前言
前面简单了解了一下RAG技术,其实对我来说虽然是先知道RAG技术的,但是真正的看到具体技术实现的是GraphRAG。对于GraphRAG在网上对其褒贬不一说他虽然准确性更高但是消耗大代价高昂,也有说他幻觉较高的。那GraphRAG到底怎么样,然后怎么用,适合在什么情况下使用以及他的缺陷和对RAG技术未来展望。
最近有些想念国漫《凡人修仙传》所以大规模文本数据下GraphRAG实战的例子是《凡人修仙传》小说部分章节。
如果文章能帮到其他小伙伴,那是我的荣幸。文中如有不当的地方欢迎大家友好讨论,对于不妥我会积极修改。(有部分图片和实现方案及操作步骤取自其他博客和公众号,作者均会在后面引用说明)
大佬们有更好的解决见解和想法,也希望能够指点指点~~~~
一、GraphRAG与传统RAG
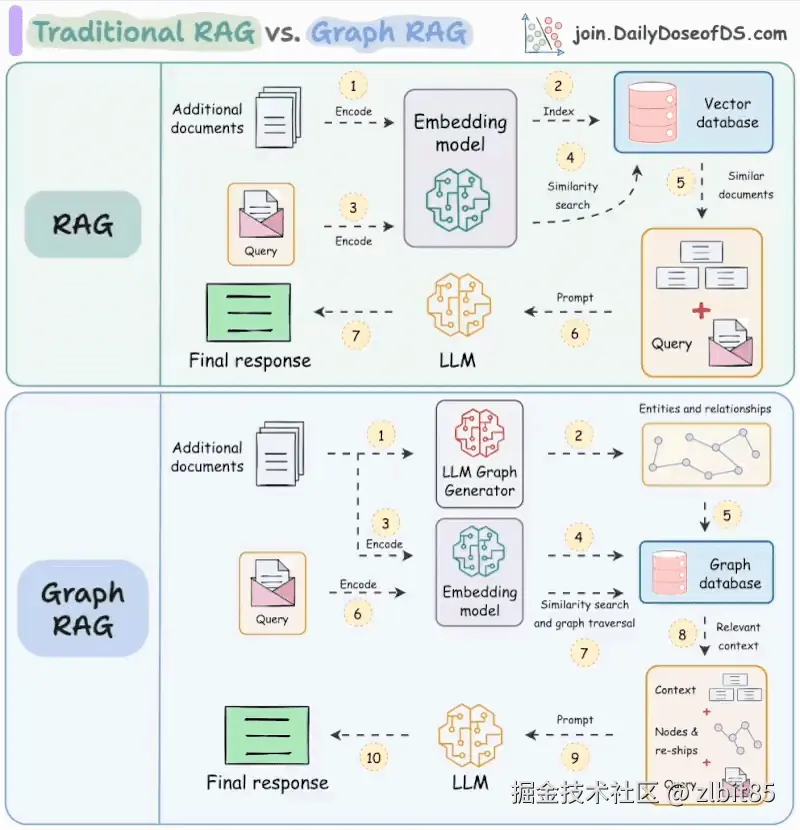
1. 经典RAG:基于语义相似性的高效检索
经典RAG通过语义向量化 与相似性搜索 实现知识检索。其流程清晰直接:将文档分割为文本块,编码为向量后存入向量数据库;当查询输入时,同样将其编码为向量,通过计算余弦相似度等方法,从海量数据中快速找出语义最相关的文本片段作为上下文,最终交由大语言模型生成答案。这种方法尤其擅长处理事实型、单跳的问题,例如,当询问"谁发明了电话?"时,RAG并非凭空生成一个名字,而是先检索出记载相关发明史实的文本块,再据此精准锚定答案:"亚历山大·格拉汉姆·贝尔"。这使得RAG成为构建可靠、可信赖智能应用的关键技术。
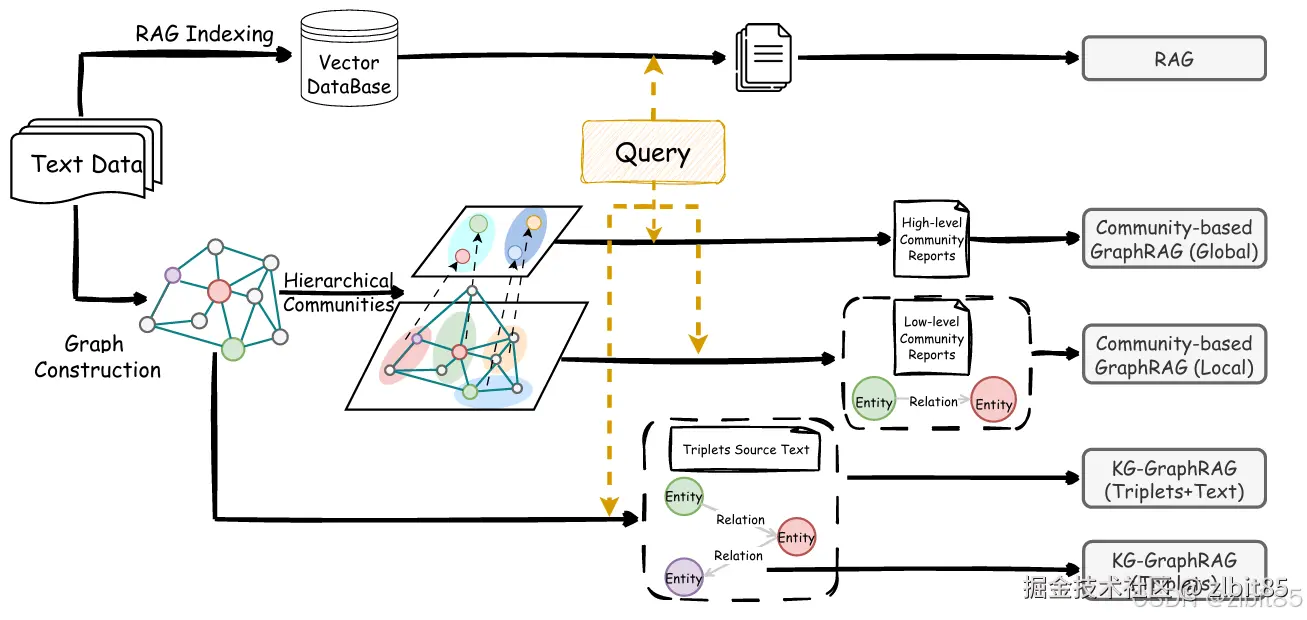
这个图是RAG、基于 KG 的 GraphRAG 和基于社区的 GraphRAG 的示意图(RAG vs. GraphRAG:系统评估与关键见解)。
2. GraphRAG:基于关系结构的深度推理
GraphRAG(欢迎 - GraphRAG 文档)是一种基于知识图谱的检索增强生成架构,它将非结构化文本转化为结构化的知识网络,从而实现对复杂关系的深度推理与精准检索。其核心流程与典型实现方式可分为三个层次:
首先,系统通过大语言模型从原始文本中提取实体 、关系 ,构成"实体-关系-实体"三元组 ,并以此构建知识图谱。图谱中的节点代表实体,边代表实体间的关系,形成了机器可理解、可遍历的语义网络。
基于这一知识结构,GraphRAG 主要提供三类检索路径:
(1)基于三元组的检索(KG-GraphRAG)
系统直接利用知识图谱进行检索。当查询输入时,先识别其中的实体,并在图谱中定位对应节点,继而通过遍历关系边,收集其多跳邻居的三元组信息作为上下文。例如,对于"爱因斯坦的导师是谁?",系统从"爱因斯坦"节点出发,沿"导师"关系边即可找到答案实体。此方法还可选择是否关联检索三元组对应的原文片段,以增强信息完整性。
(2)基于社区结构的检索(Community-GraphRAG)
在知识图谱的基础上,进一步通过社区检测算法识别出紧密关联的实体群落,并构建层次化社区结构。每个社区可自动生成摘要报告。检索时分为两种策略:
- 全局检索:根据查询语义,直接匹配和检索高层社区的摘要报告,获得全局性、概括性的语境。
- 局部检索:基于查询中的实体定位到具体社区,检索该社区的详细报告及相关三元组,获取局部深度信息。这种方式尤其适合处理"爱因斯坦的导师的导师是谁?"这类需要多跳推理的问题。
(3)基于文本节点的检索
此类方法(如HippoRAG(从RAG到记忆:大型语言模型的非参数持续学习))将知识图谱作为索引结构,但最终检索对象仍是原始文本块。系统先识别查询相关的实体,然后返回与这些实体相连的原文段落,兼具图谱的关系引导能力与文本的细节丰富性。
3.传统RAG相对于GraphRAG的局限性
传统检索增强生成系统有效缓解了大模型的幻觉问题,但其基础架构在面对复杂、关联性强的真实世界知识时,存在两大本质缺陷。这些缺陷并非简单改进检索算法所能克服,而是源于其"非结构化文本块检索"的根本范式。正因如此,GraphRAG作为一种引入结构化知识的架构,成为了更稳健、可靠的替代方案。
局限一:信息以模糊的文本形式呈现,而非确定的关系结构
传统RAG运作于一个基本假设之上:只要将相关的文本段落提供给大模型,它就能正确理解并串联其中的事实。然而,这正是其脆弱性的来源。事实上大语言模型(LLMs)天生擅长处理结构化数据,因为它们提供了实体之间的清晰关系。
-
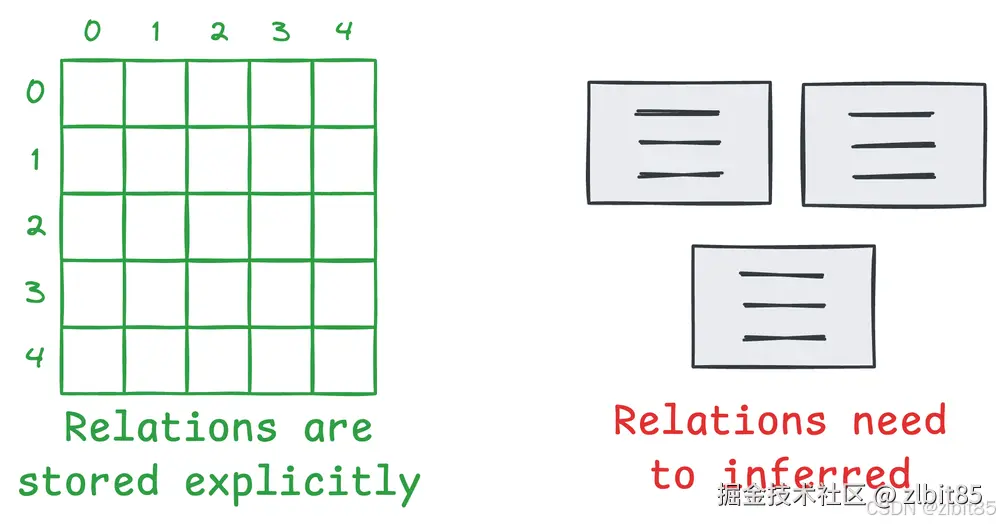
问题本质 :传统RAG检索和传递的是非结构化或半结构化的文本块。这些文本块中的实体与关系被隐藏在自然语言的叙述中,需要大模型在生成答案时进行二次识别、解析和推断。
-
关键对比:
- 传统RAG输入:"爱因斯坦提出了相对论,这对现代物理学产生了深远影响。"
- GraphRAG可提供的输入:(爱因斯坦, 提出, 相对论),(相对论, 影响, 现代物理学)
-
为何GraphRAG更稳健:

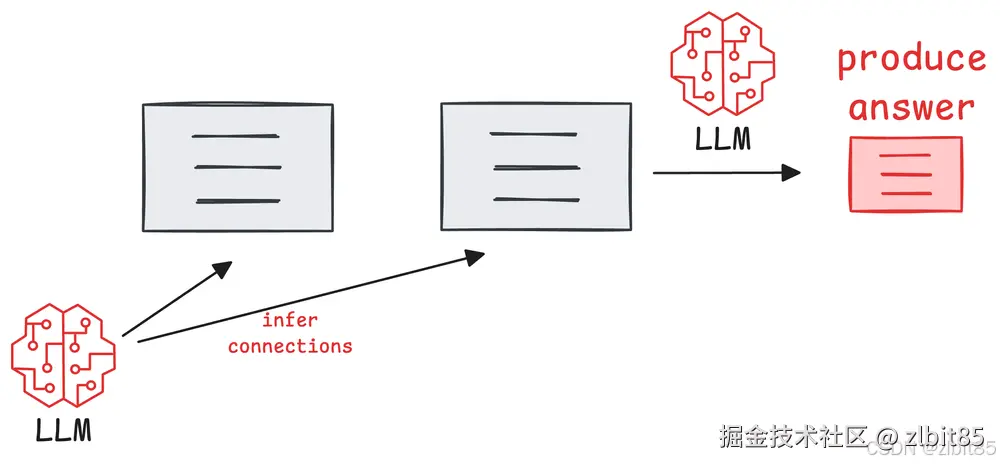
当答案依赖于精确的关系(如"谁提出了什么"、"A如何导致B")时,传统RAG迫使大模型执行一项额外且容易出错的任务:从文本中挖掘关系 。段落越长、信息越复杂,挖掘失败或产生歧义的风险就越高。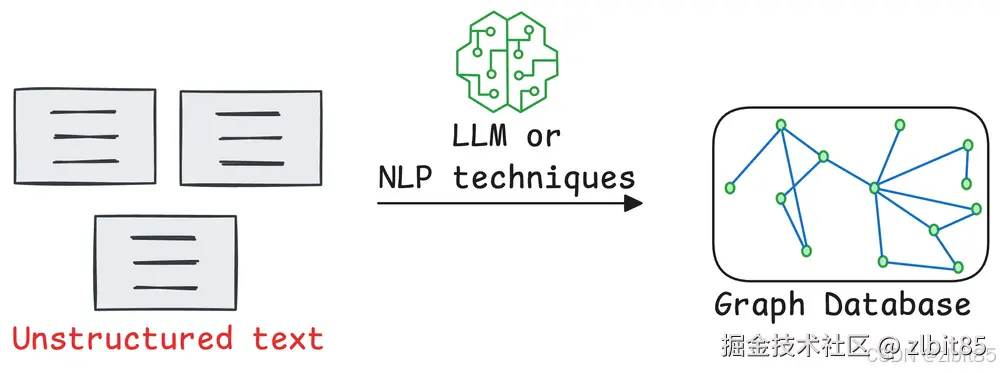
相反,GraphRAG基于知识图谱,其检索和提供给大模型的核心是显式、结构化的关系三元组 。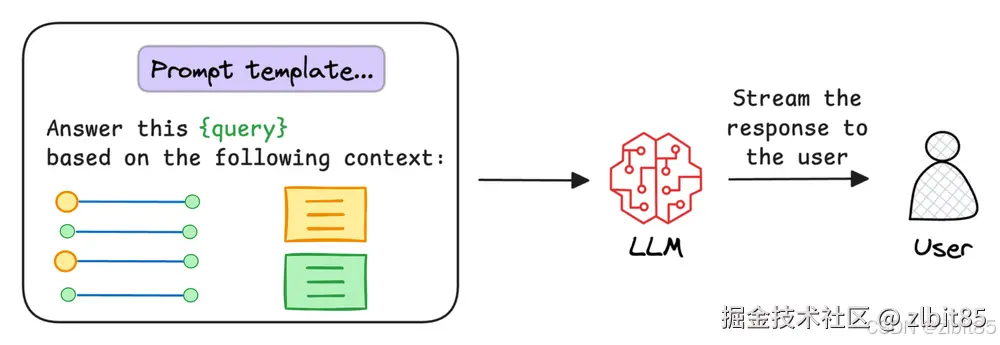
这相当于将"阅读理解并提炼关系"的难题在检索阶段就已解决,直接向大模型输送清晰、无歧义的事实网络。这大幅降低了推理的不确定性,使生成过程建立在确定性的知识骨架上,因而更为稳健。
局限二:检索基于局部语义相似,而非全局逻辑关联
传统RAG的检索机制(如向量相似度搜索)擅长寻找"谈论相似话题"的段落,但无法理解"信息之间如何逻辑相连"。这导致其在处理需要连接多个信息点的查询时,表现极不稳定。
- 问题本质 :系统以"块"为单位独立评估其与查询的相关性,完全忽略了信息块之间可能存在的、对回答问题至关重要的逻辑纽带。
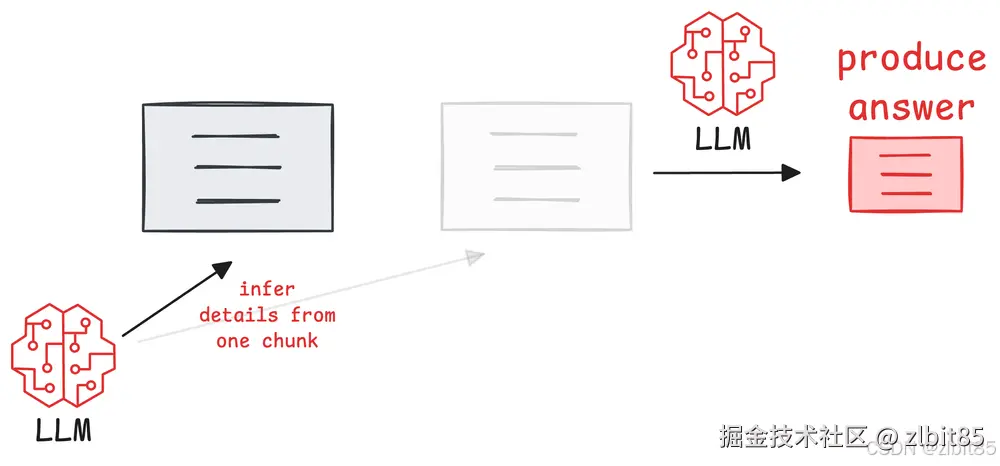
-
典型失效场景 :回答多跳问题。
- 查询:"苹果公司最新产品的芯片采用了哪家公司的制造工艺?"
