EmbeddingRWKV: State-Centric Retrieval with Reusable States
Authors: Haowen Hou, Jie Yang
Deep-Dive Summary:
以下是论文部分的中文总结:
EmbeddingRWKV: 以状态为中心的可重用状态检索
Haowen Hou* and Jie Yang* *Guangdong Laboratory of Artificial Intelligence and Digital Economy (SZ), Shenzhen, China *Shenzhen Yuanshi Intelligence Co., Ltd, Shenzhen, China houhaowen@gml.ac.cn
摘要
当前的检索增强生成 (RAG) 系统通常采用传统的两阶段流水线:首先通过嵌入模型进行初始检索,然后通过重排序器进行精炼。然而,由于阶段之间缺乏共享信息,这种范式效率低下,导致大量冗余计算。为了解决这个限制,我们提出了以状态为中心的检索(State-Centric Retrieval),这是一种统一的检索范式,它利用"状态"作为桥梁连接嵌入模型和重排序器。
首先,我们通过微调基于 RWKV 的大型语言模型来学习状态表示,将其转化为 EmbeddingRWKV,这是一个统一的模型,既作为嵌入模型,又作为提取紧凑、可重用状态的状态骨干。基于这些可重用状态,我们进一步设计了一个基于状态的重排序器 ,以充分利用预计算信息。在重排序过程中,模型仅处理查询令牌,从而使推理成本与文档长度解耦,实现了 5.4 × − 44.8 × 5.4 \times - 44.8 \times 5.4×−44.8× 的加速。此外,我们观察到保留所有中间层状态是不必要的;通过统一的层选择策略,我们的模型仅使用 25 % 25\% 25% 的层就能保持 98.62 % 98.62\% 98.62% 的完整模型性能。
大量的实验表明,以状态为中心的检索在显著提高整体系统效率的同时,实现了高质量的检索和重排序结果。代码可在我们的 GitHub 仓库中获取。
1 引言
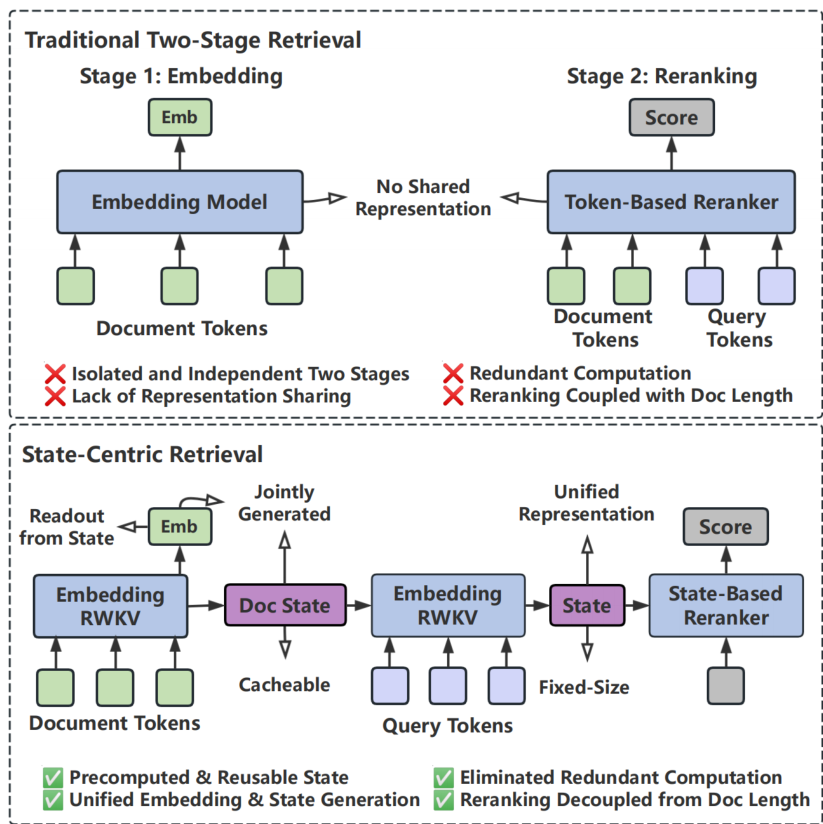
图1:传统检索与以状态为中心的检索。(上图)传统的两阶段检索是根本脱节的,由于重排序器重新编码完整的文档令牌而导致冗余计算。(下图)我们以状态为中心的检索通过共享的可重用状态将两个阶段统一为一个高效的系统。通过联合生成嵌入和紧凑状态,它实现了离线基于状态的重排序,将推理成本与文档长度解耦,实现了 5.4 × − 44.8 × 5.4 \times - 44.8 \times 5.4×−44.8× 的加速。
尽管两阶段检索范式有效,但其存在固有的效率限制,这些限制源于模型架构和流水线设计。首先,大多数最先进的嵌入模型和重排序器主要基于 Transformer 架构构建。尽管 Transformer 功能强大,但其计算复杂度随序列长度呈二次方增长,并且由于键-值 (KV) 缓存的线性扩展,内存消耗迅速增加,这使得它们在上下文长度增加时在计算和存储方面都变得越来越低效。其次,如图1所示,两阶段流水线本身由于阶段之间缺乏共享表示而引入了额外的低效率。由于嵌入模型和重排序器作为独立模块运行,它们独立地编码相同的文档,没有任何信息重用,导致大量的重复编码和冗余计算。
在这项工作中,我们提出了以状态为中心的检索(State-Centric Retrieval),这是一种从架构和流水线角度提高效率的新型检索范式。在模型架构层面,我们采用了 RWKV 模型,这是一种具有矩阵值隐藏状态的线性 RNN,其计算复杂度随序列长度呈线性增长,空间复杂度为常数。与基于 Transformer 的模型相比,RWKV 在计算和空间方面都显著提高了效率。在流水线层面,我们引入了一个统一的检索框架(图1),该框架利用可重用状态作为检索和重排序阶段的共享表示,从而实现信息重用并消除冗余计算。
我们通过两项协同贡献来实例化这种范式:学习可重用状态和有效利用这些状态进行重排序。
