在上一章中,我们详细介绍了使多个智能体能够协同工作的协调模式,通过结构化协作来处理复杂问题。我们已经具备了让智能体进行规划、共享知识并解决冲突的蓝图。然而,要让一个智能体系统超越原型、进入生产级企业环境,仅有"有效"还不够;它还必须同样"可信"。没有问责的自治就是负债。
这就引出了两个关键领域:可解释性 与合规性:
- 可解释性 关注让智能体的决策过程变得透明、可理解,回答一个关键问题:为什么智能体会这么做?
- 合规性 确保智能体的行为遵循复杂的外部监管要求与内部政策体系,回答同样重要的问题:我能否验证智能体是否遵守了规则?
为了在智能体系统中纳入这些能力,本章引入四种具体的架构模式:指令一致性审计(Instruction Fidelity Auditing) 、分形思维链嵌入(Fractal Chain-of-Thought, FCoT, Embedding) 、持久化指令锚定(Persistent Instruction Anchoring) 、以及共享认识记忆(Shared Epistemic Memory) 。
为了让这些模式尽可能实用,我们将采取一种"先看地图再启程"的方法。在深入每个模式的技术细节之前,我们会先给出一份面向落地的战略实施指南。
这份指南与我们的 GenAI 成熟度模型(GenAI Maturity Model) 对齐,提供一条路线图:随着系统从单一智能体演进为多智能体集群,对这些问责模式的需求会如何不断加深。先理解全局,你就能更好地把握每个具体模式在体系中的位置,以及它为何是构建可问责、生产级智能体系统所必需的。
实施可解释性与合规性模式的战略指南
本章中的这些模式不仅是一套工具箱;随着组织的智能体系统日趋成熟,它们的应用会不断加深。它们对于一个复杂的单智能体固然有价值,但对于治理多智能体集群内部错综复杂的交互则变得绝对必要。下表展示了:当系统从单智能体架构走向多智能体架构时,这些模式的应用如何演进。
| 架构维度 | Level 5(单智能体系统)中的应用 | Level 6(多智能体系统)中的应用 |
|---|---|---|
| 主要目标 | 确保单个自治智能体可问责,其复杂推理可审计。 | 确保协作式智能体系统整体与顶层目标对齐,并在集体层面保持可靠性。 |
| 指令一致性审计 | 用于在单个智能体采取关键行动之前审计其最终输出。 | 用于审计智能体之间的交接(handoffs),确保层级链路上的每一步都保持指令一致性。 |
| 分形思维链嵌入 | 支持单智能体的内部自我纠错,使其能改进自身多步推理过程。 | 同时支持内部自我纠错与智能体间反思(inter-agent reflectivity) :智能体可基于同伴的推理来修订计划。 |
| 持久化指令锚定 | 在长链路、多步骤任务中,让单智能体持续聚焦于核心目标与约束。 | 对于确保原始指令与约束能够穿越多智能体深层级传递至关重要。 |
| 共享认识记忆 | 对单智能体相对没那么关键,但可用于记录状态或与人工监督者共享上下文。 | 对跨智能体协作是必需的:它成为系统的"中枢神经",提供整个系统依赖的"事实基线(ground truth)"。 |
表 6.1 ------ 将可解释性与合规性模式映射到 GenAI 成熟度模型
有了这份战略层面的背景,我们就可以开始逐一展开这些提供保障的具体模式。我们将从一种关键的外部验证层模式开始:它作为必要的检查点,用于确保智能体的行动与其被赋予的指令完全对齐。
指令忠实度审计(Instruction Fidelity Auditing)
在分层的多智能体系统中,高层智能体通常会把子任务委派给专门化的下属智能体。尽管这些智能体被设计为优化各自的局部任务,它们仍可能在无意中误解或忽略高层约束。这会导致"静默失败"(silent failures):子任务看起来成功完成了,但整体结果却与最初的业务意图不一致。
为防止这种情况,指令忠实度审计(Instruction Fidelity Auditing) 模式引入了一个验证层,确保智能体的行动严格遵循其收到的原始指令。
背景(Context)
一个多智能体系统,其中监督智能体将任务委派给一个或多个执行(worker)智能体。整个操作的成功,取决于执行智能体是否严格遵守原始指令中所规定的全部约束。
问题(Problem)
系统如何确保:一个自治智能体在优化其局部子任务的同时,仍能与原始高层指令与全局约束保持严格对齐,从而避免那种整体目标被漏掉却不易察觉的"静默失败"?
