1;
/**
* 取前缀最后一个节点 path[last_elem] 的 data 作为初始值 res
* data 中已经包含了"沿着整条路径走到此处后的序列化/列/类型"。
*/
auto res = path[last_elem].data;
/**
* 逆序回溯(从 last_elem - 1 向前迭代),每遇到一个节点,检查它的 creator;如果存在,就用它重新"包裹"当前的 res:
*/
for (ssize_t i = last_elem - 1; i >= 0; --i)
{
/**
* creator 会把当前的子列信息提升回到上一层(比如从 values 子流构建出整个 Map 的序列化器/列),
* 这样逆推至指定的前缀长度后,res 就携带了该前缀对应的序列化/列上下文。
*/
const auto & creator = path[i].creator; // 每一个Substream都有一个creator
if (creator)
{
// creator->create用来构造上层的type, serialization或者IColumn信息
// 这样不断循环,用下层的res.type去包装上层的res.type
res.type = res.type ? creator->create(res.type) : res.type;
// 用下层的res.serialization去包装上层的res.serialization
res.serialization = res.serialization ? creator->create(res.serialization) : res.serialization;
// 用下层的res.column去包装上层的res.column
res.column = res.column ? creator->create(res.column) : res.column;
}
}
return res;
}-
res 初始等于SubstreamPath路径末节点
path[last_elem].data------也就是"沿整条路径走到这里时,序列化器在enumerateStreams()中提供的那份上下文"(包含当前子列的 type/column/serialization 等):cpp/** * 取前缀最后一个节点 path[last_elem] 的 data 作为初始值 res * data 中已经包含了"沿着整条路径走到此处后的序列化/列/类型"。 */ auto res = path[last_elem].data; -
然后倒序回溯路径:每遇到一个上层节点,就看它是否带了 creator。creator 是该Substream节点在 enumerateStreams() 时设置的"重建器"(比如 Array 的 SubcolumnCreator),知道如何把内层的 type/serialization/column 包装回上层结构:
cppfor (ssize_t i = last_elem - 1; i >= 0; --i) { /** * creator 会把当前的子列信息提升回到上一层(比如从 values 子流构建出整个 Map 的序列化器/列), * 这样逆推至指定的前缀长度后,res 就携带了该前缀对应的序列化/列上下文。 */ const auto & creator = path[i].creator; // 每一个Substream都有一个creator -
具体做法是:如果 res.type 存在并且有 creator,就调用 creator->create(res.type) 得到上一层的类型;serialization、column 同理。这样不断"从内向外包装",直到回溯到前缀开头,res 就变成了那段前缀对应的完整上下文:
cpp// creator->create用来构造上层的type, serialization或者IColumn信息 // 这样不断循环,用下层的res.type去包装上层的res.type res.type = res.type ? creator->create(res.type) : res.type; // 用下层的res.serialization去包装上层的res.serialization res.serialization = res.serialization ? creator->create(res.serialization) : res.serialization; // 用下层的res.column去包装上层的res.column res.column = res.column ? creator->create(res.column) : res.column; -
这个函数常被
forEachSubcolumn()调用:它先在遍历时找到一个前缀(例如tagGroup1.keys),再用createFromPath()方法把这个SubstreamPath对应的SubstreamData从叶子一路回溯到这一层,最终返回"这个子列应该具备的类型/列/序列化器",让调用方可以直接使用。
举例说明复合类型的 offsets 复用与默认值补齐
offset的准确含义
以列 tags Map(String, String) 为例。ClickHouse 在实现上把 Map(K,V) 表示为:
Array(Tuple(keys K, values V))
并且在 DataTypeMap 中明确指定 tuple 元素名就是常量 "keys" 和 "values"(而其他普通的Tuple比如Tuple(a String, b String),其Tuple的元素名则是a和b):
55:63:src/DataTypes/DataTypeMap.cpp
nested = std::make_shared<DataTypeArray>(
std::make_shared<DataTypeTuple>(DataTypes{key_type_, value_type_}, Names{"keys", "values"}));因此 tags Map(String,String) 在物理子流(substream/stream)层面至少包含:
tags.size0:外层数组的 offsets(累计计数)tags.keys:keys 的元素流(扁平化序列)tags.values:values 的元素流(扁平化序列)
这里最关键的一点是:tags.keys 和 tags.values 共用同一份 offsets(tags.size0) 。
因为 keys/value 都来自同一个外层 Array(...),每一行有多少个键值对,keys 和 values 的长度必须一致,这个"每行长度边界"由 offsets 提供。
我们看一下,Array中的offsets子流(tags.size0)到底表示什么?
tags.size0 这条 offsets 存放的数据是这个:对于表的第 N 行,offsets 存放"到第 N 行为止累计的键值对元素总数",所以,利用offsets的差分可以得到每行 Map/Array 的元素个数: 第 N 行长度 = offsets[N] - offsets[N-1](其中 offsets[-1] 约定为 0)。
注意:这里的"行"指的是 ClickHouse 表里面的数据行数,也就是最外层记录;不是指 Map 内部元素在被flattern以后的行数。
不要搞混的是这三个概念:SubstreamPath、Substream、以及由 path 计算出来的 stream_name(它不是 Substream 的字段)。
SubstreamPath / Substream / stream_name 的区别(别混)
-
Substream:一个"路径节点",描述一层结构信息(以及少量附加数据)。它大概包含:type:这一层是什么(ArraySizes/ArrayElements/TupleElement/DictionaryKeys...)name_of_substream:只有某些type才会用到的名字(例如TupleElement的"keys"/"values",或NamedOffsets的"size0")data:该节点对应的SubstreamData(type/serialization/column 等上下文)creator:用于回溯包装的 creator(可选)
-
SubstreamPath:一个vector<Substream>,也就是"从上到下的一条路径"。它只表达"结构怎么走"(Array→Tuple→LowCardinality...),本身不等于文件名、也不是"某个列名字符串"。
-
stream_name:是一个字符串 ,用于定位落盘文件前缀(例如tags.size0、tags.keys、tags.values)。它不是
Substream的成员字段,而是运行时通过类似getFileNameForStream(column, subpath)这种函数,把:- 列的
name_in_storage(例如tags) -
SubstreamPath(例如[ArraySizes]或[ArrayElements, TupleElement("keys")])
拼接/转义后计算出来的结果。
- 列的
用 tags Map(String,String) 举例(只展示最终计算结果):
-
offsets 子流:
SubstreamPath≈[ArraySizes(level=0)]- 计算得到
stream_name = "tags.size0"
-
keys 元素流:
SubstreamPath≈[ArrayElements(level=0), TupleElement(name="keys")]- 计算得到
stream_name = "tags.keys"
-
values 元素流:
SubstreamPath≈[ArrayElements(level=0), TupleElement(name="values")]- 计算得到
stream_name = "tags.values"
offset复用
我们看一下 collectOffsetsColumns() 如何复用 offsets:
在 fillMissingColumns() 里,第一步会调用:
collectOffsetsColumns(available_columns, res_columns)
它的行为很重要:它不是凭空从 available_columns 推导 offsets,而是必须依赖 res_columns 里已经读到的真实列对象。
代码要点如下:
cpp
static std::unordered_map<String, ColumnPtr> collectOffsetsColumns(
const NamesAndTypesList & available_columns, const Columns & res_columns)
{
// 遍历 available_columns[i] 与 res_columns[i] 成对
// 如果 res_columns[i] == nullptr,则跳过
// 对"这列的 serialization" enumerateStreams,只收集 ArraySizes 子流
// stream_name = getFileNameForStream(available_column, subpath) 例如 tags.size0
// offsets_columns[stream_name] = subpath.back().data.column
}因此,只有当某一列(例如 tags.values)在本轮 确实被读出来 (res_columns[i] != nullptr),collectOffsetsColumns() 才能在枚举它的子流时"顺手"拿到共享 offsets tags.size0,并保存到:
offsets_columns["tags.size0"] = <ColumnUInt64 offsets>
我们看一下这个典型场景,即part 缺失 tags.keys,但本轮却读到了 tags.values
假设某个 part 缺失了 tags.keys 的数据流,但 tags.values 在本轮读取的 available_columns 中且成功读到 res_columns(非 nullptr)。
那么:
collectOffsetsColumns()会在枚举tags.values时收集到tags.size0,形成:
offsets_columns["tags.size0"] = offsets
- 当
fillMissingColumns()尝试补齐缺失的tags.keys时,会再次对tags.keys的 type/serialization 枚举,专门找ArraySizes子流,并用getFileNameForStream(*requested_column, subpath)生成 stream_name 来查offsets_columns:
- 对 keys 来说,它的
ArraySizes(level=0)生成的 stream_name 仍然是tags.size0(因为 offsets 是外层 Array 的共享子流) - 因此
offsets_columns.find("tags.size0")命中,得到 keys 需要的 offsets
- 有了 offsets 之后,ClickHouse 会构造一个"结构一致"的默认 keys 列:
- 先创建一根 扁平默认列(flat elements) :长度等于
offsets.back()(即所有行元素总数之和),每个元素都为String的默认值"" - 再用
ColumnArray::create(flat_elements, offsets)把它包回Array(String),这样每一行的数组长度与tags.values完全一致
这一点在 fillMissingColumns() 的实现里很直观:
data_size = offsets.back()(总元素数)createColumnWithDefaultValue(..., data_size)创建扁平默认 elements- 再用 offsets 逐层
ColumnArray::create(...)包回去,生成带有offset信息的真实的ColumnArray,只不过Array内部的element都是使用的默认值而不是真实值
cpp
size_t data_size = assert_cast<const ColumnUInt64 &>(*current_offsets.back()).getData().back();
res_columns[i] = createColumnWithDefaultValue(*scalar_type, subcolumn_name, data_size);
for (auto it = current_offsets.rbegin(); it != current_offsets.rend(); ++it)
res_columns[i] = ColumnArray::create(res_columns[i], *it);如果 offsets 也拿不到会怎样?