首先,我们观察到直接利用基于 RWKV 的大型语言模型来提取状态表示会导致显著的信息损失。为了解决这个问题,我们通过微调基于 RWKV 的大型语言模型来进行状态表示学习,将它们转化为统一模型,既作为嵌入模型,又作为提取有效状态表示的状态骨干。具体来说,我们采用单阶段领域感知课程策略来提高数据效率。这种方法在 MTEB 基准测试上取得了竞争性性能,同时仅需要传统多阶段流水线通常消耗的训练数据的 5 % 5\% 5%。重要的是,对于长度为 T T T 的序列,生成的状态仅需要完整 Transformer KV 缓存内存占用量的 32 / T 32/T 32/T,这使得大规模状态缓存成为可能。
其次,基于缓存的状态,我们设计了一个基于状态的重排序器 ,充分利用存储在状态中的预计算信息。在推理过程中,重排序器仅处理查询令牌和缓存的文档状态,将推理成本与文档长度完全解耦。此外,我们观察到保留所有中间层的状态是不必要的。通过统一的层选择策略,我们的模型仅使用 25 % 25\% 25% 的层就能保持 98.62 % 98.62\% 98.62% 的完整模型性能,从而进一步减少内存占用和推理延迟。
总而言之,我们的贡献如下:
- 我们提出了以状态为中心的检索,一个通过可重用状态协同嵌入式检索和重排序的统一框架,有效消除了冗余计算。
- 我们引入了一种领域感知课程策略 用于状态表示学习,仅使用标准训练数据的 5 % 5\% 5% 就达到了竞争性性能。
- 我们设计了一个基于状态的重排序器,显著降低了计算开销和内存占用,同时保持了高重排序有效性。
2 相关工作
**用于文本嵌入的两阶段检索。**大多数检索增强生成系统采用两阶段检索范式,其中密集嵌入模型用于初始检索,重排序器用于相关性精炼。文本嵌入模型已从早期的基于 BERT 的编码器发展到大型语言模型骨干,最近的系统如 NV-Emb、E5-Mistral 和 GTE 在 MTEB 等基准测试上取得了强大性能。尽管取得了这些进展,嵌入模型和重排序器通常被训练并部署为独立组件。每个阶段独立编码相同的文档,不共享表示或中间信息,导致整个检索流水线中重复编码和冗余计算。这种设计与我们以状态为中心的检索框架形成对比,我们的框架实现了检索阶段之间的表示重用。
**多阶段训练方案。**最先进的嵌入模型通常依赖于结合大规模预训练和后续微调阶段的多阶段训练流水线。这些流水线通常包括监督微调和难负例挖掘,以逐步优化特定于检索的表示。例如,BGE 采用 RetroMAE 预训练,然后进行对比学习和带有难负例的指令微调。Jina Embeddings 采用两阶段数据中心方法,结合大规模数据过滤和基于三元组的训练。Arctic-Embed 遵循从粗到精的策略,从十亿级预训练过渡到在精选数据集上的高精度微调。尽管有效,但现有的多阶段流水线依赖于海量数据集和复杂的训练工作流,这限制了数据效率。相比之下,我们的领域感知课程策略将训练整合到单个阶段,并减少了数据使用,从而实现了更简单、更数据高效的训练过程。
**从 Transformer 到线性 RNN。**大多数开创性的嵌入模型和重排序器都构建在 Transformer 架构上。然而,Transformer 面临固有的可扩展性问题:二次方计算复杂度和线性增长的 KV 缓存内存占用。这些限制使得长上下文检索和大规模重排序的成本高得令人望而却步。为了解决这个问题,我们的工作利用了 RWKV,它是具有矩阵值状态的线性 RNN 家族的成员。与 Transformer 不同,RWKV 实现了线性计算复杂度和常数空间复杂度,为密集检索提供了更高效的架构骨干,而不会牺牲复杂语义匹配所需的表达能力。
**具有矩阵值状态的线性 RNN。**虽然 Mamba 和 RWKV-4 等线性 RNN 将复杂度降低到 O ( N ) O(N) O(N),但它们通常由于将上下文压缩到固定大小的向量而导致状态容量差距。为了弥补这一差距,最近的进展集中于将隐藏状态扩展为矩阵。自 RWKV-5 和 RWKV-6 中明确过渡到矩阵值状态以来,该架构已展示出增强的维护丰富历史上下文的能力。最近,RWKV-7 通过动态状态演化机制进一步完善了这一点。通过采用这种架构,我们的框架能够缓存高容量状态,这些状态在整个检索流水线中既紧凑又具有高度代表性。
3 以状态为中心的检索
以状态为中心的检索将状态作为主要表示。因此,对状态进行精确定义是必要的,因为它构成了整个框架的基础,并直接影响模型架构和流水线设计。