解决方案(Solution)
指令忠实度审计模式引入一个专门的审计智能体(auditor agent) ,作为自动化检查点(automated checkpoint)。审计者的职责不是执行任务,而是将执行智能体的输出与其收到的原始指令进行对比。
在动作最终落地之前,它会验证初始指令中的所有约束与目标是否都已满足。这就创建了一个显式的验证层,用于强化可追责性并防止指令漂移(instruction drift)。
示例:审计电商折扣的应用(Example: Auditing an e-commerce discount application)
某电商平台使用 SupervisorAgent 来处理客户的折扣请求。监督者必须确保 DiscountAgent 正确执行公司的折扣策略:
- SupervisorAgent 目标:确保客户请求被正确处理,并符合业务规则
- DiscountAgent 目标:高效地把指定折扣应用到客户订单上
- ComplianceAuditAgent 目标:验证其他智能体采取的动作是否符合原始指令中的全部约束
审计工作流如下展开:
- 指令(Instruction) :
SupervisorAgent生成一条精确指令:为用户'user123'的订单#5678应用 15% 的'WELCOME'折扣,但只有在这是他的首单时才可应用。 - 委派与执行(Delegation and execution) :该指令被发送给
DiscountAgent。它只关注主要动作并应用了 15% 折扣,返回成功消息:{"status": "SUCCESS", "action": "15% discount applied to order #5678"}。该智能体忽略了对"首单"约束的检查。 - 审计(Audit) :在交易最终确认前,
SupervisorAgent将原始指令与DiscountAgent的输出发送给ComplianceAuditAgent进行验证。 - 验证(Verification) :
ComplianceAuditAgent使用工具查询客户数据库,发现'user123'有多笔历史订单。 - 裁决(Verdict) :审计者返回失败结论并给出清晰原因:
{"audit_status": "FAIL", "reason": "Worker agent failed to check the 'first order' constraint. User 'user123' is not a new customer."}。 - 处置(Resolution) :
SupervisorAgent收到失败结果后,撤销DiscountAgent已应用的折扣,并向用户发送适当提示,从而避免一次策略违规。
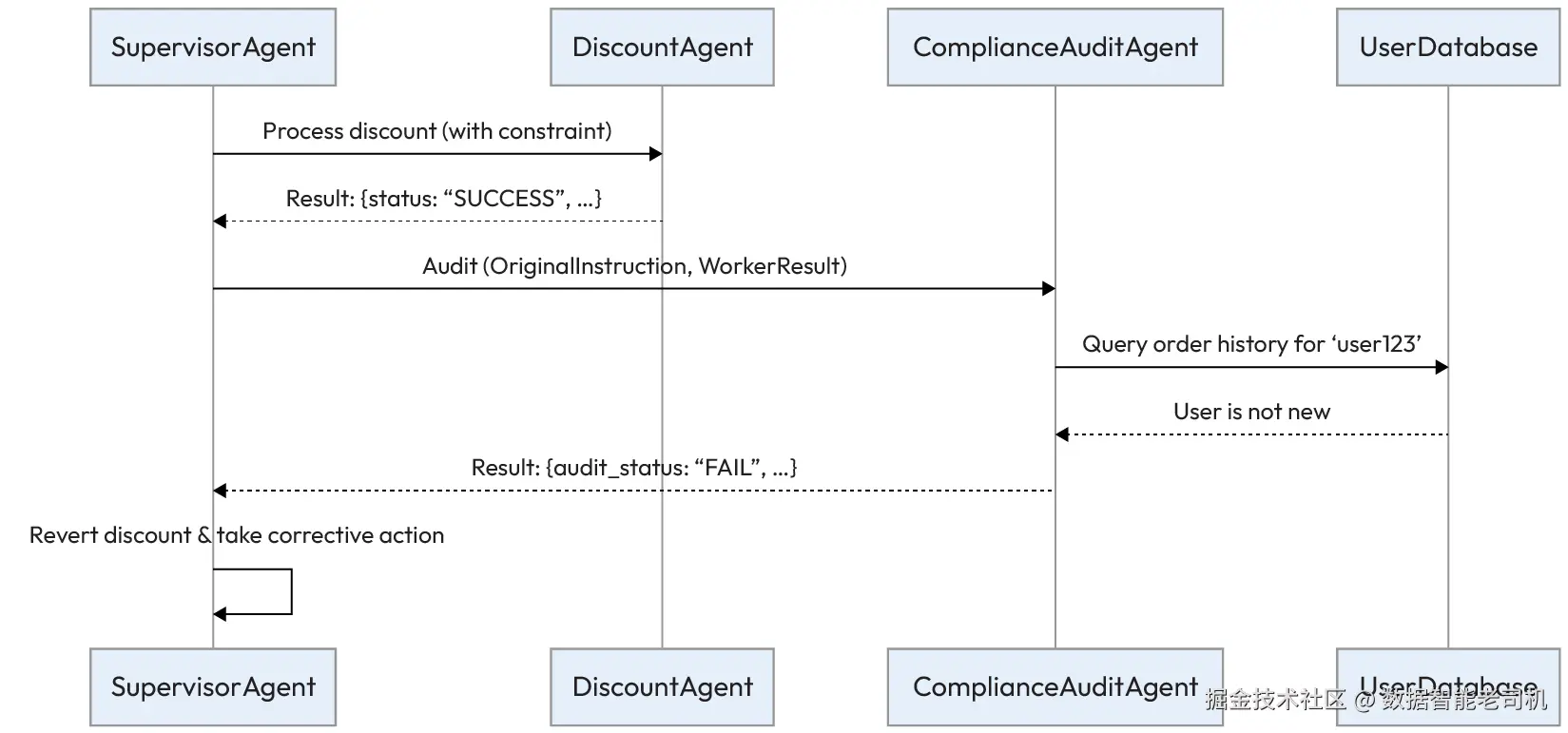
图 6.1 ------ 指令忠实度审计工作流(Instruction Fidelity Auditing workflow)
这个过程确保:即使某个专门化智能体走了"捷径",系统的完整性仍能由独立的审计层来维持。
示例实现(Example implementation)
下面的示例代码展示了指令忠实度审计模式的一种概念性实现。在这个场景中,我们看到 SupervisorAgent 负责编排工作流,确保 DiscountAgent 的输出会被传递给 ComplianceAuditAgent 做一次强制性的验证检查,然后交易才会最终落地。
python
class SupervisorAgent:
def handle_request(self, user_request):
original_instruction = (
"Apply a 15% 'WELCOME' discount for user 'user123', "
"but only if this is their first order."
)
# Delegate to worker agent
worker_result = DiscountAgent().run(instruction=original_instruction)
# Delegate to auditor agent for verification
audit_verdict = ComplianceAuditAgent().run(
original_instruction=original_instruction,
worker_output=worker_result
)
if audit_verdict.get("audit_status") == "PASS":
print("Action is compliant. Finalizing order.")
# ... logic to finalize the order ...
return "Order Finalized"
else:
print(
f"Action failed audit. Reverting. Reason: "
f"{audit_verdict.get('reason')}"
)
# ... logic to revert the action and handle the error ...
return "Action Reverted"
class DiscountAgent:
def run(self, instruction):
# This agent incorrectly focuses only on applying the discount
print("DiscountAgent: Applying 15% discount as instructed.")
return {
"status": "SUCCESS",
"action": "15% discount applied to order #5678"
}
class ComplianceAuditAgent:
def run(self, original_instruction, worker_output):
# In a real system, this would use an LLM or other tools
# For this example, we simulate the logic
is_first_order = self.check_customer_history("user123")
if "first order" in original_instruction and not is_first_order:
return {
"audit_status": "FAIL",
"reason": (
"Worker agent failed to check the 'first order' constraint. "
"User 'user123' is not a new customer."
)
}
else:
return {
"audit_status": "PASS",
"reason": "Action is compliant with all instructions."
