1 概述
1.1 方案背景
随着云原生、微服务和容器化架构在企业级应用中的广泛落地,系统规模和复杂度持续提升,监控对象已从单一基础设施扩展至应用、业务层面。Prometheus 作为云原生生态中事实上的监控标准,在指标采集、存储和基础查询方面表现出色,已被大量企业用于构建监控体系的基础设施层。
然而在实际生产落地过程中,企业逐渐发现,仅依赖 Prometheus 原生告警体系难以满足复杂业务场景下的监控与告警需求。主要体现在:
告警规则的管理与治理成本持续攀升。Prometheus 告警规则以 YAML 文件形式分散配置,随着业务系统和监控指标数量的增长,规则文件数量迅速膨胀。规则修改往往依赖人工排查与运维流程,难以频繁调整,也不利于跨团队协作,最终逐渐演变为难以维护的"配置负债"。
复杂规则难以驾驭。Prometheus 支持通过向量运算对多个指标进行联合判断,但其本质仍是基于时间序列的集合匹配。随着指标来源和业务复杂度增加,多个指标采集器(exporter,将被监控系统的状态转换为 Promthemus 的 metric) 的数据往往在时间上是不对齐的,metric 需要进行聚合与对齐处理(即在 yaml 编写清洗逻辑),导致规则可读性和可维护性迅速下降。
此外,监控数据本身也具有较高的分析价值,但 Prometheus 不具备高性能的分布式存储与计算能力,企业难以对大量历史监控数据进行长期存储和分析。
1.2 DolphinDB 规则引擎监控方案
本文设计并实现一套简洁、高效的集成方案,将 Prometheus 的监控数据与 DolphinDB 规则引擎深度融合,构建易于运维管理、高性能的监控体系。核心目标如下:
- 实时监控与告警一体化:通过规则引擎对监控指标进行实时计算,插件快速集成企业现有告警体系。
- 架构轻量与高性能:规则引擎每秒可处理高达百万级别的规则判断, 有效应对企业大量实例的监控需求。同时不引入其他中间件,降低监控系统复杂性与资源消耗。
- 数据长期存储与深度分析:可将监控数据、告警数据持久化存储至 DolphinDB 分布式数据库,支持长期趋势分析、容量规划与运维工作复盘分析。
- 易于运维管理:规则在 DolphinDB 中集中式的管理,通过脚本语言 Dlang 编写。监控规则支持热更新,能够极大地提升监控规则的管理效率。
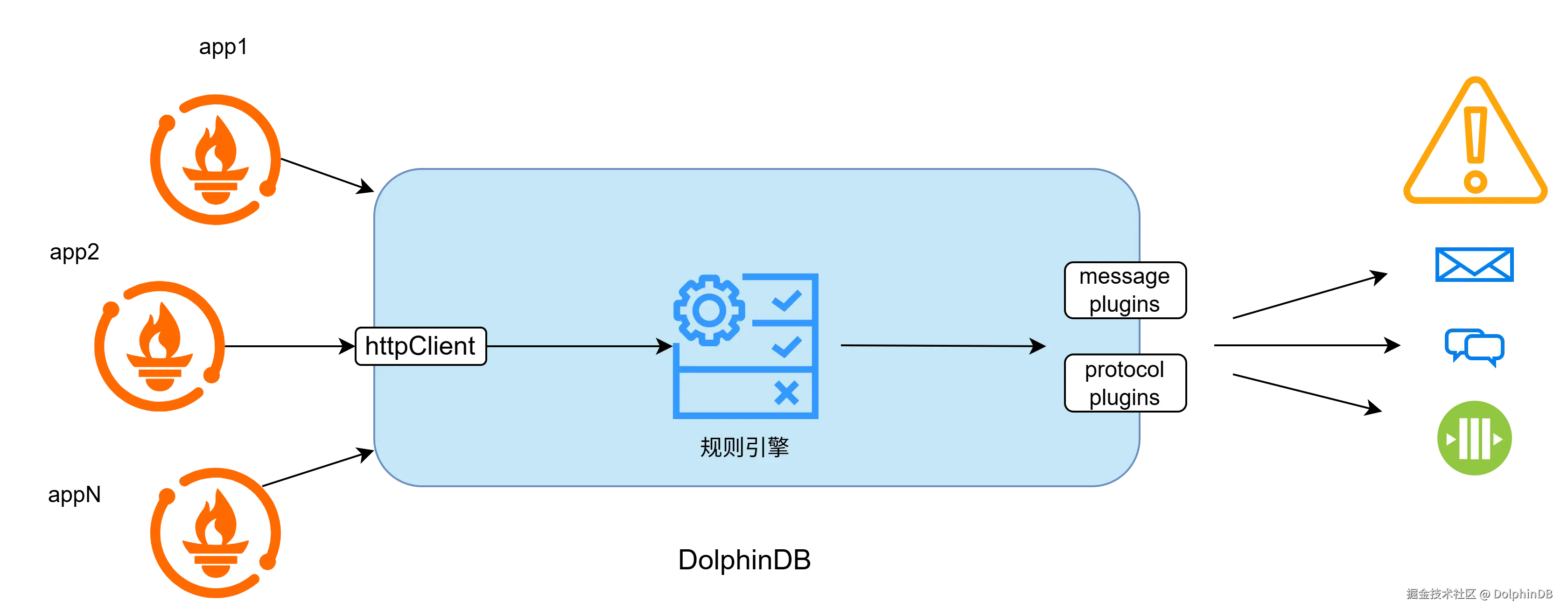
图 1-1:以规则引擎为核心的监控架构图
总而言之,用户可在 DolphinDB 中实现从实时告警到长期数据分析的端到端监控解决方案,进一步提升系统的可观测性与运维效率。
2 Prometheus 监控指标同步
HttpClient 插件支持调用 Prometheus HTTP API,实时获取监控指标数据。HttpClient 插件的具体使用方法请参考插件文档:HttpClient。经过简单的数据格式转换后,监控指标数据便可直接写入至 DolphinDB 分布式表或流表。
2.1 Prometheus HTTP API 简介
Prometheus 提供了一套稳定的 HTTP API ,用于查询和操作时间序列数据。所有的 API 响应均返回 JSON 格式数据。以下为该 API 核心功能简介,详细介绍可以参见链接:HTTP API | Prometheus - Prometheus 监控系统 。以下简要介绍下相关接口以便更好地应用 HTTPClient 插件同步数据。
2.1.1 HTTP API 基础信息
根路径:/api/v1
状态码:
- 当请求正确执行时,返回 2xx
- 当参数缺失或不正确时,返回 400 Bad Request
- 当表达式无法执行时,返回 422 Unprocessable Entity
- 当查询超时或中止时,返回 503 Service Unavailable
响应格式:JSON,响应封装格式如下
kotlin
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only set if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"],
// Only set if there were info-level annotations while executing the request.
"infos": ["<string>"]
}2.1.2 即时查询
以下端点在单个时间点进行查询。
bash
GET /api/v1/query
POST /api/v1/queryURL 查询参数:
- query=:Prometheus 表达式查询字符串。