- 信息分布 :
块1(关于产品):"苹果最新发布的iPad Pro搭载了M4芯片。"
块2(关于芯片):"M4芯片由台积电(TSMC)的3纳米工艺制造。"
传统RAG可能检索到块1(因为"苹果公司最新产品"相关性高),但很可能错过块2(因为查询未直接提及"M4"或"制造工艺"),即便检索到两者,也无法显式告知模型"M4芯片"正是"最新产品"所用的芯片。
-
为何GraphRAG更稳健 :
GraphRAG将知识组织为一张网络。检索不再是对孤立文本块的打分,而是对知识网络的导航与遍历。
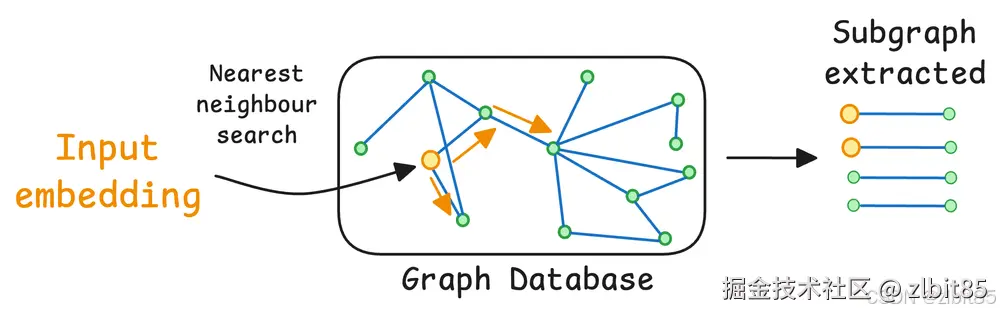
针对上述查询,图查询引擎可以执行如下的精确逻辑路径查找:苹果公司 → 发布 → iPad Pro → 搭载 → M4芯片 → 采用工艺 → 台积电3纳米。这种机制能主动地、按图索骥地 收集到所有逻辑上相关联的事实,无论这些事实在原文中相距多远。
因此,GraphRAG的稳健性体现在它用遵循逻辑的确定性检索 ,替代了传统RAG依赖概率的相似性检索,从根本上保障了复杂问题回答的完整性与准确性。
4.传统RAG与GraphRAG的互补性
在学习过程中深刻认识到技术是不断进步的,没有任何一个技术是完美的,技术也不分绝对的好坏只看适用场景。而RAG与GraphRAG也并非简单的替代关系,而是在不同任务场景下各具优势、互为补充的技术范式。那我通过RAG vs. GraphRAG:系统评估与关键见解来看看他们各自适合什么任务场景又可以如何互补。
我们的"裁判"是四个经典的QA数据集,它们就像四类不同的考题:
- NQ (自然问题) :考的是单知识点记忆,比如"泰坦尼克号是哪年沉没的?"。
- HotPotQA & MultiHop-RAG :考的是多步骤推理,比如"执导了《盗梦空间》的导演,他妻子主演了哪部科幻片?"。
- NovelQA :题型更全,包含21种不同类型的提问,像个综合能力大考。
(1)各自适用场景
1. RAG:出色的"细节猎手"
在单跳事实性问题(NQ)和需要抠细节的查询上,RAG的得分很高。为什么?因为它就像个精准的"CTRL+F",直接把包含答案原句的文本块找出来交给大模型。这种"照本宣科"的方式,对于事实复述非常可靠。
2. GraphRAG (尤其是Local版):强悍的"推理侦探"
在面对需要连接多个信息点的多跳问题时,GraphRAG的优势就凸显了。在HotPotQA和MultiHop-RAG这类"推理题"上,它表现最佳。因为它不是找句子,而是沿着知识图谱里的关系线(边)进行"侦探式走访",能一步步把分散的证据链拼凑起来。
一个关键发现 :在综合考试NovelQA中,虽然GraphRAG总体平均分可能略低于RAG,但在多跳推理这个单项上,它依然是冠军。这说明它的特长非常突出。
(2)为什么可以互补
论文做了一个更细致的分析:把每个问题按照"RAG和GraphRAG谁答对了"分成四类。

结果非常有趣!以MultiHop-RAG数据集为例:
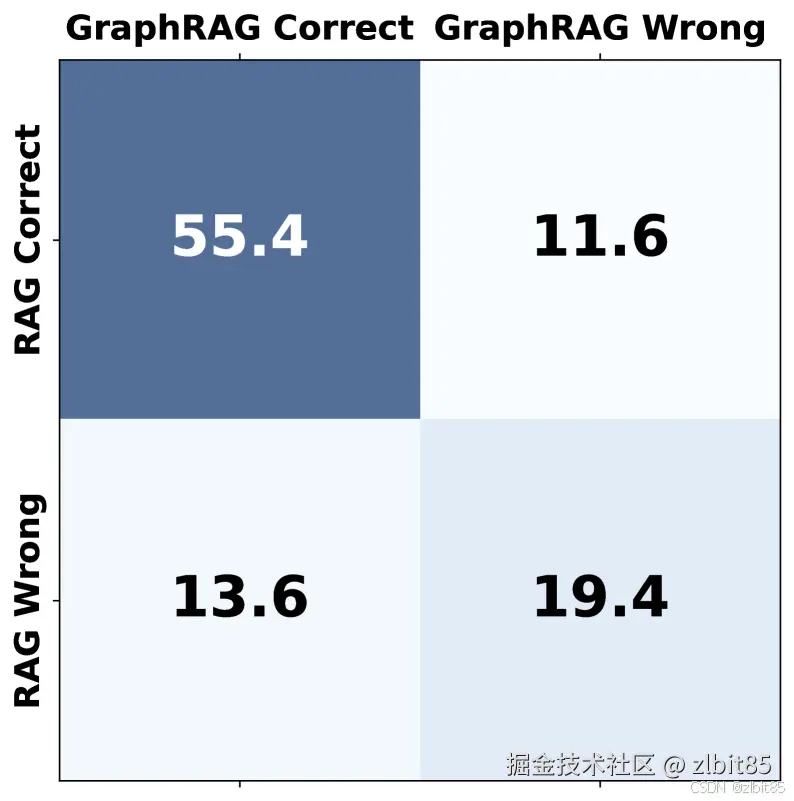
- 有相当一部分问题(约13.6%)只有GraphRAG能答对(RAG搞不定)。
- 同时,也有不少问题(约11.6%)只有RAG能答对(GraphRAG搞不定)。
这说明什么?它们俩覆盖的能力圈有重叠,但也有大片不重叠的"专属领域" 。RAG能解决一些GraphRAG解决不了的问题(比如某些极依赖原文措辞的细节),反之亦然。这不就是"互补"最直接的证据吗?
(3)如何取长补短
既然互补性这么明确,我们当然可以想办法让它们1+1>2。
策略一:智能路由(让AI自己选专家)
- 思路:接到一个问题时,先让大模型快速判断一下:"这是个靠找原文就能解决的事实题,还是个需要连点成线的推理题?"
- 做法:如果是事实题,就派给RAG处理;如果是推理题,就派给GraphRAG处理。
- 优点 :高效省钱,每个问题只用一个系统,速度快、成本低。
- 缺点:完全依赖于"分诊"这一步的准确性,万一判断错了,效果就会打折扣。
策略二:强力融合(双专家会诊)
- 思路 :不管什么问题,让RAG和GraphRAG同时开工!把RAG找到的详细原文,和GraphRAG理出的关系脉络,打包在一起塞给大模型。
- 做法:让大模型同时看到"细节碎片"和"关系地图",自己综合判断,生成最终答案。
- 优点 :效果通常最好,因为给到大模型的信息最全、视角最多。
- 缺点 :计算成本高,一个问题要处理两遍,响应更慢、更贵。
实验证明,融合策略的效果通常最好 ,能显著提升在多跳问题上的成绩。而路由策略则在效果和成本间取得了很好的平衡。选哪个,就看你是更追求极致答案,还是更在乎效率了。
(4)关于"摘要任务"和评估的冷思考
在写摘要的任务上,数据也给了我们类似启示:
- RAG因为能抓取原文细节,在贴近事实的摘要上表现很稳。
- GraphRAG如果只用知识图谱(三元组)会丢失细节,但如果把图谱和原文结合,就能做出既有逻辑骨架又有血肉的好摘要。
- 一个有趣的发现:现在流行用大模型自己来评判摘要好坏(LLM-as-a-Judge),但这种方法存在明显的位置偏见------把哪个摘要放在前面说,会极大影响它的打分。这提醒我们,客观的评估(比如对比标准答案)仍然不可或缺。
二、GraphRAG的工作流程
通过前面的对比,我们已经清晰地看到:GraphRAG凭借其结构化的知识图谱,在复杂推理与全局理解任务上,相比传统RAG展现出了显著优势。
然而,一个关键问题随之而来:这个更强大的"推理侦探"或"知识架构师",其内部究竟是如何运作的?它是怎样将一堆原始文本,一步步炼化成那个可用于深度检索的结构化知识体系的?
