视频35:50开始
之前springMVC学的内容
之前ssm
第四个视频一开始
之前ssm内容大纲:

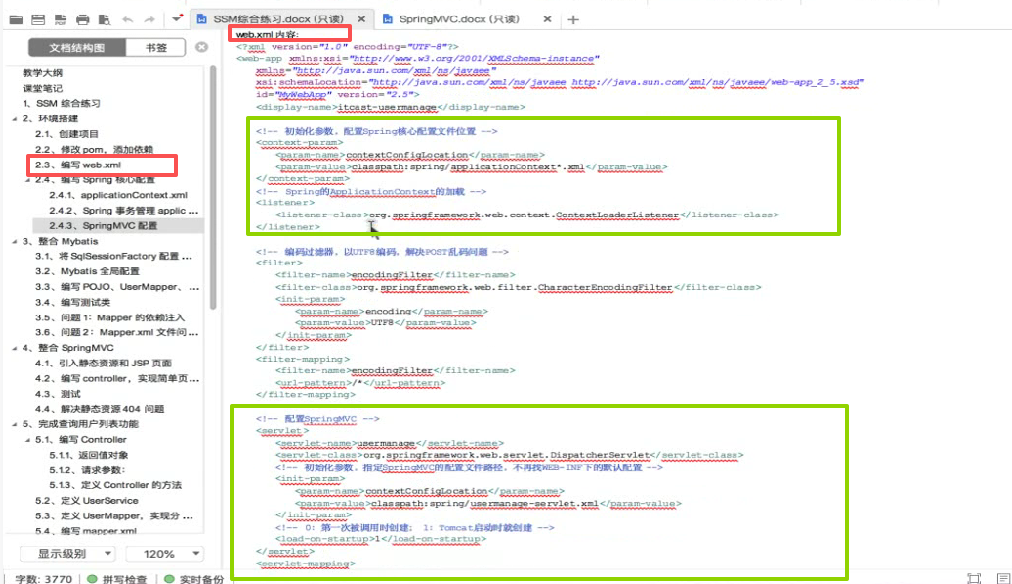
之前web.xml里面配置的内容:
1spring的配置,2乱码过滤器,3springmvc的配置:
springmvc主要配置了:
springmvc配置文件的地址,和启动时加载,和映射路径

之前applicationContext.xml里面配置的内容:
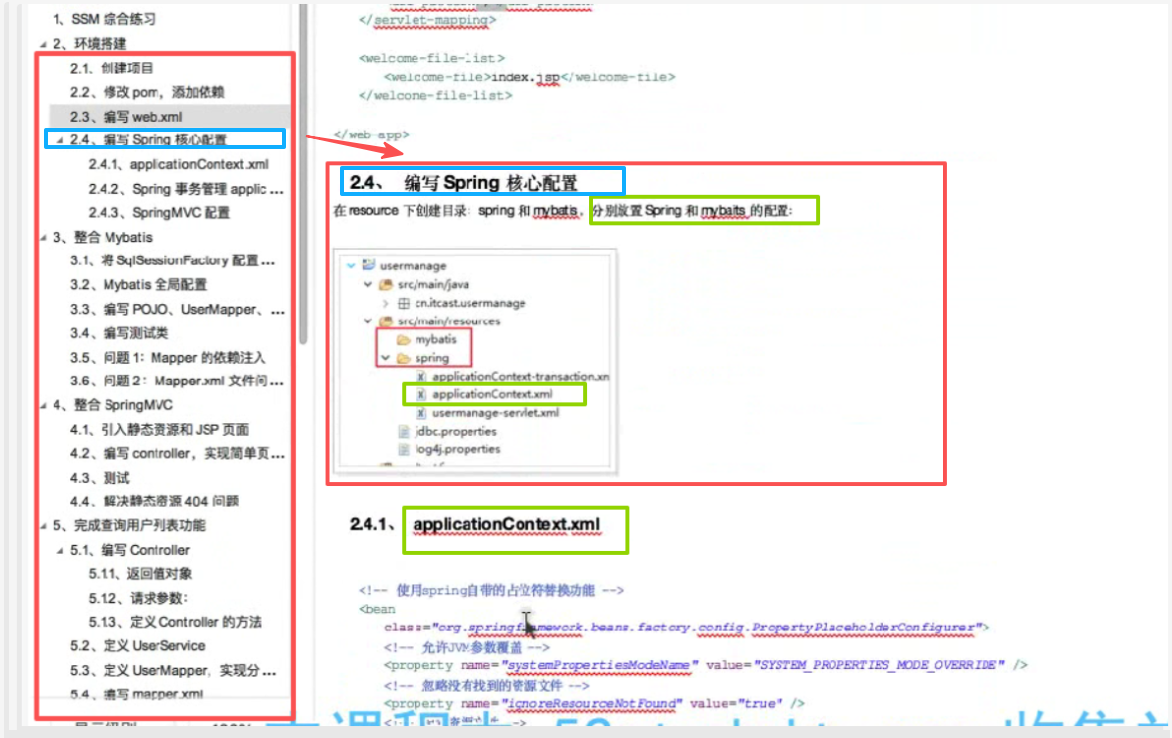
里面mybatis的配置
先配加载jdbc文件,再配连接池
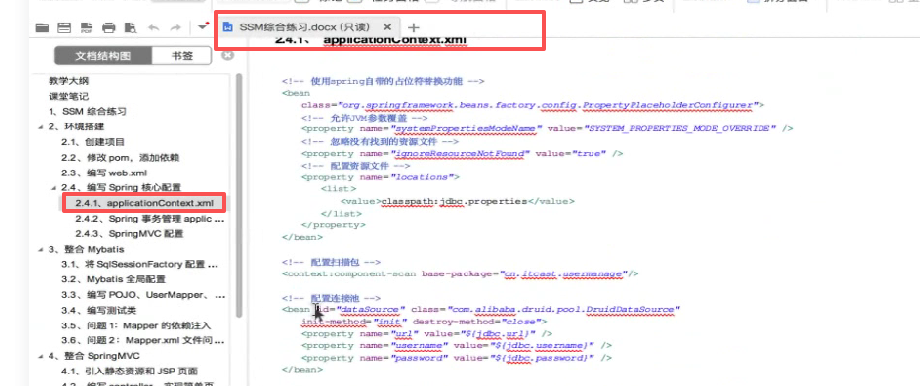
再配事务管理器:
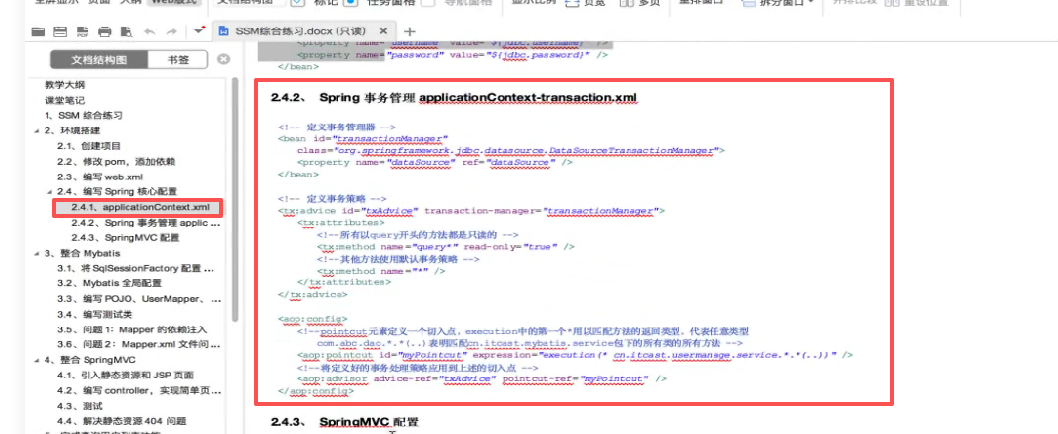
里面springmvc的配置:
第一个注解驱动 ,现在不用了 因为所有的都自动配置完成了。
第二个包扫描也不用了 ,因为注解@SpringBootApplication里面自带了@ComponentScan注解代替了Component-scan标签。
第三个视图解析器这个我们也不用了 因为我们从此以后都不玩jsp,因为我们现在前后端分离,后端只负责java代码,前端负责页面,后端返回的永远是json结构。
数据准备
表准备:
用他来实现一个简单的增删改查

写对应的实体类:
使用lombook的@Date注解
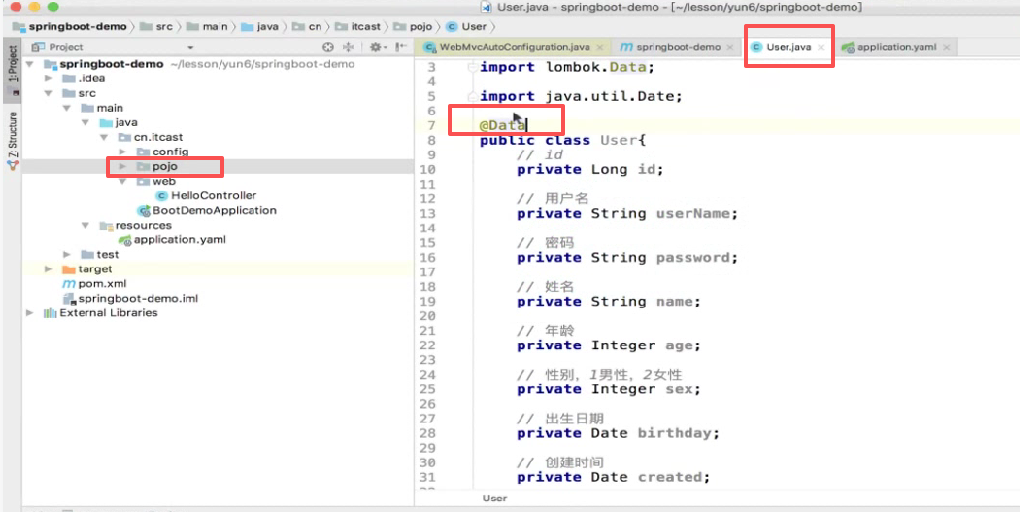

Lombok
lombok非常强大,它不光是能帮你生成get ,set方法,还有构造函数,hashcode和equals,他里面的注解非常非常多,这只是其中之一。
使用步骤
第一步:安装插件:

第二步:引入依赖:
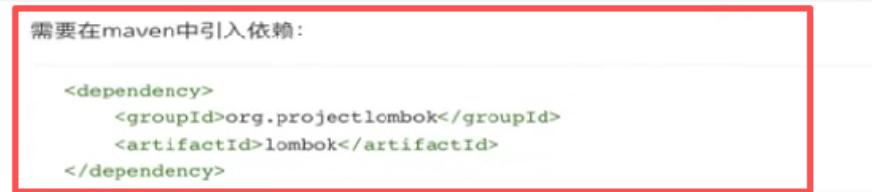
第三步:使用提供的功能对应注解:
提供的注解:
他还有日志相关方法@Slf4j,后天搭项目的时候给大家讲一下日志这块怎么去弄,现在先不说了,现在先知道有个Date注解就行了。

