文章目录
前言
接下来我将以MySQL为例来讲述什么是数据库、如何使用数据库(主要)。
什么是数据库
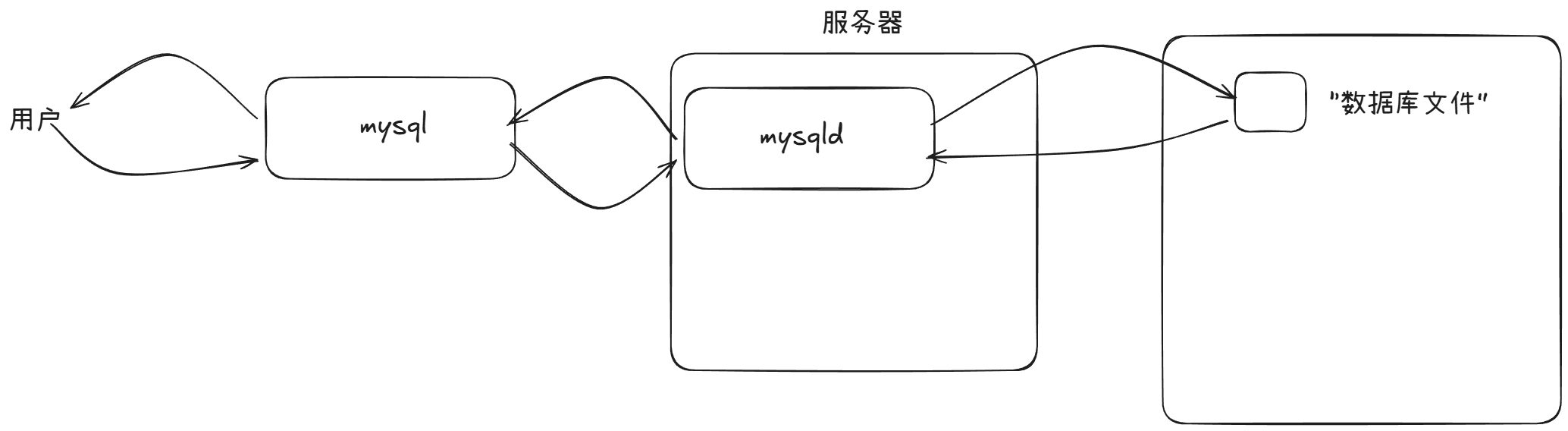
我们在Ubuntu下载mysql的时候会分别下载mysql和mysqld:

- mysql是数据库服务的客户端
- mysqld是数据库服务的服务端
- mysql的本质:基于C(mysql)S(mysqld)模式的一种网络服务
我们来验证一下:
可以看到mysqld确实是一个服务端,已经和端口号3306(mysql的默认端口号)建立连接,并且套接字处于监听状态。
所以说mysql就是一套给我提供数据存取的服务的网络程序。
数据库一般指的是,在磁盘或者内存中存储的特定结构组织的数据,具体定义:
数据库是按照数据结构组织、存储和管理数据的系统,支持高效的数据访问和管理。常见类型包括关系型数据库(如MySQL、Oracle)和非关系型数据库(如MongoDB、Redis)。
我们的mysqld就是数据库服务。
那么问题来了,文件不是已经提供了数据的存储功能了,为什么还需要数据库呢?