}
def check_customer_history(self, user_id):
# Simulate a database lookup
print(f"ComplianceAuditAgent: Checking order history for {user_id}.")
return False # Simulate that the user has previous orders后果(Consequences)
优点(Pros):
- 可追责性与可解释性(Accountability and explainability) :该模式为合规性建立了一个显式检查点。审计者给出的论证/理由会生成清晰、可审计的轨迹,解释决策如何以及为何被验证,从而提升系统透明度。
- 可靠性(Reliability) :它能主动减少"静默失败"------即子任务局部成功但整体目标被遗漏的情况,从而让系统更健壮、更可预测。
缺点(Con):
- 性能开销(Performance overhead) :增加审计层会引入额外的延迟与计算成本,因为每次检查都可能需要额外的工具调用或 LLM 调用。这形成速度与可靠性之间的直接权衡。
实施建议(Implementation guidance)
在实现该模式时,应谨慎选择最需要审计的关键节点 。在每一步都加审计会严重影响性能。应聚焦于那些误解风险或策略违规风险最高 的交接点(handoffs)。目标是在严格合规 与可接受的系统延迟之间取得平衡。
虽然指令忠实度审计模式为智能体输出提供了关键的外部检查,但它仍是一种被动(reactive)措施。要构建真正健壮的系统,我们还需要智能体对维持对齐保持主动性(proactive) 。FCoT Embedding 模式通过将自我纠错能力直接嵌入到智能体自身的推理过程中来实现这一点。
分形思维链嵌入(Fractal Chain-of-Thought Embedding)
虽然标准的思维链(CoT)能让智能体进行顺序推理,但在动态的多智能体环境中,它往往过于僵硬。在这类系统里,智能体必须协同计划、适应新信息,并基于他人的反馈修正自身推理。传统 CoT 及其变体缺乏实现这种递归修订 与反思式协同的机制。
FCoT 模式通过将智能体的推理结构化为一个递归的、多层级框架来应对这一点,从而实现动态自我纠错,并在协作任务中获得更好的对齐效果。
背景(Context)
一个多智能体系统被分配到一个需要协作推理与适应的复杂问题。随着系统中其他智能体提供新的或相互冲突的数据,某个智能体最初的结论可能会失效,因此需要一种动态方式来修订先前的推理步骤。
问题(Problem)
如何组织智能体的推理过程,使其能够进行动态自我纠错、与其他智能体的推理同步,并在多个细节层级上进行分析,从而克服传统 CoT 方法静态且孤立的特性?
解决方案(Solution)
FCoT 模式把智能体的推理过程构造成一个递归且多尺度(multi-scale)的框架。不同于静态的线性链条,FCoT 将推理组织为可自洽的单元(self-contained units),并可被递归地细化。这使得智能体能够基于新证据修正过去的结论,并将分析适配到不同的细节层级。
该模式基于若干核心原则运作:
- 递归自我纠错(Recursive self-correction) :推理由一个目标函数引导,该目标函数在最大化洞见的同时最小化错误,从而形成持续的自我纠错闭环
- 动态上下文孔径(Dynamic context aperture) :智能体可以扩大或缩小关注范围------放大以进行细致分析,或缩小/拉远以纳入来自其他智能体的更广泛上下文
- 智能体间反思性(Inter-agent reflectivity) :智能体被设计为能够评估并反思其他智能体的推理过程,从而实现更好的对齐与更智能的委派
- 时间再锚定(Temporal re-grounding) :更早的推理步骤可以基于更新证据被正式修订,从而形成一个动态且可审计的思考过程,而不是静态的、只追加(append-only)的日志
为说明这一概念,请查看下图:
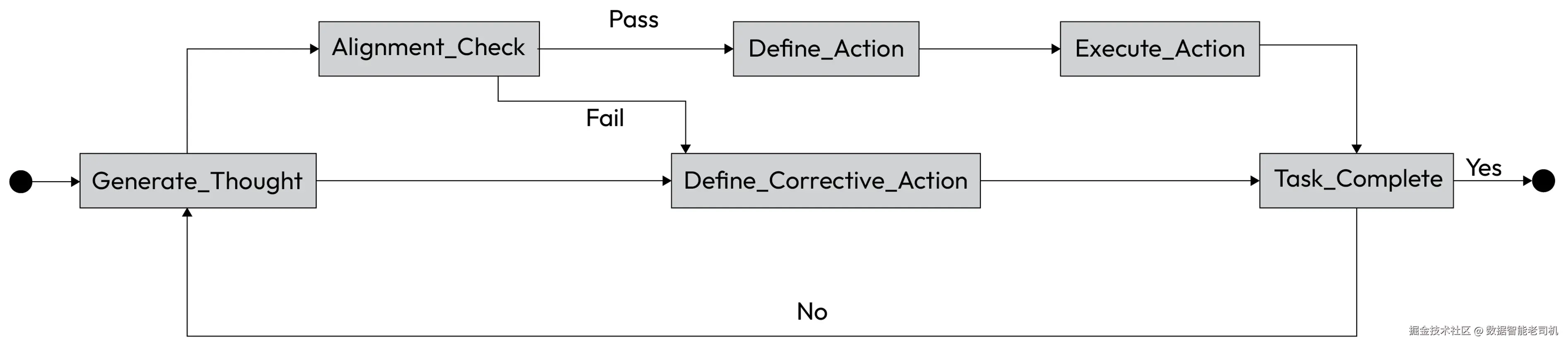
Figure 6.2 -- FCoT internal reasoning loop
示例:协作式研究综合(Example: Collaborative research synthesis)
一个 AI 系统被要求使用一组专门化智能体,针对 "climate-resilient urban design(气候韧性城市设计)" 生成一份文献综述:
- SynthesizerAgent goal:领导项目,并将各专家智能体的发现综合成一份连贯的最终报告
- ClimateScienceAgent 与 MaterialSustainabilityAgent goals:研究各自专业领域,并提供专家级摘要
使用 FCoT 的协作推理过程如下展开:
- 初始研究(Initial research) :每个专家智能体生成各自独立的摘要。
MaterialSustainabilityAgent基于其初始数据输出报告,强调 hempcrete(麻秸混凝土/麻纤维混凝土)的收益。 - 智能体间反思(Inter-agent reflection) :
SynthesizerAgent分享这些摘要。ClimateScienceAgent分析 hempcrete 的建议后指出:在沿海城市的高湿环境下,该材料的结构完整性可能会受损。 - 时间再锚定(Temporal re-grounding) :FCoT 框架促使
MaterialSustainabilityAgent基于这一新约束修订其原始评估。其最初推理被正式纠正为:"Hempcrete 是一种可行的可持续材料,但在高湿环境下若无专门处理可能会降解。" 这是一种对过去结论的直接修订,而不仅仅是追加新信息。 - 粒度控制(Granularity control) :
SynthesizerAgent起初以段落粒度整合洞见;随后将关注点调整到文档级视角,确保最终报告呈现连贯的叙事结构,而不是零散事实的堆叠。
下面的流程图展示了 FCoT 的过程:智能体生成一个想法,将其与目标与外部反馈对照检查,然后要么定稿,要么递归细化。
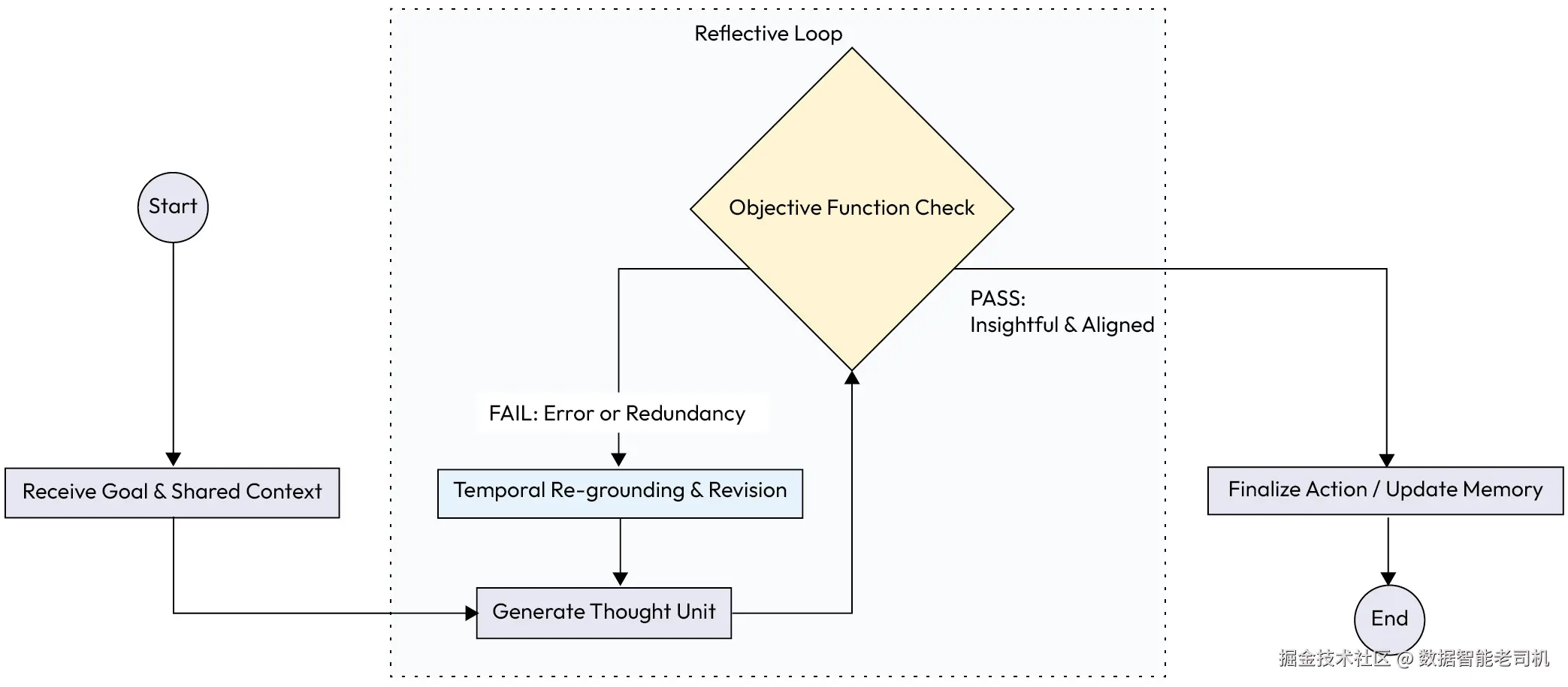
Figure 6.3 -- FCoT use case example
示例实现(Example implementation)
FCoT 通常通过一个更复杂的提示词模板(prompt template)来实现,用于引导 LLM 走完递归与反思步骤。它迫使模型将思考外显,把它与约束进行核对,并显式决定是继续推进还是修订:
ini
# Conceptual prompt template for an agent using FCoT
FRACTAL_COT_PROMPT_TEMPLATE = """
**Overall Goal:**
{original_instruction}
**Shared Context & Peer Agent Summaries:**
{context_from_shared_memory}
**My Previous Reasoning Steps (Thought Units):**
{summary_of_my_previous_reasoning}
**My Next Step:**
1. **Thought:** Based on the goal and all context, what is my next thought or hypothesis?
[LLM generates its next thought here...]
2. **Self-Correction Check (Objective Function):**
- **Objective:** Does my thought maximize new insight and align with the Overall Goal?
- **Constraint:** Does it conflict with any facts in the Shared Context or my previous reasoning? Does it introduce redundancy?
- **Verdict & Justification:** [LLM must analyze and justify its thought here...]
3. **Action / Revision:**
- **If Verdict is PASS:** State the action to take (e.g., call a tool, write to memory).
- **If Verdict is FAIL:** State the corrective action. This may involve revising a *previous* thought unit (Temporal Re-grounding).
[LLM generates its action or revision plan here...]
