什么是transformer
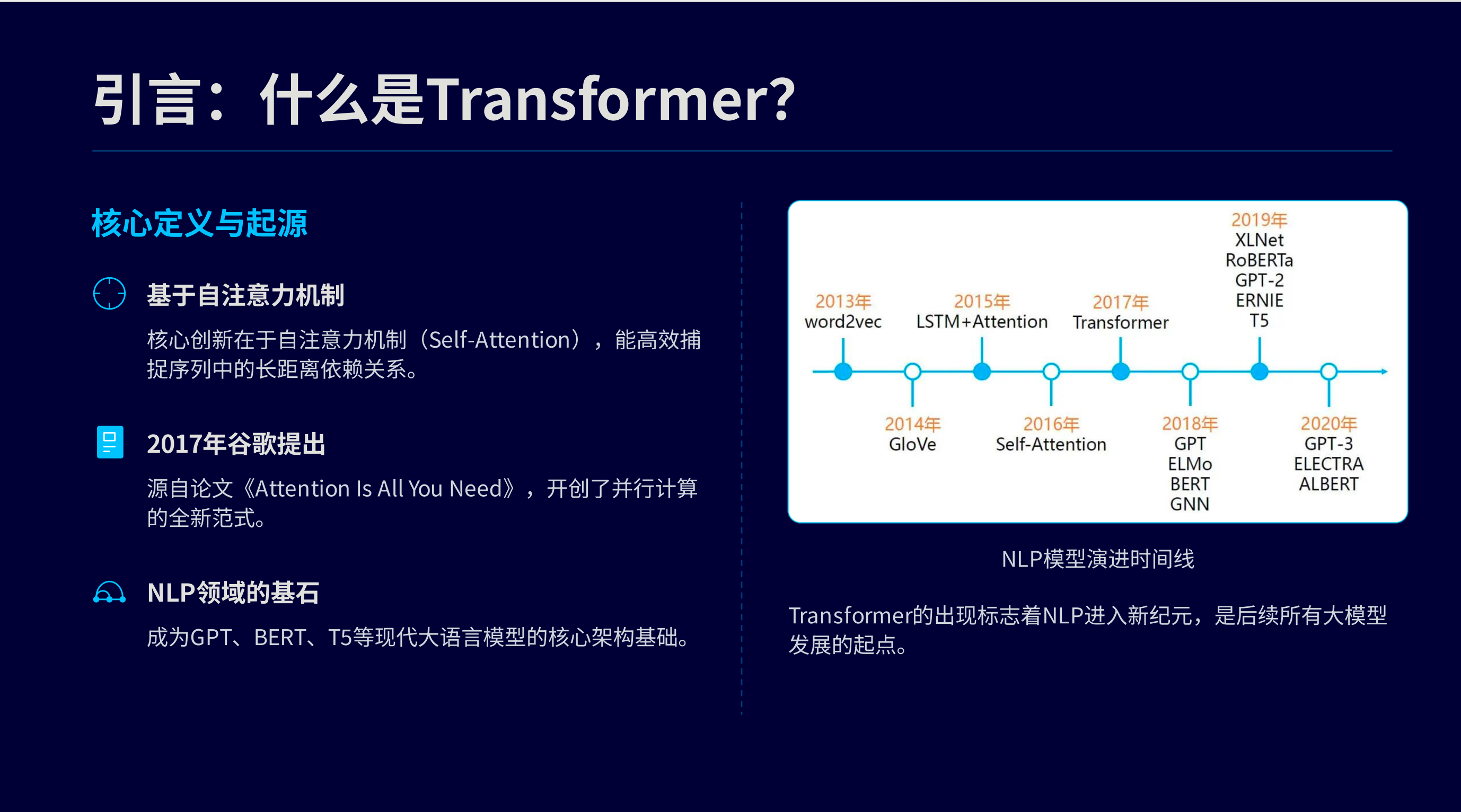
transformer的具体流程
- transformer 会多语句进行拆词
- 通过向量化模型,将词进行向量化,并加入位置编码代表词在句子中的位置
- 随后再进入由6层堆叠而成的编码器,每一层都包括1. 多头注意力机制用来捕捉句子不同位置之间的关联关系。2. 以及前馈神经网络,用来对特征进行非线性转换。3. 层与层之间通过残差连接和层归一化来保证信息稳定流动
- 接下来进入由六层堆叠而成的解码器。
- 最后解码器的输出经过线性映射跟softmax操作进而转化为词的概率分布,再从中选出概率最高的词作为模型的最终预测结果
分词与向量化
分词就是直接用分词器,分好的一个词就是一个token。
实际生产中会将多个句子打包一起处理,这个时候会转化为同等维度的矩阵(token数需要一样),但分词之后的语句token数并不一样, 此时分词数不够的会在末尾补全padding(对应于多维中的0)