使用:

整合SpringMVC
上面数据准备好了以后,我们接下来是要去做整合了。
怎么做整合,咱们先从最简单的开始。
准备工程环境
之前咱们其实已经整合好了,他已经是springMVC了
咱们现在先这么做,把这项目之前写的咱先把他注释掉,因为你不注释等一会他就会报错,因为我们依赖引的druid连接池,这些都要给他删了
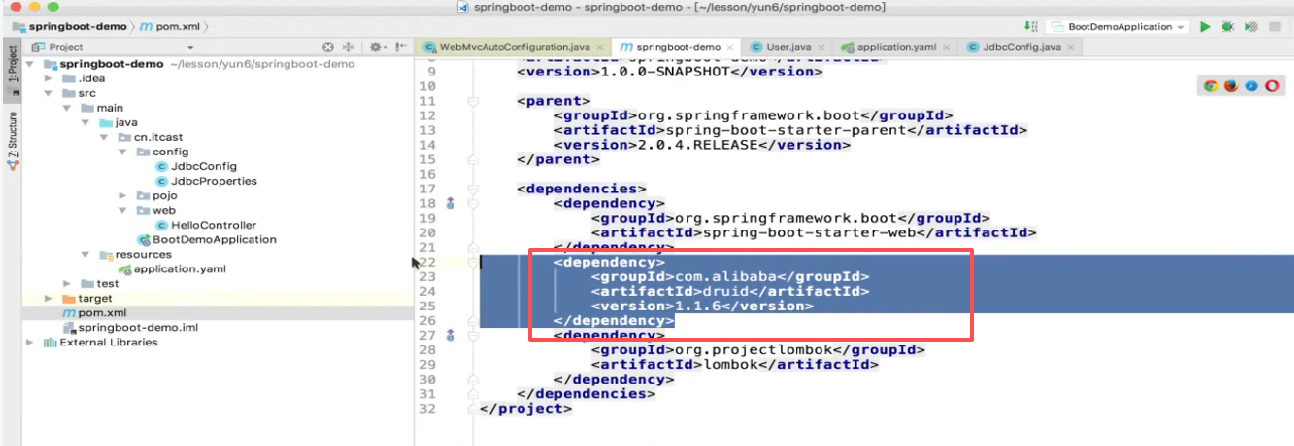
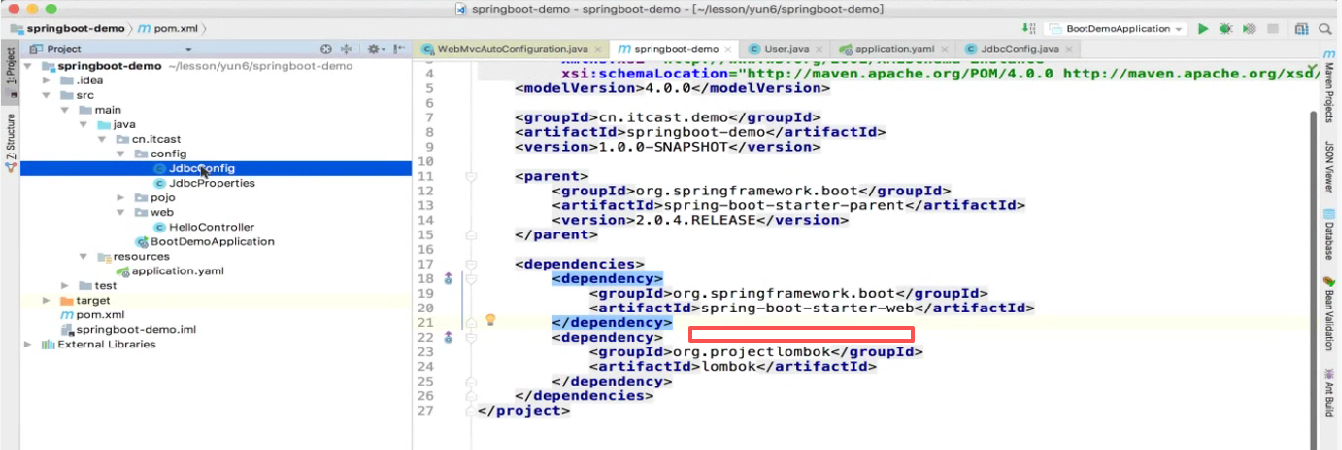
这些都要给他删了,因为我们现在要做个纯净的工程,这些都注释掉:
无非就是把这些属性注释掉而已也费不了多少事
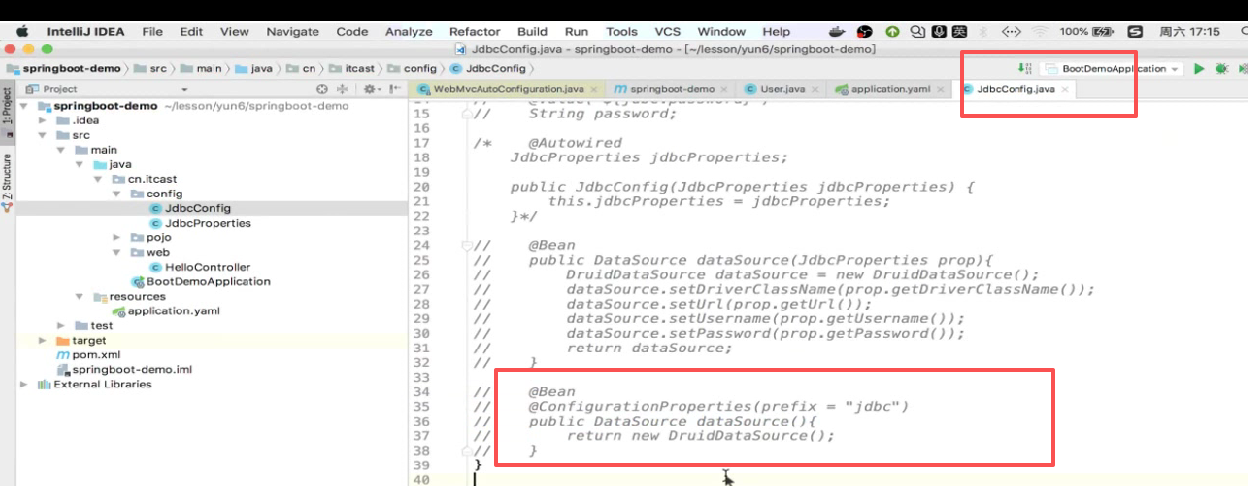
然后把这里也给注释掉
这样我们这个项目就比较干净了。
springmvc可改的配置
接下来我们玩springmvc主要玩什么呢,我给大家讲几个springmvc的配置就行了:
springmvc现在不需要配了的:
springmvc以前还配置什么东西:
注解驱动: 不用配了,自动配置全配了。
扫描包:不需要了,东西人家也都帮我们配好了。
jsp前缀后缀:
这个没弄过,但是这个要搞也很简单,这样就可以了:
但是这个我们不玩,因为springboot默认不支持jsp。也就是说你在这整jsp他访问不到,而且这个路径写web-info,这里没有web-info,他默认不支持jsp的。
springmvc拦截器:
web.xml里以前要配的东西
端口
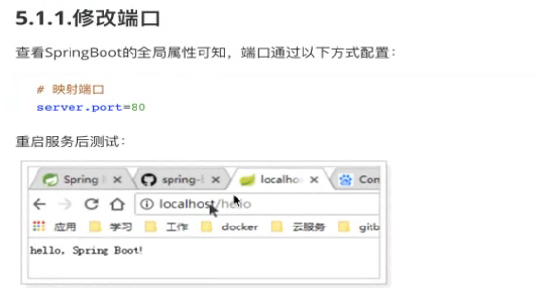
第一个是端口:
我们试试80行不行:
端口被占用了,被谁占用了不清楚

我们换一个8088:
启动成功:
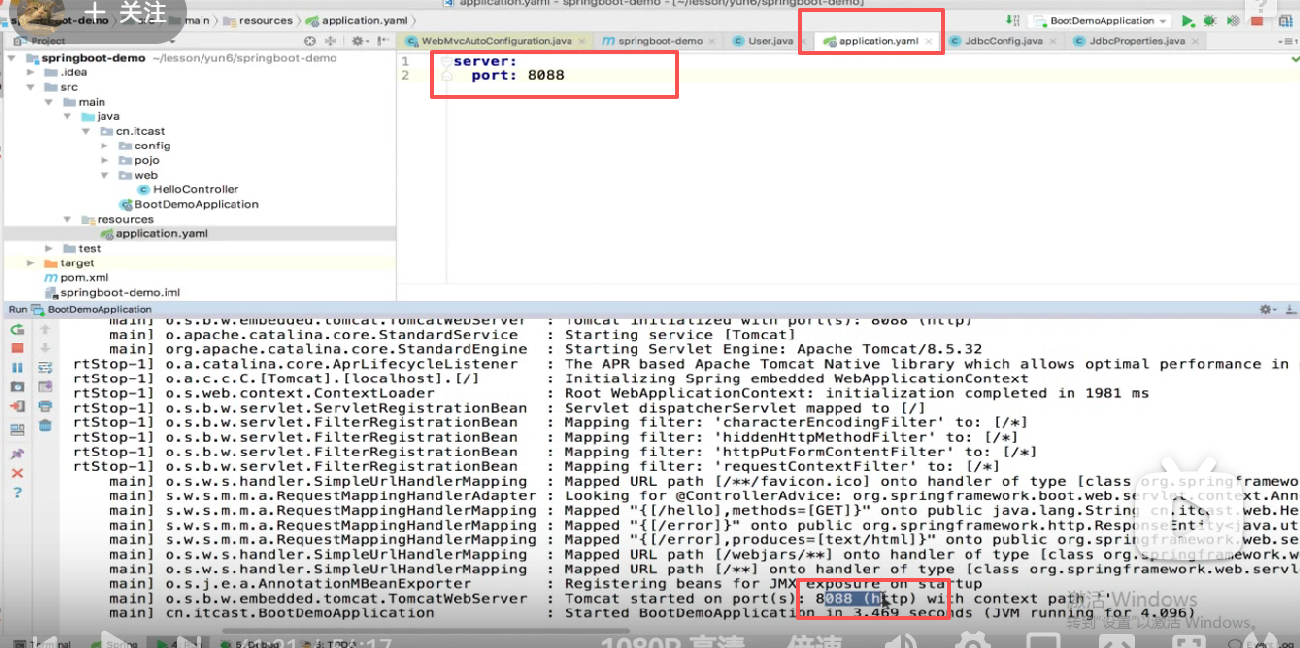
访问一下:访问成功

说明springmvc可以改端口。
dispather映射路径:
配置dispather映射路径:

默认是杠:/,杠拦截的是所有
意思我刚才写hello直接写hello就行了。

现在我们改成:*.html
注意这里不能直接写 :*.html ,因为在info中是不识别 * 的,得加上双引号把他变成字符串:

或者 * .do也行:以前玩过

重启一下:
看看写的映射路径:
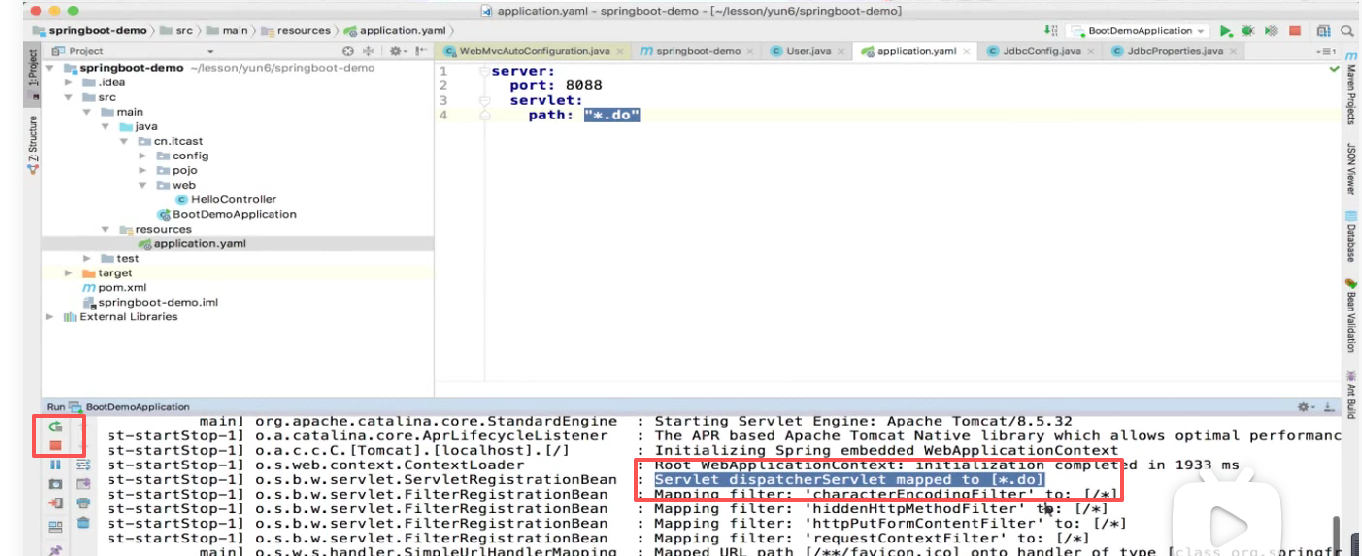
这样直接访问还是不ok的:
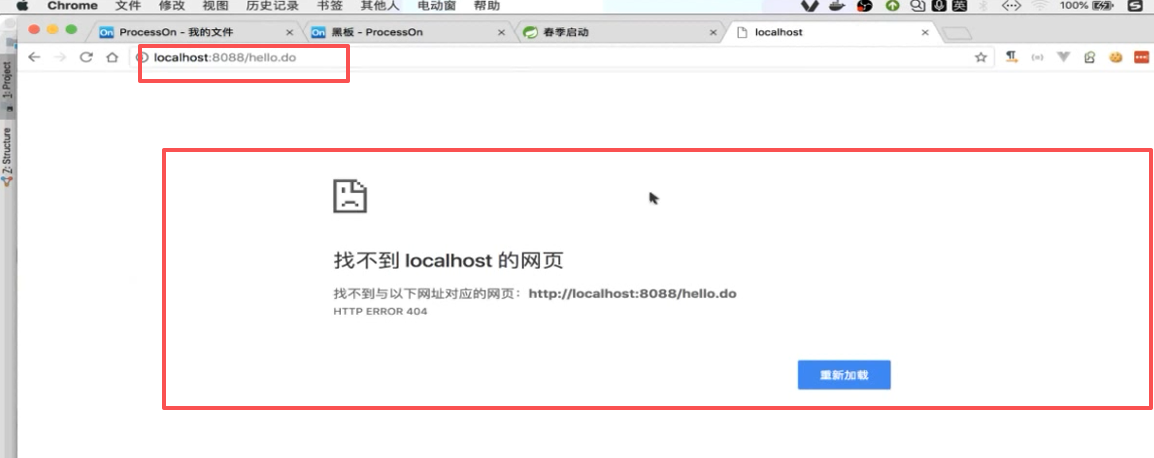
因为:
这里是.do,那你的映射路径现在:
也要是.do要匹配才行:
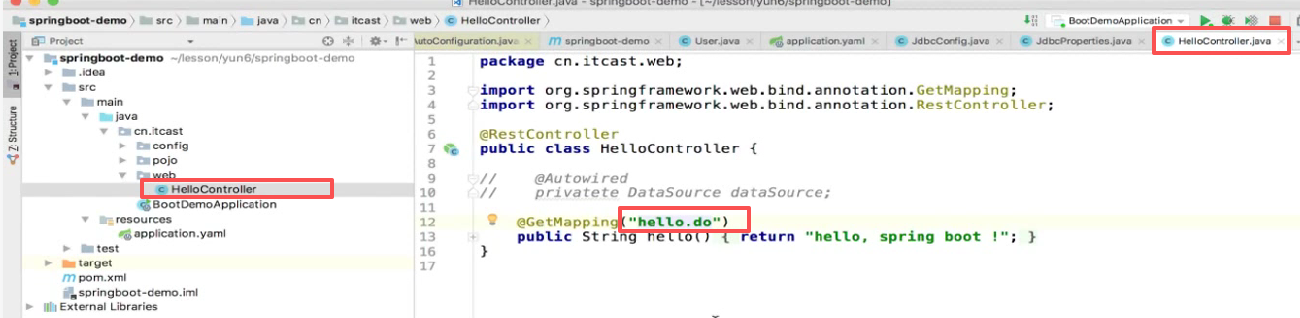
再启动:
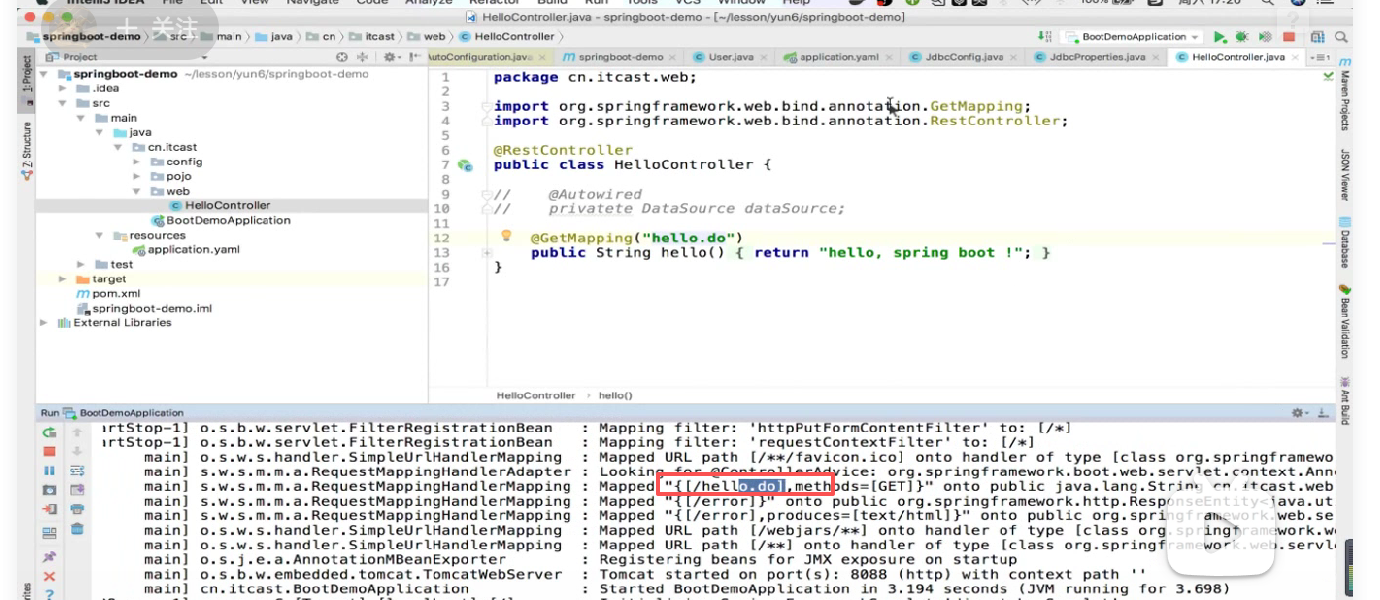
再访问一下:
hello再访问是不是就有问题了,要写成hello.do:
可以访问了