这个将 "非结构化文本"转化为"结构化知识"并加以利用 的过程,正是GraphRAG的核心魔法。理解这套工作流程,不仅能让我们知其然,更能知其所以然,看清其能力优势背后的实现逻辑。
要深入理解 GraphRAG 的设计初衷,微软的论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》2404.16130 从局部到全局:以图RAG方法进行查询聚焦总结(GraphRAG: Practical Guide to Supercharge RAG with Knowledge Graphs)给出了清晰的解答。针对传统 RAG 的两大局限性提出了解决方案:
- 针对"信息以模糊文本呈现"的局限 :传统RAG提供的是需要二次解读的自然语言片段,关系隐含其中。GraphRAG则先构建实体知识图谱 ,将知识转化为机器可直接处理的、确定性的关系结构。
- 针对"检索基于局部语义相似"的局限 :传统RAG的检索受限于向量相似度,难以进行全局逻辑关联。GraphRAG通过预先生成层次化的社区摘要 ,使系统能够基于图谱进行跨越文档的逻辑关联与推理。
因此,当面对需要对整个文档集进行综合理解的全局查询时,传统RAG往往只能返回零散的文本碎片。而GraphRAG凭借其结构化的知识表示与检索机制 ,能够生成更全面、更多样的回答,本质上是将检索从"局部文本匹配"升级为"全局知识导航"。
1.GraphRAG的基本流程
GraphRAG的基本流程如下图,分为两阶段:索引阶段和查询阶段(紫色块属于索引阶段,绿色块属于查询阶段)。
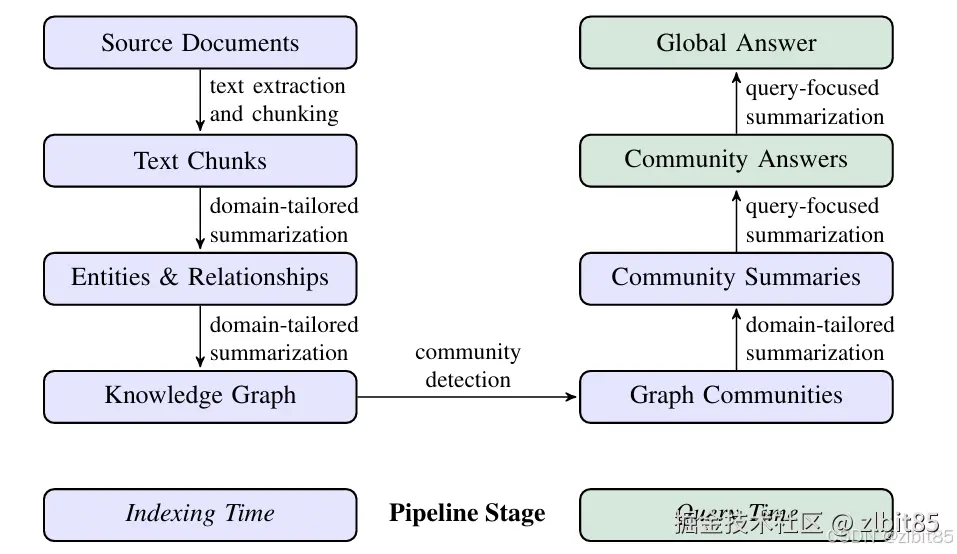
1.1GraphRAG的索引阶段
GraphRAG的索引阶段是其工作流程中的关键预处理步骤,核心目标是从原始数据中构建或丰富知识图谱。微软提出的GraphRAG索引过程包含两个主要阶段:
第一阶段:构建知识图谱------将文本转化为结构化知识
知识图谱是GraphRAG的"大脑",其构建是从原始文本中提取结构化知识的炼金过程。这个过程主要分为三步,目标是将非结构化的文字,转化为由"节点"(实体)和"边"(关系)构成的清晰网络。
步骤一:智能分块------为处理做好准备
首先,海量文档会被分割成大小适宜的文本块。这是一个关键的权衡:
- 小块策略:能保留更细粒度的信息,适合捕捉局部细节,但会增加处理次数与成本。
- 大块策略 :能减少调用、降低成本,但可能因上下文过长而遗漏文本内部的一些关键关联。
此步骤的目标是在信息完整性与处理效率间找到最佳平衡,为下一步的精准提取奠定基础。
步骤二:核心提取------识别实体与关系
每个文本块会被送入大语言模型,执行一项核心指令:识别所有指定类型的实体,以及它们彼此间的关系。
具体来说,大模型会完成两件事:
- 实体识别:找出所有人、事、物、概念等,并为其生成唯一的ID、规范的名称、类型和详细描述。
- 关系抽取:在所有实体间,找出那些存在明确关联的配对,并定义关系的具体内涵与强度。
以下是驱动这一过程的标准化指令模板与输出示例:
csharp
// 大模型接收的指令核心
-Goal-:从文本中提取所有实体及关系。
-Steps-:
1. 识别所有实体,记录其名称、类型、描述。
2. 识别所有关联的实体对,记录关系描述与强度。
// 大模型产出的结构化结果示例
# 实体(节点)
{
"nodes": [
{"id": "n0", "type": "PATIENT", "name": "患者", "description": "一位71岁男性..."},
{"id": "n1", "type": "DIAGNOSIS", "name": "外周血管疾病", "description": "一种循环系统疾病..."}
]
}
# 关系(边)
{
"edges": [
{"source": "n0", "target": "n1", "description": "患者被诊断患有此疾病"}
]
}步骤三:图谱合成------从碎片到整体
最后,系统将所有文本块中提取出的"实体-关系"碎片进行融合,构建成一个统一、全局的知识图谱。
- 关键操作是"去重与合并" :同一实体(如"患者张三")无论在不同块中被提到多少次,在最终的图谱中只会有一个对应的节点,其所有相关信息会被聚合。
- 至此,散落在文档各处的信息被整合成一张互联的知识网络,为后续的图检索与推理提供了坚实的数据基础。
第二阶段: 构建社区层次结构并生成摘要 ------从"知识网络"到"信息地图"
在构建出统一的知识图谱后,GraphRAG并没有止步。为了让系统不仅能理解细粒度的事实,还能把握文本集的整体结构与宏观主题,它进行了关键的第二阶段处理:社区发现与层次化摘要。这相当于为知识网络绘制了"行政区划图"和"地区简介"。
步骤四:图分区------自动发现知识"社区"
GraphRAG运用 Leiden社区发现算法,对知识图谱进行智能分区。这个算法的工作原理与效果如下:
- 层次化聚类 :算法以递归的方式,将图谱中联系紧密的节点聚集为语义社区,并可以进一步在社区内发现子社区,形成一种层次化结构,直至无法再分为止。
- 精准归属 :算法确保每个节点只归属于一个社区,且没有节点被遗漏,这保证了社区之间界限清晰、覆盖全面。
- 规模感知 :社区或节点的大小可以反映其在本层中的重要性或相关度,为后续检索提供直观的权重参考。
通过这种分区,零散的实体被组织成了具有内在主题性的群体,为高效检索奠定了基础。当面临查询时,系统可以根据问题的范畴,动态选择在不同层级(如第0层全局、第1层主题域、第N层具体事实)的社区中进行搜索,实现"从宏观到微观"的精准导航。
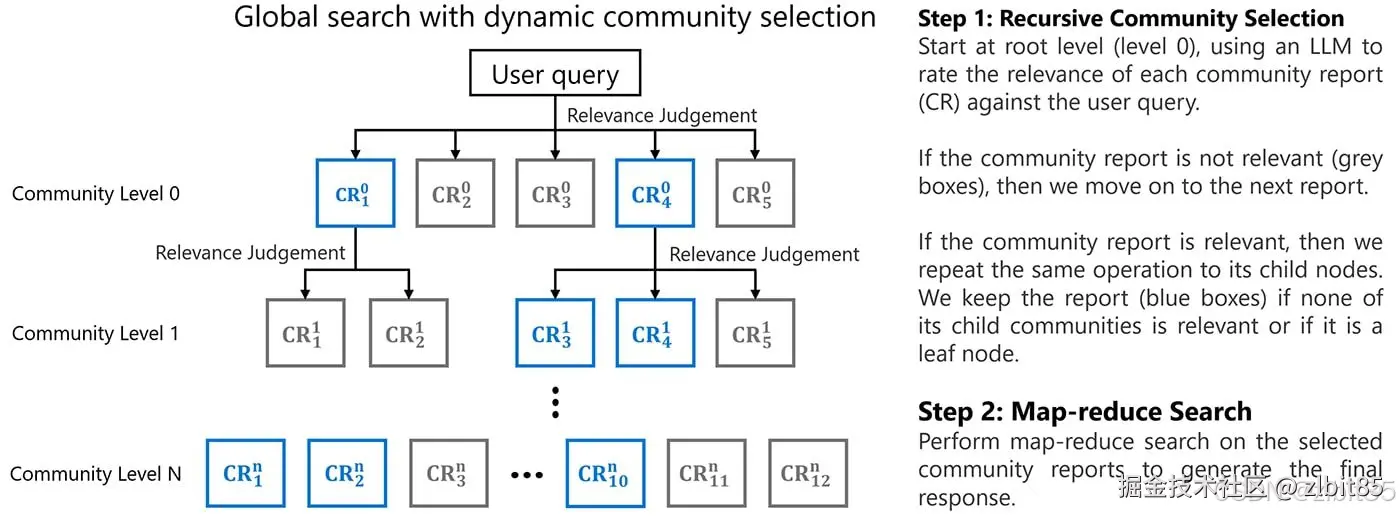
步骤五:社区摘要------生成层级"信息档案"
分区完成后,GraphRAG会为每个社区(尤其是高层级社区)生成一份结构化摘要。这份摘要旨在浓缩该社区的核心信息,使其无需回溯所有原始细节就能被理解。
生成过程遵循一个明确的报告指令,确保摘要的全面与可用:
markdown
# 目标
为指定社区撰写一份综合报告,用于向决策者清晰传达该社区的核心信息及潜在影响。
# 报告结构
- **标题**:能代表社区核心实体的简短具体名称。
- **摘要**:社区整体结构、实体关系及关键信息的概述。
- **影响等级**:一个0-10的分数,量化该社区的重要性或影响严重性。
- **等级说明**:对上述评分的一句话解释。
- **详细发现**:列出5-10条关于该社区的核心见解,每条均包含简短总结与详实阐述。通过这套方法,GraphRAG实现了 "从局部到全局" 的跨越:
- 局部:叶子或底层社区保留了最精细的节点与关系细节,擅长回答具体事实问题。
- 全局 :高层级社区聚合了多个子社区的精要,在适应大模型上下文窗口限制的同时,保留了最相关的宏观信息,使其能够回答如 "所有故事中共同涉及的核心人物是谁?" 这类需要全局视野的问题。
这正是其论文题为 《From Local to Global: A GraphRAG Approach to Query-Focused Summarization》 的原因。相比直接对源文本进行摘要,这种基于社区结构的层次化摘要 ,能够对非指向叶子节点的、更为宽泛或高层的查询,给出更准确、更具洞见的回答。
1.2GraphRAG的查询阶段
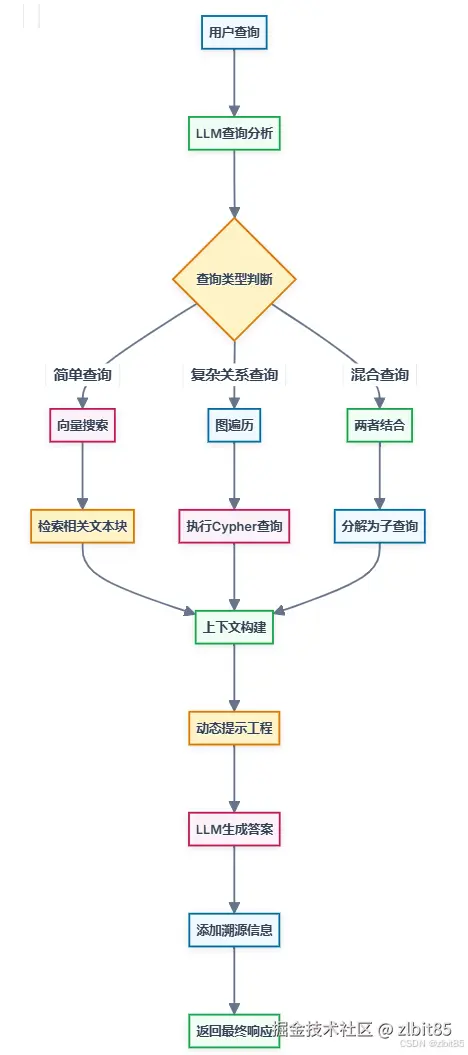
GraphRAG的查询阶段利用索引阶段构建的知识图谱和相关结构来回答用户问题,比传统RAG更复杂,涉及图遍历、多源信息整合和精细化的提示工程。
(图来自GraphRAG:原理、流程、实战与搭建)
1. 查询理解
系统接收用户自然语言查询,由LLM解析查询意图,识别关键实体并判断潜在查询类型。
2. 混合检索
根据查询类型,执行图检索(沿知识图谱关系边遍历)和/或向量检索(语义相似度搜索),支持灵活组合的检索策略。
3. 上下文增强
整合检索结果,引入相关社区摘要,并将图结构信息序列化,构建出结构清晰、信息丰富的提示内容。
4. 生成与溯源
LLM基于增强后的上下文生成自然语言答案,并可附带来源追溯与解释性信息,提升回答的可信度与可解释性。
在查询阶段,GraphRAG 并非直接检索海量的原始文本或遍历整个知识图谱,而是借助已生成的社区摘要进行高效、聚焦的信息合成。其核心流程如下:
1. 查询聚焦的摘要检索
系统首先解析用户查询,识别其中的关键实体与关系,并以此在知识图谱中匹配相似的语义模式。随后,系统仅召回与这些模式最相关的预生成社区摘要,而非处理全部图谱数据。这确保了检索的精准性与可扩展性。
2. 基于 Map Reduce 的答案合成
为了并行、高效地处理多个相关社区摘要,系统采用 Map Reduce 计算框架:
- Map(映射)阶段 :并行处理每一个被召回的社区摘要,生成多条可能回答查询的中间摘要片段 ,并为每个片段计算一个 0-100 分的重要性得分,量化该信息对回答当前问题的关键程度。
- Reduce(归约)阶段 :将所有中间摘要按重要性得分降序排序,筛选出高分片段,进行整合、去重与精炼,最终合成一个全面、连贯且紧扣问题的全局答案。
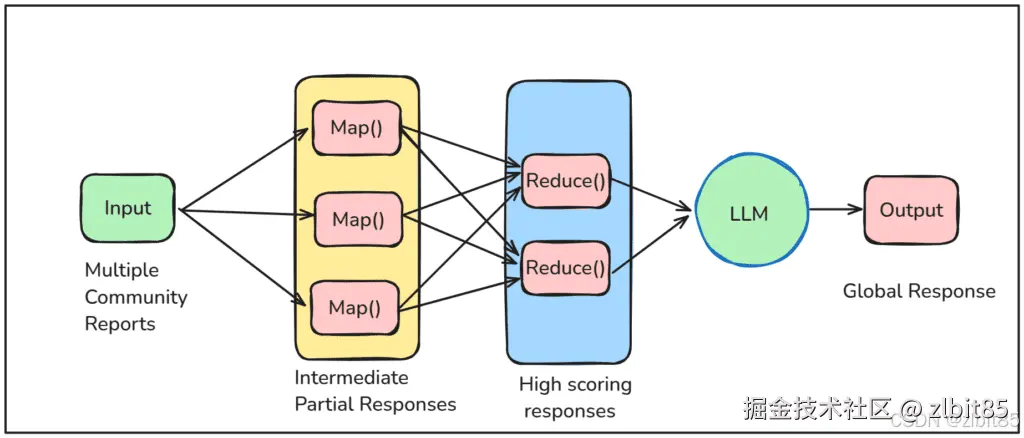
通过这一机制,GraphRAG 能够快速从大规模知识中定位核心信息,并组织成结构清晰、依据明确的回答。
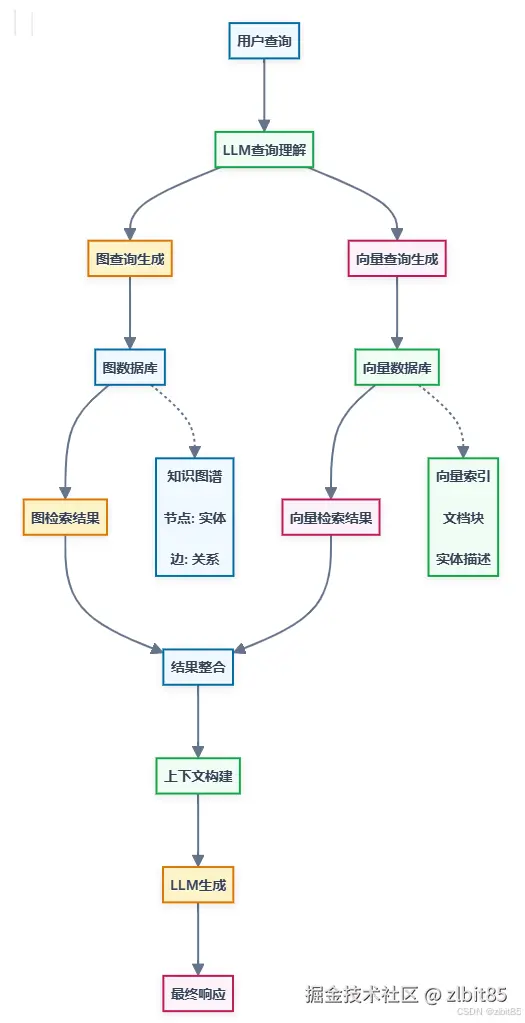
2.GraphRAG的核心架构
GraphRAG的架构是对传统RAG的扩展和增强,通过引入知识图谱及其相关处理组件,实现了更强大的信息检索和推理能力。
(图来自GraphRAG:原理、流程、实战与搭建)
知识图谱
存储结构化知识,形成节点与边的关系网络。
图检索器
执行关系路径查询,支持多跳检索与图谱遍历。
图推理器
对检索路径进行逻辑验证与相关性评估。
向量存储
存储向量嵌入,支持基于相似度的语义检索。
大型语言模型
负责查询解析、图谱增强、检索协同与最终答案生成。
编排框架
管理和协调各组件之间的交互和工作流程
3.GraphRAG的局限与改进方向
尽管微软 GraphRAG 为基于知识图谱的检索增强生成提供了开创性的实现方案,并在全局推理与复杂问答上展现出显著优势,但其在实际部署与应用中仍存在若干明显局限,也由此催生了多种旨在优化性能与效率的后续方案。
3.1GraphRAG 的主要局限
- 计算成本与效率瓶颈
基于社区的索引与检索机制需多次调用大语言模型(LLM)API,整体流程较为缓慢,且成本显著提高,难以适应实时或高频查询场景。 - 图谱噪声与冗余问题
在构建知识图谱时,系统未设置专门的去重机制,导致重复实体与关系可能被多次提取并录入图谱,从而引入噪声,影响检索精度与答案质量。 - 缺乏高效的增量更新能力
当前实现中,若要在已有知识图谱中插入新数据,必须重新构建整个图谱索引。这种全量重建的方式在数据动态更新的生产环境中缺乏可行性,限制了系统的可持续维护与扩展。
3.2GraphRAG 的演进与优化方案
微软的实现虽被广泛视为 GraphRAG 的标杆,但其上述局限也推动了后续一系列旨在提升效率与准确性的改进工作。实际上,在图谱增强检索的方向上,早期已有 NebulaGraph、LangChain、LlamaIndex、Neo4j 等项目进行过相关探索。
目前,较有代表性的改进方向与衍生方案包括:
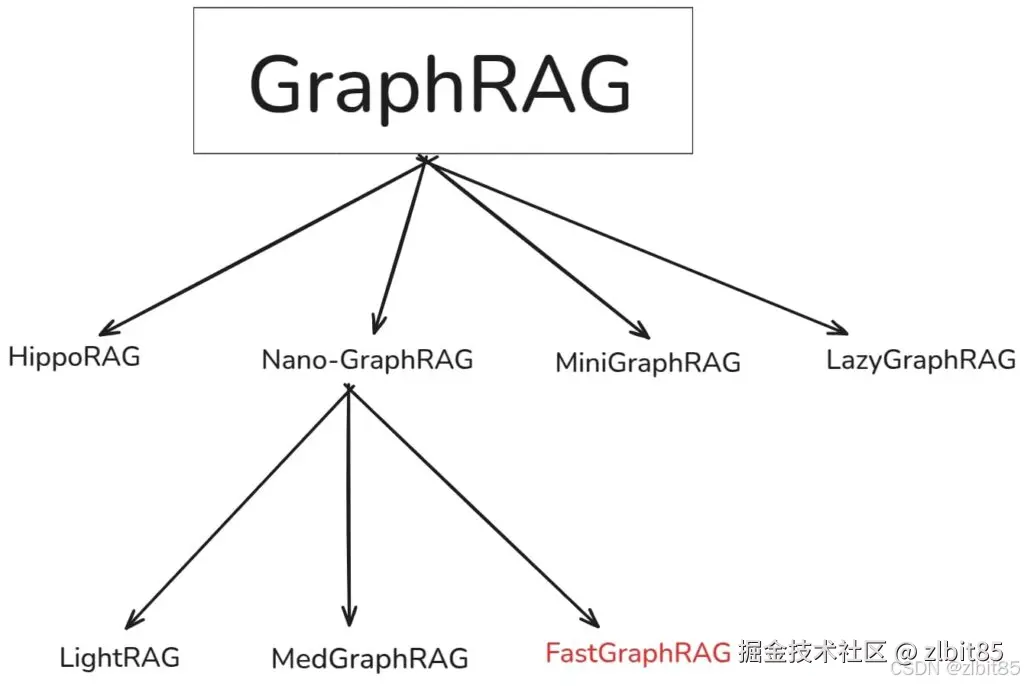
- 轻量化与高效化变体
例如 Nano-GraphRAG 系列(含 LightRAG、MedGraphRAG、FastGraphRAG 等),通过简化检索逻辑、减少不必要的社区计算与聚合步骤,显著降低了系统复杂性与响应延迟。
以nano-graphrag为例,它不再采用原版中 Map-Reduce 式的多社区打分与合并策略,而是仅选取 Top‑K 个最相关社区进行深度检索,从而在保证效果的前提下大幅提升效率。 - 结构优化与扩展方案
诸如 HippoRAG、MiniGraphRAG、LayGraphRAG 等,则在图谱构建、社区划分、检索融合等环节引入不同优化策略,进一步在效果、效率与可扩展性之间寻求更优平衡。
这些改进方案共同反映了 GraphRAG 生态的一个清晰趋势:在保持其结构化检索与全局推理核心优势 的同时,不断优化工程落地成本、响应速度与运维灵活性,推动图增强检索技术向更实用、更易用的方向发展。
二、GraphRAG的工作流程
通过前面的对比,我们已经清晰地看到:GraphRAG凭借其结构化的知识图谱,在复杂推理与全局理解任务上,相比传统RAG展现出了显著优势。
然而,一个关键问题随之而来:这个更强大的"推理侦探"或"知识架构师",其内部究竟是如何运作的?它是怎样将一堆原始文本,一步步炼化成那个可用于深度检索的结构化知识体系的?
这个将 "非结构化文本"转化为"结构化知识"并加以利用 的过程,正是GraphRAG的核心魔法。理解这套工作流程,不仅能让我们知其然,更能知其所以然,看清其能力优势背后的实现逻辑。
要深入理解 GraphRAG 的设计初衷,微软的论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》2404.16130 从局部到全局:以图RAG方法进行查询聚焦总结(GraphRAG: Practical Guide to Supercharge RAG with Knowledge Graphs)给出了清晰的解答。针对传统 RAG 的两大局限性提出了解决方案:
- 针对"信息以模糊文本呈现"的局限 :传统RAG提供的是需要二次解读的自然语言片段,关系隐含其中。GraphRAG则先构建实体知识图谱 ,将知识转化为机器可直接处理的、确定性的关系结构。
- 针对"检索基于局部语义相似"的局限 :传统RAG的检索受限于向量相似度,难以进行全局逻辑关联。GraphRAG通过预先生成层次化的社区摘要 ,使系统能够基于图谱进行跨越文档的逻辑关联与推理。
因此,当面对需要对整个文档集进行综合理解的全局查询时,传统RAG往往只能返回零散的文本碎片。而GraphRAG凭借其结构化的知识表示与检索机制 ,能够生成更全面、更多样的回答,本质上是将检索从"局部文本匹配"升级为"全局知识导航"。
1.GraphRAG的基本流程
GraphRAG的基本流程如下图,分为两阶段:索引阶段和查询阶段(紫色块属于索引阶段,绿色块属于查询阶段)。
编辑
1.1GraphRAG的索引阶段
GraphRAG的索引阶段是其工作流程中的关键预处理步骤,核心目标是从原始数据中构建或丰富知识图谱。微软提出的GraphRAG索引过程包含两个主要阶段:
第一阶段:构建知识图谱------将文本转化为结构化知识
知识图谱是GraphRAG的"大脑",其构建是从原始文本中提取结构化知识的炼金过程。这个过程主要分为三步,目标是将非结构化的文字,转化为由"节点"(实体)和"边"(关系)构成的清晰网络。
步骤一:智能分块------为处理做好准备
首先,海量文档会被分割成大小适宜的文本块。这是一个关键的权衡:
- 小块策略:能保留更细粒度的信息,适合捕捉局部细节,但会增加处理次数与成本。
- 大块策略 :能减少调用、降低成本,但可能因上下文过长而遗漏文本内部的一些关键关联。
此步骤的目标是在信息完整性与处理效率间找到最佳平衡,为下一步的精准提取奠定基础。
步骤二:核心提取------识别实体与关系
每个文本块会被送入大语言模型,执行一项核心指令:识别所有指定类型的实体,以及它们彼此间的关系。
具体来说,大模型会完成两件事:
- 实体识别:找出所有人、事、物、概念等,并为其生成唯一的ID、规范的名称、类型和详细描述。
- 关系抽取:在所有实体间,找出那些存在明确关联的配对,并定义关系的具体内涵与强度。
以下是驱动这一过程的标准化指令模板与输出示例:
csharp
// 大模型接收的指令核心
-Goal-:从文本中提取所有实体及关系。
-Steps-:
1. 识别所有实体,记录其名称、类型、描述。
2. 识别所有关联的实体对,记录关系描述与强度。
// 大模型产出的结构化结果示例
# 实体(节点)
{
"nodes": [
{"id": "n0", "type": "PATIENT", "name": "患者", "description": "一位71岁男性..."},
{"id": "n1", "type": "DIAGNOSIS", "name": "外周血管疾病", "description": "一种循环系统疾病..."}
]
}
# 关系(边)
{
"edges": [
{"source": "n0", "target": "n1", "description": "患者被诊断患有此疾病"}
]
}步骤三:图谱合成------从碎片到整体
最后,系统将所有文本块中提取出的"实体-关系"碎片进行融合,构建成一个统一、全局的知识图谱。
- 关键操作是"去重与合并" :同一实体(如"患者张三")无论在不同块中被提到多少次,在最终的图谱中只会有一个对应的节点,其所有相关信息会被聚合。
- 至此,散落在文档各处的信息被整合成一张互联的知识网络,为后续的图检索与推理提供了坚实的数据基础。
第二阶段: 构建社区层次结构并生成摘要 ------从"知识网络"到"信息地图"
在构建出统一的知识图谱后,GraphRAG并没有止步。为了让系统不仅能理解细粒度的事实,还能把握文本集的整体结构与宏观主题,它进行了关键的第二阶段处理:社区发现与层次化摘要。这相当于为知识网络绘制了"行政区划图"和"地区简介"。
步骤四:图分区------自动发现知识"社区"
GraphRAG运用 Leiden社区发现算法,对知识图谱进行智能分区。这个算法的工作原理与效果如下:
- 层次化聚类 :算法以递归的方式,将图谱中联系紧密的节点聚集为语义社区,并可以进一步在社区内发现子社区,形成一种层次化结构,直至无法再分为止。
- 精准归属 :算法确保每个节点只归属于一个社区,且没有节点被遗漏,这保证了社区之间界限清晰、覆盖全面。
- 规模感知 :社区或节点的大小可以反映其在本层中的重要性或相关度,为后续检索提供直观的权重参考。
通过这种分区,零散的实体被组织成了具有内在主题性的群体,为高效检索奠定了基础。当面临查询时,系统可以根据问题的范畴,动态选择在不同层级(如第0层全局、第1层主题域、第N层具体事实)的社区中进行搜索,实现"从宏观到微观"的精准导航。
编辑
步骤五:社区摘要------生成层级"信息档案"
分区完成后,GraphRAG会为每个社区(尤其是高层级社区)生成一份结构化摘要。这份摘要旨在浓缩该社区的核心信息,使其无需回溯所有原始细节就能被理解。
生成过程遵循一个明确的报告指令,确保摘要的全面与可用:
markdown
# 目标
为指定社区撰写一份综合报告,用于向决策者清晰传达该社区的核心信息及潜在影响。
# 报告结构
- **标题**:能代表社区核心实体的简短具体名称。
- **摘要**:社区整体结构、实体关系及关键信息的概述。
- **影响等级**:一个0-10的分数,量化该社区的重要性或影响严重性。
- **等级说明**:对上述评分的一句话解释。
- **详细发现**:列出5-10条关于该社区的核心见解,每条均包含简短总结与详实阐述。通过这套方法,GraphRAG实现了 "从局部到全局" 的跨越:
- 局部:叶子或底层社区保留了最精细的节点与关系细节,擅长回答具体事实问题。
- 全局 :高层级社区聚合了多个子社区的精要,在适应大模型上下文窗口限制的同时,保留了最相关的宏观信息,使其能够回答如 "所有故事中共同涉及的核心人物是谁?" 这类需要全局视野的问题。
这正是其论文题为 《From Local to Global: A GraphRAG Approach to Query-Focused Summarization》 的原因。相比直接对源文本进行摘要,这种基于社区结构的层次化摘要 ,能够对非指向叶子节点的、更为宽泛或高层的查询,给出更准确、更具洞见的回答。
1.2GraphRAG的查询阶段
GraphRAG的查询阶段利用索引阶段构建的知识图谱和相关结构来回答用户问题,比传统RAG更复杂,涉及图遍历、多源信息整合和精细化的提示工程。
编辑
(图来自GraphRAG:原理、流程、实战与搭建)
1. 查询理解
系统接收用户自然语言查询,由LLM解析查询意图,识别关键实体并判断潜在查询类型。
2. 混合检索
根据查询类型,执行图检索(沿知识图谱关系边遍历)和/或向量检索(语义相似度搜索),支持灵活组合的检索策略。
3. 上下文增强
整合检索结果,引入相关社区摘要,并将图结构信息序列化,构建出结构清晰、信息丰富的提示内容。
4. 生成与溯源
LLM基于增强后的上下文生成自然语言答案,并可附带来源追溯与解释性信息,提升回答的可信度与可解释性。
在查询阶段,GraphRAG 并非直接检索海量的原始文本或遍历整个知识图谱,而是借助已生成的社区摘要进行高效、聚焦的信息合成。其核心流程如下:
1. 查询聚焦的摘要检索
系统首先解析用户查询,识别其中的关键实体与关系,并以此在知识图谱中匹配相似的语义模式。随后,系统仅召回与这些模式最相关的预生成社区摘要,而非处理全部图谱数据。这确保了检索的精准性与可扩展性。
2. 基于 Map Reduce 的答案合成
为了并行、高效地处理多个相关社区摘要,系统采用 Map Reduce 计算框架:
- Map(映射)阶段 :并行处理每一个被召回的社区摘要,生成多条可能回答查询的中间摘要片段 ,并为每个片段计算一个 0-100 分的重要性得分,量化该信息对回答当前问题的关键程度。
- Reduce(归约)阶段 :将所有中间摘要按重要性得分降序排序,筛选出高分片段,进行整合、去重与精炼,最终合成一个全面、连贯且紧扣问题的全局答案。
编辑
通过这一机制,GraphRAG 能够快速从大规模知识中定位核心信息,并组织成结构清晰、依据明确的回答。
2.GraphRAG的核心架构
GraphRAG的架构是对传统RAG的扩展和增强,通过引入知识图谱及其相关处理组件,实现了更强大的信息检索和推理能力。
编辑
(图来自GraphRAG:原理、流程、实战与搭建)
知识图谱
存储结构化知识,形成节点与边的关系网络。
图检索器
执行关系路径查询,支持多跳检索与图谱遍历。
图推理器
对检索路径进行逻辑验证与相关性评估。
向量存储
存储向量嵌入,支持基于相似度的语义检索。
大型语言模型
负责查询解析、图谱增强、检索协同与最终答案生成。
编排框架
管理和协调各组件之间的交互和工作流程
3.GraphRAG的局限与改进方向
尽管微软 GraphRAG 为基于知识图谱的检索增强生成提供了开创性的实现方案,并在全局推理与复杂问答上展现出显著优势,但其在实际部署与应用中仍存在若干明显局限,也由此催生了多种旨在优化性能与效率的后续方案。
3.1GraphRAG 的主要局限
- 计算成本与效率瓶颈
基于社区的索引与检索机制需多次调用大语言模型(LLM)API,整体流程较为缓慢,且成本显著提高,难以适应实时或高频查询场景。 - 图谱噪声与冗余问题
在构建知识图谱时,系统未设置专门的去重机制,导致重复实体与关系可能被多次提取并录入图谱,从而引入噪声,影响检索精度与答案质量。 - 缺乏高效的增量更新能力
当前实现中,若要在已有知识图谱中插入新数据,必须重新构建整个图谱索引。这种全量重建的方式在数据动态更新的生产环境中缺乏可行性,限制了系统的可持续维护与扩展。
3.2GraphRAG 的演进与优化方案
微软的实现虽被广泛视为 GraphRAG 的标杆,但其上述局限也推动了后续一系列旨在提升效率与准确性的改进工作。实际上,在图谱增强检索的方向上,早期已有 NebulaGraph、LangChain、LlamaIndex、Neo4j 等项目进行过相关探索。
目前,较有代表性的改进方向与衍生方案包括:
编辑
- 轻量化与高效化变体
例如 Nano-GraphRAG 系列(含 LightRAG、MedGraphRAG、FastGraphRAG 等),通过简化检索逻辑、减少不必要的社区计算与聚合步骤,显著降低了系统复杂性与响应延迟。
以nano-graphrag为例,它不再采用原版中 Map-Reduce 式的多社区打分与合并策略,而是仅选取 Top‑K 个最相关社区进行深度检索,从而在保证效果的前提下大幅提升效率。 - 结构优化与扩展方案
诸如 HippoRAG、MiniGraphRAG、LayGraphRAG 等,则在图谱构建、社区划分、检索融合等环节引入不同优化策略,进一步在效果、效率与可扩展性之间寻求更优平衡。
这些改进方案共同反映了 GraphRAG 生态的一个清晰趋势:在保持其结构化检索与全局推理核心优势 的同时,不断优化工程落地成本、响应速度与运维灵活性,推动图增强检索技术向更实用、更易用的方向发展。
三、GraphRAG的实践
纸上得来终觉浅,绝知此事要躬行。我这次的实践例子是参考"微信公众号:大模型真好玩"发布的案例:微软GraphRAG代码实战。
1.GraphRAG安装使用
1.1GraphRAG环境搭建