这是因为文件存储有以下缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
可以看到文件系统对用户层面 的数据操作不是特别便利,没有给用户提供良好的数据管理能力。
数据库本质上就是要提供一套对数据存储的解决方案,输入字段或者要求,就直接返回结果:
初步使用数据库
首先在默认配置文件:/etc/mysql/mysql.conf.d/mysqld.cnf中
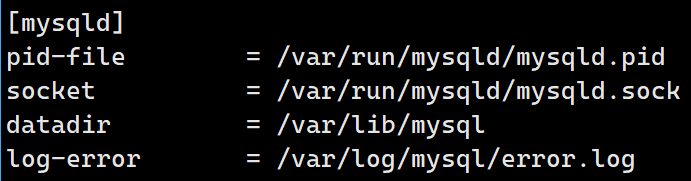
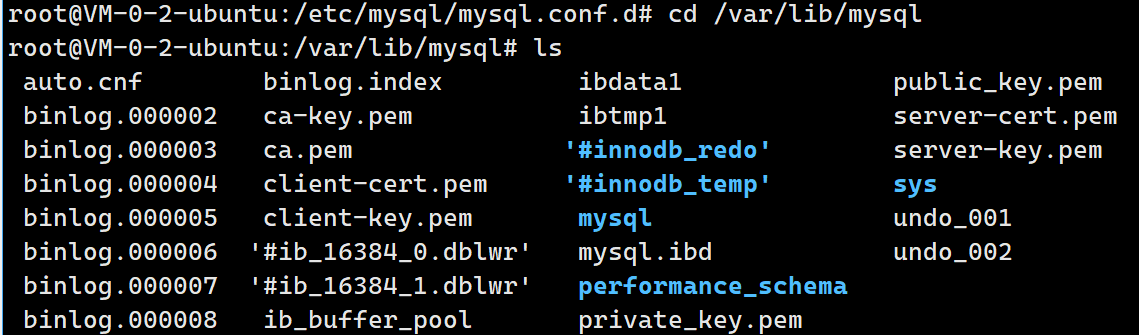
datadir就标注了默认创建的数据库位置,我们进入查看一波:

可以看到我们的访问被拒绝了
可以看到,普通用户是完全没有权限的,因此我们要用root身份进入:
那么我们现在要登录mysql并创建数据库了,mysql的登录指令是:
shell
mysql -h 127.0.0.1 -P 3306 -u root -p这里就是要输入服务端的ip和端口号,-u代表用户,-p则是密码。
实际上我们在本地登录可以省略前面部分:
shell
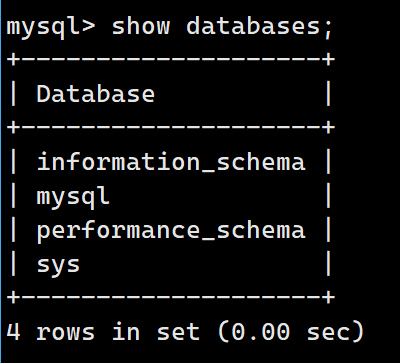
mysql -uroot -p登录后可以输入show databases; 来查看已经存在的数据库:
创建数据库
输入
sql
create database helloworld;来创建数据库:
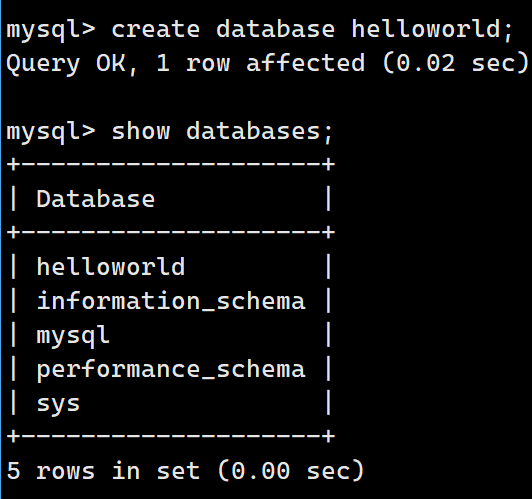
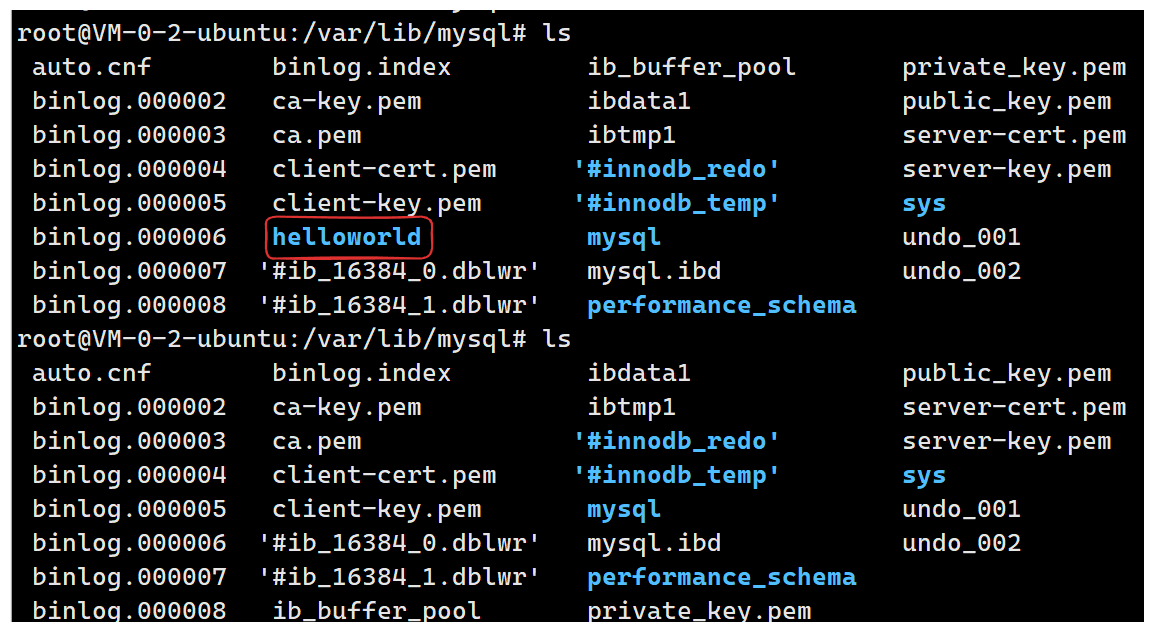
可以看到我们确实创建了一个新的数据库,这是再查看/var/lib/mysql:
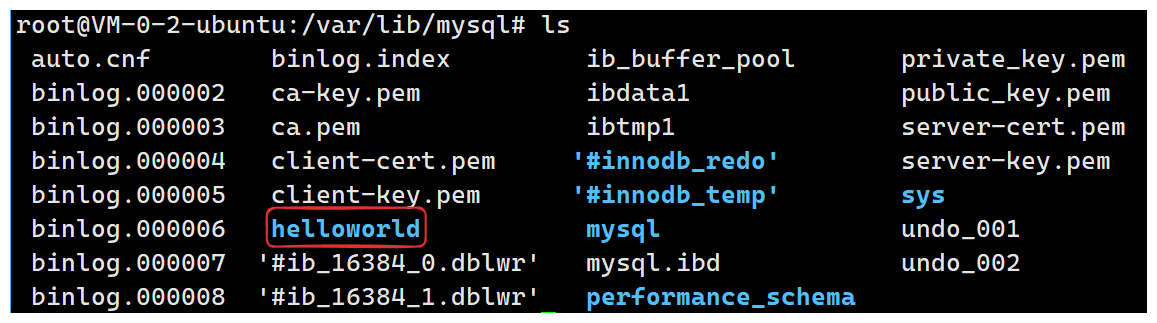
可以看到多了一个helloworld目录,因此创建数据库本质就是创建一个目录 。
我们来查看里面有什么:

可以看到现在暂时是空的。
创建数据库表
接下来使用数据库,输入指令:
sql
use helloworld;所谓使用数据库就是代表接下来的指令都在这个数据库中执行。
创建数据库表:
sql
create table student(
id int,
name varchar(32),
gender varchar(2)
);类似C++中的类,我们数据库表要有表名(类名),属性(id、name、gender),属性数值类型(int、varchar)。
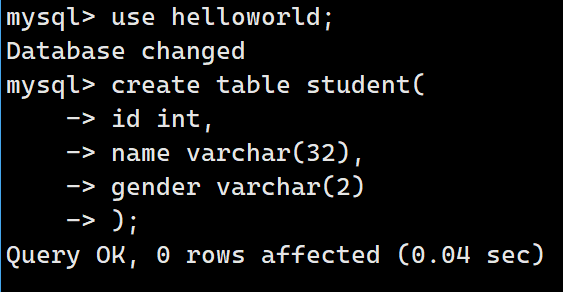
这时再查看/var/lib/mysql/helloworld:

可以看到多了一个文件。里面是二进制存储的一堆数据。