控制日志
日志级别要人为控制的,他默认写的都是info级别,你将来可能要改debug级别啊,或者什么其他的一些日志级别比如:error, warning, info, debug等等,是不是这么多。
那么这个日志级别一定要控制,而且控制的要很精细,因为将来你还要输出到文件吧,你们将来学大数据大数据处理的最重要的一个东西之一就是日志,有一堆日志文件给你,你们要去做处理啊做运算做分析这都要去做的啊,那这个日志的记录就很重要了。
那日志的级别怎么控制的呢:
直接改报错了:
属性绑定失败,人家要map,而你写的是字符串。
就是level这个变量是个map
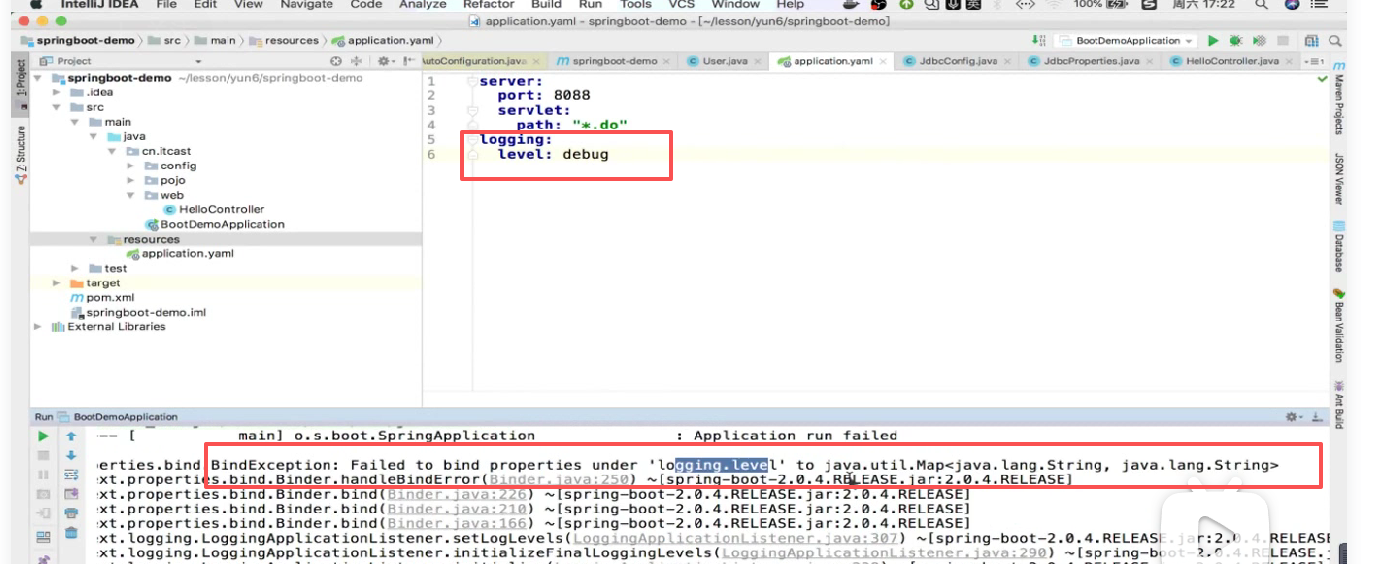
配置为map格式:
key是包名,值是级别。
就是可以控制精细到这个程度。
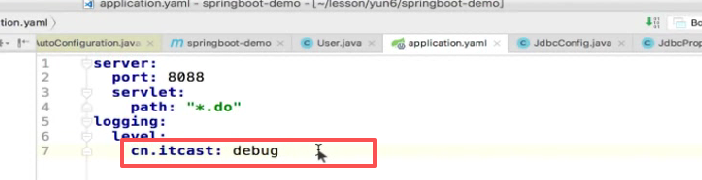
比如说我要把spring的级别调成这个:
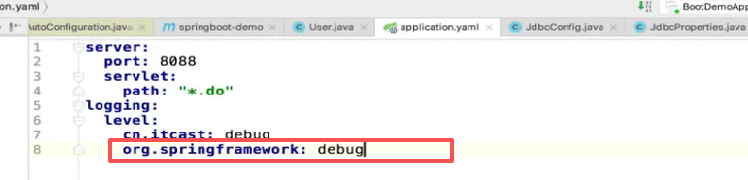
再启动:
发现刚才日志很少现在成堆的日志:
而且后面的信息都很详细,往下拉超级多看都看不完

访问静态资源
之前访问
咱们以前springmvc里面咱们玩的是web工程,那你的静态资源是直接放在webapp下面的,放webapp下面就可以直接浏览器访问了。
现在假如说我有个静态资源,我们现在是没有webapp的,那我们往哪放?
往resource里面放?
我们试下:
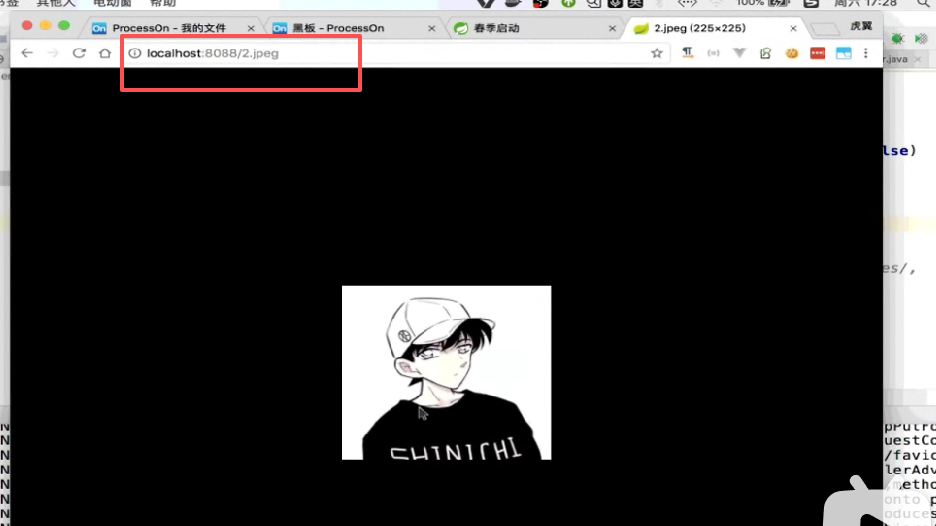
我们找个静态资源找个图片:
启动访问下:
进都进不去:

那可能是拦截路径问题,改下:
改成杠/:
日志太多不需要了也删掉
再启动访问下:
这回进到spring里面去了,刚才是连spring都没进,因为拦截的是.do,现在拦截杠是进spring了。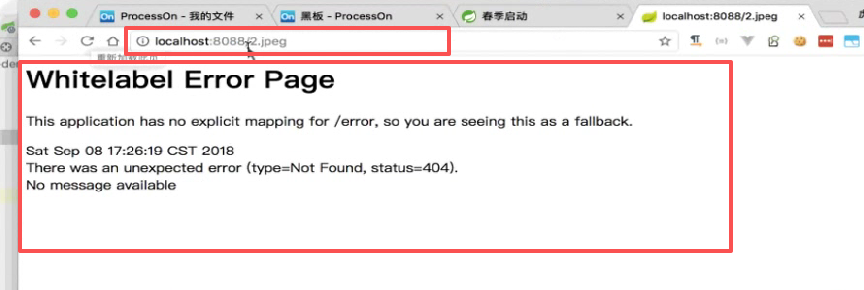
但是什么都没有,那怎么办:
现在访问
是这样的:
你现在是jar工程不是web工程没有webapp,你不能放到这里。
springmvc里面有个默认配置:
这里面读取了这么一个属性,我们刚才读了两个属性:

resource是资源,跟进去:
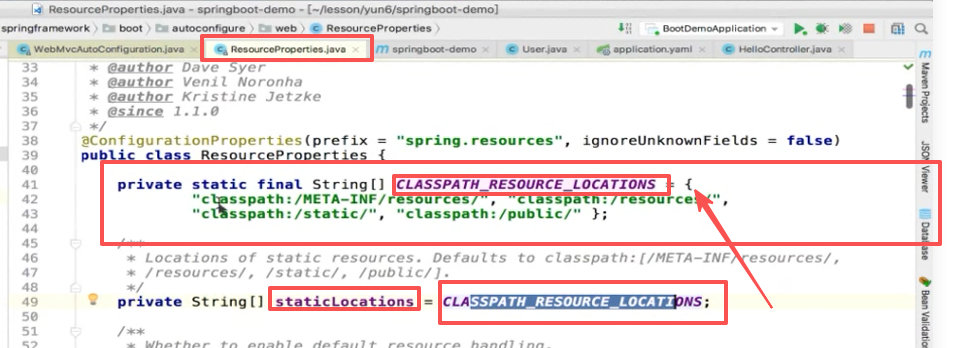
资源属性配置的就是你的静态资源属性,可以看下默认静态资源去哪找的:
classpath下的META-INFO下的resource
或者是classpath下的resource
或者是classpath下的static
或者是classpath下的public
这四个都可以
说明:
这个resource不是这个哦,这个resource本身就是classpath,是两码事。

所以一般情况下resource的容易产生冲突,我们习惯性用static:
新建一个static,然后把静态资源扔进去:
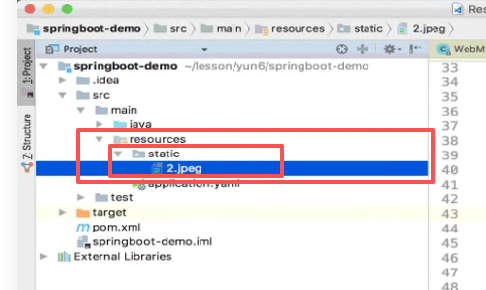
再启动访问:
可以了:
!!!注意:
处理是这么处理,但是现在开发讲究前后端分离,前端完全是前端工程,后端完全是后端工程,后端不管静态资源。
所以如果我们做纯粹的前后端分离开发,这种用法根本就用不到,因为后端只提供java代码只提供接口,明白我意思吧,是这么去开发的。
所以这个只是给大家提一嘴,你知道就行了。
拦截器
以前写的:
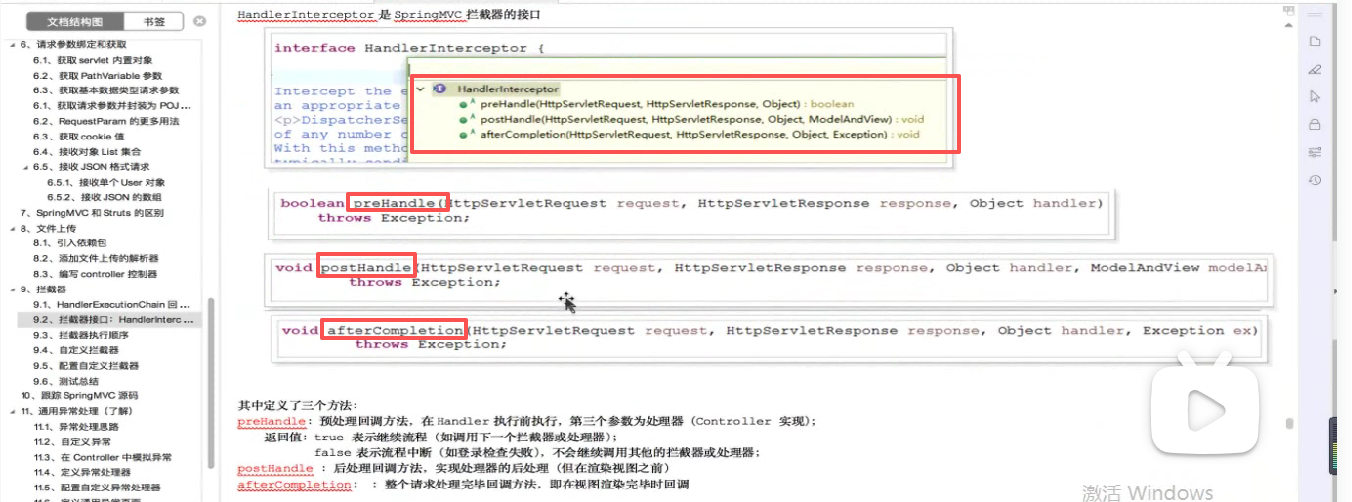
springmvc的HandlerInterceptor就是他的拦截器。
以前第一步 :
要实现一个接口HandlerInterceptor,然后实现三个方法:
前置,后置和最终
前置方法返回true代表放行,返回false是拦截。
第二步 :自定义拦截器:
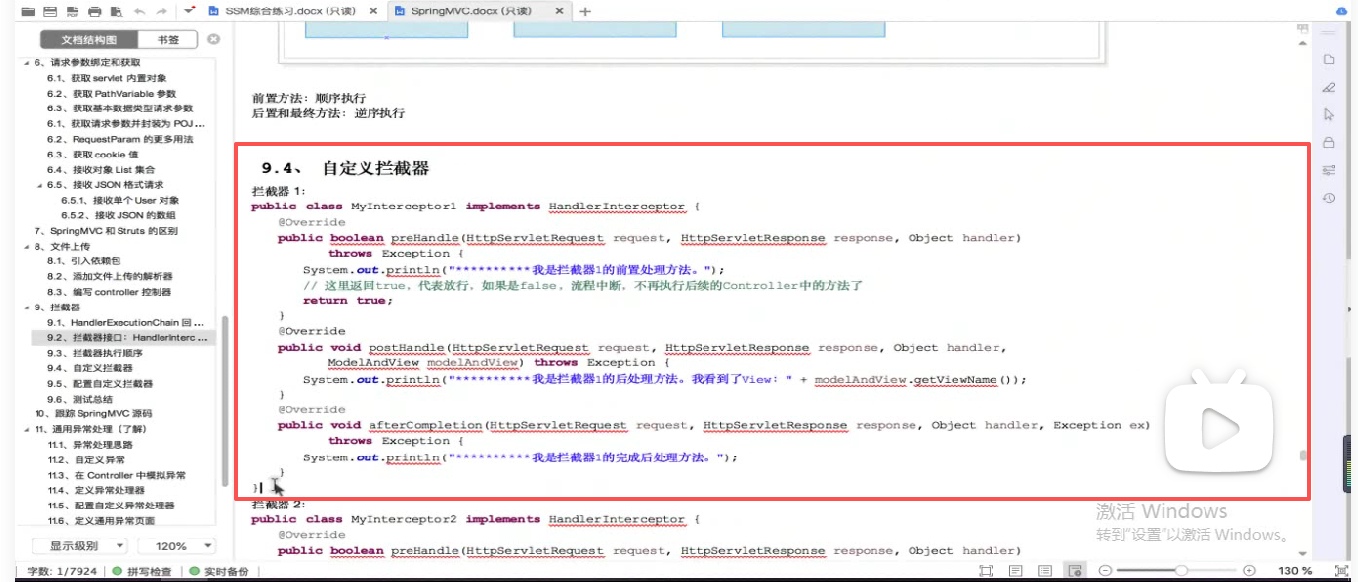
第三步 :