如果本轮没有任何可用列能提供 tags.size0(例如 tags.values 也没读到、或者被置为 nullptr),那么 current_offsets 会为空,补齐会退化为:"按表行数 num_rows 生成默认列" 。对 Array(String) ,这意味着每行都是空数组 [],无法还原真实每行长度。
所以:
Map(K,V)的 keys/value 子流共享同一份外层 Array offsets(如tags.size0)。collectOffsetsColumns()通过"已读到的列对象 res_columns"枚举ArraySizes子流,把 offsets 按stream_name(如tags.size0)收集起来。- 补齐缺失的
tags.keys/tags.values时,只要能复用到tags.size0,就能用"扁平默认 elements + offsets 包回 ColumnArray"的方式生成结构一致的默认列,从而保证 keys/value 长度与每行边界一致。
扁平是什么意思
我们在讲默认值补齐的时候,一直在说默认值补齐时的"扁平(平铺)",因此我们需要理解一下什么是"扁平",什么是"非扁平"。
基于最简单的数组类型Array(T) 的"elements/offsets"与默认值补齐:三种情况
在 ClickHouse 中,Array(T) 的列对象是:
ColumnArray = (elements, offsets)
其中:
elements:一根一维列(例如Array(String)的 elements 是ColumnString),把所有行的数组元素按顺序扁平摊平;offsets:一根UInt64列(累计值/前缀和),长度等于表行数,用来把扁平 elements 切回"每行一个数组"。
因此:"扁平"只描述 elements 的内部存储形态;一个 Array 列对外永远是按行的数组列。
-
情况 1:有真实 offsets(正常读到的 Array 列)
这是最常见的正常情况:我们从磁盘把
ArraySizes(例如size0)读到了,也把 elements 读到了,于是能直接构造出完整的ColumnArray(elements, offsets)。示例:3 行 offsets 为
offsets=[3,3,5],elements 一共 5 个元素。对外语义是:- 行1:elements[0...3)(长度 3)
- 行2:elements[3...3)(长度 0)
- 行3:elements[3...5)(长度 2)
-
情况 2:能复用 offsets(按 offsets 补齐,保留每行长度)
当某个 Array/Map 的某个子列缺失,但你能从同一个复合列的其它子流里复用到 offsets (典型是从
tags.values读到了共享的tags.size0),ClickHouse 会做:- 用
data_size = offsets.back()先创建一根"扁平默认 elements 列"(长度=总元素数,每个元素都是 T 的默认值); - 再用
ColumnArray(elements, offsets)把它与 offsets 组合成完整 Array 列。
示例:仍用
offsets=[3,3,5],则:-
先构建扁平默认 elements(长度 5):
["", "", "", "", ""] -
组合成
ColumnArray(elements, offsets)后,对外语义是:- 行1:
["", "", ""] - 行2:
[] - 行3:
["", ""]
- 行1:
注意:这不是"扁平列"。它对外仍是按行数组列;只是 elements 在内部始终是扁平存储。
这类补齐的优势是:保留真实的每行长度边界(长度信息不丢)。
- 用
-
情况 3:拿不到 offsets(退化补齐:每行空数组,长度信息丢失)
如果 ClickHouse 既没有读到 offsets,也无法从其它子流复用 offsets,那么它无法知道每行数组真实长度,只能按表行数
num_rows生成默认值:- 3 行 →
[[], [], []]
这在类型上仍是合法的
Array(T)列,但它丢失了真实的每行长度信息 (比如真实应为[3,0,2],但退化后变成[0,0,0])。 - 3 行 →
总之:
elements永远扁平存储;- 是否能得到/复用
offsets,决定了你能不能保留每行数组的真实边界与长度 :- 有 offsets 或可复用 offsets ⇒ 长度保留
- 拿不到 offsets ⇒ 退化成每行空数组,长度丢失
第二次补列: 通过IMergeTreeReader::evaluateMissingDefaults()来评估默认值计算
我们从堆栈中看到,异常就发生在默认值的计算中。
我们讲解过,默认值的计算是基于should_evaluate_missing_defaults=True决定的。对这个变量的准确理解当然需要基于对方法fillMissingColumns()的理解。
从上面我们讲解的fillMissingColumns()可以看到:
- 那些在Part中存在(有数据)的列,自然不需要补列,
- 而那些在Part中不存在并且也没有默认值(表达式)的列,已经被
IMergeTreeReader::fillMissingColumns()进行了基于类型的默认值填充。 - 那么,经过
fillMissingColumns(),交付给IMergeTreeReader::evaluateMissingDefaults()方法的列,就是那些在Part中不存在、并且有默认值(表达式)`的列**。
IMergeTreeReader::evaluateMissingDefaults()的基本流程
我们具体看一下IMergeTreeReader::evaluateMissingDefaults()的实现细节。
cpp
/**
* 新增的 host 列在该 part 中不存在,并且这个新增的host列有默认值表达式,因此需要填补默认值,因此调用 IMergeTreeReader::evaluateMissingDefaults。
* 但是在IMergeTreeReader::evaluateMissingDefaults中抛异常的确是另外的列tagGroup1.values
* 这里的res_columns就是请求的列,比如,当前的VerticalMergeStage正在请求的例,在这里,包含 host和tagGroup1.value两个列,其中tagGroup1.value是子列
* Columns & res_columns 与 original_requested_columns(构造IMergeTreeReader的时候传入的) 对齐,由于 host缺失,因此res_columns中它的对应位置是nullptr
* 代表调用方本次请求的列集:有可能是基列,也可能是子列。
* 它和 original_requested_columns 一一对应,位置相同;已读出的列是非空指针,缺失的列为 nullptr,后续默认值计算会据此填满。
*
* 在我们的例子中,
* 这个列是Map<LowCardinality<String>,String>,而不是缺失的那5个非LowCardinality列,但是方法evaluateMissingDefaults
* 的触发确实是由那5列缺失触发的
* @param additional_columns 在Vertical Merge的场景下,additional_columns是{}
* @param res_columns
*/
void IMergeTreeReader::evaluateMissingDefaults(Block additional_columns, Columns & res_columns) const
{
size_t num_columns = original_requested_columns.size();
NameSet full_requested_columns_set;
NamesAndTypesList full_requested_columns;
/// Convert columns list to block. And convert subcolumns to full columns.
/// Defaults should be executed on full columns to get correct values for subcolumns.
/// TODO: rewrite with columns interface. It will be possible after changes in ExpressionActions.
auto it = original_requested_columns.begin();
// 遍历构造IMergeTreeReader的时候传入的参数列 original_requested_columns,这里是 [host, tagGroup1.values]
for (size_t pos = 0; pos < num_columns; ++pos, ++it)
{
// 找到对应的存储列。如果是子列,则映射到对应的表结构的基列
auto name_in_storage = it->getNameInStorage();
// 构建 full_requested_columns, 把对应的子列提升为对应的存储列(基列)级别
// 如果 full_requested_columns_set中不存在name_in_storage, 则执行插入
// NameSet full_requested_columns_set; 和 NamesAndTypesList full_requested_columns;。前者用来去重存储列名,后者存对应列名+类型
if (full_requested_columns_set.emplace(name_in_storage).second)
full_requested_columns.emplace_back(name_in_storage, it->getTypeInStorage());
// res_columns 是与original_requested_columns同样位置对齐的 Columns 数组,
// Columns & res_columns 与 original_requested_columns 对齐,代表调用方本次请求的列集:有可能是基列,也可能是子列。
// 它和 original_requested_columns 一一对应,位置相同;已读出的列是非空指针,缺失的列为 nullptr,后续默认值计算会据此填满。
// res_columns里面有的指针已经被上一步读取填好,有的缺失仍是 nullptr。
if (res_columns[pos]) // 空指针就代表缺失列,不往下插,因为缺的列要靠后面的默认表达式去补
// 所以,additional_columns 代表的是不缺的列,即如果当前列已有数据,就把它塞进临时的 Block additional_columns.
