一、查看显卡驱动版本
-
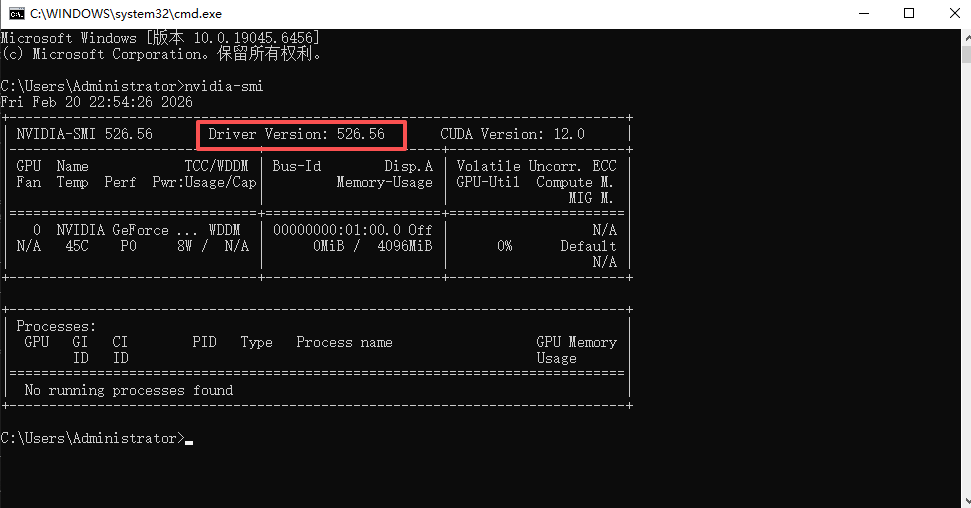
打开CMD命令行,输入指令:
nvidia-smi -
查看输出结果中的驱动版本(示例:RTX 3050 laptop 对应驱动版本 526.56)。
二、匹配并下载对应CUDA版本
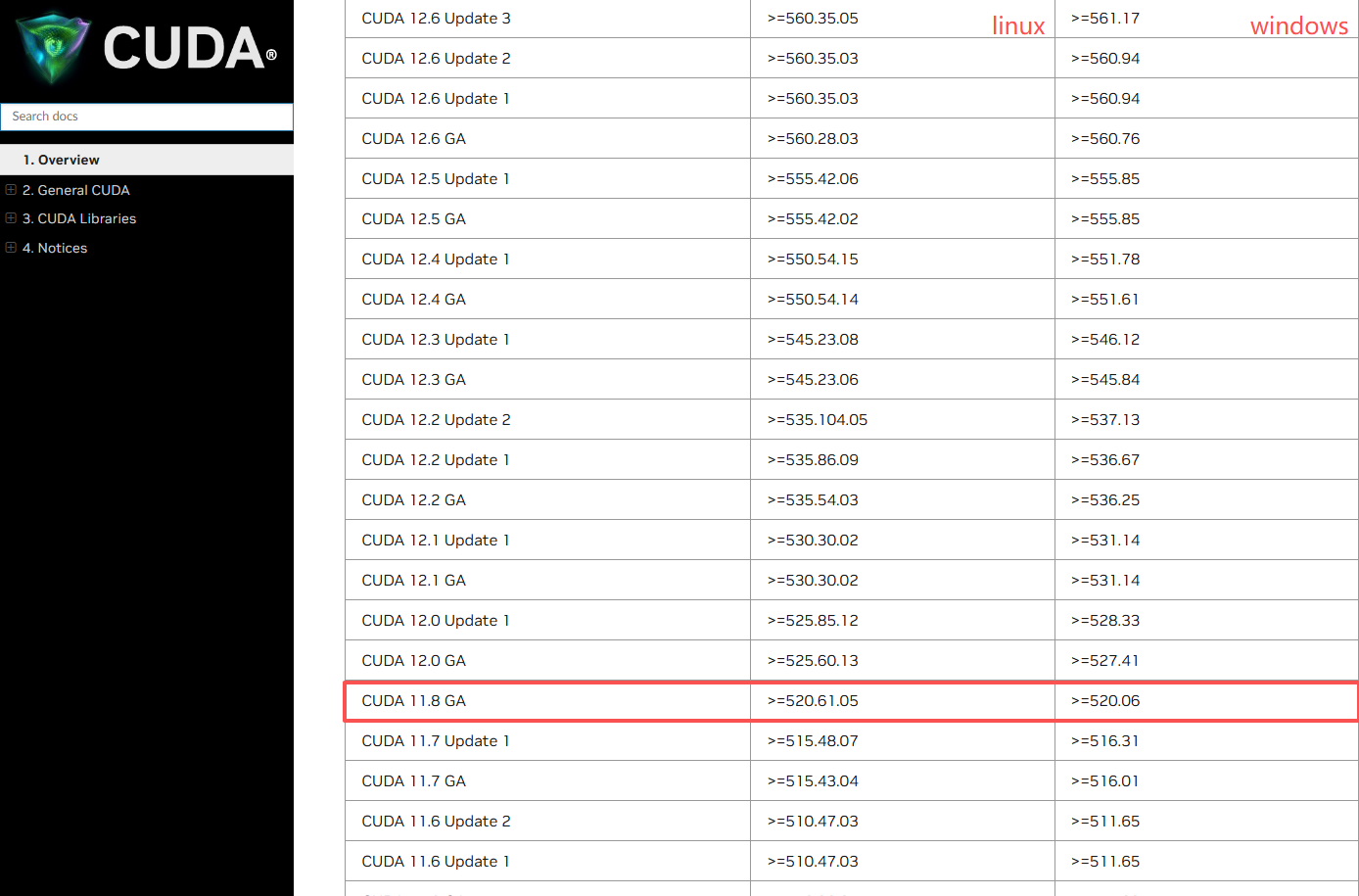
- 查询驱动对应的CUDA版本:访问 NVIDIA CUDA版本对应文档,根据自身驱动版本确定可安装的CUDA版本(示例:驱动526.56 → 仅支持CUDA 11.8)。
- 下载CUDA Toolkit:访问 CUDA Toolkit归档页面,下载对应版本,安装时直接点击"下一步"即可完成默认安装。
三、安装并配置CuDNN
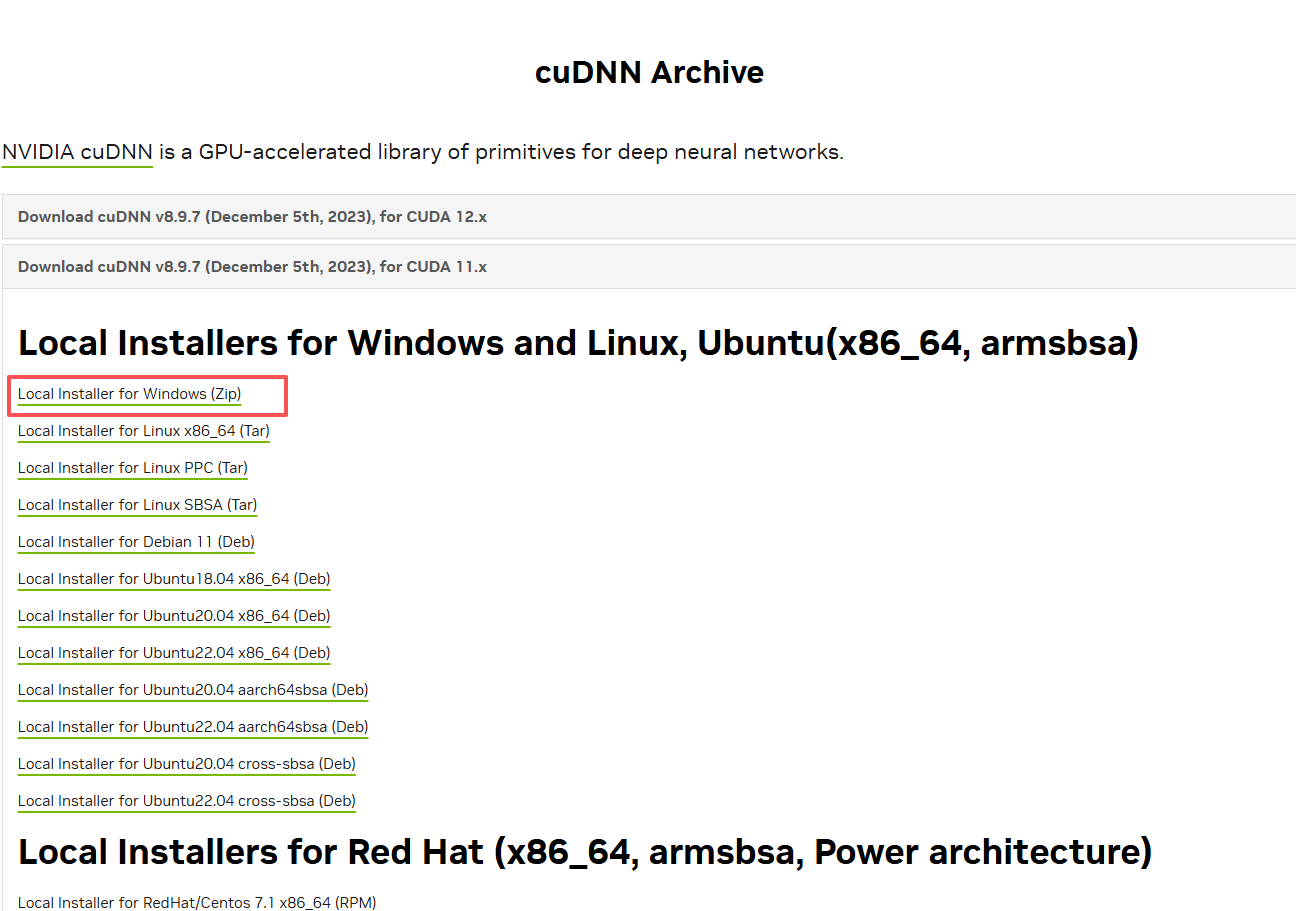
- 下载对应CuDNN版本:访问https://developer.nvidia.com/rdp/cudnn-archive,根据已安装的CUDA版本(示例:CUDA 11.8),下载匹配的CuDNN(需登录NVIDIA账号方可下载)。
- 解压CuDNN压缩包,得到bin、include、lib三个目录。
- 复制文件至CUDA安装目录(默认路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8),做如下操作:
-
将 bin\cudnn*.dll 复制到 → CUDA安装目录\bin
-
将 include\cudnn*.h 复制到 → CUDA安装目录\include
-
将 lib\x64\cudnn*.lib 复制到 → CUDA安装目录\lib\x64
四、配置环境变量
添加以下3个环境变量(路径对应CUDA安装目录):
-
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
-
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include
-
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64
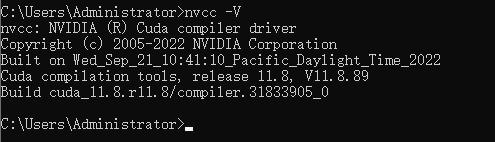
验证:CMD输入 nvcc -V,出现对应CUDA版本信息即配置成功。
五、验证深度学习测试环境(重点避坑)
1. 安装依赖库(坑点)
whl需对应CUDA版本。 我的是CUDA11.8:
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple --index-url https://download.pytorch.org/whl/cu118坑点说明及解决方法:
-
坑点1:依赖库版本和whl文件版本必须与CUDA版本严格匹配! whl文件可访问 PyTorch whl文件页面 确认对应版本。
-
坑点2:下载缓慢 → 用迅雷下载对应whl文件(如torch-2.4.0+cu118-cp311-win_amd64.whl),放入项目根目录,执行以下指令安装:
先装下载好的torch GPU包
pip install .\torch-2.4.0+cu118-cp311-win_amd64.whl
再装torchvision和torchaudio(这两个包很小,直接装很快)
pip install torchvision==0.19.0 torchaudio==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple --index-url https://download.pytorch.org/whl/cu118
2. 环境验证(二选一即可)
极简测试指令(CMD输入):
bash
python -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available())"或
bash
Write-Host "=== CUDA/深度学习环境速测 ==="; nvcc -V | Select-String "release|V"; python -c "import torch; avail=torch.cuda.is_available(); print(f'PyTorch: {torch.