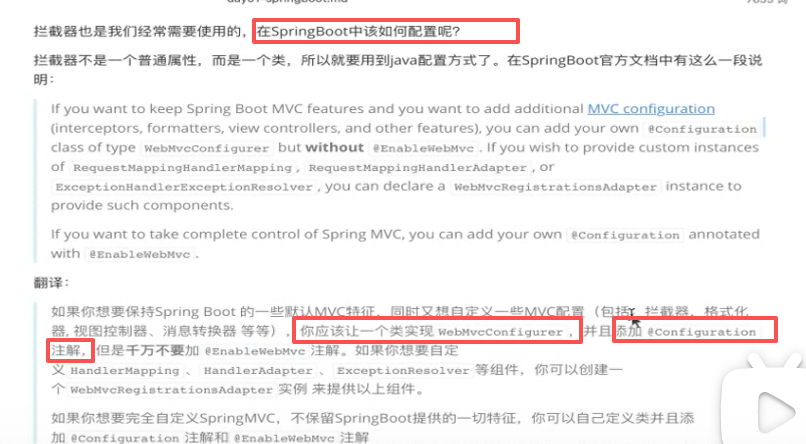
现在
仍然要实现接口,自定义拦截器:
第一步 :新建一个类,仍然要实现接口:
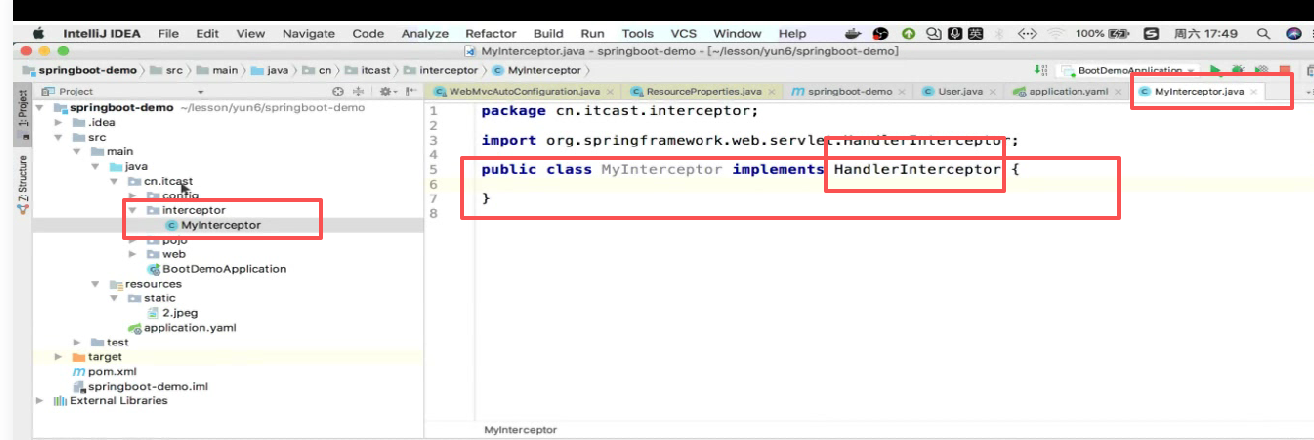
第二步 :仍然同样要实现三个方法:
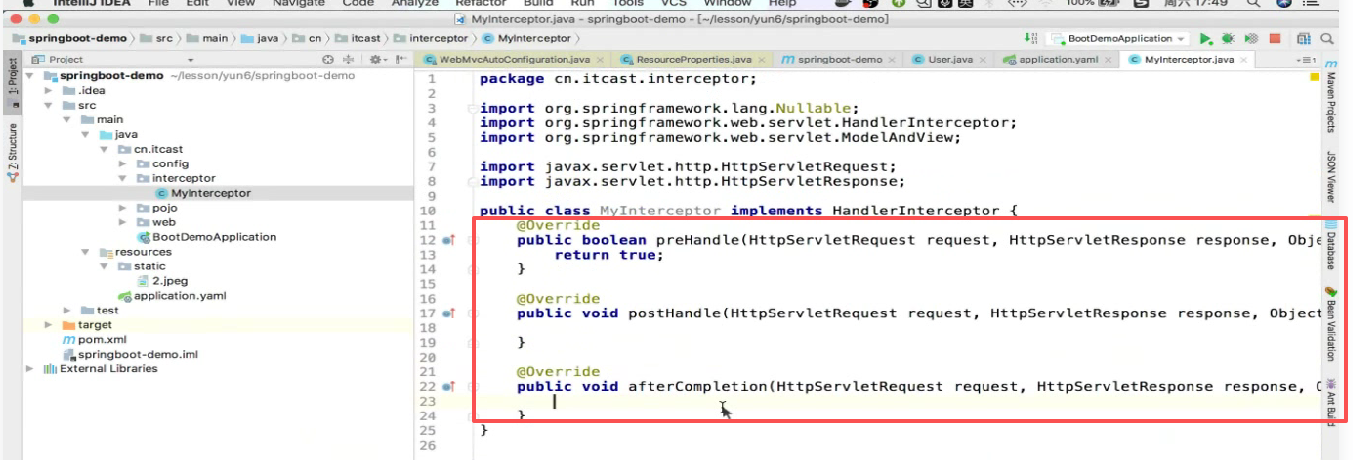
第三步 :写点东西:
这里使用log4j记录日志:
记录内容详情见下面记录日志小节
第四步 :仍然要配置拦截器
意思写个类实现接口,完了加个注解就行了:
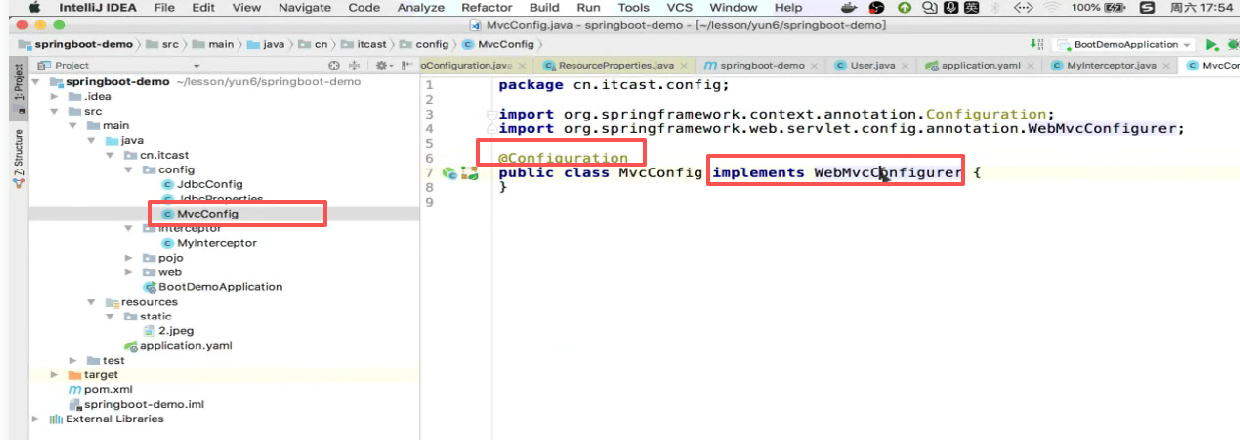
为什么说实现这个接口就配置拦截器了呢,进去这个类看下:
下载源码,然后看类的结构:
看方法名发现:
内容协调器,ServletHandling servlet处理器,拦截器,配置视图解析器,配置消息转换器,异常处理器等这里面全都有,这就是springmvc的高级配置类。
我们现在要配置拦截器:只需要实现addInterceptors()就可以了
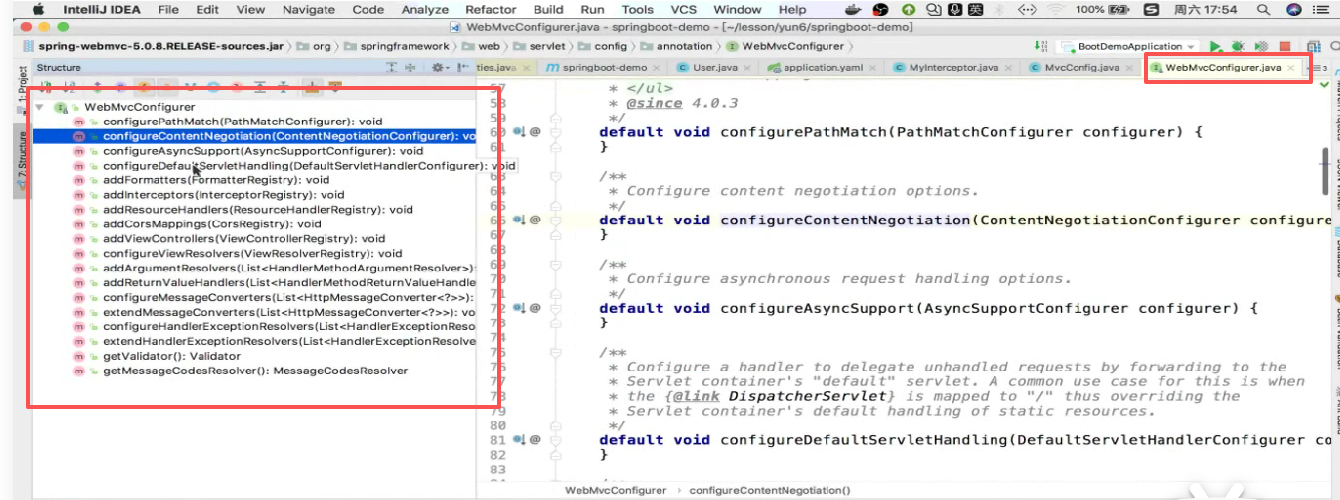
实现addInterceptors ()方法:
当spring扫描到@Configuration注解以后,就会调用addInterceptors()方法,并且把参数传进去
然后我们就用这个变量调用addInterceptor()方法添加一个拦截器:
怎么添加:最简单就是直接new了
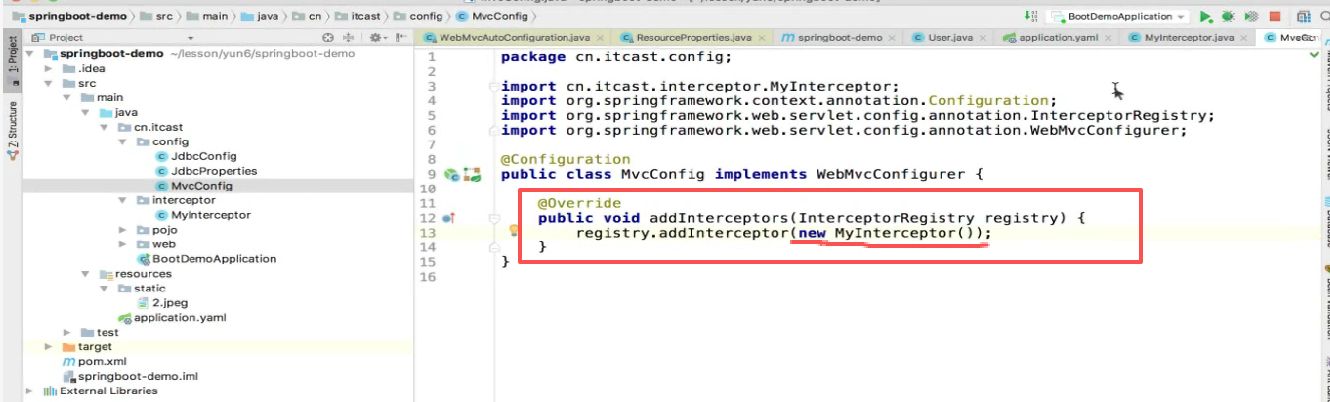
第五步 :配置映射路径
继续调用这个路径匹配方法:

这里配置/** :拦截一切路径
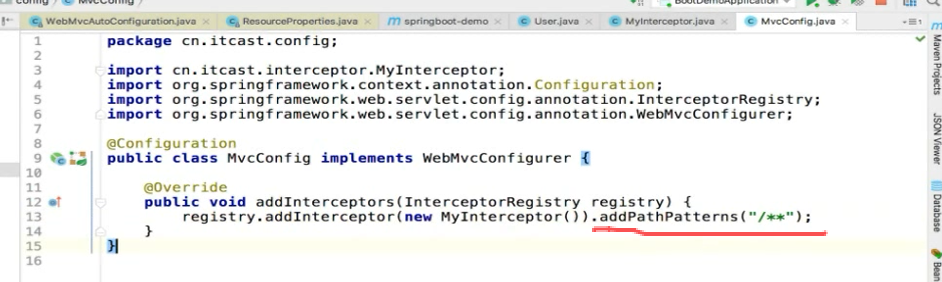
至此拦截器就生效了。
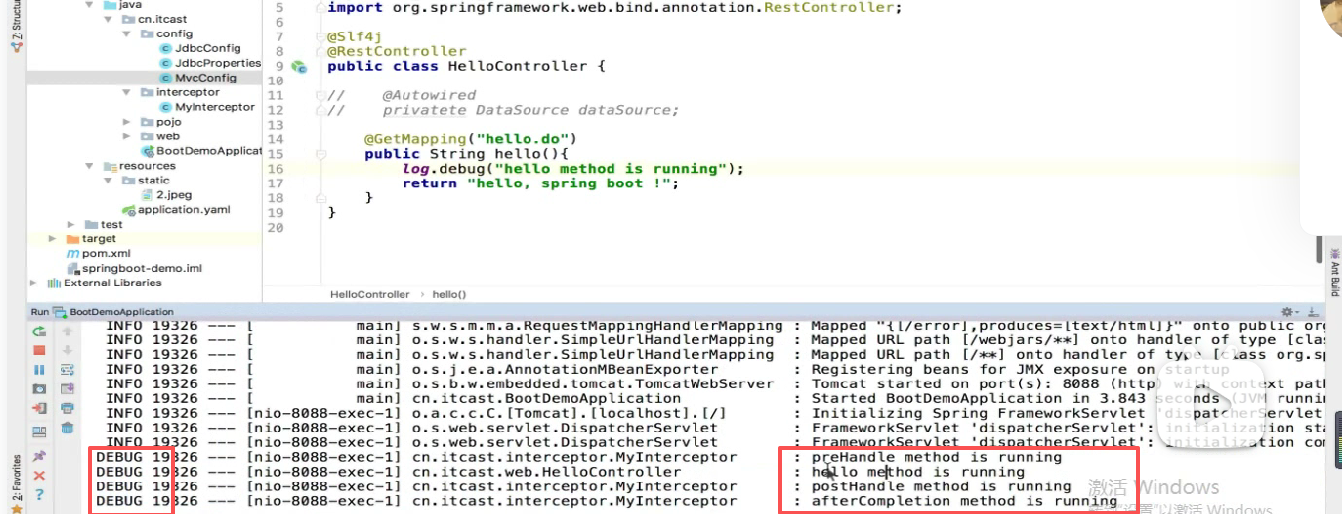
最后 :重启访问
成功:

查看日志:
使用log4j打印的一样很专业 ,级别,进程号,线程号,我们打印的内容都有。
自己打印的很low。
然后可以看到日志输出的顺序就是完全符合拦截器的执行顺序。
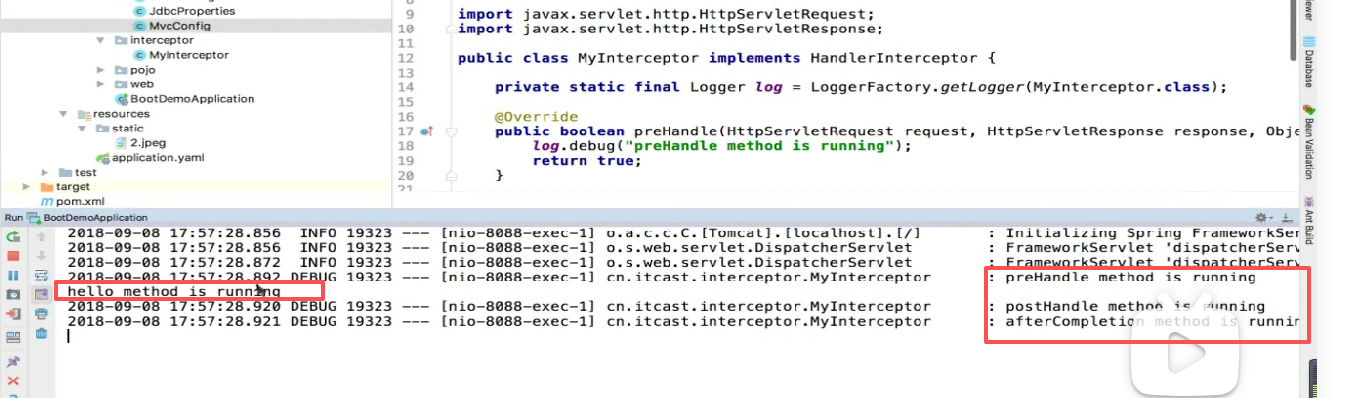
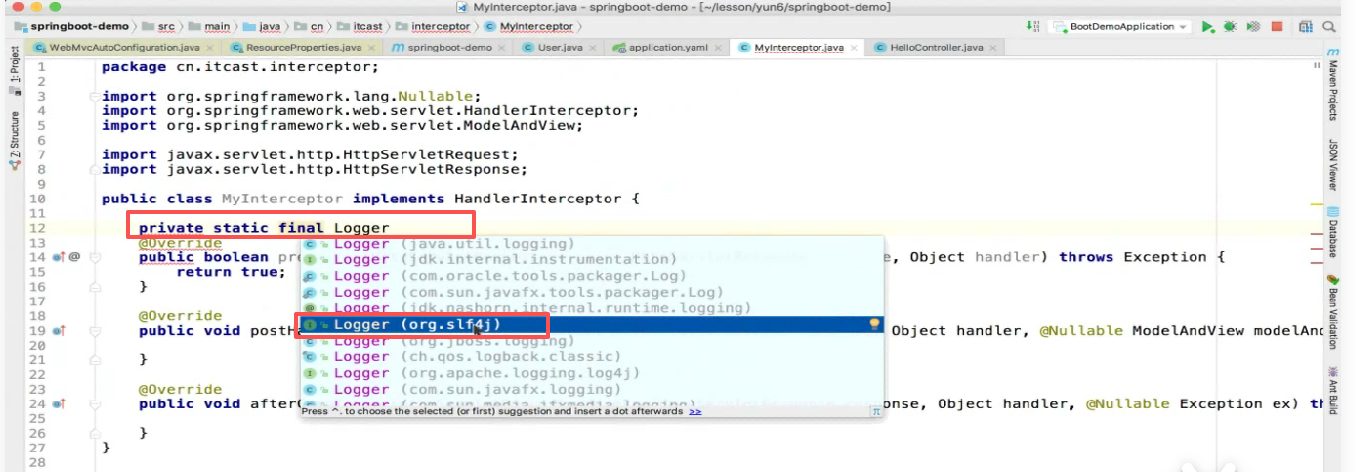
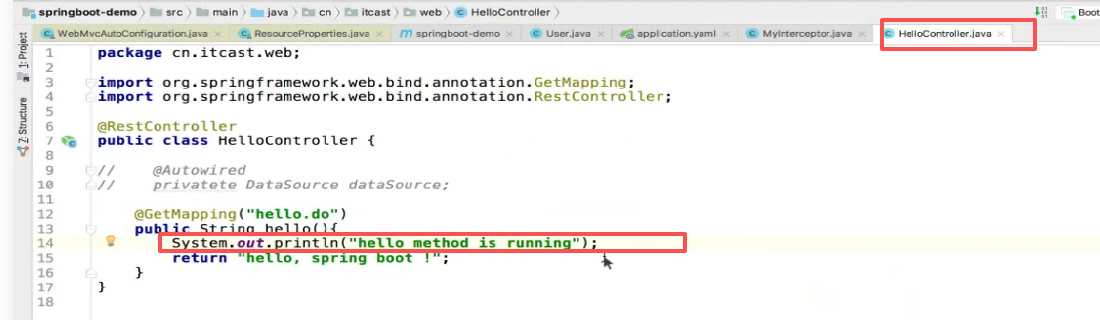
使用log4j记录日志
第一步 :给log4j里面的Logger对象整出来:
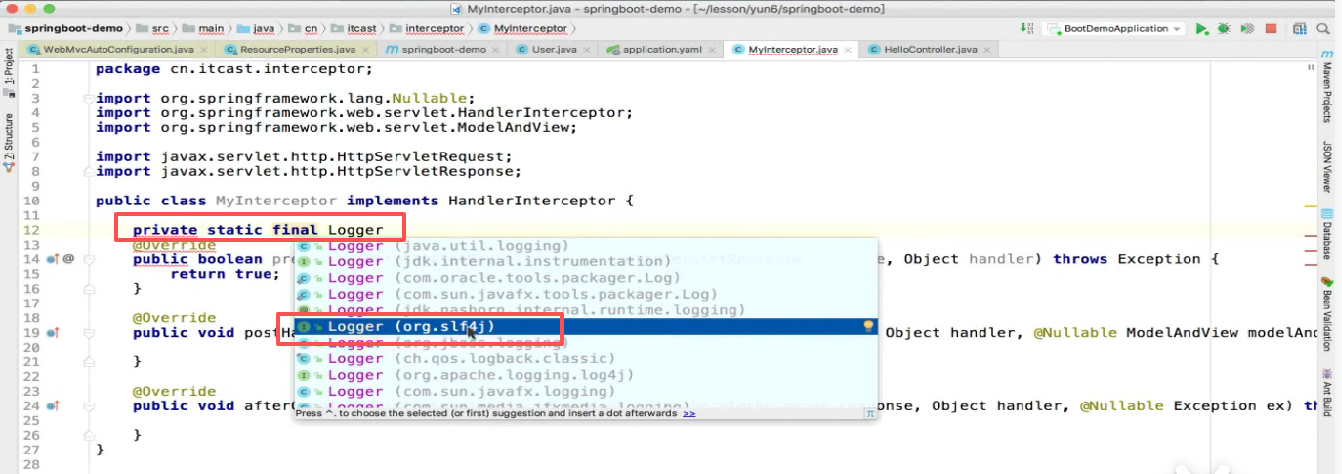
log对象是个记日志的对象但是不需要我们去new,而是使用了工厂模式:

发现他要传一个class,class就是这个类的名字:
以后写日志都需要这么一个类:

!!原因:
可以发现spring里面自己记日志是怎么记的:
时间戳,级别,进程号,线程,类名:
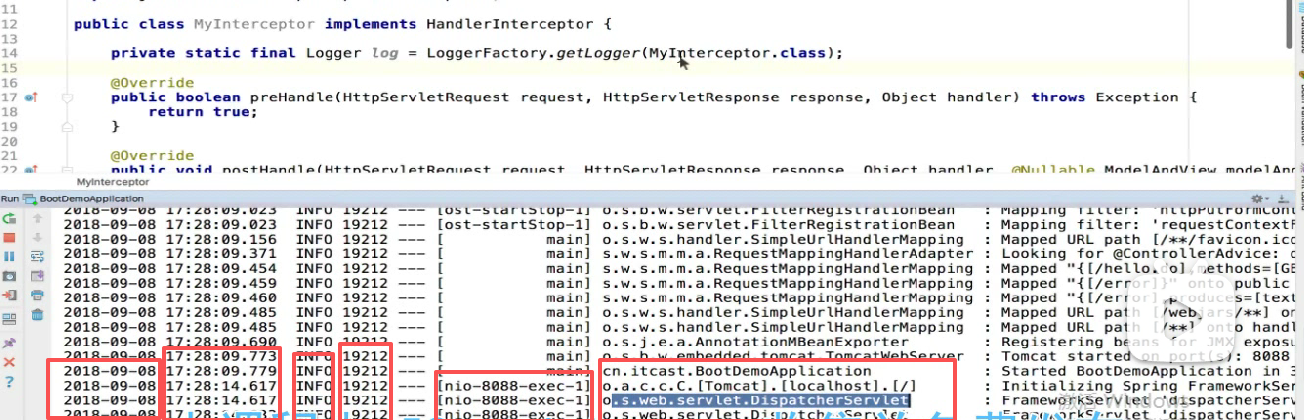
所以你记日志一定要记是哪个类记的日志,所以我们把这个类传给他他就知道是哪个类在记日志了。
第二步: 记录日志:
用log对象,log里面把日志级别分成了好多种,刚好就有很多方法,比如说info,debug,error,warn等等
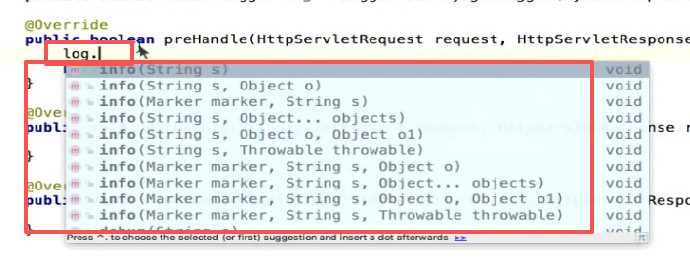
我们可以记debug级别,因为我们日志级别现在调的是debug级别,所以日志可以打印出来可以看见:

于是打印:
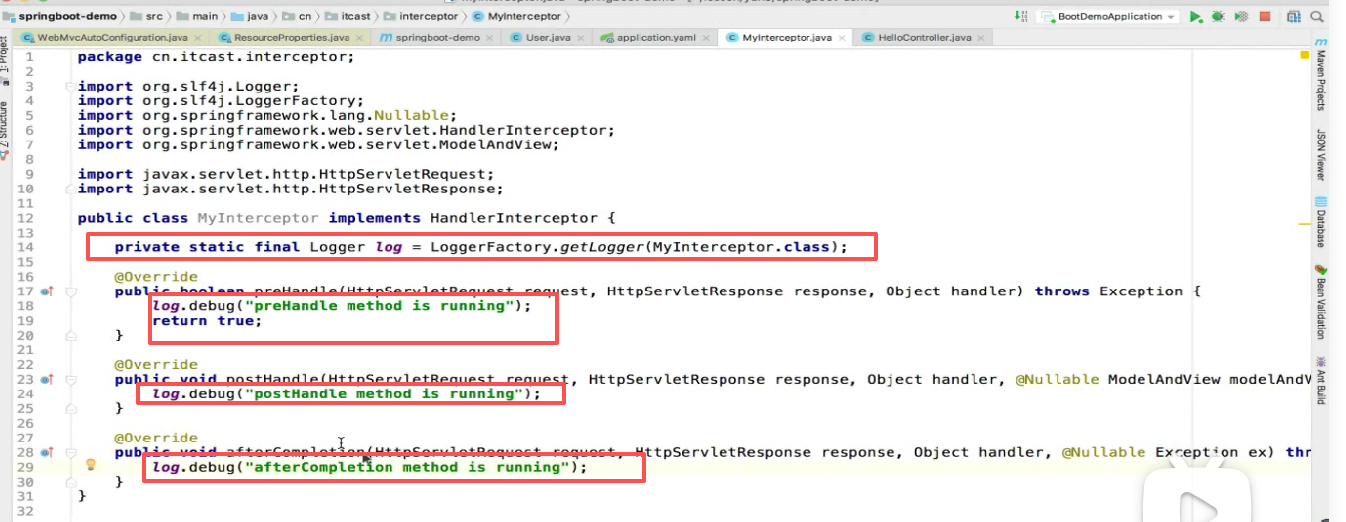
为了看起来清晰,在这也记录下也打印一行:
对比一下打印和日志看起来哪个更好
lombok优化日志
上面打印日志的时候有个麻烦点:
每次都要new这个

