摘要 :在LLM(大语言模型)"参数爆炸"的今天,如何让小模型拥有大模型的智慧?**知识蒸馏(Knowledge Distillation, KD)**是关键技术之一。不同于仅利用API返回结果的"黑盒蒸馏",白盒蒸馏通过利用大模型的完整内部状态(Logits、Hidden States、Attention Maps),能更高效、更精准地完成知识迁移。本文将带你深入白盒蒸馏的内部世界。
1. 什么是白盒蒸馏?
在介绍白盒蒸馏之前,我们先厘清两个概念:
- 黑盒蒸馏(Black-box KD) :学生模型(Student)仅学习教师模型(Teacher)生成的文本结果。例如,用GPT-4生成的指令数据去微调一个Llama-3-8B。这本质上是一种有监督微调(SFT)。
- 白盒蒸馏(White-box KD) :学生模型不仅学习教师的输出结果,还学习教师的内部概率分布(Logits)和中间层特征(Hidden States)。
为什么选择白盒?
黑盒就像是"死记硬背"标准答案,而白盒则是"理解解题思路"。白盒蒸馏包含的信息量远大于黑盒,通常能获得更好的性能和泛化能力。
2. 核心架构与原理
白盒蒸馏的核心在于**损失函数(Loss Function)**的设计,它强迫学生模型的行为尽可能接近教师模型。
2.1 架构总览图
以下是白盒蒸馏的通用架构图。我们通常固定教师模型的参数(Frozen),仅训练学生模型。
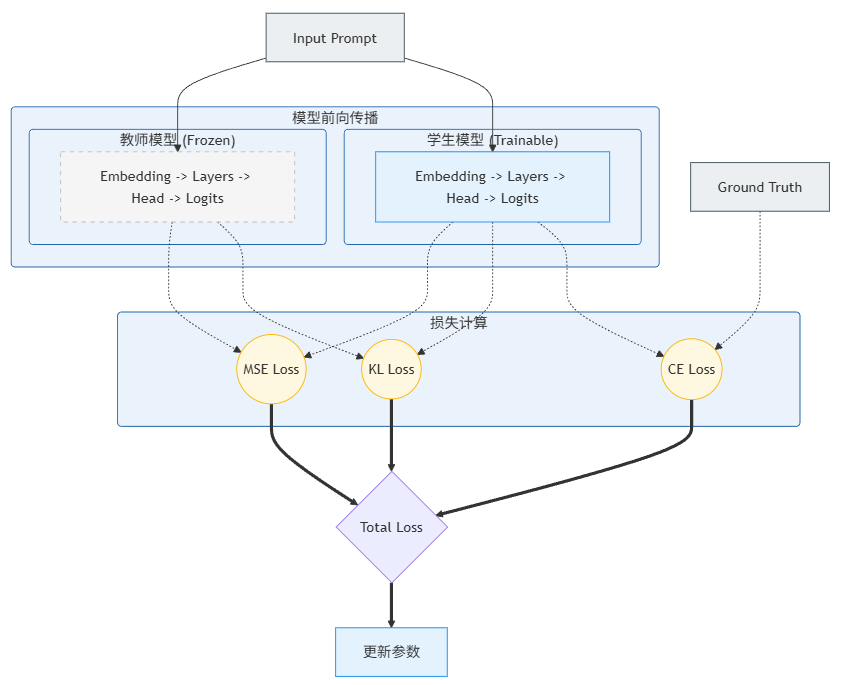
2.2 关键技术点
白盒蒸馏通常由两部分Loss组成:
-
Logits 蒸馏(输出层对齐):
- 使用 KL散度(Kullback-Leibler Divergence)。
- 引入 温度系数 (Temperature, T) :将Logits除以 TTT 再做Softmax。TTT 越大,分布越平滑,学生能学到负标签(Negative Logits)中的信息(即"哪些答案是错误的"这一知识)。
-
中间层蒸馏(Hidden States 对齐):
- 使用 MSE(均方误差) 或 Cosine Similarity。
- 投影层(Projector):如果Teacher和Student的隐藏层维度不同(例如Teacher是4096维,Student是2048维),需要训练一个线性层将Student的特征映射到Teacher的维度。
3. 实战:PyTorch 代码实现
下面我们将实现一个完整的白盒蒸馏训练循环(Training Loop)。为了演示清晰,我们假设使用 Hugging Face transformers 库。
3.1 环境准备与模型加载
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
# 假设我们蒸馏一个小模型 (Student) 学习大模型 (Teacher)
teacher_model_name = "gpt2-large" # 示例:教师模型
student_model_name = "gpt2" # 示例:学生模型
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
print("正在加载模型...")