现在我们向表中插入数据:
sql
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
insert into student (id, name, gender) values (3, '王五', '男');然后输入指令查询表的数据:
sql
select * from student;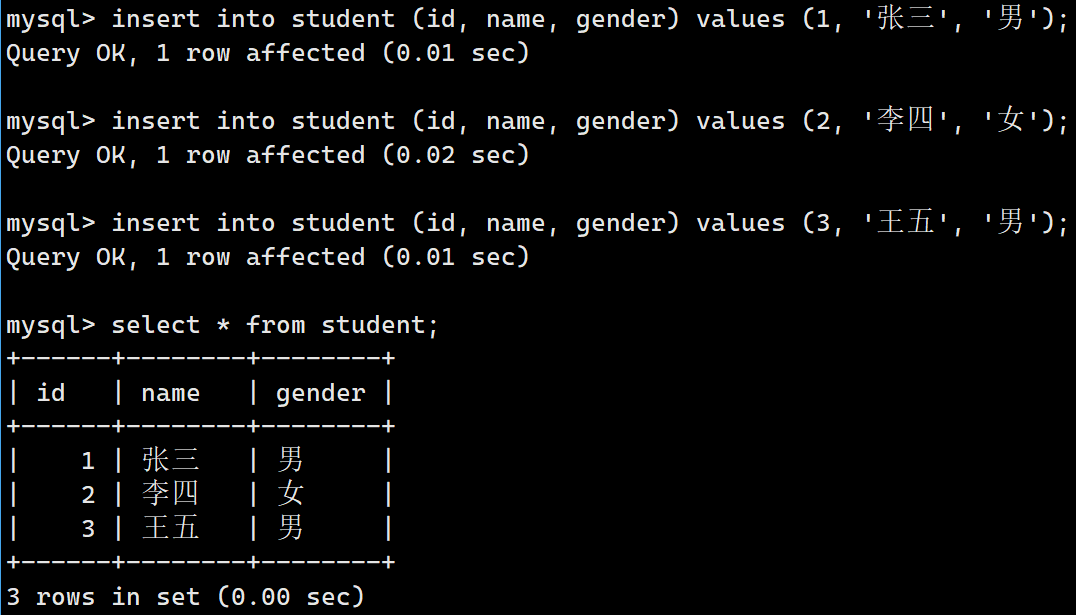
这就是一个数据库的大概创建过程。
接下来我们可以输入:
sql
drop database helloworld;来删除刚刚创建的数据库,可以看到输入指令之后,刚刚创建的目录就没有了:
最后我们输入quit或者\q就能退出数据库:

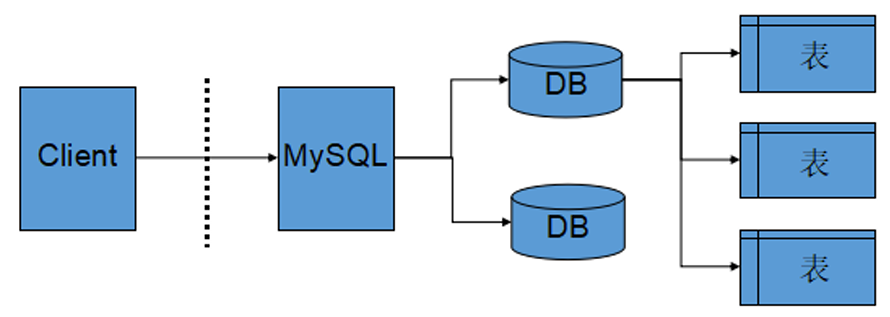
服务器,数据库,表关系
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
- 数据库服务器、数据库和表的关系如下:
主流数据库
- SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
- Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
- MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
- PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
- SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
- H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
其中使用范围最广的就是MySQL。
MySQL架构
既然知道MySQL是一个网络程序,那么我们看看他实现的具体架构:
包含
包含
包含
包含
包含
包含
包含
包含
包含
包含
包含
包含
实现
实现
实现
包含
包含
建立连接
调用存储引擎
持久化数据
<<layer>>
ClientLayer
客户端连接层:提供多语言/协议接入能力
ClientConnectors
+supportJDBC() : : void
+supportODBC() : : void
+supportPHP_Python() : : void
+connectToServer() : : Connection
<<layer>>
ServerCoreLayer
服务端核心层:统一处理SQL与连接,不直接存储数据
<<sublayer>>
