反思模式概述
在前面的文章中,我们探讨了基础的 Agent 模式:顺序执行的链式、动态路径选择的路由以及并发任务执行 的并行化。这些模式使 Agent 能够更高效、更灵活地执行复杂任务。然而,即使采用复杂的工作流,Agent 的初始输出或计划也可能并非最优、准确或完整。这正是反思模式发挥关键作用之处。
反思模式涉及 Agent 评估其自身工作、输出或内部状态,并利用该评估来提升性能或优化响应。这是一种自 我纠正或自我改进机制,允许 Agent 基于反馈、内部评审或与预期标准的对比,迭代优化其输出或调整策 略。反思有时可由专门的 Agent 来促进,其特定职责是分析初始 Agent 的输出。
与简单顺序链(输出直接传递至下一步)或路径选择的路由不同,反思引入了反馈循环。Agent 不仅产生输 出,还会检查该输出(或其生成过程),识别潜在问题或改进空间,并运用这些洞察生成优化版本或调整后 续行动。
该过程通常包含以下步骤:
-
1、执行:Agent执行任务或生成初始输出
-
2、评估/评审:Agent(通常通过另一个LLM调用或规则集)分析上一步结果。此评估可能涉及事实准确性、连贯性、风格、完整性、指令遵循度或其他相关标准
-
3、反思/优化:基于评审意见,Agent确定改进方向。这可能包括生成优化后的输出、调整后续步骤参数,甚至修改整体计划
-
4、迭代(可选但常见):优化后的输出或调整后的方法可继续执行,反思过程可重复进行,直至获得满意结果或达到停止条件
反思模式的关键高效实现是将流程分离为两个逻辑角色:生产者和评审者。这通常称为"生成器‐评审者"或" 生产者‐审查者"模型。虽然单个 Agent 可执行自我反思,但使用两个专门 Agent(或两个不同系统提示的独 立 LLM 调用)通常产生更稳健客观的结果。
-
1、生产者 Agent:此 Agent 的主要职责是执行任务的初始工作。它完全专注于内容生成,无论是编写代 码、起草博客文章还是制定计划。它接收初始提示并生成输出的第一版
-
2、评审者 Agent:此 Agent 的唯一目的是评估生产者生成的输出。它被赋予不同的指令集,通常承担特 定角色(如"高级软件工程师"、"严谨的事实核查员")。评审者的指令引导其根据特定标准分析生产 者工作,包括事实准确性、代码质量、风格要求或完整性。其设计目标是发现缺陷、提出改进建议并 提供结构化反馈