3.1 背景:矩阵值状态
在循环模型中,状态总结了过去的输入,并作为上下文信息的载体。传统 RNNs 将状态表示为固定长度的向量,这限制了在长序列中可以保留的信息量。
矩阵值状态通过将循环状态表示为矩阵而非向量来泛化这种形式,从而允许模型维护更丰富、更结构化的记忆。形式上,给定一个矩阵值状态 S t S_{t} St 和当前输入 x t x_{t} xt,循环更新形式为:
S t = S t − 1 W t + v t k t ⊤ , ( 1 ) S_{t} = S_{t - 1}W_{t} + v_{t}k_{t}^{\top}, \quad (1) St=St−1Wt+vtkt⊤,(1)
其中 S t ∈ R d × d S_{t}\in \mathbb{R}^{d\times d} St∈Rd×d, W t ∈ R d × d W_{t}\in \mathbb{R}^{d\times d} Wt∈Rd×d,且 v t , k t ∈ R d v_{t},k_{t}\in \mathbb{R}^{d} vt,kt∈Rd 是从 x t x_{t} xt 计算出的列向量。在此形式下, S t S_{t} St 充当一个动态关联记忆,它增量地累积键和值的外积,同时通过 W t W_{t} Wt 有选择地保留或丢弃过去的信息。
在 RWKV-7 的情况下,过渡矩阵 W t W_{t} Wt 通过动态演化进一步完善,通常通过对向量 w t w_{t} wt 进行对角化并结合低秩更新来表达:
W t = d i a g ( w t ) − κ ^ t ( a t ⊙ κ ^ t ) ⊤ ( 2 ) W_{t} = \mathrm{diag}(w_{t}) - \hat{\kappa}{t}\big(a{t}\odot \hat{\kappa}_{t}\big)^{\top} \quad (2) Wt=diag(wt)−κ^t(at⊙κ^t)⊤(2)
其中 κ ^ t \hat{\kappa}{t} κ^t 和 a t a{t} at 是快速权重,它们增强了模型选择性更新其内部记忆的能力。
重要的是,矩阵值状态可以以恒定内存增量更新,而无需存储完整的令牌历史。这一特性允许
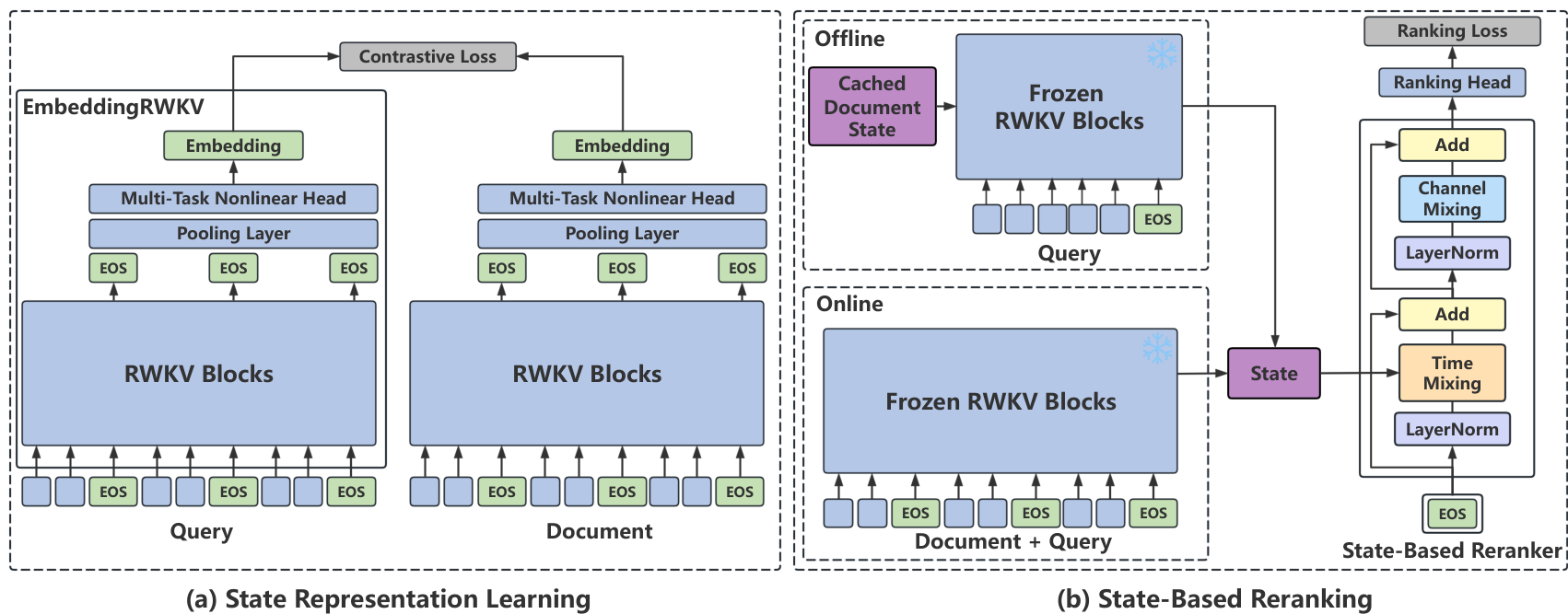
图2:(a) 状态表示学习:展示了"学习状态"的过程。(b) 基于状态的重排序:展示了通过直接重用缓存状态进行推理,从而避免冗余重新计算的"利用状态"范式。
模型以线性时间计算和常数空间复杂度处理任意长序列,同时保持强大的上下文建模能力。
3.2 状态表示学习
状态表示学习旨在将基于 RWKV 的语言模型调整为统一的骨干网络,能够同时产生高质量的嵌入和可重用状态。
**模型架构。**为了实现状态表示学习,我们引入了 EmbeddingRWKV,其架构如图 2(a) 所示。EmbeddingRWKV 由 RWKV 块、一个池化层和一个非线性头组成。多个序列结束 (EOS) 令牌被插入到输入序列中,并提取相应的输出表示。这些表示通过池化层进行平均,并通过非线性头投影以生成最终嵌入。
**训练和数据方案。**我们引入了一种领域感知课程策略,用于高效的状态表示学习。来自同一领域的数据样本共享相似的语义子空间,因此自然形成了对比学习的难负例。相比之下,跨异构领域随机混合的批次通常会产生易负例,提供有限的训练信号。
为了利用这一特性,我们以分布式方式按领域组织训练批次。具体来说,我们首先将训练数据集 D \mathcal{D} D 划分为领域特定的子集 { D 1 , D 2 , ... , D K } \{\mathcal{D}_1, \mathcal{D}_2, \ldots , \mathcal{D}_K\} {D1,D2,...,DK}。在 N N N 个 GPU 上的分布式训练期间,每个 GPU 处理一个从单个领域采样的微批次。在同一训练步骤中,不同的 GPU 被分配到不同的领域。
因此,同一领域内的样本在每个 GPU 的局部批次中自然形成难负例。这种简单的调度策略实现了有效的难负例训练,而无需显式挖掘。
