引言:当你的 AI 变成了"复读机"
你是否经历过这样的崩溃时刻:
你在本地部署了一个 7B 参数的小模型(如 Llama 3, Falcon, Qwen 等),试图用它来处理业务逻辑。为了保证回答的严谨性,你小心翼翼地把 Temperature(温度)降到了极低(0.01),把 Top_P 设为 0.1。你认为这样能让模型"如履薄冰",只说实话。
然而,结果却是灾难性的。模型不仅没有变得精准,反而陷入了诡异的死循环:
"建议您联系物业...建议您联系物业...建议您联系物业..."
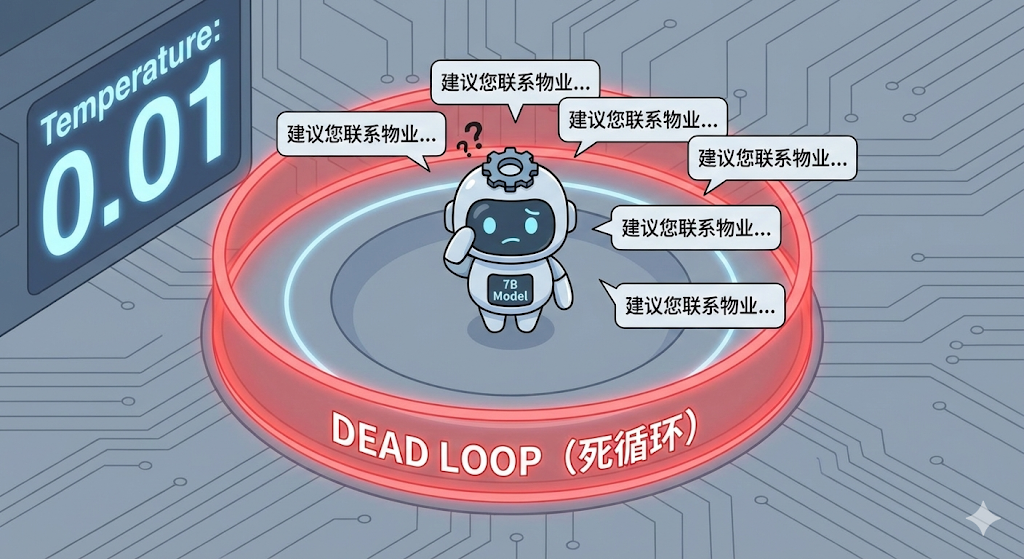
一个请求发出去,后台 CPU 狂转,十几分钟后才吐出一篇满屏重复的废话。
为什么我们为了"精准"而设的参数,反倒把模型逼疯了?对于 7B 这种小参数量模型,解决死循环的钥匙,其实藏在 llama.cpp 底层那个鲜为人知的 Sampler Chain(采样流水线) 里。
本文将带你从 Logits 走到 Dist,彻底解构大模型是如何决定"下一个词"的,并给出终结死循环的"核武器"级配置。
一、 现象解析:为什么小模型容易"鬼打墙"?