这种关注点分离有效避免了 Agent 审查自身工作时可能产生的"认知偏差"。评审者 Agent 以全新视角处理 输出,专注于发现错误和改进空间。其反馈传回生产者 Agent,生产者以此为指南生成优化版本。LangChain 和 ADK 代码示例均实现这种双 Agent 模型:LangChain 使用特定"reflector_prompt"创建评审者角色,而 ADK 明确定义生产者和审查者 Agent。
实现反思需要在 Agent 工作流中构建反馈循环,可通过迭代循环或支持状态管理的框架实现。虽然单步评估 优化可在 LangChain/LangGraph、ADK 或 Crew.AI 链中完成,但真正的迭代反思通常涉及更复杂编排。
反思模式对于构建高质量输出、处理精细任务并展现自我适应性的 Agent 至关重要。它推动 Agent 从单纯执 行指令转向更复杂的问题解决和内容生成。
值得注意的是反思与目标设定和监控的交叉点。目标为 Agent 自我评估提供最终基准,监控 跟踪其进展。实践中,反思常充当纠正引擎,利用监控反馈分析偏差并调整策略。这种协同使 Agent 从被动 执行者转变为有目的的自适应工作体。
当 LLM 保持对话记忆时,反思模式有效性显著增强。对话历史提供关键上下文,使 Agent 能在 先前交互和用户反馈背景下评估输出。没有记忆时,反思是独立事件;有了记忆,反思成为累积过程,每个 周期基于前一个,实现更智能的上下文感知优化。
概览
是什么: Agent 的初始输出通常次优,存在不准确、不完整或未满足复杂要求的问题。基础 Agent 工作流缺 乏 Agent 识别和修复自身错误的内置流程。这通过让 Agent 评估自身工作,或更稳健地引入独立逻辑 Agent 充当评审者来解决,防止无论质量如何初始响应都成为最终结果
为什么:反思模式通过引入自我纠正和优化机制提供解决方案。它建立反馈循环,其中"生产者"Agent 生 成输出,然后"评审者"Agent(或生产者自身)根据预定义标准进行评估。随后使用此评审生成改进版本。 这种生成、评估和优化的迭代过程逐步提升最终结果质量,从而产生更准确、连贯和可靠的结果
经验法则:当最终输出的质量、准确性和细节比速度和成本更重要时使用反思模式。它对生成精炼长篇内 容、编写调试代码以及创建详细计划等任务特别有效。当任务需要通用生产者 Agent 可能遗漏的高客观性或 专门评估时,使用独立评审者 Agent
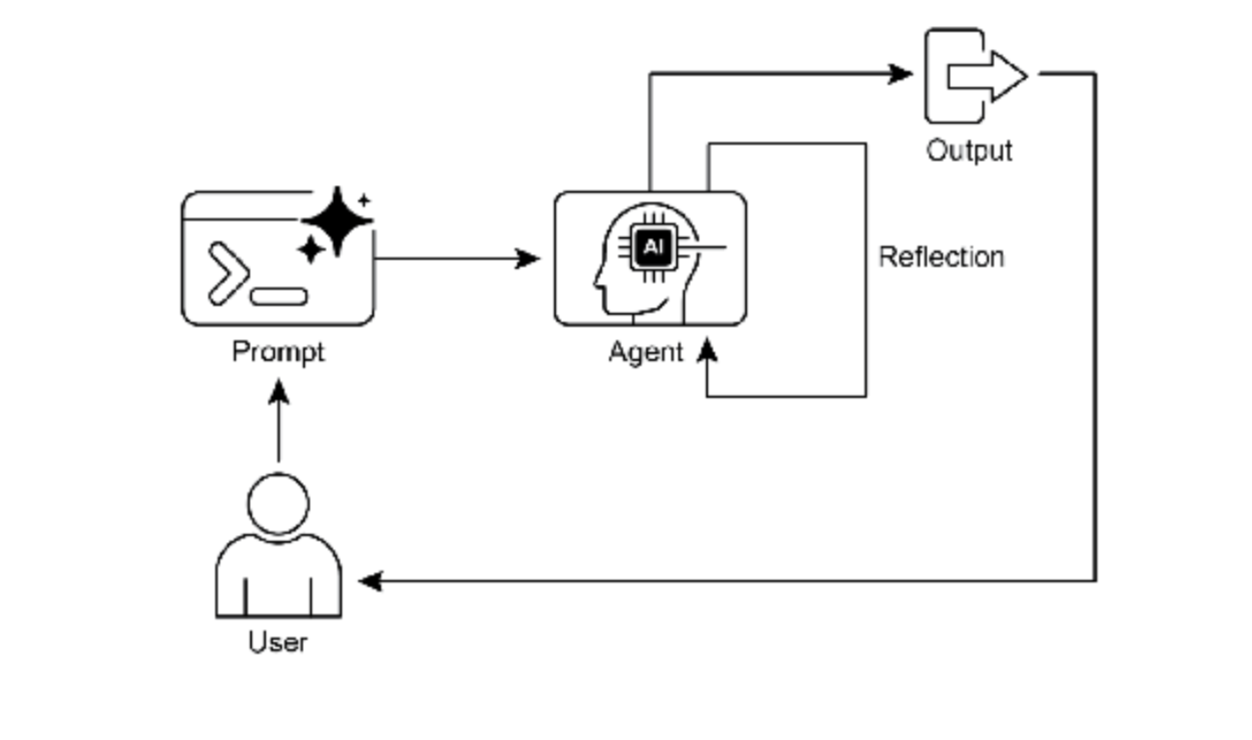 图 1:反思设计模式,自我反思
图 1:反思设计模式,自我反思
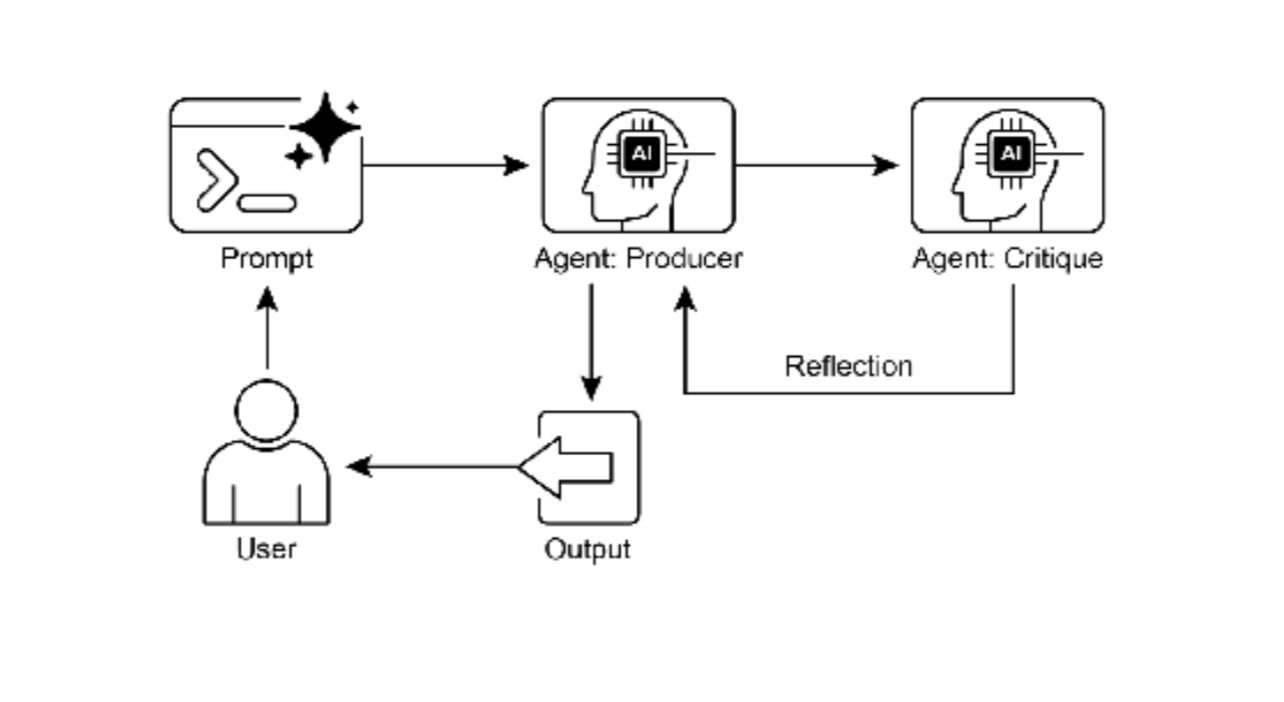