ConnManagementSubLayer
连接管理子层:认证/安全/连接池
ConnectionPool
+manageConnections() : : void
+authentication(User) : : boolean
+securityCheck() : : void
<<sublayer>>
SQLProcessSubLayer
SQL处理子层:接收/解析/优化SQL
SQLInterface
+receiveSQL(String sql) : : void
+supportDML_DDL() : : void
+supportStoredProcedure() : : void
Parser
+lexicalAnalysis() : : void
+syntaxAnalysis() : : void
+generateExecCode() : : ExecutableCode
Optimizer
+rewriteQuery() : : void
+optimizeScanOrder() : : void
+selectBestIndex() : : Index
<<sublayer>>
CacheSubLayer
缓存子层:查询结果缓存
QueryCache
+globalCache : Map
+engineCache : Map
+getCache(String key) : : ResultSet
+updateCache(String key, ResultSet data) : : void
<<sublayer>>
ServiceUtilSubLayer
工具服务子层:备份/复制/安全等
ServicesUtilities
+backupRestore() : : void
+replication() : : void
+securityManagement() : : void
+partition() : : void
<<layer>>
StorageEngineLayer
存储引擎层:数据实际存储/读取
<<interface>>
StorageEngine
+storeData(Data) : : void
+readData(Query) : : ResultSet
InnoDB
+supportTransaction() : : void
+supportForeignKey() : : void
+rowLevelLock() : : void
MyISAM
+highReadPerformance() : : void
+tableLevelLock() : : void
+noTransaction() : : void
MemoryEngine
