TensorRT LLM plugin背景
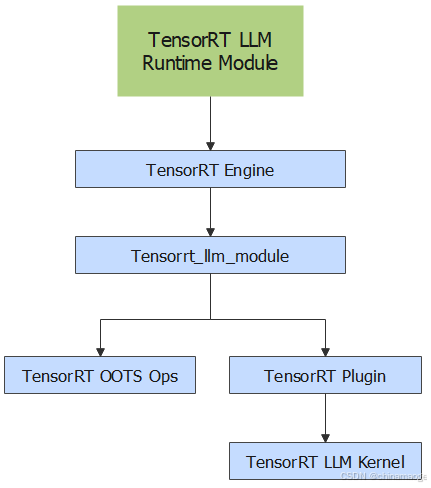
- TensorRT LLM Runtime代表着我们之前三个博客介绍的内容,Runtime下面就对接了TensorRT Engine,但是原生的TensorRT都是适配传统模型的算子
- TensorRT为了更好的适配TensorRT LLM处理大模型,特别设计Tensorrt_llm_module模块,其中特别封装了 LLM 推理所需的核心计算逻辑(比如注意力机制、前馈网络(FFN)、层归一化等),是 TensorRT-LLM 框架中 "将 LLM 架构转化为可执行计算图" 的关键载体。
- Tensorrt_llm_module中发挥解析LLM能力的是通过TensorRT Plugin的形式存在的,往下是高效发挥GPU并行计算能力TensorRT LLM Kernel ,也就是CUDA kernel。
- 这篇博客就是想探究整个链路软件架构和代码具体实现
TensorRT Plugin
Plugin register
- TensorRT Plugin作为中间模块发挥着承上启下重要的作用,在TensorRT LLM代码仓库中有Plugin文件夹存放plugin module
- 里面有很多plugin模块,我选取在调试过程中使用的Plugin GPTAttentionPlugin(我选取的模型文件是Qwen)作为example给大家分析
- 先说下TensorRT Plugin的注册流程
cpp
// TensorRT-LLM-main\cpp\tensorrt_llm\plugins\api\tllmPlugin.cpp
void initOnLoad()
{
auto constexpr kLoadPlugins = "TRT_LLM_LOAD_PLUGINS";
auto const loadPlugins = std::getenv(kLoadPlugins);
if (loadPlugins && loadPlugins[0] == '1')
{
initTrtLlmPlugins(gLogger);
}
}
bool initTrtLlmPlugins(void* logger, char const* libNamespace)
{
if (pluginsInitialized)
{
return true;
}
if (logger)
{
gLogger = static_cast<nvinfer1::ILogger*>(logger);
}
setLoggerFinder(&gGlobalLoggerFinder);
auto registry = getPluginRegistry();
{
std::int32_t nbCreators;
auto creators = getPluginCreators(nbCreators);
for (std::int32_t i = 0; i < nbCreators; ++i)
{
auto const creator = creators[i];
creator->setPluginNamespace(libNamespace);
registry->registerCreator(*creator, libNamespace);
if (gLogger)
{
auto const msg = tc::fmtstr("Registered plugin creator %s version %s in namespace %s",
creator->getPluginName(), creator->getPluginVersion(), libNamespace);
gLogger->log(nvinfer1::ILogger::Severity::kVERBOSE, msg.c_str());
}
}
}
{
std::int32_t nbCreators;
auto creators = getCreators(nbCreators);
for (std::int32_t i = 0; i < nbCreators; ++i)
{
auto const creator = creators[i];
registry->registerCreator(*creator, libNamespace);
}
}
pluginsInitialized = true;
return true;
}- 调用initOnLoad之后开始加载 Plugin,getPluginCreators函数会获取所有创建出来的PluginCreator,registerCreator把creator注册到 TensorRT 注册表,plugin creator注册之后才能使用。
- 为什么creator很重要呢?因为具体的Plugin use Creator create instance。
- Plugin instance是TensorRT自动化调用
cpp
// cpp\tensorrt_llm\plugins\gptAttentionPlugin\gptAttentionPlugin.cpp
//删除了很多参数
IPluginV2* GPTAttentionPluginCreator::createPlugin(char const* name, PluginFieldCollection const* fc) noexcept
{
PluginFieldParser p{fc->nbFields, fc->fields};
try
{
auto* obj = new GPTAttentionPlugin(p.getScalar<int32_t>("layer_idx").value(),
p.getScalar<int32_t>("num_heads").value(), p.getScalar<int32_t>("vision_start").value(),