**学习目标。**我们使用对比目标训练状态表示,称为损失 L s t a t e L_{\mathrm{state}} Lstate。我们采用标准的 InfoNCE 损失,包含批内负例。给定一个包含 B B B 个训练实例的批次,损失定义为:
L s t a t e = − 1 B ∑ i = 1 B log e s ( q i , d i + ) / τ Z i , ( 3 ) L_{\mathrm{state}} = -\frac{1}{B}\sum_{i = 1}^{B}\log \frac{e^{s(q_i,d_i^+)} / \tau}{Z_i}, \quad (3) Lstate=−B1i=1∑BlogZies(qi,di+)/τ,(3)
其中 s ( ⋅ , ⋅ ) s(\cdot , \cdot) s(⋅,⋅) 表示池化层和非线性头为查询和文档生成的嵌入之间的余弦相似度, τ \tau τ 是温度参数。归一化项 Z i = ∑ j = 1 B e s ( q i , d j ) / τ Z_i = \sum_{j = 1}^{B} e^{s(q_i,d_j)} / \tau Zi=∑j=1Bes(qi,dj)/τ 聚合了正对和所有批内负例的分数。
3.3 基于状态的重排序
基于状态的重排序旨在高效利用学习到的状态进行重排序。
**模型架构。**基于状态的 RWKV-Reranker 由 RWKV 块和一个排序头组成,如图 2(b) 所示。它以矩阵值状态作为输入,并输出相关性得分。使用基于状态的 RWKV-Reranker 有两种模式:离线模式和在线模式。
在离线模式下,文档状态 S d S_{d} Sd 被预计算并缓存。我们使用缓存的文档状态 S d S_{d} Sd 初始化 EmbeddingRWKV,然后仅将查询令牌 { x t q } t = 1 T q \{x_{t}^{q}\}{t = 1}^{T{q}} {xtq}t=1Tq 输入到冻结的 EmbeddingRWKV 中以获得更新后的状态 S ′ S^{\prime} S′。更新后的状态 S ′ S^{\prime} S′ 被输入到基于状态的重排序器中以生成相关性得分。
在在线模式下,文档和查询由相同的冻结 EmbeddingRWKV 共同处理,即时生成用于重排序的状态。除非另有说明,我们冻结 EmbeddingRWKV 中的所有 RWKV 块,仅训练基于状态的 RWKV-Reranker 的参数。
**重排序训练目标。**对于重排序任务,我们将相关性预测表述为二分类问题,并使用二元交叉熵 (BCE) 损失优化模型:
L r e r a n k i n g = − y log s + ( 1 − y ) log ( 1 − s ) , ( 4 ) L_{\mathrm{reranking}} = -\lefty\\log s + (1 - y)\\log (1 - s)\\right, \quad (4) Lreranking=−ylogs+(1−y)log(1−s),(4)
其中 y ∈ { 0 , 1 } y\in \{0,1\} y∈{0,1} 表示真实标签。 s = s ( q , d ) s = s(q,d) s=s(q,d) 表示基于状态的重排序器输出的查询-文档对的预测相关性概率。
**计算成本分析。**基于 Transformer 的重排序器依赖于查询和文档令牌之间的完全注意力,导致二次方的计算复杂度。这种成本随文档长度快速增长,成为长文档重排序的主要瓶颈。
相比之下,我们基于状态的重排序器缓存文档状态并在推理时仅处理查询令牌。这种设计将推理延迟与文档长度解耦,并实现了关于查询长度的线性时间计算。
**内存占用分析。**我们比较了使用 Transformer 的 KV 缓存和我们的矩阵值状态缓存表示的内存成本。它们的内存占用比例如下:
B y t e s t o k e n B y t e s s t a t e = 2 L H S T b L H S 2 b = 2 T S . \frac{\mathrm{Bytes}{\mathrm{token}}}{\mathrm{Bytes}{\mathrm{state}}} = \frac{2LHS^Tb}{LHS^2b} = \frac{2T}{S}. BytesstateBytestoken=LHS2b2LHSTb=S2T.