// 在我的场景下,是正在进行Merge的Map的子列 tagGroup.key ,而host由于缺失,不在res_columns中
additional_columns.insert({res_columns[pos], it->type, it->name});
}
/**
* requested_full=[host:String, tagGroup1:Map(LowCardinality(String), String)],
* original_requested=[host:String, tagGroup1.values:Array(String)],
* res_columns=[host(storage='host'):nullptr, tagGroup1.values(storage='tagGroup1'):Array(String)],
* additional_block=[tagGroup1.values:Array(String)]
*/
// 构造评估默认值的DAG, 这里根据表元数据(包含 DEFAULT/MATERIALIZED)和已存在的列,生成一棵表达式 DAG,指明哪些缺失列要怎么计算。
auto dag = DB::evaluateMissingDefaults(
additional_columns, //
full_requested_columns, // 请求的所有的列的基列,这里是host 和 tagGroup1两列
storage_snapshot->metadata->getColumns(),
data_part_info_for_read->getContext());
if (dag)
{
dag->addMaterializingOutputActions();
auto actions = std::make_shared<ExpressionActions>(
std::move(*dag),
ExpressionActionsSettings::fromSettings(data_part_info_for_read->getContext()->getSettingsRef()));
/**
* actions->execute(additional_columns); 会"把计算结果放进这个 Block additional_columns中",既包括:
* 对原本缺失的列(host):按照默认表达式新建出一列,加到 additional_columns 里(原来没有这一列,现在有了)。
* 对已有的列(tagGroup1):如果表达式图里定义了对它的计算(比如 MATERIALIZED/DEFAULT 依赖),也会在同一个 Block 里覆盖/更新对应列的数据。
*
* - host 有 DEFAULT,会补一根常量列。
* - tagGroup1 在 additional_columns 中不存在且无 DEFAULT,因此用类型默认值补一根空 Map,内部键/值子列默认构造成 ColumnNothing。
*/
actions->execute(additional_columns);
}
/**
* 这里执行完,Map对应的类型就已经是Map(Nothing, Nothing)了
* additional_block=[host:String, tagGroup1:Map(Nothing, Nothing), tagGroup1.values:Array(String)]
*/
/// Move columns from block.
// 再次遍历原始的请求列,
// 这里的循环负责把默认值计算后的结果从 additional_columns 拿出来,按调用方请求的粒度(可能是基列,也可能是子列)填回 res_columns
it = original_requested_columns.begin();
for (size_t pos = 0; pos < num_columns; ++pos, ++it)
{
// 如果请求的是子列,这里取的是它所属的存储列名;如果请求的是基列,就是自身列名。
auto name_in_storage = it->getNameInStorage(); // 获取对应基列的列名
// 先拿到对应存储列在 additional_columns 里的完整列数据指针,放到结果槽位。
// 此时 res_columns[pos] 持有的是"基列"的完整数据。
res_columns[pos] = additional_columns.getByName(name_in_storage).column;
// 若原请求是子列而不是基列,就还要从刚取出的完整基列里切出子列
if (it->isSubcolumn()) // 如果当前的这个请求列是子列
{
// 拿到基列的数据类型对象,用它来解析子列
const auto & type_in_storage = it->getTypeInStorage(); // 获取对应的基列的列类型
// 在这里报错了
// 这里,从完整列(res_columns[pos])中提取出对应的子列数据,替换掉 res_columns[pos]。
// 这样最终返回给上层的就是用户请求的那一列形状,而不是整个基列
res_columns[pos] = type_in_storage->getSubcolumn(it->getSubcolumnName(), res_columns[pos]);
}
}
}我们已经讲过MergeTreeSequentialSource::generate()中调用 IMergeTreeReader::fillMissingColumns()和IMergeTreeReader::evaluateMissingDefaults()的过程:
cpp
if (rows_read) // 如果的确读到了数据
{
// 填充诸如 _part, _part_index 的虚拟列(查 storage_snapshot->virtual_columns)。
fillBlockNumberColumns(columns, sample, data_part->info.min_block, current_row, rows_read);
reader->fillVirtualColumns(columns, rows_read);
// 更新 current_row、current_mark:推进游标,下一轮知道从哪继续。
current_row += rows_read; // 更新读取的总行数
current_mark += (rows_to_read == rows_read);
bool should_evaluate_missing_defaults = false;
reader->fillMissingColumns(columns, should_evaluate_missing_defaults, rows_read);
reader->performRequiredConversions(columns);
if (should_evaluate_missing_defaults)
reader->evaluateMissingDefaults({}, columns); // 调用的时候,columns包含了两列,host和tagGroup1.values从参数看到,除了res_columns存放的是请求列的信息,还有一个Block additional_columns参数在调用的时候是{},它在IMergeTreeReader::evaluateMissingDefaults()中非常重要,因为,它是默认值表达式执行时的"输入 + 输出容器",即:
Block additional_columns里面先放"当前已经有的数据列"(tagGroup1.values从res_columns中拷贝进来),然后,默认值系统(DAG)在这个容器上计算缺失列,并把新生成/补齐的基列(例如 host、tagGroup1)直接写回到同一个 Block(additional_columns) 里;最后再从这个 Block(additional_columns) 把结果搬回res_columns。
为什么需要Block additional_columns,而不是直接在 res_columns 上算?
因为res_columns 是一个"按原请求顺序对齐的裸列指针数组",里面既可能是基列也可能是子列,且缺失列用 nullptr 表示;它本身不携带列名到列的映射,不方便表达式系统(ExpressionActions/ActionsDAG)按列名取用/产出。表达式系统(ExpressionActions/ActionsDAG)工作的对象是 Block:它需要一个能按列名查找/插入/覆盖列的容器。 因此 evaluateMissingDefaults() 会先把 res_columns 里已有的列放进 additional_columns(输入),执行表达式把缺列补出来(输出),再按基列名把结果取回并在需要时 getSubcolumn() 变回子列形状。
-
可以看到,这里的
additional_columns参数是{},而res_columns则是IMergeTreeReader中计算得到的结果:res_columns中值为nullptr的位置是留给IMergeTreeReader::evaluateMissingDefaults()进行计算的列。cppvoid IMergeTreeReader::evaluateMissingDefaults(Block additional_columns, Columns & res_columns) const { ..... -
构建每一个请求列对应的基列的列表
full_requested_columns_set,并将构建一个Block additional_columns,将res_columns中已经有值(无论是本身part中有这一列、还是说没有列但是已经通过fillMissingColumns()进行了类型默认值填充)的列存放到Block additional_columns中去:cppauto it = original_requested_columns.begin(); // 遍历构造IMergeTreeReader的时候传入的参数列 original_requested_columns,这里是 [host, tagGroup1.values] for (size_t pos = 0; pos < num_columns; ++pos, ++it) { // 找到对应的存储列(即基列)。如果是子列,则映射到对应的表结构的基列 auto name_in_storage = it->getNameInStorage(); // 构建 full_requested_columns, 把对应的子列提升为对应的存储列(基列)级别 // 如果 full_requested_columns_set中不存在name_in_storage, 则执行插入 // NameSet full_requested_columns_set; 和 NamesAndTypesList full_requested_columns;。前者用来去重存储列名,后者存对应列名+类型 if (full_requested_columns_set.emplace(name_in_storage).second) full_requested_columns.emplace_back(name_in_storage, it->getTypeInStorage()); // res_columns 是与original_requested_columns同样位置对齐的 Columns 数组, // Columns & res_columns 与 original_requested_columns 对齐,代表调用方本次请求的列集:有可能是基列,也可能是子列。 // 它和 original_requested_columns 一一对应,位置相同;已读出的列是非空指针,缺失的列为 nullptr,后续默认值计算会据此填满。 // res_columns里面有的指针已经被上一步读取填好(或者根本就不缺),有的缺失仍是 nullptr。 if (res_columns[pos]) // 空指针就代表缺失列,不往下插,因为缺的列要靠后面的默认表达式去补 // 所以,additional_columns 代表的是不缺的列(不缺可能是因为这一列本来就有数据,也可能是因为这一列没有数据也没有默认值因此被IMergeTreeReader::fillMissingColumns()补了数据), // 即如果当前列已有数据,就把它塞进临时的 Block additional_columns. // 在我的场景下,是正在进行Merge的Map的子列 tagGroup.values ,而host由于缺失,不在res_columns中 // 调用Block::insert()方法 additional_columns.insert({res_columns[pos], it->type, it->name}); }我们在评估默认值的时候必须从基列进行 ,是因为我们的默认值(表达式)肯定是定义在表的DDL上(即基列上)的,因此评估默认值必须从基列进行。
从上面的代码可以看到:
-
full_requested_columns_set一开始空,用来去重基列名,存放的是每一个请求列对应的基列的列表。显然,如果请求列是基列,那么基列就是它本身,如果请求的是子列,那么基列就是这个子列所属的存储列。 -
遍历当前的请求列
original_requested_columns,逐个生成其对应的基列信息:-
对
host:name_in_storage = "host",这个名字第一次出现,于是full_requested_columns.emplace_back("host", DataTypeString);res_columns[0]为空,所以不会往additional_columns插入。 -
对
tagGroup1.values:name_in_storage = "tagGroup1",第一次出现,又把(tagGroup1, Map(LowCardinality(String), String))加进full_requested_columns;res_columns[1]有值(Map value 数据读到了),于是把它插进additional_columns,列描述是{ column=ColumnArray(String), type=Array(String), name="tagGroup1.values" }。
这里,将对应的Column插入到Block中是调用Block::insert()方法:cpp/** * 往 Block 这个容器里追加一列(ColumnWithTypeAndName),包含三样东西:列名、列类型、列数据指针。 * 它做的是"把这个列对象放进 Block 的内部存储",不是仅仅登记元数据,也不是拷贝一份原数据;实现里直接 data.emplace_back(std::move(elem))。 * 同时会在 index_by_name 里注册列名,若重名则校验结构一致,否则报错。 * @param elem */ void Block::insert(ColumnWithTypeAndName elem) { auto [it, inserted] = index_by_name.emplace(elem.name, data.size()); ... data.emplace_back(std::move(elem)); }
-
-
执行到这里,部分变量的值为:
full_requested_columns = [ ("host", String), ("tagGroup1", Map(...)) ]full_requested_columns_set = { "host", "tagGroup1" },这里是去重的基列名称Block additional_columns只有一列tagGroup1.values(我们读到的那份数组),host缺失所以不在Block里,等待下一步评估。我们在下面的ExpressionActions::execute()方法可以看到,ExpressionActions::execute()会把addition_columns的行数设置到Block中作为这个Block中所有column(当前只有tagGroup1.values列,dag->execute()执行完以后会基于默认值新增tagGroup1和host列),这也就是为什么ClickHouse在当前Merge只有一个缺失的host列时需要添加进来一个额外的列tagGroup1.values进来,就是为了把这个tagGroup1.values的行数设置到Block中,进而使用这个行数来设置host的行数。
-
-
生成 / 执行默认值 DAG
-
调
DB::evaluateMissingDefaults(...)来生成对应的默认值评估的计算DAG,这个DAG的作用就是根据默认值(无论是默认值表达式还是类型默认值)评估出host和tagGroup1的值。这一步会根据表定义里的 DEFAULT/MATERIALIZED、以及当前
additional_columns里已有的列(tagGroup1.values),构造出一棵表达式 DAG。对这个 case:cpp// 构造评估默认值的DAG, 这里根据表元数据(包含 DEFAULT/MATERIALIZED)和已存在的列,生成一棵表达式 DAG,指明哪些缺失列要怎么计算。 auto dag = DB::evaluateMissingDefaults( additional_columns, // 当前只有tagGroup1.values对应的Block信息,没有host,也没有tagGroup1.values对应的基列tagGroup1的信息 full_requested_columns, // 请求的所有的列的基列,这里是 host 和 tagGroup1 两列 storage_snapshot->metadata->getColumns(), data_part_info_for_read->getContext());在我们的例子中, dag会基于类型默认值或者默认值表达式,计算下面两列的值:
host有 DEFAULT(例如DEFAULT ''),所以 DAG 里会添加一个"生成 host" 的节点;tagGroup1这个基列也在full_requested_columns里,但additional_columns没有它,且表定义可能没有 DEFAULT,于是 DAG 会为它添加"类型默认值"动作(也就是Map(Nothing, Nothing))。
-
如果 DAG 非空,就转成
ExpressionActions并执行这个DAG, 在这个DAG执行完成以后:host列被补进additional_columns,变成一列常量 String(DEFAULT 结果);tagGroup1基列也被补进additional_columns,类型是Map(Nothing, Nothing)(因为默认值里键和值都没有数据)。
cppif (dag) { dag->addMaterializingOutputActions(); auto actions = std::make_shared<ExpressionActions>( std::move(*dag), ExpressionActionsSettings::fromSettings(data_part_info_for_read->getContext()->getSettingsRef())); /** * actions->execute(additional_columns); 会"把计算结果放进这个 Block additional_columns中",既包括: * 对原本缺失的列(host):按照默认表达式新建出一列,加到 additional_columns 里(原来没有这一列,现在有了)。 * 对已有的列(tagGroup1):如果表达式图里定义了对它的计算(比如 MATERIALIZED/DEFAULT 依赖),也会在同一个 Block 里覆盖/更新对应列的数据。很显然,我们的表中tagGroup1列没有默认值 * * - host 有 DEFAULT, 会根据默认值补列 * - tagGroup1 在 additional_columns 中不存在且无 DEFAULT,因此用类型默认值补一根空 Map,内部键/值子列默认构造成 ColumnNothing。 */ actions->execute(additional_columns); }注意,
actions->execute(additional_columns)执行之前,Block additional_columns中已经有了tagGroup1.values,那么之后之所以 还要"从基列 tagGroup1 再切一次 tagGroup1.values",不是因为 tagGroup1.values "没算出来",而是因为这段代码的契约就是:- 默认值表达式只对"基列"产出结果(
full_requested_columns里只有host、tagGroup1)。 子列必须从"最终确定的基列"派生,否则可能会出现结构不一致的问题(尤其是 Map:keys/values 必须长度一致;如果只"保留/计算tagGroup1.values子列"而不经由基列tagGroup1,无法保证和 keys 侧一致)。因此 ClickHouse 选择了统一策略:默认值在基列层面执行,子列在最后从基列切出来。 - 而调用方最终要的可能是子列(
original_requested_columns里有tagGroup1.values),所以最后一步必须把"基列结果"切回"子列形状"。
-
执行后
additional_columns变成[ host:String , tagGroup1:Map(Nothing, Nothing), tagGroup1.values:Array(String) ](后面会有DEBUG日志来证明)。这里,关于tagGroup1基列,由于DAG 开始执行时,它看见tagGroup1这条基列根本不存在(block 里只有tagGroup1.values这一个子列,缺少tagGroup1.keys),既没有输入数据又没有 DEFAULT 表达式,于是只能用类型默认值构造一列Map(Nothing,Nothing) -
我们在
ExpressionActions::execute()中看到-
该方法会首先从
Block中提取出行数,一个Block中所有的Column的行数一定是一样的。由于当前的Block additional_columns其实只有tagGroup1.values一列,因此Block的行数就是tagGroup1.values的行数:cppvoid ExpressionActions::execute(Block & block, bool dry_run, bool allow_duplicates_in_input) const { size_t num_rows = block.rows(); // 提取行数 execute(block, num_rows, dry_run, allow_duplicates_in_input); ..... } -
后续执行每个 action时,会用这个
num_rows把列扩展成同样的行数。例如当 DAG 节点已经有 node->column(常量/literal)时(字面量,比如host),会直接为这个column生成一根长度等于输入 block 行数的结果列:cppstatic void executeAction(const ExpressionActions::Action & action, ExecutionContext & execution_context, bool dry_run, bool allow_duplicates_in_input) { ...... switch (action.node->type) { case ActionsDAG::ActionType::FUNCTION: { auto & res_column = columns[action.result_position]; // 省略:设置 res_column.type/name ... if (action.node->column) { /// 这个列的结果已经都知道了,因此,直接根据这个Block的行数直接resize这个常量列. res_column.column = action.node->column->cloneResized(num_rows); ....... break; // 这里直接 break,不会走到下面的 function->execute(...) } // 只有 node->column 为空时,才会真正执行函数 res_column.column = action.node->function->execute(arguments, res_column.type, num_rows, dry_run); // ... break; } // ... 其他 case ... } }
-
-
-
基于基列的默认值计算结果并存放在
additional_columns中。 下一步就需要进一步计算请求列的默认值了,并把最终的请求列的默认值计算结果拷回res_columns完成任务:这里,会再次遍历
original_requested_columns,逐个为这些请求列基于计算的基列默认值来计算请求列默认值。前面说过,original_requested_columns指的是当前的请求列,即["host", "tagGroup1.values"]-
pos=0(
host):name_in_storage = "host",直接从additional_columns里取 host 列放进res_columns[0],这就是按照 DEFAULT 生成的那列 String。因为 host 不是子列,所以不用再切子列。 -
pos=1(
tagGroup1.values):先把additional_columns里整个tagGroup1列(Map(Nothing, Nothing))放到res_columns[1]。接着由于它是子列(it->isSubcolumn()),调用type_in_storage->getSubcolumn("values", res_columns[1]),也就是从整列 Map 中提取values子列。由于默认的 Map 是Nothing,getSubcolumn()会返回一列Array(Nothing)(或空列),最终res_columns[1]被替换为缺省值版的tagGroup1.values。我们之前的崩溃就发生在这一步。cpp// 再次遍历原始的请求列, // 这里的循环负责把默认值计算后的结果从 additional_columns 拿出来,按调用方请求的粒度(可能是基列,也可能是子列)填回 res_columns it = original_requested_columns.begin(); for (size_t pos = 0; pos < num_columns; ++pos, ++it) { // 如果请求的是子列,这里取的是它所属的存储列名;如果请求的是基列,就是自身列名。 auto name_in_storage = it->getNameInStorage(); // 获取对应基列的列名 // 先拿到对应存储列在 additional_columns 里的完整列数据指针,放到结果槽位。 // 此时 res_columns[pos] 持有的是"基列"的完整数据。 res_columns[pos] = additional_columns.getByName(name_in_storage).column; // 若原请求是子列而不是基列,就还要从刚取出的完整基列里提取出子列 if (it->isSubcolumn()) // 如果当前的这个请求列是子列 { // 拿到基列的数据类型对象,用它来解析子列 const auto & type_in_storage = it->getTypeInStorage(); // 获取对应的基列的列类型 // 在这里报错了 // 这里,从完整列(res_columns[pos])中提取出对应的子列数据,替换掉 res_columns[pos]。 // 这样最终返回给上层的就是用户请求的那一列形状,而不是整个基列 res_columns[pos] = type_in_storage->getSubcolumn(it->getSubcolumnName(), res_columns[pos]); } }调用
IDataType::getSubcolumn()方法来从基列(tagGroup1)的IColumn中获取子列(tagGroup1.values)的IColumn。真正的异常就在这里发生,基列中的类型是补充得到的ColumnMap(ColumnNothing keys, ColumnNothing values),在处理Key的ColumnNothing的类型的时候,发生了从ColumnNothing到ColumnLowCardinality的转换异常。下文详细讲解ColumnNothing的生成,和ColumnLowCardinaltity的转换。
-
总之:
IMergeTreeReader::evaluateMissingDefaults()方法会:
- 给我们在Part中缺失的列
host根据默认值(表达式)填写默认值 - 给
tagGroup1.values的基列tagGroup1构造空的默认Map(注意,这里不是填充默认值,因为tagGroup1.values并没缺失,tagGroup1.values的值真实存在于res_columns中,这个空的Map不会影响res_columns中的tagGroup1.values的实际值),再将tagGroup1.values替换成getSubcolumn得到的子列(虽然值是 Nothing)。但正因为getSubcolumn()基于type_in_storage生成,这块 Map 默认列如果结构不匹配,就会触发我们遇到的类型转换的报错
构造基列数据时为Map构造默认数据,产生ColumnNothing类型
从上面的分析可以看到,IMergeTreeReader::evaluateMissingDefaults() 会被调用来补齐缺失列的默认值。
上面讲过,Block additional_columns 参数是整个默认值评估的输入输出的。调用的时候,additional_columns处传入的是空{},但函数内部会先把"已经读到的列"塞进 Block additional_columns 里,作为默认值表达式执行的输入;同时把请求的子列(tagGroup1.values)提升为对应的基列集合(tagGroup1,默认值系统只按基列工作),然后再从这个基列的值中获取到子列tagGroup1.values的值,正是在这个过程中发生了类型转换错误。
-
准备好输入的
