该模式将复杂的任务分解为一系列步骤,其中每个 LLM 调用都会处理前一个调用的输出。
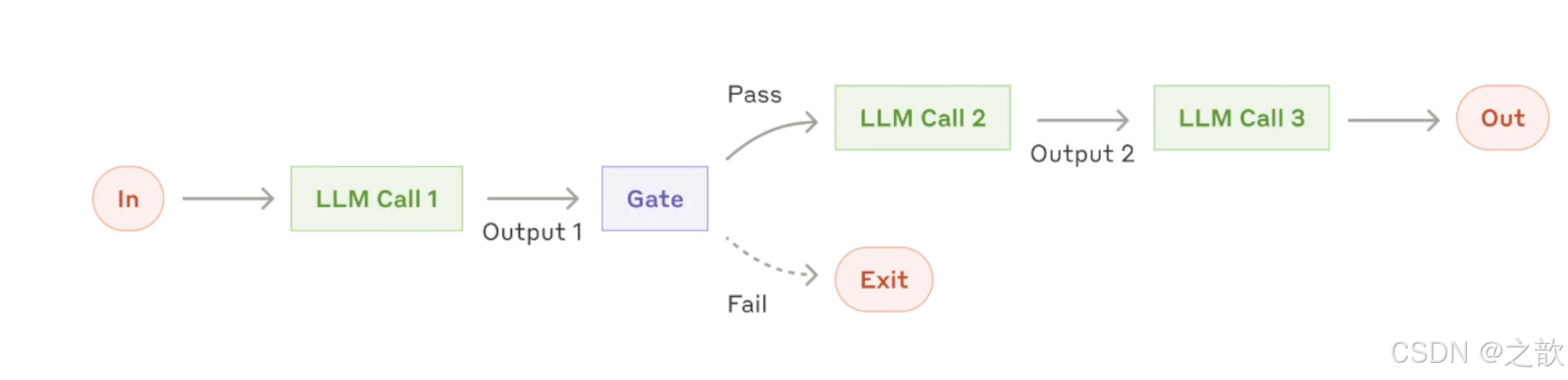
链式工作流模式(Chain Workflow Pattern)详解
📋 目录
概述
链式工作流模式(Chain Workflow Pattern) 是一种顺序执行多个步骤的 AI Agent 工作模式,每个步骤的输出作为下一个步骤的输入,形成一个处理链。
核心思想
输入 → 步骤1 → 步骤2 → 步骤3 → ... → 最终输出
↓ ↓ ↓
输出1 输出2 输出3关键特点
- 顺序执行:步骤按顺序执行,有明确的先后关系
- 数据传递:前一步的输出作为后一步的输入
- 流程控制:支持 Gate 逻辑,可以提前终止流程
- 依赖关系:后续步骤依赖前面步骤的结果
适用场景
- ✅ 有明确步骤顺序的任务
- ✅ 需要逐步推进的工作流
- ✅ 项目全流程处理
- ✅ 需要阶段性验证的场景
核心原理
1. 架构设计
┌─────────────────────────────────────────────────────────┐
│ 链式工作流模式架构 │
└─────────────────────────────────────────────────────────┘
输入
│
▼
┌──────────────┐
│ 步骤1 │
│ 需求分析 │
└──────┬───────┘
│ 输出1
▼
┌──────────────┐
│ 步骤2 │
│ 架构设计 │
└──────┬───────┘
│ 输出2
▼
┌──────────────┐
│ 步骤3 │
│ 实施计划 │
└──────┬───────┘
│ 输出3
▼
┌──────────────┐
│ 步骤4 │
│ 交付清单 │
└──────┬───────┘
│ 最终输出
▼
完成2. 数据流
输入数据 → 步骤1处理 → 中间结果1 → 步骤2处理 → 中间结果2 → ... → 最终结果关键点:
- 每个步骤接收前一步的输出
- 数据在链中逐步传递和转换
- 可以访问所有前面的中间结果
3. Gate 逻辑(流程控制)
链式工作流支持 Gate(门控)逻辑,可以在特定条件下提前终止流程:
步骤1 → [Gate检查] → 通过 → 步骤2 → ...
│
└─ 不通过 → 提前终止示例:
- 需求分析返回 "FAIL" → 流程终止
- 架构设计不满足要求 → 流程终止
- 风险评估过高 → 流程终止
代码结构分析
1. 核心类:PracticalChainWorkflow
java
public class PracticalChainWorkflow {
private final ChatClient chatClient;
// 各个步骤的 Prompt
private static final String REQUIREMENT_ANALYSIS_PROMPT = "...";
private static final String ARCHITECTURE_DESIGN_PROMPT = "...";
private static final String IMPLEMENTATION_PLAN_PROMPT = "...";
private static final String DELIVERY_CHECKLIST_PROMPT = "...";
}2. 核心方法:process()
java
public void process(String businessRequirement) {
String currentOutput = businessRequirement;
// 步骤1: 需求分析
String currentOutput1 = chatClient.prompt()
.user(u -> u.text(REQUIREMENT_ANALYSIS_PROMPT)
.param("input", currentOutput))
.call()
.content();
// Gate 逻辑:检查是否可以继续
if (currentOutput1.contains("FAIL")) {
System.out.println("【流程终止】:需求无法实现");
return; // 提前终止
}
// 步骤2: 架构设计(使用步骤1的输出)
String currentOutput2 = chatClient.prompt()
.user(u -> u.text(ARCHITECTURE_DESIGN_PROMPT)
.param("input", currentOutput1)) // 使用步骤1的输出
.call()
.content();
// 步骤3: 实施计划(使用步骤2的输出)
String currentOutput3 = chatClient.prompt()
.user(u -> u.text(IMPLEMENTATION_PLAN_PROMPT)
.param("input", currentOutput2)) // 使用步骤2的输出
.call()
.content();
// 步骤4: 交付清单(使用步骤3的输出)
String currentOutput4 = chatClient.prompt()
.user(u -> u.text(DELIVERY_CHECKLIST_PROMPT)
.param("input", currentOutput3)) // 使用步骤3的输出
.call()
.content();
}关键点:
- 每个步骤使用前一步的输出作为输入
- 支持 Gate 逻辑提前终止
- 数据在链中逐步传递
3. Prompt 设计
步骤1:需求分析
java
private static final String REQUIREMENT_ANALYSIS_PROMPT = """
你是一个资深的需求分析师,请分析以下业务需求:
需求描述: {input}
请从以下角度进行分析:
1. 核心业务目标
2. 主要功能模块
3. 技术难点识别
4. 风险评估
如果需求无法实现直接回复"FAIL"。
""";特点:
- 明确角色:需求分析师
- 明确分析维度
- 支持 Gate 逻辑(返回 "FAIL" 终止流程)
步骤2:架构设计
java
private static final String ARCHITECTURE_DESIGN_PROMPT = """
你是一个系统架构师,基于以下需求分析,设计系统架构:
需求分析: {input}
请设计:
1. 系统整体架构
2. 技术栈选择
3. 数据库设计要点
4. 接口设计规范
5. 部署架构建议
""";特点:
- 接收需求分析结果作为输入
- 基于需求分析进行架构设计
- 提供完整的架构方案
步骤3:实施计划
java
private static final String IMPLEMENTATION_PLAN_PROMPT = """
你是一个项目经理,基于以下架构设计,制定实施计划:
架构设计: {input}
请制定:
1. 开发阶段划分
2. 人员配置建议
3. 时间节点规划
4. 质量保证措施
5. 风险应对策略
""";特点:
- 接收架构设计结果作为输入
- 基于架构设计制定实施计划
- 考虑项目管理的各个方面
步骤4:交付清单
java
private static final String DELIVERY_CHECKLIST_PROMPT = """
你是一个交付经理,基于以下实施计划,制定交付清单:
实施计划: {input}
请制定:
1. 开发完成标准
2. 测试验收标准
3. 部署上线清单
4. 运维监控要求
5. 用户培训计划
""";特点:
- 接收实施计划作为输入
- 基于实施计划制定交付清单
- 确保项目可交付
工作流程详解
完整执行流程
┌─────────────────────────────────────────────────────────────┐
│ 链式工作流执行流程 │
└─────────────────────────────────────────────────────────────┘
开始
│
▼
┌─────────────────────────────────────┐
│ 输入:业务需求 │
│ "电商平台需要升级订单处理系统..." │
└────────┬────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 步骤1:需求分析 │
├─────────────────────────────────────┤
│ 输入:业务需求 │
│ 处理:分析核心目标、功能模块、 │
│ 技术难点、风险评估 │
│ 输出:需求分析报告 │
└────────┬────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Gate 检查:是否包含 "FAIL"? │
├─────────────────────────────────────┤
│ 是 → 流程终止 ❌ │
│ 否 → 继续执行 ✅ │
└────────┬────────────────────────────┘
│ (继续)
▼
┌─────────────────────────────────────┐
│ 步骤2:架构设计 │
├─────────────────────────────────────┤
│ 输入:需求分析报告 │
│ 处理:设计系统架构、技术栈、 │
│ 数据库、接口、部署架构 │
│ 输出:架构设计方案 │
└────────┬────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 步骤3:实施计划 │
├─────────────────────────────────────┤
│ 输入:架构设计方案 │
│ 处理:制定开发阶段、人员配置、 │
│ 时间节点、质量保证、风险应对 │
│ 输出:项目实施计划 │
└────────┬────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 步骤4:交付清单 │
├─────────────────────────────────────┤
│ 输入:项目实施计划 │
│ 处理:制定完成标准、验收标准、 │
│ 部署清单、监控要求、培训计划 │
│ 输出:交付清单 │
└────────┬────────────────────────────┘
│
▼
完成 ✅实际执行示例
输入
电商平台需要升级订单处理系统,要求:
1. 处理能力提升到每秒1000单
2. 支持多种支付方式和优惠券
3. 实时库存管理和预警
4. 订单状态实时跟踪
5. 数据分析和报表功能
现有系统:Spring Boot + MySQL,日订单量10万步骤1:需求分析输出
核心业务目标:
- 提升订单处理能力10倍(从每秒100单到1000单)
- 增强支付和优惠券功能
- 实现实时库存管理
- 提供订单跟踪功能
- 支持数据分析和报表
主要功能模块:
1. 订单处理模块(高并发处理)
2. 支付集成模块(多种支付方式)
3. 优惠券管理模块
4. 库存管理模块(实时更新)
5. 订单跟踪模块(实时状态)
6. 数据分析模块(报表生成)
技术难点识别:
- 高并发处理(每秒1000单)
- 实时库存更新(避免超卖)
- 分布式事务处理
- 系统性能优化
风险评估:
- 高并发场景下的系统稳定性
- 数据一致性保证
- 系统迁移风险
- 性能瓶颈风险步骤2:架构设计输出
系统整体架构:
- 微服务架构:订单服务、支付服务、库存服务、分析服务
- 消息队列:RabbitMQ/Kafka 处理异步任务
- 缓存层:Redis 缓存热点数据
- 数据库:MySQL 主从复制 + 分库分表
技术栈选择:
- 后端:Spring Boot + Spring Cloud
- 消息队列:RabbitMQ
- 缓存:Redis
- 数据库:MySQL 8.0
- 监控:Prometheus + Grafana
数据库设计要点:
- 订单表分库分表(按订单ID哈希)
- 库存表使用 Redis 缓存
- 支付记录表独立存储
- 建立合适的索引
接口设计规范:
- RESTful API 设计
- 统一响应格式
- 接口版本控制
- 限流和熔断机制
部署架构建议:
- 容器化部署(Docker + K8s)
- 负载均衡(Nginx)
- 服务注册与发现(Consul/Eureka)
- 配置中心(Spring Cloud Config)步骤3:实施计划输出
开发阶段划分:
阶段1(2周):架构设计和基础框架搭建
阶段2(4周):核心功能开发(订单、支付、库存)
阶段3(2周):订单跟踪和数据分析功能
阶段4(2周):测试和优化
阶段5(1周):部署上线
人员配置建议:
- 架构师:1人
- 后端开发:4人
- 前端开发:2人
- 测试工程师:2人
- 运维工程师:1人
时间节点规划:
- 第1-2周:架构设计
- 第3-6周:核心功能开发
- 第7-8周:扩展功能开发
- 第9-10周:测试和优化
- 第11周:部署上线
质量保证措施:
- 代码审查机制
- 单元测试覆盖率 > 80%
- 集成测试和压力测试
- 代码质量扫描
风险应对策略:
- 技术风险:提前进行技术验证
- 进度风险:设置缓冲时间
- 性能风险:提前进行性能测试
- 数据迁移风险:制定详细迁移方案步骤4:交付清单输出
开发完成标准:
✅ 所有功能模块开发完成
✅ 代码审查通过
✅ 单元测试覆盖率 > 80%
✅ 接口文档完整
测试验收标准:
✅ 功能测试全部通过
✅ 性能测试达到要求(每秒1000单)
✅ 压力测试通过
✅ 安全测试通过
部署上线清单:
✅ 生产环境配置完成
✅ 数据库迁移脚本准备
✅ 回滚方案准备
✅ 监控告警配置完成
运维监控要求:
✅ 系统监控(CPU、内存、磁盘)
✅ 应用监控(接口响应时间、错误率)
✅ 业务监控(订单量、支付成功率)
✅ 告警规则配置
用户培训计划:
✅ 管理员培训(系统管理、监控)
✅ 业务人员培训(订单处理、报表查看)
✅ 技术支持培训(问题处理)Gate 逻辑(流程控制)
什么是 Gate 逻辑
Gate(门控)逻辑 是链式工作流中的流程控制机制,允许在特定条件下提前终止流程。
Gate 的作用
- 早期终止:在发现问题时及时终止,避免浪费资源
- 条件检查:验证前一步的输出是否满足继续执行的条件
- 风险控制:在风险过高时停止流程
实现方式
java
// 步骤1:需求分析
String requirementAnalysis = chatClient.prompt()
.user(REQUIREMENT_ANALYSIS_PROMPT)
.call()
.content();
// Gate 检查:如果需求无法实现,提前终止
if (requirementAnalysis.contains("FAIL")) {
System.out.println("【流程终止】:需求无法实现,流程提前退出。");
return; // 提前返回,不进行后续步骤
}
// 继续执行后续步骤
String architectureDesign = chatClient.prompt()
.user(ARCHITECTURE_DESIGN_PROMPT)
.param("input", requirementAnalysis)
.call()
.content();Gate 检查的常见场景
场景1:需求可行性检查
java
if (requirementAnalysis.contains("FAIL") ||
requirementAnalysis.contains("不可行")) {
return; // 需求不可行,终止流程
}场景2:风险评估检查
java
if (riskLevel > HIGH_RISK_THRESHOLD) {
System.out.println("风险过高,终止流程");
return;
}场景3:资源检查
java
if (estimatedCost > budget) {
System.out.println("预算不足,终止流程");
return;
}场景4:技术可行性检查
java
if (architectureDesign.contains("技术不可行")) {
System.out.println("技术方案不可行,终止流程");
return;
}使用方式
1. 基本使用
java
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public CommandLineRunner commandLineRunner(DashScopeChatModel dashScopeChatModel) {
// 1. 创建 ChatClient
var chatClient = ChatClient.create(dashScopeChatModel);
// 2. 创建链式工作流处理器
var chainWorkflow = new PracticalChainWorkflow(chatClient);
// 3. 处理业务需求
return args -> {
String requirements = """
电商平台需要升级订单处理系统,要求:
1. 处理能力提升到每秒1000单
2. 支持多种支付方式和优惠券
...
""";
chainWorkflow.process(requirements);
};
}
}2. 自定义步骤
如果需要自定义工作流步骤,可以修改 PracticalChainWorkflow 类:
java
public void process(String input) {
String step1Output = processStep1(input);
if (shouldTerminate(step1Output)) {
return;
}
String step2Output = processStep2(step1Output);
String step3Output = processStep3(step2Output);
// ... 更多步骤
}
private String processStep1(String input) {
return chatClient.prompt()
.user(CUSTOM_STEP1_PROMPT)
.param("input", input)
.call()
.content();
}3. 添加更多 Gate 检查
java
public void process(String input) {
// 步骤1
String step1Output = processStep1(input);
// Gate 1:需求可行性检查
if (step1Output.contains("FAIL")) {
return;
}
// 步骤2
String step2Output = processStep2(step1Output);
// Gate 2:架构可行性检查
if (step2Output.contains("不可行")) {
return;
}
// Gate 3:成本检查
if (extractCost(step2Output) > budget) {
return;
}
// 继续后续步骤...
}4. 保存中间结果
java
public ProjectDeliverable processWithHistory(String input) {
List<String> processSteps = new ArrayList<>();
String currentOutput = input;
// 步骤1
currentOutput = processStep1(currentOutput);
processSteps.add("步骤1完成:" + currentOutput);
if (shouldTerminate(currentOutput)) {
return new ProjectDeliverable(null, processSteps);
}
// 步骤2
currentOutput = processStep2(currentOutput);
processSteps.add("步骤2完成:" + currentOutput);
// ... 更多步骤
return new ProjectDeliverable(currentOutput, processSteps);
}业务场景
场景 1:软件项目全流程
需求:从需求分析到交付的完整项目流程
应用:
- 项目规划工具
- 项目管理助手
- 技术方案生成
流程:
需求分析 → 架构设计 → 实施计划 → 交付清单示例:
java
chainWorkflow.process("""
开发一个智能客服系统,支持:
- 多渠道接入
- 智能问答
- 工单管理
""");场景 2:产品设计流程
需求:从产品需求到设计方案的完整流程
应用:
- 产品规划
- 设计工具
- 需求管理
流程:
产品需求 → 功能设计 → UI/UX设计 → 技术方案 → 开发计划示例:
java
chainWorkflow.process("""
设计一个移动端购物APP,包括:
- 商品浏览
- 购物车
- 订单管理
- 个人中心
""");场景 3:技术方案评审
需求:从问题分析到解决方案的完整流程
应用:
- 技术咨询
- 问题诊断
- 方案设计
流程:
问题分析 → 技术调研 → 方案设计 → 实施计划 → 验证方案示例:
java
chainWorkflow.process("""
解决高并发系统的性能问题:
- 响应时间慢
- 数据库压力大
- 内存泄漏
""");场景 4:业务流程优化
需求:从现状分析到优化方案的完整流程
应用:
- 流程优化
- 数字化转型
- 业务咨询
流程:
现状分析 → 问题识别 → 优化方案 → 实施计划 → 效果评估示例:
java
chainWorkflow.process("""
优化订单处理流程:
- 当前处理时间:5分钟
- 目标处理时间:1分钟
- 需要保证数据准确性
""");场景 5:培训课程设计
需求:从培训需求到课程设计的完整流程
应用:
- 培训规划
- 课程设计
- 教育工具
流程:
培训需求 → 课程大纲 → 内容设计 → 教学计划 → 评估方案示例:
java
chainWorkflow.process("""
设计一个 Spring AI 培训课程:
- 目标学员:Java 开发工程师
- 培训时长:3天
- 需要包含理论和实践
""");场景 6:数据分析报告
需求:从数据收集到报告生成的完整流程
应用:
- 数据分析
- 报告生成
- 决策支持
流程:
数据收集 → 数据清洗 → 数据分析 → 可视化设计 → 报告生成示例:
java
chainWorkflow.process("""
分析电商平台的销售数据:
- 时间范围:最近3个月
- 分析维度:商品、地区、渠道
- 需要生成可视化报告
""");场景 7:系统迁移规划
需求:从现状评估到迁移方案的完整流程
应用:
- 系统迁移
- 架构升级
- 技术转型
流程:
现状评估 → 迁移方案 → 风险评估 → 实施计划 → 回滚方案示例:
java
chainWorkflow.process("""
将单体应用迁移到微服务架构:
- 当前系统:Spring Boot 单体应用
- 目标架构:Spring Cloud 微服务
- 需要保证业务连续性
""");与其他模式的对比
链式工作流 vs 编排器-工作者模式
| 特性 | 链式工作流 | 编排器-工作者模式 |
|---|---|---|
| 执行方式 | 顺序执行 | 可以并行执行 |
| 任务关系 | 有依赖关系 | 可以独立执行 |
| 数据传递 | 前一步输出作为后一步输入 | 每个工作者接收原始任务 |
| 适用场景 | 有明确步骤顺序 | 可以分解为独立子任务 |
| 复杂度 | 相对简单 | 相对复杂 |
链式工作流 vs 评估优化器
| 特性 | 链式工作流 | 评估优化器 |
|---|---|---|
| 执行方式 | 顺序执行不同步骤 | 循环执行同一任务 |
| 目标 | 完成多步骤流程 | 提升单任务质量 |
| 迭代 | 不迭代 | 迭代优化 |
| 适用场景 | 多步骤流程 | 质量要求高的任务 |
选择建议
- 链式工作流:适用于有明确步骤顺序、需要逐步推进的场景
- 编排器-工作者:适用于可以分解为独立子任务、需要并行处理的场景
- 评估优化器:适用于需要高质量输出、可以迭代优化的场景
优缺点分析
优点
1. 清晰的流程
- ✅ 步骤顺序明确,易于理解和维护
- ✅ 每个步骤的职责清晰
- ✅ 流程可视化程度高
2. 数据传递自然
- ✅ 前一步的输出直接作为后一步的输入
- ✅ 数据在链中逐步传递和转换
- ✅ 可以访问所有前面的中间结果
3. 支持流程控制
- ✅ 支持 Gate 逻辑,可以提前终止
- ✅ 可以在关键节点进行验证
- ✅ 避免无效的后续处理
4. 易于扩展
- ✅ 可以轻松添加新的步骤
- ✅ 可以调整步骤顺序
- ✅ 可以自定义每个步骤的 Prompt
5. 适合复杂流程
- ✅ 适合多步骤的复杂流程
- ✅ 每个步骤可以专注于特定任务
- ✅ 可以逐步推进复杂项目
缺点
1. 串行执行
- ❌ 必须按顺序执行,无法并行
- ❌ 执行时间 = 所有步骤时间之和
- ❌ 效率相对较低
2. 错误传播
- ❌ 前一步的错误会影响后续步骤
- ❌ 缺少错误恢复机制
- 解决方案:添加错误处理和重试机制
3. 缺少并行能力
- ❌ 无法利用并行处理提高效率
- ❌ 不适合可以并行执行的场景
- 解决方案:结合其他模式(如编排器-工作者)
4. 上下文管理
- ❌ 只能访问前一步的输出
- ❌ 无法访问更早的步骤输出
- 解决方案:维护完整的上下文历史
5. 灵活性有限
- ❌ 步骤顺序固定,难以动态调整
- ❌ 无法根据条件跳过某些步骤
- 解决方案:添加条件分支逻辑
改进建议
1. 添加错误处理和重试
java
public void processWithRetry(String input) {
String currentOutput = input;
int maxRetries = 3;
// 步骤1
for (int i = 0; i < maxRetries; i++) {
try {
currentOutput = processStep1(currentOutput);
break;
} catch (Exception e) {
if (i == maxRetries - 1) throw e;
// 重试前可以调整输入
}
}
// 继续后续步骤...
}2. 支持条件分支
java
public void processWithBranch(String input) {
String step1Output = processStep1(input);
// 根据步骤1的结果选择不同的分支
if (step1Output.contains("简单需求")) {
// 简单流程
processSimpleFlow(step1Output);
} else {
// 复杂流程
processComplexFlow(step1Output);
}
}3. 支持步骤跳过
java
public void processWithSkip(String input) {
String step1Output = processStep1(input);
// 如果满足条件,跳过步骤2
if (shouldSkipStep2(step1Output)) {
String step3Output = processStep3(step1Output);
} else {
String step2Output = processStep2(step1Output);
String step3Output = processStep3(step2Output);
}
}4. 维护完整上下文
java
public void processWithContext(String input) {
List<String> contextHistory = new ArrayList<>();
contextHistory.add("原始输入:" + input);
String currentOutput = input;
// 步骤1
currentOutput = processStep1(currentOutput);
contextHistory.add("步骤1输出:" + currentOutput);
// 步骤2(可以访问所有历史上下文)
currentOutput = processStep2(currentOutput, contextHistory);
contextHistory.add("步骤2输出:" + currentOutput);
// ... 更多步骤
}5. 支持并行子流程
java
public void processWithParallelSubflows(String input) {
String step1Output = processStep1(input);
// 步骤2和步骤3可以并行执行
CompletableFuture<String> step2Future =
CompletableFuture.supplyAsync(() -> processStep2(step1Output));
CompletableFuture<String> step3Future =
CompletableFuture.supplyAsync(() -> processStep3(step1Output));
// 等待两个步骤都完成
String step2Output = step2Future.join();
String step3Output = step3Future.join();
// 步骤4需要步骤2和步骤3的结果
String step4Output = processStep4(step2Output, step3Output);
}6. 添加进度回调
java
public interface ProgressCallback {
void onStepStart(int stepNumber, String stepName);
void onStepComplete(int stepNumber, String stepName, String output);
void onStepError(int stepNumber, String stepName, Exception error);
void onComplete(String finalOutput);
}
public void processWithCallback(String input, ProgressCallback callback) {
callback.onStepStart(1, "需求分析");
String step1Output = processStep1(input);
callback.onStepComplete(1, "需求分析", step1Output);
// ... 更多步骤
}7. 支持动态步骤配置
java
public class ConfigurableChainWorkflow {
private final List<WorkflowStep> steps;
public ConfigurableChainWorkflow(List<WorkflowStep> steps) {
this.steps = steps;
}
public void process(String input) {
String currentOutput = input;
for (WorkflowStep step : steps) {
if (step.shouldExecute(currentOutput)) {
currentOutput = step.execute(currentOutput);
if (step.shouldTerminate(currentOutput)) {
return;
}
}
}
}
}8. 添加结果验证
java
public void processWithValidation(String input) {
String step1Output = processStep1(input);
// 验证步骤1的输出
if (!validateStep1(step1Output)) {
throw new ValidationException("步骤1输出验证失败");
}
String step2Output = processStep2(step1Output);
// ... 更多步骤和验证
}总结
核心价值
链式工作流模式通过顺序执行 和数据传递,实现了:
- 清晰的流程:步骤顺序明确,易于理解
- 逐步推进:每个步骤基于前一步的结果
- 流程控制:支持 Gate 逻辑,可以提前终止
- 适合复杂流程:适合多步骤的复杂项目
适用场景
- ✅ 有明确步骤顺序的任务
- ✅ 需要逐步推进的工作流
- ✅ 项目全流程处理
- ✅ 需要阶段性验证的场景
关键要点
- 顺序执行:步骤按顺序执行,有明确的先后关系
- 数据传递:前一步的输出作为后一步的输入
- Gate 逻辑:支持流程控制,可以提前终止
- 灵活配置:可以自定义步骤和 Prompt
改进方向
- 添加错误处理和重试机制
- 支持条件分支和步骤跳过
- 维护完整上下文历史
- 支持并行子流程
- 添加进度回调和结果验证
- 支持动态步骤配置
参考代码位置:
PracticalChainWorkflow.java:核心实现Application.java:使用示例
相关模式:
- 链式工作流模式(Chain Workflow Pattern)
- 管道模式(Pipeline Pattern)
- 责任链模式(Chain of Responsibility Pattern)
适用框架:
- LangChain
- Spring AI
- AutoGen
测试
application.properties
java
spring.ai.dashscope.api-key=sk-xxx
spring.ai.dashscope.embedding.options.model= text-embedding-v4pom.xml
java
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.xs.springai</groupId>
<artifactId>spring-ai-parent</artifactId>
<version>0.0.1-xs</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.xs</groupId>
<artifactId>spring-ai-agent</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-ai-agent</name>
<description>spring-ai-agent</description>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0</spring-ai.version>
<!-- Spring AI Alibaba -->
<spring-ai-alibaba.version>1.0.0.2</spring-ai-alibaba.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>业务代码
java
package com.xs.agent.chain_workflow;
import org.springframework.ai.chat.client.ChatClient;
import java.util.ArrayList;
import java.util.List;
public class PracticalChainWorkflow {
private final ChatClient chatClient;
// 实战场景的中文提示词
private static final String REQUIREMENT_ANALYSIS_PROMPT = """
你是一个资深的需求分析师,请分析以下业务需求:
需求描述: {input}
请从以下角度进行分析:
1. 核心业务目标
2. 主要功能模块
3. 技术难点识别
4. 风险评估
如果需求无法实现直接回复"FAIL"。
""";
private static final String ARCHITECTURE_DESIGN_PROMPT = """
你是一个系统架构师,基于以下需求分析,设计系统架构:
需求分析: {input}
请设计:
1. 系统整体架构
2. 技术栈选择
3. 数据库设计要点
4. 接口设计规范
5. 部署架构建议
请提供完整的架构设计方案。
""";
private static final String IMPLEMENTATION_PLAN_PROMPT = """
你是一个项目经理,基于以下架构设计,制定实施计划:
架构设计: {input}
请制定:
1. 开发阶段划分
2. 人员配置建议
3. 时间节点规划
4. 质量保证措施
5. 风险应对策略
请提供详细的项目实施计划。
""";
private static final String DELIVERY_CHECKLIST_PROMPT = """
你是一个交付经理,基于以下实施计划,制定交付清单:
实施计划: {input}
请制定:
1. 开发完成标准
2. 测试验收标准
3. 部署上线清单
4. 运维监控要求
5. 用户培训计划
请以清晰的表格形式输出交付清单。
""";
public PracticalChainWorkflow(ChatClient chatClient) {
this.chatClient = chatClient;
}
public void process(String businessRequirement) {
List<String> processSteps = new ArrayList<>();
String currentOutput = businessRequirement;
System.out.println("=== 开始项目全流程处理 ===");
// 步骤1: 需求分析
System.out.println("步骤1: 业务需求分析");
String currentOutput1 = chatClient.prompt()
.user(u -> u.text(REQUIREMENT_ANALYSIS_PROMPT).param("input", currentOutput))
.call()
.content();
// ==== Gate 逻辑 ====
if (currentOutput1.contains("FAIL")) {
System.out.println("【流程终止】:需求无法实现,流程提前退出。");
return; // 提前返回,不进行后续步骤
}
System.out.println("需求分析完成:"+currentOutput1);
// 步骤2: 架构设计
System.out.println("步骤2: 系统架构设计");
String currentOutput2 = chatClient.prompt()
.user(u -> u.text(ARCHITECTURE_DESIGN_PROMPT).param("input", currentOutput1))
.call()
.content();
System.out.println("架构设计完成:"+currentOutput2);
// 步骤3: 实施计划
System.out.println("步骤3: 项目实施规划");
String currentOutput3 = chatClient.prompt()
.user(u -> u.text(IMPLEMENTATION_PLAN_PROMPT).param("input", currentOutput2))
.call()
.content();
System.out.println("实施计划完成:"+currentOutput3);
// 步骤4: 交付清单
System.out.println("步骤4: 交付清单制定");
String currentOutput4 = chatClient.prompt()
.user(u -> u.text(DELIVERY_CHECKLIST_PROMPT).param("input", currentOutput3))
.call()
.content();
System.out.println("交付清单完成:"+currentOutput4);
System.out.println("=== 项目全流程处理完成 ===");
}
public record ProjectDeliverable(String finalDeliverable, List<String> processSteps) {}
}启动Application
java
/*
* Copyright 2024 - 2024 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.xs.agent.chain_workflow;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.xs.agent.config.RestClientConfig;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Import;
// ------------------------------------------------------------
// EVALUATOR-OPTIMIZER
// ------------------------------------------------------------
@SpringBootApplication
@Import(RestClientConfig.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public CommandLineRunner commandLineRunner(DashScopeChatModel dashScopeChatModel) {
var chatClient = ChatClient.create(dashScopeChatModel);
return args -> {
String requirements = """
电商平台需要升级订单处理系统,要求:
1. 处理能力提升到每秒1000单
2. 支持多种支付方式和优惠券
3. 实时库存管理和预警
4. 订单状态实时跟踪
5. 数据分析和报表功能
现有系统:Spring Boot + MySQL,日订单量10万
""";
new PracticalChainWorkflow(chatClient).process(requirements);
};
}
}测试结果
=== 开始项目全流程处理 ===
步骤1: 业务需求分析
需求分析完成:1. 核心业务目标
本次订单处理系统升级的核心业务目标是:在保障系统稳定性和数据一致性的前提下,实现高并发、高可用的订单处理能力,以支持电商平台未来业务规模的快速增长。具体包括:
- 提升系统吞吐量至每秒处理1000个订单(即每日约8640万单),远超当前日均10万单的水平,支撑大促等高峰场景;
- 增强支付与营销能力,通过支持多种支付方式(如微信、支付宝、银联、数字货币等)和复杂优惠券逻辑(满减、折扣、叠加、限时等),提升用户转化率和购物体验;
- 实现库存的实时扣减与预警机制,避免超卖并保障供应链协同效率;
- 提供端到端的订单状态实时跟踪能力,增强用户透明度与客服响应能力;
- 构建数据分析与报表体系,为运营决策提供数据支持,如订单趋势、支付成功率、库存周转率等。
- 主要功能模块
基于需求描述,系统应划分为以下核心功能模块:
(1)订单服务模块
- 高并发订单创建、拆单(多商品分仓)、合并支付支持
- 订单状态机管理(待支付、已支付、发货中、已完成、已取消等)
- 支持异步下单与幂等性控制
(2)支付集成模块
- 对接多种第三方支付渠道,统一支付网关接口
- 支付结果异步通知处理与对账机制
- 支付超时自动关闭与重试机制
(3)优惠券与促销引擎
- 优惠券发放、核销、回收管理
- 规则引擎支持复杂优惠策略(优先级、互斥、叠加)
- 与订单服务解耦,支持预计算与实时校验
(4)库存管理模块
- 实时库存查询与扣减(支持预占库存、确认/回滚)
- 分布式锁或乐观锁防止超卖
- 库存预警(低库存提醒、阈值告警)
- 支持多仓库、SKU维度管理
(5)订单状态跟踪服务
- 基于事件驱动架构(EDA)推送状态变更
- 用户端实时查询订单轨迹(如"已打包""已发货")
- 集成物流信息API获取外部运单状态
(6)数据采集与分析模块
- 订单流水、支付、库存变更等数据采集
- 实时/离线数据仓库构建(如使用Kafka + Flink + Hive)
- 报表系统:销售统计、订单转化漏斗、支付成功率、库存周转等
- 支持可视化看板与导出功能
- 技术难点识别
(1)高并发订单写入性能瓶颈
当前Spring Boot + MySQL架构在每秒1000单(尤其瞬时峰值可能更高)场景下,MySQL单库写入将成为严重瓶颈。需引入分库分表(如ShardingSphere)、读写分离、异步落库等方案。
(2)分布式事务一致性
订单创建涉及"扣库存、锁优惠券、生成订单、调用支付"等多个操作,需保证最终一致性。传统XA事务性能差,建议采用基于消息队列的最终一致性方案(如RocketMQ事务消息)或Saga模式。
(3)实时库存高并发扣减
热点商品库存扣减易引发数据库锁竞争。解决方案包括:
- 利用Redis原子操作实现库存预扣(结合Lua脚本)
- 异步持久化到MySQL,保障高性能与一致性
- 使用库存分段或本地缓存+批量同步机制
(4)支付与优惠券的幂等与状态同步
多种支付方式回调时间不一,需设计幂等机制防止重复处理;优惠券使用需防重复领取与并发冲突,建议使用Redis分布式锁 + 数据库唯一约束双重保障。
(5)订单状态实时跟踪的延迟问题
订单状态更新频繁,若全部同步刷新将造成数据库压力。建议采用事件驱动架构(Event Sourcing)+ 消息中间件(Kafka)解耦状态变更,并通过CQRS模式分离查询视图。
(6)数据分析实时性要求
原始订单数据量大,传统MySQL难以支撑复杂报表查询。需构建独立的数据链路:
- 使用Canal监听MySQL binlog,实时同步至数据湖
- 流处理(Flink)实现实时指标计算
- 数仓分层建模(ODS → DWD → DWS)支撑灵活报表
- 风险评估
| 风险项 | 描述 | 可能影响 | 缓解措施 |
|---|---|---|---|
| 系统性能不达标 | 单体MySQL架构无法支撑1000 TPS订单写入 | 大促期间系统崩溃、订单丢失 | 重构为微服务 + 分库分表 + 异步化处理 |
| 超卖风险 | 高并发下库存扣减不一致 | 客户投诉、经济损失 | 引入Redis + 分布式锁 + 最终一致性补偿机制 |
| 支付对账困难 | 多渠道支付回调异常或延迟 | 资金差异、财务风险 | 建立定时对账任务 + 补单机制 + 明确对账流程 |
| 数据延迟或丢失 | 消息积压或ETL失败导致报表不准 | 决策失误、运营误判 | 监控消息堆积、设置重试与告警机制 |
| 项目周期紧张 | 从现有系统迁移至新架构工作量大 | 上线延期、旧系统不堪重负 | 采用渐进式重构,先做订单服务拆分试点 |
| 技术团队能力不足 | 缺乏高并发、分布式系统经验 | 架构设计缺陷、线上故障 | 引入外部专家评审,加强培训与代码审查 |
结论:该需求在技术上具有挑战性,但通过合理的架构演进(如微服务化、引入中间件、数据分层)是可实现的。
因此:SUCCESS
步骤2: 系统架构设计
架构设计完成:# 电商平台订单处理系统架构设计方案
1. 系统整体架构设计
1.1 架构风格:微服务 + 事件驱动 + CQRS + 分层数据体系
为应对高并发、高可用和复杂业务逻辑的挑战,系统采用基于领域驱动设计(DDD)的微服务架构 ,结合事件驱动架构(EDA) 和 CQRS 模式,实现写读分离与解耦。整体架构分为以下层次:
+------------------+ +---------------------+
| 客户端 / API网关 | <---> | 统一API Gateway |
+------------------+ +----------+----------+
|
+-----------------------v------------------------+
| 微服务集群(Spring Cloud) |
+-------------------+-------------+--------------+
| |
+-----------------------+ +---------v-----------+
| Order Service | | Payment Service |
+-----------------------+ +---------------------+
| |
+-----------------------+ +---------------------+
| Coupon & Promotion Eng| | Inventory Service |
+-----------------------+ +----------+----------+
|
+-----------------------v------------------+
| Kafka Event Bus |
+-------------------+------------------------+
|
+---------------------------------v----------------------------------+
| 数据同步与分析链路 |
+----------------------------+----------------------+---------------+
| | |
+-----------------v------+ +--------v--------+ +---v-----------+
| Canal → Kafka → Flink | | Elasticsearch | | Redis Cache |
| (实时ETL & 计算) | | (状态索引/搜索) | | (热点数据) |
+-------------------------+ +-----------------+ +-------------+
|
+--------v---------+
| Data Warehouse |
| (Hive/Doris) |
+------------------+
|
+--------v---------+
| BI & Dashboard |
| (Superset/Grafana)|
+------------------+1.2 核心架构原则
| 原则 | 说明 |
|---|---|
| 微服务化拆分 | 按业务边界划分服务,降低耦合,提升可维护性与扩展性 |
| 异步通信优先 | 使用消息队列解耦核心流程,提高吞吐量与容错能力 |
| 最终一致性保障 | 通过事务消息、补偿机制、对账任务保证分布式事务一致 |
| 读写分离(CQRS) | 写模型专注命令执行,读模型构建轻量视图供查询 |
| 弹性伸缩 | 所有服务无状态部署,支持K8s自动扩缩容 |
| 全链路监控 | 集成Prometheus + Grafana + ELK + SkyWalking 实现可观测性 |
2. 技术栈选择
2.1 后端技术栈
| 类别 | 技术选型 | 选型理由 |
|---|---|---|
| 开发框架 | Spring Boot + Spring Cloud Alibaba | 成熟生态,支持Nacos、Sentinel、Seata等中间件集成 |
| RPC通信 | OpenFeign + Dubbo(部分高性能调用) | Feign简洁易用,Dubbo适合库存类高频调用 |
| 注册中心 | Nacos | 支持服务发现、配置管理一体化,性能优异 |
| 配置中心 | Nacos Config | 动态配置推送,支持灰度发布 |
| 限流熔断 | Sentinel | 流控、降级、熔断三位一体,适配大促场景 |
| 分布式事务 | Seata AT/Saga 或 RocketMQ 事务消息 | 根据场景选择:简单场景用AT,跨系统用事务消息 |
| 消息中间件 | Apache Kafka | 高吞吐、低延迟、持久化能力强,适合事件广播与异步解耦 |
| 缓存系统 | Redis Cluster(主从+哨兵) | 支持原子操作、分布式锁、Lua脚本,用于库存预扣与幂等控制 |
| 分布式锁 | Redisson(基于Redis) | 提供可重入锁、公平锁、红锁等多种模式 |
| 任务调度 | XXL-JOB / Quartz Cluster | 对账、补单、预警等定时任务统一调度 |
2.2 数据存储技术栈
| 类别 | 技术选型 | 说明 |
|---|---|---|
| 主数据库 | MySQL 8.0(InnoDB) | 关系型数据强一致性保障,支持JSON字段 |
| 分库分表 | ShardingSphere-JDBC | 客户端分片,透明路由,支持按用户ID或订单ID分库 |
| 读写分离 | MyCat / ShardingSphere Proxy | 实现主从复制下的读写分离 |
| 实时缓存 | Redis 7.x Cluster | 存储热点商品库存、优惠券使用记录、会话幂等令牌 |
| 搜索引擎 | Elasticsearch 8.x | 构建订单轨迹、物流信息的全文检索与聚合分析 |
| 实时计算 | Apache Flink 1.17 | 流式处理订单事件,计算实时指标(如QPS、支付成功率) |
| 数据仓库 | Hive + Doris(MPP) | Hive用于离线数仓建模,Doris支持亚秒级OLAP查询 |
| 数据采集 | Canal + Kafka | 监听MySQL binlog,实现增量数据实时同步 |
| 可视化报表 | Apache Superset / Grafana | 多维数据分析看板,支持导出与告警 |
2.3 前端与网关
| 组件 | 技术选型 | 说明 |
|---|---|---|
| API网关 | Spring Cloud Gateway | 路由、鉴权、限流、日志埋点统一入口 |
| 前端应用 | Vue3 + Element Plus | 用户端展示订单详情、状态跟踪、支付结果 |
| 移动端接入 | RESTful API + WebSocket | 支持APP实时推送订单变更 |
| 安全认证 | JWT + OAuth2.0 | 用户身份验证,第三方系统对接授权 |
3. 数据库设计要点
3.1 分库分表策略
目标:支撑每日8640万订单,峰值TPS ≥ 1000
| 表名 | 分片键 | 分片方式 | 分片数量 |
|---|---|---|---|
order_master |
order_id(雪花算法生成) |
按order_id % 16分16个库,每库16表 |
共256张表 |
order_item |
order_id |
与主表同库同源(绑定表) | 同上 |
inventory |
sku_id |
按warehouse_id % 4分4库,再按sku_id分片 |
4库×16表=64表 |
coupon_usage |
user_id |
按用户哈希分片,避免热点集中 | 8库×8表=64表 |
✅ 说明 :使用雪花算法生成全局唯一ID,避免DB自增瓶颈;ShardingSphere配置绑定表关联查询。
3.2 核心表结构设计(关键字段示意)
(1)订单主表 order_master
sql
CREATE TABLE `order_master` (
`order_id` BIGINT NOT NULL COMMENT '雪花ID',
`user_id` BIGINT NOT NULL,
`total_amount` DECIMAL(10,2) DEFAULT 0.00,
`pay_amount` DECIMAL(10,2) DEFAULT 0.00,
`coupon_ids` VARCHAR(255) DEFAULT NULL COMMENT '使用的优惠券ID列表',
`status` TINYINT NOT NULL DEFAULT 0 COMMENT '0待支付,1已支付,2发货中...',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` DATETIME ON UPDATE CURRENT_TIMESTAMP,
`expire_time` DATETIME NOT NULL COMMENT '超时关闭时间',
`source_channel` VARCHAR(20) DEFAULT 'app' COMMENT '来源渠道',
PRIMARY KEY (`order_id`),
INDEX idx_user_status (`user_id`, `status`),
INDEX idx_create_time (`create_time`)
) ENGINE=InnoDB;(2)库存表 inventory
sql
CREATE TABLE `inventory` (
`id` BIGINT AUTO_INCREMENT PRIMARY KEY,
`sku_id` BIGINT NOT NULL,
`warehouse_id` INT NOT NULL,
`total_stock` INT NOT NULL,
`available_stock` INT NOT NULL,
`locked_stock` INT NOT NULL DEFAULT 0,
`version` INT NOT NULL DEFAULT 0 COMMENT '乐观锁版本号',
UNIQUE KEY uk_sku_warehouse (`sku_id`, `warehouse_id`)
) ENGINE=InnoDB;🔐 并发更新时使用:
sql
UPDATE inventory SET available_stock = available_stock - 1,
locked_stock = locked_stock + 1,
version = version + 1
WHERE sku_id = ? AND warehouse_id = ? AND available_stock > 0 AND version = ?(3)优惠券使用记录 coupon_usage
sql
CREATE TABLE `coupon_usage` (
`id` BIGINT AUTO_INCREMENT PRIMARY KEY,
`coupon_id` BIGINT NOT NULL,
`user_id` BIGINT NOT NULL,
`order_id` BIGINT DEFAULT NULL,
`status` TINYINT NOT NULL DEFAULT 0 COMMENT '0未使用,1已使用,2已失效',
`used_time` DATETIME NULL,
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY uk_coupon_user (`coupon_id`, `user_id`) -- 防止重复领取
);3.3 缓存设计
| 场景 | 缓存方案 | 更新策略 |
|---|---|---|
| 热点商品库存 | Redis Hash: inv:sku:{sku_id} → {total, available, locked} |
扣减走Redis Lua脚本,异步回刷MySQL |
| 订单状态缓存 | Redis Key: order:status:{order_id} → String(value) |
Kafka监听变更后更新 |
| 幂等Token | Redis Set: idempotent:{token} → EX 600s |
下单前生成Token,防止重复提交 |
| 优惠券规则缓存 | Redis JSON 或 Hash | 规则变更时主动刷新 |
4. 接口设计规范
4.1 设计原则
- 遵循 RESTful 风格,资源命名清晰
- 统一返回格式(JSON)
- 版本控制:URL 中包含
/v1/ - 认证方式:Header 中携带
Authorization: Bearer <token> - 请求幂等性:关键接口需传递
X-Request-ID或业务唯一键
4.2 关键接口定义
(1)创建订单(POST /v1/orders)
json
// Request
{
"userId": 10001,
"items": [
{ "skuId": 20001, "count": 2 },
{ "skuId": 20002, "count": 1 }
],
"coupons": [30001],
"deliveryAddress": "北京市朝阳区...",
"requestId": "req_abc123_xyz" // 幂等标识
}
// Response
{
"code": 0,
"msg": "success",
"data": {
"orderId": "198765432109876543",
"payAmount": 299.00,
"expireTime": "2025-04-05T12:00:00Z"
}
}⚠️ 幂等处理:先检查
requestId是否已存在 → 若存在则直接返回原订单ID
(2)支付回调通知(POST /v1/payments/notify)
json
// 来自微信/支付宝异步通知原始参数透传
{
"channel": "wechat",
"tradeNo": "wx123456789",
"outTradeNo": "198765432109876543",
"amount": 29900, // 单位:分
"status": "SUCCESS",
"sign": "..."
}✅ 处理流程:
- 验签
- 查询订单是否存在且未支付
- 发送「支付成功」事件至 Kafka
- 返回
success(防止重复通知)
(3)查询订单状态(GET /v1/orders/{orderId})
json
// Response
{
"code": 0,
"data": {
"orderId": "198765432109876543",
"status": "PAID",
"items": [...],
"track": [
{ "time": "2025-04-05T10:00:00", "event": "订单创建" },
{ "time": "2025-04-05T10:02:30", "event": "支付成功" },
{ "time": "2025-04-05T10:05:00", "event": "已打包" }
]
}
}📌 数据来源:读取 Elasticsearch 或 Redis Cache View,不查主库!
(4)获取实时库存(GET /v1/inventory/{skuId}?warehouseId=1)
json
// Response
{
"code": 0,
"data": {
"skuId": 20001,
"availableStock": 98,
"isLowStock": false
}
}🔁 数据优先从 Redis 获取,兜底查 DB 并缓存
5. 部署架构建议
5.1 部署拓扑图
Internet
↓
+------------------+
| CDN + WAF | ← DDoS防护、静态资源加速
+------------------+
↓
+------------------+
| Nginx LB | ← 负载均衡,SSL终止
+------------------+
↓
+------------------+ +------------------+
| API Gateway |<--->| Config Server |
| (Spring Cloud) | | (Nacos) |
+--------+---------+ +------------------+
|
+-----v------+ +------------------+
| OrderSvc | | Monitoring Stack |
| PaymentSvc | | (Prometheus + |
| InventorySvc| | Grafana + ES) |
| CouponSvc | +------------------+
+-----+------+ ↑
| |
↓ ↓
+--------v-----------------v---------+
| Kafka Cluster (3节点) |
| Topic: order.created, payment.success, ... |
+------------------------------------+
|
↓
+--------v---------------------------+
| Flink Job Manager (HA) |
| → 实时计算支付成功率、订单趋势 |
+------------------------------------+
|
↓
+--------v---------------------------+
| 数据湖平台 |
| Kafka → Hive (ODS/DWD) |
| → Doris (DWS/ADS) |
+------------------------------------+
|
↓
+--------v---------------------------+
| BI 报表系统 (Superset) |
+------------------------------------+5.2 高可用与容灾设计
| 组件 | HA方案 | 备注 |
|---|---|---|
| 微服务实例 | Kubernetes Pod 多副本 + Horizontal Pod Autoscaler | CPU > 70% 自动扩容 |
| 数据库 | MySQL MHA + 主从复制 + 定期备份 | RPO < 30s, RTO < 5min |
| Redis | Redis Cluster(6节点,3主3从) | 支持自动故障转移 |
| Kafka | 3 Broker + Replication Factor=3 | 消息持久化,防丢失 |
| ZooKeeper | 3节点奇数集群 | Kafka依赖 |
| Nacos | 集群模式(3节点) | CP一致性保证注册中心稳定 |
| Flink | JobManager HA + Checkpoint | At-least-once / Exactly-once语义 |
5.3 网络与安全
- VPC隔离:生产、测试、数据层网络隔离
- 访问控制 :
- DB仅允许内网访问
- Redis/Kafka 加密通信(SASL_SSL)
- 审计日志:所有敏感操作记录到ELK
- 限流保护 :
- Sentinel 设置单IP QPS ≤ 100
- API网关限制
/orders创建接口总QPS ≤ 1200
5.4 CI/CD 与运维建议
| 项目 | 建议 |
|---|---|
| CI/CD工具 | GitLab CI + Argo CD / Jenkins |
| 镜像仓库 | Harbor 私有镜像库 |
| 发布策略 | 蓝绿发布 or 金丝雀发布(配合Nacos权重) |
| 日志收集 | Filebeat → Kafka → Logstash → Elasticsearch |
| 告警机制 | Prometheus Alertmanager → 企业微信/钉钉机器人 |
| 压测方案 | JMeter + Grafana 实施上线前全链路压测(目标:≥1500 TPS) |
附录:关键流程示例 ------ 高并发下单流程
MySQL Redis PaySvc Kafka CouponSvc InvSvc OrderSvc APIGW User MySQL Redis PaySvc Kafka CouponSvc InvSvc OrderSvc APIGW User alt 幂等判断 新请求 POST /orders (含requestId) 调用创建订单 GET requestId 已存在 → 返回已有订单 SET requestId EX 600 NX checkAndLock(skuList) EVAL Lua扣预占库存 success validateCoupons(user, coupons) valid 插入订单(分库分表) send event "order.created" 触发支付链接生成 返回 orderId + 支付信息 {orderId, payUrl, expireTime}
💡 异步后续动作由消费者完成:
- 库存确认失败 → 补偿回滚(释放Redis库存 + 标记订单异常)
- 支付成功 → 更新订单状态 + 推送轨迹事件
总结:SUCCESS 实现路径
| 目标 | 实现手段 |
|---|---|
| 1000 TPS订单写入 | 分库分表 + 异步落库 + Redis缓冲 |
| 防止超卖 | Redis Lua原子扣减 + 乐观锁 + 补偿机制 |
| 多支付接入 | 统一支付网关 + 事务消息最终一致 |
| 实时状态跟踪 | EDA + Kafka + CQRS + ES索引 |
| 数据分析能力 | Binlog → Kafka → Flink → 数仓分层建模 |
| 高可用保障 | 微服务 + K8s + 多活部署 + 全链路监控 |
✅ 结论 :该架构具备高并发、高可用、可扩展、易维护特性,完全满足当前及未来3年业务发展需求,建议按此方案推进实施。
🎯 下一步建议:
- 启动"订单服务"微服务拆分试点
- 搭建Kafka + Canal + Flink实时链路PoC
- 制定分阶段迁移计划(旧系统并行运行3个月)
- 组织团队培训:分布式事务、Kafka原理、Flink编程
文档版本 :v1.0
编写人 :系统架构师
日期 :2025年4月5日
步骤3: 项目实施规划
实施计划完成:# 电商平台订单处理系统项目实施计划
1. 项目概述
本项目旨在构建一个高并发、高可用、可扩展的电商平台订单处理系统,基于微服务架构(DDD)、事件驱动(EDA)、CQRS 和分层数据体系设计。系统需支持每日8640万订单、峰值TPS ≥ 1000,并具备实时状态追踪、库存防超卖、分布式事务一致性保障等核心能力。
本实施计划将围绕以下五个维度展开:
- 开发阶段划分
- 人员配置建议
- 时间节点规划
- 质量保证措施
- 风险应对策略
2. 开发阶段划分
为确保项目可控、迭代交付和风险隔离,采用"渐进式演进 + 分阶段验证 "的开发模式,共分为 6个关键阶段:
| 阶段 | 名称 | 目标 | 输出物 |
|---|---|---|---|
| Phase 1 | 架构验证与PoC搭建 | 验证核心技术链路可行性 | 技术原型、压测报告、决策文档 |
| Phase 2 | 微服务拆分与基础平台建设 | 搭建通用基础设施与首个微服务 | Nacos/Kafka/Flink环境;Order Service上线 |
| Phase 3 | 核心流程闭环实现 | 实现下单→支付→状态查询全链路 | 可运行的核心业务流 |
| Phase 4 | 数据同步与分析链路建设 | 建立实时ETL与OLAP能力 | 数仓模型、BI看板初版 |
| Phase 5 | 全链路压测与优化 | 性能调优至目标指标 | 达到≥1500 TPS的稳定系统 |
| Phase 6 | 灰度发布与旧系统迁移 | 并行运行、逐步切流 | 完整切换方案、监控告警完备 |
详细说明
Phase 1:架构验证与PoC搭建(第1--3周)
- 搭建最小可行技术栈:Kafka + Flink + Redis Cluster + MySQL分片模拟
- 实现两个关键验证点:
- 使用Lua脚本在Redis中实现原子预扣库存并回刷MySQL
- 利用Canal监听binlog写入Kafka,Flink消费后写入Elasticsearch
- 成果输出:《技术选型验证报告》《性能基线测试结果》
✅ 关键成功标准:Redis库存操作无超卖、Flink端到端延迟 < 1s
Phase 2:微服务拆分与基础平台建设(第4--8周)
- 搭建统一开发框架模板(Spring Boot + Alibaba组件)
- 部署生产级中间件集群:
- Nacos注册/配置中心(3节点)
- Kafka集群(3 Broker + SASL_SSL)
- Redis Cluster(6节点)
- Prometheus + Grafana + SkyWalking监控栈
- 开发并部署第一个微服务:Order Service
- 完成API网关接入与JWT鉴权集成
✅ 关键产出:自动化CI/CD流水线、微服务骨架代码库、服务注册发现正常