这里, L L L 表示层数, H H H 表示头数, S S S 表示每个头的状态维度, T T T 表示序列长度, b b b 表示每个元素的字节数。对于 RWKV-7, S = 64 S = 64 S=64,这个比率变为 T / 32 T/32 T/32。换句话说,Transformer 的 KV 缓存所需的内存是单个状态的 T / 32 T/32 T/32 倍。虽然 Transformer 的内存占用随序列长度 T T T 线性增长,但 RWKV 状态保持不变,使其在长文档重排序方面显著节省内存。
4 实验
4.1 检索实验和结果
我们使用对比学习在自建的开源数据集上训练了我们的嵌入模型 (EmbeddingRWKV)(详细信息见附录 C)。我们报告了模型在 MTEB 英语基准测试上的性能。
**EmbeddingRWKV 具有竞争力。**表 1 显示,EmbeddingRWKV 在三种模型规模(0.1B、0.4B 和 1.4B 参数)上均提供了强大的检索质量,并且性能随着模型容量的增加而单调提升。在基础规模方面,EmbeddingRWKV-0.1B 在 MTEB 英语基准测试上取得了具有竞争力的平均分数,与类似规模的广泛采用的开源基线模型持平或超越。在中等规模方面,EmbeddingRWKV-0.4B 进一步提升了性能,并与相同参数范围内的强大基于 Transformer 的嵌入模型保持竞争力。当扩展到 1.4B 参数时,EmbeddingRWKV-1.4B 在整体 MTEB 平均分上几乎与表现最佳的大型嵌入模型和商业 API 持平,同时在面向分类的子集上表现尤为出色,这表明学习到的状态表示有效地捕获了判别性语义结构。总的来说,这些结果表明基于 RWKV 的骨干网络可以作为 Transformer 模型的有力替代品,用于密集检索,而不会牺牲嵌入质量。
**课程训练具有数据效率。**表 2 比较了我们的单阶段领域感知课程训练与传统多阶段流水线(预训练后进行 SFT)。多阶段基线总共使用了 132.1M 训练样本,而我们的课程训练仅使用了 6.7M 样本(约 5%)。尽管数据量大幅减少且训练方案更简单,但经过课程训练的 EmbeddingRWKV 在 MTEB 英语基准测试上取得了比多阶段基线更高的性能,即课程训练 (6.7M) > 多阶段 (132.1M)。这些
Table 1: Comparison of embedding models on MTEB (English, v2). γ \gamma γ Taken from (Lee et al., 2025). For other compared models, the scores are retrieved from MTEB online leaderboard.
|-----------------------------------------------------------|------|-------|----------------|------------|-----------|-----------|-------|-------|
| Model | Size | Mean | Classification | Clustering | Reranking | Retrieval | STS | Summ. |
| e5-base-v2 (Wang et al., 2024a) | 109M | 62.67 | 75.48 | 45.20 | 45.13 | 49.67 | 80.64 | 34.26 |
| e5-base (Wang et al., 2023) | 109M | 61.79 | 75.20 | 43.77 | 44.86 | 47.70 | 80.70 | 33.38 |
| gte-base (Li et al., 2023a) | 109M | 63.90 | 75.04 | 47.74 | 47.17 | 51.90 | 82.17 | 30.90 |
| jina-embedding-b-en-v1 (Günther et al., 2023) | 110M | 59.76 | 72.06 | 39.95 | 46.98 | 46.38 | 80.00 | 27.15 |
| granite-embedding-english-r2 (Awasthy et al., 2025b) | 149M | 62.84 | 70.71 | 47.20 | 49.10 | 56.43 | 78.12 | 29.31 |
| granite-embedding-125m-english (Awasthy et al., 2025a) | 125M | 62.08 | 68.29 | 47.18 | 49.35 | 55.65 | 77.56 | 29.34 |
| nomic-embed-text-v1.5 (Nussbaum et al., 2024) | 137M | 62.20 | 75.71 | 47.55 | 46.01 | 47.97 | 78.70 | 28.56 |
| snowflake-arctic-embed-m-v1.5 (Merrick, 2024a) | 109M | 61.51 | 70.71 | 44.65 | 45.90 | 58.05 | 72.96 | 29.89 |
| mmlw-roberta-base (Dadas et al., 2023a) | 124M | 61.15 | 77.67 | 46.26 | 46.69 | 40.15 | 81.81 | 30.83 |
| EmbeddingRWKV-0.1B | 144M | 63.06 | 81.01 | 46.21 | 46.07 | 48.06 | 80.30 | 25.13 |
| SearchMap-Preview (Team, 2025) | 435M | 64.08 | 74.97 | 48.47 | 47.90 | 52.21 | 81.56 | 33.25 |
| bilingual-embedding-large (Thakur et al., 2024b) | 559M | 63.77 | 77.17 | 46.53 | 46.25 | 46.86 | 86.00 | 32.95 |
| mmlw-e5-large (Dadas et al., 2024) | 559M | 62.32 | 79.63 | 48.30 | 47.63 | 41.37 | 81.35 | 34.07 |
| gte-large (Li et al., 2023b) | 335M | 64.77 | 75.47 | 48.20 | 47.84 | 53.29 | 83.27 | 32.90 |
| snowflake-arctic-embed-l (Merrick, 2024b) | 335M | 62.04 | 69.59 | 45.70 | 44.71 | 59.04 | 75.42 | 20.38 |
| mmlw-roberta-large (Dadas et al., 2023b) | 434M | 61.80 | 79.66 | 47.89 | 47.56 | 39.69 | 81.20 | 34.97 |
| e5-large-v2 (Wang et al., 2024b) | 335M | 62.79 | 76.44 | 45.23 | 45.72 | 49.31 | 80.67 | 32.34 |
| EmbeddingRWKV-0.4B | 389M | 64.86 | 86.21 | 47.78 | 46.92 | 49.42 | 79.58 | 31.37 |
| sentence-crossant-alpha-v0.4 (Reimers and Gurevych, 2020) | 1B | 57.71 | 70.34 | 43.22 | 44.65 | 43.18 | 75.34 | 28.46 |
| gte-Qwen2-1.5B-instruct (Li et al., 2023c) | 1.5B | 67.20 | 85.84 | 53.54 | 49.25 | 50.25 | 82.51 | 33.94 |
| OpenAI Commercial APIs: text-embedding-3-large | - | 66.43 | - | - | - | - | - | - |
| Cohere Commercial APIs: cohere-embed-multilingual-v3.0 | - | 66.01 | - | - | - | - | - | - |
| EmbeddingRWKV-1.4B | 1.4B | 66.41 | 87.52 | 48.16 | 48.22 | 52.43 | 81.04 | 32.73 |
结果表明,课程训练提供了一种更强大、更数据高效的方式来学习可重用状态表示,这不仅改善了检索效果,还为后续的基于状态的重排序阶段提供了高质量的状态。
Table 2: Comparison of retrieval performance between standard Multi-stage training and Single-stage DomainAware Curriculum training. The curriculum method achieves higher scores using only ∼ 5 % \sim 5\% ∼5% of the baseline's total training data.