Block additional_columns,下面的代码运行以后,Block additional_columns中会包含tagGroup1.values:cppvoid IMergeTreeReader::evaluateMissingDefaults(Block additional_columns, Columns & res_columns) const { NameSet full_requested_columns_set; NamesAndTypesList full_requested_columns; auto it = original_requested_columns.begin(); for (size_t pos = 0; pos < num_columns; ++pos, ++it) { auto name_in_storage = it->getNameInStorage(); if (full_requested_columns_set.emplace(name_in_storage).second) full_requested_columns.emplace_back(name_in_storage, it->getTypeInStorage()); if (res_columns[pos]) additional_columns.insert({res_columns[pos], it->type, it->name}); } auto dag = DB::evaluateMissingDefaults( additional_columns, full_requested_columns, storage_snapshot->metadata->getColumns(), data_part_info_for_read->getContext()); } -
在运行DAG进行默认值评估的时候,工作
Block additional_columns只包含tagGroup1.values(子列)。由于默认值系统需要得到基列集合full_requested_columns(例如[host, tagGroup1]),它会把缺失的基列tagGroup1当成"需要补齐的列",并在执行默认值表达式时把tagGroup1生成出来:cppif (dag) { dag->addMaterializingOutputActions(); auto actions = std::make_shared<ExpressionActions>(std::move(*dag), ...); actions->execute(additional_columns); } -
默认值表达式DAG的构造发生在
addDefaultRequiredExpressionsRecursively()。当某个 required column(这里就是tagGroup1)在输入 block 中不存在 ,并且在表元数据中也没有显式的DEFAULT ...表达式 时,代码会退化到"类型默认值":调用该列(tagGroup1)的IDataType::getDefault()得到一个Field常量,然后用ASTLiteral把这个常量塞进表达式里(即"用类型默认值补齐这一列"):cppauto column_default = columns.getDefault(required_column_name); if (column_default) // 有默认值表达式,则用表达式计算 { // 有 DEFAULT 表达式:用表达式计算 auto column_default_expr = column_default->expression->clone(); auto required_type = std::make_shared<ASTLiteral>(columns.get(required_column_name).type->getName()); auto expr = makeASTFunction("_CAST", column_default_expr, required_type); default_expr_list_accum->children.emplace_back(setAlias(expr, required_column_name)); added_columns.emplace(required_column_name); } else if (columns.has(required_column_name)) // 没有 DEFAULT 表达式:用类型默认值补齐(Field → ASTLiteral) { const auto & column = columns.get(required_column_name); auto default_value = column.type->getDefault(); // 这里生成ColumnNothing ASTPtr expr = std::make_shared<ASTLiteral>(default_value); default_expr_list_accum->children.emplace_back(setAlias(expr, required_column_name)); added_columns.emplace(required_column_name); }对
Map类型来说,类型默认值由DataTypeMap::getDefault()决定,它返回的是一个空的Map()(这是一个Field值,表示"空 map",内部没有任何(key,value)元素)。cppField DataTypeMap::getDefault() const { return Map(); } -
尽管
tagGroup1在表DDL中有明确类型Map(LowCardinality(String), String),但是,ASTLiteral(Map())的类型不是"强行用DDL类型Map(LowCardinality(String), String)",而是表达式分析阶段从 literal 的Field value推导出来的。ActionsVisitor访问ASTLiteral时,会调用FieldToDataType从literal.value推导类型:cppvoid ActionsMatcher::visit(const ASTLiteral & literal, const ASTPtr &, Data & data) { DataTypePtr type; if (literal.custom_type) type = literal.custom_type; else type = applyVisitor(FieldToDataType(), literal.value); const auto value = convertFieldToType(literal.value, *type); // ... }FieldToDataType(Map)的推导规则是:遍历 map 的每个元素,把每个元素当成二元Tuple(key,value),分别收集 key/value 的类型集合,然后对集合求 least supertype(最小超集),构造出DataTypeMap(key_super, value_super)。cppDataTypePtr FieldToDataType<on_error>::operator() (const Map & map) const { DataTypes key_types; DataTypes value_types; for (const auto & elem : map) { const auto & tuple = elem.safeGet<const Tuple &>(); assert(tuple.size() == 2); key_types.push_back(applyVisitor(*this, tuple[0])); value_types.push_back(applyVisitor(*this, tuple[1])); } return std::make_shared<DataTypeMap>( getLeastSupertype<on_error>(key_types), getLeastSupertype<on_error>(value_types)); }由于
DataTypeMap::getDefault()返回的是空Map(),因此key_types和value_types都是空集合。对空集合求getLeastSupertype的规则是:直接返回DataTypeNothing()。因此空 map 的 literal 会被必然推导成Map(Nothing, Nothing)。cppDataTypePtr getLeastSupertype(const DataTypes & types) { if (types.empty()) return std::make_shared<DataTypeNothing>(); // ... } -
一旦类型推导成
Nothing,创建列对象时就会落到DataTypeNothing::createColumn(),它返回的就是ColumnNothing。因此Map(Nothing, Nothing)的内部 key/value 子列会是ColumnNothing。cppMutableColumnPtr DataTypeNothing::createColumn() const { return ColumnNothing::create(0); } -
最终,在
actions->execute(additional_columns)执行后,additional_columns中出现了tagGroup1:Map(Nothing, Nothing)。随后evaluateMissingDefaults()会按"基列 → 子列"的方式回填结果:先getByName("tagGroup1")取到基列,再getSubcolumn("values")提取子列。由于此时基列内部 key 侧已经是ColumnNothing,而声明类型要求 key 是LowCardinality(String),于是会在SerializationLowCardinality的typeid_cast(ColumnNothing → ColumnLowCardinality)处触发Bad cast异常。cppauto name_in_storage = it->getNameInStorage(); res_columns[pos] = additional_columns.getByName(name_in_storage).column; if (it->isSubcolumn()) { const auto & type_in_storage = it->getTypeInStorage(); res_columns[pos] = type_in_storage->getSubcolumn(it->getSubcolumnName(), res_columns[pos]); }
getSubcolumnData: 通过构造出来的基列数据来获取子列数据并发生转换错误
可以看到,在 IMergeTreeReader::evaluateMissingDefaults()中,在完成了基列的默认值评估以后,会将基列的默认值还原到子列的默认值上,因为我们真正请求的是子列,而不是基列:
cpp
// 再次遍历原始的请求列,
// 这里的循环负责把默认值计算后的结果从 additional_columns 拿出来,按调用方请求的粒度(可能是基列,也可能是子列)填回 res_columns
it = original_requested_columns.begin();
for (size_t pos = 0; pos < num_columns; ++pos, ++it)
{
// 如果请求的是子列,这里取的是它所属的存储列名;如果请求的是基列,就是自身列名。
auto name_in_storage = it->getNameInStorage(); // 获取对应基列的列名
// 先拿到对应存储列在 additional_columns 里的完整列数据指针,放到结果槽位。
// 此时 res_columns[pos] 持有的是"基列"的完整数据。
res_columns[pos] = additional_columns.getByName(name_in_storage).column;
if (it->isSubcolumn()) // 如果当前的这个请求列是子列,比如, tagGroup1.values
{
// 拿到基列的数据类型对象,用它来解析子列
const auto & type_in_storage = it->getTypeInStorage(); // 获取对应的基列的列类型
// 还原子列的默认数据
res_columns[pos] = type_in_storage->getSubcolumn(it->getSubcolumnName(), res_columns[pos]);
}
}这里,对于tagGroup1.values(),由于它是子列,对应的基列(type_in_storage)类型是DataTypeMap。DataTypeMap没有实现IDataType::getSubcolumn(),所以其实是调用IDataType::getSubcolumn()方法来从基列中获取子列。真正的异常就在这里发生这里:
cpp
/**
* 在 IMergeTreeReader::evaluateMissingDefaults()中调用这个方法的时候,IDataType对象是子类所在的基类对象,而subcolumn_name是对应的子列名,ColumnPtr & column是对应的基列的Column
* @param subcolumn_name
* @param column
* @return
*/
ColumnPtr IDataType::getSubcolumn(std::string_view subcolumn_name, const ColumnPtr & column) const
{
/**
* 这里是
*/
auto data = SubstreamData(getDefaultSerialization()).withType(getPtr()).withColumn(column);
return getSubcolumnData(subcolumn_name, data, true)->column;
}这里,IDataType::getSubcolumnData()会对复合类型进行stream的枚举:
cpp
std::unique_ptr<IDataType::SubstreamData> IDataType::getSubcolumnData(
std::string_view subcolumn_name,
const SubstreamData & data,
bool throw_if_null)
{
std::unique_ptr<IDataType::SubstreamData> res;
/**
* 构造对应的StreamCallback,这个callback就是用来作为ISerialization::enumerateStreams()来用的
* 这个StreamCallback 会一路遍历 SerializationMap 的路径:先 1.ArraySizes(tagGroup.size0),
* 2.1 再 TupleElement("keys"),
* 2.2 再 TupleElement("values")
*/
ISerialization::StreamCallback callback_with_data = [&](const auto & subpath)
{
/**
* 对于当前的SubstreamPath(Vector<String> substream),从根逐个遍历
*/
for (size_t i = 0; i < subpath.size(); ++i)
{
size_t prefix_len = i + 1;
// 如果遇到了一个可以独立访问的子列,比如ArraySizes, TupleElements等, 那么需要看看这个可以独立访问的子列是不是就是我们的subcolumn
if (!subpath[i].visited && ISerialization::hasSubcolumnForPath(subpath, prefix_len))
{
auto name = ISerialization::getSubcolumnNameForStream(subpath, prefix_len);
/// Create data from path only if it's requested subcolumn.