- time=<rfc3339 | unix_timestamp>:可选参数,查询时间戳,如果省略 time 参数,则使用当前服务器时间。。
- timeout=:可选参数, 查询超时限制。
- limit=:可选参数, 返回的最大序列数。
⚠️ 重要说明:时间参数处理
由于 Prometheus 内部统一以 UTC 时间存储所有时序数据,大部分客户端的执行环境,都将时区设置为本地时间。因此在构造查询请求时需要进行时间转换,具体转换方式取决于您使用的客户端工具:
- curl 命令:需要在命令行中手动将本地时间转换为 UTC 时间。例如,将北京时间 "2025-11-10 16:14:27" 转换为 UTC 时间 "2025-11-10T08:14:27Z" 后传入。
- DolphinDB HTTP Client :DolphinDB 默认使用本地时间(如东八区)进行数据处理和查询,当查询某个时间点的指标时,可以利用内置的时间函数(gmtime)转换成 UTC 后传入。从 promethus 取出数据进行告警规则处理时,也需要转换为本地时间(localtime)。
示例:在时间 2025-11-10T08:14:27Z (UTC 时间)查询指标 lastMinuteNetworkRecv。
erlang
curl 'localhost:9090/api/v1/query?query=lastMinuteNetworkRecv&time=2025-11-10T08:14:27Z'返回:
vbnet
text: '{
"status":"success",
"data":{
"resultType":"vector",
"result":[
{
"metric":{
"__name__":"lastMinuteNetworkRecv",
"instance":"host:port",
"job":"DolphinDB"
},
"value":[1762762467,"1952900"]
}
]
}
}'
elapsed: 0.001651
headers: 'HTTP/1.1 200 OK Content-Type: application/json Vary: Origin Date: Mon, 10 Nov 2025 08:51:03 GMT Content-Length: 193 '
responseCode: 2002.1.3 范围查询
通过 query_range 端点查询一段时间范围的数据,Prometheus 定义了查询的"分辨率"(指是数据采集和存储的粒度),最大单次查询单时间序列最多返回 11000 条。
bash
GET /api/v1/query_range
POST /api/v1/query_rangeURL 查询参数
- query, limit, timeout 参数与即时查询相同,这里不再赘述。
- start=<rfc3339 | unix_timestamp>:开始时间戳,包含在内。
- end=<rfc3339 | unix_timestamp>:结束时间戳,包含在内。
- step=<duration | float>:查询步长,格式为 duration 或以秒为单位的浮点数。
示例:在时间 2025-11-10T08:14:00 至 2025-11-10T08:15:00 范围内,以 15s 为步长查询表达式 lastMinuteNetworkRecv。
erlang
curl 'localhost:9090/api/v1/query_range?query=lastMinuteNetworkRecv&start=2025-11-10T08:14:00Z&end=2025-11-10T08:15:00Z&step=15s'返回:
vbnet
text: '{
"status":"success",
"data":{
"resultType":"matrix",
"result":[
{
"metric":{
"__name__":"lastMinuteNetworkRecv",
"instance":"host:ip",
"job":"DolphinDB"
},
"values":[
[1762762440,"1985379"],
[1762762455,"1952832"],
[1762762470,"1952900"]
]
}
]
}
}'
elapsed: 0.001218
headers: 'HTTP/1.1 200 OK Content-Type: application/json Vary: Origin Date: Mon, 10 Nov 2025 09:03:54 GMT Content-Length: 242 '