|---------------|----------|------|-------------|--------|--------|
| Model | Stage | Size | Sample Size | MTEB-E | MTEB-C |
| Multi-stage Training ||||||
| EmbeddingRWKV | Pretrain | 144M | 123.2M | 53.85 | 51.47 |
| EmbeddingRWKV | SFT | 144M | 8.9M | 59.60 | 54.37 |
| EmbeddingRWKV | Pretrain | 389M | 123.2M | 54.88 | 53.69 |
| EmbeddingRWKV | SFT | 389M | 8.9M | 60.85 | 55.17 |
| Single-stage Curriculum Training ||||||
| EmbeddingRWKV | SFT | 144M | 6.7M | 63.06 | 57.12 |
| EmbeddingRWKV | SFT | 389M | 6.7M | 64.86 | 58.68 |
4.2 重排实验与结果
我们冻结 EmbeddingRWKV 模型,并采用监督学习训练基于状态的 RWKV-Reranker。实验结果在 NanoBEIR、MTEB (English, v2) Retrieval 和 MTEB (Chinese, v1) Retrieval 数据集上进行报告。
状态表示学习是必要的。 一个自然的问题是,我们是否可以直接重用基础 RWKV 语言模型的状态进行重排,而无需进行面向检索的状态表示学习。表 3 的结果表明并非如此:使用基础 LM 状态初始化重排器在所有评估指标和基准上均持续表现不佳。我们将这种差距归因于训练目标的不匹配。重排需要细粒度的相关性匹配和检索特定的表示几何,而基础 LM 主要学习与检索监督不一致的生成式语言建模信号。因此,明确学习与检索对齐的状态表示对于有效的基于状态的重排至关重要。
Table 3: Comparison of state-based reranking performance using states generated by RWKV-7 LM and EmbeddingRWKV on NanoBEIR.
|----------------|------|-------|--------|---------|
| State Backbone | Size | MAP | MRR@10 | NDCG@10 |
| RWKV-7 LM | 190M | 48.58 | 59.37 | 54.78 |
| EmbeddingRWKV | 144M | 58.29 | 69.50 | 63.41 |
基于状态的重排是有效的。 在我们的设计中,一个核心问题是基于状态的机制与传统架构相比是否会损害排名质量。为了探究这一点,我们训练了一个参数规模(0.1B 参数)与我们提出的模型相同的标准 RWKV 单塔重排器。如表 4 所示,基于状态的重排器在 NanoBEIR、MTEB-E (eng, v2) 和 MTEB-C (cmn, v1) 上达到了与单塔基线相当的性能。此外,将模型从 90M 扩展到 1.3B 参数,性能呈现单调提升,验证了基于状态重排器良好的扩展行为。
我们还与三种基于 Transformer 的重排器进行了比较,包括 ModernBERT (Warner et al., 2024)、EuroBERT (Boizard et al., 2025) 和 Jina 重排器 (Wang et al., 2025)。总体而言,我们的基于状态的重排器与强大的单塔 Transformer 重排器相比,差距很小,并且在 NanoBEIR 基准测试中与这些 Transformer 基线保持了性能持平。
Table 4: State-Based Reranker performance on NanoBEIR (NDCG@10) and MTEB-E (English, v2) Retrieval, MTEB-C (Chinese, v1) Retrieval. Scores are scaled by 100 (higher is better).