__version__} | CUDA可用: {avail}'); print(f'GPU: {torch.cuda.get_device_name(0)} | 显存: {torch.cuda.get_device_properties(0).total_memory/1024**3:.1f}GB' if avail else 'CUDA不可用')"; Write-Host "=== 测试完成 ==="详细测试脚本:
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
CUDA深度学习环境核心测试脚本(极简实用版)
适配:CUDA 11.8 + PyTorch 2.4.0 + Windows 10/11
核心功能:验证CUDA可用性 + GPU运算性能
"""
import platform
import sys
import time
def print_separator(title: str):
"""打印分隔线"""
print(f"\n{'=' * 60}")
print(f"【{title}】")
print('=' * 60)
def main():
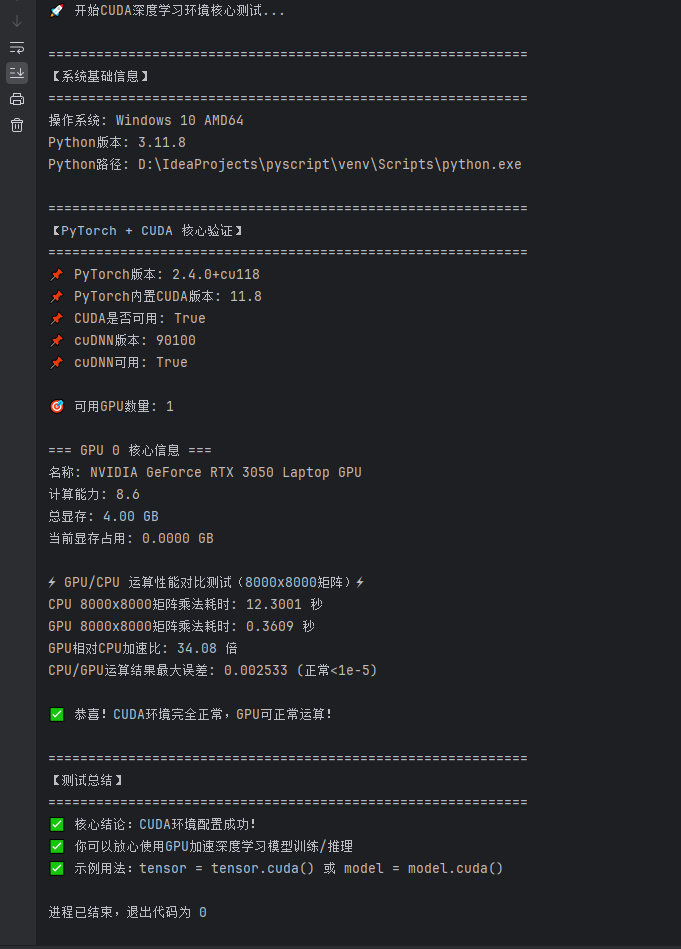
print("🚀 开始CUDA深度学习环境核心测试...")