transformer的核心机制 - 自注意力机制
自注意力机制解决的问题是:类似于多义词,不同的文字在不同的语境下是不同的意思
一句话总结做的事情 :
让每个token结合上下文去理解自己的含义,实际上是去计算输入的不同token 之间的的关联度(权重)是多少
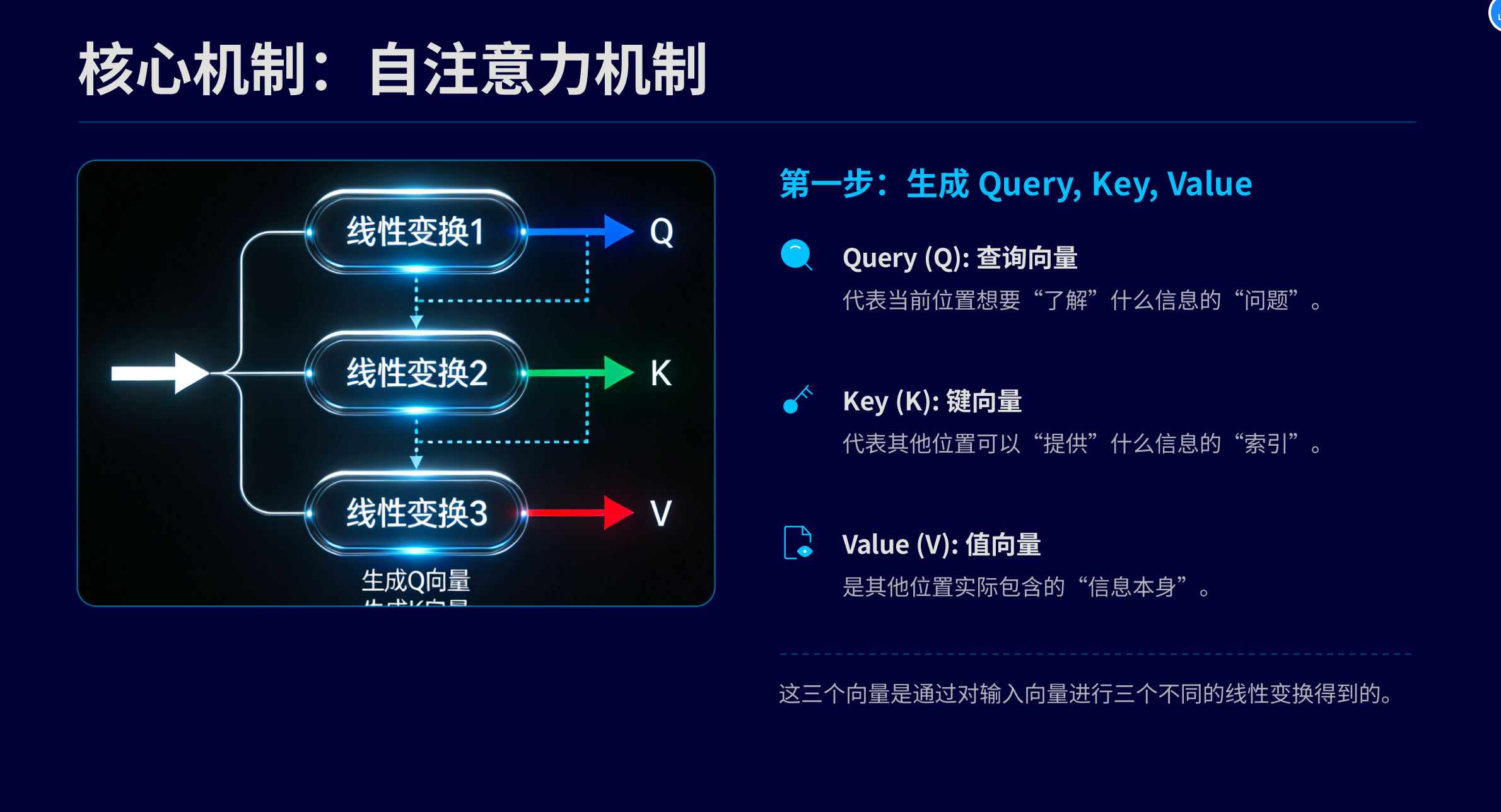
注意力机制中的QKV
- Q(查询):当前需要处理的信息
- K(键):是指来自输入序列的一组表示
- V(值):是指来自输入序列的一组表示
其实就是拿输入的向量去跟 模型随机生成的Q,K,V三个矩阵 去生成三个矩阵值。
而这个矩阵值其实就会拿到token之间的关系,每个token的语义了。
会在后续的残缺网络,归一化,前馈网络等多个流程中使用

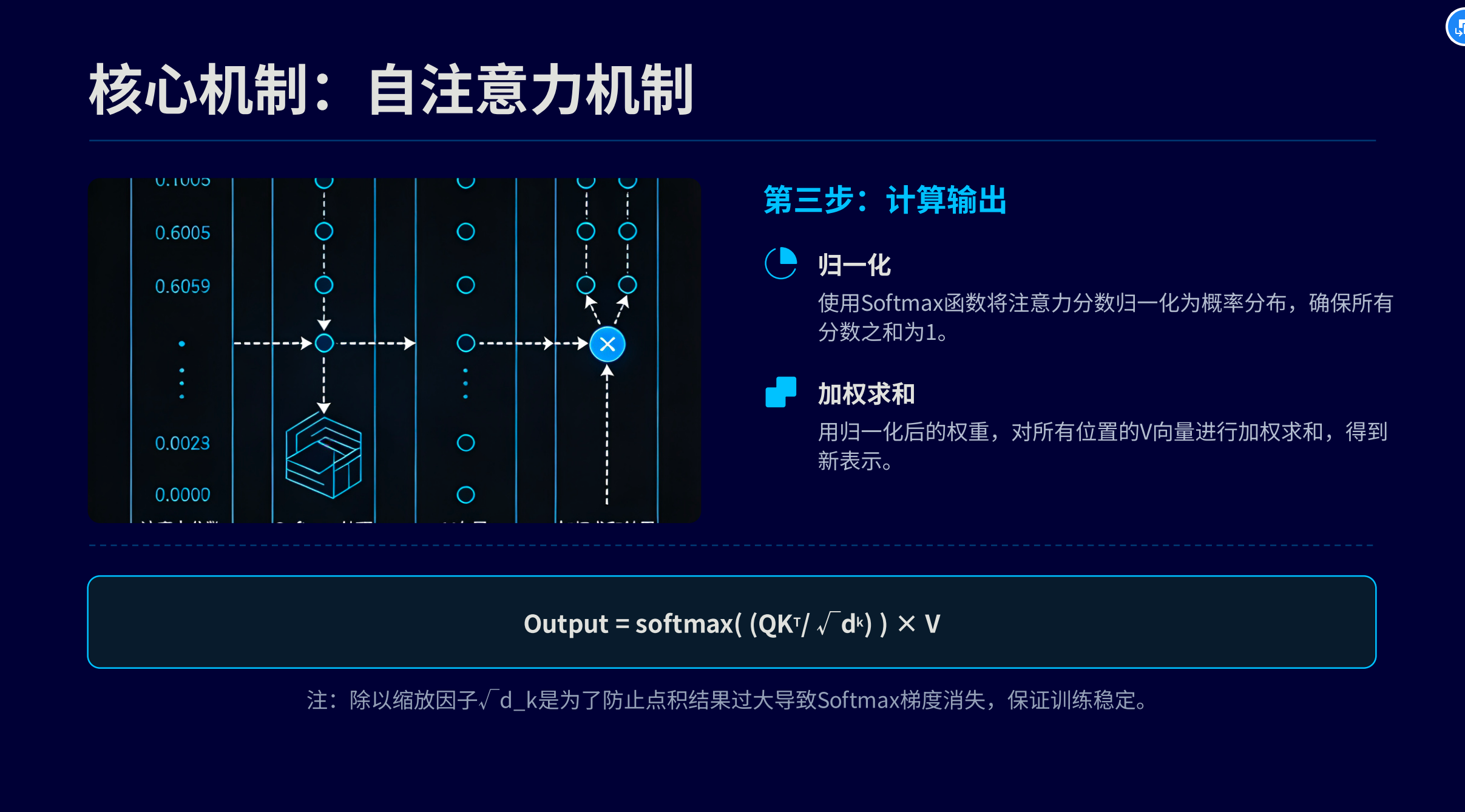
