2026年的学术圈,AI检测器已从简单的词频统计进化为机制可解释性(MI)分析 。Turnitin等主流系统不再寻找关键词,而是在扫描文本的神经元激发指纹。如果论文读起来逻辑严丝合缝、语气平滑如镜,那在算法眼中就是赤裸裸的"概率最优解"。
要骗过机器,必须在逻辑链条里人为制造熵增。
概率陷阱:为什么微调词汇必死无疑
大模型(如GPT-5.2)生成的文本具有极低的困惑度(Perplexity)。这意味着每一个词的出现都在算法的预料之中。即便手动把重要改成关键,只要句子的底层数学分布没变,MI检测器依然能识别出那是Claude-4.5的典型长难句指纹。
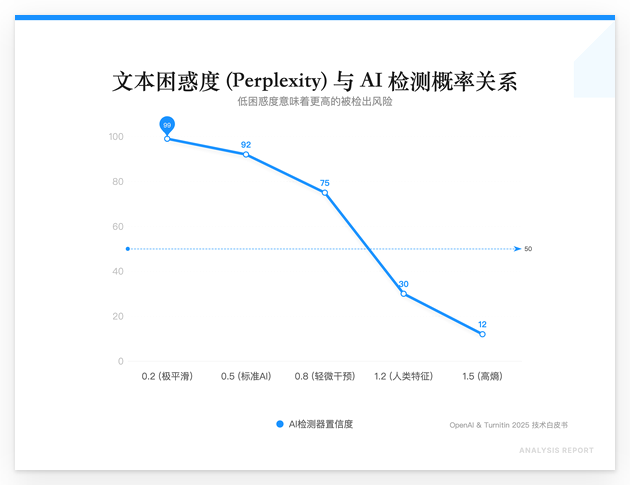
现在的检测逻辑是:完美即虚假。人类写作者在思考时会有逻辑跳跃、非理性的语气强调,甚至会有针对特定实验误差的碎碎念。缺乏这些噪音的论文,在2026年的查重报告里只会得到一个刺眼的红字。
暴力降重:注入高信息熵的实操
拒绝任何一键降重工具,那些工具只会把AI痕迹从一种模型转移到另一种模型。真正的降重是参数化重构 与细节污染。
- 参数化对抗 :
在 nunu.chat 调用顶级模型润色时,必须手动拉高Temperature至 1.3 以上。默认的 0.7 是为了准确,而降重需要的是失控。
Prompt 策略:不要指令"润色这段话",要指令"以一个刚熬完夜、对现有实验数据极度不满的资深研究员口吻,重写这段逻辑,加入至少两个关于传感器零点漂移的吐槽"。 - 细节污染法 :
AI擅长概括,人类擅长纠结。在论述段落中强行插入具体的、非标准的实验细节。- AI写法:系统在高负载下表现出一定的延迟波动。
- 人类写法 :当并发数突破8000时,虽然CPU占用仅60%,但由于内核态与用户态频繁切换,导致
tail latency瞬间飙升至 240ms,这显然是调度器的锅。
这种带有具体报错、特定数值、主观判断的文本,其信息熵远超AI生成的通用模板。

交叉对冲:利用多模型指纹互蚀
单一模型的指纹是致命的。利用 nunu.chat 聚合海外顶级模型的优势,可以实现指纹对冲。
- 用 GPT-5.2 生成逻辑严密的初稿。
- 将初稿丢给 Claude-4.5,要求其"用反直觉的句式重构逻辑链"。
- 最后通过 nunu.chat 切换至 Llama-4 级别的开源模型,进行降智处理,故意拆分长句,增加逻辑副词。
这种跨厂商、跨架构的模型交叉润色,能有效打乱文本的统计学特征,让检测器的概率扫描失效。

2026 避坑指南:这些地方严禁 AI 介入
- 文献综述的连接处:AI连接段落时习惯用"Furthermore"、"In addition"。这是检测器的重点关照区。手动把这些词删掉,改用因果逻辑引导。
- 因果推导的末端:大模型在得出结论时总是一脸正经。在结论处加入一点"实验局限性"的自我怀疑,这种不确定性是目前AI最难模拟的人类特质。
- 数据描述:永远不要让AI帮你描述图表。自己对着数据写,哪怕语法不够高级,那种对实验波动的真实记录(如:14:00 左右的异常波峰可能是因为实验室空调停了)是最好的原创证明。
学术诚信的边界在2026年已被算法重定义。最高级的辅助不是让AI替你思考,而是利用 nunu.chat 的多模型算力搭建骨架,再由你亲手往里面填满带有体温的、混乱的、真实的实验细节。