p.getScalar<int32_t>("vision_length").value(), p.getScalar<int32_t>("num_kv_heads").value(),
static_cast<bool>(p.getScalar<int8_t>("remove_input_padding").value()),
static_cast<AttentionMaskType>(p.getScalar<int32_t>("mask_type").value()),
BlockSparseParams{p.getScalar<int32_t>("block_sparse_block_size").value(),
static_cast<bool>(p.getScalar<int8_t>("block_sparse_homo_head_pattern").value()),
p.getScalar<int32_t>("block_sparse_num_local_blocks").value(),
p.getScalar<int32_t>("block_sparse_vertical_stride").value()},
obj->setPluginNamespace(mNamespace.c_str());
return obj;
}
catch (std::exception const& e)
{
caughtError(e);
}
return nullptr;
}- getCreators会获取EaglePrepareDrafterInputsPluginCreator、DoraPluginCreator两个特殊的PluginCreator
- getPluginCreators函数是 TensorRT LLM 插件库的 "启动开关"------ 只有调用它,所有 LLM 专用优化插件(注意力、量化、Mamba、分布式等)才会被 TensorRT 识别
- 所有plugin creator加载完之后会通过logger打印出来
Plugin Create
- TensorRT Plugin create 相当于是自定义Plugin,NVIDIA 给出一套非常标准的TensorRT Plugin添加流程,最核心是实现「Plugin 计算类」和「Plugin 工厂类(Creator)」,重写几个重要的接口。
cpp
// cpp\tensorrt_llm\plugins\gptAttentionPlugin\gptAttentionPlugin.h
class GPTAttentionPlugin : public GPTAttentionPluginCommon{
int enqueue(nvinfer1::PluginTensorDesc const* inputDesc, nvinfer1::PluginTensorDesc const* outputDesc,
void const* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept override;
// IPluginV2 Methods
char const* getPluginType() const noexcept override;
char const* getPluginVersion() const noexcept override;
int getNbOutputs() const noexcept override;
GPTAttentionPlugin* clone() const noexcept override;
}
class GPTAttentionPluginCreator : public GPTAttentionPluginCreatorCommon{
char const* getPluginName() const noexcept override;
char const* getPluginVersion() const noexcept override;
nvinfer1::PluginFieldCollection const* getFieldNames() noexcept override;
nvinfer1::IPluginV2* createPlugin(char const* name, nvinfer1::PluginFieldCollection const* fc) noexcept override;
}
//cpp\tensorrt_llm\plugins\gptAttentionCommon\gptAttentionCommon.h
class GPTAttentionPluginCommon : public BasePlugin{}
class GPTAttentionPluginCreatorCommon : public BaseCreator
{
public:
GPTAttentionPluginCreatorCommon();
nvinfer1::PluginFieldCollection const* getFieldNames() noexcept override;
template <typename T>
T* deserializePluginImpl(char const* name, void const* serialData, size_t serialLength) noexcept;
protected:
std::vector<nvinfer1::PluginField> mPluginAttributes;
nvinfer1::PluginFieldCollection mFC{};
};
//cpp\tensorrt_llm\plugins\common\plugin.h
class BasePlugin : public nvinfer1::IPluginV2DynamicExt