|---------------|------|----------|-------------|-------------|
| Model | Size | NanoBEIR | MTEB-E-Retr | MTEB-C-Retr |
| EmbeddingRWKV | 0.1B | 59.10 | 48.06 | 57.26 |
| Traditional Single-Tower Reranker |||||
| RWKV-Reranker | 90M | 64.88 | 49.31 | 58.16 |
| EuroBERT | 210M | 47.38 | - | - |
| ModernBERT | 395M | 64.18 | - | - |
| Jina Reranker | 278M | 70.68 | - | - |
| State-Based Reranker |||||
| RWKV-Reranker | 90M | 63.41 | 47.78 | 58.42 |
| RWKV-Reranker | 317M | 68.60 | 53.22 | 63.60 |
| RWKV-Reranker | 1.3B | 71.58 | 56.44 | 66.30 |
基于状态的重排是高效的。 如图 3 所示,我们的离线基于状态的重排器比使用 FlashAttention-2 (Dao, 2023; Li et al., 2025) 的强大 Transformer 重排器实现了显著加速,文档长度从 512 512 512 增加到 4096 4096 4096 时,加速比从 5.4 × 5.4 \times 5.4× 提升到 44.8 × 44.8 \times 44.8×,同时还显著减少了 GPU 内存使用。其关键机制在于离线重排只处理查询 token 和缓存的文档状态;因此推理成本与文档长度无关。这种解耦反映在缩放曲线上:基于 Transformer 的重排器吞吐量随文档长度增加而迅速下降,而 RWKV 离线重排器在不同长度下几乎保持平坦。类似地,基于注意力机制的基线模型峰值 VRAM 使用量随文档长度急剧增长,而我们的方法由于状态大小恒定而保持稳定。此外,即使在在线设置中,基于状态的重排器也比基于 Transformer 的重排器更节省内存:其峰值 VRAM 随序列长度增长更慢,这与 RWKV 线性内存缩放的特性一致。不同模型大小的额外效率分析详见附录 B.1 和表 8。
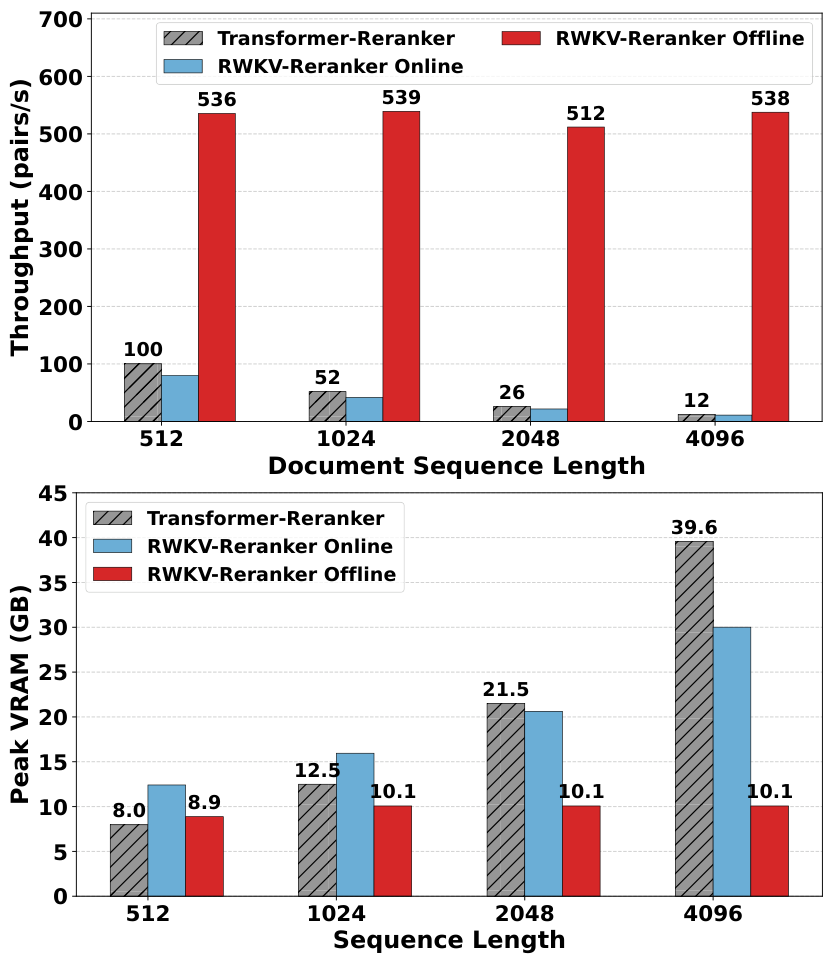
Figure 3: Performance benchmarking across various sequence lengths. Baseline: mxbai-renark-large-v2 (1.5B) (Li et al., 2025) with FlashAttention-2 vs. Ours: EmbeddingRWKV-1.4B + RWKV-Reranker-1.3B. Top: Throughput comparison (pair/s), where higher is better. Bottom: Peak VRAM usage (GB), where lower is better.
状态是冗余的。 一个重要的实际问题是需要缓存多少状态以及保留哪些层,即压缩边界在哪里。表 5 显示,层之间存在显著冗余:只保留一小部分层状态就能保留大部分的完整深度性能。例如,使用 50 % 50\% 50% 的层已经保留了 99.59 % 99.59\% 99.59% 的性能,即使是更激进地只选择少数均匀分布的层,也能达到 97.70 % − 98.62 % 97.70\% - 98.62\% 97.70%−98.62% 的相对性能。这些结果表明重排信号高度可压缩,重排信息分布在模型深度中,而非集中在单个层中。
重要的是,我们发现层选择比层数量更重要。在相同的三层预算下,顶层偏重的选择导致性能急剧下降( 85.99 % 85.99\% 85.99%),而均匀分布的选择则能将性能恢复到 98.62 % 98.62\% 98.62%。这表明有效的重排依赖于结合从早期到晚期层的多级信号。基于此观察,我们采用均匀步幅层选择作为我们状态缓存设计的默认策略。
Table 5: Ablation on state-based reranker layer selection strategies. Mean is the average of NanoBEIR, MTEB-ERet, and MTEB-C-Retr scores. Ratio indicates performance retention relative to the best configuration in the same model group. Uniform selection strategies (e.g., 1, 6, 10) significantly outperform contiguous top-layer strategies.