responseCode: 2002.2 Promethus 数据同步案例
若本地尚无可用的监控数据,可参考 启用 Prometheus 持续监控 DolphinDB Server 文档,对 DolphinDB 实例进行监控以生成样例数据。
2.2.1 批量历史数据导入
首先创建 TSDB 引擎表存储监控数据,按月分区(数据量大的可以改为按日分区),以监控指标做为 sortKey,完整代码请见附件 metricData.dos。
sql
//drop database if exists "dfs://metricDB"
create database "dfs://metricsDB"
partitioned by VALUE(2025.10M..2025.11M)
engine="TSDB"
create table "dfs://metricsDB"."data"(
metric_name SYMBOL[comment="监控指标"],
timestamp TIMESTAMP[comment="监控时间戳",compress="delta"],
value DOUBLE[comment="监控值"],
instance SYMBOL[comment="监控实例"],
job SYMBOL[comment="Promethus job 名称"]
)
partitioned by timestamp
sortColumns = `metric_name`timestamp以抓取历史 1 天的数据为例
ini
// 加载插件,每次启动服务器仅需加载一次
loadPlugin("httpClient");
// url:符合Prometheus的查询规范
// 查询过去7天lastMinuteNetworkRecv指标的全部数据,Prometheus默认采样频率为15s故 step=15s
//1. 发送请求
url = 'localhost:9090/api/v1/query_range?query=lastMinuteNetworkRecv&start=2025-11-09T08:15:00Z&end=2025-11-10T08:15:00Z&step=15s'
res = httpClient::httpGet(url)请求返回一个字典,包含键 responseCode, header, elapsed, text,在本案例中返回示例如下:
rust
text: '{"status":"success","data":{"resultType":"matrix","result":[{"metric":{"__name__":"cpuUsage","instance":"host:port","job":"DolphinDB"},"values":[[1764576480,"0"],[1764576495,"0"],[1764576510,"0"]]}]}}'
elapsed: 0.0021
headers: 'HTTP/1.1 200 OK Content-Type: application/json Vary: Origin Date: Fri, 05 Dec 2025 04:33:34 GMT Content-Length: 211 '
responseCode: 200实际的数据返回值为键 text 所对应的 STRING 类型值,内容以 JSON 格式组织。需要将 STRING 类型的返回数据作为元代码执行并解析,方便数据转换及存储。另外,Prometheus 默认返回的时间戳为整型,时间戳起点为 1970.01.01,单位为秒,这里通过 temporalAdd 函数将其转换为 DolphinDB 的时间类型 TIMESTAMP。
scss
//2. 构造解析模板
str = '{
"metric":{
"__name__":"lastMinuteNetworkRecv",
"instance":"host:9001",
"job":"DolphinDB"
},
"values":[[1,2]]
}'
d3 = parseExpr(str).eval()
d2=dict(STRING, ANY)
d2["resultType"]="matrix"
d2["result"]=[d3]
d1=dict(STRING, ANY)
d1["status"]="success"
d1["data"]=d2
res2 = parseExpr(res.text, d1).eval()
//3. 解析并组装数据
res3 = res2.data.result[0]
res4=res3.values.transpose()
metricDict=res3.metric
ts = temporalAdd(timestamp(1970.01.01), res4[0], "s")
val = res4[1].double()
n = val.size()
data = table(take(metricDict["__name__"], n) as metricName,
localtime(ts) as timestamp,
val as value,
take(metricDict["instance"], n) as instance,
take(metricDict["job"], n) as job
)
//4. 写入分布式表
pt = loadTable("dfs://metricsDB","data")
tableInsert(loadTable("dfs://metricsDB", "data"), data)3 集成 DolphinDB 规则引擎与 Prometheus
3.1 数据库资源监控方案
本案例实现了 DolphinDB 服务器 CPU 使用率、内存占用、磁盘空间和网络流量等硬件资源实时监控。通过 Prometheus 自动采集 cpuUsage, memoryUsed, diskFreeSpaceRatio 等关键指标,结合 DolphinDB 规则引擎设置阈值告警,及时发现资源瓶颈并预警,确保数据库服务的稳定运行。
告警规则示意:
cpuUsage > 90
diskFreeSpaceRatio < 0.1
networkRecvRate > 10000000整体采用流数据表 + 分布式表的双层存储架构,分别实现了实时数据处理、历史数据存储。流数据表做为规则引擎的输入及输入缓冲层, 这种设计提高了系统的并发性能,也增强了数据消费层的扩展性。
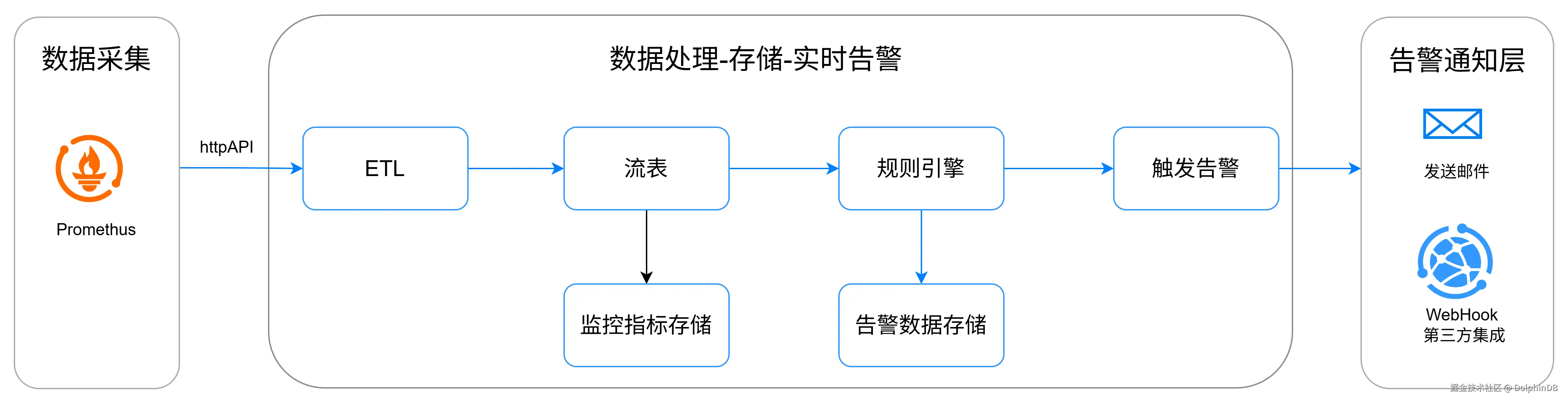
图 3-1:监控数据流程图
3.2 程序实现
程序主要分为三部分,分别完成 Promethus 监控数据接入与 ETL,规则引擎创建与输出告警,监控规则的热更新。
3.2.1 监控数据接入 DolphinDB 流表
ini
// 定义表结构
colName = `metricName`timestamp`value`instance`job;
colType = [SYMBOL, DATETIME, DOUBLE, STRING, STRING];
// 创建dataReceiveTable流表并持久化,接收实时抓取的数据
enableTableShareAndPersistence(
table=streamTable(1000:0, colName, colType),
tableName=`dataReceiveTable,
cacheSize=1000000
);
// 创建dfs数据表,保存规则引擎处理后数据
create table "dfs://metricsDB"."warn"(
metric_name SYMBOL,
timestamp TIMESTAMP,
value DOUBLE,
instance SYMBOL,
job SYMBOL,
rule BOOL[]
)
partitioned by timestamp
sortColumns = `metric_name`timestamp这里采用定时轮询的方式获取服务器硬件资源数据,共定义两个相关函数 query 和 pullData。轮询的方式能够最大程度减少对监控目标端的倾入性(更加符合监控轻量化的诉求)。
- query: 用于发送即时查询请求并将 response HTTP 报文解析成 table 类型的数据。
- pullData:调用 query 函数定时轮询 Prometheus Server 以获取数据。
参数 metrics 是一个包含了所要查询硬件资源的参数名的字符串向量,interval 为轮询的时间间隔(秒),建议与 Prometheus 配置文件中的 scrape interval 设置保持一致。
ini
loadPlugin("httpClient");
def dict2Table(dataDict){
v = dataDict.value
metricDict=dataDict.metric
ts = timestamp(long(v[0]*1000))
val = v[1].double()
return table(
take(metricDict["__name__"], 1) as metricName,
localtime(ts) as timestamp,
val as value,
take(metricDict["instance"], 1) as instance,