"""后果(Consequences)
优点(Pros):
- 可靠性与自我纠错(Reliability and self-correction) :该框架最大的优势在于能实现实时的、自我纠错式推理。智能体可以捕捉并修复自身的不对齐,从而得到更健壮、更可靠的结果。
- 可解释性(Explainability) :显式的自我纠错检查与时间再锚定,会生成透明且可审计的轨迹。人们不仅能看到智能体做了什么决定,还能看到它如何、以及为何改变了主意。
缺点(Con):
- 复杂度与开销(Complexity and overhead) :FCoT 的实现复杂度高于标准 CoT。它需要一个更成熟的编排层来管理共享上下文并触发反思循环,这会增加延迟与 token 成本。
实施建议(Implementation guidance)
实现 FCoT 需要一个健壮的编排层,能够管理共享记忆、触发反思循环,并处理递归更新。
应先定义清晰的自我纠错目标函数。注意递归检查带来的额外延迟与 token 成本,并把该模式用在那些复杂且高价值的任务上------在这些任务中,正确性与适应性比纯粹速度更重要。
FCoT 为智能体提供了强大的内部推理与自我纠错框架。然而,即便是最精密的推理,也可能在系统级故障中失效,例如上下文丢失或指令被遗忘。
为此,我们将把视角从智能体的内部思考过程,转向跨工作流的指令管理方式。在下一节,我们将探讨基础模式 Persistent Instruction Anchoring,它确保核心目标无论对话多长、多复杂,都能始终"置顶"(front and center)。
持久指令锚定(Persistent Instruction Anchoring)
在长链路、分层的智能体链条中,来自顶层编排器(orchestrator)的初始指令通常会被放在上下文的开头。随着下游智能体不断加入各自的推理与数据,这条关键指令会被挤到上下文窗口的中部。
LLM 往往会在这种"中间丢失(lost in the middle) "问题上表现不佳:它们会对不位于提示词最开头或最末尾的信息赋予更低的权重。
持久指令锚定(Persistent Instruction Anchoring) 模式通过使用特殊标签让关键指令更醒目,确保下游智能体不会忘记它们,从而解决这一问题。
背景(Context)
在一个深层、分层的多智能体系统中,初始指令沿着智能体链向下传递。随着每个智能体加入自己的推理与数据,上下文窗口不断增长,原始指令会被进一步推离那些高优先级的位置(开头与结尾)。
问题(Problem)
系统如何确保:当上下文窗口变得更长、更杂乱时,关键的高层指令与约束不会被下游智能体遗忘或忽略?如果没有一种机制来对抗模型天然的近因偏置(recency bias),就可能逐渐发生"指令漂移(instruction drift)",使最终输出偏离最初意图。
解决方案(Solution)
持久指令锚定模式确保关键指令无论处在上下文的哪个位置,都能保持显著(salient)。其做法是把高优先级目标或约束嵌入到语义上显著的标签 中(例如 <CRITICAL_INSTRUCTION>、[GOAL]、#DO_NOT_FORGET:)。这些"锚点(anchors)"会沿着链条传递,并被设计为让 LLM 易于识别,从而在工作流的每一步都有效提醒其核心目标。
示例:在财务报告中维持约束(Example: Maintaining constraints in financial reporting)
某财务报告系统使用一组智能体生成季度总结。系统必须确保整个过程中始终遵守一项严格的法律约束:
- ReportingSupervisor goal:生成 Q3 财务摘要,但不得包含任何违法的前瞻性陈述(illegal forward-looking statements)
- DataExtractionAgent goal:从内部数据库提取 Q3 的特定财务数据
- SummarizationAgent goal:基于提供的财务数据生成叙事性摘要
该工作流通过一个锚点来防止指令漂移:
- 指令与锚定(Instruction and anchoring) :
ReportingSupervisor智能体用一个严格的否定约束来定义任务,并将其框定为锚点:
"生成 Q3 财务表现摘要。PERSISTENT_GOAL: [NO_FORWARD_LOOKING_STATEMENTS]"。 - 委派(Delegation) :监督者将任务的第一部分委派给
DataExtractionAgent,并在新指令中一并传递带锚定的约束。 - 处理与交接(Processing and handoff) :
DataExtractionAgent完成任务后,把发现交给SummarizationAgent。它传递的上下文同时包含提取的数据与持久目标锚点:
"Data: {revenue: 10M, profit: 2M}. PERSISTENT_GOAL: [NO_FORWARD_LOOKING_STATEMENTS]. Please summarize this." - 最终输出(Final output) :此时