GraphRAG环境搭建我们使用Anaconda管理Python虚拟环境。首先执行以下命令创建并配置虚拟环境,将其命名为metaGraphRAG,并在该环境中安装GraphRAG相关依赖。此外,我们还将使用Jupyter Notebook编写代码,因此需要一并安装Jupyter内核。
具体操作命令如下:
ini
# 1. 创建虚拟环境
conda create -n metaGraphRAG python=3.12
# 2. 激活虚拟环境
conda activate metaGraphRAG
# 3. 安装JupyterLab及内核
conda install jupyterlab ipykernel
# 4. 将当前环境添加为Jupyter内核
python -m ipykernel install --user --name metaGraphRAG --display-name "Python (metaGraphRAG)"完成上述步骤后,在项目目录下执行
jupyter notebook浏览器将自动打开Jupyter界面。若内核安装正确,将显示类似下图的界面:
接下来,在激活的 metaGraphRAG 环境中安装GraphRAG依赖包:
pip install graphrag1.2 GraphRAG项目配置
创建好虚拟环境后,接下来使用GraphRAG构建知识图谱。
步骤一:创建项目目录结构
在项目目录下执行以下命令,创建嵌套的检索文件夹。外层目录可自定义(此处示例为openl),内层文件夹必须命名为input:
bash
mkdir -p ./openl/input步骤二:准备数据集
在 ./openl/input 文件夹中创建 大数据时代.txt 文件,并写入如下内容:
《大数据时代》是一本由维克托·迈尔-舍恩伯格与肯尼斯·库克耶合著的书籍,讨论了如何在海量数据中挖掘出有价值的信息。这本书深入探讨了数据科学的应用,并阐述了数据分析和预测在各行各业中的影响力。在书中,作者举了许多实际例子,说明大数据如何改变我们的生活,甚至如何预测未来的趋势。步骤三:初始化项目
GraphRAG 会针对 input 文件夹中的每个文件进行分析。将文档放入 input 文件夹后,执行以下命令,GraphRAG 将根据输入文档生成相应的配置文件:
bash
graphrag init --root ./openl初始化完成后,openl 文件夹中会自动生成 prompt(提示词文件夹)和 settings.yaml(配置文件)。
步骤四:配置模型参数
GraphRAG 依赖大模型进行知识图谱构建与检索,默认使用 OpenAI 模型。由于网络限制,本次我们使用硅基流动提供的模型服务
修改 settings.yaml 配置文件中 models 部分如下,其中 chat 模型选用 Qwen3-8B,embedding 模型选用 BAAI/bge-m3:
yaml
models:
default_chat_model:
type: chat
model_provider: openai # 硅基流动兼容OpenAI API
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY} # 设置为硅基流动的API Key
model: Qwen/Qwen3-8B
api_base: https://api.siliconflow.cn/v1 # 添加硅基流动的API端点
# api_version: 2024-05-01-preview
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25
async_mode: threaded # or asyncio
retry_strategy: exponential_backoff
max_retries: 10
tokens_per_minute: null
requests_per_minute: null
default_embedding_model:
type: embedding
model_provider: openai
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: BAAI/bge-m3 # 修改为BAAI/bge-m3
api_base: https://api.siliconflow.cn/v1 # 添加硅基流动的API端点
# api_version: 2024-05-01-preview
concurrent_requests: 25
async_mode: threaded # or asyncio
retry_strategy: exponential_backoff
max_retries: 10
tokens_per_minute: null
requests_per_minute: null步骤五:调整文本切分参数
为了更清晰地演示 GraphRAG 的全过程,此处需根据短文本来调整 chunk 大小。修改 settings.yaml 中的 chunks 配置如下:
yaml
chunks:
size: 50 # 每个文本块包含的词语数
overlap: 10 # 不同文本块间重合词语数
group_by_columns: [id]至此,GraphRAG 的基本配置已完成。接下来可以按照我们前面介绍过的基本流程进行:执行知识图谱构建与检索的后续流程。
1.3GraphRAG 使用方法
GraphRAG 提供了不同层次的调用方法。我感觉使用命令行调用 还挺方便的,一两行命令即可完成核心流程。若需要进行定制化开发或与现有系统集成调优,则需使用低层级的 Python API 。本小章将介绍这两种方法,并依照 "索引" 与 "查询" 两大核心阶段进行组织。
1.3.1命令行调用
(1)索引阶段:构建知识图谱
1.命令行构建知识图谱
执行以下命令,启动完整的索引流程。该过程将自动化执行知识图谱构建与社区发现:
bash
graphrag index --root ./openl执行期间,GraphRAG 会在后台依次完成文本分块、实体关系提取、图谱合成、社区划分与摘要生成。所有输出结果将以高效的 Parquet 格式 保存在 ./openl/output/ 目录下,包含以下关键数据表:
entities.parquet:实体表,知识图谱的所有节点。relationships.parquet:关系表,知识图谱中连接实体的边。communities.parquet:社区表,通过算法划分出的实体群落。community_reports.parquet:社区报告表,每个社区的结构化摘要,用于全局检索。documents.parquet:原始文档表。text_units.parquet:文本块表。

2.数据探查:表格展示
为直观理解索引结果,可在 Jupyter Notebook 中使用 pandas 读取并查看各表内容。这是评估知识图谱构建质量(如实体抽取是否全面)的直接方式。
读取文件表:
python
import pandas as pd
document_df = pd.read_parquet(r'D:\pycharm(code)\Agent\GraphRAG\openl\output\documents.parquet')
document_df
读取文件块表:
python
text_unit_df = pd.read_parquet(r'D:\pycharm(code)\Agent\GraphRAG\openl\output\text_units.parquet')
text_unit_df
读取实体表, 知识图谱构建完成后,我们一般第一时间去看实体表,看实体构建是否合适,合适表示知识图谱构建比较全面, 不合适就要对提示词进行调整了。
python
entities_df = pd.read_parquet(r'D:\pycharm(code)\Agent\GraphRAG\openl\output\entities.parquet')
entities_df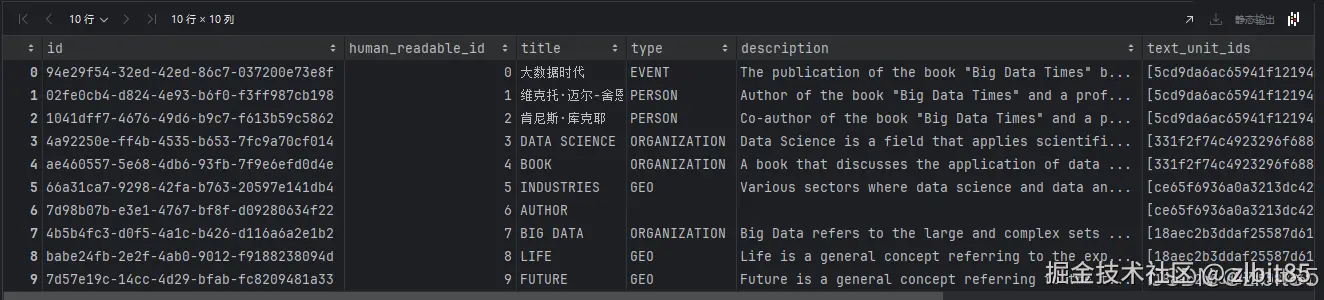
读取关系表:
python
relationships_df = pd.read_parquet(r'D:\pycharm(code)\Agent\GraphRAG\openl\output\relationships.parquet')
relationships_df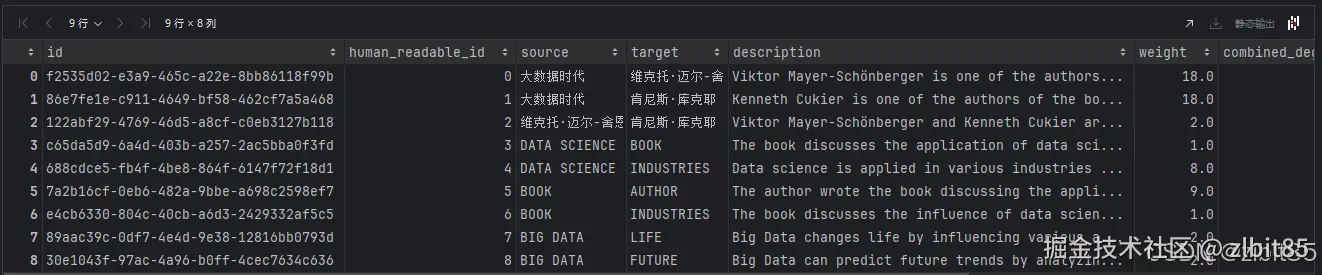
读取社区表:
python
communities_df = pd.read_parquet(r'D:\pycharm(code)\Agent\GraphRAG\openl\output\communities.parquet')
communities_df
读取社区报告表:
ini
community_reports_df = pd.read_parquet('D:\pycharm(code)\Agent\GraphRAG\openl\output\community_reports.parquet')
community_reports_df
提示 :默认输出为英文,这是因为 GraphRAG 内置的提取提示词为英文。如需中文输出,需提前翻译
./openl/prompts/目录下的提示词模板文件。
3.可视化:知识图谱展示
除表格外,可通过可视化直观呈现实体与关系构成的网络。
安装可视化库:
ini
%pip install yfiles_jupyter_graphs==1.7.3准备数据并绘图:
实体数据处理函数:
scss
def convert_entities_to_dict(df):
nodes_dict = {}
for _, row in df.iterrows():
node_id = row['title'] # 使用title作为节点唯一标识
if node_id not in nodes_dict:
nodes_dict[node_id] = {
"id": node_id,
"properties": row.to_dict(),
}
return list(nodes_dict.values())功能:将Pandas DataFrame格式的实体表转换为图可视化所需的节点列表格式
- 输入:
entities.parquet读取的DataFrame - 输出:格式为
[{"id": "...", "properties": {...}}, ...]的节点列表 - 去重逻辑:基于
title字段避免重复节点
关系数据处理函数
python
def convert_relationships_to_dicts(df):
relationships = []
for _, row in df.iterrows():
relationships.append({
"start": row['source'], # 关系的起始节点(title)
"end": row['target'], # 关系的目标节点(title)
"properties": row.to_dict(), # 关系的所有属性
})
return relationships功能:将关系表转换为图的边列表格式
- 每一条边包含
start(源节点)、end(目标节点)和完整属性
颜色映射函数
python
# 社区到颜色的映射
def community_to_color(community):
"""Map a community to a color"""
colors = [
"crimson",
"darkorange",
"indigo",
"cornflowerblue",
"cyan",
"teal",
"green",
]
try:
return colors[int(community) % len(colors)] if community is not None else "lightgray"
except (ValueError,TypeError):
# 如果 community 不少整数或其他错误,返回默认颜色
return "lightgray"功能:为不同社区分配不同颜色,便于视觉区分
- 每个社区ID对应一个固定颜色(使用取模运算循环使用颜色列表)
- 未分配社区或错误的社区ID使用灰色
lightgray
边颜色映射辅助函数
python
def edge_to_source_community(edge):
"""Get the community of the source node of an edge."""