图 2:反思设计模式,生产者和评审者 Agent
关键要点
-
・ 反思模式的主要优势在于其迭代自我纠正和优化输出的能力,带来显著更高的质量、准确性和复杂指令遵循度
-
・ 它涉及执行、评估/评审和优化的反馈循环。反思对需要高质量、准确或精细输出的任务至关重要
-
・ 一个强大的实现是生产者‐评审者模型,其中独立 Agent(或提示角色)评估初始输出。这种关注点分离增强客观性,并支持更专业、结构化的反馈
-
・ 然而,这些优势以增加的延迟和计算成本为代价,同时伴随超出模型上下文窗口或被 API 服务限制的更高风险
-
・ 虽然完整迭代反思通常需要状态化工作流(如 LangGraph),但单个反思步骤可在 LangChain 中使用LCEL 实现,以传递输出进行评审和后续优化
-
・ Google ADK 可通过顺序工作流促进反思,其中一个 Agent 的输出被另一个 Agent 评审,允许后续优化步骤
-
・ 此模式使Agent能够执行自我纠正并随时间提升性能
实际应用与用例
反思模式在输出质量、准确性或复杂约束遵循度至关重要的场景中极具价值:
- 创意写作与内容生成:优化生成的文本、故事、诗歌或营销文案
・ 用例: 博客文章撰写Agent
**-- 反思:**生成草稿,评审其流畅度、语气和清晰度,然后基于评审重写。重复直至内容达到质量标准
**-- 优势:**产出更精炼有效的内容
- 代码生成与调试:编写代码、识别错误并进行修复
・用例: Python函数编写Agent
**-- 反思:**编写初始代码,运行测试或静态分析,识别错误或低效环节,然后基于发现修改代码
**-- 优势:**生成更健壮和功能完善的代码
- 复杂问题解决:评估多步推理任务中的中间步骤或建议方案
・ 用例: 逻辑谜题求解Agent
**-- 反思:**提出步骤,评估其是否接近解决方案或引入矛盾,必要时回溯或选择不同步骤
**-- 优势:**提升Agent在复杂问题空间中的导航能力
- 摘要与信息综合:优化摘要的准确性、完整性和简洁性
・ 用例: 长文档摘要Agent
**-- 反思:**生成初始摘要,与原始文档关键点对比,优化摘要以补全缺失信息或提升准确性
**-- 优势:**创建更准确全面的摘要
- 规划与策略:评估提议计划并识别潜在缺陷或改进点
・ 用例: 目标达成行动规划Agent
**-- 反思:**生成计划,模拟执行或根据约束评估可行性,基于评估修订计划
**-- 优势:**制定更有效和现实的计划
- 对话Agent:审查对话历史轮次以保持上下文、纠正误解或提升响应质量