|-----------|--------|----------------------|-------|----------|-------------|-------------|-------|--------|
| Strategy | Layers | Layer Index | Size | NanoBEIR | MTEB-E-Retr | MTEB-C-Retr | Mean | Ratio |
| RWKV-Reranker-0.1B (Full Depth: 12 Layers) |||||||||
| Top-heavy | 3 | 9-11 | 23.1M | 56.94 | 38.86 | 50.07 | 48.62 | 85.99% |
| Uniform | 3 | 0, 5, 11 | 23.1M | 61.85 | 44.82 | 55.71 | 54.13 | 95.74% |
| Uniform | 3 | 1, 6, 10 | 23.1M | 62.35 | 48.05 | 56.88 | 55.76 | 98.62% |
| Top-heavy | 6 | 6-11 | 45.8M | 62.01 | 46.99 | 57.65 | 55.55 | 98.25% |
| Uniform | 6 | 0, 3, 5, 7, 9, 11 | 45.8M | 64.08 | 47.52 | 57.32 | 56.31 | 99.59% |
| Full | 12 | 0-11 | 90.0M | 63.41 | 47.78 | 58.42 | 56.54 | 100.0% |
| RWKV-Reranker-1.3B (Full Depth: 24 Layers) |||||||||
| Top-heavy | 1 | 23 | 54M | 50.02 | 35.55 | 45.10 | 43.56 | 67.25% |
| Uniform | 3 | 1, 11, 22 | 161M | 70.33 | 54.92 | 64.58 | 63.28 | 97.70% |
| Top-heavy | 6 | 18-23 | 318M | 69.01 | 51.43 | 64.39 | 61.61 | 95.12% |
| Uniform | 6 | 1, 6, 11, 15, 19, 22 | 318M | 71.19 | 55.10 | 65.51 | 63.93 | 98.70% |
| Full | 24 | 0-23 | 1.3B | 71.58 | 56.44 | 66.30 | 64.77 | 100.0% |
共享状态导致性能灾难性下降。 尽管层剪枝表明存在显著冗余,但压缩并非任意的。作为反例,表 6 显示强制所有层共享单一最终层状态会导致显著的性能下降。这一结果明确指出,冗余并不意味着所有有用的信号都可以坍缩到一个状态中。
我们将这种失败归因于层间的功能特化。中间层状态倾向于保留细粒度的匹配线索和局部证据,而最终层状态则更抽象且与任务无关。因此,硬共享移除了准确相关性估计所需的多尺度信号,导致重排质量的灾难性下降。
Table 6: Ablation on sharing a single state across layers in RWKV-Reranker 0.1B.
|------------------|--------|----------|-------------|-------------|
| States | Layers | NanoBEIR | MTEB-E-Retr | MTEB-C-Retr |
| All states | 12 | 63.41 | 47.78 | 58.42 |
| One shared state | 12 | 51.23 | 11.00 | 5.62 |
为什么不缓存 Transformer KV 进行重排? 一个自然的问题是,类似的想法是否可以应用于 Transformer:我们能否缓存文档的 KV 缓存来加速重排?答案是否定的,原因很简单------KV 缓存过大。对于一个 2000 token 的文档,一个参数规模相当的 Transformer 重排器需要 62.5 × 62.5 \times 62.5× 倍于我们矩阵值状态的存储空间来缓存其 KV 状态。这使得基于 KV 的缓存在大规模应用中不切实际,尤其是在重排需要缓存大型语料库的状态时。相比之下,RWKV 风格的模型维护着一个恒定大小的矩阵值状态,这正是我们旨在利用的架构特性:我们将重排流水线围绕这种紧凑、可重用的表示进行设计,以实现高效推理。详细讨论请参阅附录 B.3。
5 结论
我们提出了一种以状态为中心的检索范式,利用状态作为连接嵌入和重排阶段的桥梁,以实现架构协同。这种方法使重排器能够重用缓存状态,从而在提高效率的同时获得高质量的结果。除了检索,我们的结果还表明直接对状态进行建模是可行且有前景的。这种范式为将状态中心建模扩展到更广泛的场景提供了机会,包括基于状态的值模型、验证器和奖励模型。我们相信以状态为中心的建模在推广到各种应用场景中具有巨大潜力,特别是在智能代理的开发中,它可以自然地整合到传统的强化学习框架中。
局限性
尽管我们的工作在经验性能和效率方面表现出色,但仍存在一些局限性,有待进一步研究。虽然我们基于状态的重排减少了推理时对文档长度的依赖,但整个流水线仍需要运行和维护两个模型,这会引入额外的资源开销。此外,我们的重排器作用于缓存的矩阵值状态,这只是文档的压缩摘要。对于极长或高度详细的文档,这种压缩可能会丢弃细粒度证据,从而可能导致精度下降。
致谢
我们感谢 Yuanshi Intelligence Co. 提供计算资源和基础设施支持,使这项研究得以实现。
Original Abstract: Current Retrieval-Augmented Generation (RAG) systems typically employ a traditional two-stage pipeline: an embedding model for initial retrieval followed by a reranker for refinement. However, this paradigm suffers from significant inefficiency due to the lack of shared information between stages, leading to substantial redundant computation. To address this limitation, we propose \textbf{State-Centric Retrieval}, a unified retrieval paradigm that utilizes "states" as a bridge to connect embedding models and rerankers. First, we perform state representation learning by fine-tuning an RWKV-based LLM, transforming it into \textbf{EmbeddingRWKV}, a unified model that serves as both an embedding model and a state backbone for extracting compact, reusable states. Building upon these reusable states, we further design a state-based reranker to fully leverage precomputed information. During reranking, the model processes only query tokens, decoupling inference cost from document length and yielding a 5.4 × \times ×--44.8 × \times × speedup. Furthermore, we observe that retaining all intermediate layer states is unnecessary; with a uniform layer selection strategy, our model maintains 98.62% of full-model performance using only 25% of the layers. Extensive experiments demonstrate that State-Centric Retrieval achieves high-quality retrieval and reranking results while significantly enhancing overall system efficiency. Code is available at \href{https://github.com/howard-hou/EmbeddingRWKV}{our GitHub repository}.
PDF Link: 2601.07861v1
部分平台可能图片显示异常,请以我的博客内容为准