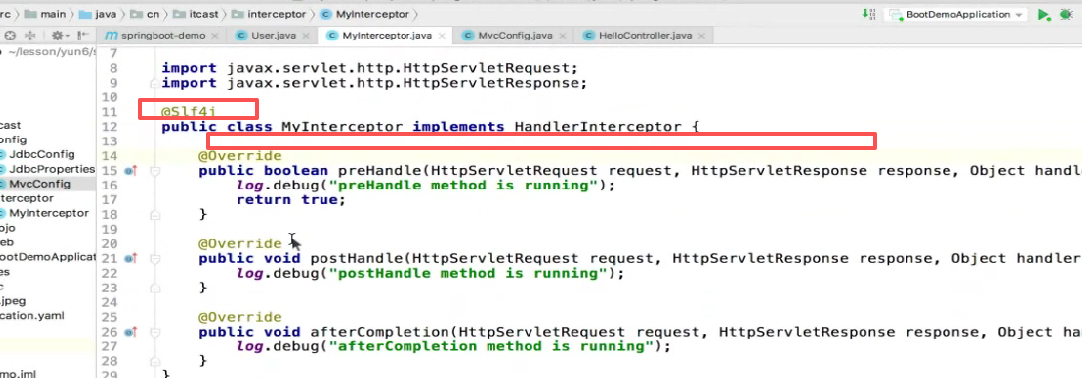
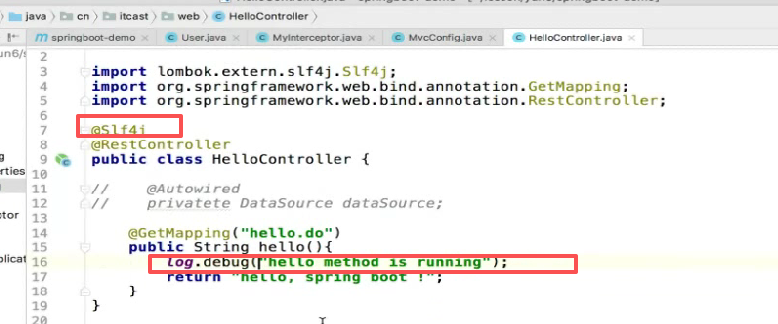
使用lombok:
加上@Slf4j注解,再把new的删了,发现下面的log对象没报错
因为@Slf4j注解会自动给你声明log变量,而且就叫log
哪个类需要打日志在哪个类上写就行:
运行调试:
整合jdbc和事务
视频四15:00
jdbc的话,要做的事情很简单就是要配置数据库连接池
以前
连接池的产品
连接池有很多:c3p0,druid
druid的优势:具有监控功能,可以监控每一条sql的执行总数,最大并发数,总耗时,平均耗时,读取行数等等,通过这个可以找到一些比较垃圾的sql,就是耗时速度比较长的,访问频率比较高的那种,证明这个sql写的有问题需要进行优化,是阿里巴巴的产品
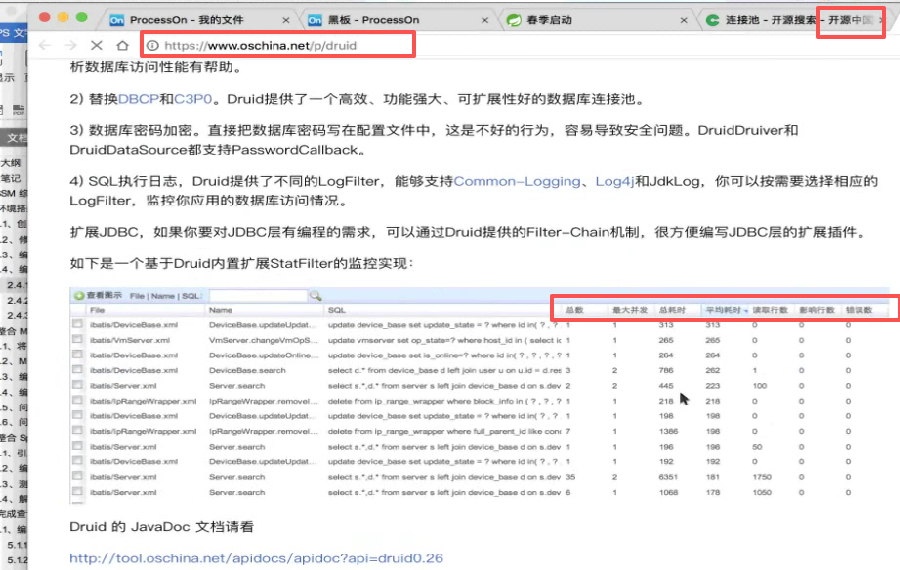
从速度上来讲,druid不占特别大的优势。
速度最快的产品是:追光者HikariCP
日本人写的
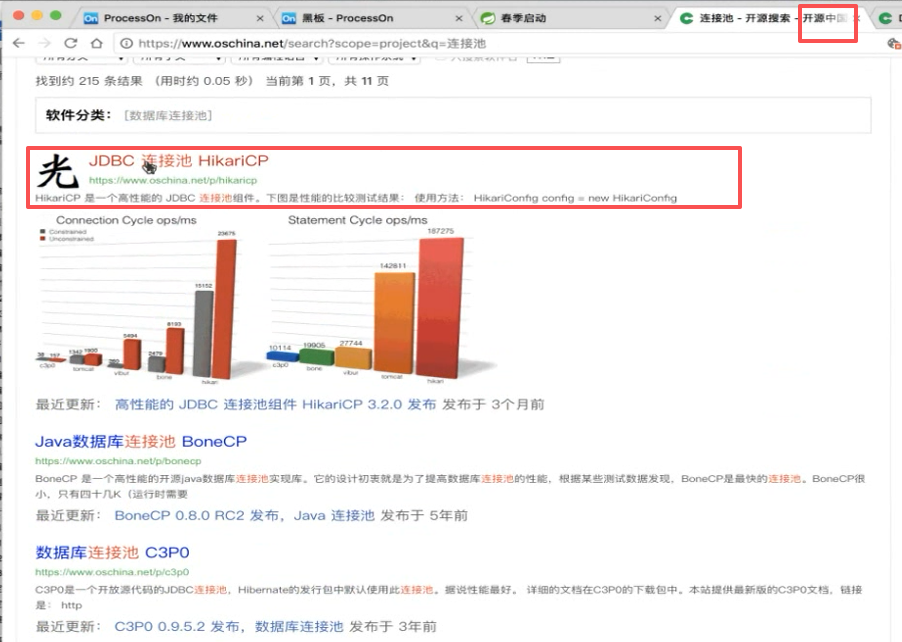
速度非常快,可以看下对比:
ops是每秒并发量:可以发现差的很远,c3p0跟这个没法比,因此现在企业大部分都在用这个HikariCP。
因为他速度非常快,不管企业用不用,spring已经默认支持HikariCP了,就是说你什么都不引,他已经支持HikariCP了。

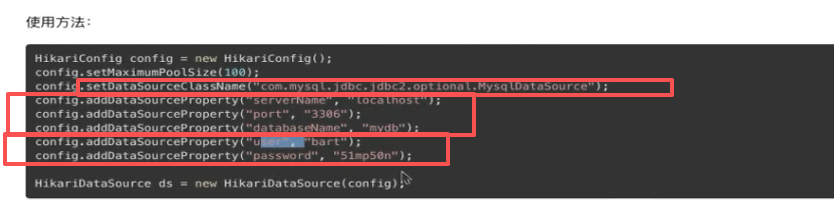
使用:
可以发现和别的一样是四大参数:
驱动,url,用户名和密码
完全一样,最多就是要配一下最大连接数,最大空闲连接,什么空闲时常配置这些东西。
由于我们要追求性能,我们使用HikariCP
一定要去找性能强的。
整合HikariCP
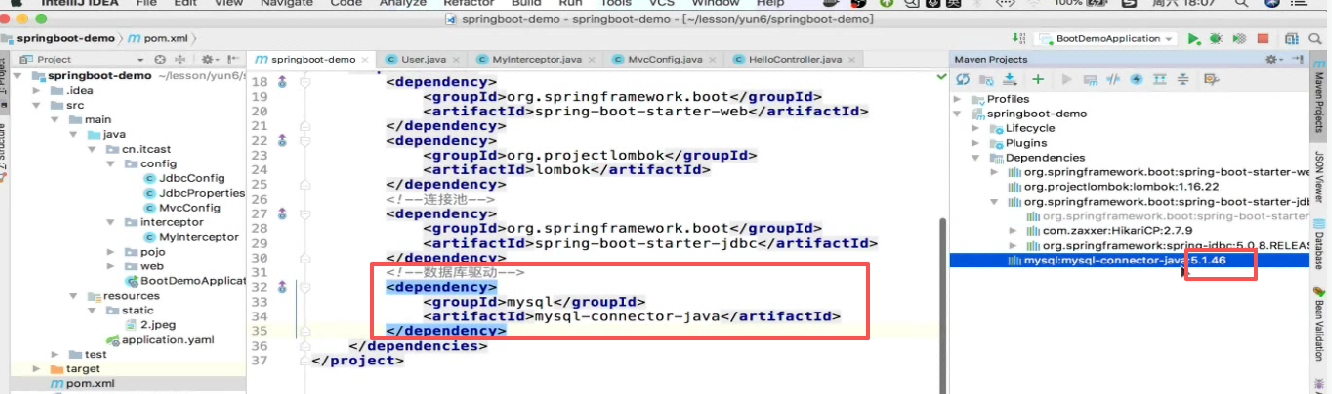
第一步:引入依赖
不需要引入追光者依赖,因为spring已经默认支持了。
你需要引spring的东西,是jdbc:
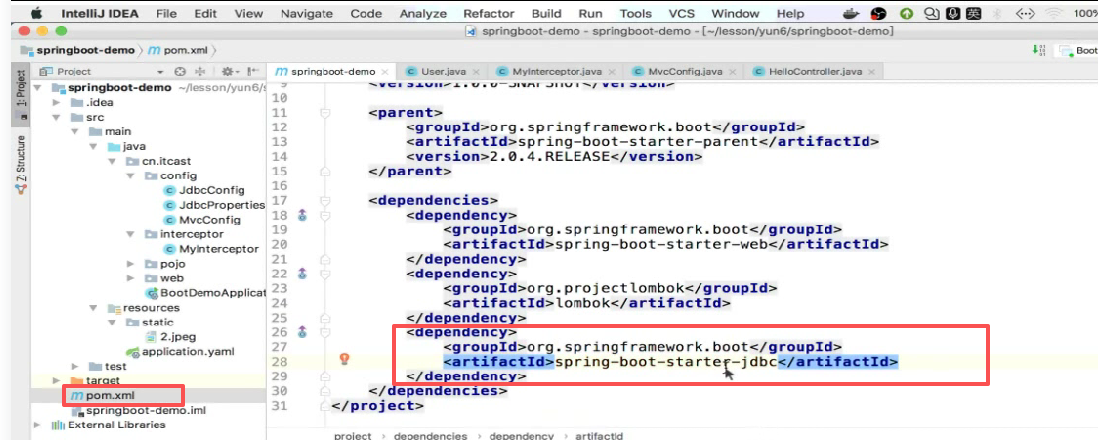
可以发现已经默认支持了:
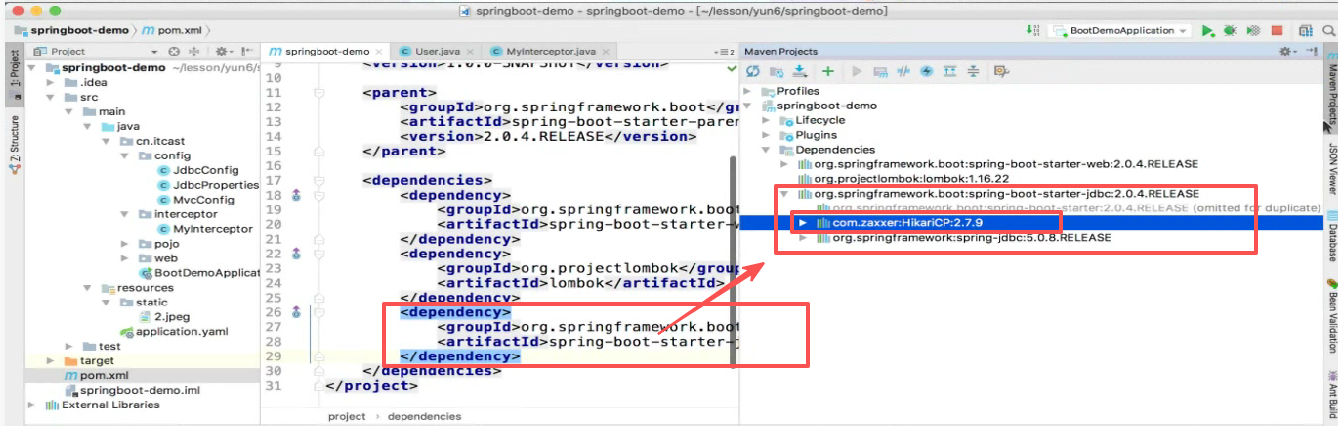
第二步:配数据库驱动
但是你要连接什么数据库,连接池是不知道的
所以还要配数据驱动 :
没有给版本,查看下他给的版本5.1.46: