最近在研究YOLOE和YOLO World文本图像融合模型的时候,都提到了OpenAI的文本视觉模型CLIP,并就此详细介绍一下CLIP模型。
1、概述
CLIP(Constrastive Language-Image Pre-training),是OpenAI推出的采用对比学习的文本-图像预训练模型。CLIP惊艳之处在于架构非常简洁且效果好到难以置信,可用于zero-shot文本-图像检索,zero-shot图像分类,文本→图像生成任务和检测分割等任务,已经成为基础模型里的破圈者。其论文名称为《Learning Transferable Visual Models From Natural Language Supervision/从自然语言监督中学习可迁移的视觉模型》论文下载地址为:https://github.com/OpenAI/CLIP
2、CLIP工作原理
CLIP模型的核心思想是将文本和图像嵌入到一个共同的语义空间中,使得相关的文本描述和图像内容在这个空间中的表示彼此靠近,而不相关的则远离。CLIP模型的总览图如下图所示。
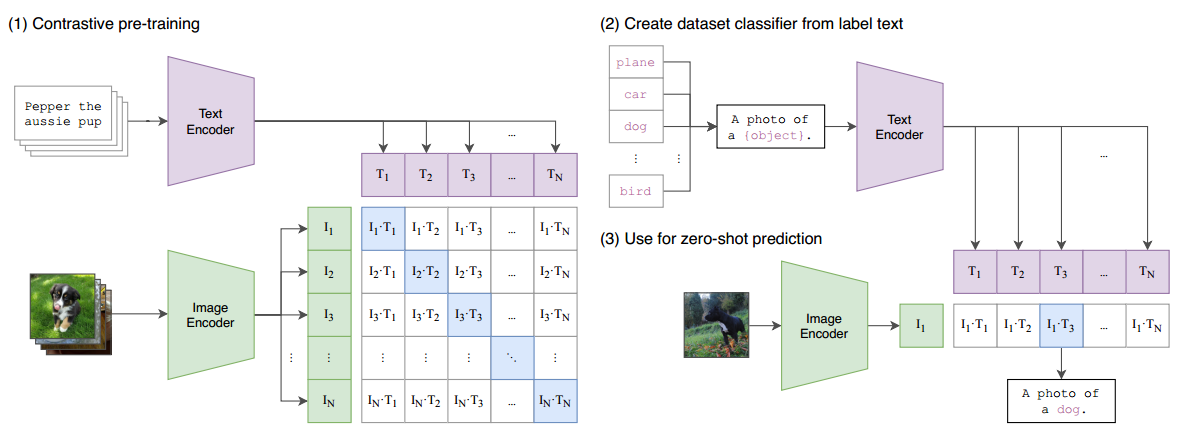
图像编码器:用于将图像映射到特征空间;
文本编码器:用于将文本映射到相同的特征空间。
在模型训练过程中,我们取到的每个batch由 N 个图像-文本对组成。这 N 个图像送入到图像编码器中会得到 N 个图像特征向量 (I1,I2,⋯,IN) ,同理将这 N 个文本送入到文本编码器中我们可以得到 N 个文本特征向量 (T1,T2,⋯,TN) 。因为只有在对角线上的图像和文本是一对,所以CLIP的训练目标是让是一个图像-文本对的特征向量相似度尽可能高,而不是一对的相似度尽可能低,这里相似度的计算使用的是向量内积。通过这个方式,CLIP构建了一个由 N 个正样本和 N*N−N 个负样本组成的损失函数。另外,因为不同编码器的输出的特征向量长度不一样,CLIP使用了一个线性映射将两个编码器生成的特征向量映射到统一长度,CLIP的计算过程伪代码如下。

3、CLIP意义
CLIP(Contrastive Language--Image Pre-training)是OpenAI的第一篇多模态预训练的算法,它延续了GPT系列"大力出奇迹 "的传统。模型是一个基于图像和文本并行的多模态模型,然后通过两个分支的特征向量的相似度计算来构建训练目标。为了训练这个模型,OpenAI采集了超过4亿的图像-文本对。CLIP在诸多多模态任务上取得了非常好的效果,例如图像检索,地理定位,视频动作识别等等,而且在很多任务上仅仅通过无监督学习就可以得到和主流的有监督算法接近的效果。CLIP的思想非常简单,但它仅仅通过如此简单的算法也达到了非常好的效果,这也证明了多模态模型强大的发展潜力。
4、优缺点
4.1优点
1)零样本迁移能力强:不需要针对特定任务微调,就能直接用于诸如ImageNet分类、图文检索等任务,并取得可观性能。这种"即插即用"的能力在多标签分类、开放集识别等场景非常宝贵。
2)通用性高:由于预训练语料覆盖广泛的日常概念,CLIP 学到的图像和文本表示具有很好的通用语义意义,可以支撑各种下游应用。从搜索引擎到推荐系统,CLIP 提供了统一的表示空间,减少了为每个任务单独训练模型的需求。
3)高效利用弱标注数据:CLIP 利用互联网现成的图文对进行训练,避免了昂贵的人工逐例标注。相比传统视觉模型需要大量人工标签,这为利用海量非结构化数据学习提供了范例。
4)多模态融合:CLIP天生打通了图像与文本两种模态,弥合了计算机视觉与自然语言处理的鸿沟。在需要跨模态的应用中(如图文内容审核、图像描述生成辅助),CLIP提供了现成的桥梁。
4.2缺点
1)非生成式模型:CLIP 只能进行判别式的相似度计算,无法直接产出新文本或新图 。这意味着它不能单独完成图像描述、对话等需要生成内容的任务,需要与其它模型配合(例如结合语言模型以产生描述)。
2)精细粒度理解不足:CLIP在某些精细识别任务上表现不佳。例如,在区分非常相似的细小差别(如鸟类品种)。研究发现CLIP对抽象概念或需要计数的场景(如图中有多少物体)表现不如有监督模型,这是因为图文对弱监督很少涵盖这类精确标。
3)偏见和数据噪声:CLIP的训练数据来自互联网,难免带有各种社会偏见和不准确信。结果是模型可能继承这些偏见,在性别、种族等方面产生不恰当的关联。此外,噪声数据还可能导致模型对某些离谱的匹配关系过于自信。虽然这些问题可以通过后处理和精调缓解,但仍是部署CLIP需考虑的风险。
4)长文本处理能力弱:由于模型训练时将文本截断为不超过76个token , CLIP 对长段文本或复杂描述的表示可能不完整。例如,对于一段长篇描述,CLIP只关注开头部分内容,这在需要精准理解长文本时是不足的。在应用中需要策略将长文本分句处理或使用专门的文本模型配合。
跨语言能力有限:原版CLIP主要针对英语训练,对其他语言(中文、法语等)直接使用效果不佳。这需要借助翻译或训练多语言版CLIP来解决。但多语言支持依然是挑战之一。
5、发展趋势
1)更大规模与多模态融合:研究社区正尝试训练更大规模的CLIP类模型,使用数十亿对图文数据(如LAION-5B)以获取更强的表征能力。与此同时,多模态融合不再局限于图像和文本,视频-文本、音频-文本版的"CLIP"也在涌现,将类似的对比学习应用到视频、音频与语言的对齐上,实现"一模型跨多模态"的野心。例如,已有模型尝试将音频和对应说明文字对齐,拓展出音频理解的CLIP变体。未来,我们可能见到将图像、文本 、音频、视频统一到同一向量空间的强大多模态模型。
2)与生成模型深度结合:CLIP 已经作为评价模型用于引导图像生成,未来这种判别模型与生成模型的结合会更紧密。一方面,生成模型可以用CLIP来实时校正输出(例如文本生成过程中,让CLIP判断配图是否匹配文字,从而调整描述);另一方面,判别模型也可能反过来从生成模型中受益(通过生成少样本来提升判别能力)。多模态对话系统(如带视觉能力的ChatGPT)很可能在背后使用了类似CLIP的模块处理图像输入,然后将信息传递给语言模型。这种复合架构可能会成为多模态AI的标准范式。
3)模型优化和高效微调:在模型体量巨大的情况下,如何高效地微调 或更新 CLIP模型也是趋势之一。近来出现的方法如LoRA、Prompt Tuning等,都可能用于CLIP的高效调优,使其在不完全重训的情况下适应新领域或新任务。另外,学术界也在探索更好的对比学习损失和结构,让模型在细粒度对齐和概念组合上做得更好,减少CLIP目前在精细识别方面的弱点。
4)应用落地与社会影响:随着CLIP相关技术成熟,我们预计会有更多产品化的应用出现,如多模态搜索引擎、智能媒资管理系统等。与此同时,对于模型的公平性、偏见移除和解释性也会更受重视。未来的研究可能聚焦于让CLIP这类多模态模型变得更可控和透明,例如用户可以要求模型忽略某些属性(性别、种族)来消除偏见影响,或者提供可解释的检索理由。产业层面,也需要制定相应标准来规避多模态模型可能带来的误用风险。