take(metricDict["job"], 1) as job
)
}
def query(host, port, metrics){
url = host + ":" + port + '/api/v1/query'
params = {
query: metrics
}
res = httpClient::httpGet(url, params)
rst = parseExpr(res.text).eval()
allMetrics = select instance, timestamp, metricName, value, job
from each(dict2Table, rst.data.result).unionAll()
order by instance, metricName
return allMetrics
}
// 定义实时数据抓取函数,interval 可与 Prometheus 数据抓取间隔设置一致
def pullData(host, port, metrics, table, interval=15){
do{
data = query(host, port, metrics)
tableInsert(table, data)
sleep(interval*1000)
}while(true)
}
//请根据你的监控需求替换变量值
host = "192.198.1.36"
port = 9090
metrics = '{__name__=~"cpuUsage|diskFreeSpaceRatio|networkRecvRate"}'
targetTable = objByName("metricsStream")
jobId = stringFormat("pullPromethus_%W_%i", host, port).strReplace(".", "_")
submitJob(jobId, "get Promethus metrics", pullData, host, port, metrics, targetTable)
图 3-2:拉取的监控指标
3.2.2 DolphinDB 规则引擎监控预警
DolphinDB 规则引擎是一个简洁、高效、可扩展的规则检查与告警模块,支持对监控规则的集中化运维(新增、修改、删除),能够极大地提升运维效率。
DolphinDB 规则引擎会将插入的数据根据用户预先定义的规则集进行标记,将标记后的数据输出至指定数据表,并调用回调函数,根据用户自定义逻辑处理被标记的数据。具体用法请参考 createRuleEngine。
在本案例中,ruleSets 初始化如下:
scss
// 初始化ruleSet
index = array(SYMBOL, 0)
index.append!(`cpuUsage`diskFreeSpaceRatio`networkRecvRate NULL)
rule = [[<value > 90>], [<value < 0.1>], [<value > 10000000>], [<value == NULL >]];
ruleSets = dict(index, rule);回调函数中可实现数据清洗、数据写入、数据告警等逻辑。在本案例中,示例提供了两种告警推送方式:发送邮件告警和企业微信机器人告警。读者可根据实际应用场景,结合 DolphinDB 消息/协议插件集成企业现有告警体系。
- 使用 DolphinDB httpClient 插件向邮箱发送告警邮件
ini
def send2Email(result){
if(result.rule[0]){
text = stringFormat("服务器 %W 服务/资源 %W %W 告警, 当前值:%.2f",
result.instance[0], result.job[0], result.metricName[0], result.value[0])
res = httpClient::sendEmail('MailFrom@xxx.com','password','MailDestination@xxx.com','数据告警', text);
}
}- 使用 DolphinDB httpClient 插件向企业微信机器人发送告警信息,并由企业微信机器人将告警信息推送至目标群聊。
ini
// url 为企业微信机器人 Webhook 地址,采用 UUID 来标识其唯一的推送目标
def send2Wechat(result){
if(result.rule[0]){
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=yourUUidKey"