死循环(Repetition Loop)通常表现为两种形式:
- Token 级复读 :
the the the the... - 逻辑级复读:不断重复同一句车轱辘话,虽然语法通顺,但逻辑无法推进。
核心原因:确定性的陷阱
对于 7B 级别的模型,其知识密度和逻辑推理能力不如 70B 或 GPT-4。当遇到逻辑两难(例如:System Prompt 禁止它联系房东,但用户又逼问房东在哪)时,模型会寻找一个"局部最优解"。
如果你设置了极端的参数(Temperature: 0.01),这相当于贪婪解码(Greedy Decoding) 。模型每次必须选择概率最大的那个词。
一旦模型输出了那句"兜底废话"(比如"建议联系物业"),在生成下一个词时,它回头看上下文,发现接这一句最顺口(概率最高)。由于没有随机性(Randomness)让它去尝试"第二选项",它就被锁死在这个概率的高地上下不来了。
二、 硬核干货:解构 Sampler Chain(采样流水线)
要打破死循环,不能只盯着 Temperature 看。我们需要理解 llama.cpp 处理输出的完整流水线。
在最新的 llama.cpp 实现中,从神经网络输出到最终选定 Token,遵循以下严格顺序:
logits -> penalties -> dry -> top-n-sigma -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
你可以把它想象成一个精密漏斗:模型吐出几万个候选词,经过层层打压、截断、调温,最后只剩一个。理解这个顺序至关重要。
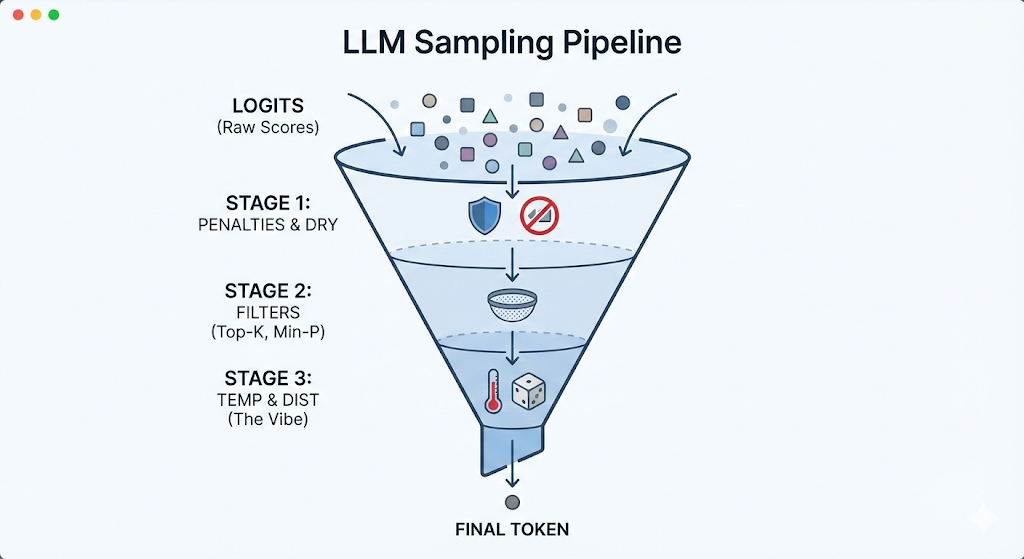
第一阶段:原始产出与暴力镇压 (The Source & The Police)
这是解决死循环的主战场。
- **
logits(原始分数)**:神经网络直接输出的数值。在死循环中,复读词在这里通常拥有极高的分数。 - **
penalties(传统惩罚)**:包含 Repetition/Frequency/Presence Penalty。系统检查历史记录,如果这个词刚说过,就强行扣分。 dry(DRY Sampling):关键点! 这是专门为了解决死循环引入的"大杀器"(Don't Repeat Yourself)。它检测 N-gram(连续词组)重复。
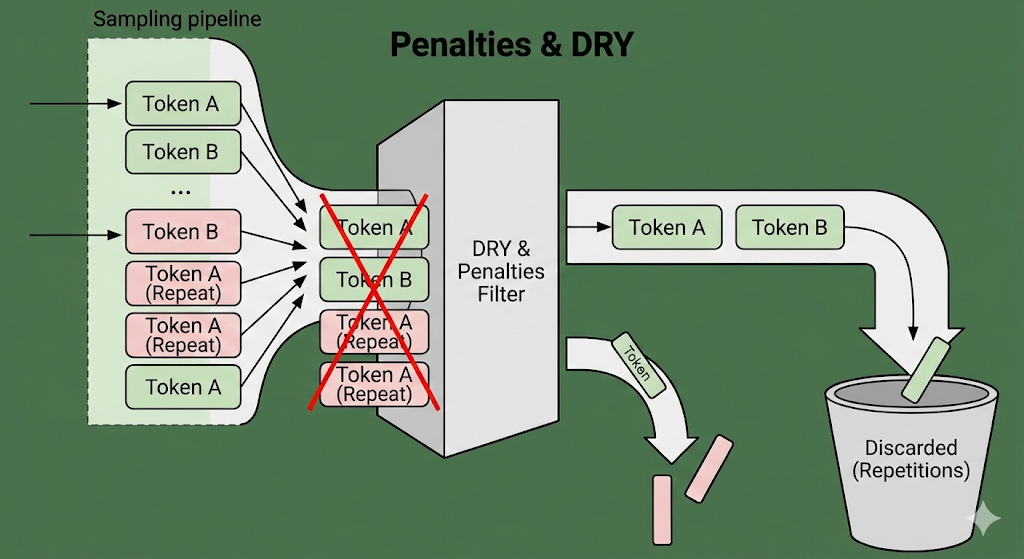
- 为何重要? 因为它排在所有筛选之前。如果启用了 DRY,那个试图复读的长句子在进入筛选漏斗之前,就会被直接打成负分,根本没有机会进入下一轮。
第二阶段:切除杂质 (The Filter)
这一阶段把"不靠谱"的词扔掉。
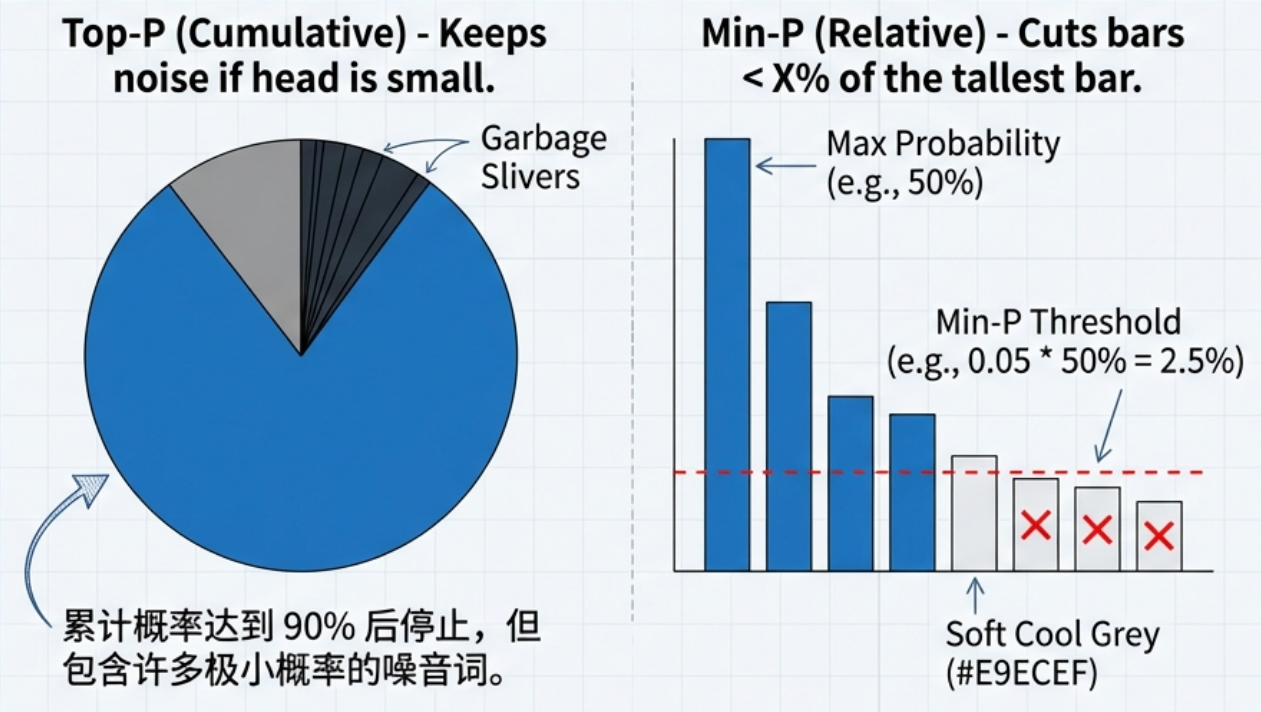
- **
top-k**:硬截断,只留前 K 个(如前 40 名)。 - **
top-p(核采样)**:累积概率截断。 min-p:小模型的救星 。它切掉那些相对于最大概率词过于微小的选项。比如最大概率是 50%,min-p=0.05会切掉所有概率低于 2.5% 的词。这比 Top-P 更能有效去除小模型的胡言乱语。
第三阶段:调温与抉择 (The Vibe)
这是导致很多人配置错误的重灾区。
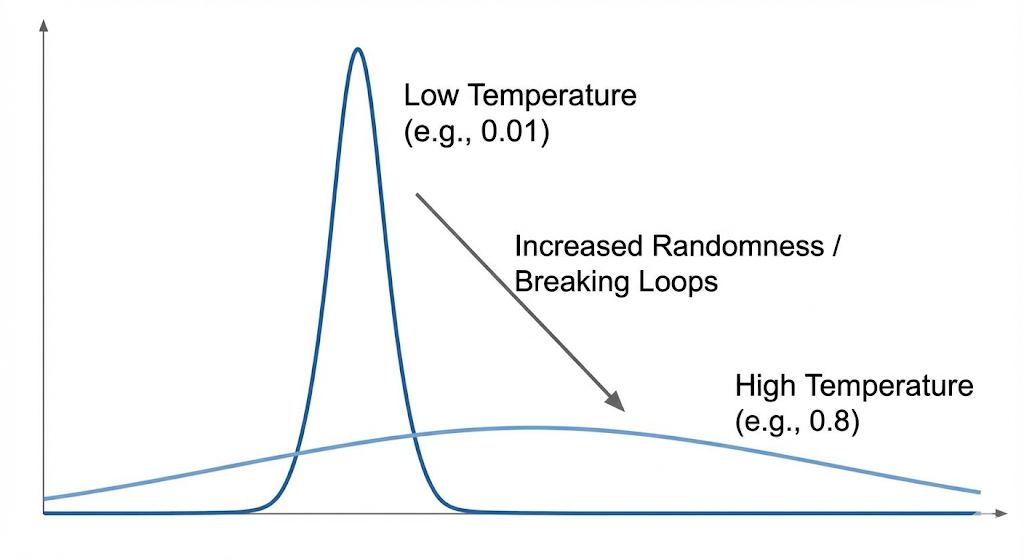
temp-ext(Temperature / 温度):注意,它排在最后面!
- 它的作用不是过滤,而是 拉伸或压缩 剩下那些词的概率差距。
- **
dist(Distribution)**:最终的掷骰子环节。
三、 深度分析:为什么"低温"反而导致死循环?
回到开头的问题:为什么 Temperature: 0.01 会导致死循环?