teacher = AutoModelForCausalLM.from_pretrained(teacher_model_name).to(device)
student = AutoModelForCausalLM.from_pretrained(student_model_name).to(device)
tokenizer = AutoTokenizer.from_pretrained(student_model_name)
# 冻结教师模型参数(关键步骤)
for param in teacher.parameters():
param.requires_grad = False
teacher.eval() # 切换到评估模式
# 如果维度不一致,需要定义投影层 (此处假设维度需对齐)
# Teacher dim: 1280, Student dim: 768
class Projector(nn.Module):
def __init__(self, s_dim, t_dim):
super().__init__()
self.linear = nn.Linear(s_dim, t_dim)
def forward(self, x):
return self.linear(x)
projector = Projector(768, 1280).to(device)
optimizer = torch.optim.AdamW(list(student.parameters()) + list(projector.parameters()), lr=5e-5)3.2 定义蒸馏损失函数
这是白盒蒸馏的灵魂所在。
python
def distillation_loss(student_logits, teacher_logits,
student_hidden, teacher_hidden,
labels, temperature=2.0, alpha=0.5, beta=0.5):
"""
Args:
temperature: 软化概率分布的温度系数
alpha: 用于平衡 Hard Loss (真实标签) 和 Soft Loss (教师Logits) 的权重
beta: 用于平衡 中间层 Loss 的权重
"""
# 1. Hard Loss (常规的交叉熵,学习真实标签)
# 这里的 labels 通常是 input_ids 向左移动一位
loss_fct = nn.CrossEntropyLoss()
loss_hard = loss_fct(student_logits.view(-1, student_logits.size(-1)), labels.view(-1))
# 2. Soft Loss (Logits 蒸馏 - KL散度)
# T越大,分布越平滑,包含更多暗知识
p_s = F.log_softmax(student_logits / temperature, dim=-1)
p_t = F.softmax(teacher_logits / temperature, dim=-1)
# KLDivLoss expecting input as log_probabilities
loss_soft = nn.KLDivLoss(reduction="batchmean")(p_s, p_t) * (temperature ** 2)
# 3. Hidden States Loss (中间层对齐 - MSE)
# 假设我们只对齐最后一层 hidden state
# 需要先通过投影层将 student 维度映射到 teacher 维度
projected_student_hidden = projector(student_hidden)
loss_hidden = F.mse_loss(projected_student_hidden, teacher_hidden)
# 总 Loss 组合
total_loss = (alpha * loss_hard) + ((1 - alpha) * loss_soft) + (beta * loss_hidden)
return total_loss, loss_hard, loss_soft, loss_hidden3.3 训练循环 (Training Loop)
python
# 模拟一个简单的输入 batch
inputs = tokenizer(["Knowledge distillation is amazing.", "LLMs are the future."],
return_tensors="pt", padding=True, truncation=True).to(device)
labels = inputs["input_ids"].clone()
# 开始训练迭代
student.train()
projector.train()
# --- 前向传播 ---
# 1. Teacher Forward (No Grad)
with torch.no_grad():
t_outputs = teacher(**inputs, output_hidden_states=True)
t_logits = t_outputs.logits
# 获取最后一层 hidden state
t_hidden = t_outputs.hidden_states[-1]
# 2. Student Forward
s_outputs = student(**inputs, output_hidden_states=True)
s_logits = s_outputs.logits
s_hidden = s_outputs.hidden_states[-1]
# --- 计算 Loss ---
loss, l_hard, l_soft, l_hidden = distillation_loss(
s_logits, t_logits,
s_hidden, t_hidden,
labels=labels,
temperature=2.0,
alpha=0.5,
beta=1.0
)
# --- 反向传播与优化 ---
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Total Loss: {loss.item():.4f}")
print(f" - Hard Label Loss: {l_hard.item():.4f}")
print(f" - Soft (KL) Loss: {l_soft.item():.4f}")
print(f" - Hidden MSE Loss: {l_hidden.item():.4f}")4. 白盒蒸馏的挑战与解决方案
虽然白盒蒸馏效果好,但在实际落地大模型(如Llama-3-70B -> 8B)时会面临巨大挑战:
4.1 显存爆炸 (OOM)
问题 :你需要同时将巨大的Teacher和Student加载到显存中,还得保留计算图。
解决方案:
- Offloading:将Teacher模型放在CPU内存中,仅在计算某一层时传输到GPU(速度慢)。
- Pre-computed Logits:预先运行一遍Teacher模型,将所有数据的Logits和Hidden States存入硬盘(需海量存储空间)。
- Multi-GPU:Teacher放在一张卡,Student放在另一张卡。
4.2 Tokenizer 对齐
问题 :如果Teacher和Student使用不同的分词器(Tokenizer),Logits的维度会对不上(Vocab Size不同)。
解决方案:
- 仅进行中间层蒸馏,放弃Logits蒸馏。
- 或者强制让Student使用Teacher的Tokenizer(此时需从头预训练Embedding层)。
4.3 层映射策略 (Layer Mapping)
问题 :Teacher有80层,Student只有12层,如何对应?
解决方案:
- Uniform:每隔几层取一层(如 80/12)。
- Last Layer:只对齐最后一层(最常用,效果性价比高)。
- Learnable:通过Attention机制自动学习层与层的对应关系。
5. 总结
白盒蒸馏是大模型**小型化(Model Compression)**最有效的手段之一。
- 相比SFT:它不仅告诉模型"结果是什么",还展示了"概率分布是什么",保留了模型的不确定性知识。
- 核心实现:KL散度用于对齐输出概率,MSE用于对齐思维过程(隐藏层)。
- 未来趋势:随着端侧AI(On-device AI)的兴起,如何极低成本地进行白盒蒸馏(如 MiniLLM, TinyLlama 等项目)将是研究热点。