+inMemoryStorage() : : void
+temporaryData() : : void
<<layer>>
StorageLayer
底层存储层:数据持久化到文件系统
FileSystem
+supportNTFS_Ext4() : : void
+storeFile(File) : : void
LogsFiles
+binlog : BinaryLog
+redoLog : RedoLog
+undoLog : UndoLog
+dataFile : DataFile
+indexFile : IndexFile
MySQL 采用分层式模块化架构,核心分为 4 层,各层职责清晰且解耦:
| 层级 | 核心组件 | 核心职责 |
|---|---|---|
| 客户端连接层 | 多语言连接器(JDBC/ODBC 等) | 提供不同编程语言/协议与 MySQL 服务端的通信能力,是应用访问 MySQL 的入口。 |
| 服务端核心层 | 连接池、SQL 接口、解析器等 | 统一处理连接、SQL 解析优化、缓存、权限认证,是 MySQL 的 "大脑",不直接存储数据。 |
| 可插拔存储引擎层 | InnoDB/MyISAM 等引擎 | 负责数据的实际存储、读取,不同引擎适配不同业务场景(如 InnoDB 支持事务)。 |
| 底层存储层 | 文件系统、日志/数据文件 | 将数据持久化到磁盘,通过各类日志保证数据安全与恢复能力。 |
SQL分类
SQL(Structured Query Language,结构化查询语言) 是客户端与关系型数据库(如 MySQL、Oracle、PostgreSQL)交互的统一语言,用于实现对数据库的 "定义、操作、查询、控制" 等全生命周期管理,是关系型数据库的 "通用接口"。
那么SQL可以分成:
-
DDL【data definition language】数据定义语言,用来维护存储数据的结构
代表指令: create, drop, alte
-
DML【data manipulation language】数据操纵语言,用来对数据进行操作
代表指令:insert,delete,update
-
DML中又单独分了一个DQL,数据查询语言
代表指令:select
-
DCL【Data Control Language】数据控制语言,主要负责权限管理和事务
代表指令:grant,revoke,commit
存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
我们可以输入指令:
sql
show engines;来查看存储引擎:
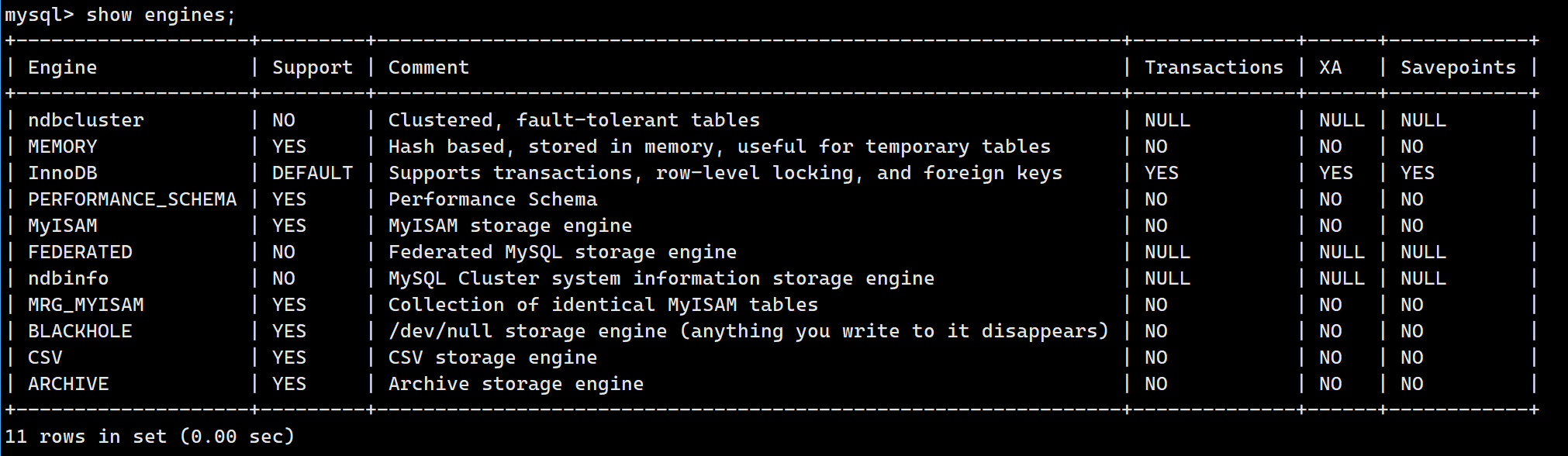
其中最常用的就是InnoDB。