if (name == subcolumn_name) // 的确遍历到了当前的subcolumn_name,比如,在我们的例子中的values
{
// 找到了这个subcolumn,因此构造对应的SubstreamData
res = std::make_unique<SubstreamData>(ISerialization::createFromPath(subpath, prefix_len));
}
/// Check if this subcolumn is a prefix of requested subcolumn and it can create dynamic subcolumns.
else if (subcolumn_name.starts_with(name + ".") && subpath[i].data.type && subpath[i].data.type->hasDynamicSubcolumnsData())
{
....
}
}
subpath[i].visited = true;
}
};
ISerialization::EnumerateStreamsSettings settings;
settings.position_independent_encoding = false;
/// Don't enumerate dynamic subcolumns, they are handled separately.
settings.enumerate_dynamic_streams = false;
data.serialization->enumerateStreams(settings, callback_with_data, data);
if (!res && data.type->hasDynamicSubcolumnsData())
return data.type->getDynamicSubcolumnData(subcolumn_name, data, throw_if_null);
if (!res && throw_if_null)
throw Exception(ErrorCodes::ILLEGAL_COLUMN, "There is no subcolumn {} in type {}", subcolumn_name, data.type->getName());
return res;
}-
可以看到,在
IDataType::getSubcolumn()中调用IDataType::getSubcolumnData(...)的时候,对应的参数SubstreamData中的信息为:- data.type 是基列类型 Map(LowCardinality(String), String);
- data.column 是 ColumnMap(在你这里是那份默认值 Map);
- data.serialization 是 SerializationMap。
这些信息描述了"从列根出发"的上下文。
-
然后,开始通过自定义的
StreamCallback callback_with_data来试图找到对应的subcolumn,即values:ISerialization::enumerateStreams()从根开始"走"所有可能的子流,每深入一层就把路径记录在SubstreamPath subpath(Vector(Substrema))中(例如[ArrayElements, TupleElement("values")])。对于每一层Substream:ISerialization::hasSubcolumnForPath(subpath, prefix_len)判断当前前缀是否代表一个独立子列(Map 的 keys/values、Array 的 size0、Nullable 的 NullMap 等);- 如果是,就获取这个独立子列的名称并检查这个独立子列是否就是我们需要获取数据的独立子列
name = getSubcolumnNameForStream(subpath, prefix_len)。 - 一旦发现这个Substream对应独立子列就是我们想要获取数据的独立子列,就通过
ISerialization::createFromPath(...)构造这条"前缀路径"的SubstreamData(包含类型、列数据、序列化器及 creator 信息):
cppif (!subpath[i].visited && ISerialization::hasSubcolumnForPath(subpath, prefix_len)) { auto name = ISerialization::getSubcolumnNameForStream(subpath, prefix_len); /// Create data from path only if it's requested subcolumn. if (name == subcolumn_name) // 的确遍历到了当前的subcolumn_name,比如,在我们的例子中的values { // 找到了这个subcolumn,因此构造对应的SubstreamData res = std::make_unique<SubstreamData>(ISerialization::createFromPath(subpath, prefix_len)); } /// Check if this subcolumn is a prefix of requested subcolumn and it can create dynamic subcolumns. else if (subcolumn_name.starts_with(name + ".") && subpath[i].data.type && subpath[i].data.type->hasDynamicSubcolumnsData()) { .... } }
在我的 case 里,这个函数本来应该沿 SerializationMap → SerializationTuple → SerializationNamed("values") → SerializationArray → SerializationLowCardinality 路径找到 value 子列;只不过它最终抵达 SerializationLowCardinality::enumerateStreams 时,里面第一行把 ColumnNothing 强转成 ColumnLowCardinality,因此在 getColumnLowCardinality() 就崩了:
cpp
void SerializationLowCardinality::enumerateStreams(
EnumerateStreamsSettings & settings,
const StreamCallback & callback,
const SubstreamData & data) const
{
const auto * column_lc = data.column ? &getColumnLowCardinality(*data.column) : nullptr;
....SELECT失败的原因分析
SELECT Query的查询报错原因是非常明确的。
Query 报错的原因可以明确说明:
-
读完数据后,调用
fillMissingColumns,若有缺列则置should_evaluate_missing_defaults=true;随后若为 true 则进入evaluateMissingDefaults(注意这里additional_columns传的是空 Block{})cppChunk MergeTreeSequentialSource::generate() try { ..... if (!isCancelled() && current_row < data_part->rows_count) { ...... size_t rows_read = reader->readRows(current_mark, num_marks_in_part, continue_reading, rows_to_read, columns); if (rows_read) // 如果读取到了数据,则填充块号和虚拟列 { // 填充块号和虚拟列 fillBlockNumberColumns(columns, sample, data_part->info.min_block, current_row, rows_read); reader->fillVirtualColumns(columns, rows_read); // 填充虚拟列 current_row += rows_read; // 当前行数加上读取到的数据行数 current_mark += (rows_to_read == rows_read); // 如果读取到了数据,则当前标记加1 bool should_evaluate_missing_defaults = false; // 填充缺失的列 reader->fillMissingColumns(columns, should_evaluate_missing_defaults, rows_read); reader->performRequiredConversions(columns); // 评估缺失的默认值 if (should_evaluate_missing_defaults) reader->evaluateMissingDefaults({}, columns);
添加日志解释疑惑并找到整个异常发生的原因
第一次添加日志:为什么VerticalMerge会多一列
由于现在我们只知道针对Map(LowCardinality(String), String)报错了,并且报错发生在LowCardinality的转换,因此可以知道是Map类型的values发生了问题,但是我们并不知道:
-
具体报错的是哪一个Map列,因为我们的表结构是这样的,有很多的Map列:
sqlCREATE TABLE {{ DATABASE NAME PLACEHOLDER }}.emo_mdm_flowwork_pt30m_local ON CLUSTER {{ CLUSTER NAME PLACEHOLDER FOR ALL HOSTS }} ( `timestampMs` DateTime64(3) CODEC(ZSTD(1)), `flowId` LowCardinality(String) DEFAULT '' CODEC(ZSTD(1)), .... `host` String DEFAULT '' CODEC(ZSTD(1)), `path` String DEFAULT '' CODEC(ZSTD(1)), `referrer` String DEFAULT '' CODEC(ZSTD(1)), `tagGroup1` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `tagGroup2` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `tagGroup3` Map(LowCardinality(String), String) CODEC(ZSTD(1)), `tagGroup4` Map(LowCardinality(String), String) CODEC(ZSTD(1)), ... `metricIntGroup1` Map(LowCardinality(String), Int32) CODEC(ZSTD(1)), `metricIntGroup2` Map(LowCardinality(String), Int32) CODEC(ZSTD(1)), `metricIntGroup3` Map(LowCardinality(String), Int32) CODEC(ZSTD(1)), `metricIntGroup4` Map(LowCardinality(String), Int32) CODEC(ZSTD(1)), ... `metricFloatGroup1` Map(LowCardinality(String), Float32) CODEC(ZSTD(1)), `metricFloatGroup2` Map(LowCardinality(String), Float32) CODEC(ZSTD(1)), `metricFloatGroup3` Map(LowCardinality(String), Float32) CODEC(ZSTD(1)), `metricFloatGroup4` Map(LowCardinality(String), Float32) CODEC(ZSTD(1)), ... ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/{{ DATABASE NAME PLACEHOLDER }}/emo_mdm_flowwork_pt30m_local','{replica}') PARTITION BY toYYYYMMDD(timestampMs) ... -
从时间上来看,报错与我们
ALTER TABLE ADD COLUMN的行为有关(因为所有的错误都发生在我们运行ALTER TABLE ADD COLUMN操作发生以前的Partition),但是堆栈报出的错误确是在表创建的时候就已经存在的Map类型,而不是我们新添加的column。但是,对于Vertical Merge,我们明明知道,一个Merge Task每次只会处理一列,而不是像Horizontal Merge一样处理多列。如果按照堆栈报错显式当前是处理Map列报错的,为什么在错误的partition分布上又显示出和新增的5个简单列发生关联呢? -
我们从
IMergeTreeReader::fillMissingColumns(...)中探寻should_evaluate_missing_defaults被设置为True的过程可以看到,如果当前Vertical Merge处理的是Map列,那么should_evaluate_missing_defaults不可能被设置为True,因为Map列是一致在表中存在的。只有当当前处理的列是host的时候,should_evaluate_missing_defaults才会因为缺列而被设置为true,可是,我们在堆栈中看到的列明明是Map类型的复合列呀?