SummarizationAgent的提示词里,关键指令就紧贴在它需要处理的数据旁边。其 LLM 核心更可能看到并遵守该否定约束,避免加入关于 Q4 表现的推测性措辞,从而防止策略违规。
下图对比了两种工作流:一种没有锚定,指令会丢失;另一种有锚定,指令始终突出,从而保证输出对齐。
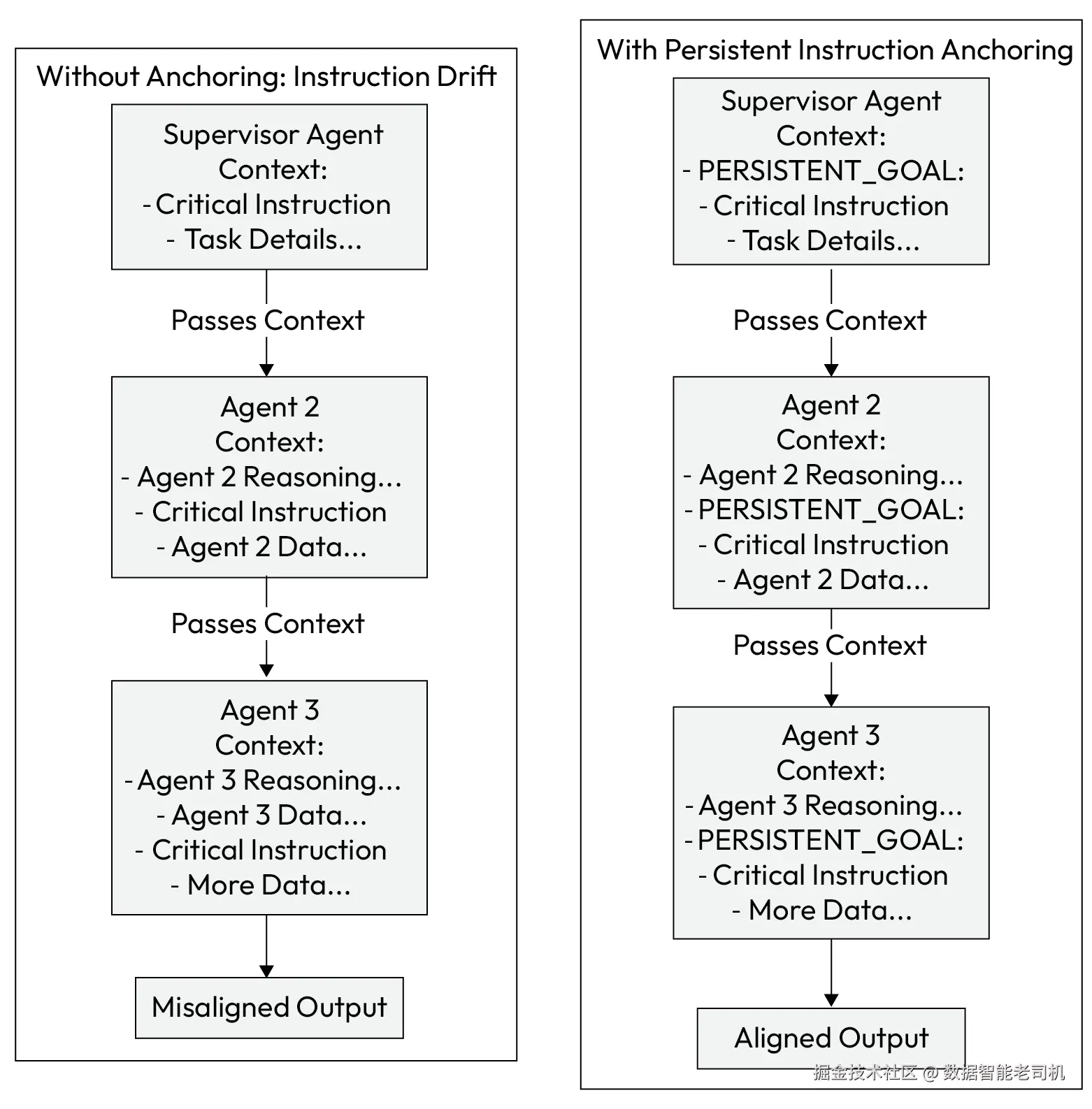
Figure 6.4 -- Persistent Instruction Anchoring workflow
示例实现(Example implementation)
实现方式是在智能体链条中传递带锚定的指令字符串:
python
class ReportingSupervisor:
def generate_report(self):
# The critical constraint is defined once and anchored
anchored_instruction = "PERSISTENT_GOAL: [NO_FORWARD_LOOKING_STATEMENTS]"
print(f"Supervisor initiated process with anchor: {anchored_instruction}\n")
# Delegate to the first agent
data = DataExtractionAgent().run(anchored_instruction)
# Delegate to the second agent, passing the data and the same anchor
summary = SummarizationAgent().run(data, anchored_instruction)
print("\n--- Final Report Summary ---")
print(summary)
print("--- End of Report ---")
class DataExtractionAgent:
def run(self, instruction):
print(f"DataExtractionAgent received instruction: {instruction}")
# Extracts data from a source...
extracted_data = "{revenue: '10M', profit: '2M'}"
print("DataExtractionAgent completed its task.")
return extracted_data
class SummarizationAgent:
def run(self, data, instruction):
# The LLM prompt includes both the data and the anchored instruction
# ensuring the constraint is visible at the point of generation.
prompt = f"""
Summarize the following financial data.
Data: {data}
{instruction}
"""
print(f"\nSummarizationAgent is using the final prompt for the LLM.")
# Simulate LLM call that adheres to the constraint
return "The company's Q3 performance showed a revenue of $10M with a profit margin of 20%."
# Execute the workflow
supervisor = ReportingSupervisor()
supervisor.generate_report()后果(Consequences)
优点(Pros):
- 可靠性(Reliability) :该模式显著提升了对上游指令的召回能力,减少指令漂移,确保下游智能体始终与主要使命保持对齐。
- 可解释性(Explainability) :锚定指令在智能体间消息中的存在,为关键约束如何在整个工作流中被保持提供了清晰、可审计的轨迹。
缺点(Con):
- 提示词开销(Prompt overhead) :它会给提示词增加轻微的额外负担,并且要有效,需要系统内所有智能体都采用一致的模板化结构。
实施建议(Implementation guidance)
为锚点建立一个标准化格式(例如 PERSISTENT_GOAL: [...] 或 <CONSTRAINT>...</CONSTRAINT>),并确保在系统内所有智能体中一致使用。这样,指令就能被可靠地解析,并在链条的每一步被重新插入,从而最大化其对 LLM 的可见性。
持久指令锚定模式提供了一种基础技术,通过确保单个智能体记住其目标来防止指令漂移。
然而,记住指令只是战斗的一半。在协作环境中,智能体还需要共享对当前现实的动态理解。比如,当某个智能体发现一条关键信息------服务器宕机或库存变化------我们如何确保团队其他成员能立刻知晓,而不需要无休止地传递消息?