source_node = next(
(entry for entry in w.nodes if entry["properties"]["title"] == edge["start"]),
None,
)
source_node_community = source_node["properties"].get("community")
return source_node_community if source_node_community is not None else None绘图
ini
from yfiles_jupyter_graphs import GraphWidget
import pandas as pd
# 1. 定义数据转换函数(将实体/关系表转为图数据结构,略如上)
# 2. 读取数据
entities_df = pd.read_parquet('./openl/output/entities.parquet')
relationships_df = pd.read_parquet('./openl/output/relationships.parquet')
# 3. 创建并配置图谱控件
w = GraphWidget()
w.directed = True # 设置为有向图
w.nodes = convert_entities_to_dicts(entities_df) # 自定义转换函数
w.edges = convert_relationships_to_dicts(relationships_df) # 自定义转换函数
w.node_label_mapping = "title"
# 4. 应用布局并显示
w.circular_layout()
display(w)图谱将清晰展示实体间的关联,例如"《大数据时代》"与"改变我们生活"相连,"维克托"和"肯尼斯"作为合著者相互连接,与原文语义一致。
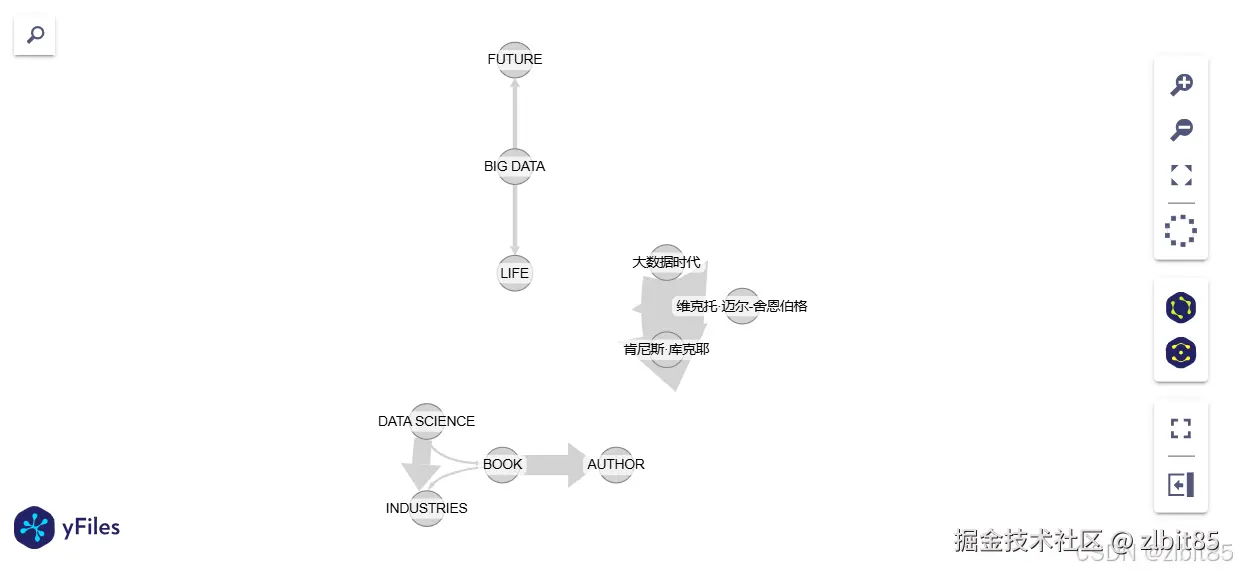
(2)查询阶段:进行问答检索
索引构建完成后,即可进入查询阶段,利用生成的知识图谱和社区摘要回答用户问题。
GraphRAG 支持两种检索策略,通过 --method 参数指定:
- 本地查询 (
local) :在查询相关的具体实体和关系(即图谱的"叶子"社区)中进行深度搜索,适合具体、事实型问题。
erlang
graphrag query --root "D:\pycharm(code)\Agent\GraphRAG\openl" --method local --query "请介绍《大数据时代》" 编辑
编辑
- 全局查询 (
global) :综合利用高层级的社区摘要进行广度搜索,适合宏观、主题型问题。
erlang
graphrag query --root "D:\pycharm(code)\Agent\GraphRAG\openl" --method global --query "请介绍《大数据时代》"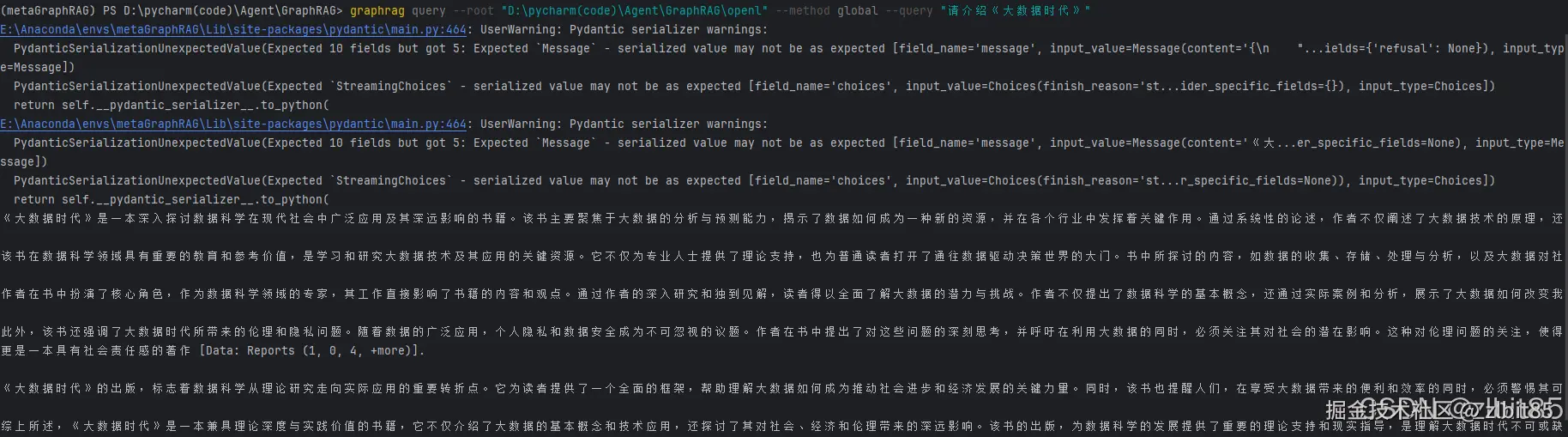
1.3.2python API 调用------高级开发
对于需要将 GraphRAG 集成到现有系统或进行深度定制的开发者,Python API 提供了完整的编程控制能力。本节将详细介绍两种查询模式的 API 调用方法,并解析其内部工作原理。
(1)全局查询模式 API 调用
全局查询利用社区摘要进行高层次语义检索,适合回答宏观、主题型问题。
1.环境初始化
python
import os
import pandas as pd
import yaml
from pathlib import Path
# --- 必须修改:请填入你真实的硅基流动 API Key ---
SILICON_FLOW_KEY = "sk-xxxx"
# 注入环境变量,确保 GraphRAG 底层能读到
os.environ["GRAPHRAG_API_KEY"] = SILICON_FLOW_KEY
os.environ["OPENAI_API_KEY"] = SILICON_FLOW_KEY
os.environ["OPENAI_API_BASE"] = "https://api.siliconflow.cn/v1"
os.environ["OPENAI_BASE_URL"] = "https://api.siliconflow.cn/v1"
print("✅ 环境初始化完成")其实这一步困扰了我一会儿,按照"微软GraphRAG代码实战"例子中我已经在settings.yaml中配置好了环境,在.env文件中也写好了硅基流动的API Key。但是运行起来就报错:401。

这种 "配置幽灵" 之前也又遇到过初步猜测原因可能是变量占位符未被"解析",我显式覆盖就没有问题。
2.导入必要依赖库
python
from collections.abc import AsyncGenerator
from typing import Any
from graphrag.callbacks.noop_query_callbacks import NoopQueryCallbacks
from graphrag.callbacks.query_callbacks import QueryCallbacks
from graphrag.config.models.graph_rag_config import GraphRagConfig
from graphrag.query.factory import get_global_search_engine
from graphrag.query.indexer_adapters import (
read_indexer_communities,
read_indexer_entities,
read_indexer_reports,
)
from graphrag.utils.api import load_search_prompt3.核心函数实现
流式查询函数
ini
def global_search_streaming(
config: GraphRagConfig,
entities: pd.DataFrame,
communities: pd.DataFrame,
community_reports: pd.DataFrame,
community_level: int | None,
dynamic_community_selection: bool,
response_type: str,
query: str,
callbacks: list[QueryCallbacks] | None = None,
) -> AsyncGenerator:
communities_ = read_indexer_communities(communities, community_reports)
reports = read_indexer_reports(
community_reports,
communities,
community_level=community_level,
dynamic_community_selection=dynamic_community_selection,
)
entities_ = read_indexer_entities(
entities, communities, community_level=community_level
)
map_prompt = load_search_prompt(config.root_dir, config.global_search.map_prompt)
reduce_prompt = load_search_prompt(config.root_dir, config.global_search.reduce_prompt)
knowledge_prompt = load_search_prompt(config.root_dir, config.global_search.knowledge_prompt)
search_engine = get_global_search_engine(
config,
reports=reports,
entities=entities_,
communities=communities_,
response_type=response_type,
dynamic_community_selection=dynamic_community_selection,
map_system_prompt=map_prompt,
reduce_system_prompt=reduce_prompt,
general_knowledge_inclusion_prompt=knowledge_prompt,
callbacks=callbacks,
)
return search_engine.stream_search(query=query)完整查询函数(合并流式结果)
ini
async def global_search(
config: GraphRagConfig,
entities: pd.DataFrame,
communities: pd.DataFrame,
community_reports: pd.DataFrame,
community_level: int | None,
dynamic_community_selection: bool,
response_type: str,
query: str,
callbacks: list[QueryCallbacks] | None = None,
) -> tuple[str, dict]:
callbacks = callbacks or []
full_response = ""
context_data = {}
def on_context(context: Any) -> None:
nonlocal context_data
context_data = context
local_callbacks = NoopQueryCallbacks()
local_callbacks.on_context = on_context
callbacks.append(local_callbacks)
async for chunk in global_search_streaming(
config=config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=community_level,
dynamic_community_selection=dynamic_community_selection,
response_type=response_type,
query=query,
callbacks=callbacks,
):
full_response += chunk
return full_response, context_data4.配置与数据准备
python
settings_yaml = r'D:\pycharm(code)\Agent\GraphRAG\openl\settings.yaml'
root_dir = r'D:\pycharm(code)\Agent\GraphRAG\openl'
with open(settings_yaml, 'r', encoding='utf-8') as f:
config_dict = yaml.load(f, Loader=yaml.FullLoader)
# 如果 YAML 里有 ${GRAPHRAG_API_KEY},手动替换为真实 Key
# 针对models 结构进行替换
def replace_key(d):
for k, v in d.items():
if isinstance(v, dict):
replace_key(v)
elif isinstance(v, str) and "${GRAPHRAG_API_KEY}" in v:
d[k] = SILICON_FLOW_KEY
replace_key(config_dict)
# 设置根目录并实例化配置对象
config_dict['root_dir'] = str(Path(root_dir).resolve())
graphRagConfig = GraphRagConfig(**config_dict)
print("✅ 配置文件解析成功,API Key 已注入")
output_path = Path(root_dir) / "output"
entities_df = pd.read_parquet(output_path / 'entities.parquet')
communities_df = pd.read_parquet(output_path / 'communities.parquet')
community_reports_df = pd.read_parquet(output_path / 'community_reports.parquet')
print("✅ 数据文件加载完成")5.执行全局查询
ini
query_text = "请介绍《大数据时代》"
# 在 Notebook 中直接使用 await
res, context = await global_search(
config=graphRagConfig,
entities=entities_df,
communities=communities_df,
community_reports=community_reports_df,
community_level=2,
dynamic_community_selection=False,
response_type="Single Paragraph",
query=query_text,
)
print("-" * 50)
print(f"搜索问题: {query_text}")
print(f"回答内容: {res}")
(2)本地查询模式API调用
1. 环境初始化
本地查询的实现流程与全局查询类似:
python
import os
import pandas as pd
import yaml
import warnings
from pathlib import Path
# --- 必须修改:请填入你真实的硅基流动 API Key ---
SILICON_FLOW_KEY = "sk-XXXX"
# 注入环境变量
os.environ["GRAPHRAG_API_KEY"] = SILICON_FLOW_KEY
os.environ["OPENAI_API_KEY"] = SILICON_FLOW_KEY
os.environ["OPENAI_API_BASE"] = "https://api.siliconflow.cn/v1"
os.environ["OPENAI_BASE_URL"] = "https://api.siliconflow.cn/v1"
print("✅ 环境初始化完成")2.依赖导入
python
from collections.abc import AsyncGenerator
from typing import Any
from graphrag.callbacks.noop_query_callbacks import NoopQueryCallbacks
from graphrag.callbacks.query_callbacks import QueryCallbacks
from graphrag.config.embeddings import entity_description_embedding
from graphrag.config.models.graph_rag_config import GraphRagConfig
from graphrag.query.factory import get_local_search_engine
from graphrag.query.indexer_adapters import (
read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.utils.api import (
get_embedding_store,
load_search_prompt,
)
from graphrag.utils.cli import redact3.核心函数实现
本地流式查询函数
与全局查询不同,本地查询不直接加载社区表与社区报告表,而是直接基于文本向量库和实体表进行检索。
ini
def local_search_streaming(
config: GraphRagConfig,
entities: pd.DataFrame,
communities: pd.DataFrame,
community_reports: pd.DataFrame,
text_units: pd.DataFrame,
relationships: pd.DataFrame,