综上所示,我们对Vertical Merge的理解(每次只有可能Merge一列),以及堆栈中报错的是针对复合列而不是我们所添加的简单列的现象,以及从堆栈中体现出来的如果evaluateMissingDefault被调用那么一定是should_evaluate_missing_defaults被设置为True,以及IMergeTreeReader::fillMissingColumns(...)代码逻辑中体现出来的如果是复合列那么should_evaluate_missing_defaults不可能为true, 以及我们添加的是简单列而不是复合列的行为,相互交织矛盾。
我们唯一的手段,就是添加代码,找到根本原因。因为我看到,测试环境还可以继续复现这个问题,并且,上面说过,这个问题不会因为ClickHouse的重启而消失。因此,我需要加代码,重新Build ClickHouse,然后观察问题的具体细节。
我们首先需要搞清楚的,是报错的时候ClickHouse的Vertical Merge到底是在处理某一列,还是,有可能,的确在处理多列。
cpp
void IMergeTreeReader::evaluateMissingDefaults(Block additional_columns, Columns & res_columns) const
{
try
{
size_t num_columns = original_requested_columns.size();
if (res_columns.size() != num_columns)
throw Exception(ErrorCodes::LOGICAL_ERROR, "invalid number of columns passed to MergeTreeReader::fillMissingColumns. "
"Expected {}, got {}", num_columns, res_columns.size());
NameSet full_requested_columns_set;
NamesAndTypesList full_requested_columns;
/// Convert columns list to block. And convert subcolumns to full columns.
/// Defaults should be executed on full columns to get correct values for subcolumns.
/// TODO: rewrite with columns interface. It will be possible after changes in ExpressionActions.
auto it = original_requested_columns.begin();
for (size_t pos = 0; pos < num_columns; ++pos, ++it)
{
auto name_in_storage = it->getNameInStorage();
if (full_requested_columns_set.emplace(name_in_storage).second)
full_requested_columns.emplace_back(name_in_storage, it->getTypeInStorage());
if (res_columns[pos])
additional_columns.insert({res_columns[pos], it->type, it->name});
}
try
{
const auto & part_storage = data_part_info_for_read->getDataPartStorage();
String where = part_storage->getFullPath();
String table = data_part_info_for_read->getTableName();
LOG_INFO(getLogger("VMTrace"),
"IMergeTreeReader::evaluateMissingDefaults(pre): table='{}', part='{}', full_requested_size={}, add_cols={}",
table, where, full_requested_columns.size(), additional_columns.columns());
}
catch (...) {}
auto dag = DB::evaluateMissingDefaults(
additional_columns, full_requested_columns,
storage_snapshot->metadata->getColumns(),
data_part_info_for_read->getContext());
if (dag)
{
dag->addMaterializingOutputActions();
auto actions = std::make_shared<ExpressionActions>(
std::move(*dag),
ExpressionActionsSettings::fromSettings(data_part_info_for_read->getContext()->getSettingsRef()));
actions->execute(additional_columns);
}
/// Move columns from block.
it = original_requested_columns.begin();
for (size_t pos = 0; pos < num_columns; ++pos, ++it)
{
auto name_in_storage = it->getNameInStorage();
res_columns[pos] = additional_columns.getByName(name_in_storage).column;
if (it->isSubcolumn())
{
try
{
const auto & part_storage = data_part_info_for_read->getDataPartStorage();
String where = part_storage->getFullPath();
String table = data_part_info_for_read->getTableName();
LOG_INFO(getLogger("VMTrace"),
"IMergeTreeReader::evaluateMissingDefaults(getSubcolumn): table='{}', part='{}', base='{}', sub='{}', base_type='{}', col_kind='{}'",
table, where, name_in_storage, it->getSubcolumnName(),
it->getTypeInStorage()->getName(),
res_columns[pos] ? res_columns[pos]->getName() : String("nullptr"));
}
catch (...) {}
const auto & type_in_storage = it->getTypeInStorage();
try
{
res_columns[pos] = type_in_storage->getSubcolumn(it->getSubcolumnName(), res_columns[pos]);
}
catch (Exception & e)
{
const auto & part_storage = data_part_info_for_read->getDataPartStorage();
e.addMessage(fmt::format(
"(VMTrace evaluateMissingDefaults getSubcolumn) table='{}', part='{}', base='{}', sub='{}', base_type='{}', column_kind='{}'",
data_part_info_for_read->getTableName(),
part_storage->getFullPath(),
name_in_storage,
it->getSubcolumnName(),
type_in_storage->getName(),
res_columns[pos] ? res_columns[pos]->getName() : String("nullptr")));
throw;
}
}
}
}
catch (Exception & e)
{
/// Better diagnostics.
const auto & part_storage = data_part_info_for_read->getDataPartStorage();
e.addMessage(
"(while reading from part " + part_storage->getFullPath()
+ " located on disk " + part_storage->getDiskName()
+ " of type " + part_storage->getDiskType() + ")");
throw;
}
}重新发布ClickHouse,我们看到对应的error依然在打印,看来我们有可能找到根本原因:
shell
2025.11.13 14:06:52.226098 [ 3854516 ] {8688ca72-3405-46db-b3d0-3fd6948e6996::20250901_90_169_3} <Information> VMTrace: IMergeTreeReader::fillMissingColumns: table='fat2_default.emo_mdm_flowwork_pt30m_local (8688ca72-3405-46db-b3d0-3fd6948e6996)', part='/clickhouse/store/868/996/8688ca72-3405-46db-b3d0-3fd6948e6996/20250901_90_115_2/', should_eval_defaults=true, cols=[host=null;tagGroup1.values(values)=set], partially_read=[]
2025.11.13 14:06:52.226114 [ 3854516 ] {8688ca72-3405-46db-b3d0-3fd6948e6996::20250901_90_169_3} <Information> VMTrace: IMergeTreeReader::evaluateMissingDefaults(pre): table='fat2_default.emo_mdm_flowwork_pt30m_local (8688ca72-3405-46db-b3d0-3fd6948e6996)', part='/clickhouse/store/868/996/8688ca72-3405-46db-b3d0-3fd6948e6996/20250901_90_115_2/', full_requested_size=2, add_cols=1
2025.11.13 14:06:52.226344 [ 3854516 ] {8688ca72-3405-46db-b3d0-3fd6948e6996::20250901_90_169_3} <Information> VMTrace: IMergeTreeReader::evaluateMissingDefaults(getSubcolumn): table='fat2_default.emo_mdm_flowwork_pt30m_local (8688ca72-3405-46db-b3d0-3fd6948e6996)', part='/clickhouse/store/868/996/8688ca72-3405-46db-b3d0-3fd6948e6996/20250901_90_115_2/', base='tagGroup1', sub='values', base_type='Map(LowCardinality(String), String)', col_kind='Map(Nothing, Nothing)'
2025.11.13 14:06:52.226619 [ 3854516 ] {} <Error> 8688ca72-3405-46db-b3d0-3fd6948e6996::20250901_90_169_3 (MergeFromLogEntryTask): virtual bool DB::ReplicatedMergeMutateTaskBase::executeStep(): Code: 49. DB::Exception: Bad cast from type DB::ColumnNothing to DB::ColumnLowCardinality: (VMTrace evaluateMissingDefaults getSubcolumn) table='fat2_default.emo_mdm_flowwork_pt30m_local (8688ca72-3405-46db-b3d0-3fd6948e6996)', part='/clickhouse/store/868/996/8688ca72-3405-46db-b3d0-3fd6948e6996/20250901_90_115_2/', base='tagGroup1', sub='values', base_type='Map(LowCardinality(String), String)', column_kind='Map(Nothing, Nothing)': (while reading from part /clickhouse/store/868/996/8688ca72-3405-46db-b3d0-3fd6948e6996/20250901_90_115_2/ located on disk disk1 of type local): While executing MergeTreeSequentialSource. (LOGICAL_ERROR), Stack trace (when copying this message, always include the lines below):
0. DB::Exception::Exception(DB::Exception::MessageMasked&&, int, bool) @ 0x000000000dafec3b
1. DB::Exception::Exception(PreformattedMessage&&, int) @ 0x0000000007e58fcc