请看 Sampler Chain 的顺序。Temperature 是在 penalties 和 top-k 之后才起作用的。
- 假设模型陷入逻辑死角,复读词"建议"的原始概率是 40%,新思路"报警"的概率是 35%。差距很小。
- 如果你没有设置足够的
penalties,这两个词都进入了最后的决赛圈。 - 这时,你应用了
Temperature: 0.01。极低温会极度放大强弱差距。那 5% 的微弱优势被瞬间拉大,复读词的选中率变成了 **99.99%**。 - 模型失去了"赌一把"选 35% 那个词的机会,只能被迫复读。
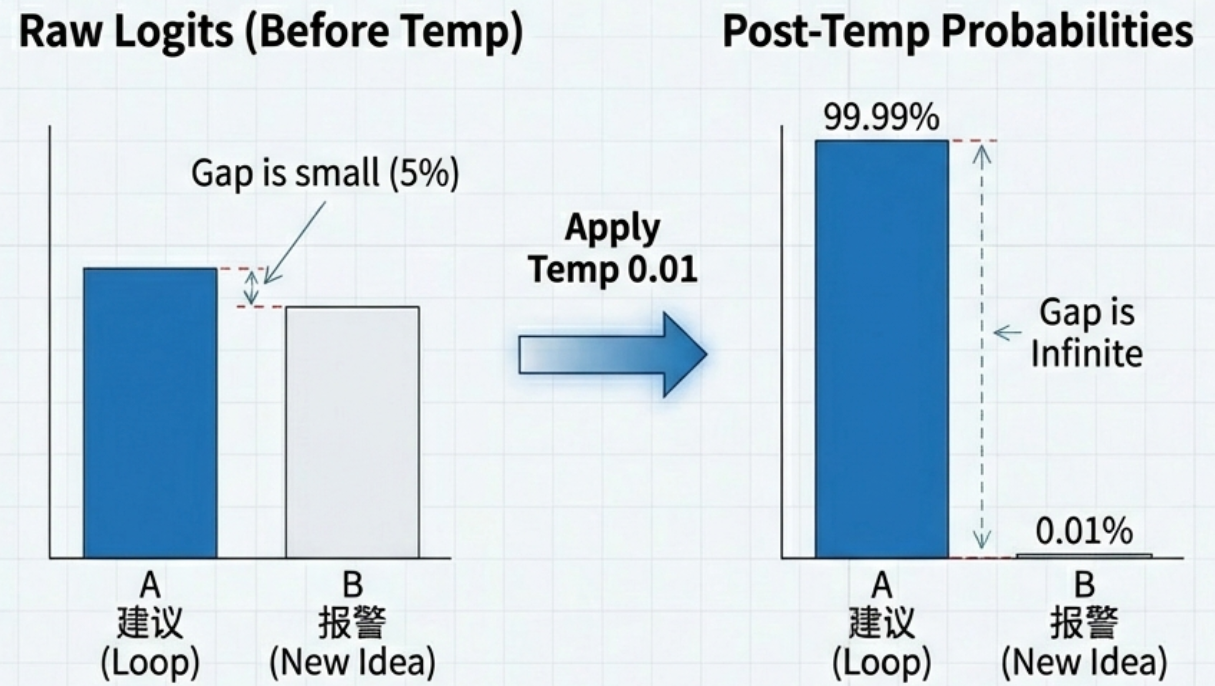
结论:越是容易死循环的模型,越不能用极低温度。你需要给它一点"犯错"的空间,它才能跳出死循环。
四、 解决方案:一套防死循环的"组合拳"
基于以上原理,针对 7B 小模型,我推荐以下这套配置策略:
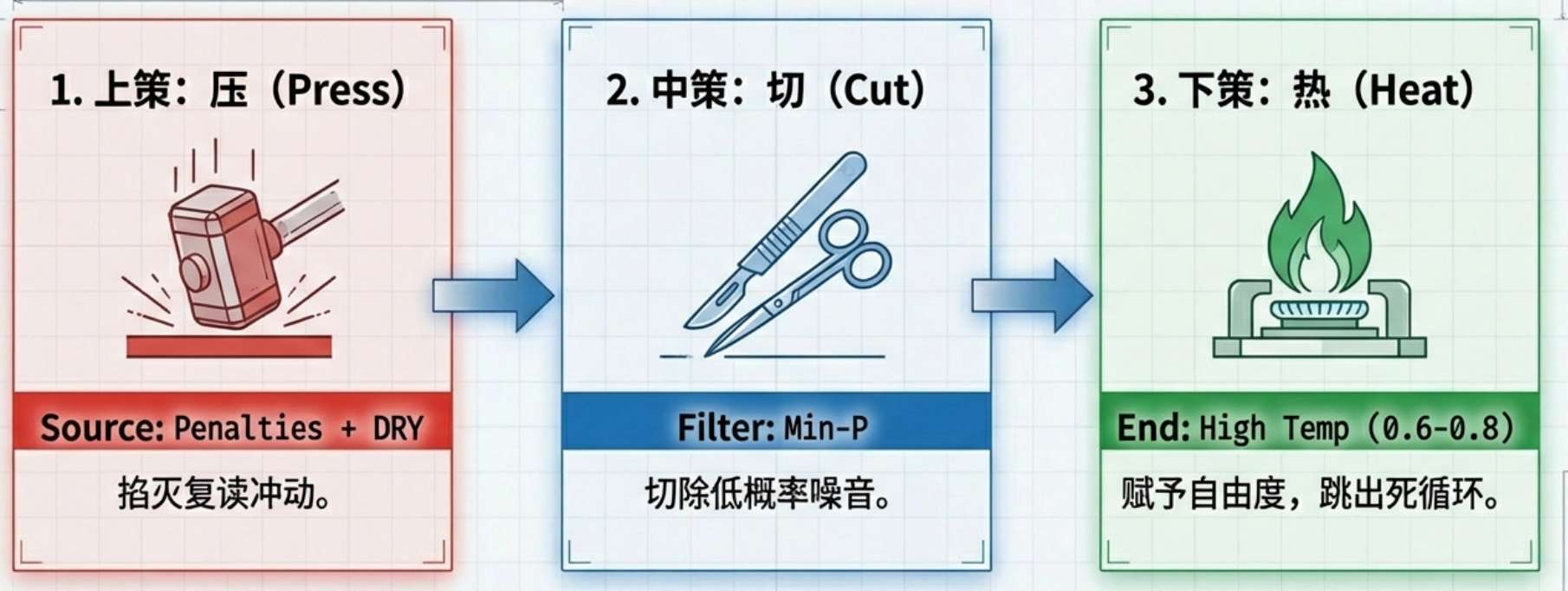
1. 上策:在源头掐灭 (DRY / Penalties)
既然 dry 和 penalties 排在最前面,我们就在这里动手。
- 启用 DRY Sampling(如果你的推理引擎支持):
dry_multiplier: 0.8 (强力抑制)dry_base: 1.75 (指数级惩罚)dry_allowed_length: 2 (允许重复 2 个 token 的短语,超过直接罚死)- 传统惩罚:
repetition_penalty: 1.15 ~ 1.2 (不要吝啬,7B 模型脸皮厚,罚重一点)