这就引出了 Shared Epistemic Memory 模式,它将我们从个体专注带向集体同步。
共享认知记忆(Shared Epistemic Memory)
在单智能体系统中,"记忆"往往只是对话历史,有时也被称为会话记忆(session memory)或短期记忆(short-term memory)。然而,在多智能体集体中,依赖各自独立的上下文窗口会产生一种"巴别塔(Tower of Babel)"效应:如果一个智能体知道服务器宕机了,但另一个仍认为它在运行,那么它们的协同行动就会失败。
共享认知记忆(Shared Epistemic Memory) 模式通过在个体智能体上下文窗口之外建立一个单一、可变(mutable)的真相来源(source of truth) 来解决这个问题,确保整个集体对世界状态有相同的理解。
背景(Context)
一个多智能体系统,其中智能体各自拥有本地记忆并接收不同任务。某个智能体做出的观察(例如某个工具输出或状态变化)可能不会自然地被其他智能体获得,从而导致基于碎片化、不完整或不一致信息的决策。
问题(Problem)
如果缺乏一个统一且可演化的真相来源,层级体系中的智能体很容易发生不对齐。某个智能体可能基于一条新数据更新了自己的理解,但如果这一"事实"没有被传播,其他智能体就可能在过时的假设上继续运行。
这种不对齐源于三股核心力量:
- 知识碎片化(Fragmented knowledge) :每个智能体的"世界观"都受限于其本地上下文
- 有损通信(Lossy communication) :通过漫长的对话链传递状态,经常会导致细微差别被丢失
- 缺乏"真实基准"(Lack of "ground truth") :没有一个权威参考点用来核对任务的规范状态(canonical state)
解决方案(Solution)
共享认知记忆模式建立一个全局"草稿板(scratchpad)"或中心化记忆模块,使特定工作流中的所有智能体都能对其进行读写。
这份共享记忆充当集体的、权威的真相来源。它确保所有智能体------无论位于层级中的哪个位置------都基于同一组事实与假设运行。这也是诸如 "chain-of-agents" 框架等架构的关键特性,使系统即使在个体智能体进行孤立推理任务时也能保持一致性(coherence)。
示例:供应链中断(Example: Supply chain disruption)
一个多智能体系统管理某公司的全球供应链。系统依赖三个智能体:MonitoringAgent(新闻源)、LogisticsAgent(货运追踪)以及 CustomerNoctificationAgent(客户沟通)。
共享记忆包含如下基线状态:
{"shipment_A1": {"status": "On Time"}, "shipment_B2": {"status": "On Time"}}
工作流如下推进:
- 事件检测(Event detection) :
MonitoringAgent发现关键航运枢纽出现强风暴的报道。它向共享记忆写入更新:SharedMemory.update({"event_log": ["Storm reported at Port X"]}). - 影响分析(Impact analysis) :
LogisticsAgent周期性读取共享记忆。看到新的事件日志后,它查询内部工具并确认shipment_B2的路线经过 Port X。它写入更具体的更新:SharedMemory.update({"shipment_B2": {"status": "Delayed", "reason": "Storm at Port X"}}. - 主动行动(Proactive action) :
CustomerNotificationAgent读取共享记忆,看到shipment_B2状态变为 "Delayed",立刻触发工具通知受影响客户,从而避免服务投诉。
如果没有这种模式,CustomerNotificationAgent 将不会意识到延误,直到人工介入或错过期限为止。
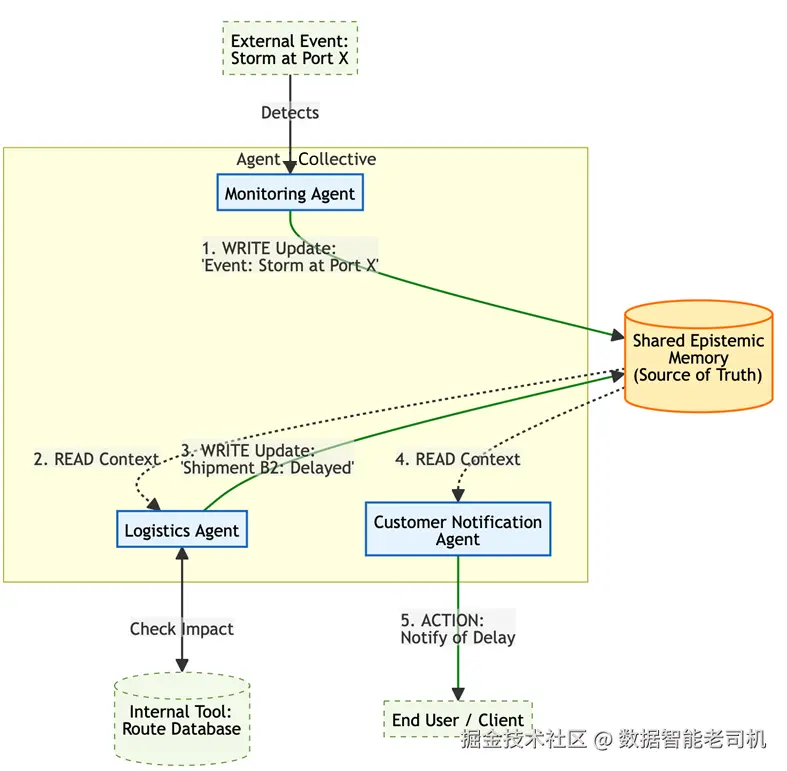
Figure 6.5 -- Shared Epistemic Memory Workflow
示例实现(Example implementation)
下面的示例代码展示了如何通过一个中心化状态管理器实现共享认知记忆模式。在这个供应链场景中,SharedMemory 类充当一个全局"草稿板"或单一真相来源。不同于个体智能体的上下文窗口(私有且短暂),这个共享模块允许专门化智能体以异步方式对共同状态进行读写,确保诸如风暴导致的延误这类关键更新能即时在整个集体中传播。
python
class SharedMemory:
def __init__(self):
self.store = {
"shipments": {
"shipment_A1": {"status": "On Time"},
"shipment_B2": {"status": "On Time"}
},
"event_log": []
}
def update(self, key, value):
print(f"[Memory Update] Setting {key} to {value}")
if key == "event_log":
self.store["event_log"].append(value)
else:
# Simplified recursive update for demo purposes
self.store["shipments"].update(value)
def read(self):
return self.store
class MonitoringAgent:
def run(self, memory):
# Simulate detecting external news
print("MonitoringAgent: Detected storm at Port X.")
memory.update("event_log", "Storm reported at Port X")
class LogisticsAgent:
def run(self, memory):
state = memory.read()
if "Storm reported at Port X" in state["event_log"]:
print("LogisticsAgent: Found affected shipment_B2.")
memory.update(
"shipments",
{"shipment_B2": {"status": "Delayed", "reason": "Storm at Port X"}}
)
class CustomerNotificationAgent:
def run(self, memory):
state = memory.read()
b2_status = state["shipments"]["shipment_B2"]
if b2_status["status"] == "Delayed":
print(
f"CustomerNotificationAgent: Alerting customer about delay due to {b2_status['reason']}."