# 1. 系统基础信息
print_separator("系统基础信息")
print(f"操作系统: {platform.system()} {platform.release()} {platform.machine()}")
print(f"Python版本: {sys.version.split()[0]}")
print(f"Python路径: {sys.executable}")
# 2. PyTorch + CUDA 核心验证(重点)
print_separator("PyTorch + CUDA 核心验证")
try:
import torch
# 核心版本信息
print(f"📌 PyTorch版本: {torch.__version__}")
print(f"📌 PyTorch内置CUDA版本: {torch.version.cuda if torch.cuda.is_available() else 'N/A'}")
print(f"📌 CUDA是否可用: {torch.cuda.is_available()}")
print(f"📌 cuDNN版本: {torch.backends.cudnn.version() if torch.cuda.is_available() else 'N/A'}")
print(f"📌 cuDNN可用: {torch.backends.cudnn.is_available()}")
if torch.cuda.is_available():
# 核心GPU信息(只保留稳定的属性)
gpu_count = torch.cuda.device_count()
print(f"\n🎯 可用GPU数量: {gpu_count}")
for idx in range(gpu_count):
props = torch.cuda.get_device_properties(idx)
print(f"\n=== GPU {idx} 核心信息 ===")
print(f"名称: {props.name}")
print(f"计算能力: {props.major}.{props.minor}")
print(f"总显存: {props.total_memory / 1024 ** 3:.2f} GB")
# 清空显存缓存
torch.cuda.empty_cache()
used_mem = torch.cuda.memory_allocated(idx) / 1024 ** 3
print(f"当前显存占用: {used_mem:.4f} GB")
# 核心:GPU vs CPU 运算性能测试(修复加速比异常)
print("\n⚡ GPU/CPU 运算性能对比测试(8000x8000矩阵)⚡")
test_size = (8000, 8000) # 增大矩阵尺寸,体现GPU并行优势
# CPU运算(固定线程数,避免多线程干扰)
torch.set_num_threads(1) # 关闭CPU多线程,保证测试公平
cpu_a = torch.randn(test_size)
cpu_b = torch.randn(test_size)
start = time.time()
cpu_result = torch.matmul(cpu_a, cpu_b.T)
cpu_time = time.time() - start
# GPU运算(增加预热步骤,消除初始化开销)
# GPU预热:先运行一次空运算,加载GPU内核
warmup_a = torch.randn(100, 100).cuda()
torch.matmul(warmup_a, warmup_a.T)
torch.cuda.synchronize() # 等待预热完成
# 正式GPU运算
gpu_a = cpu_a.cuda()
gpu_b = cpu_b.cuda()
torch.cuda.synchronize() # 等待GPU数据拷贝完成
start = time.time()
gpu_result = torch.matmul(gpu_a, gpu_b.T)
torch.cuda.synchronize() # 等待GPU运算完成
gpu_time = time.time() - start
# 计算加速比(增加异常值判断)
speedup = cpu_time / gpu_time if gpu_time > 0 else 0
print(f"CPU 8000x8000矩阵乘法耗时: {cpu_time:.4f} 秒")
print(f"GPU 8000x8000矩阵乘法耗时: {gpu_time:.4f} 秒")
print(f"GPU相对CPU加速比: {speedup:.2f} 倍")
# 结果一致性验证
diff = abs(cpu_result.numpy() - gpu_result.cpu().numpy()).max()
print(f"CPU/GPU运算结果最大误差: {diff:.6f} (正常<1e-5)")
print("\n✅ 恭喜!CUDA环境完全正常,GPU可正常运算!")
else:
print("\n⚠️ 未检测到CUDA,仅能使用CPU运算")
except ImportError:
print("❌ 未安装PyTorch,请执行:")
print(" pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple --index-url https://download.pytorch.org/whl/cu118")
except Exception as e:
print(f"❌ 测试过程中出现非核心错误: {str(e)}")
print("💡 提示:只要显示CUDA可用=True,就不影响实际使用")
# 3. 最终总结
print_separator("测试总结")
try:
import torch
if torch.cuda.is_available():
print("✅ 核心结论:CUDA环境配置成功!")
print("✅ 你可以放心使用GPU加速深度学习模型训练/推理")
print("✅ 示例用法:tensor = tensor.cuda() 或 model = model.cuda()")
else:
print("❌ 核心结论:CUDA未启用,仅能使用CPU")
except:
print("❌ 未安装PyTorch,无法验证CUDA")
if __name__ == "__main__":
main()运行脚本,输出结果中显示"CUDA可用: True"及GPU信息,即完成所有配置。