header = "Content-Type: application/json"
warnMsg = stringFormat("服务器 %W 服务/资源 %W %W 告警, 当前值:%.2f",
result.instance[0], result.job[0], result.metricName[0], result.value[0])
params = stringFormat("{'msgtype': 'text', 'text': {'content': '%W'}}", warnMsg)
httpClient::httpPost(url, params, 1000, header)
}
}最终,通过 subscribeTable 函数订阅流数据表并消费数据。
ini
// 创建规则引擎
colName = `metricName`timestamp`value`instance`job;
colType = [SYMBOL, DATETIME, DOUBLE, STRING, STRING];
dummy = table(1:0, colName, colType)
ruleEngine = createRuleEngine(
name="ruleEngine",
ruleSets=ruleSets,
dummyTable=dummy,
outputColumns=`metricName`timestamp`value`instance`job,
outputTable=loadTable("dfs://metricsDB", "warn"),
policy="all",
ruleSetColumn="metricName",
callback=send2Wechat
)
subscribeTable(
tableName="dataReceiveTable",
actionName="write2ruleEngine",
handler=getStreamEngine("ruleEngine"),
msgAsTable=true,
batchSize=10000,
throttle=3
)请注意: 本教程示例假设告警事件的频率为"秒级",这通常符合大部分应用场景。若实际场景中告警消息的密度非常大(例如每秒产生上千条告警),由于 callback 是同步执行的,不建议在 callback 中直接调用 I/O 相关函数。此时可通过 outputTable 写入告警结果到流表,再订阅该流表,并在 handler 中实现告警推送逻辑。
初始化引擎后执行 getStreamEngineStat() 查看引擎状态。

图 3-3:规则引擎状态监控
引擎的输出(outputTable)包含了原始的监控信息及判断结果 rule, rule 是一个布尔类型的 array,通过 rule0 = true 筛选其中超过阈值的数据。
sql
select * from loadTable("dfs://metricsDB", "warn")
where rule[0] = true
order by timestamp desc limit 100
图 3-4:筛选报警数据
3.2.3 规则集热更新
满足随着监控工况的变化,如容器硬件资源的扩缩容、业务负载变化,监控阈值需要动态调整。DolphinDB 规则引擎支持在线动态规则调整,通过 updateRule 和 deleteRule 两个函数实现规则运行时新增、修改、删除。
监控规则更新案例
调用 updateRule在线更新 CPU 的阈值为 85(百分比)。
erlang
updateRule("ruleEngine","cpuUsage",[<value>85>])更新后,再插入一条新时间戳的数据。
csharp
ruleEngine.append!(table("cpuUsage" as metric_name, datetime(2025.12.01 10:00:00) as timestamp, 88.0 as value, "localhost:8848" as instance, "DolphinDB" as job))
getRules(["ruleEngine"])
图 3-5:更新后的规则
修改后,规则引擎成功输出了新的告警信息。

图 3-6:更新后的告警信息
4 总结
本文通过集成 Prometheus 与 DolphinDB,利用规则引擎的高效实时计算与规则热更新能力,实现了监控告警的集中化, 架构简洁、运维便捷。有效解决传统方案中规则分散难管理,线上规则调整成本高,以及监控与长期存储脱节的问题。支撑企业级应用的稳定运行与持续演进。