Phase 3:核心流程闭环实现(第9--14周)
- 开发剩余三大核心微服务:
- Inventory Service(含Redis Lua扣减逻辑)
- Payment Service(对接微信/支付宝模拟器)
- Coupon & Promotion Engine(规则缓存+使用校验)
- 实现事件总线交互:
- 订单创建 → 发布
order.created→ 触发支付链接生成 - 支付成功 → 发布
payment.success→ 更新订单状态 + 推送轨迹
- 订单创建 → 发布
- 实现读写分离视图:
- 查询接口从ES或Redis获取数据,不直连主库
- 完成前端Vue应用基础页面联调
✅ 关键成果:用户可完成"下单→支付→查单"全流程,日志可追溯
Phase 4:数据同步与分析链路建设(第15--18周)
- 配置Canal监听所有核心表binlog,写入Kafka指定Topic
- 部署Flink Job实现:
- 实时统计:QPS、支付成功率、异常订单率
- 流式聚合:按小时维度汇总订单金额
- 构建数仓模型(Hive + Doris):
- ODS层:原始日志
- DWD层:清洗后的明细事实表
- DWS层:轻度汇总宽表
- ADS层:面向BI的报表主题
- 搭建Superset/Grafana可视化看板
✅ 关键产出:运营团队可用BI查看实时交易大盘
Phase 5:全链路压测与优化(第19--21周)
- 使用JMeter进行压力测试:
- 模拟1000并发用户持续下单
- 注入流量覆盖:热点商品、优惠券组合、异常场景
- 识别瓶颈并优化:
- Redis连接池扩容
- ShardingSphere SQL路由优化
- Kafka消费者组并行度调整
- Sentinel动态限流规则配置
- 进行故障演练:
- 模拟数据库宕机 → 验证降级策略
- 消息积压 → 检查重试机制与告警触发
✅ 目标达成:连续3次压测达到 ≥1500 TPS,P99响应时间 < 800ms
Phase 6:灰度发布与旧系统迁移(第22--26周)
- 启动双系统并行运行机制:
- 新老系统同时接收订单(通过网关分流)
- 对账任务每日比对订单一致性
- 实施灰度发布:
- 第一周:5%流量切入新系统
- 第二周:20% → 50% → 80%
- 第四周:100%切换
- 下线旧系统前完成:
- 所有历史数据迁移补录
- 团队培训与运维手册移交
- 应急回滚预案演练一次
✅ 最终交付:新系统独立承载全部订单流量,SLA ≥ 99.95%
3. 人员配置建议
根据项目复杂度和技术广度,建议组建一支 跨职能敏捷团队(Scrum Team) ,共 14人,分角色如下:
| 角色 | 人数 | 职责说明 |
|---|---|---|
| 项目经理(PM) | 1 | 统筹进度、协调资源、风险管理、汇报进展 |
| 系统架构师 | 1 | 技术把关、方案评审、关键技术攻关指导 |
| 后端开发工程师 | 5 | 微服务开发、数据库设计、消息处理、性能优化 |
| 大数据工程师 | 2 | Flink作业开发、数仓建模、Canal/Kafka运维 |
| 前端开发工程师 | 1 | Vue订单页面开发、WebSocket状态推送 |
| 测试工程师(QA) | 2 | 编写自动化测试用例、执行功能/性能/安全测试 |
| DevOps工程师 | 1 | CI/CD流水线搭建、K8s部署、监控告警配置 |
| 安全与合规专员(兼职) | 1(外协) | 审计权限、审查加密通信、协助等保测评 |
📌 建议组织结构:
项目经理
↓
┌────────────┐ ┌────────────┐
│ 后端小组 │ │ 大数据小组 │
│ (5人) │ │ (2人) │
└────────────┘ └────────────┘
↓ ↓
API Gateway Data Pipeline
↓ ↓
┌──────────────────────────────┐
│ 测试/QA │ ← 全流程介入
└──────────────────────────────┘
↑
┌─────────────────┐
│ DevOps + 监控 │
└─────────────────┘💬 团队协作方式:
- 每日站会(Daily Scrum)
- 每两周 Sprint Review + Retrospective
- 技术难题设立"专项攻坚组"(如分布式锁竞争问题)
4. 时间节点规划(总周期:26周 ≈ 6个月)
| 时间段 | 周数 | 主要任务 | 里程碑事件 |
|---|---|---|---|
| W1--W3 | 第1--3周 | PoC搭建与技术验证 | 《技术验证报告》评审通过 |
| W4--W8 | 第4--8周 | 基础设施部署 + Order Service上线 | 微服务框架定型、CI/CD就绪 |
| W9--W14 | 第9--14周 | 四大微服务开发 + 核心流程打通 | 用户可完整下单支付 |
| W15--W18 | 第15--18周 | 数据链路建设 + BI看板上线 | 运营可用Superset查看数据 |
| W19--W21 | 第19--21周 | 全链路压测 + 性能调优 | 达到1500 TPS且稳定性达标 |
| W22--W24 | 第22--24周 | 灰度发布启动(5%→50%) | 完成第一次小范围线上验证 |
| W25--W26 | 第25--26周 | 全量切换 + 旧系统下线 | 正式宣布新系统接管全部流量 |
⏳ 缓冲期预留:在第27周设置为期1周的"应急观察期",用于处理突发问题。
🗓️ 关键检查点(Gate Review):
- W3末:技术选型冻结会议
- W8末:微服务架构冻结
- W14末:核心业务闭环验收
- W21末:性能达标签字确认
- W26末:项目结项评审
5. 质量保证措施
为保障系统高质量交付,建立"预防为主、检测为辅、持续反馈"的质量管理体系。
5.1 代码质量控制
- 强制Code Review制度:Merge Request必须由至少两人审核
- SonarQube静态扫描:阻断严重漏洞(如SQL注入、空指针)
- 单元测试覆盖率要求:
- 核心服务 > 80%
- 工具类 > 90%
- 接口契约测试(Pact)确保上下游兼容性
5.2 自动化测试体系
| 类型 | 工具 | 频率 | 覆盖范围 |
|---|---|---|---|
| 单元测试 | JUnit5 + Mockito | 提交即运行 | 业务逻辑 |
| 接口测试 | Postman + Newman | 每日构建 | REST API |
| 集成测试 | Testcontainers(MySQL/Kafka/Redis) | 每日夜间 | 跨服务调用 |
| 端到端测试 | Cypress(前端)+ Karate DSL | 每周 | 下单全流程 |
| 性能测试 | JMeter + InfluxDB + Grafana | 上线前必做 | TPS/P99/错误率 |
5.3 可观测性保障
- 日志规范:
- 统一日志格式(JSON),包含traceId、requestId、level
- Filebeat采集 → Kafka → ELK集中存储
- 监控指标:
- JVM:GC频率、堆内存使用
- 中间件:Kafka Lag、Redis命中率、MySQL慢查询
- 业务:订单创建成功率、支付回调延迟
- 分布式追踪:
- SkyWalking 实现全链路Trace跟踪,定位瓶颈
5.4 发布质量门禁
每次发布前必须满足以下条件方可上线:
- ✅ 所有自动化测试通过
- ✅ Sonar扫描无Blocker级别问题
- ✅ Prometheus无新增严重告警
- ✅ 压测报告显示无性能退化
- ✅ 安全扫描(OWASP ZAP)无高危漏洞
6. 风险应对策略
| 风险类别 | 具体风险 | 概率 | 影响 | 应对策略 |
|---|---|---|---|---|
| 技术风险 | Redis集群脑裂导致库存错乱 | 中 | 高 | 采用Redis Cluster而非哨兵;加入Redlock双重保护;增加对账补偿任务每日核对 |
| Kafka消息丢失或重复 | 中 | 高 | 设置replication.factor=3;启用幂等生产者;消费者实现去重机制(Redis set + expire) | |
| 分库分表后跨片查询困难 | 高 | 中 | 设计初期规避跨片查询;必要时引入Elasticsearch作为全局索引 | |
| 性能风险 | 下单TPS无法达标 | 高 | 高 | 预设多级缓存(本地缓存+Redis);异步落库;提前进行容量评估与横向扩容预案 |
| 热点Key(如爆款商品)引发Redis瓶颈 | 高 | 高 | 数据打散(加随机后缀);本地缓存+短TTL;限流熔断降级 | |
| 业务风险 | 与旧系统数据不一致 | 中 | 高 | 建立双写期间的自动对账系统;差异数据人工干预通道;保留回滚能力至少1个月 |
| 支付渠道对接失败 | 低 | 高 | 封装统一支付SDK;内置mock模式便于测试;签订SLA协议明确责任边界 | |
| 组织风险 | 核心成员离职 | 低 | 高 | 实施知识共享机制(文档+结对编程);关键模块双人负责制 |
| 团队技能不足(如Flink编程) | 中 | 中 | 安排外部专家培训;引入顾问支持前两周;编写内部开发手册 |
🔁 应急预案清单(Runbook):
- 数据不一致 → 启动对账修复Job
- 消息积压 → 扩容消费者实例 + 告警通知
- DB主库宕机 → MHA自动切换 + 服务降级返回缓存数据
- 系统过载 → Sentinel触发熔断,拒绝非关键请求
附录:下一步行动计划(Week 1重点)
| 任务 | 负责人 | 截止时间 |
|---|---|---|
| 召开项目启动会,明确目标与分工 | 项目经理 | W1周一 |
| 搭建GitLab代码仓库与CI流水线模板 | DevOps | W1周三 |
| 部署Kafka/ZooKeeper/Nacos测试环境 | 架构师 + DevOps | W1周四 |
| 编写《PoC实验计划书》并分配任务 | 架构师 | W1周五 |
| 组织首次技术培训:Kafka原理与Seata事务模式 | 架构师 | W1周五下午 |
总结
本实施计划以架构先行、渐进交付、质量内建、风险可控为核心原则,全面覆盖从技术验证到正式上线的全过程。通过科学的阶段划分、合理的资源配置、严格的质控手段和前瞻的风险预判,确保该高并发订单系统能够按时、按质、安全地投入生产,支撑未来三年电商业务高速增长需求。
✅ 项目口号 :
"稳架构、快迭代、强监控、零事故"
编制人 :项目经理
审核人 :CTO / 架构委员会
版本号 :v1.0
日期 :2025年4月5日
步骤4: 交付清单制定
交付清单完成:以下是基于《电商平台订单处理系统项目实施计划》制定的完整交付清单,涵盖开发完成标准、测试验收标准、部署上线清单、运维监控要求及用户培训计划。所有内容以清晰表格形式呈现,便于项目团队执行与验收。
