在上一章中,我们建立了单个智能体的架构蓝图,探讨了它们的解剖结构与核心能力。我们看到,一个设计良好的单智能体就已经能够成为自动化任务的强大工具。然而,企业中最复杂、最有价值的挑战往往超出任何单个智能体的能力范围。正如一家公司依赖一支由专业员工组成的团队一样,高级AI解决方案也需要一组专业化智能体协同工作。
本章聚焦于使这种协作成为可能的协调模式(coordination patterns) 。当多个自治智能体在共享环境中运行时,必须对它们的行动进行协调,以避免冲突、管理资源,并实现总体目标。
为了让这些模式尽可能实用,我们将采用一种"先看地图,再开始旅程(map before the journey) "的方法。在深入每种模式的技术细节之前,我们会先给出一份面向实施的战略指南。
这份指南与我们的GenAI成熟度模型(GenAI Maturity Model) 对齐,提供一条逐步采用协调模式的路线图:从构建基础、可预测的工作流,到编排高级、自治的智能体集群。先理解全局图景,你将更容易把握每个具体模式的位置以及它为何重要。
本章将覆盖以下主题:
- 协调模式实施的战略指南
- Agent Router模式(基于意图的路由)
- 任务委派框架(Task Delegation Frameworks)
- 智能体组合拓扑(Agent Composition Topologies)
- 多智能体规划(Multi-Agent Planning)
- 知识共享(Knowledge Sharing)
- 多智能体上下文中的工具路由(Tool Routing in Multi-Agent Contexts)
- 共识(Consensus)
- 智能体协商(Agent Negotiation)
- 资源分配(Resource Allocation)
- 冲突消解(Conflict Resolution)
- 编队控制(Formation Control)
协调模式实施的战略指南(A strategic guide to implementing coordination patterns)
协调模式与GenAI成熟度模型之间的关系,并不是简单地把某个模式"分配"给某个具体层级。更准确地说,这是一种演进:当组织从单智能体系统(Level 1--3)走向多智能体系统(Level 4)时,这些协调模式的实现会变得更动态、更复杂,也更去中心化。
为了把讨论锚定在同一坐标系上,我们先回顾第3章介绍的Agentic AI成熟度等级。
| 成熟度等级 | 描述 | 可扩展性洞察 | 合规洞察 | 关键模式/方法 |
|---|---|---|---|---|
| 1. 基础智能体系统(Basic agentic systems) | 单智能体以半自治方式处理特定、定义明确的任务,使用简单、预定义的工作流与对外部API/工具的函数调用。 | 可适应但较僵硬。工作流相对固定,限制创新空间。 | 任务定义清晰,易于管理,降低策略违规风险。 | Single-Agent Baseline, Static Function Calling, Watchdog Timeout, Agent Calls Human |
| 2. 动态单智能体工作流(Dynamic single-agent workflows) | 单智能体可在多种预选工具/API中动态选择,以更灵活地解决问题。 | 更通用、更高效,可通过选择合适工具处理更复杂问题。 | 因工具预选仍可控,但自治提升后需要更谨慎监控行为。 | Agent Router (Basic), Dynamic Tool Selection, Simple RAG, Simple Retry |
| 3. 具备ReAct与Reflexion的内省模式(Introspective patterns) | 单智能体使用ReAct/Reflexion等方法进行分步推理与自我反思,通过反馈回路实现自纠。 | 引入反馈与自纠后可处理更复杂任务,并随时间改进,具备可扩展路径。 | 随学习与自治增强,需要实时监控与纠偏机制以保持合规对齐。 | ReAct, Reflexion, Instruction Fidelity Auditing, Adaptive Retry with Prompt Mutation |
| 4. 多智能体系统(Multi-agent systems) | 多个专业化智能体协作处理复杂任务,各自聚焦不同且不重叠的功能,协调实现并行处理。 | 适合高规模场景。任务可分布到多智能体并行执行复杂工作流。 | 管理更复杂,需要监控系统确保半自治智能体协作符合监管要求。 | Supervisor Architecture, Multi-Agent Planning, Shared Epistemic Memory, Event-Driven Reactivity, Tool/Agent Registry |
| 5. 引入元智能体的高级协调(Advanced coordination with meta-agents) | 引入"元智能体"监督与协调其他智能体,实现动态任务再分配与实时规划调整。 | 适应性更强。通过元智能体优化任务分配,可在变化环境中有效扩展。 | 元智能体作为监督者,通过调整工作流与再分配任务维护策略遵循。 | Meta-agents, Blackboard Topology, Resource Allocation, Contract-Net Marketplace, Supervision Trees |
| 6. 自纠智能体:带自学习反馈机制的智能体工作流(Self-correcting agents) | 高级多智能体系统使用复杂多轮反馈回路,智能体相互批判、纠正、迭代精炼输出,实现持续改进。 | 通过内建持续改进实现高度可扩展,系统可实时演化,适合动态任务。 | 最复杂。需要自动化合规检查与自纠动作,确保在适应过程中仍对齐策略。 | Consensus, Agent Negotiation, Conflict Resolution, Fractal CoT, Coevolved Agent Training, Trust Decay |
表5.1 -- Agentic AI成熟度模型
既然已经把协调模式与成熟度层级对齐,我们接下来将探讨:组织如何从建立基础、结构化工作流开始,迈入多智能体系统(Level 4)。在这一阶段,重点是稳定性------从孤立智能体走向结构化协作。
注:本章后续提到的"Level",均指表5.1中的Agentic AI成熟度模型层级。
多智能体系统:基础协调(Level 4)(Multi-agent systems: foundational coordination)
在多智能体系统的基础阶段,首要目标是建立一个可运转、可预测、可审计的系统,使多个智能体能够围绕一个定义明确的工作流成功协作。协调通常是显式的、由上至下管理的。架构选择更偏向清晰控制与中心化编排,而不是复杂的去中心化自治。
这种基础协调风格的关键特征包括:
- 任务委派与规划:
这一层最常见的方法是Supervisor Architecture 。它包含一个中心编排智能体,易于构建、调试与治理。该编排者使用Multi-Agent Planning分解任务,并分配给专业化"worker"智能体。规划通常是静态或半静态的,对应结构化业务流程。 - 信息与资源管理:
Knowledge Sharing 通常通过简单的Shared Epistemic Memory 实现,例如共享数据库。基础的Resource Allocation 与Conflict Resolution多由supervisor集中处理,依赖预定义策略或优先级规则。 - 交互模型:
这一层的智能体一般不会彼此协商。supervisor主导工作流,并依赖层级权威来解决冲突。
高级多智能体协调与自纠(Levels 5--6)(Advanced multi-agent coordination and self-correction)
更高级的多智能体系统在自治性上是一次显著跃迁。系统需要能够处理歧义、适应突发事件,并解决那些事先并不知道解法路径的问题。协调变得更"涌现"且去中心化。关注点从自上而下的命令结构,转向在智能体之间启用"社会化"能力,使其能在实时环境中自行化解冲突、对齐目标并调整集体策略。
这种高级协调风格的关键方面包括:
-
演进的委派与规划:
系统可能转向更具韧性的去中心化Swarm Architecture ,或采用Hybrid Model。规划变得动态,可实时调整。
-
高级"社会化"交互:
Level 6最显著的变化是引入一组规范自治A2A交互的模式:
- Consensus: 当智能体拥有冲突数据时,通过迭代式辩论收敛到共享理解。
- Negotiation: 当智能体目标竞争时,直接协商折中,得到更灵活、更优的结果。
- Specialized coordination: 对与物理世界交互的系统,Formation Control变得关键,使无人机/机器人等智能体群能够自组织并保持集体结构。
Level 4的基础多智能体系统与Level 6的系统之间,核心差异在于:从中心化管理、可预测的工作流 ,转向去中心化、可适应、更自治的集体。下表对比了各成熟度阶段关键架构要素的实现方式:
| 架构要素 | 多智能体系统(Level 4) | 高级与自纠系统(Levels 5--6) |
|---|---|---|
| 主要目标 | 建立可运转、可预测、可审计的工作流。 | 处理歧义、适应突发事件、解决动态问题。 |
| 协调模型 | 自上而下、显式协调,由中心权威管理。 | 自下而上、涌现式协调,由智能体交互产生。 |
| 主要架构 | Supervisor架构:中心编排智能体主导工作流。 | Swarm或Hybrid:智能体以P2P网络或自组织团队运行。 |
| 规划方法 | 静态规划:supervisor分解任务并制定大体固定计划。 | 动态规划:计划可实时调整与修订。 |
| 知识共享 | 简单共享记忆:主要用于在智能体间传递状态。 | 丰富共享认知记忆:用于构建集体智能。 |
| 冲突消解 | 集中式、策略驱动:supervisor按预定义规则解决。 | 自治式、协商式:智能体通过协商与共识直接解决。 |
表5.3 -- 协调模式的成熟度映射对比
现在我们已经定义了:Level 4的多智能体系统与更高级系统的高层架构(可由中心supervisor或去中心化swarm代表),接下来立刻会遇到一个非常现实的挑战:流量控制(traffic control) 。仅有层级结构还不够;系统必须有一个具体机制来分析入站请求并把它分发给正确的专家。supervisor如何知道关于"Q3 Audit Logs"的查询应该交给合规智能体而不是销售智能体?
这就引出我们的第一个基础协调模式:Agent Router。
Agent Router 模式(基于意图的路由)
Agent Router 是一种基础模式,用于将用户的意图 与实际执行该意图的具体智能体 解耦。在早期或简单系统中,开发者往往依赖硬编码的条件逻辑(例如:if "sales" in query: call_sales_agent)。但在企业级场景下,系统可能拥有几十个专业化智能体,这种做法会变得脆弱且难以维护。Agent Router 通过引入一个专门的架构层来解决该问题,这个层就像一个高级总机(switchboard)。
该模式结合了两种不同机制:语义意图抽取 (理解"要做什么")与图约束路由(决定"谁来做")。通过分离这两个关注点,系统可以扩展以支持新智能体与新能力,而无需重写核心编排逻辑。它可以被视为智能体协调的"Hello World":实现智能分发所需的最小可行核心。
背景(Context)
系统拥有一组专业化智能体,每个智能体具备不同能力。用户通过自然语言与系统交互,而自然语言往往含糊、表述多样,或夹杂无关噪声。
问题(Problem)
系统如何在不"臆造(hallucinate)"能力、也不依赖脆弱的关键词匹配的前提下,把一个非结构化、可变的自然语言请求,准确映射到最适合处理它的特定智能体?该问题空间中的驱动因素包括:
- 歧义 vs 精确: 用户输入往往模糊且非结构化,但智能体执行需要精确、结构化指令。
- 可扩展性 vs 可维护性: 增加新智能体不应迫使重写中心路由逻辑;系统必须能动态容纳不断增长的能力集合。
- 安全 vs 幻觉: 系统必须确保请求绝不会被路由到无法处理它的智能体,避免智能体越过护栏去尝试执行其能力范围之外的任务。
解决方案(Solution)
Agent Router 采用一个两步流程:
- 意图抽取(Intent extraction): 使用带严格Schema的LLM进行语义意图抽取,把原始查询翻译成结构化的"意图对象(intent object)",其中包含标准化的动作(动词)与资源(名词)。
- 图约束路由(Graph-constrained routing): 查询查找表或知识图谱,确定哪个智能体声明了"对该资源执行该动作"的能力。若图中存在有效路径,则进行路由;否则将请求判定为不支持并拒绝。
示例:路由一个合规请求(Example: Routing a compliance request)
用户问:"Where is the latest security audit for the Q3 finance project?"(Q3财务项目最新的安全审计在哪里?)工作流如下:
-
意图抽取: Router 分析文本,抽取出结构化意图:
{Action: "Find", Resource: "Document", Params: {"type": "audit", "period": "Q3"}} -
图查询: Router 在能力图中查询二元组
(Find, Document)。 -
评估:
- SalesAgent 注册能力为
(Find, SalesReport)→ 不匹配。 - ComplianceAgent 注册能力为
(Find, Document)→ 匹配。
- SalesAgent 注册能力为
-
分发: Router 实例化 ComplianceAgent,并传入参数。
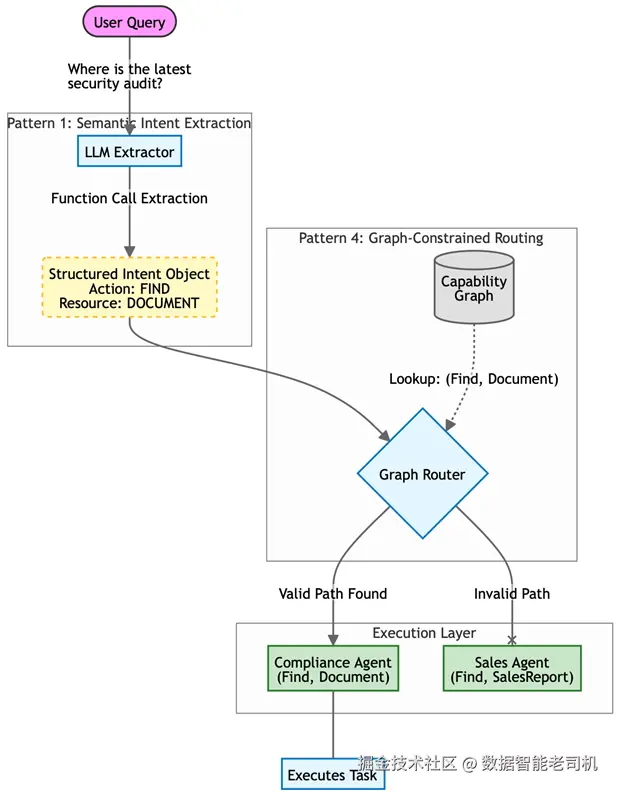
图 5.1 -- Agent Router 模式
示例实现(Example implementation)
下面的 Python 示例展示了 Agent Router 的工作方式。该示例使用 Pydantic 来定义严格的"词汇表(vocabulary)",即系统允许的动作与资源集合。
逻辑分成两部分:首先建立 RoutingIntent schema,作为用户请求与智能体之间的契约;其次构建 AgentRouter 类,维护一个能力图谱。该图谱是事实来源(source of truth),把特定的"动作-资源"对映射到最适合执行任务的专业智能体。在生产环境中,通常会先用 LLM 从自然语言中抽取结构化意图,再交给这段路由逻辑处理。
python
from pydantic import BaseModel
from typing import Literal, List, Tuple
# 1. Define the "Vocabulary" of the system
ActionType = Literal["find", "analyze", "create"]
ResourceType = Literal["sales_report", "server_log", "document"]
class RoutingIntent(BaseModel):
action: ActionType
resource: ResourceType
parameters: dict
class AgentRouter:
def __init__(self):
# The Capability Graph: Maps (Action, Resource) -> Agent Name
self.capability_graph = {
("find", "sales_report"): "SalesAgent",
("analyze", "sales_report"): "SalesAgent",
("find", "document"): "ComplianceAgent",
("create", "server_log"): "DevOpsAgent"
}
def route_request(self, intent: RoutingIntent):
# 1. Lookup the capability in the graph
key = (intent.action, intent.resource)
target_agent_name = self.capability_graph.get(key)
# 2. Safety Check: If no link exists in the graph, block the request
if not target_agent_name:
return f"Error: No agent exists that can '{intent.action}' a '{intent.resource}'."
# 3. Dispatch (Simplified)
return self.dispatch_to_agent(target_agent_name, intent.parameters)
def dispatch_to_agent(self, agent_name, params):
print(f"Routing to {agent_name} with params: {params}")
# In real code, this would instantiate the agent class and call .run()
return "Success"结果影响(Consequences)
优点(Pros):
- 解耦(Decoupling): 抽取层不需要知道智能体名称;智能体也无需解析自然语言。双方通过结构化"意图对象"通信。
- 可扩展(Scalability): 新增智能体只需在图中注册其能力;路由逻辑无需改变。
- 安全(Safety): 能力图是白名单。除非图中显式定义链接,否则路由器不可能把"delete database"这类命令发给某个智能体。
缺点(Cons):
- 延迟(Latency): 意图抽取需要一次LLM调用,会在真正执行前增加额外延迟。
- Schema僵硬(Schema rigidity): 若用户请求不符合预定义的 Action/Resource 枚举,抽取可能失败或性能退化。
实施建议(Implementation guidance)
Agent Router 的成功高度依赖于 schema 定义质量。定义动作(动词)与资源(名词)时,应追求"金发姑娘(Goldilocks) "级别的抽象:
- 过细(例如 FindPDF、FindWordDoc)会导致路由图爆炸且难维护;
- 过粗(例如 DoWork)会让路由器失去区分智能体的能力。
对大多数企业系统而言,10--20 个规范化动作与资源通常足够。
在语义意图抽取步骤上,强烈建议使用 LLM 的 function calling / tool use 模式,而不是仅靠提示词工程。Function calling 强制输出严格 JSON 结构,可消除自由文本响应常见的解析错误。
最后,建议在路由层实现语义缓存(semantic cache) 。企业环境中用户常问相似问题(例如"Show me the sales report")。通过对用户查询做 embedding,并在向量数据库中检索历史相似请求,你可以对重复查询直接绕过 LLM 抽取步骤,从而显著降低延迟与成本。
你将面临的第一个、也是影响最深远的决策,是确定系统的控制结构(control structure) 。正如人类组织需要明确的管理风格(层级式或扁平式),你的智能体系统也需要一个清晰的工作分发模型。这将把我们带入任务委派框架(Task Delegation Frameworks) ------它们是支配流程与责任的"操作系统"。
任务委派框架(Task Delegation Frameworks)
多智能体系统需要一种高层结构,用来治理任务如何被发起 、如何被分配给各个智能体 、以及如何被跟踪直到完成。如果缺少清晰的框架,就很难管理复杂工作流、确保任务被路由给正确的专家,并维持整体系统的一致性与连贯性。
核心挑战在于定义系统中工作的总体流动模型:任务如何分配、谁对推进负责、以及如何确保最终目标达成。依赖临时的、随意的委派方式,往往会导致任务丢失、责任不清,以及难以调试或扩展的架构。
任务委派模式通过确立一种架构模型来解决这一挑战:它规定智能体如何组织、如何接收工作。它不仅是个体交互的模式,更像系统的"操作系统",塑造控制流与通信流。选择正确的框架,是设计多智能体系统时最重要的早期决策之一,因为它奠定了端到端工作的管理方式。
不同框架带来不同权衡。层级式框架 提供清晰的权威链路、易于监控,因此常用于强调可审计性与可预测性的企业应用。相对地,去中心化框架 具备更强的灵活性与韧性,更适合创意型或高度动态的领域------在这些领域里,通往解法的路径无法事先定义。最常见的两种任务委派方式是:Supervisor(Orchestrator)架构 与 Swarm 架构。
Supervisor 架构(集中式编排)
Supervisor 架构是多智能体系统中的核心模式:由一个单一的中央编排者(orchestrator)智能体管理并指挥其他专业化"工人(worker)"智能体的工作。它类似传统的层级管理结构:编排者接收高层目标,将其拆解为一系列子任务,并把子任务委派给合适的工人。该模式提供清晰的自上而下控制,非常适合结构化、可预测的业务流程。
这种模式为企业应用提供一种基础方案,以保证流程系统化、可审计、可重复。它把管理复杂工作流的负担从用户转移到自治的 AI 系统上,同时仍保留一个中央控制与监督点。
背景(Context)
一个复杂任务需要执行多个步骤,这些步骤往往是顺序的或带条件分支的。系统需要确保流程被正确执行,并具备清晰的指挥链与责任链。
问题(Problem)
多智能体系统如何可靠且可预测地执行一个需要多步骤与专业能力的复杂任务?系统必须管理数据流与控制流、控制操作顺序,而无需持续的人类干预。问题空间中的驱动因素包括:
- 可预测性 vs 灵活性: 结构化工作流可预测、易管理,但可能缺乏应对意外情况的灵活性。
- 中心化 vs 瓶颈: 集中控制有利于治理与调试,但会形成单点故障与性能瓶颈。
- 专业化 vs 协调开销: 专业化智能体能提升单步效率,但会增加交接与全局协调的复杂度。
解决方案(Solution)
Supervisor 架构通过指定一个智能体负责所有协调来解决问题。编排者的主要职责是理解用户请求、制定计划(可预先编排或动态生成),然后按需调用工人智能体。编排者接收每个工人的输出,并据此决定下一步,从而以受控、审慎的方式确保整体目标达成。
示例:集中式贷款处理(Example: Centralized loan processing)
用户向 LoanOrchestratorAgent 提交贷款申请。工作流如下:
- 编排(supervisor 的角色): 编排者接收高层任务:"处理这份贷款申请"。
- 委派: 编排者把申请发送给
DocumentValidationAgent。 - 执行:
DocumentValidationAgent完成任务并把结果返回给编排者。 - 条件委派: 根据结果(例如文件有效),编排者再把下一步委派给
CreditCheckAgent。 - 完成: 编排者从
RiskAssessmentAgent收到最终风险分数,组装摘要并做最终决策,完成顶层任务。
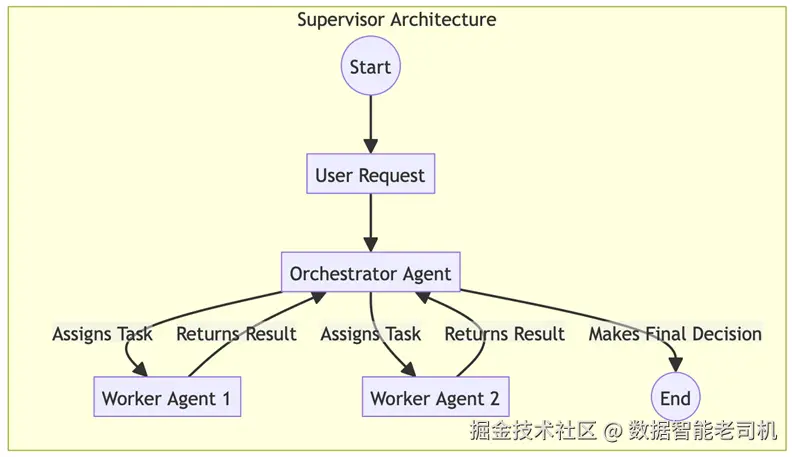
图 5.2 -- Supervisor 架构工作流
示例实现(Example implementation)
下面的代码展示了 Supervisor 架构在企业贷款审批流程中的应用。在这个 Level 4 的实现中,LoanOrchestratorAgent 作为中央权威,负责管理整个工作流的状态与步骤编排。注意:编排者不亲自执行验证或征信检查;相反,它维护一组专业化工人智能体。这种关注点分离使 supervisor 能专注于高层业务逻辑与条件分支(例如发现材料无效就终止流程),而专业智能体负责单步任务的技术执行。该结构为高监管金融环境提供所需的可预测性与清晰审计链路。
ruby
class LoanOrchestratorAgent:
def __init__(self):
self.doc_validator = DocumentValidationAgent()
self.credit_checker = CreditCheckAgent()
self.risk_assessor = RiskAssessmentAgent()
def handle_loan_application(self, application_data):
# Step 1: Delegate document validation
validation_result = self.doc_validator.validate(application_data)
if validation_result != "valid":
return "Application Rejected: Invalid Documents"
# Step 2: Delegate credit check
credit_report = self.credit_checker.check(application_data.applicant_id)
if credit_report.score < 600:
return "Application Rejected: Low Credit Score"
# Step 3: Delegate risk assessment
risk_assessment = self.risk_assessor.assess(application_data, credit_report)
# Step 4: Assemble final result and make decision
final_decision = self.make_final_decision(risk_assessment)
return final_decision影响与权衡(Consequences)
优点(Pros):
- 可预测性: Supervisor 模式提供清晰、可预测的流程,易于监控、调试与审计。
- 治理: 中心化控制便于统一实施业务规则与合规要求。
缺点(Cons):
- 可扩展性: 单一编排者在系统扩展时可能成为性能瓶颈。
- 单点故障: 一旦编排者失败,整个工作流会停止。
实施建议(Implementation guidance)
实现 Supervisor 架构时,最关键的设计原则是保持严格的关注点分离,避免形成"上帝智能体(God agent) "。编排者应只负责协调:路由任务、跟踪状态、基于结果做决策,而不应亲自执行领域逻辑。所有实质工作都应封装在专业化工人智能体中。这样能让编排者保持轻量,避免逻辑演化成纠缠、不可维护的巨石。
在这种中心化模型里,可靠性取决于健壮的状态管理 。因为 supervisor 是单点故障,系统必须在工作流每一步之后实现状态持久化(常称为 checkpointing)。例如 LangGraph 这类框架就为此目的而设计,允许把图状态持久化到数据库中,确保即使编排者或底层基础设施故障,工作流也能从中断点精确恢复而不丢数据。
最后,supervisor 与工人之间的通信必须是确定性的(deterministic) 。用自由形式自然语言做交接几乎注定不稳定。应强制严格的输出 schema(例如使用 Pydantic 或 JSON mode),让编排者收到可程序化解析的结构化数据。此外,supervisor 应作为故障的中央处理者:当某个工人失败或卡住时,supervisor 必须具备重试、切换到备用智能体,或优雅失败(fail gracefully)的逻辑,以保护整体系统不被单点错误拖垮。
尽管中心化的 Supervisor 架构在可管理性与可审计性方面表现卓越,但它并非放之四海皆准。对于环境不可预测、或系统需要在个别组件失败时仍能持续运行的场景,刚性的层级结构反而可能成为负担。为了获得真正的鲁棒性与适应性,我们必须探索光谱的另一端:一种将控制分布到同级节点之间的去中心化方法。
群体架构(Swarm Architecture:涌现式去中心化协调)
在群体架构中,没有中心领导者。相反,智能体以点对点网络的方式运行,通过一种涌现的、自组织的方式协作解决问题。任务通常会被广播到整个专业化智能体群体中,随后各智能体会基于自身能力对任务"竞标"或自我选择。工作流是由智能体之间的交互自然形成的,而不是由某个中心 supervisor 明确下达与编排。
这种模式尤其适用于创意类任务、动态问题求解,以及对高韧性要求很高的环境。它利用智能体的集体智能,使系统能够实时适应并演化。
背景(Context)
复杂任务是动态且非结构化的,或者系统需要对变化具备高度韧性与适应性。单点故障不可接受,问题求解过程更适合并行、自治的行动,而不是僵硬的串行流程。
问题(Problem)
在没有中心编排者的情况下,一组自治智能体如何有效协作以达成共同目标?系统需要一种机制,以去中心化且具韧性的方式完成任务发现、交接与闭环。问题空间的驱动因素包括:
- 自治 vs 协调: 最大化智能体自治能提升韧性与适应性,但缺乏显式协调可能导致重复劳动或目标不一致。
- 可扩展性 vs 开销: 去中心化网络可以横向扩展而不产生瓶颈,但这需要高效通信协议来控制智能体间的"闲聊"开销。
- 涌现行为 vs 可预测性: 群体的自组织特性可能带来高度创造性与适应性的解法,但最终结果往往更难预测,也更难调试。
解决方案(Solution)
群体架构通常依赖一个共享的通信板或任务板。任务被发布后,任何智能体都可以在准备好时从任务板"拉取"任务。一旦某个智能体完成它负责的部分,它会在任务板上更新任务状态,使其对工作流中的下一个专业化智能体可见。这样就支持异步并行处理,并消除了对单一控制点的依赖。
示例:去中心化内容创作(Example: Decentralized content creation)
将"写一篇关于太阳能的博客文章"的任务发送给一群智能体。工作流如下:
- 任务广播: 任务发布到共享任务板上。
- 自我选择:
ResearchAgent轮询任务板,识别任务状态为(new),并自我选择接手。 - 执行并更新:
ResearchAgent收集事实,将发现写入任务数据,并把状态改为researched。 - 交接:
DraftingAgent看到状态为researched,拉取任务,撰写初稿,并把状态更新为drafted。 - 完成:
EditorAgent做最终校对并将任务标记为complete。
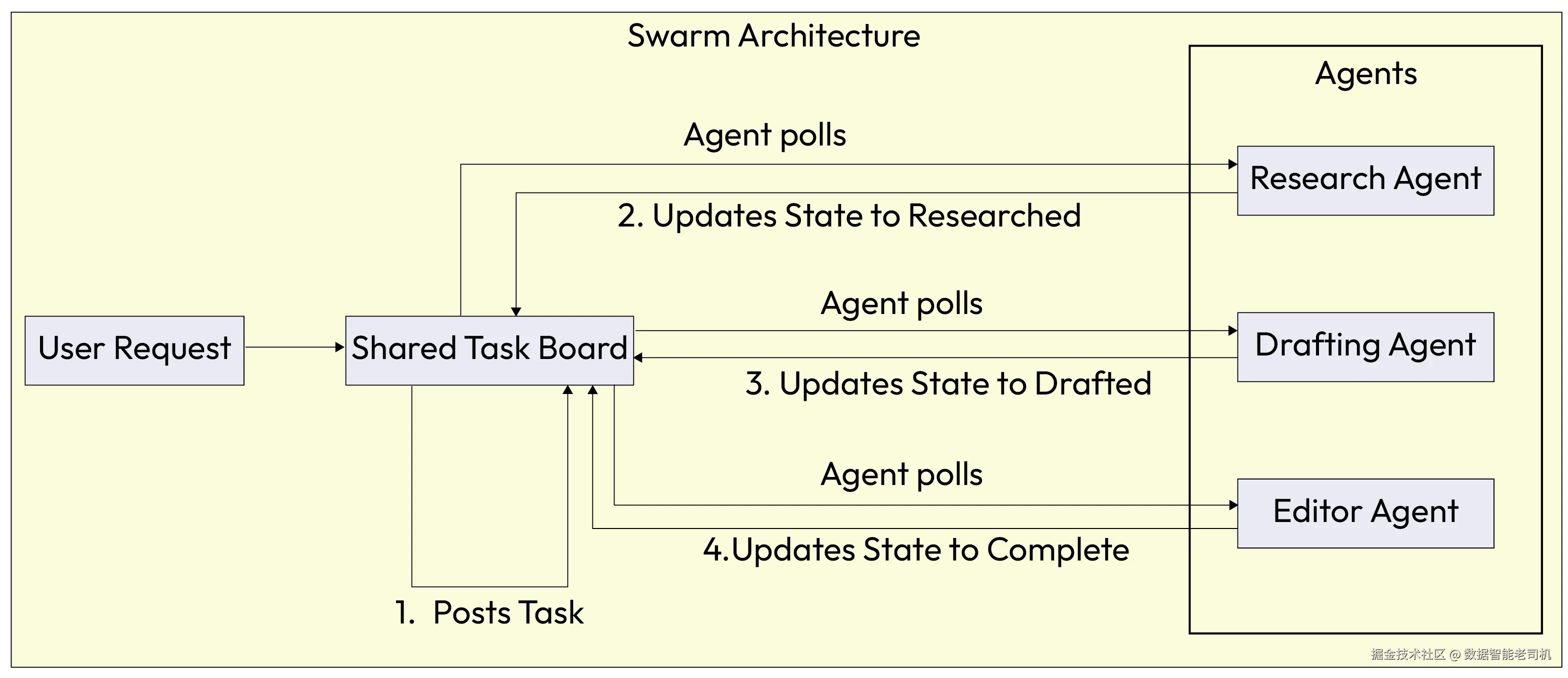
图 5.3 -- 群体架构工作流
示例实现(Example implementation)
下面的示例实现展示了群体架构,强调在 Level 6 下从自上而下命令转向涌现式、去中心化协调。在该模型中,智能体作为网络中的同级节点运行,使用 shared_task_board 来管理项目全生命周期。
不同于由 supervisor 指挥,每个智能体(如 ResearchAgent、DraftingAgent)都会独立监控任务板状态。当某个智能体发现任务状态与其专业能力匹配时,它就"认领"工作,执行自身逻辑,并更新共享状态。这种解耦的、拉取式交互模型使系统保持高韧性与高灵活性,因为工作流是由智能体的局部决策自然演化出来的,而不是由静态、预编排的计划驱动。
ini
class ResearchAgent:
def check_for_tasks(self, shared_task_board):
task = shared_task_board.get("task_id_123")
if task.status == "new":
facts = self.gather_facts(task.topic)
task.data["research"] = facts
task.status = "researched" # Update status for next agent
print("ResearchAgent completed work.")
class DraftingAgent:
def check_for_tasks(self, shared_task_board):
task = shared_task_board.get("task_id_123")
if task.status == "researched":
draft = self.write_draft(task.data["research"])
task.data["draft_content"] = draft
task.status = "drafted" # Update status for next agent
print("DraftingAgent completed work.")
class EditorAgent:
def check_for_tasks(self, shared_task_board):
task = shared_task_board.get("task_id_123")
if task.status == "drafted":
final_text = self.proofread(task.data["draft_content"])
task.data["final_text"] = final_text
task.status = "complete"
print("EditorAgent completed work.")影响与权衡(Consequences)
优点(Pros):
- 韧性: 没有中心控制器,意味着没有单点故障;即使部分智能体离线,系统仍可继续运行。
- 可扩展性: 点对点特性支持横向扩展------只需向群体中加入更多智能体即可。
缺点(Cons):
- 可调试性: 任务的涌现式、非线性流动会让系统行为更难预测与调试。
- 治理: 缺少中央权威时,实施业务规则或确保合规会更具挑战。
实施建议(Implementation guidance)
在设计多智能体系统时,一个好的起点通常是采用中心化方案。对大多数企业应用来说,Supervisor 架构更容易搭建、调试与治理,因为它提供清晰的责任边界与集中监控点。
但随着时间推移,一些应用可能会从去中心化中获益。群体架构更能抗故障、对环境变化更敏感,因此天然适配那些必须强调智能体自治的动态环境。实践中,许多复杂系统会采用混合模型:顶层编排者负责整体业务过程,但会把较大的子目标委派给自组织的"群体"或"crew",由它们在内部自行协调执行细节。这种平衡把中心控制的清晰性与分布式决策的适应性结合起来。
两种任务委派架构对比(Table 5.2)
| 特性 | Supervisor 架构(中心化) | Swarm 架构(去中心化) |
|---|---|---|
| 控制流 | 层级式:单一编排者向工人智能体委派任务 | 点对点:智能体自选任务或相互传递 |
| 协调方式 | 显式、自上而下:supervisor 管理工作流 | 涌现式、自下而上:由局部交互产生协调 |
| 模块化 | 高:可在 supervisor 下轻松增删替换专家智能体 | 高:智能体自治,可在群体中自由增删 |
| 关键收益 | 可预测、监督清晰;更易调试与治理 | 韧性强、适应性强;无单点故障 |
| 关键代价 | supervisor 可能成为性能瓶颈或单点故障 | 难治理、难调试;整体行为更难预测 |
| 最适用场景 | 结构化业务流程、步骤明确的工作流(如贷款处理) | 创意任务、动态求解、需要高韧性的环境 |
在中心化的 Supervisor 与去中心化的 Swarm 之间做选择,相当于为智能体确定高层"操作系统"------它决定权威与控制的流动方式。然而,真实世界的问题通常还需要更具体的结构安排,以有效管理数据与交互。
例如:当解法必须以增量方式逐步演化时怎么办?或者当能力随负载波动时,如何为任务找到最合适的智能体?为了解决这些更具体的挑战,我们将转向 Agent Composition Topologies(智能体组合拓扑) 。这些架构模式定义了智能体之间的结构关系。
智能体组合拓扑(Agent Composition Topologies)
尽管前述的任务委派框架定义了总体的"交战规则"(中心化 vs 去中心化),更具体的组合拓扑则会更细致地描述智能体与数据的结构性安排。这些模式用于解决与知识收敛 、基于市场的任务分配 以及容错相关的特定挑战。
黑板知识枢纽(Blackboard Knowledge Hub)
在复杂的问题求解场景中,多个专业化智能体必须向一个正在形成的解决方案贡献部分的、或不确定的事实。随着新信息的到来,任务会动态演化,这就要求系统既支持向解法逐步收敛,也能对信息来源进行严格的溯源管理。
背景(Context)
系统面对的是定义不清或高度复杂的问题,没有任何单一智能体拥有解决整个问题所需的全部知识。解决方案需要来自不同"专家"的增量式贡献,而且这些专家贡献的先后顺序无法被完全预先确定。
问题(Problem)
如何让多个彼此独立的智能体在不使用直接、紧耦合的通信通道(这在规模扩大后会变得不可管理)的情况下,共同推动一个正在演化的解决方案?问题空间的驱动因素包括:
- 共享理解 vs 竞态条件: 智能体需要对问题状态有统一视图,但并发更新可能产生冲突。
- 开放贡献 vs 质量控制: 系统需要允许多位专家贡献,但必须过滤低质量或"幻觉式"的数据。
- 全局一致性 vs 智能体自治: 智能体需要独立行动,但最终方案必须在全局上保持一致。
解决方案(Solution)
黑板知识枢纽模式实现一个中心化仓库------黑板(Blackboard) ,用于保存带类型、带版本的事实与假设 。知识来源(各智能体)不直接相互通信;相反,它们将更新发布到黑板上。一个控制器对流程阶段进行仲裁(发布 → 评估 → 集成),确保贡献被校验,并使解决方案在逻辑上逐步收敛。
示例:协作式医学诊断(Example: Collaborative medical diagnosis)
一名患者表现出复杂且模糊的症状。工作流如下:
- 发布(Posting):
SymptomAnalysisAgent将"患者发热并伴有皮疹"发布到黑板。 - 触发(Triggering):
DermatologyAgent看到"皮疹"后被触发,分析图像并发布:"皮疹提示可能为病毒感染(置信度:0.8)"。 - 细化(Refining):
VirologyAgent读取该假设后,发布对"血液检测结果"的请求。 - 收敛(Convergence): 控制器评估汇总事实,直到
DiagnosisAgent以足够置信度综合生成最终诊断。
示例实现(Example implementation)
下面代码给出黑板知识枢纽模式的基础实现。该架构专为复杂、非线性问题而设计,例如医学诊断或欺诈检测------解决方案通过多个专业化"专家"的增量贡献而涌现。
在此实现中,Blackboard 类充当一个中心化、线程安全的"事实/假设"仓库。注意:智能体之间不直接通信;它们将发现以附带置信度分数与时间戳的形式"发布"到黑板。这样,独立的控制器就能对求解过程进行仲裁,在保持完整、可审计的黑板历史(用于追踪系统"思维链条")的同时,推动系统向全局一致的解法收敛。
ruby
class Blackboard:
def __init__(self):
self.facts = []
def post_hypothesis(self, agent_id, hypothesis, confidence):
entry = {"agent": agent_id, "data": hypothesis, "conf": confidence, "timestamp": now()}
self.facts.append(entry)
return entry
class Controller:
def run_cycle(self, problem_state):
# 1. Selection: Determine which agents can contribute to current state
eligible_agents = self.select_knowledge_sources(problem_state)
# 2. Execution: Agents write to blackboard
for agent in eligible_agents:
hypothesis = agent.generate_hypothesis(problem_state)
self.blackboard.post_hypothesis(agent.id, hypothesis)
# 3. Evaluation: Validator checks for convergence or conflicts
if self.validator.check_convergence(self.blackboard.facts):
return self.validator.synthesize_solution()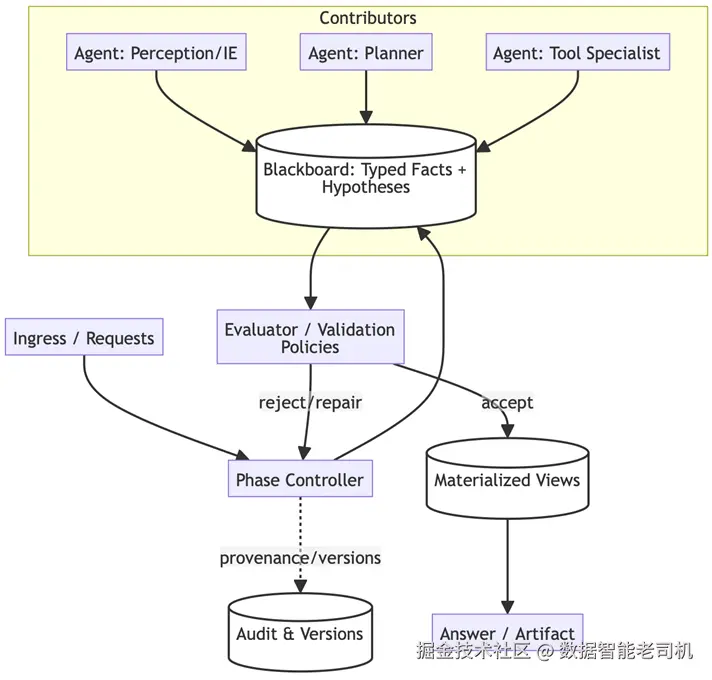
图 5.4 -- 黑板拓扑(Blackboard topology)
影响与权衡(Consequences)
优点(Pros):
- 灵活性: 非常适用于病态问题(ill-posed problems)------前进路径不清晰、需要多轮迭代贡献的场景。
- 可审计性: 追加写(append-only)日志提供了解法如何演化的清晰历史,这对解释系统的"思维链条"至关重要。
缺点(Cons):
- 延迟: 中心化写入与评估步骤会引入延迟,使其比直接消息传递更慢。
- 瓶颈: 如果黑板没有做合理分片或索引,控制器可能成为吞吐瓶颈。
实施建议(Implementation guidance)
该模式最适用于以下情况:你拥有大量"弱专家"(专业但能力有限的智能体),或对可追踪的收敛过程有强烈需求。但不要把它用于低延迟、简单的工具型任务,因为维护黑板状态的开销会超过收益。为保持系统卫生,应实现"清理策略"或"遗忘机制"来裁剪过期或已失效的事实;否则黑板可能变成噪声很大的草稿板,进而拖累智能体性能。
黑板模式强调:智能体集体如何通过共享知识状态逐步收敛到解。但当主要挑战从"如何解题"转变为"在一个能力波动的专家池里,谁最适合处理某个任务"时,我们就会从中心化知识枢纽转向一种动态、市场驱动的方法:合同网市场(Contract-Net Marketplace) 。
合同网市场(Contract-Net Marketplace:中介 + 投标)
系统面临的任务在复杂度与领域上差异巨大。可用能力是异构且动态的:智能体可能上线或下线,或者其负载随时波动。你需要在运行时选择最匹配的智能体,而不是把分配关系硬编码死。
背景(Context)
你运行在一个分布式环境中,拥有一个多样化的智能体池。这些智能体的能力存在重叠,但它们的可用性、成本与性能特征会动态变化。静态路由逻辑既脆弱又低效,因为它无法考虑实时负载或具体任务细节带来的差异。
问题(Problem)
当最优选择取决于运行时才知道的动态因素(如可用性、成本、置信度)时,你该如何把任务分配给最合适的智能体?问题空间的驱动因素包括:
- 专业化 vs 路由开销: 你希望拥有高度专业化的智能体,但手动把请求路由给它们会非常复杂。
- 竞争式投标 vs 协调成本: 竞价能确保"最合适的智能体"拿到任务,但拍卖过程会消耗时间与计算资源。
- 探索 vs 服务等级协议(SLA): 你想探索最优方案,但又不能错过执行时限。
解决方案(Solution)
实现合同网协议(Contract-Net Protocol) ------一种基于市场的协商机制。一个征询者(solicitor,也可称 manager)向潜在执行者广播任务公告。投标者(各智能体)评估公告后,提交正式投标,其中包含自身能力、成本、预计到达时间(ETA)以及置信度分数。征询者随后充当授标者(awarder),把任务分配给效用(utility)得分最高的智能体。
示例:选择云服务商智能体(Example: Selecting a cloud provider agent)
用户想训练一个大模型,但预算非常严格。工作流如下:
-
公告(Announcement):
TrainingSolicitor广播:"任务:训练 Model X。约束:最高成本 100 美元。"
-
投标(Bidding):
AWS_Agent投标:90 美元,ETA 2 小时。Azure_Agent投标:85 美元,ETA 2.5 小时。OnPrem_Agent投标:10 美元,ETA 12 小时。
-
授标(Award): 征询者权衡时间与金钱,将合同授予
AWS_Agent,认为其在两者间取得最佳平衡。
示例实现(Example implementation)
下面示例实现展示了合同网市场模式,强调 Level 6 系统如何从硬编码逻辑跃迁到一种动态、市场驱动的任务分配模型。
代码定义了两个核心角色:
- Solicitor(征询者) :管理拍卖过程;
- BidderAgent(投标智能体) :代表一种专业化资源。
系统通过广播公告并基于某个效用函数(例如在模型置信度与算力成本之间做权衡)评估投标,确保每个任务在那个时刻由最符合要求的智能体来处理。这种去中心化协商使系统对企业环境中智能体可用性与 API 成本的实时波动具备高度适应性。
ruby
class Solicitor:
def request_task_fulfillment(self, task):
# 1. Announce task to all available subscribers
bids = self.broadcast_announcement(task)
# 2. Evaluate bids based on utility function (Confidence vs Cost)
best_bid = self.evaluate_bids(bids)
if best_bid:
# 3. Award contract
result = best_bid.agent.execute_contract(task)
return result
else:
raise NoBidsException()
class BidderAgent:
def receive_announcement(self, task):
if not self.can_handle(task):
return None # Refusal
# Calculate cost and confidence
cost = self.estimate_compute_cost(task)
confidence = self.assess_capability(task)
return Bid(agent=self, cost=cost, confidence=confidence)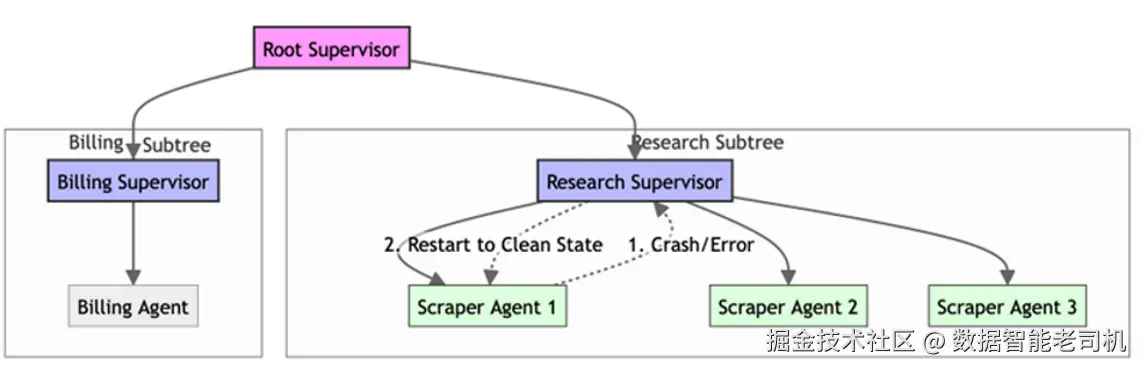
图 5.5 -- 合同网协议(Contract-Net Protocol)
影响与权衡(Consequences)
优点(Pros):
- 自适应选择: 系统无需改代码即可动态适配智能体可用性与能力变化。
- 高利用率: 将请求方与提供方解耦,使工作在当下流向最适合的智能体。
缺点(Cons):
- 拍卖延迟: 协商过程在真正开始工作前就引入了额外开销。
- 博弈风险: 若缺乏促使"真实投标"的激励机制,智能体可能夸大置信度来赢得任务。
实施建议(Implementation guidance)
当你拥有一个规模大且变化频繁的工具/智能体集合,或者需要针对成本、速度等动态因素做优化时,应使用该模式。但对于固定、可预测的工作流(例如基于意图的静态路由),静态路由更简单也更快,应避免用合同网增加不必要的开销。
为防止无限等待,征询者必须为接收投标设置严格截止时间(deadline)。另外,可以为投标者引入"信誉分(reputation score)",对赢得合同却无法交付高质量结果的智能体进行惩罚。
基于市场的分配非常适合在多专家具备、环境动态变化的场景下优化效率与成本。然而在企业系统中,智能体可能执行高风险或高赌注动作,此时效率必须与绝对稳定性、容错能力做平衡。这就引出了一个借鉴自高可用分布式系统世界的模式:带护栏能力的监督树(Supervision Tree with Guarded Capabilities) 。
带护栏能力的监督树(Supervision Tree with Guarded Capabilities)
"带护栏能力的监督树"是一种面向多智能体系统的架构模式,用于遏制故障扩散 并强制执行安全边界 。它不会让单个智能体的错误一路传播并拖垮整个应用,而是把智能体组织成一棵分层树:上层的监督者负责监控其下属(子节点)的健康状态与行为表现。该模式将"参与者模型(Actor Model)"的 "让它崩(let it crash)" 哲学与严格的能力护栏(capability guarding) 结合起来:确保每个智能体只拥有其角色所需的特定工具访问权,同时提供一套结构化机制来实现自动恢复与自愈。
背景(Context)
该模式源自参与者模型(以 Erlang 与 Akka 系统著称),并被应用到 Agentic AI 中。它在如下系统中尤为关键:大量智能体会进行自治且可能高风险的工具调用,例如执行生成代码、抓取网页、或与不稳定的外部 API 交互。
问题(Problem)
系统如何在不拖垮整个应用的前提下,把自治智能体的故障圈定住 ,同时又给予它们足够的行动自由?问题空间的驱动因素包括:
- 安全 vs 速度: 我们希望智能体自治且快速行动,但一个子智能体里未处理的异常可能向上冒泡并杀死主编排器。
- 隔离 vs 协作: 智能体需要共享数据以协作,但若直接共享内存,一个智能体的状态污染会"感染"其他智能体。
- 开发敏捷 vs 政策约束: 开发者需要快速添加新能力,但给所有智能体完整系统权限会违反最小权限原则。
解决方案(Solution)
实现一棵监督树(Supervision Tree) ,将智能体分层组织。监督者是专门的智能体,其职责只是管理其子节点(工作智能体)的生命周期:一旦子节点崩溃或违反策略,监督者就能检测到故障并应用恢复策略(例如重启子节点)。能力按子树授予,确保"研究(Research)"分支无法访问"计费(Billing)"工具。
示例:高韧性的网页抓取器(Example: Resilient web scraper)
- 派生(Spawn): 根监督者(Root Supervisor)派生一个
ResearchSupervisor,后者再派生三个ScraperAgent。 - 故障(Failure): 某个
ScraperAgent遇到阻断性验证码并抛出致命错误(或陷入死循环)。 - 检测(Detection):
ResearchSupervisor检测到崩溃信号。 - 恢复(Recovery): 按照 "one-for-one" 策略,监督者只重启失败的那个
ScraperAgent并给予一份干净状态,其余智能体继续运行;故障被圈定在局部。
示例实现(Example implementation)
下面示例代码展示了"带护栏能力的监督树"模式,重点在于系统如何隔离风险并自动化恢复。在该实现中,SupervisorAgent 充当生命周期管理器,明确为每个工作节点划定边界:通过在初始化时只向子智能体提供受限工具子集 ,系统确保某个分支被攻破或崩溃时,不会暴露另一个分支的敏感能力。该结构再配合诸如 ONE_FOR_ONE 之类的恢复策略,使系统在面对不可预测的外部工具时仍能保持韧性与自愈能力。
python
class SupervisorAgent:
def __init__(self, strategy="ONE_FOR_ONE"):
self.children = []
self.strategy = strategy
def spawn_child(self, agent_cls, tools):
# Isolate capabilities by passing specific tools only to this child
child = agent_cls(allowed_tools=tools)
self.children.append(child)
return child
def monitor_loop(self):
# Continuously check health of children
for child in self.children:
if child.status == "CRASHED" or child.status == "POLICY_VIOLATION":
self.handle_failure(child)
def handle_failure(self, failed_agent):
log_incident(failed_agent.id, failed_agent.error)
if self.strategy == "ONE_FOR_ONE":
print(f"Restarting agent {failed_agent.id} to clean state.")
failed_agent.restart()
elif self.strategy == "ESCALATE":
# If the supervisor can't handle it, crash itself to signal up the tree
raise SupervisorFailureException(failed_agent)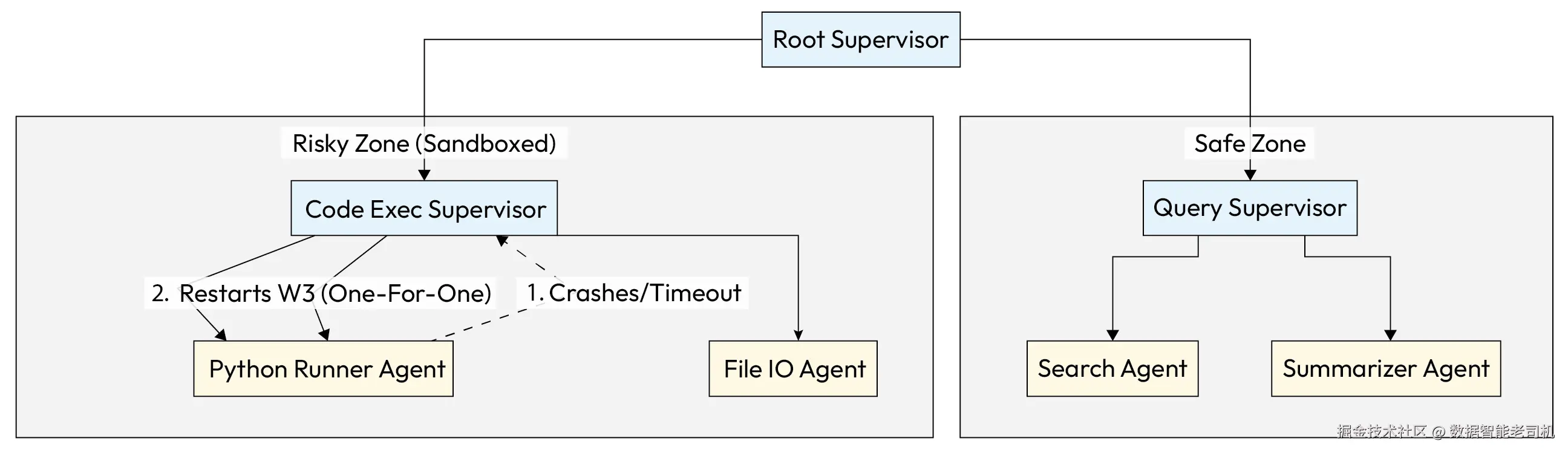
图 5.6 -- 带护栏能力的监督树(Supervision Tree with Guarded Capabilities)
影响与权衡(Consequences)
优点(Pros):
- 高韧性: 自动错误恢复让系统无需人工干预即可自愈。
- 爆炸半径控制: 高风险分支(例如网页抓取器)发生崩溃不会影响安全分支或根编排器。
缺点(Cons):
- 复杂度: 增加架构编排难度;开发者必须以"树 + 生命周期管理"的方式思考系统。
- 通信开销: 跨树通信需要清晰的网关(mailboxes),因为智能体不能直接从兄弟节点"抓"数据。
实施建议(Implementation guidance)
该模式对使用不稳定工具(如网页浏览或代码执行)的生产系统至关重要。对于简单、一次性的工具调用场景,避免构建过深的监督树,否则搭建开销会压过执行收益。定义恢复策略时务必加入退避(backoff)逻辑:如果某个子节点在 1 秒内崩溃 5 次,就应停止重启,以免形成"崩溃循环"消耗资源。并且要严格保证子节点不能绕过监督者直接与根节点通信。
建立拓扑会赋予系统一个形状,但形状本身并不能解决问题。智能体一旦组织起来------无论是蜂群、层级还是市场------还需要一套流程来攻克复杂目标:面对"发布一个产品"这样的高层目标,推导出达成它所需的步骤序列。这正是多智能体规划(Multi-Agent Planning) 的领域------驱动集体前进的认知引擎。
多智能体规划(Multi-Agent Planning)
一旦高层的任务委派框架(例如集中式监督者或去中心化蜂群)就位,系统就需要一种具体的方法 来处理复杂目标。像"发布一款新产品"这样的单一高层目标,任何单个智能体都无法直接执行。它需要一个经过深思熟虑的过程:把目标拆解为一系列可协调的小动作 ,再将这些动作分配给具备相应专长的智能体。这正是多智能体规划模式的核心目的:为系统提供一种结构化方法,用于分析复杂目标并生成一个连贯、可执行的计划,从而将工作负载智能地分配到整个智能体团队中。
背景(Context)
系统收到一个复杂问题,它规模过大或维度过多,任何单个智能体都无法独立解决。总体目标清晰,但实现它所需的步骤序列以及劳动力分工并不清楚。系统需要一个连贯的计划,能够利用不同智能体的专长技能。
问题(Problem)
一组自治智能体如何协同创建并执行一个统一计划,以达成共同目标?如果缺乏共享计划,智能体可能会重复劳动、以错误顺序执行步骤,或无法有效整合彼此的成果,导致低效甚至彻底失败。问题空间的驱动因素包括:
- 分解 vs 内聚: 必须把大目标拆成小任务,但系统需要确保这些子任务保持内聚,并确实服务于总体目标。
- 专长 vs 协调开销: 专业化智能体能提升单项任务效率,但也提高了交接与整体协同管理的复杂度。
- 静态 vs 动态规划: 预先定义的计划可预测,但缺乏对新信息或意外挑战的适应能力。
解决方案(Solution)
多智能体规划模式通过建立一种机制来解决上述问题:将高层目标分解为一个任务图(graph)或序列 的可管理子任务,并把这些任务分派给最合适的智能体。这个过程通常称为协作式任务分解(collaborative task decomposition) ,在集中式框架中一般由编排器智能体负责完成。计划本身会成为一种共享工件(shared artifact) ,用于指导集体行为。
示例:生成市场分析报告(Example: Market analysis report generation)
系统接到一个高层目标:"为产品 X 生成一份全面的市场分析报告"。使用多智能体规划时,编排器会把该目标分解为一系列子任务:
gather_sales_data:分配给DataRetrieverAgent。analyze_competitor_chatter:分配给SocialMediaMonitoringAgent。summarize_analyst_reports:分配给FinancialDocsAgent。synthesize_findings_and_draft_report:分配给ReportWriterAgent。
这些子任务可以并行或串行执行,依赖关系由编排器管理,或通过智能体之间的直接通信来完成协调。
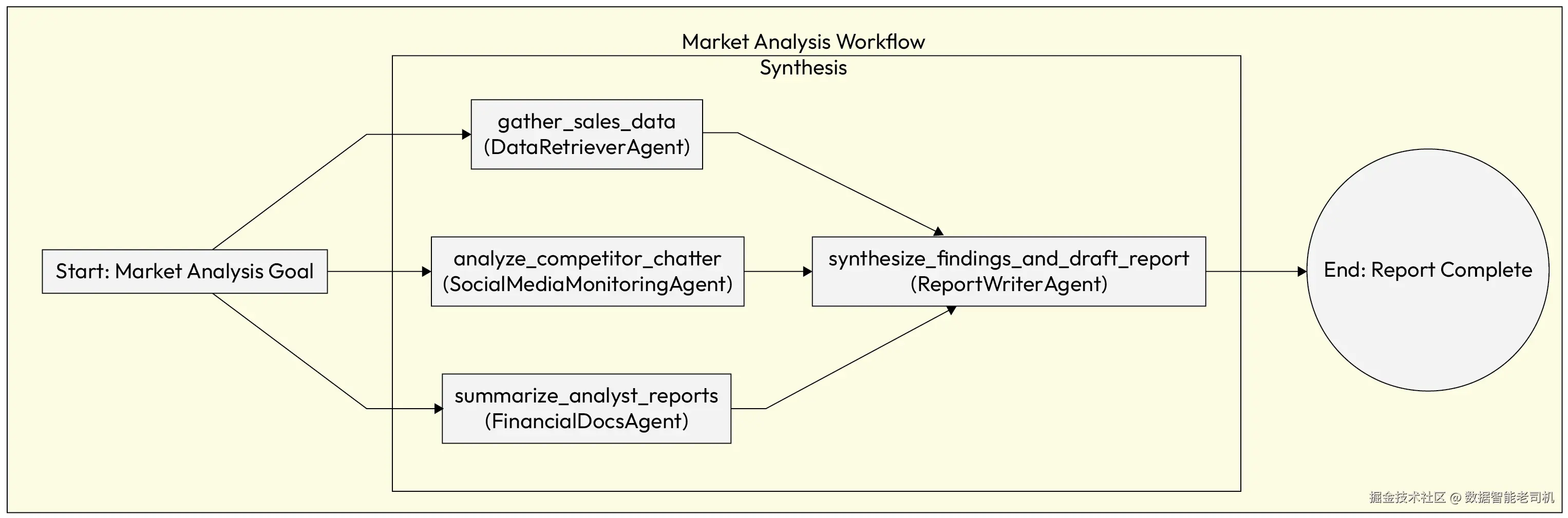
图 5.7 -- 多智能体规划工作流(Multi-Agent Planning workflow)
实现示例(Implementation example)
下面的示例实现展示了多智能体规划模式,说明复杂目标如何被分解为可执行的子任务。在该场景中,MarketAnalysisOrchestrator 充当主规划者,识别完成市场调研请求所需的专业智能体。
通过使用 concurrent.futures 库,编排器可以并行执行彼此独立的数据收集任务,从而显著降低整体延迟。当来自不同专家的基础数据被取回后,编排器会管理最终依赖:把所有发现统一交给报告撰写智能体,确保最终输出连贯且有依据。
python
import concurrent.futures
class MarketAnalysisOrchestrator:
def __init__(self, data_retriever_agent, social_media_agent, financial_docs_agent, report_writer_agent):
self.data_retriever = data_retriever_agent
self.social_media = social_media_agent
self.financial_docs = financial_docs_agent
self.report_writer = report_writer_agent
def generate_report(self, product_name):
# 1. Decompose the high-level goal into a plan
plan = {
"task1": {"agent": self.data_retriever, "input": product_name},
"task2": {"agent": self.social_media, "input": product_name},
"task3": {"agent": self.financial_docs, "input": product_name}
}
# 2. Execute independent tasks in parallel
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_task = {
executor.submit(plan[key]["agent"].run, plan[key]["input"]): key
for key in plan
}
results = {}
for future in concurrent.futures.as_completed(future_to_task):
task_name = future_to_task[future]
try:
results[task_name] = future.result()
except Exception as exc:
print(f'{task_name} generated an exception: {exc}')
# 3. Execute dependent tasks
sales_data = results.get("task1")
competitor_chatter = results.get("task2")
analyst_summaries = results.get("task3")
final_report = self.report_writer.run(
sales_data, competitor_chatter, analyst_summaries
)
return final_report影响与权衡(Consequences)
优点(Pros):
- 效率: 借助专长分工与并行执行来解决复杂问题,提升效率与能力边界。
- 发挥专业化优势: 任务分配给专业智能体,结果质量通常优于单一通用智能体。
缺点(Cons):
- 协调开销: 规划过程本身会消耗资源,若设计不当可能成为瓶颈。
- 僵化风险: 若环境变化或某个子任务失败,静态计划可能失效。
实施建议(Implementation guidance)
为缓解僵化与协调开销的风险,计划应保持可变(flexible) 而非静态。系统必须能在出现新信息或子任务失败时动态调整计划。对子任务间依赖关系进行清晰定义至关重要,这能保证交接顺畅并避免执行错误。
既然我们已经讨论了多智能体系统的编排蓝图与复杂问题的分解,下一步自然是理解这些智能体如何交换信息。知识共享(Knowledge Sharing) 模式提供了智能体之间共享数据、协调行动与管理依赖关系的基础原则。
知识共享(Knowledge Sharing)
当一个多智能体系统拥有一份连贯的计划之后,每个智能体执行质量在很大程度上取决于它所掌握的知识。如果智能体各自处于信息孤岛之中,整个系统就无法受益于单个智能体随着时间积累的独特洞察与经验教训。知识共享模式 正面应对这一挑战,它提供一种机制来形成集体智能,并确保某个智能体发现的有价值信息能够被所有智能体访问,从而让整个系统更有效、更具适应性。
背景(Context)
在多智能体系统中,单个智能体往往会通过自身经历获得有价值的信息或学会新技能。例如,一个智能体可能学会了查询某个数据库的最高效方式,而另一个智能体可能学会了识别一种新型的客户投诉。没有共享机制,这些知识就会被封闭在各个智能体内部,成为孤岛。
问题(Problem)
如何将某个智能体获得的宝贵知识或经验共享给系统中的其他智能体,从而提升整个群体的集体智能?如果没有共享机制,每个智能体都必须独立学习所有内容,这既低效,又会导致系统整体能力低于各部分能力之和。问题空间中的驱动因素包括:
- 孤岛知识 vs 集体智能: 把知识保留在单个智能体本地更简单,但会阻碍整个系统随时间学习与改进。
- 写入容易 vs 检索成本: 系统需要让智能体能方便地把新知识写入共享仓库,同时共享仓库也必须具备结构化能力,以便其他智能体高效且准确地检索。
- 知识传播 vs 完整性: 广泛共享知识可以加速问题求解,但也伴随错误或过期信息被扩散的风险。
解决方案(Solution)
知识共享模式通过实现一种共享认识记忆(Shared Epistemic Memory) 来解决问题:这是一个全局、持久化的数据存储,所有智能体都可以读写。该共享记忆可以是简单的知识图谱、向量数据库,或其他形式的持久化存储,它超越了简单的消息传递机制。它创建了一个中心化的知识池,使整个系统能够从各成员的经验中学习,避免理解碎片化与语义漂移。
示例:共享客服解决方案(Example: Shared customer service solutions)
为了说明共享认识记忆的实际影响,考虑一个大规模客户支持场景。在这个例子中,系统不再只做简单的被动响应,而是构建一个持久化的组织知识库。通过允许智能体向中心向量数据库贡献并查询内容,组织确保某个智能体发现的解决方案会立刻成为整个集体的资产,从而减少重复排障,并提升复杂问题的解决速度。
Agent_A发现:ProWidget X 的 Error 503 基本都能通过让用户清理设备缓存解决。Agent_A将该成功解法写入共享向量数据库。- 几周后,
Agent_B遇到类似问题,通过对共享知识库进行语义检索,立刻找到Agent_A的解法,并在第一次尝试就解决了问题。
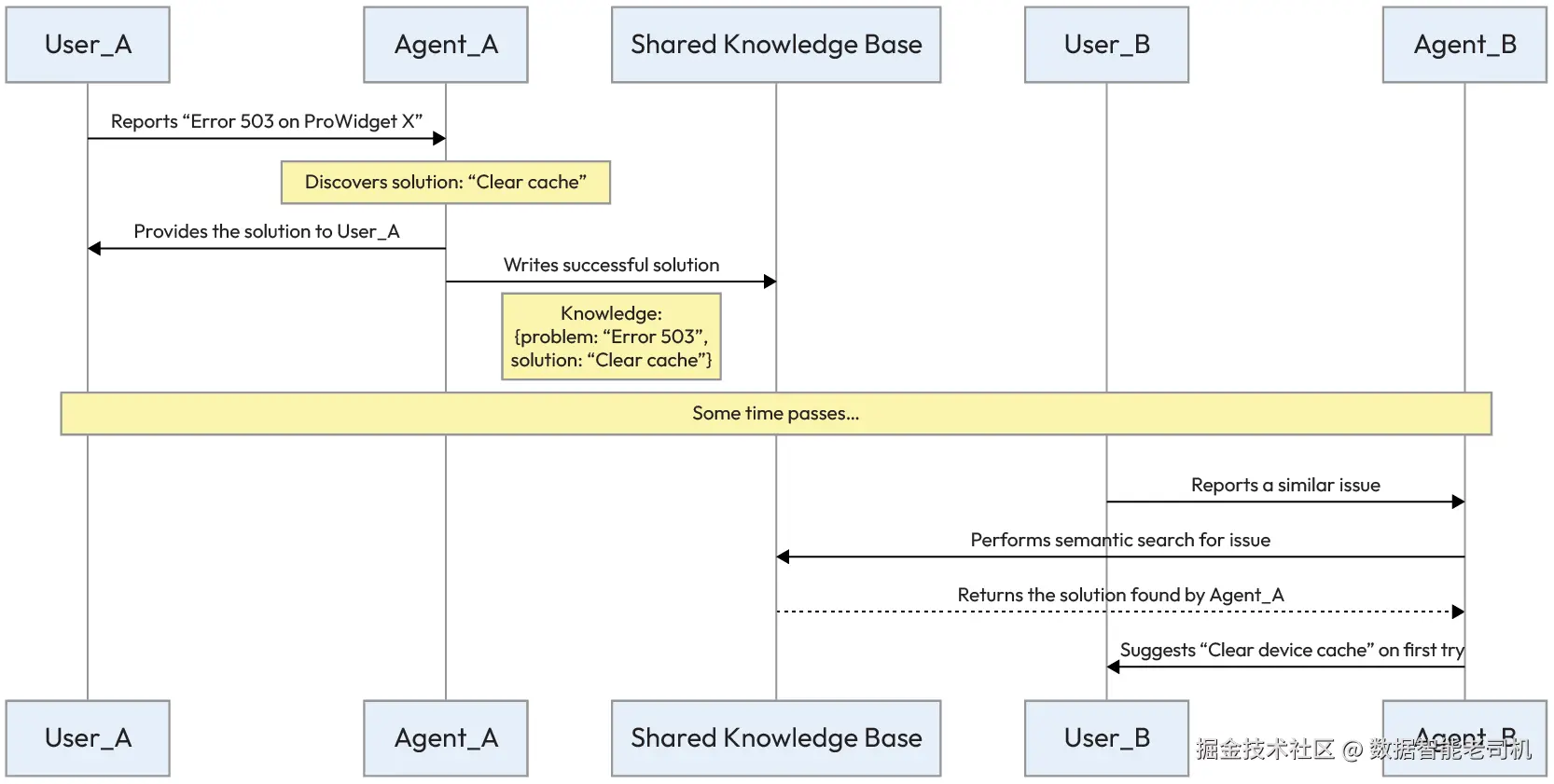
图 5.8 -- 智能体信息共享(Agent information sharing)
这一序列说明:共享记忆使整个多智能体系统能够随着时间从单个成员的经验中学习并持续改进。
实现示例(Example implementation)
下面的实现更具体地展示了智能体如何与共享认识记忆交互。在这个 Python 示例中,我们使用一个概念性的向量数据库作为组织知识的全局存储。代码演示了一个知识条目的生命周期:先展示 AgentA 如何识别成功解法并提交到共享库,然后展示 AgentB 在遇到相似查询时如何通过语义检索取回同样的上下文。该模式是构建"越用越聪明"系统的基础,因为它避免了知识被封闭在单次会话历史中所造成的"失忆"。
python
# Shared Knowledge Base (e.g., a Vector Database)
SHARED_KNOWLEDGE_BASE = VectorDatabase()
class AgentA:
def handle_issue(self, user_query):
if "Error 503 on ProWidget X" in user_query:
solution = "Have the user clear their device's cache."
# ... solves the user's problem ...
# Write the successful solution to shared memory
knowledge_entry = {
"problem_description": "Error 503 on ProWidget X",
"solution_steps": solution
}
SHARED_KNOWLEDGE_BASE.add_entry(knowledge_entry)
print("AgentA learned and shared a new solution.")
class AgentB:
def handle_issue(self, user_query):
# Search the shared knowledge base for similar problems
relevant_solutions = SHARED_KNOWLEDGE_BASE.semantic_search(user_query)
if relevant_solutions:
# Use the solution found by another agent
solution = relevant_solutions[0].solution_steps
print(f"AgentB found a solution from the knowledge base: {solution}")
return solution
else:
# Handle the issue using its own logic
...影响与权衡(Consequences)
优点(Pros):
- 集体智能: 最重要的收益是系统会变得"强于各部分之和",因为它可以从所有智能体的集体经验中持续学习。
- 效率: 智能体可以复用既有知识快速解决重复问题,而不是每次从零开始。
缺点(Cons):
- 数据完整性: 存在错误信息或恶意信息被扩散的风险。
- 治理开销: 需要一套机制来管理、验证并修剪知识库,维持其准确性与可靠性。
实施建议(Implementation guidance)
要实现成功的知识共享架构,实践者需要聚焦几项基础原则,首先是知识表示:对于明确、客观的事实,系统应采用如 JSON 这样的结构化格式;而更细腻、经验型的知识,则适合以非结构化文本的形式存入向量数据库。
仅有存储还不够,维护**来源可追溯性(provenance)**至关重要:追踪每条共享知识的来源,有助于架构师评估其可靠性,并在错误信息被传播时更高效地调试系统。
最后,一个健壮的设计还应纳入信任与验证机制:例如允许智能体对同伴贡献的信息进行评分或验证,甚至委派一个专门的"治理智能体"定期审查并修剪知识库,以确保其持续准确与相关。
一份良好的计划与一个共享的知识池为智能体提供了做出合理决策所需的智力基础。然而,智能体把决策转化为可见成果的能力,往往取决于它与外部世界交互的能力。此时,各类工具(如 API、函数、数据库)就派上用场了,这也引入了新的协同挑战:在拥有大量专业智能体与工具的系统中,如何确保"正确的智能体"为特定任务调用"正确的工具"?多智能体场景下的工具路由(Tool Routing in Multi-Agent Contexts) 模式将通过一套框架来解决这一问题,用于高效管理与引导全系统的工具使用。
多智能体场景下的工具路由(Tool Routing in Multi-Agent Contexts)
虽然知识共享(Knowledge Sharing) 模式确保智能体能够访问到最佳的集体信息,但它们能否把这些知识转化为有效行动,往往取决于是否能正确使用外部工具。
这引入了一个新的协同挑战:在一个拥有大量专业智能体与工具的系统中,如何确保针对某个具体任务,由正确的智能体 去调用正确的工具 ,或将任务委派给合适的执行者?多智能体场景下的工具路由模式通过提供一套框架来解决这一问题,用于在系统范围内高效管理与引导工具的使用。
背景(Context)
一个多智能体系统可以访问多种工具(API、函数、数据库),用以执行行动。当某个任务需要特定能力时,系统必须决定:由哪个智能体去调用哪个工具。
问题(Problem)
在拥有大量智能体与工具的系统中,如何确保对某个子任务选对工具,并由最合适的智能体来发起调用?如果智能体目标与其使用的工具不匹配,可能导致性能下降、结果错误,或资源浪费。问题空间中的驱动因素包括:
- 准确性 vs 灵活性: 刚性的、硬编码的路由映射能保证已知任务的高准确性,但缺乏应对意外请求的灵活性。
- 中心化 vs 瓶颈: 中央路由器能简化路由逻辑,但在高流量系统中可能成为单点故障或性能瓶颈。
- 工具专用化 vs 工具发现: 智能体受益于拥有一小套专属工具,但当需要时,它们也必须具备发现新工具或外部工具的机制。
解决方案(Solution)
工具路由模式通过为每个智能体或中央监督者提供一份只描述其相关工具 的专用提示(prompt),来提升专注度并降低决策疲劳。也就是说,并非让每个智能体都能访问所有工具,而是对能力进行范围限定(scoping) 。编排器(orchestrator)或一个专门的路由智能体负责将任务引导给那个专属工具集最匹配的智能体。该方法确保智能体在清晰定义的能力边界内高效运行,从而实现更准确、更可靠的工具调用。
示例:智能个人助理(Example: Intelligent personal assistant)
设想一个个人助理机器人,需要处理从查询股价到预订航班等多种用户请求。
- 用户请求: 用户问:"Google 当前股价是多少?"
- 分类: 中央 Router 智能体分析意图,将其归类为
financial_query(金融查询)。 - 路由: 基于该分类,Router 智能体把任务委派给
FinancialAgent,后者持有市场数据所需的 API Key 与工具。 - 专业执行:
FinancialAgent使用其get_stock_price工具抓取数据。 - 完成: 结果返回给用户,而
WeatherAgent和TravelAgent不会被打扰,从而避免它们编造答案或误用工具。
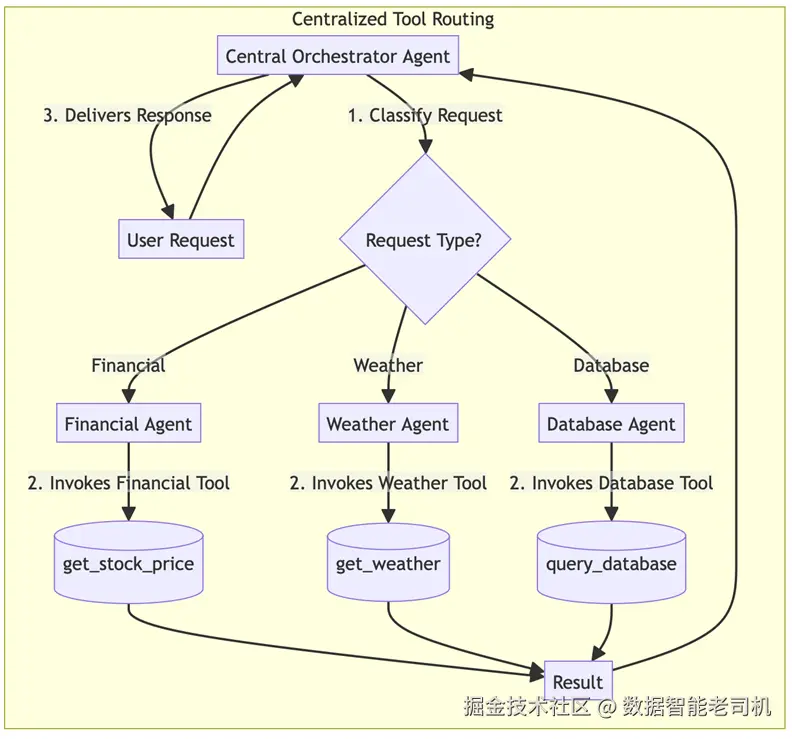
图 5.9 -- 中央化工具路由示例实现(Centralized tool routing example implementation)
实现示例(Example implementation)
一个 CentralOrchestrator 智能体基于请求分类,将用户请求路由到正确的专业智能体。
ruby
class CentralOrchestrator:
# This map defines which agent is responsible for which type of task
AGENT_ROUTING_MAP = {
"financial_query": "FinancialAgent",
"weather_query": "WeatherAgent",
"database_query": "DatabaseAgent"
}
def classify_request(self, user_request):
# Uses an LLM to classify the request type
# For example, "What is the current stock price of Google?" -> "financial_query"
# Or, "What is the weather like in London today?" -> "weather_query"
return self.llm.classify(user_request)
def handle_request(self, user_request):
# 1. Determine the type of request
request_type = self.classify_request(user_request)
# 2. Find the correct agent from the routing map
target_agent_name = self.AGENT_ROUTING_MAP.get(request_type)
if target_agent_name:
# 3. Delegate the request to the specialized agent
print(f"Routing request to {target_agent_name}")
target_agent = self.get_agent_instance(target_agent_name)
result = target_agent.process(user_request)
return result
else:
return "Sorry, I don't have an agent capable of handling that request."
class FinancialAgent:
# This agent ONLY knows about financial tools
def process(self, request):
# Uses its internal LLM to decide which of its specific tools to use
# e.g., self.llm.decide_tool(request, available_tools=[get_stock_price_tool])
...
class WeatherAgent:
# This agent ONLY knows about weather tools
def process(self, request):
# Uses its internal LLM to decide which of its specific tools to use
# e.g., self.llm.decide_tool(request, available_tools=[get_current_weather_tool])
...影响与权衡(Consequences)
优点(Pros):
- 更高准确性: 通过限制每个智能体可用的工具选项,系统降低了错误工具调用的概率,从而得到更可靠的结果。
- 专注: 智能体在各自领域高度专业化,提升效率与性能。
缺点(Cons):
- 刚性: 当任务意外需要超出某个智能体预设工具集的工具时,该模式可能不够灵活。
- 前期设计成本: 需要谨慎设计并持续维护路由映射或智能体能力定义。
实施建议(Implementation guidance)
对于工具数量庞大的系统,可以考虑构建一个工具注册表(tool registry) 供智能体查询。这样相较于硬编码的"工具-智能体"绑定关系,可以实现更动态的路由。路由逻辑也可以委派给一个专门的、由 LLM 驱动的 Router 智能体,让其通过函数调用(function-calling)来选择正确的智能体及其关联工具,从而获得更强的灵活性。
确保"正确的智能体"使用"正确的工具",是行动协同的关键一步。但要让行动真正有效,它必须基于对环境清晰且一致 的理解。然而,当不同智能体对同一环境产生不同感知、从而得到冲突数据时该怎么办?系统需要在行动之前,先把这些差异调和为一个统一的"事实版本",再继续推进。这正是 共识(Consensus) 模式所要解决的挑战。
共识(Consensus)
在任何分布式系统中,达成共享视角都是一个基础性难题。对于多智能体系统而言,自主智能体会基于各自对世界的感知来做决策,因此这一挑战会更加尖锐。
共识(Consensus) 模式提供了一组协议,使一群智能体能够就某条具体数据或系统状态达成一致。这不仅仅是"投票"那么简单;它强调的是一种结构化的沟通与收敛过程 ,确保系统能够在一个单一、可靠的视角下运转,从而避免由于依据相互矛盾的信息行动而引发的错误。
背景(Context)
在分布式系统中,多个智能体可能获取到关于环境状态的不同信息:有的可能不完整,有的甚至彼此冲突。为了推进协同行动,智能体必须先对一个共享理解达成一致。
问题(Problem)
即便存在噪声数据或轻微分歧,一组自主智能体如何才能对某个特定值或状态达成有保证的一致?如果缺少共识机制,智能体可能会依据相互矛盾的信息采取行动,进而导致系统级故障或低效。问题空间中的驱动因素包括:
- 一致性 vs 个体准确性: 智能体可能各自拥有高度准确、但彼此冲突的数据点。共识过程迫使它们在单一数值上妥协,可能以牺牲部分个体精度为代价。
- 收敛 vs 时间: 达成共识可能耗时,尤其在大规模智能体网络中。系统必须在"可靠结果"与"及时决策"之间权衡。
- 诚实参与者 vs 恶意参与者: 共识算法必须足够鲁棒,以处理噪声与小分歧;同时也需要识别与隔离那些故意提供虚假信息、试图破坏过程的智能体。
解决方案(Solution)
共识模式提供了一套协议,使智能体能够在共同状态上收敛,通常通过迭代式辩论实现。在该模型中,智能体广播其当前信念,接收其他智能体的信念,并基于预定义规则调整自身信念。该过程重复进行,直到所有智能体的状态在可接受的容差范围内收敛。这样可以在采取行动之前,确保对共享状态形成稳健且经过验证的理解。
示例:金融预测辩论(Example: Financial forecasting debate)
一家金融服务公司使用一组智能体为某公司的下一季度收入生成一个"共识预测"。每个智能体拥有不同视角或模型。
-
初始预测(第 1 轮): 编排器智能体向团队请求预测。
OptimistAgent通过分析积极市场趋势,预测 $110M。PessimistAgent聚焦潜在供应链风险,预测 $95M。RealistAgent使用历史业绩数据,预测 $102M。
-
迭代辩论(第 2 轮): 智能体彼此共享预测结果。它们计算平均值( $102.3M),并将自己的预测值向该均值方向调整一部分。
-
收敛: 共享与调整持续进行。每一轮最高与最低预测之间的范围都会缩小,直到所有预测都落入预设容差范围内。
-
行动: 系统宣布最终共识预测为 $103M,用于指导公司的投资策略。
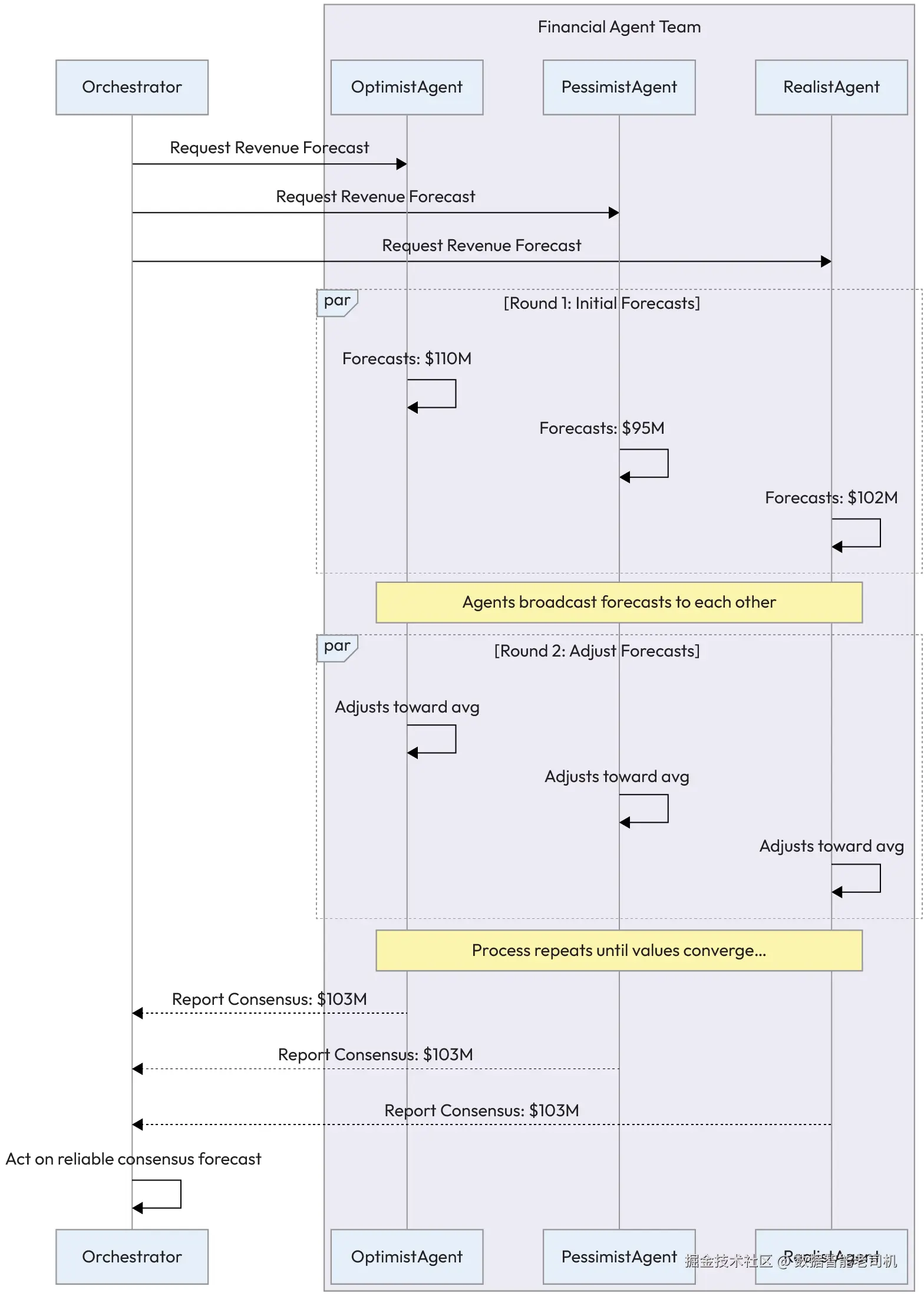
图 5.10 -- 智能体共识工作流(Agent consensus workflow)
实现示例(Example implementation)
下面的示例实现展示了共识模式:一组智能体如何通过迭代收敛来形成共享视角。在该 Level 6 架构中,ConsensusManager 充当结构化辩论的主持者,协调专业金融智能体之间的交互。
它并非只是简单平均分歧数据点;而是执行一个多轮协议:每个智能体观察集体均值,并依据自身内部逻辑调整自己的假设。该过程持续,直到各自预测落入指定容差,确保最终决策不仅是统计意义上的折中,而是通过所有自主成员的主动参与而达成的、经过验证的一致。
python
class ConsensusManager:
def get_consensus_forecast(self, agents, tolerance=1.0, max_rounds=5):
# Round 1: Get initial forecasts
forecasts = {agent.name: agent.get_initial_forecast() for agent in agents}
for round_num in range(1, max_rounds + 1):
# Check for convergence
max_forecast = max(forecasts.values())
min_forecast = min(forecasts.values())
if (max_forecast - min_forecast) <= tolerance:
print(f"Consensus reached in round {round_num}.")
return sum(forecasts.values()) / len(forecasts)
# Share and adjust
average_forecast = sum(forecasts.values()) / len(forecasts)
for agent in agents:
# Each agent adjusts its forecast towards the average
current_forecast = forecasts[agent.name]
adjusted_forecast = agent.adjust_forecast(
current_forecast, average_forecast
)
forecasts[agent.name] = adjusted_forecast
print("Max rounds reached. No consensus.")
return sum(forecasts.values()) / len(forecasts) # Fallback to average
class FinancialAgent:
def __init__(self, name, initial_forecast_value):
self.name = name
self.initial_forecast = initial_forecast_value
def get_initial_forecast(self):
return self.initial_forecast
def adjust_forecast(self, current_forecast, average_forecast, adjustment_factor=0.5):
# Adjusts the forecast by a certain factor towards the average
return current_forecast + (average_forecast - current_forecast) * adjustment_factor影响与权衡(Consequences)
优点(Pros):
- 可靠性: 通过结构化辩论,共识模式提升了系统决策的可靠性与鲁棒性,确保行动基于共享、已验证的理解,而非单一且可能有缺陷的数据点。
- 容错性: 该过程天然鲁棒,即便某个智能体未参与或无法提供有效响应,也不一定会导致整个过程停摆。
缺点(Cons):
- 延迟: 共识协议需要多轮通信与计算,会引入天然延迟,因此不适用于要求瞬时决策的实时系统。
- 复杂度: 实现一个鲁棒的共识协议较复杂,需要认真处理智能体失败、网络分区、恶意参与者等边界情况。
实施建议(Implementation guidance)
要让共识协议成功落地,设计中必须纳入若干核心原则:
- 明确终止条件: 例如最大轮数或明确的收敛阈值,防止系统陷入无限循环。
- 收敛算法作为核心逻辑: 决定智能体如何调整状态------从简单数值平均,到基于智能体历史可靠性的加权方法都可以。
- 优先可解释性: 记录辩论过程中的推理与中间状态,形成关键审计链路,便于相关方理解最终共识是如何达成的。
共识可以帮助智能体在"事实"层面达成一致,但它并不能解决"目标"本身相互对立的情况。下一种模式------协商(Negotiation) ------提供了一个框架,用于在存在竞争性利益时,帮助智能体化解冲突并找到互利的结果。
智能体协商(Agent Negotiation)
当智能体以自主方式运行时,它们往往拥有各自的目标,而这些目标未必总能与其他智能体的目标完全一致。这会导致一些情形:智能体对资源提出竞争性主张,或对行动方案存在相互冲突的偏好。
与其诉诸一种简单的、自上而下的裁决(这种裁决可能对所有参与方都不够理想),更高级的做法是让智能体自行化解冲突 。协商(Negotiation) 模式为这类交互提供了一套结构化协议。
背景(Context)
多个自主智能体(往往带有自利动机或相互冲突的目标)需要达成一个各方都可接受的协议,以完成任务或解决争议。
问题(Problem)
在没有中央权威来强制裁决的情况下,自利型智能体如何达成互利的协议?一种固定、不可协商的方式容易导致僵局,或产生次优结果,使潜在的"双赢"方案被错过。问题空间中的驱动因素包括:
- 自主性 vs 对齐: 智能体需要自由追求各自目标,但系统必须确保个体成功不会以牺牲集体目标为代价。
- 公平性 vs 效率: 协商理想情况下应产生"共赢"结果、让各方满意;但达成协议所需的时间与算力必须与及时决策的需求相平衡。
- 策略行为 vs 透明度: 复杂协商策略可能带来最优结果,但往往会使决策背后的推理更难审计、也更难向人类利益相关者解释。
解决方案(Solution)
协商模式提供一套结构化协议,使智能体通过"报价---还价"的往返对话来寻找折中方案。该模式深受博弈论影响,在博弈论中,智能体被视为试图最大化自身效用的理性行动者。
典型的协商协议包含:发起(初始报价) 、评估 、以及响应(接受、拒绝或提出还价) 。该过程循环进行,直到达成协议或触发终止条件。
示例:围绕共享资源的协商(Example: Negotiating for a shared resource)
在一个数据处理环境中,两名智能体都需要使用一台高性能 GPU 服务器来完成任务。ResourceManagerAgent 负责管理该服务器,并在发生冲突时发起协商。
AnalyticsAgent目标:运行一个时间敏感、优先级很高的金融模型,需要一个 2 小时 的计算窗口,理想情况下从 凌晨 2:00 开始。TrainingAgent目标:运行一个例行的、优先级较低的模型再训练任务,需要一个 4 小时 窗口,也安排在 凌晨 2:00。
由 ResourceManagerAgent 作为调停者(mediator),协商过程如下展开:
-
冲突检测:
AnalyticsAgent与TrainingAgent都请求在 2:00 AM 锁定 GPU 服务器。ResourceManagerAgent检测到冲突。 -
发起:
ResourceManagerAgent告知双方存在冲突,并要求它们说明自身优先级与可调整空间。AnalyticsAgent回复:{"priority": "high", "duration": "2 hours", "flexibility": "low"}TrainingAgent回复:{"priority": "low", "duration": "4 hours", "flexibility": "medium"}
-
评估与提议:
ResourceManagerAgent的策略是优先处理 "high" 优先级任务,于是要求TrainingAgent提出一个新的时间方案。 -
还价:
TrainingAgent查看调度表,提出折中方案:- 报价: 我可以推迟我的任务。我建议在 4:00 AM 开始执行 4 小时任务,紧接在
AnalyticsAgent的 2 小时窗口结束之后。
- 报价: 我可以推迟我的任务。我建议在 4:00 AM 开始执行 4 小时任务,紧接在
-
达成一致:
ResourceManagerAgent确认新的排程消除了冲突并满足所有约束,向双方发送确认。- 确认: 协议达成。
AnalyticsAgent排程为 2:00 AM--4:00 AM;TrainingAgent排程为 4:00 AM--8:00 AM。
- 确认: 协议达成。
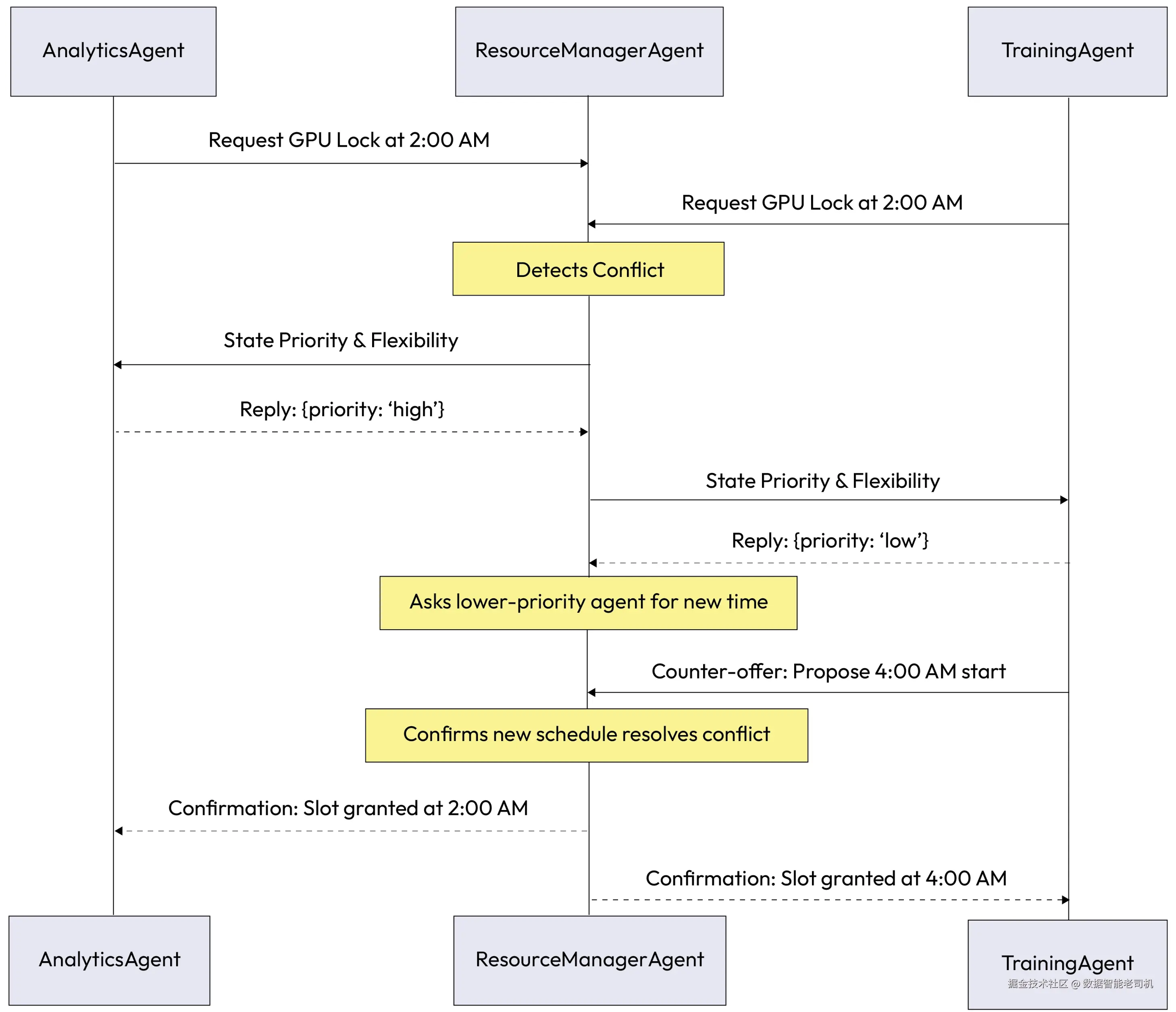
图 5.11 -- 智能体协商工作流(Agent Negotiation workflow)
在这个场景中,智能体成功协商出了一个新的排程方案,既尊重了任务优先级,也确保最关键的作业按时完成,全程无需人工介入。
实现示例(Example implementation)
下面的示例实现展示了资源管理场景下的智能体协商模式。在该场景中,ResourceManagerAgent 作为调停者,识别自主同伴之间的排程冲突。代码并非强制给出固定裁决,而是展示了协商协议的第一阶段:调停者评估任务优先级,并通过请求低优先级智能体给出还价来启动对话。该方式使系统能够在遵守业务约束的同时,找到各方可接受的方案,并维持单个智能体的自主性。
python
class ResourceManagerAgent:
def handle_requests(self, request1, request2):
if request1.time == request2.time: # Conflict detected
# Determine which agent is lower priority
if request1.priority < request2.priority:
lower_priority_agent = Agent1
higher_priority_agent = Agent2
else:
lower_priority_agent = Agent2
higher_priority_agent = Agent1
# Ask the lower-priority agent to propose a new time
new_proposal = lower_priority_agent.propose_new_time()
# Check if the new proposal resolves the conflict
if self.is_conflict_resolved(new_proposal, higher_priority_agent.request):
self.grant_slot(higher_priority_agent, higher_priority_agent.request.time)
self.grant_slot(lower_priority_agent, new_proposal.time)
return "Agreement Reached"
else:
# Fallback or further negotiation rounds
return "Negotiation Failed"
def is_conflict_resolved(self, proposal, existing_request):
# Logic to check if the proposed time slot is available
pass
def grant_slot(self, agent, time):
# Logic to update the schedule and inform the agent
pass
class TrainingAgent: # (Lower Priority)
def propose_new_time(self):
# Agent logic to find the next best available slot
new_time = "4:00 AM"
print(f"I am lower priority. I can defer. I propose to start at {new_time}.")
return Proposal(time=new_time)
class Proposal:
def __init__(self, time):
self.time = time影响与权衡(Consequences)
优点(Pros):
- 灵活性: 该模式允许形成灵活、动态的协议,相比僵硬的固定策略,往往能为各方带来更好的结果。
- 最优性: 能够发现一些"共赢"方案,而这些方案可能并不显然,也未必能靠中央权威或预设规则提前写死。
缺点(Cons):
- 时间与复杂度: 协商可能耗时且计算开销大,并且无法保证一定能达成一致。
- 无保证: 协商过程可能失败而无法给出解决方案;若缺少兜底机制,可能导致僵局。
实施建议(Implementation guidance)
- 定义清晰的终止条件与兜底立场: 如果谈不拢怎么办?智能体必须有 Plan B。
- 记录完整的报价与还价序列: 用于审计、复盘,并支持必要的人类监督。
协商是一种有效模式,可用于解决两个或多个智能体之间的特定冲突;但系统往往还面临更宏观的问题:如何把有限的资源池分配给许多竞争的智能体。这需要一种更系统化的供需管理方法。资源分配(Resource Allocation) 模式为这一系统级挑战提供了框架。
资源分配(Resource Allocation)
在任何复杂系统中,资源都是有限的。无论是计算能力、网络带宽、对某个特定 API 的访问额度,还是诸如机械臂这类物理资产,往往都存在供不应求 的情况。当多个智能体同时需要同一类受限资源时,系统就必须具备一种公平且高效的方法来决定"谁得到什么"。
资源分配(Resource Allocation) 模式为这种分配提供了结构化方法,使系统能够超越简单的"先到先得"逻辑,转向更智能、更目标导向的模型。
背景(Context)
一个多智能体系统拥有有限的资源池(例如网络带宽、算力或 API 调用配额),必须在多个存在竞争需求的智能体之间进行分配。
问题(Problem)
系统如何在相互竞争的智能体之间分配有限资源,既高效 、公平,又能与系统整体目标保持一致?如果缺乏明确的分配策略,多智能体系统可能出现争用、瓶颈以及次优性能表现。问题空间中的驱动因素包括:
- 吞吐量 vs 公平性: 系统希望通过优先处理高价值任务来最大化整体产出,但也必须防止"饥饿(starvation)"现象------即低优先级智能体永远得不到运行所需资源。
- 集中控制 vs 额外开销: 中央分配器可以掌握全局优先级与资源可用性并确保一致性,但随着智能体与请求数量增长,它可能成为性能瓶颈或单点故障。
- 可预测性 vs 适应性: 固定分配规则简单且可预测,但往往无法应对任务重要性动态变化,或需要立即重分配资源的突发环境变化。
解决方案(Solution)
资源分配模式实现一种管理资源分发的机制。关键方法包括:
- 集中式分配器(Centralized allocator): 由一个专门智能体(如管理者)基于系统优先级与资源可用性的全局视角做出分配决策。
- 拍卖机制(Auction mechanisms): 智能体使用内部货币或优先级分数对资源"出价",最高出价者在指定时段内获得资源。当任务真实价值能够由智能体自身量化时,这种方式尤其有效。
- 公平划分算法(Fair division algorithms): 当公平性至关重要时,可用算法计算"可能公平"的分配,例如将资源分成让任何智能体都不会嫉妒他人份额的方式。
示例:智能工厂中的自主机器人分配(Example: Autonomous robot allocation in a smart factory)
一家智能工厂使用数量有限的自主移动机器人(AMR)来运输物料。中央 AMR_DispatcherAgent 根据任务优先级分配机器人,以最大化工厂产出。
ProductionLine_A_Agent发出高优先级请求:需要一台 AMR 运送关键零部件,并警告产线即将停线。WarehouseAgent发出低优先级请求:需要一台 AMR 执行例行库存盘点。ShippingAgent发出中优先级请求:需要一台 AMR 将成品运至装卸区,以满足两小时后到期的出货。
AMR_DispatcherAgent 评估这些相互竞争的请求。按照其优先级规则,它会立即将下一台可用 AMR 分配给 ProductionLine_A_Agent,以避免代价高昂的停线。随后为 ShippingAgent 分配一台 AMR 以满足出货时限。WarehouseAgent 的低优先级请求则被放入队列,只有在有机器人可用且没有更高优先级任务待处理时才会被满足。
这种基于优先级的分配流程可视化如下:
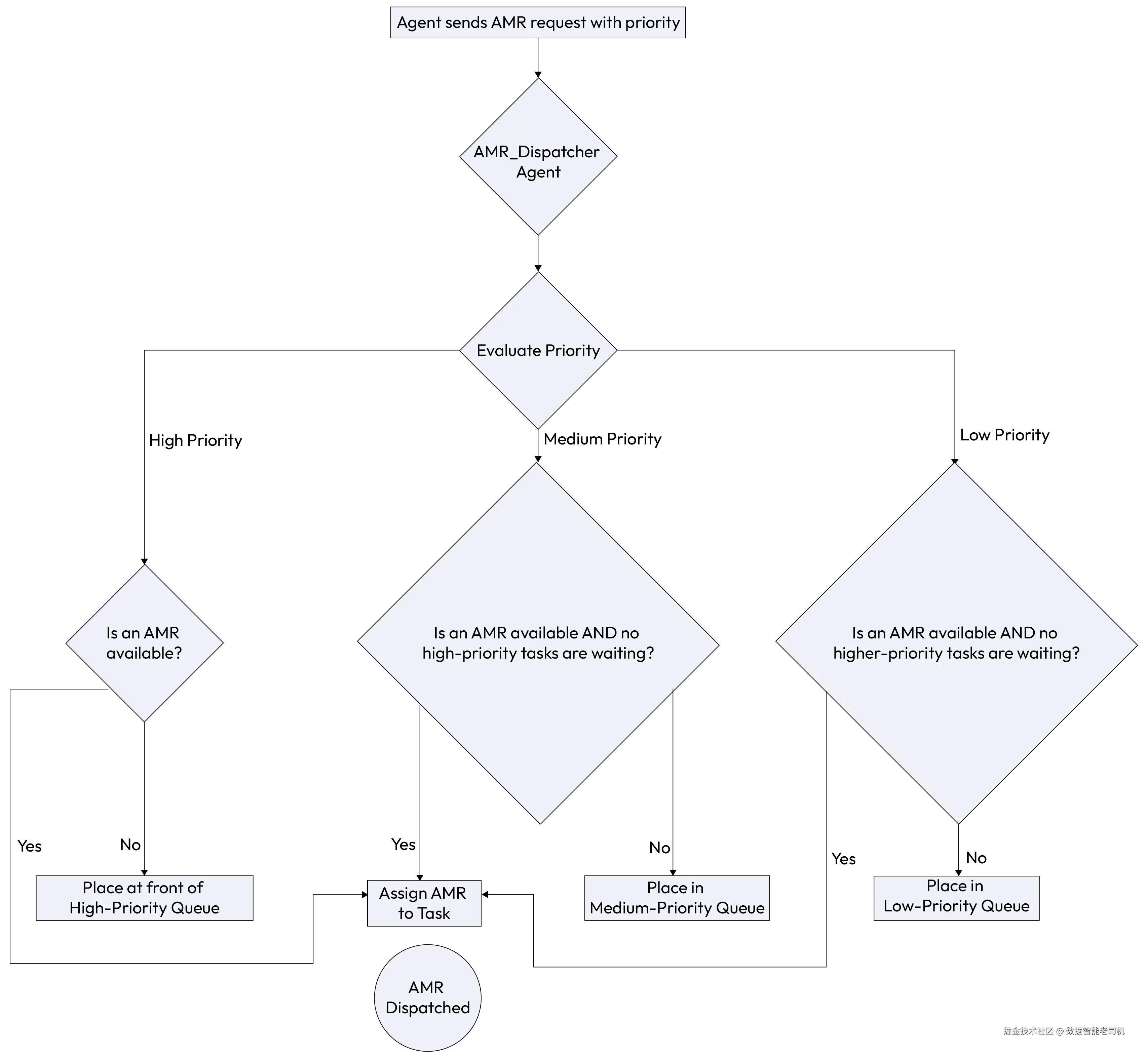
图 5.12 -- 资源分配(Resource Allocation)
实现示例(Example implementation)
下面的实现通过一个 AMR 调度器演示资源分配模式。在这种高级协同(Level 5)场景中,系统通过分层优先队列处理传入请求,以管理有限的实体机器人编队。
该代码展示了 AMR_DispatcherAgent 如何作为集中式控制器,评估来自不同部门任务的紧急程度(例如产线关键部件与例行盘点),并确保最有影响力的工作被分配给下一台可用机器人。该方法有效平衡了车间的竞争性需求,同时防止资源争用,并确保系统级目标(如避免停线)始终被优先保障。
python
class AMR_DispatcherAgent:
def __init__(self):
# Queues for holding requests of different priorities
self.high_priority_queue = []
self.medium_priority_queue = []
self.low_priority_queue = []
self.available_amrs = [AMR1(), AMR2(), AMR3()]
def receive_request(self, request):
if request.priority == "high":
self.high_priority_queue.append(request)
elif request.priority == "medium":
self.medium_priority_queue.append(request)
else:
self.low_priority_queue.append(request)
self.dispatch()
def dispatch(self):
if not self.available_amrs:
return # No robots available right now
# Process highest priority requests first
if self.high_priority_queue:
task = self.high_priority_queue.pop(0)
robot = self.available_amrs.pop(0)
robot.assign_task(task)
elif self.medium_priority_queue:
task = self.medium_priority_queue.pop(0)
robot = self.available_amrs.pop(0)
robot.assign_task(task)
elif self.low_priority_queue:
task = self.low_priority_queue.pop(0)
robot = self.available_amrs.pop(0)
robot.assign_task(task)
class AMR1:
def assign_task(self, task):
print(f"AMR1 is assigned a {task.priority} priority task: {task.name}")
class AMR2:
def assign_task(self, task):
print(f"AMR2 is assigned a {task.priority} priority task: {task.name}")
class AMR3:
def assign_task(self, task):
print(f"AMR3 is assigned a {task.priority} priority task: {task.name}")
class Request:
def __init__(self, name, priority):
self.name = name
self.priority = priority
# Example Usage:
dispatcher = AMR_DispatcherAgent()
dispatcher.receive_request(Request("deliver critical component", "high"))
dispatcher.receive_request(Request("move finished goods", "medium"))
dispatcher.receive_request(Request("perform inventory count", "low"))影响与权衡(Consequences)
优点(Pros):
- 优化(Optimization): 确保稀缺资源被导向最关键任务,使系统整体效用最大化,而不是仅满足最快发起请求的智能体。
- 稳定性(Stability): 防止资源争用、死锁与竞态条件,这些问题可能导致系统崩溃或行为不可预测。
缺点(Cons):
- 额外开销(Overhead): 分配过程(无论是集中式计算还是分布式拍卖)都会在任务实际执行前引入延迟。
- 饥饿风险(Risk of starvation): 如果分配规则设计不当,低优先级智能体可能永远得不到运行所需资源,因此必须配套保护机制。
实施建议(Implementation guidance)
- 分配逻辑必须透明且显式。无论是基于优先级、竞价还是公平性,这种清晰性对调试与可解释性都至关重要。
- 在拍卖型系统中,规则应鼓励智能体按真实价值出价,这一原则被称为激励相容(incentive compatibility) ,以防止智能体为了获得优势而虚报需求。
- 分配机制也应能随条件变化而调整,并在更关键任务出现时**抢占(preempt)**低优先级任务。
通过实施清晰的资源分配策略,多智能体系统就能超越简单且往往低效的争用方式,确保关键资源被高效使用并导向最重要任务,从而提升整体性能,并使行动与全局优先级保持一致。它为管理复杂智能体生态系统的运行成本与约束提供了稳定基础。
健壮的资源分配方案能有效防止一种常见冲突来源。然而,多智能体系统中的分歧并不只来自资源稀缺:智能体还可能形成彼此不兼容的计划或目标,从而导致潜在死锁或不安全状态。
下一个模式------冲突解决(Conflict Resolution) ------提供了检测与调解这些直接冲突所需的机制。
冲突解决(Conflict Resolution)
当自主智能体追求各自目标时,它们的路径难免会在某些时候发生交叉,从而形成直接冲突。例如,一个智能体计划把机械臂移动到某个特定位置,可能会与另一个智能体计划占用同一空间的操作相冲突。又比如,两名金融智能体可能会对同一只股票给出相反的交易建议。**冲突解决(Conflict Resolution)**模式对系统稳定性至关重要,它提供了一个结构化框架,用于识别这些争执点,并以避免系统故障、且与系统总体目标一致的方式加以解决。
背景(Context)
在多智能体系统中,两个或多个智能体可能拥有相互冲突的计划动作或目标。比如,两个物流智能体可能试图在同一时间让各自的卡车穿过同一条狭窄街道。
问题(Problem)
系统如何解决智能体之间的分歧或冲突计划,以避免死锁、不安全状态或次优结果?如果允许智能体在冲突动作下继续执行,可能导致系统失败、低效的来回振荡,或策略不一致。问题空间中的驱动因素包括:
- 安全性 vs 运行速度: 确保不发生冲突动作能防止系统故障或物理损坏,但检测与解决过程会引入延迟,从而拖慢高频操作。
- 集中式权威 vs 分布式敏捷: 监督者可以提供果断且一致的裁决,但依赖中心控制点可能形成瓶颈,限制各智能体的响应速度。
- 逻辑一致性 vs 目标达成: 解决冲突通常要求至少一个智能体放弃或修改当前计划,这可能牺牲特定任务的最优性,以换取更大系统的完整性。
解决方案(Solution)
冲突解决模式提供一套结构化机制,用于检测并化解冲突。它不是让智能体卡住,而是引入一个调解(mediation) 过程。采用何种方法取决于系统架构、冲突性质,以及你更需要果断的自上而下控制,还是更动态、涌现式的达成一致。
下面是一些常见方法:
1)层级式裁决(Hierarchical resolution)
指定的监督者或编排器智能体拥有最终权威,可以推翻冲突智能体并强制施加决策。这是最直接的方法,结果清晰且可预测。它在需要全局视角、且存在明确权责边界的系统中特别有效,类似传统的管理结构。
在企业应用中,这往往是默认选择,因为合规、安全与可审计决策至关重要。监督者作为单一事实源,避免系统陷入犹豫或死锁。
2)基于策略的裁决(Policy-based resolution)
系统预先定义一组策略或规则,用于自动处理特定类型冲突。这种方法高度可靠且便于审计。例如策略可以规定:"安全关键智能体始终优先于效率优化智能体",或"面向客户的任务优先于内部报表任务"。
这种裁决是确定性的、一致的。其强大之处在于将决策逻辑外置,使人类无需理解每个智能体的内部状态,也能理解、修改并审计系统行为。
3)协商(Negotiation)
冲突智能体可以进入协商过程(使用协商模式)以寻找双方可接受的折中方案。这种自下而上的方法适用于存在"共赢"或"少输"空间的场景,并要求智能体具备让步与评估反要约的能力。
不同于自上而下命令,该方法让冲突相关方在系统约束内,找到更符合各自目标的方案。它增强适应性,且可能产生比僵硬策略更细腻、更具创造性的结果。
4)博弈论式裁决(Game-theoretic resolution)
在高度复杂的场景中,可将冲突形式化为一个博弈:为每个智能体的潜在动作赋予收益或成本,系统再寻找稳定解,例如纳什均衡(Nash equilibrium) ------在该状态下,任何智能体单方面改变策略都无法获益。
该方法计算成本高,但可用于设计"可能稳定"的系统,并让智能体的自利行为与全局目标对齐。通过形式化冲突,它支持更深层分析,并可工程化地塑造一种结构,使期望的合作行为能从智能体理性逐利中自然涌现。
示例:解决企业工作流冲突(Example: Resolving an enterprise workflow conflict)
在贷款处理系统中,两个智能体目标冲突:
- ThroughputAgent:优化每小时处理尽可能多的贷款申请,以满足速度 KPI
- FairnessAgent:对申请批次执行计算开销很大的公平性分析,用于检查人口统计偏差,这会降低速度
冲突出现于:ThroughputAgent 为维持速度,试图将某批申请直接推进到最终审批;而 FairnessAgent 将同一批次标记为需要进行耗时 20 分钟的详细审查。
- 冲突检测: 两个互斥动作("推进到审批" vs "因公平性复核而冻结")被记录到中央
SupervisorAgent中。 - 策略式裁决:
SupervisorAgent查询内部策略框架,发现一条不可协商策略:所有贷款批次在进入审批前必须获得FAIRNESS_PASSED状态。合规与伦理要求优先于速度 KPI。 - 裁决:
SupervisorAgent使ThroughputAgent的计划失效,命令其停止并等待公平性检查完成;同时确认FairnessAgent具有优先权继续分析。 - 继续:
FairnessAgent完成检查并更新批次状态为FAIRNESS_PASSED后,SupervisorAgent允许ThroughputAgent恢复执行。
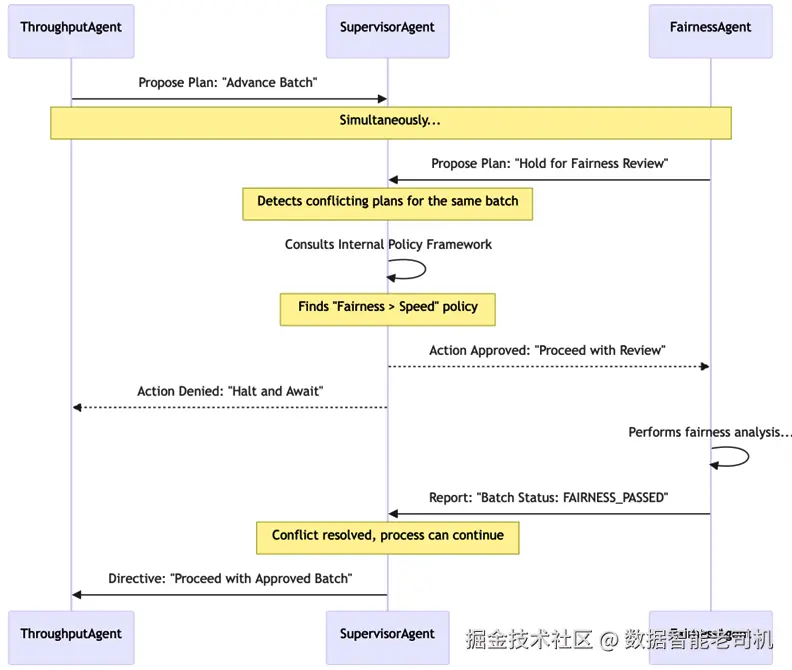
图 5.13 -- 冲突解决工作流(Conflict Resolution workflow)
实现示例(Example implementation)
下面的实现展示了企业贷款处理中冲突解决模式的一个例子。SupervisorAgent 作为调解者,处在两个目标相反的智能体之间:一个追求吞吐最大化,另一个追求人口统计公平性。
代码演示了基于策略的裁决:监督者根据不可协商的合规框架评估两份计划。通过否决高速方案、优先执行公平性复核,系统确保伦理规范被遵守,而无需让各智能体理解更宏观的公司政策。该集中式调解可避免系统陷入逻辑不一致,或在未经验证的决策下继续推进。
python
class SupervisorAgent:
def __init__(self):
# Policies define the rules of engagement
self.POLICY_FRAMEWORK = {
"FAIRNESS_CHECK_REQUIRED": True
}
def handle_proposed_plans(self, plan1, plan2):
if self.is_conflicting(plan1, plan2):
print("Conflict Detected!")
# Apply Policy-Based Resolution
if self.POLICY_FRAMEWORK["FAIRNESS_CHECK_REQUIRED"]:
if plan1.action == "HOLD_FOR_FAIRNESS_REVIEW":
# FairnessAgent's plan has priority
self.approve_plan(plan1)
self.deny_plan(plan2, reason="Fairness check must complete first.")
else:
# ThroughputAgent's plan must wait
self.approve_plan(plan2)
self.deny_plan(plan1, reason="Fairness check must complete first.")
else:
# Other resolution logic
pass
def is_conflicting(self, plan1, plan2):
# A simple example of a conflicting condition
return plan1.target == plan2.target and plan1.action != plan2.action
def approve_plan(self, plan):
print(f"Approving plan: {plan.name}")
def deny_plan(self, plan, reason):
print(f"Denying plan: {plan.name}. Reason: {reason}")
class Plan:
def __init__(self, name, target, action):
self.name = name
self.target = target
self.action = action
# Example Usage:
supervisor = SupervisorAgent()
plan1 = Plan("Fairness Check", "Loan Batch 123", "HOLD_FOR_FAIRNESS_REVIEW")
plan2 = Plan("Advance to Approval", "Loan Batch 123", "ADVANCE_TO_APPROVAL")
supervisor.handle_proposed_plans(plan1, plan2)影响与权衡(Consequences)
优点(Pros):
- 一致性(Coherence): 确保系统不会陷入自相矛盾或死锁状态,维护整体运行的完整性。
- 安全性(Safety): 防止智能体互相干扰导致危险情况(例如机器人碰撞或逻辑数据损坏)。
缺点(Cons):
- 延迟(Latency): 冲突检测与解决会引入计算开销,降低系统响应速度。
- 复杂度(Complexity): 为所有潜在冲突场景设计健壮策略或协商协议,会显著增加工程工作量。
实施建议(Implementation guidance)
1)冲突检测:第一步
在解决冲突前,必须先检测冲突。这一点关键却常被低估,就像"预警系统"。最直接的方法是用一个中央监督者智能体监控所有智能体的计划与动作。
例如,当两个智能体登记要使用同一稀缺资源时,监督者可立即标记冲突。其他方法包括资源锁(智能体对即将使用的资源加锁),或要求智能体在执行前先把意图动作注册到共享空间。
2)可解释的裁决:审计轨迹
冲突被解决后,系统不能只是继续运行;必须记录决策理由。审计轨迹对调试、合规和建立信任至关重要。日志应清晰说明为何选择某种裁决。
例如:"之所以批准智能体 B 的方案而拒绝智能体 A,是因为策略 编号 规定安全关键任务优先于其他所有任务。" 这种透明度让人类能理解并验证系统行为。
3)明确的升级路径:人类介入(Human-in-the-Loop)
理想情况下冲突都能自动解决,但现实中总会有关键、未预见场景使自动机制失败或无法收敛。因此必须提供清晰可靠的升级路径。
在企业系统中,最终兜底通常是人类在环:由人类操作员审阅冲突上下文并给出最终裁决。系统应能把必要信息打包交付给人类,以便快速、明智地决策。
4)通过仿真理解:韧性测试
在部署多智能体系统之前,尤其是使用复杂协商或博弈论模型时,必须在多种条件下仿真智能体交互。
这能对冲突解决策略进行压力测试,识别潜在死锁或不良涌现行为。通过在安全环境中模拟冲突与解决过程,开发者可微调策略与协议,确保系统在真实世界挑战下保持一致性与稳定性。
一致性与稳定性的基础(The foundation for coherence and stability)
多智能体系统需要清晰协议来解决冲突,使整体系统在其组成智能体目标分歧、观点不同甚至结论相反时,仍能保持一致性与稳定性。这能避免代价高昂的死锁,并确保系统能持续运作、做出符合全局优先级的决策,而不是被内部争执卡住。
解决逻辑冲突与资源管理对抽象任务协作至关重要。但协同挑战并不总是关于目标或数据;有时它关乎智能体本身的物理(或逻辑)编队结构。在机器人或复杂仿真等领域,一组智能体能否以特定结构(如群体)作为整体行动,将直接决定项目成败。
这正是 Formation Control(队形控制) 模式变得必不可少的原因。
队形控制(Formation Control)
队形控制模式是一种用于群体移动与空间组织 的设计原则,适用于一组智能体的集体行为。不同于管理抽象任务或资源的模式,这一模式专门面向这样的场景:一组智能体在穿行于环境中时,必须在彼此之间保持某种既定的物理或逻辑结构。
它使得一群("swarm"或"squad")智能体能够像一个单一、协同的整体那样行动,在没有集中式控制器的情况下,也能流畅地对变化做出反应。
背景(Context)
系统包含一组智能体,它们在移动或在环境中执行动作时,需要相互之间保持特定的物理或逻辑结构。这在机器人系统、复杂仿真,以及任何需要统一、集体行动的场景中都很常见。
问题(Problem)
如何让一组智能体在不依赖僵硬、集中式控制器逐个指定位置的情况下,动态维持队形?依赖单一领队会引入单点故障,并且难以适应障碍物或环境变化,最终可能导致碰撞、队形破裂或导航效率低下。问题空间中的驱动因素包括:
- 全局一致性 vs 局部感知: 群体需要维持某种全局形状,但单个智能体往往只能获得周边邻居的局部信息,使得在大规模群体上维持完美队形变得困难。
- 结构刚性 vs 避障需求: 群体必须保持预定义队形以达成目标,但个体智能体也必须能偏离结构来绕开环境风险或避免碰撞。
- 通信延迟 vs 同步速度: 精确队形控制需要智能体之间快速更新以保持对齐,但高频通信可能会压垮网络,或增加电池供电设备(如无人机、移动机器人)的能耗。
解决方案(Solution)
队形控制模式通过去中心化控制逻辑 ,使一组智能体能够自组织。核心思想是:每个智能体根据其邻近智能体的位置与状态来做决策,而不是跟随中央领队的命令。每个智能体被编程为遵循一组简单的控制律,规定它与指定邻居之间应保持的期望距离与方位角。这样一来,队形能够对障碍与环境变化做出流畅适应:每个智能体的局部反应会在队形中级联传播,从而形成集体的、涌现式响应。
示例:农业无人机编队(Example: Agricultural drone swarm)
设想一支农业无人机机群,需要以精确网格队形喷洒一大片农田,以保证覆盖均匀。
- 队形规则: 每架无人机都遵循一条简单规则:保持在左侧邻居右侧 10 米处,并与前方邻居保持同一直线对齐。
- 协同移动: 当领航无人机向前飞行时,群体中的每架无人机会跟随,并基于邻居的位置持续调整自身速度与位置,以维持网格。
- 动态适应: 位于队形中部的 Drone_C 检测到前方路径上有一棵树。它自主执行避障动作:减速并绕开障碍物飞行。
- 自组织: Drone_C 的相邻无人机会立即感知到其位置变化。Drone_B(左侧)和 Drone_D(右侧)降低速度以避免碰撞;Drone_C 后方的无人机也减速以维持间距。
- 重组队形: 当 Drone_C 通过障碍物后,它加速回到指定位置。其邻居感知到这一纠正并调整各自速度,从而无缝恢复完美队形,全程无需任何中央指令。
对于队形中的任意单个智能体,其核心逻辑循环可用下图表示:
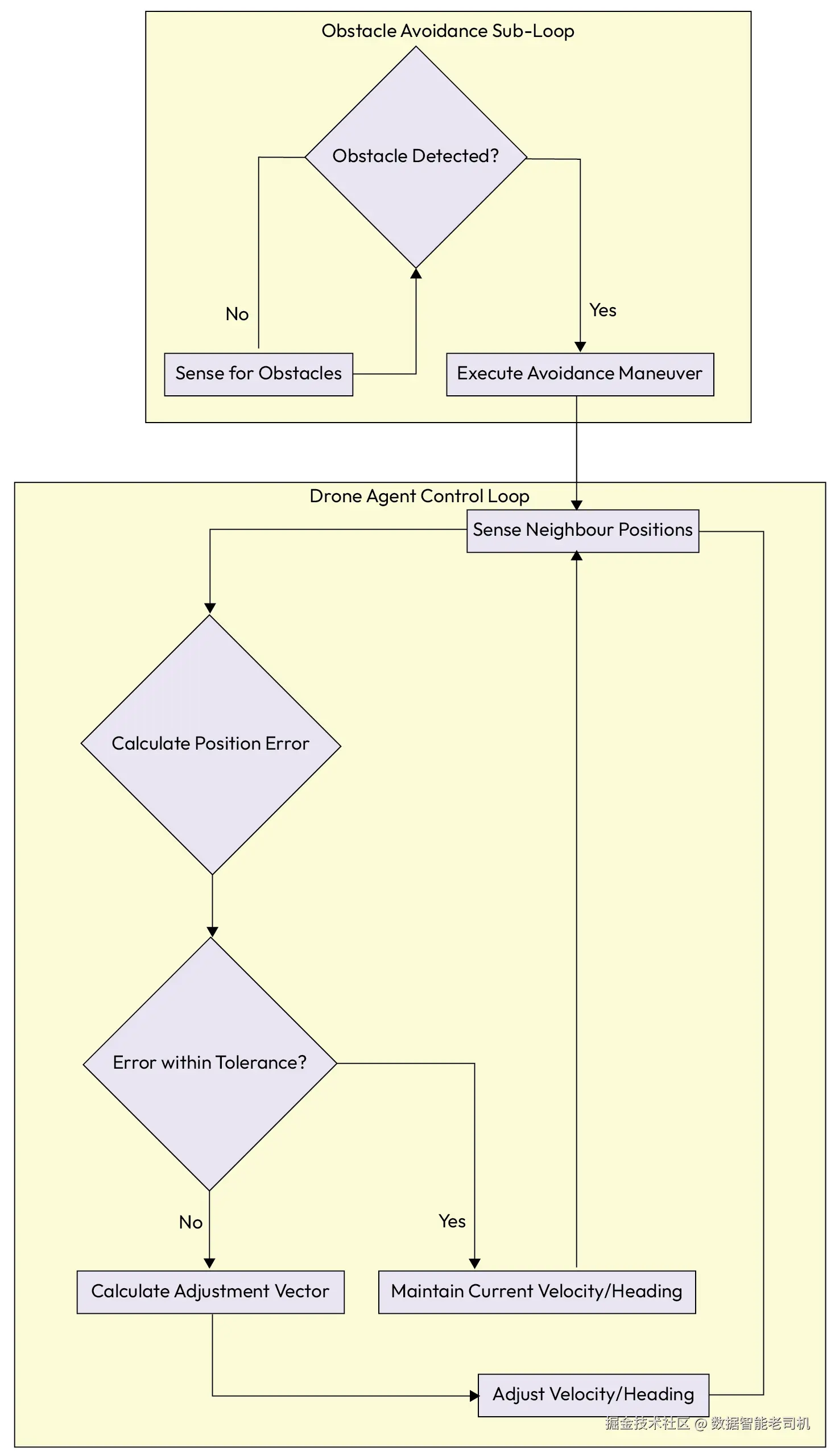
图 5.14 -- 队形控制中单个智能体的控制回路(A single agent's control loop for Formation Control)
实现示例(Example implementation)
下面的实现通过一个简化的无人机机群仿真展示队形控制模式。在该示例中,每个 DroneAgent 都运行一个去中心化控制回路:其运动由相对于指定邻居的固定偏移量决定。
代码说明:集体结构来自局部规则而不是中央命令。每个智能体持续感知邻居位置,基于预定义偏移计算自身期望坐标,并通过速度调整纠正误差。这种局部方法使整体队形保持流畅与韧性:机群能够适应个体偏离或环境变化,而无需全局路径规划器。
ini
class DroneAgent:
DESIGNATED_OFFSET = Vector(10, 0) # e.g., 10 meters to the right
def control_loop(self):
while True:
# 1. Sense neighbor's position
neighbor_position = self.get_neighbor_position()
my_position = self.get_my_position()
# 2. Calculate the desired position based on the neighbor
desired_position = neighbor_position + self.DESIGNATED_OFFSET
# 3. Calculate the error between current and desired position
position_error = desired_position - my_position
# 4. Check if adjustment is needed
if NORM(position_error) > TOLERANCE:
# 5. Calculate an adjustment vector to correct the error
adjustment_vector = self.calculate_adjustment(position_error)
self.adjust_velocity(adjustment_vector)
else:
self.maintain_velocity()
# An obstacle avoidance sub-loop would also be running
...影响与权衡(Consequences)
优点(Pros):
- 可扩展性(Scalability): 编队可扩展到数百乃至数千个智能体,而不会增加任何单一控制器的计算负担,因为决策是局部的。
- 韧性(Resilience): 对单个智能体故障具有鲁棒性;如果某个智能体掉线,相邻智能体会自然补位、缩小空隙。
缺点(Cons):
- 局部最优(Local optima): 仅基于局部信息的智能体在复杂障碍环境中可能陷入困局(例如死胡同),而全局规划器通常能轻松规避。
- 稳定性风险(Stability risks): 如果控制律参数调得不好,可能出现振荡:智能体不断过度纠正位置,导致队形抖动。
实施建议(Implementation guidance)
要成功实现队形控制模式,需要处理若干关键技术点,首先是邻居发现(neighbor discovery) :智能体必须有可靠机制识别并跟踪相关同伴的状态。可通过低延迟的直接通信(例如本地 mesh 网络)实现,或通过观察共享状态表示实现。
该模式的核心是控制律(control laws) ------决定智能体如何相对他者调整位置的具体规则。必须运用控制理论原则精心设计这些规则,以确保队形稳定,在压力下不发生振荡或破裂。
最后,仿真(simulation) 是部署前测试与打磨控制律的关键手段:它为集体行为的迭代提供一种安全、低成本的方式,避免在真实物理环境中试错带来的高风险与高成本。
通过队形控制模式,我们 завершили(完成了)对多智能体协同的基础模式的探讨:从高层的任务委派与规划,一路走到协商、资源管理,再到如今的空间组织这一更精细的动态机制。
现在,让我们退一步,总结本章的关键要点。
总结(Summary)
本章探讨了使多个自治智能体能够作为一个连贯且智能的系统 协同工作的关键模式。我们明确:从单一智能体迈向多智能体系统,会引入一层新的复杂性,需要用结构化方案来处理协作、竞争与通信 。这些模式为构建鲁棒、可扩展且一致 的多智能体系统提供了架构蓝图。我们不仅细化了各个模式本身,还将它们置于 GenAI 成熟度模型中进行语境化说明,展示了当系统从"基础阶段"走向"自治阶段"时,这些模式的应用如何随之演进。
我们首先建立了高层的任务委派框架 (监督者/编排者 Supervisor vs. 群体 Swarm),并进一步探讨了若干具体的智能体组合拓扑 :例如用于共享知识渐进演化的 Blackboard ,用于市场化任务分配的 Contract-Net ,以及用于容错与故障隔离的 Supervision Trees(监督树) 。在此基础上,我们深入到协作的具体机制,包括用于任务分解的 Multi-Agent Planning(多智能体规划) 、用于形成集体智能的 Knowledge Sharing(知识共享) ,以及用于管理能力与工具使用的 Tool Routing(工具路由) 。
随后,讨论转向管理任何分布式系统中天然存在的"摩擦"。我们探索了一组能够优雅处理分歧与竞争的模式,包括 Consensus(共识) 、Negotiation(协商) 、Resource Allocation(资源分配) 与 Conflict Resolution(冲突消解) 。最后,我们考察了适用于需要空间协同的系统的 Formation Control(队形控制) 模式。
关键结论如下:
- 协同是被架构出来的,而不是理所当然的: 高效的多智能体系统建立在一组明确的协同模式之上,这些模式定义了系统如何委派任务、如何规划、以及如何相互交互。
- 框架与拓扑决定控制流: 架构选择------无论是集中式的 Supervisor 、去中心化的 Swarm ,还是像 Blackboard 这样的专用拓扑------都会塑造系统在可预测性 与适应性之间的平衡。
- 协作需要共享上下文: 智能体要高效协同,既需要共享计划 (Multi-Agent Planning),也需要共享知识池(Knowledge Sharing),从而使系统能够随时间作为整体持续改进。
- 处理分歧的协议不可或缺: 为避免混乱与死锁,系统必须具备结构化的竞争管理模式:用 Consensus 对事实达成一致,用 Negotiation 化解目标冲突,用 Conflict Resolution 处理直接对撞。
- 协同扩展到执行与环境: 有效协同不仅停留在抽象规划层,还必须落到具体动作上,例如管理"哪个智能体调用哪个工具"(Tool Routing),以及智能体如何在物理或逻辑空间中编组与排列(Formation Control)。
- 协同的演进式路径: 协同模式的选择与复杂度与系统成熟度直接映射。基础多智能体系统(Level 4)依赖集中式、可预测的模式(如 Supervisor);而高级与自纠错系统(Levels 5--6)则需要更动态、去中心化的模式(如 Negotiation、Consensus 与元智能体)来管理涌现行为。
通过审慎地应用这些协同模式,开发者能够构建出远强于各个智能体简单相加 的多智能体系统,使其能够以鲁棒、可扩展且智能的方式应对复杂的真实世界挑战。
在系统性地梳理了协调多个智能体行动的关键模式之后,我们已经具备了构建"集体解决复杂问题"的坚实基础:我们知道如何让它们进行规划、共享知识并化解冲突。
然而,在面向生产级、企业级环境时,仅仅"有效"还远远不够。我们还必须确保这些自治系统具备透明性 、可审计性,并能在严格的伦理与监管边界内运行。
在下一章中,我们将把重心从"协同"转向"问责",探讨使智能体系统值得信赖的关键模式。