・ 用例: 客户支持聊天机器人
**-- 反思:**用户响应后,审查对话历史和最后生成消息,确保连贯性并准确回应用户最新输入
**-- 优势:**促成更自然有效的对话
反思为 Agent 系统增加了元认知层,使其能从自身输出和过程中学习,从而产生更智能、可靠和高质量的结果
实操代码示例(LangChain)
实现完整的迭代反思过程需要状态管理和循环执行机制。虽然这些在基于图的框架(如 LangGraph)中内置 处理或通过自定义程序代码实现,但单个反思周期的基本原理可通过 LCEL(LangChain 表达式语言)的组 合语法有效演示。
反思模式是使AI智能体具备自我审查和改进能力的关键机制。以下是基于LangChain的反思模式实现示例,涵盖多个应用场景:
1、基础反思模式实现
python
from langchain.chains import LLMChain, SequentialChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from typing import Dict, List, Tuple
import re
class BasicReflectionAgent:
"""基础反思代理:生成-评估-改进循环"""
def __init__(self):
self.llm = OpenAI(temperature=0.7, max_tokens=1000)
# 生成链
self.generation_chain = LLMChain(
llm=self.llm,
prompt=PromptTemplate(
input_variables=["task"],
template="""请完成以下任务:
任务:{task}
请生成初始版本:"""
),
output_key="initial_output"
)
# 评估链
self.evaluation_chain = LLMChain(
llm=self.llm,
prompt=PromptTemplate(
input_variables=["task", "initial_output"],
template="""请评估以下输出:
原始任务:{task}
生成的输出:{initial_output}
请从以下角度进行评估:
1. 准确性:信息是否准确?
2. 完整性:是否覆盖了任务要求的所有方面?