1. 开发完成标准
| 模块/阶段 | 完成标准 | 验证方式 | 责任人 |
|---|---|---|---|
| Phase 1: 架构验证与PoC搭建 | - Redis原子扣库存无超卖 - Flink消费延迟 < 1s - 技术选型报告评审通过 | 压测日志 + 单元测试结果 + 会议纪要 | 架构师 |
| Phase 2: 微服务基础平台建设 | - Nacos/Kafka/Redis集群部署完成 - Order Service可注册并被调用 - CI/CD流水线自动构建镜像 | 部署检查 + 接口调用验证 + 流水线运行截图 | DevOps + 后端 |
| Phase 3: 核心流程闭环实现 | - 四大微服务(Order/Inventory/Payment/Coupon)代码提交完毕 - 事件驱动链路打通(Kafka消息发布/订阅正常) - 查询接口走ES或Redis不直连主库 | E2E测试通过 + 日志追踪traceId一致性 | 后端 + QA |
| Phase 4: 数据同步与分析链路 | - Canal实时捕获binlog写入Kafka - Flink Job完成流式聚合统计 - Superset看板展示核心指标(QPS、成功率等) | 数据比对 + BI图表可视化确认 | 大数据工程师 |
| Phase 5: 性能压测优化 | - 连续三次压测达到 ≥1500 TPS - P99响应时间 < 800ms - 所有瓶颈已优化并记录 | JMeter报告 + Prometheus监控图 | QA + 架构师 |
| Phase 6: 灰度发布准备 | - 双写机制就绪 - 对账任务每日运行 - 回滚预案演练完成 | 切流模拟 + 对账日志输出 + 演练记录 | PM + DevOps |
✅ 整体开发完成标志 :所有模块代码合并至
main分支,文档归档,技术债务清零(Sonar扫描无Blocker问题)
2. 测试验收标准
| 测试类型 | 验收标准 | 工具/方法 | 通过条件 | 负责人 |
|---|---|---|---|---|
| 单元测试 | 核心服务覆盖率 > 80% 工具类 > 90% | JUnit5 + Mockito + SonarQube | 覆盖率达标且无严重漏洞 | 开发人员 |
| 接口测试 | 所有REST API功能正确 支持JWT鉴权和限流控制 | Postman + Newman自动化脚本 | 自动化套件100%通过 | QA |
| 集成测试 | 跨服务调用稳定 消息传递不丢失、不重复 | Testcontainers模拟中间件环境 | 消息一致性验证通过 | QA + 后端 |
| 端到端测试 | 用户可完成"下单→支付→查单"全流程 | Cypress(前端)+ Karate DSL(后端) | 成功率 ≥ 99.9%,异常场景覆盖完整 | QA |
| 性能测试 | TPS ≥ 1500 P99 < 800ms Kafka Lag < 1000条 | JMeter + InfluxDB + Grafana | 连续3次达标,资源使用合理 | QA + 架构师 |
| 安全测试 | 无高危漏洞(如SQL注入、XSS) 通信加密启用 | OWASP ZAP + 手工审计 | ZAP扫描结果为"Clean" | 安全专员 |
| 故障演练 | 支持数据库宕机切换、消息积压恢复、服务降级 | Chaos Engineering(模拟故障) | 自动告警触发 + 业务影响可控 | DevOps + QA |
✅ 最终验收标志:五大关键门禁全部满足(见质量保证措施),并通过W21末性能达标签字确认会
3. 部署上线清单
| 类别 | 项目 | 描述 | 状态(✅/❌) | 负责人 |
|---|---|---|---|---|
| 基础设施 | Kafka集群(3 Broker + SASL_SSL) | 生产级安全配置,replication.factor=3 | ✅ | DevOps |
| Redis Cluster(6节点) | 支持分片与高可用,开启持久化 | ✅ | DevOps | |
| Nacos集群(3节点) | 注册中心+配置中心双模式运行 | ✅ | DevOps | |
| Prometheus + Grafana | 全链路监控栈部署完成 | ✅ | DevOps | |
| SkyWalking分布式追踪 | traceId贯穿全链路 | ✅ | DevOps | |
| 应用部署 | Order Service 上线 | 可通过API网关访问 | ✅ | 后端 |
| Inventory Service 上线 | Lua脚本预扣库存生效 | ✅ | 后端 | |
| Payment & Coupon Service 上线 | 模拟支付回调成功 | ✅ | 后端 | |
| Gateway接入JWT鉴权 | 访问需Token验证 | ✅ | 后端 | |
| Flink Job运行中 | 实时ETL作业持续消费Kafka | ✅ | 大数据 | |
| Superset/Doris连接正常 | BI看板数据更新频率≤1分钟 | ✅ | 大数据 | |
| CI/CD | GitLab CI流水线就绪 | 提交代码自动构建、打包、推送到镜像仓库 | ✅ | DevOps |
| K8s Helm Chart部署模板 | 支持一键部署各微服务 | ✅ | DevOps | |
| 灰度发布准备 | 流量分流规则配置(5% → 100%) | 网关支持按比例路由 | ✅ | DevOps |
| 双写对账Job定时运行 | 每日比对新老系统订单一致性 | ✅ | 后端 | |
| 回滚脚本与操作手册完备 | 可在30分钟内切回旧系统 | ✅ | DevOps |
📌 上线前最终检查:所有项打勾,经PM、架构师、QA三方签字确认后方可启动灰度发布
4. 运维监控要求
| 监控维度 | 监控项 | 目标值/阈值 | 告警方式 | 工具平台 | 负责人 |
|---|---|---|---|---|---|
| 系统层 | CPU使用率 | < 75%(持续) | 企业微信/钉钉 | Prometheus | DevOps |
| 内存使用率 | < 80% | 同上 | Prometheus | DevOps | |
| JVM GC频率 | Full GC < 1次/小时 | 同上 | SkyWalking | DevOps | |
| 中间件 | Kafka Lag | < 1000条 | 同上 | Prometheus + Burrow | DevOps |
| Redis命中率 | > 95% | 同上 | Redis INFO命令 + Exporter | DevOps | |
| MySQL慢查询数 | < 5条/分钟 | 同上 | Slow Query Log + ELK | DBA | |
| Nacos健康实例数 | 100%在线 | 同上 | Nacos控制台 | DevOps | |
| 应用层 | 接口成功率 | ≥ 99.95% | 同上 | SkyWalking + Prometheus | DevOps |
| P99响应时间 | < 800ms | 同上 | SkyWalking | DevOps | |
| 下单TPS | 实时显示,目标≥1500 | 同上 | Grafana仪表盘 | DevOps | |
| 业务层 | 订单创建失败率 | < 0.05% | 同上 | 日志分析 + 自定义埋点 | QA |
| 支付回调延迟 | 平均 < 2s | 同上 | Kafka Topic延时检测 | 后端 | |
| 异常订单率 | < 0.1% | 邮件日报 | BI看板 + 告警Job | 大数据 | |
| 日志与追踪 | 日志采集完整性 | 所有服务日志进入ELK | ------ | Filebeat + Kafka + ES | DevOps |
| 分布式Trace覆盖率 | 所有请求含traceId | ------ | SkyWalking UI可查 | DevOps | |
| 错误日志关键词监控 | 如"超卖"、"幂等失败"等 | 企业微信告警 | ELK + Watcher | DevOps |
🔔 SLA承诺:
- 系统可用性 ≥ 99.95%
- 故障响应时间 ≤ 15分钟
- 重大问题修复 ≤ 2小时
5. 用户培训计划
| 培训对象 | 培训主题 | 内容概要 | 形式 | 时间安排 | 主讲人 | 输出物 |
|---|---|---|---|---|---|---|
| 运营团队 | 新系统数据查看与使用 | - BI看板功能介绍 - 实时交易大盘解读 - 异常订单筛选与导出 | 线下实操培训 + 案例演示 | W20第3周 | 大数据工程师 | 《BI使用手册V1.0》 |
| 客服团队 | 订单状态查询与问题处理 | - 如何通过新系统查单 - 常见异常状态说明(如待支付、锁定库存) - 工单转接路径 | 视频教学 + 模拟系统练习 | W21第1周 | QA + PM | 《客服操作指南》 |
| 财务团队 | 支付对账与结算逻辑 | - 支付成功标识判断 - 对账文件生成机制 - 补单与退款流程 | 小班讲解 + 文档阅读 | W22第1周 | Payment开发 | 《财务对账说明文档》 |
| IT运维团队 | 系统维护与应急处理 | - 监控平台使用 - 日常巡检项 - 故障排查流程与Runbook操作 | 实战演练 + 沙盘推演 | W23第2周 | DevOps + 架构师 | 《运维手册V1.0》《应急预案清单》 |
| 管理层 | 项目成果汇报与能力展示 | - 架构亮点 - 性能对比(旧 vs 新) - 未来扩展方向 | 汇报会议(PPT+Demo) | W26第4周 | 项目经理 | 《项目总结报告》 |
📘 培训评估机制:
- 每场培训后进行满意度调查(评分≥4.5/5)
- 关键岗位设置"认证考试",合格者颁发上岗证书
✅ 交付总览(Checklist Summary)
| 类别 | 是否完成 | 签字确认 |
|---|---|---|
| 开发工作全部完成 | □ 是 / □ 否 | ___________(PM) |
| 测试验收全部通过 | □ 是 / □ 否 | ___________(QA负责人) |
| 系统成功上线并稳定运行7天 | □ 是 / □ 否 | ___________(DevOps) |
| 运维监控全面覆盖 | □ 是 / □ 否 | ___________(运维主管) |
| 用户培训完成且反馈良好 | □ 是 / □ 否 | ___________(培训负责人) |
| 项目正式结项 | □ 是 / □ 否 | ___________(CTO) |
🏁 交付口号践行 :
"稳架构、快迭代、强监控、零事故" ------ 全体交付团队共勉!
编制人 :交付经理
审核人 :项目经理、CTO
版本号 :v1.0
日期 :2025年4月5日
=== 项目全流程处理完成 ===