2. 中策:中间层去噪 (Min-P)
- 使用 Min-P 替代 Top-P:
min_p: 0.05top_p: 1.0 (或者是 0.9,让 min_p 主导)- 理由:这能保证即便我们提高了温度,模型也不会吐出完全不相关的垃圾字符。
3. 下策:末端放水 (High Temperature)
- 提高温度:
temperature: 0.6 ~ 0.8- 理由 :配合前面的惩罚和去噪,这里的高温度不再会产生幻觉,而是提供了宝贵的 "随机性",让模型在遇到死胡同时,有概率跳到另一条逻辑线上。
抄作业:推荐配置 JSON
{
"temperature": 0.7, // 保持较高的活跃度,避免死板
"top_p": 0.9,
"min_p": 0.05, // 切除低概率噪音,确保逻辑通顺
"repeat_penalty": 1.15, // 传统惩罚,兜底
"dry_multiplier": 0.8, // 【核武器】DRY 采样,精准打击长句复读
"dry_base": 1.75,
"dry_allowed_length": 4
}总结
小模型虽然参数少,但只要我们理解了 logits -> penalties -> ... -> dist 这条河流的流向,就能通过精细化的治理(调参)来弥补其先天不足。
记住这个口诀:先惩罚(Penalties/Dry)压住复读欲,再过滤(Min-P)切掉垃圾词,最后升温(Temp)给它找条新出路。
告别 0.01 的低温迷信,你的 7B 模型也能像真人一样灵活对话。
本文由mdnice多平台发布