{
public:
void setPluginNamespace(char const* libNamespace) noexcept override
{
mNamespace = libNamespace;
}
[[nodiscard]] char const* getPluginNamespace() const noexcept override
{
return mNamespace.c_str();
}
protected:
std::string mNamespace{api::kDefaultNamespace};
};
class BaseCreator : public nvinfer1::IPluginCreator
{
public:
void setPluginNamespace(char const* libNamespace) noexcept override
{
mNamespace = libNamespace;
}
[[nodiscard]] char const* getPluginNamespace() const noexcept override
{
return mNamespace.c_str();
}
protected:
std::string mNamespace{api::kDefaultNamespace};
};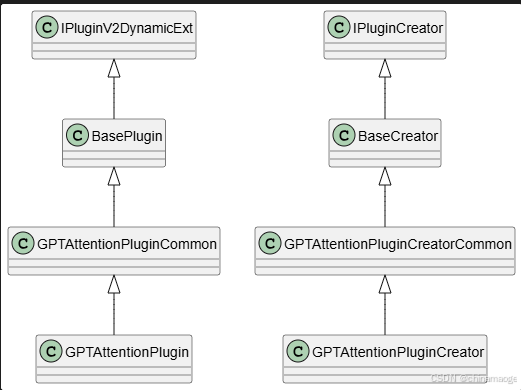
- 为了大家更加清楚GPTAttentionPlugin 继承关系这里直接给出类图
- 现在NVIDIA已经升级到第三代plugin:IPluginV3、IPluginCreatorV3One,但是GPTAttention功能比较老还是用的第二代plugin
- GPTAttentionPluginCreator在通过initTrtLlmPlugins registerCreator之后,在推理过程中会自动调用GPTAttentionPluginCreator::createPlugin new GPTAttentionPlugin,
- 然后使用enqueue作为接口被调用,调用点是第三篇博客提到的:enqueueV3 interface
GPTAttentionPlugin调用到CUDA
- GPTAttentionPlugin 是专为 GPT 类大模型(Qwen、LLaMA、GPT-3 等自回归模型) 设计的注意力层优化插件,核心作用是替代原生 TensorRT 算子,通过硬件加速、计算融合、内存优化等手段,实现低延迟、高吞吐、省显存的注意力计算。
- Qwen 模型的注意力层与 GPT 类模型高度兼容,所以复用成熟的 GPTAttentionPlugin 来优化 QWEN 的注意力计算
- 流程图:
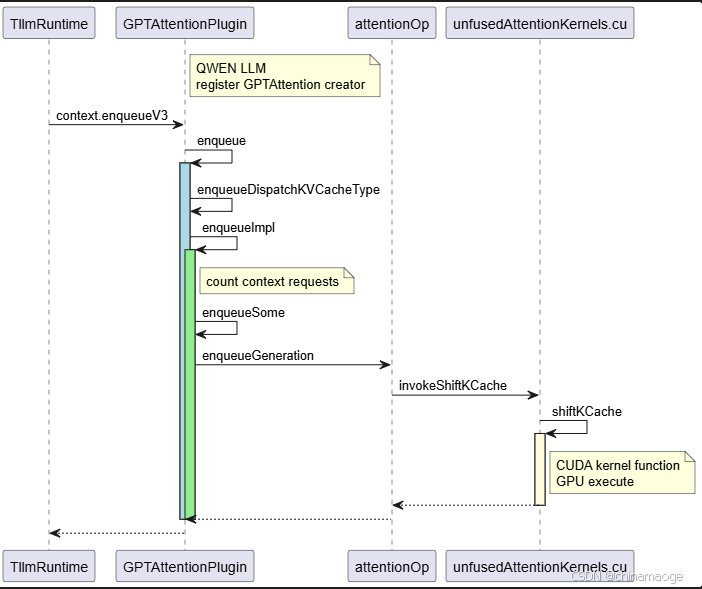
- enqueueV3被调用之后会调用GPTAttentionPlugin::enqueue interface,会根据量化的nvinfer1::DataType类型选择路径
- enqueueImpl准备一下Requests Context。enqueueSome根据各种优化技术设置参数,都设置好之后
cpp
// GPTAttentionPlugin::enqueueSome
if (is_context) // context stage
{enqueueContext<T, KVCacheBuffer>(enqueue_params, stream);}
else // generation stage
{enqueueGeneration<T, KVCacheBuffer>(enqueue_params, stream);}- enqueueGeneration是在AttentionOp 负责具体的注意力层向前计算逻辑,operation确实写得很复杂。。。
- 当使用了useKVCache的时候,会调用invokeShiftKCache对key缓存进行处理。实际的处理是在GPU 上运行shiftKCache CUDA函数执行
cpp
// cpp\tensorrt_llm\kernels\unfusedAttentionKernels.cu
template <typename T, typename KVCacheBuffer>
void invokeShiftKCache(KVCacheBuffer const& kvCacheBuffer, KVLinearBuffer const& shiftKCacheBuffer,
const KvCacheDataType cache_type, int const sizePerHead, int const timestep, int const batch_beam,
int const kv_head_num, int const beam_width, int const maxKCacheLen, int const sinkTokenLen,
float const* kScaleQuantOrig, int const* sequence_lengths, int const* input_lengths, int const rotary_embedding_dim,
float rotary_embedding_base, RotaryScalingType const rotary_scale_type, float rotary_embedding_scale,
int const rotary_embedding_max_positions, PositionEmbeddingType const position_embedding_type, cudaStream_t stream)
{
// Block handles K tile.