3. 清晰度:表达是否清晰易懂?
4. 质量:整体质量如何?
请列出具体的改进建议:"""
),
output_key="evaluation"
)
# 改进链
self.improvement_chain = LLMChain(
llm=self.llm,
prompt=PromptTemplate(
input_variables=["task", "initial_output", "evaluation"],
template="""基于评估改进输出:
原始任务:{task}
初始输出:{initial_output}
评估反馈:{evaluation}
请生成改进后的版本:"""
),
output_key="final_output"
)
# 创建反思链
self.reflection_chain = SequentialChain(
chains=[
self.generation_chain,
self.evaluation_chain,
self.improvement_chain
],
input_variables=["task"],
output_variables=["initial_output", "evaluation", "final_output"],
verbose=True
)
def reflect_and_improve(self, task: str) -> Dict:
"""执行反思循环"""
return self.reflection_chain({"task": task})
# 使用示例
reflection_agent = BasicReflectionAgent()
result = reflection_agent.reflect_and_improve(
"写一篇关于人工智能伦理的短文,300字左右"
)
print("初始输出:", result["initial_output"][:200], "...")
print("\n评估反馈:", result["evaluation"])
print("\n改进后的输出:", result["final_output"][:200], "...")2、代码生成与调试反思系统
python
import ast
import traceback
from typing import Optional
class CodeReflectionAgent:
"""代码生成与调试反思代理"""
def __init__(self):
self.llm = OpenAI(temperature=0.3, max_tokens=1500)
def generate_code(self, requirement: str) -> str:
"""生成初始代码"""
prompt = f"""根据以下需求编写Python代码:
需求:{requirement}
请提供完整、可运行的代码:"""
return self.llm(prompt)
def analyze_code(self, code: str, requirement: str) -> Dict:
"""分析代码问题"""
prompt = f"""分析以下Python代码:
需求:{requirement}
代码:
```python
{code}请分析:
-
代码逻辑是否正确?
-
是否有语法错误?
-
是否符合Python最佳实践?
-
代码效率如何?
-
是否有潜在bug?
请给出详细分析:"""
python
analysis = self.llm(prompt)
# 尝试执行代码以发现运行时错误
execution_result = self._test_execution(code)
return {
"static_analysis": analysis,
"execution_test": execution_result
}
def _test_execution(self, code: str) -> Dict:
"""测试代码执行"""
try:
# 检查语法
ast.parse(code)
# 尝试在受限环境中执行
local_vars = {}
exec(code, {"__builtins__": {}}, local_vars)
return {
"status": "success",
"message": "代码语法正确且可执行"
}
except SyntaxError as e:
return {
"status": "syntax_error",
"message": f"语法错误:{str(e)}",
"line": e.lineno,
"offset": e.offset
}
except Exception as e:
return {
"status": "runtime_error",
"message": f"运行时错误:{str(e)}",
"traceback": traceback.format_exc()
}
def improve_code(self, code: str, requirement: str, analysis: Dict) -> str:
"""改进代码"""
prompt = f"""基于以下分析改进代码:原始需求:{requirement}
原始代码:
python
{code}分析结果:
静态分析:{analysis'static_analysis'}
执行测试:{analysis'execution_test''message' if 'message' in analysis'execution_test' else str(analysis'execution_test')}
请生成改进后的代码:"""
python
return self.llm(prompt)
def full_reflection_cycle(self, requirement: str, max_iterations: int = 3) -> Dict:
"""完整的反思循环"""
results = {
"iterations": [],
"final_code": None,
"improvements_made": []
}
current_code = self.generate_code(requirement)
for iteration in range(max_iterations):
print(f"\n{'='*50}")
print(f"第 {iteration + 1} 次迭代")
# 分析当前代码
analysis = self.analyze_code(current_code, requirement)
# 检查是否满足要求
if (analysis['execution_test']['status'] == 'success' and
"错误" not in analysis['static_analysis'].lower()[:100]):
print("代码质量达标,停止迭代")
results['final_code'] = current_code
break
# 记录当前状态
iteration_result = {
"code": current_code,
"analysis": analysis,
"iteration": iteration + 1
}
results['iterations'].append(iteration_result)
# 改进代码
print("正在改进代码...")