)
# Orchestration
shared_mem = SharedMemory()
MonitoringAgent().run(shared_mem)
LogisticsAgent().run(shared_mem)
CustomerNotificationAgent().run(shared_mem)后果(Consequences)
优点(Pros):
- 一致性(Consistency) :该模式大幅降低语义漂移(semantic drift)。它确保所有智能体对任务与环境保持同步理解,从而产生一致的集体行为。
- 效率(Efficiency) :相比通过直接对话消息传递大量状态信息,它往往更高效------智能体只需在需要时拉取所需的特定上下文即可。
缺点(Cons):
- 中心化风险(Centralization risk) :如果未针对高可用与并发访问进行设计,共享记忆可能成为单点故障或性能瓶颈。
- 复杂性(Complexity) :它引入了共享状态管理的复杂度;当多个智能体同时尝试写入同一份数据时,需要机制处理潜在的竞态条件(race conditions)。
实施建议(Implementation guidance)
在实现共享认知记忆时,底层存储(backing store)的选择至关重要。对于生产系统,应避免使用进程重启就消失的简单内存字典。相反,应使用低延迟、持久化的键值存储(key-value stores),例如 Redis 或 Memcached。这些工具支持原子操作(atomic operations),这对于防止多个智能体同时更新状态时产生竞态条件至关重要。
此外,你必须实现 TTL(Time-to-Live) 或时间戳校验策略。在智能体系统中,信息"腐烂(rots)"得很快:五分钟前为真的服务器状态,现在可能就为假。强制采用一种 schema:每条记忆项都必须包含 timestamp 与 source_agent_id 字段。这样,下游智能体就能衡量数据的可靠性("这条事实已经 20 分钟了;我应该再验证一次"),而不是盲目信任它。
最后,应通过严格的、类型化(typed)的工具把这份记忆暴露给智能体(例如 update_order_status(id, status)),而不是提供一个泛化的 write_memory(text) 工具。这样可以避免共享记忆沦为堆放非结构化、不可解析文本的"垃圾场"。
有了共享认知记忆模式,我们确保智能体共享一致的世界观。不过,这个模式只是拼图的一块。真正的系统级可靠性并非来自某一个单独技巧,而是来自将多个模式组合成分层防御(layered defense)。
下一节将探讨这些单独策略如何协同工作。
面向系统级可靠性的模式组合(Pattern composition for systemic reliability)
尽管每个模式都针对某个特定故障点,它们的真正价值在于被组合成一个多层防御体系,用以抵御指令漂移与不对齐。它们并非互斥选择,而是健壮、生产级架构的互补组件。
一个具备韧性的分层系统可以通过组合以下模式来设计:
- Shared Epistemic Memory:充当真相的基础层。它确保所有智能体基于一组共同、同步的事实,以及对任务状态的共享理解来工作。
- Persistent Instruction Anchoring:充当使命的持续提醒。它确保无论任务多复杂、涉及多少智能体,核心目标与约束都不会在上下文"中间丢失(lost in the middle)"。
- Fractal CoT Embedding:充当内部、主动的自我治理机制。它是在智能体工作过程中持续发生的"过程改进",确保其内部推理始终与目标对齐。
- Instruction Fidelity Auditing:充当外部、被动的检查点。它是最终的质量保证闸门(QA gate),在结果被最终确认或传递到下一阶段之前,检查智能体工作输出,验证其是否完全符合原始指令。
例如,可以设计一个系统:SupervisorAgent 先把主要目标写入共享认知记忆;随后把子任务委派给 WorkerAgent,并传递一个持久指令锚点;WorkerAgent 使用 FCoT Embedding 持续让自己的思考过程与所分配的子目标对齐;当它产出最终输出后,再把输出交给一个独立的审计智能体,由其验证结果是否符合存储在共享记忆中的顶层原始指令。
通过组合这些模式,你就构建了一个具有多重、冗余安全护栏的系统。对于生产级可靠性而言,建议最佳实践是:至少同时实例化其中两到三种模式来进行分层防御设计。
现在,让我们来总结本章讨论过的所有内容。
总结(Summary)
本章聚焦于智能体 AI(agentic AI)系统在企业落地中两项关键要求:可解释性(explainability)与合规性(compliance) 。我们确立了这样一个结论:随着自治程度提高,为了建立信任并确保可靠性,对透明度与可追责性(accountability)的需求也会同步上升。我们还展示了:当系统从单智能体架构成熟演进到多智能体架构时,这些模式的应用会随之加深。
我们所要解决的核心挑战是指令漂移(instruction drift) ------在复杂、分层的智能体系统中,任务的原始意图会被稀释甚至丢失。为对抗这一点,我们引入了四个彼此互补的模式组合:Instruction Fidelity Auditing 、FCoT Embedding 、Persistent Instruction Anchoring 和 Shared Epistemic Memory。
关键要点如下:
- 信任需要透明(Trust requires transparency) :要让智能体在生产环境部署,其决策过程必须可审计(auditable)且可解释(explainable)。
- 防止指令漂移是关键(Preventing instruction drift is key) :在分层系统中,你必须主动在架构上设计安全护栏,确保原始目标不会被下属智能体遗漏或误解。
- 结合内部与外部检查(Combine internal and external checks) :最健壮的系统会同时采用用于内部自我纠错(FCoT)的模式,以及用于外部验证(auditing)的模式组合。
- 共享知识可防止不对齐(Shared knowledge prevents misalignment) :共享的真相来源(Shared Epistemic Memory)是基础设施,用于确保一组智能体能够一致、连贯地协同工作。
- 成熟度决定治理需求(Maturity dictates governance needs) :这些模式对单个复杂智能体(Level 4)同样有价值;但在多智能体系统(Level 5)中,它们将变得绝对必要,用于管理指令漂移并确保集体对齐------治理重点也会从个体可追责转向系统级可靠性。
通过策略性地组合这些模式,开发者可以设计出不仅更有效,而且更透明、可审计,并与其预期目标更一致的智能体系统。
既然我们已经确立了让智能体系统更可追责、更合规的一组模式,接下来就必须把注意力转向生产就绪性的另一个关键方面:抵御意外的能力。一个能够完美遵循指令、但在首次遇到错误或外部故障时就崩溃的智能体,并不真正健壮。
在下一章中,我们将探讨鲁棒性(Robustness)与容错(Fault Tolerance) 模式。这些模式提供了构建韧性系统所需的架构性解决方案,使系统能够优雅地处理错误、管理意外事件,并在单个组件失效时仍保持运行完整性(operational integrity)。