note
- Engram:给大语言模型加了个"快速查知识的小模块"。也就是条件记忆模块,实现上,融合静态N-gram嵌入与动态隐藏状态,通过确定性寻址实现O(1)查找,以可扩展查找,作为混合专家(MoE)之外的新稀疏性维度。如此一来,原来的模型(比如MoE架构)靠"实时计算"处理信息,这个模块补了个"静态记忆库",存着常用的短语、知识片段,后续一键调取,不用重复计算。
- 尽管混合专家(Mixture-of-Experts, MoE)通过条件计算来扩展模型容量,但标准Transformer架构缺乏一种原生的机制用于知识检索。为解决这一问题,DeepSeek探索了"条件记忆"作为稀疏性的补充维度,并通过Engram模块加以实现------该模块对经典的N元语法(N-gram)嵌入进行了现代化改造,支持O(1)复杂度的快速查找。
- 稀疏性分配:DeepSeek系统地刻画了神经计算(MoE)与静态记忆(Engram)之间的权衡关系,发现了一种U型缩放规律,可用于指导模型容量的最优分配。
- 实证验证:在严格保持参数量和计算量(FLOPs)不变的条件下,Engram-27B模型在知识、推理、代码和数学等多个领域均持续优于MoE基线模型。
- 机制分析:我们的分析表明,Engram能够减轻模型浅层对静态模式重建的负担,从而可能保留更多有效深度用于复杂推理任务。
- 系统效率:该模块采用确定性寻址机制,使得大规模嵌入表可以高效卸载至主机内存,同时在推理时仅引入极低的额外开销。
文章目录
一、Engram
【Deepseek进展】给大语言模型加了个"快速查知识的小模块"。也就是条件记忆模块,实现上,融合静态N-gram嵌入与动态隐藏状态,通过确定性寻址实现O(1)查找,以可扩展查找,作为混合专家(MoE)之外的新稀疏性维度。如此一来,原来的模型(比如MoE架构)靠"实时计算"处理信息,这个模块补了个"静态记忆库",存着常用的短语、知识片段,后续一键调取,不用重复计算。
《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》,
https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf,
项目地址:https://github.com/deepseek-ai/Engram
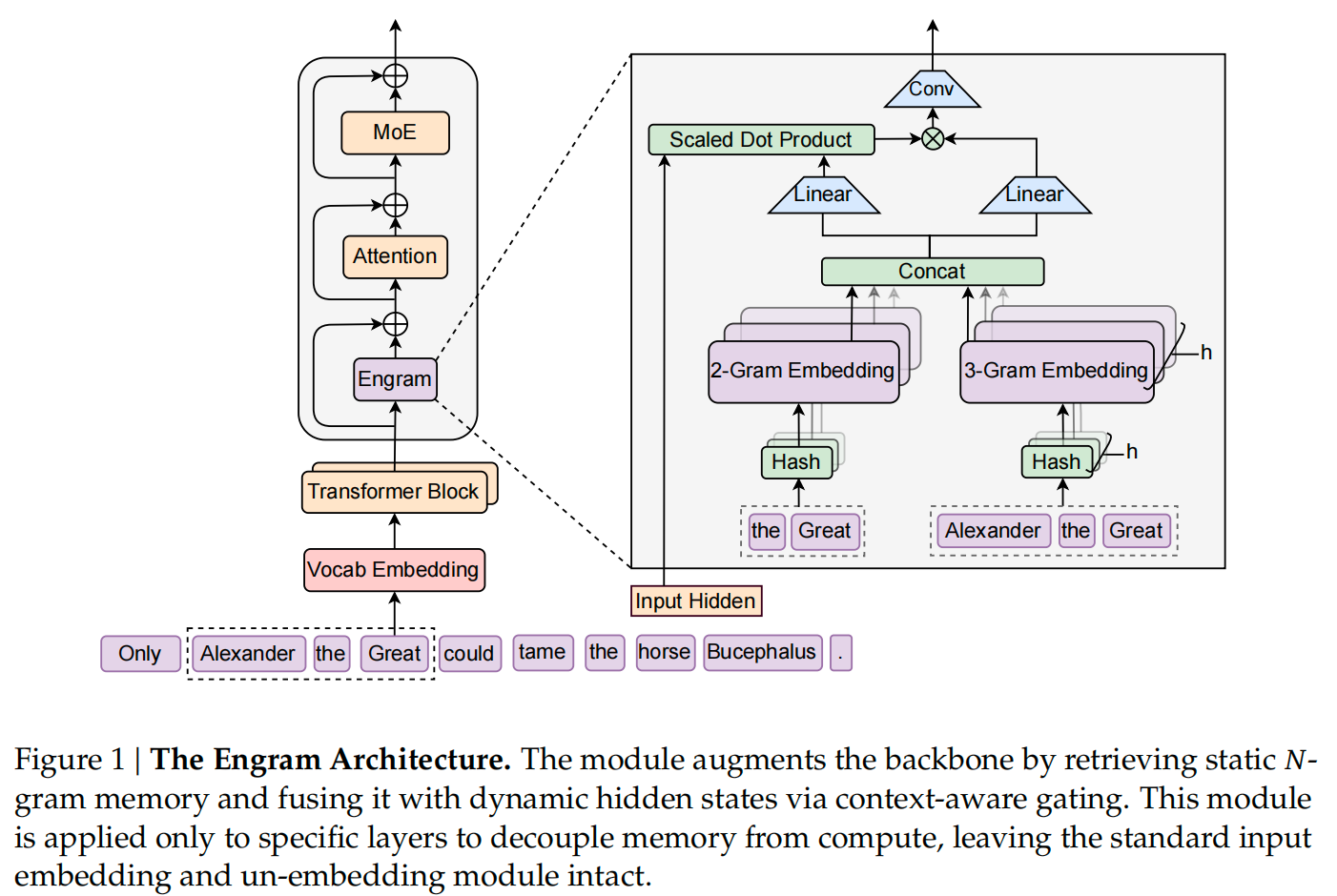
核心实现是"静态记忆库 + 动态计算层"的融合,细分6点。
1)静态记忆库:本质是一个超大的"常用知识片段仓库",存储的是N-gram(比如单词、短语、短句子)的嵌入向量(可以理解为"知识的数字编码")。这些N-gram是从海量文本中统计出来的高频、高价值片段(比如"机器学习""因果推理""for循环语法"),提前做好编码存起来,不用模型再实时生成。
2)动态计算层:就是大模型原来的Transformer层,负责处理复杂推理(比如逻辑链、代码调试、数学推导),不再需要兼顾"记住简单知识"。
3)融合逻辑:模型处理输入时,先从"静态记忆库"里快速调取匹配的知识片段(比如看到"牛顿第二定律",直接拿出库里存好的相关编码),再和Transformer层的动态计算结果结合,输出最终答案。
4)确定性寻址:不用像传统检索那样遍历整个库,而是通过固定规则(比如N-gram的哈希值)直接定位到对应的记忆位置,调取速度是"常数级"(不管库多大,都能一键找到)。
5)内存优化:把这个超大的记忆库卸载到主机内存(而不是占显卡显存),显卡只负责处理动态计算,解决了"大记忆库占用显存"的问题,推理时不增加额外开销。
6)U型缩放定律:一套"怎么分配记忆库容量和模型参数"的规则------模型越小,记忆库可以适当大一点;模型越大,记忆库和计算层的比例要动态调整,确保"记忆"和"推理"不脱节。
Reference
1 Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models