缩放点积注意力
做的事情很简单,就是把输入的因子进行简单缩放,通过多次缩放去确定最终的矩阵函数,这么做是怕输入的部分因子误差过大,导致最后的函数失去预测的特性
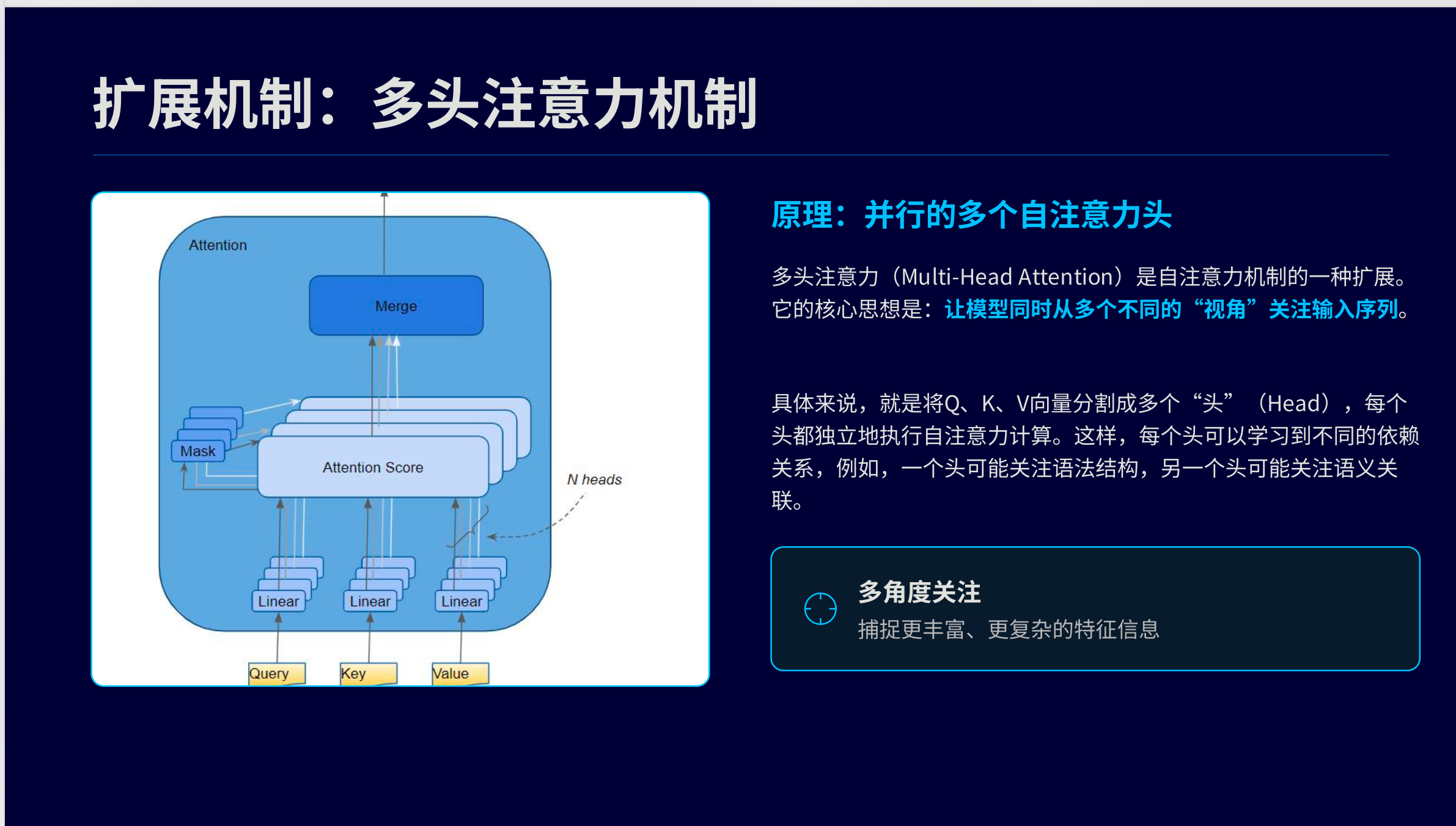
多头注意力机制
ADD(残差网络)和Norm(归一化)
- 残差网络是指在算出来的注意力的结果会跟原始的输入相加,以达到确保token自身的信息不会被覆盖掉
- 残差网络后,为了让权重数值保障在0-1之间,模型会对结果进行一次简单调整,这一步叫归一化(避免偏差过大)
FFN(前馈网络)
- 前馈网络是将猜想函数从线形变为非线形的核心步骤
- 在经过残差连接跟归一化处理后,函数跟token的走势其实还是个线形函数,前馈网络会通过激活函数将线形的映射掰弯,变为非线形的曲线。
- 其实原理就是在线形函数 y=ax+b 上的外层去匹配各种曲线数学函数,比如 y=sin(ax+b), 去看token是否匹配走势,通过这种方式去猜想走势
- 每次FFN后还需要再做一次 ADD&Norm
编码器是什么
- 一次 (多头注意力+ Add&Norm + FFN+FFN后的Add&Norm)这种行为构成一次编码层
- 执行一次编码层,模型对输入就会进行一次语义理解,多次执行,模型对输入理解就会加深
- 多个编码层组层一个编码层
- 他编码层的输出是向量,代表一串汉字输入对应的数字表现形式
翻译原理
- 其实就是拿编码器去做相似匹配,看下一个更贴合的输出是啥,拿到输出后再拿输入+拿到的输出看后面的输出是啥更匹配
- 像以token为单元素的,近似匹配的成语接龙
解码器是什么
- 解码器做的事情跟编码器很像,但是不同的是,他用翻译原理去做输出生成
- 编码器做理解,解码器去做生成,生成好的向量再转文字即可
- transformer中编码器跟解码器并不需要共同存在,比如Bert只需要编码器,ChatGpt只需要解码器即可