improved_code = self.improve_code(current_code, requirement, analysis)
# 记录改进
improvement_note = f"迭代{iteration+1}: {analysis['execution_test']['message'][:100]}"
results['improvements_made'].append(improvement_note)
# 更新当前代码
current_code = improved_code
results['final_code'] = current_code
return results使用示例
code_agent = CodeReflectionAgent()
requirement = "编写一个函数,计算斐波那契数列的第n项,要求时间复杂度为O(n)"
result = code_agent.full_reflection_cycle(requirement, max_iterations=2)
print("\n最终代码:")
print(result'final_code')
print("\n改进记录:")
for imp in result'improvements_made':
print(f"- {imp}")
python
## 三、多轮对话反思系统
```python
from datetime import datetime
from collections import deque
class ConversationalReflectionAgent:
"""对话反思代理,保持上下文一致性"""
def __init__(self, max_history: int = 10):
self.llm = OpenAI(temperature=0.7)
self.conversation_history = deque(maxlen=max_history)
self.context_summary = ""
def reflect_on_conversation(self, user_input: str, agent_response: str) -> Dict:
"""反思对话质量"""
history_str = self._format_history()
reflection_prompt = f"""对话反思分析:
对话历史:
{history_str}
最新交互:
用户:{user_input}
助手:{agent_response}
请分析:
1. 我的回应是否准确回答了用户的问题?
2. 我的回应是否与对话历史保持一致?
3. 是否有误解或需要澄清的地方?
4. 对话流程是否自然流畅?
反思结果:"""
reflection = self.llm(reflection_prompt)
# 提取关键改进点
improvement_points = self._extract_improvement_points(reflection)
return {
"reflection": reflection,
"improvement_points": improvement_points,
"needs_clarification": "澄清" in reflection or "误解" in reflection,
"confidence_score": self._calculate_confidence(reflection)
}
def generate_response(self, user_input: str, use_reflection: bool = True) -> str:
"""生成回应,可选择使用反思"""
history_str = self._format_history()
if not use_reflection:
# 直接生成回应
prompt = f"""对话历史:{history_str}
用户:{user_input}
助手:"""
response = self.llm(prompt)
else:
# 先生成草稿,然后反思改进
draft_prompt = f"""基于对话历史生成回应草稿:
对话历史:{history_str}
用户最新输入:{user_input}
回应草稿:"""
draft_response = self.llm(draft_prompt)
# 反思草稿
reflection_result = self.reflect_on_conversation(user_input, draft_response)
# 基于反思改进
if reflection_result['needs_clarification']:
improvement_prompt = f"""改进回应草稿:
原始草稿:{draft_response}
反思反馈:{reflection_result['reflection']}
需要特别关注的改进点:{', '.join(reflection_result['improvement_points'])}
用户输入:{user_input}
请生成改进后的回应:"""
response = self.llm(improvement_prompt)
else:
response = draft_response
# 更新历史
self._update_history(user_input, response)
return response
def _format_history(self) -> str:
"""格式化对话历史"""
if not self.conversation_history:
return "(无历史对话)"
history_lines = []
for i, (user, assistant, timestamp) in enumerate(self.conversation_history, 1):
history_lines.append(f"{i}. 用户({timestamp}): {user}")
history_lines.append(f" 助手: {assistant}")
return "\n".join(history_lines)
def _update_history(self, user_input: str, response: str):
"""更新对话历史"""
timestamp = datetime.now().strftime("%H:%M:%S")
self.conversation_history.append((user_input, response, timestamp))
# 定期更新上下文摘要
if len(self.conversation_history) % 5 == 0:
self._update_context_summary()
def _update_context_summary(self):
"""更新上下文摘要"""
history_str = self._format_history()
summary_prompt = f"""基于以下对话历史,生成简短的上下文摘要:
{history_str}
上下文摘要(包括主要话题、用户偏好、重要信息):"""
self.context_summary = self.llm(summary_prompt)
def _extract_improvement_points(self, reflection: str) -> List[str]:
"""从反思中提取改进点"""
# 简单关键词提取
improvement_keywords = ["改进", "更好", "应该", "需要", "建议", "优化"]
sentences = reflection.split('。')
improvement_points = []
for sentence in sentences:
if any(keyword in sentence for keyword in improvement_keywords):
improvement_points.append(sentence.strip())
return improvement_points[:3] # 返回最多3个改进点
def _calculate_confidence(self, reflection: str) -> float:
"""计算置信度分数"""
positive_indicators = ["准确", "一致", "流畅", "自然", "恰当"]
negative_indicators = ["误解", "错误", "不一致", "混乱", "不清晰"]
positive_count = sum(1 for indicator in positive_indicators
if indicator in reflection)
negative_count = sum(1 for indicator in negative_indicators
if indicator in reflection)
total = positive_count + negative_count
if total == 0:
return 0.5
return positive_count / total
# 使用示例
chat_agent = ConversationalReflectionAgent(max_history=5)
# 模拟对话
conversation = [
"你好,我想了解人工智能",
"AI有哪些主要应用领域?",
"我对机器学习特别感兴趣",
"能解释一下监督学习和无监督学习的区别吗?"
]
for user_input in conversation:
print(f"\n用户: {user_input}")
response = chat_agent.generate_response(user_input, use_reflection=True)
print(f"助手: {response}")
# 显示最新反思(模拟)
if hasattr(chat_agent, 'last_reflection'):
print(f"[反思] {chat_agent.last_reflection['improvement_points'][0] if chat_agent.last_reflection['improvement_points'] else '无问题'}")3、反思模式最佳实践
python
class ReflectionPatternBestPractices:
"""反思模式最佳实践实现"""
@staticmethod
def implement_gradual_refinement(task: str, initial_generator,
evaluator, refiner, max_iterations: int = 3):
"""渐进式精炼模式"""
current_output = initial_generator(task)
for i in range(max_iterations):
print(f"\n迭代 {i+1}/{max_iterations}")
# 评估
evaluation = evaluator(current_output, task)
# 检查是否满足质量阈值
if evaluation["quality_score"] >= 0.8: # 质量阈值
print(f"达到质量要求,停止迭代")
break
# 精炼
current_output = refiner(current_output, evaluation, task)
print(f"质量分数: {evaluation['quality_score']:.2f}")
return current_output
@staticmethod
def implement_multi_perspective_reflection(text: str, perspectives: List[str]):
"""多视角反思"""
reflections = []
for perspective in perspectives:
prompt = f"""从{perspective}视角分析以下文本:
文本:{text}
请提供分析:"""
llm = OpenAI(temperature=0.5)
analysis = llm(prompt)
reflections.append({
"perspective": perspective,
"analysis": analysis,
"suggestions": ReflectionPatternBestPractices._extract_suggestions(analysis)
})
return reflections
@staticmethod
def _extract_suggestions(analysis: str, max_suggestions: int = 3) -> List[str]:
"""从分析中提取具体建议"""
# 简单实现:按句号分割,提取包含建议关键词的句子
suggestion_keywords = ["建议", "应该", "可以", "改进", "优化", "考虑"]
sentences = analysis.split('。')
suggestions = []
for sentence in sentences:
if any(keyword in sentence for keyword in suggestion_keywords):
suggestions.append(sentence.strip())
return suggestions[:max_suggestions]
@staticmethod
def implement_reflection_with_metrics(output: str, metrics: Dict[str, callable]):
"""带度量标准的反思"""
metric_results = {}
for metric_name, metric_func in metrics.items():
score = metric_func(output)
metric_results[metric_name] = {
"score": score,
"interpretation": ReflectionPatternBestPractices._interpret_metric_score(metric_name, score)
}
# 综合评估
overall_score = sum(r["score"] for r in metric_results.values()) / len(metrics)
return {
"metric_results": metric_results,
"overall_score": overall_score,
"recommendation": ReflectionPatternBestPractices._generate_recommendation(metric_results)
}
@staticmethod
def _interpret_metric_score(metric_name: str, score: float) -> str:
"""解释度量分数"""
if score >= 0.8:
return "优秀"
elif score >= 0.6:
return "良好"
elif score >= 0.4:
return "一般"
else:
return "需要改进"
@staticmethod
def _generate_recommendation(metric_results: Dict) -> str:
"""生成改进建议"""
low_metrics = [name for name, result in metric_results.items()
if result["score"] < 0.6]
if not low_metrics:
return "所有指标表现良好,无需重大改进"
else:
return f"建议优先改进以下指标:{', '.join(low_metrics)}"
# 示例度量函数
def calculate_clarity_score(text: str) -> float:
"""计算清晰度分数(简化版)"""
# 实际应用中可以使用更复杂的NLP方法
sentence_lengths = [len(sentence.split()) for sentence in text.split('.')]
avg_sentence_length = sum(sentence_lengths) / len(sentence_lengths) if sentence_lengths else 0
# 句子平均长度在15-25词之间通常最易读
if 15 <= avg_sentence_length <= 25:
return 0.8
elif 10 <= avg_sentence_length <= 30:
return 0.6
else:
return 0.4
def calculate_completeness_score(text: str) -> float:
"""计算完整性分数(简化版)"""
# 检查是否有常见的完整性标记
completeness_indicators = ["首先", "其次", "最后", "总结", "综上所述", "因此"]
indicator_count = sum(1 for indicator in completeness_indicators
if indicator in text)
return min(1.0, indicator_count / 3) # 最多3个指示器
# 使用最佳实践示例
practices = ReflectionPatternBestPractices()
# 多视角反思示例
text = "人工智能将改变未来工作方式"
perspectives = ["技术发展", "社会经济", "伦理道德", "教育培训"]
reflections = practices.implement_multi_perspective_reflection(text, perspectives)
print("多视角反思结果:")
for reflection in reflections:
print(f"\n视角: {reflection['perspective']}")
print(f"建议: {reflection['suggestions'][0] if reflection['suggestions'] else '无'}")这些示例展示了反思模式在不同场景下的实际应用。反思模式的核心价值在于使AI系统能够自我评估和改进,从而提高输出质量。关键设计考虑包括:
-
反思深度控制:根据任务复杂度调整反思的深度和频率
-
评估标准明确:定义清晰的评估标准和指标
-
迭代终止条件:设置合理的停止条件避免无限循环
-
上下文保持:在反思过程中保持重要上下文信息
-
效率与质量平衡:在反思开销和输出质量间取得平衡
反思模式与路由模式结合可以创建更强大的智能体系统:路由决定处理路径,反思确保处理质量。
结论
反思模式为 Agent 工作流中的自我纠正提供关键机制,实现超越单次执行的迭代改进。这是通过创建循环实 现的:系统生成输出,根据特定标准评估,然后使用该评估产生优化结果。此评估可由 Agent 自身(自我反 思)执行,或通常更有效地由不同评审者 Agent 执行,这代表了模式内的关键架构选择
虽然完全自主的多步反思过程需要强大的状态管理架构,但其核心原理可在单个生成‐评审‐优化周期中有效演示。作为控制结构,反思可与其他基础模式集成,以构建更健壮和功能更复杂的 Agent 系统。
参考文献
-
LangChain Expression Language (LCEL) Documentation: https://python.langchain.com/docs/in troduction/
-
LangGraphDocumentation:https://www.langchain.com/langgraph