covariates: pd.DataFrame | None,
community_level: int,
response_type: str,
query: str,
callbacks: list[QueryCallbacks] | None = None,
) -> AsyncGenerator:
"""执行本地搜索并通过生成器返回上下文和响应。"""
# 初始化向量存储参数
vector_store_args = {}
for index, store in config.vector_store.items():
vector_store_args[index] = store.model_dump()
# 获取实体描述的向量库存储
description_embedding_store = get_embedding_store(
config_args=vector_store_args,
embedding_name=entity_description_embedding,
)
# 读取索引数据适配器
entities_ = read_indexer_entities(entities, communities, community_level)
covariates_ = read_indexer_covariates(covariates) if covariates is not None else []
prompt = load_search_prompt(config.root_dir, config.local_search.prompt)
# 构建本地搜索引擎
search_engine = get_local_search_engine(
config=config,
reports=read_indexer_reports(community_reports, communities, community_level),
text_units=read_indexer_text_units(text_units),
entities=entities_,
relationships=read_indexer_relationships(relationships),
covariates={"claims": covariates_},
description_embedding_store=description_embedding_store,
response_type=response_type,
system_prompt=prompt,
callbacks=callbacks,
)
return search_engine.stream_search(query=query)本地查询同步封装函数
ini
async def local_search(
config: GraphRagConfig,
entities: pd.DataFrame,
communities: pd.DataFrame,
community_reports: pd.DataFrame,
text_units: pd.DataFrame,
relationships: pd.DataFrame,
community_level: int,
response_type: str,
query: str,
covariates: pd.DataFrame | None = None,
callbacks: list[QueryCallbacks] | None = None,
) -> tuple[str, dict]:
callbacks = callbacks or []
full_response = ""
context_data = {}
def on_context(context: Any) -> None:
nonlocal context_data
context_data = context
local_callbacks = NoopQueryCallbacks()
local_callbacks.on_context = on_context
callbacks.append(local_callbacks)
async for chunk in local_search_streaming(
config=config,
entities=entities,
communities=communities,
community_reports=community_reports,
text_units=text_units,
relationships=relationships,
covariates=covariates,
community_level=community_level,
response_type=response_type,
query=query,
callbacks=callbacks,
):
full_response += chunk
return full_response, context_data4.配置与数据准备
python
settings_yaml = r'D:\pycharm(code)\Agent\GraphRAG\openl\settings.yaml'
root_dir = r'D:\pycharm(code)\Agent\GraphRAG\openl'
with open(settings_yaml, 'r', encoding='utf-8') as f:
config_dict = yaml.load(f, Loader=yaml.FullLoader)
# 递归替换 ${GRAPHRAG_API_KEY} 占位符
def replace_key_recursively(d):
for k, v in d.items():
if isinstance(v, dict):
replace_key_recursively(v)
elif isinstance(v, str) and "${GRAPHRAG_API_KEY}" in v:
d[k] = SILICON_FLOW_KEY
replace_key_recursively(config_dict)
# 设置根目录并创建配置对象
config_dict['root_dir'] = str(Path(root_dir).resolve())
graphRagConfig = GraphRagConfig(**config_dict)
print("✅ 配置文件解析并注入 Key 成功")
output_path = Path(root_dir) / "output"
entities_df = pd.read_parquet(output_path / 'entities.parquet')
communities_df = pd.read_parquet(output_path / 'communities.parquet')
community_reports_df = pd.read_parquet(output_path / 'community_reports.parquet')
text_unit_df = pd.read_parquet(output_path / 'text_units.parquet')
relationships_df = pd.read_parquet(output_path / 'relationships.parquet')
# covariates 通常可选,如果存在则读取
covariates_file = output_path / 'covariates.parquet'
covariates_df = pd.read_parquet(covariates_file) if covariates_file.exists() else None
print("✅ 本地搜索所需 Parquet 数据加载完成")5.执行本地查询
ini
query_text = "请介绍《大数据时代》"
res, context = await local_search(
config=graphRagConfig,
entities=entities_df,
communities=communities_df,
ini
query_text = "请介绍《大数据时代》"
res, context = await local_search(
config=graphRagConfig,
entities=entities_df,
communities=communities_df,
community_reports=community_reports_df,
text_units=text_unit_df,
relationships=relationships_df,
covariates=covariates_df,
community_level=2,
response_type="Single Paragraph",
query=query_text,
)
print("-" * 50)
print(f"本地查询问题: {query_text}")
print(f"回答内容: {res}")
ini
community_reports=community_reports_df,
text_units=text_unit_df,
relationships=relationships_df,
covariates=covariates_df,
community_level=2,
response_type="Single Paragraph",
query=query_text,
)
print("-" * 50)
print(f"本地查询问题: {query_text}")
print(f"回答内容: {res}")
2.GraphRAG大规模数据实战:以《凡人修仙传》为例
这个案例有些夹带私货,最近看的国漫《凡人修仙传》断更了。
2.1环境准备
(1)数据准备
本次实战项目使用的是网络小说 《凡人修仙传》的前37章公开内容 ,文档总规模约81444个字符。该数据集情节连贯、人物与地点众多,非常适合用于测试GraphRAG在构建叙事性文本知识图谱时的表现(也可以方便我们重温韩老魔的来时路)。
可能会有人问为什么不放完整的《凡人修仙传》,因为作者忘语实在太会写了,完整版本有八百多万字,我感觉太多了并且GraphRAG也有检索缓慢等缺点。
(2)创建检索文件夹
在命令行输入以下命令创建项目文件夹:
bash
mkdir -p ./openl_big/input将准备好的 《凡人修仙传》前37章 文档(可整理为单个txt或pdf文件)上传到 openl_big/input 文件夹中。
特别注意:虽然本例使用单一文档,但GraphRAG本身支持多文档。您可以将多个章节拆分为独立文件放入input文件夹,也可合并为一个文件上传,系统均能自动处理。
(3)初始化项目文件
bash
graphrag init --root ./openl_big初始化完成后,openl_big 文件夹下会生成三个关键文件/文件夹:
- prompts/ :包含知识图谱各构建阶段的提示词,可用于后续任务调优。
- .env:用于存储API Key等环境变量。
- settings.yaml:GraphRAG的主要配置文件。
(4)修改配置文件
本例依旧采用 硅基流动 提供的国内可用模型服务。修改 settings.yaml 中的 models 部分如下:
yaml
models:
default_chat_model:
type: chat
model_provider: openai # 硅基流动兼容OpenAI API
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY} # 设置为硅基流动的API Key
model: Qwen/Qwen3-8B
api_base: https://api.siliconflow.cn/v1 # 添加硅基流动的API端点
# api_version: 2024-05-01-preview
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25
async_mode: threaded # or asyncio
retry_strategy: exponential_backoff
max_retries: 10
tokens_per_minute: null
requests_per_minute: null
default_embedding_model:
type: embedding
model_provider: openai
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: BAAI/bge-m3 # 修改为BAAI/bge-m3
api_base: https://api.siliconflow.cn/v1 # 添加硅基流动的API端点
# api_version: 2024-05-01-preview
concurrent_requests: 25
async_mode: threaded # or asyncio
retry_strategy: exponential_backoff
max_retries: 10
tokens_per_minute: null
requests_per_minute: null2.2知识图谱构建
(1)执行图谱构建
命令行输入以下命令开始构建知识图谱:
bash
graphrag index --root ./openl_bigGraphRAG将自动执行文本分块、实体与关系提取、社区发现等建表流程。
性能参考(针对本数据集):
- 模型:硅基流动 Qwen3-8B
- 运行时间:约1.5h-2h
(2)查看生成的知识图谱表
构建完成后,所有数据表将保存在 openl_big/output 文件夹中。您可使用pandas读取并分析,例如:
ini
import pandas as pd
entities = pd.read_parquet("D:\pycharm(code)\Agent\GraphRAG\openl_big\output\entities.parquet")
entities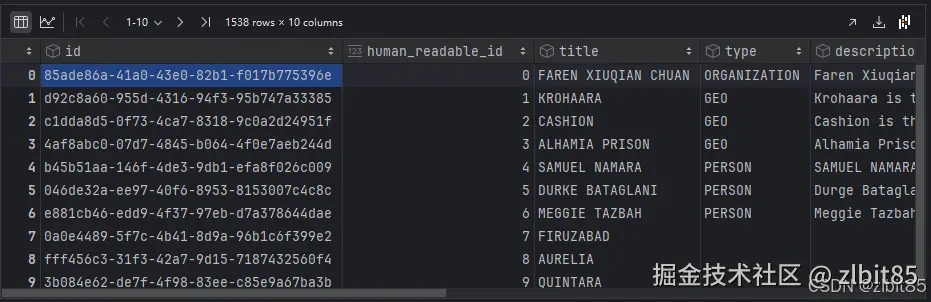
- 实体表:包含如"韩立""墨大夫""七玄门"等人物、地点、功法实体。
ini
relationships = pd.read_parquet("D:\pycharm(code)\Agent\GraphRAG\openl_big\output\relationships.parquet")
relationships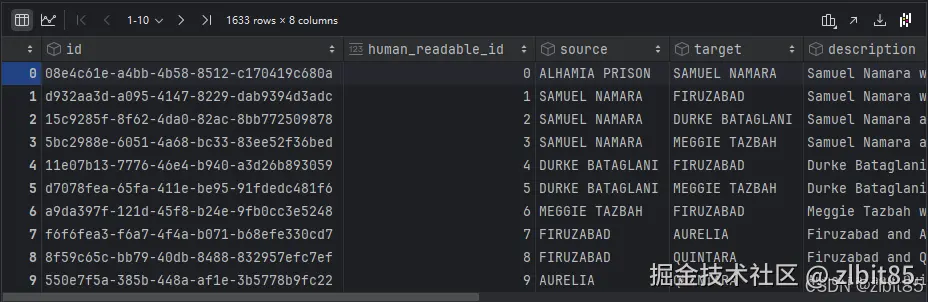
- 关系表:记录实体间关系,如"师徒""所属门派""使用功法"等。
ini
reports = pd.read_parquet("D:\pycharm(code)\Agent\GraphRAG\openl_big\output\community_reports.parquet")
reports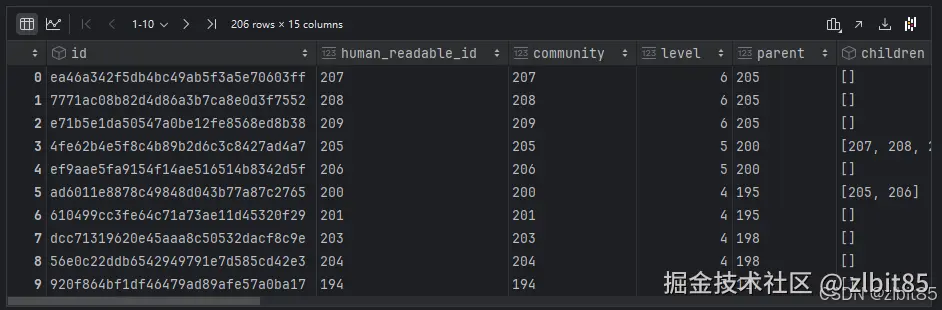
- 报告表:存储社区级摘要,反映故事中的情节聚类。
2.3检索查询实战
(1) GraphRAG三种查询模式
- Local(本地模式) :从问题中抽取实体,在实体表中匹配并扩展关联实体与文本块,基于这些局部信息生成答案。
- Global(全局模式) :将问题与社区报告匹配,找到相关社区后进行报告提纯与总结,再结合关联文本块回答。此模式调用两次LLM,答案更全面,token消耗较多。
- Drift(扩散模式) :在实体匹配基础上,进一步扩散到层级关联的实体,适合探索多跳关系。
(2)全局模式 vs. 本地模式:适用场景分析
| 场景 | 本地模式 | 全局模式 | 举例(基于《凡人修仙传》) |
|---|---|---|---|
| 具体事实查询 | ✅ 适合 | ✅ 适合 | "韩立是如何加入七玄门的?" |
| 总结类问题 | ❌ 不适合 | ✅ 适合 | "前37章主要出现了哪些修真境界?" |
| 综合评价类 | ❌ 不适合 | ✅ 适合 | "你认为韩立修炼的'长春功'有什么特点?" |
| 主观/泛化提问 | ❌ 不适合 | ✅ 适合 | "这段故事中哪个角色的塑造最精彩?" |
| 多情节关联推理 | ⚠️ 有限 | ✅ 更适合 | "韩立与墨大夫的冲突如何影响他后续的修行?" |
实测对比:
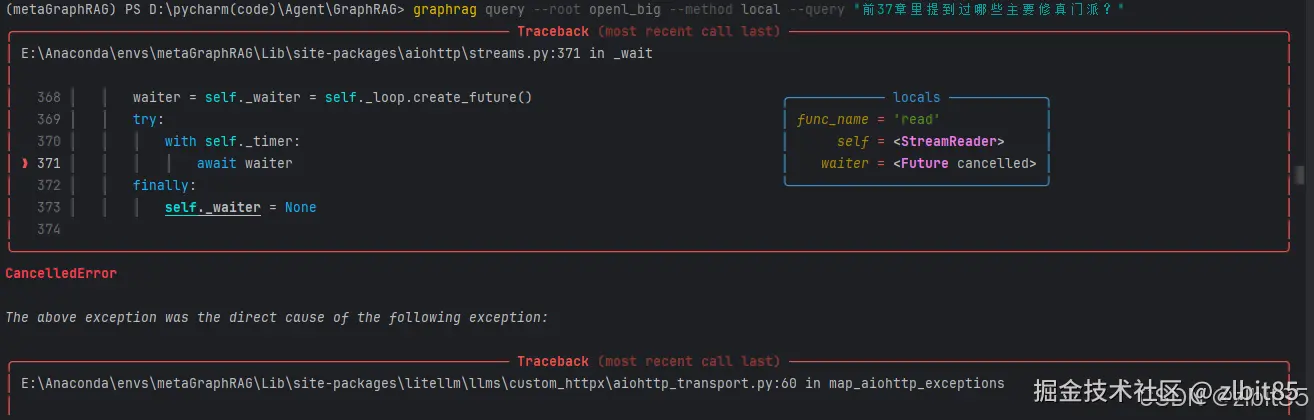
1.总结类问题
css
graphrag query --root openl_big --method local --query "前37章里提到过哪些主要修真门派?"本地模式无法回答,因为问题中实体不明确。
css
graphrag query --root openl_big --method global --query "前37章里提到过哪些主要修真门派?"