2. DB::Exception::Exception<String, String>(int, FormatStringHelperImpl<std::type_identity<String>::type, std::type_identity<String>::type>, String&&, String&&) @ 0x0000000007e5adcb
3. _Z11typeid_castIRKN2DB20ColumnLowCardinalityEKNS0_7IColumnEQsr3stdE14is_reference_vIT_EES6_RT0_ @ 0x00000000081b00c4
4. DB::SerializationLowCardinality::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111aac90
5. DB::SerializationNamed::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111b6c9a
6. DB::SerializationTuple::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111f4fe2
7. DB::SerializationArray::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x000000001117e57d
8. DB::SerializationMap::enumerateStreams(DB::ISerialization::EnumerateStreamsSettings&, std::function<void (DB::ISerialization::SubstreamPath const&)> const&, DB::ISerialization::SubstreamData const&) const @ 0x00000000111b61c7
9. DB::IDataType::getSubcolumnData(std::basic_string_view<char, std::char_traits<char>>, DB::ISerialization::SubstreamData const&, bool) @ 0x000000001113ff6e
10. DB::IDataType::getSubcolumn(std::basic_string_view<char, std::char_traits<char>>, COW<DB::IColumn>::immutable_ptr<DB::IColumn> const&) const @ 0x0000000011140b68
11. DB::IMergeTreeReader::evaluateMissingDefaults(DB::Block, std::vector<COW<DB::IColumn>::immutable_ptr<DB::IColumn>, std::allocator<COW<DB::IColumn>::immutable_ptr<DB::IColumn>>>&) const @ 0x0000000012b453d2
12. DB::MergeTreeSequentialSource::generate() @ 0x0000000012b6ba36
13. DB::ISource::tryGenerate() @ 0x000000001303bafb
14. DB::ISource::work() @ 0x000000001303b807
15. DB::ExecutionThreadContext::executeTask() @ 0x0000000013054a47
16. DB::PipelineExecutor::executeStepImpl(unsigned long, std::atomic<bool>*) @ 0x0000000013049310
17. DB::PipelineExecutor::executeStep(std::atomic<bool>*) @ 0x0000000013048d28
18. DB::PullingPipelineExecutor::pull(DB::Chunk&) @ 0x0000000013058d97
19. DB::PullingPipelineExecutor::pull(DB::Block&) @ 0x0000000013058f99
20. DB::MergeTask::VerticalMergeStage::executeVerticalMergeForAllColumns() const @ 0x0000000012987747
21. DB::MergeTask::VerticalMergeStage::execute() @ 0x0000000012986b6e
22. DB::MergeTask::execute() @ 0x0000000012986322
23. DB::ReplicatedMergeMutateTaskBase::executeStep() @ 0x0000000012c50fa0
24. DB::MergeTreeBackgroundExecutor<DB::DynamicRuntimeQueue>::threadFunction() @ 0x000000001299f77d
25. ThreadPoolImpl<ThreadFromGlobalPoolImpl<false, true>>::worker(std::__list_iterator<ThreadFromGlobalPoolImpl<false, true>, void*>) @ 0x000000000dbd3649
26. void std::__function::__policy_invoker<void ()>::__call_impl<std::__function::__default_alloc_func<ThreadFromGlobalPoolImpl<false, true>::ThreadFromGlobalPoolImpl<void ThreadPoolImpl<ThreadFromGlobalPoolImpl<false, true>>::scheduleImpl<void>(std::function<void ()>, Priority, std::optional<unsigned long>, bool)::'lambda0'()>(void&&)::'lambda'(), void ()>>(std::__function::__policy_storage const*) @ 0x000000000dbd7791
27. void* std::__thread_proxy[abi:v15007]<std::tuple<std::unique_ptr<std::__thread_struct, std::default_delete<std::__thread_struct>>, void ThreadPoolImpl<std::thread>::scheduleImpl<void>(std::function<void ()>, Priority, std::optional<unsigned long>, bool)::'lambda0'()>>(void*) @ 0x000000000dbd6509
28. ? @ 0x00007fa54f1aa609
29. ? @ 0x00007fa54f0cf353
(version 24.8.4.1)我们在打印日志的时候,尽量往日志中添加尽可能多的上下文信息,比如数据库,表,part等信息,这样,我们可以轻松地从日志中通过grep的方式来获取一个完整的事件脉络。如果没有上下位,日志就变得难以分析。
从上面的日志,我们发现:
- 尽管是Vertial Merge,但是出问题的时候,居然是两列:
host和tagGroup1.values:
shell
<Information> VMTrace: IMergeTreeReader::fillMissingColumns: table='fat2_default.emo_mdm_flowwork_pt30m_local (8688ca72-3405-46db-b3d0-3fd6948e6996)', part='/clickhouse/store/868/996/8688ca72-3405-46db-b3d0-3fd6948e6996/20250901_90_115_2/', should_eval_defaults=true, cols=[host=null;tagGroup1.values(values)=set], partially_read=[]对应的代码是:
cpp
void IMergeTreeReader::fillMissingColumns(Columns & res_columns, bool & should_evaluate_missing_defaults, size_t num_rows) const
{
try
{
NamesAndTypesList available_columns(columns_to_read.begin(), columns_to_read.end());
DB::fillMissingColumns(
res_columns, num_rows,
Nested::convertToSubcolumns(requested_columns),
Nested::convertToSubcolumns(available_columns),
partially_read_columns, storage_snapshot->metadata);
should_evaluate_missing_defaults = std::any_of(
res_columns.begin(), res_columns.end(), [](const auto & column) { return column == nullptr; });
try
{
......
LOG_INFO(getLogger("VMTrace"),
"IMergeTreeReader::fillMissingColumns: table='{}', part='{}', should_eval_defaults={}, cols=[{}], partially_read=[{}]",
table, where, should_evaluate_missing_defaults, nulls, pr);
}
catch (...) {}
}先不考虑为什么VerticalMerge居然会同时处理两列,至少,从当前的日志,我们成功的解释了上面的这些疑惑:
- 为什么错误中会有LowCardinality : 因为出问题的时候的确有
Map的参与,所以,我们看到堆栈中出现的是对Map类型的类型转换错误; - 既然是Map参与,为什么会有缺列问题 : 因为出问题的时候的确有
host的参与,所以,should_evaluate_missing_defaults是true并且因此触发了后续的evaluateMissingDefault(...); - 为什么都是添加列以前的Partition出问题,以后的Partition不出问题 : 因为出问题的时候的确有
host的参与,所以,我们添加host列以前的Partition会报错,但是添加host列以后的Partition都不报错就变得可以解释,即,尽管在异常堆栈中我们没有直接看到我们所添加的列host,但是堆栈的触发原因的确与我们添加的host列有关;
第二次添加日志:什么时候多的这一列
所以,下面需要解释的,是为什么Vertical Merge居然会引入两列,这个是完全不符合VerticalMerge的基本原则的。我们讲过,Vertical Merge会对排序键进行horizontal merge,因此是一次性读取,但是对Gathering Column是一列一列进行的,无论是我们新添加的host列,还是已经存在的Map列,都是gathering column,不应该出现在同一个Merge任务中。
我们初步怀疑,有可能是的确是对某一列进行merge,但是,处于某种需要和特殊性,把另外一列给添加了进来。这就有两种可能:
- 本来是对Map.values进行Merge,但是出于某种原因(host在part中缺失?),必须把缺失的列添加进来?
- 这种情况的可能性较弱,因为我们添加的列有5列,这5列都是简单类型,且都设置了默认值,如果是这种可能,那么为什么只有host出现在日志中,而不是我们添加的所有列?
- 本来是对Host进行Merge,但是出于某种原因(host列在part中缺失),必须把另外一列(Map.values)添加进来
- 这种可能性稍微大一些。这可以解释成,Vertical Merge刚开始对
host列进行处理,由于某种原因,又增加了复合列Map,由于报错,Host后面的列都没有再处理了,因此我们在日志中只看到了Host相关的异常日志。这就要求我们确认,对于Part中缺失但是表中存在的列,VerticalMerge也会尝试进行Merge,即VerticalMerge所处理的列,是表中的列,而不是直接忽略在part中不存在的列。
- 这种可能性稍微大一些。这可以解释成,Vertical Merge刚开始对
但是我们还需要解释的是,为什么此次Vertical Merge会处理两列?
我们开始怀疑方法injectRequiredColumns()。
我们开始并不了解方法,因此一直认为,是当前正在Merge的是Map列,然后由于host列缺失,因此injectRequiredColumns()把host加了进来。但是,添加日志以后,我们发现,恰恰相反,是当前的 Vertical Merge列是host列,随后由于host列缺失而无法使用行数,因此需要再添加一列进来,因此就把tagGroup1.value这一列给添加了进来。上文在讲解代码的时候已经讲解过。我们这里只是讲解并分析添加的日志
我们添加日志以后的代码如下文所示:
cpp
NameSet injectRequiredColumns(
const IMergeTreeDataPartInfoForReader & data_part_info_for_reader,
const StorageSnapshotPtr & storage_snapshot,
bool with_subcolumns,
Names & columns)
{
NameSet required_columns{std::begin(columns), std::end(columns)};
NameSet injected_columns;
bool have_at_least_one_physical_column = false;
AlterConversionsPtr alter_conversions;
if (!data_part_info_for_reader.isProjection