int const token_num_in_k = (timestep <= maxKCacheLen) ? timestep : maxKCacheLen;
int const vec_size = 16u / sizeof(T);
dim3 block((sizePerHead / vec_size + 31) / 32 * 32);
dim3 grid(token_num_in_k, kv_head_num, batch_beam);
size_t smem_size = (position_embedding_type == PositionEmbeddingType::kROPE_GPT_NEOX
|| position_embedding_type == PositionEmbeddingType::kLONG_ROPE
|| position_embedding_type == PositionEmbeddingType::kROPE_M
? 2 * rotary_embedding_dim * sizeof(T)
: 0);
if (cache_type == KvCacheDataType::INT8)
{
shiftKCache<T, int8_t, KVCacheBuffer><<<grid, block, smem_size, stream>>>(kvCacheBuffer, shiftKCacheBuffer,
sizePerHead, timestep, beam_width, maxKCacheLen, sinkTokenLen, kScaleQuantOrig, sequence_lengths,
input_lengths, rotary_embedding_dim, rotary_embedding_base, rotary_scale_type, rotary_embedding_scale,
rotary_embedding_max_positions, position_embedding_type);
}
#ifdef ENABLE_FP8
else if (cache_type == KvCacheDataType::FP8)
{
shiftKCache<T, __nv_fp8_e4m3, KVCacheBuffer><<<grid, block, smem_size, stream>>>(kvCacheBuffer,
shiftKCacheBuffer, sizePerHead, timestep, beam_width, maxKCacheLen, sinkTokenLen, kScaleQuantOrig,
sequence_lengths, input_lengths, rotary_embedding_dim, rotary_embedding_base, rotary_scale_type,
rotary_embedding_scale, rotary_embedding_max_positions, position_embedding_type);
}
#endif // ENABLE_FP8
else
{
shiftKCache<T, T, KVCacheBuffer><<<grid, block, smem_size, stream>>>(kvCacheBuffer, shiftKCacheBuffer,
sizePerHead, timestep, beam_width, maxKCacheLen, sinkTokenLen, kScaleQuantOrig, sequence_lengths,
input_lengths, rotary_embedding_dim, rotary_embedding_base, rotary_scale_type, rotary_embedding_scale,
rotary_embedding_max_positions, position_embedding_type);
}
}
//global CUDA 函数实际执行在GPU
template <typename T, typename T_cache, typename KVCacheBuffer>
__global__ void shiftKCache(KVCacheBuffer kvCacheBuffer, KVLinearBuffer shiftKCacheBuffer, int const sizePerHead,
int const timestep, int const beam_width, int const maxKCacheLen, int const sinkTokenLen,
float const* kScaleQuantOrig, int const* sequence_lengths, int const* input_lengths, int const rotary_embedding_dim,
float rotary_embedding_base, RotaryScalingType const rotary_scale_type, float rotary_embedding_scale,
int const rotary_embedding_max_positions, PositionEmbeddingType const position_embedding_type)TensorRT Plugin 创建
- 从上面的代码可以看到createPlugin new GPTAttentionPlugin,那createPlugin是在什么时候调用的呢?
- 是在trtllm-build的阶段,这个阶段会逐 Layer 构建网络时实时解析和适配判断,最终会覆盖 Qwen 模型的每一层,决定是否用自定义plugin 替代原生 TensorRT 层
- 当build的过程使用GPTAttentionPlugin替换原生TensorRT之后,在实际运行过程中,如果creator注册之后就可以使用register Plugin去实现推理,提升大模型运行效率
Summary
- 通过以上的流程分析,使用自定义TensorRT Plugin嵌入到TensorRT LLM框架中, 在build转换模型阶段create Plugin、推理框架运行加载模型阶段register creator,实际模型接收Request消息阶段使用Plugin 实际代码处理。
- 这样高效合理的框架保证大模型可以使用自定义的Plugin、自定义的operation、自定义的CUDA算子,对每个大模型针对性优化的高效运行