全局模式可通过社区报告提取汇总信息,并列出相关社区供进一步查看。
2.主观评价类问题
css
graphrag query --root openl_big --method global --query "你认为韩立在七玄门时期的成长经历如何?"
全局模式可基于多个相关情节社区进行归纳与评价。
(3)模式选择建议
- 优先尝试本地模式:针对具体人物、事件、地点的查询,本地模式响应更快,消耗更低。
- 复杂/总结/主观问题使用全局模式:尤其适合需要跨章节归纳、评价或理解剧情走向的任务。
- 扩散模式用于深度探索:当问题涉及多层关系(如"韩立的师傅的仇敌是谁?")时可尝试。
四、对RAG技术"未来展望"
其实作为一名本科还没有毕业的学生不敢随便妄言对某项技术的展望,因为了解得实在太粗浅了。所以我主要是通过阅读RAGflow这篇博客(从 RAG 到 Context - 2025 年 RAG 年终回顾 | RAGFlow 引擎),并且结合前几天聆听南航李舟军教授的讲座来谈一谈自己的理解。
2025年,检索增强生成(RAG)领域经历了一场深刻的自我重塑。曾经围绕其"过渡性角色"的质疑声,如今已被一种新的共识所取代:RAG不再仅仅是修补大模型知识缺口的临时方案,而是企业智能基础设施的核心组件。 李舟军教授在文档处理有很多成果,当李教授介绍前言与未来:多模态多智能体框架与系统 时说:"智能文档Agent = 文档智能+大模型(RAG) +多模态多智能体框架",并且强调"*AI Agent = LLM (规划+记忆+工具+行动)", 李教授表示今年(2026年)Agent的研究会有很多集中在记忆 方面,记忆又主要包括外部知识库 和本地上下文。 最后我感觉李教授说了一句让我感觉不一样的话:"技术是好掌握的,也是在不断变更的,对于我们想要在垂直领域做出成果来数据是万分重要的"。
过去一年(2025年),尽管AI智能体(Agents)占据了公众讨论的中心舞台,但真正致力于构建可持续AI能力的企业------尤其是大中型组织------却在悄然加深并系统化对RAG的投入。一个有趣的趋势显现:RAG正在从"易上手、难精通"的调优挑战,演变为企业AI架构中不可动摇的基石。
本章节回顾2025年RAG技术的关键演进,剖析其如何从单一检索工具蜕变为支撑下一代AI应用的 "上下文引擎" ,并展望2026年的发展趋势。
第一章:长上下文 vs. RAG------一场建设性的辩论
1.1 实践检验的理论问题
2024年被热烈讨论的"长上下文能否取代RAG?"在2025年进入了实践测试阶段。一些对延迟和成本不敏感的场景(如固定格式合同审查)开始尝试直接使用长上下文窗口,希望绕过检索环节。
然而,实践很快揭示了这一策略的局限性:
- 注意力稀释效应:将大量文本机械塞入上下文窗口,导致模型"迷失在中间"
- 成本非线性增长:处理长上下文的计算开销急剧上升
- 灵活性缺失:难以应对动态变化的知识和复杂查询
1.2 从对立到协同:上下文工程的兴起
真正的突破出现在对两者关系的重新认识上。长上下文能力的提升并未预示RAG的终结,而是催生了"上下文工程"这一新范式。
智能的解决方案是让RAG与长上下文窗口协同工作:
- RAG负责精准定位:从海量数据中筛选最相关的信息片段
- 长上下文负责深度理解:容纳完整、连贯的上下文供模型推理
- 动态组装策略:根据查询复杂度动态调整检索深度和上下文广度
这种"检索先行,上下文容纳"的协同模式,使得企业能够以最佳性价比将最有效的信息纳入模型处理流程。
第二章:RAG性能的深层优化
2.1 破解"切片困境"
传统RAG面临一个根本矛盾:语义匹配需要小切片 以实现高召回率,而上下文理解需要大切片以保证连贯性。
2025年的解决方案是将检索过程解耦为两个逻辑阶段:
阶段一:搜索(Search)
- 目标:快速、精确地定位所有潜在相关线索
- 粒度:使用较小的、语义纯净的文本单位(100-256 tokens)
- 类比:类似于在图书馆目录中查找相关书目
阶段二:检索(Retrieve)
- 目标:为LLM生成答案组装完整的"阅读材料"
- 粒度:基于搜索结果动态聚合为连贯的大片段(1024+ tokens)
- 类比:从书架上取出相关书籍,翻开至具体章节
2.2 结构化检索的创新
TreeRAG:层级化智能
以RAGFlow的TreeRAG技术为代表,通过在离线阶段使用LLM分析文档结构,构建层级化的树状目录摘要:
- 离线处理:文档→切片→LLM分析→多级树状结构
- 在线检索:细粒度搜索→树状导航→上下文动态组装
- 优势:有效缓解固定大小切片导致的上下文碎片化问题
GraphRAG:关联性探索
通过从文档中提取实体和关系构建知识图谱,利用图算法发现间接相关的知识:
- 能力:发现语义相关但物理距离远的内容
- 挑战:Token消耗大、实体提取质量波动、知识碎片化
- 趋势:与TreeRAG结合形成混合架构,平衡局部连贯性与全局关联性
2.3 技术融合的深层逻辑
所有这些进阶架构的核心范式是在传统RAG流水线上增加 "语义增强层" :
text
原始数据 → LLM深度分析 → 结构化表示 → 智能检索 → 动态组装这一转变标志着RAG从优化单一检索算法 ,转向系统化设计端到端信息处理流水线。
第三章:从知识库到数据基座
3.1 RAG的定位演进
随着AI Agent的兴起,RAG正在经历角色转变:
| 传统定位 | 新兴定位 |
|---|---|
| 问答知识库 | Agent数据基座 |
| 静态知识检索 | 实时数据供给 |
| 独立应用组件 | 统一上下文服务 |
3.2 工业化摄入流水线(PTI)
现代RAG系统的核心是一个健壮的摄入流水线,称之为 PTI(解析-转换-索引) ,这是AI时代的"非结构化数据ETL":
与传统ETL/ELT的对比
| 阶段 | 传统ETL(结构化数据) | RAG PTI(非结构化数据) |
|---|---|---|
| 提取/解析 | 从API、数据库提取 | 多模态文档解析(PDF、图像、音频) |
| 转换 | SQL清洗、业务逻辑计算 | LLM语义增强(摘要、结构提取、实体识别) |
| 加载/索引 | 加载到数据仓库表 | 构建混合索引(向量+关键词+元数据) |
3.3 统一数据基座的蓝图
一个完整的Agent数据基座需要整合三大数据源:
text
markdown
企业AI数据基座
├── 领域知识库(RAG核心)
│ ├── 文档、手册、规范
│ └── 静态业务知识
├── 交互记忆系统
│ ├── 对话历史
│ ├── 用户偏好
│ └── 动态状态数据
└── 工具与指南库
├── 工具描述(MCP封装)
├── 使用指南
└── 最佳实践剧本拥有这样的平台,RAG系统才能真正从"问答系统"进化为企业非结构化数据的统一处理与访问中枢。
第四章:上下文工程------AI应用的新范式
4.1 为什么需要上下文工程?
实践反复证明:不加选择地将所有数据塞进上下文窗口,不仅成本高昂,还会因信息过载损害LLM的理解和推理能力。
上下文工程的核心任务是智能地过滤、排序和拼接三类数据:
- 领域知识数据:通过RAG检索的企业私有知识
- 工具数据:通过工具检索(Tool Retrieval)筛选的相关工具和指南
- 对话与状态数据:通过记忆系统(Memory)管理的交互历史
4.2 工具检索:被忽视的关键环节
2025年下半年,一个关键问题浮现:当企业有数百个通过MCP封装的工具时,如何让Agent在正确的时间选择正确的工具?
解决方案:动态工具检索
- 建立索引:为所有工具描述构建专门的语义索引
- 查询生成:Agent根据当前任务生成工具功能查询
- 精准召回:仅召回Top-K最相关的工具描述
- 上下文注入:将精简后的工具集动态插入当前上下文
研究显示,即使是简单的BM25关键词检索,也能为此任务提供强大的基线。而微调的专用嵌入模型能实现更精确的匹配。
4.3 记忆与RAG:同源互补
尽管"记忆"在2025年获得了远超RAG的关注度,但从技术本质上,两者同源异流:
-
同源:核心能力都是存储、索引和检索
-
异流:数据源和目标不同
- RAG:处理静态的企业知识资产
- 记忆:处理动态的交互日志数据
未来的上下文平台将统一这两大能力,为Agent提供完整的"外脑"支持。
第五章:多模态RAG的工程化挑战
5.1 价值定位清晰,落地路径曲折
多模态RAG在需要图文结合理解的任务上表现卓越,但其全面工程化面临严峻挑战:
技术路径对比
-
模态转换路径:OCR/VLM→文本→文本RAG
- 优势:兼容现有架构
- 劣势:丢失视觉细节和布局信息
-
原生多模态路径:统一编码→多向量表示→张量检索
- 优势:保留完整跨模态语义
- 劣势:存储和计算成本爆炸
5.2 成本瓶颈与突破方向
假设每个页面图像生成1024个Token(特征向量),单个页面的张量数据约512KB。百万页文档库的索引将达到TB级别------这对存储、内存和检索延迟都是巨大挑战。
突破路径
-
张量量化压缩:将向量二值化或低比特量化,压缩存储至1/32或更低
-
Token剪枝策略:
- 随机投影(如MUVERA算法)
- Token聚类
- 模型侧自适应Token剪枝
5.3 协同发展的未来
多模态RAG的成熟需要基础设施 与模型层的协同突破:
- 基础设施:检索引擎需原生支持张量索引和重排
- 模型层:需要量化友好、支持Token剪枝的新一代多模态嵌入模型
随着2026年相关研讨会和研究的深入,我们预计将看到更多工程化的多模态RAG解决方案。
第六章:展望2026------上下文平台的工业化时代
6.1 从实验到规模化
2026年,企业对LLM应用的关注将从概念验证转向规模化采用和ROI考量。在这一过程中,RAG技术作为AI应用的基础数据层,将迎来更稳健、系统化的建设浪潮。
6.2 上下文平台:企业AI的新竞争壁垒
未来的竞争将不再是模型参数的比拼,而是上下文供给能力的较量。上下文平台将呈现以下特征:
四大演进方向
- 自动化:上下文创建与数据源深度整合,持续同步更新
- 动态化:基于实时意图,从多数据源智能检索和组装上下文
- 可治理:客户可管理、可视化配置的上下文运营体系
- 产品化:从专家手工活转向标准化、可复用的平台服务