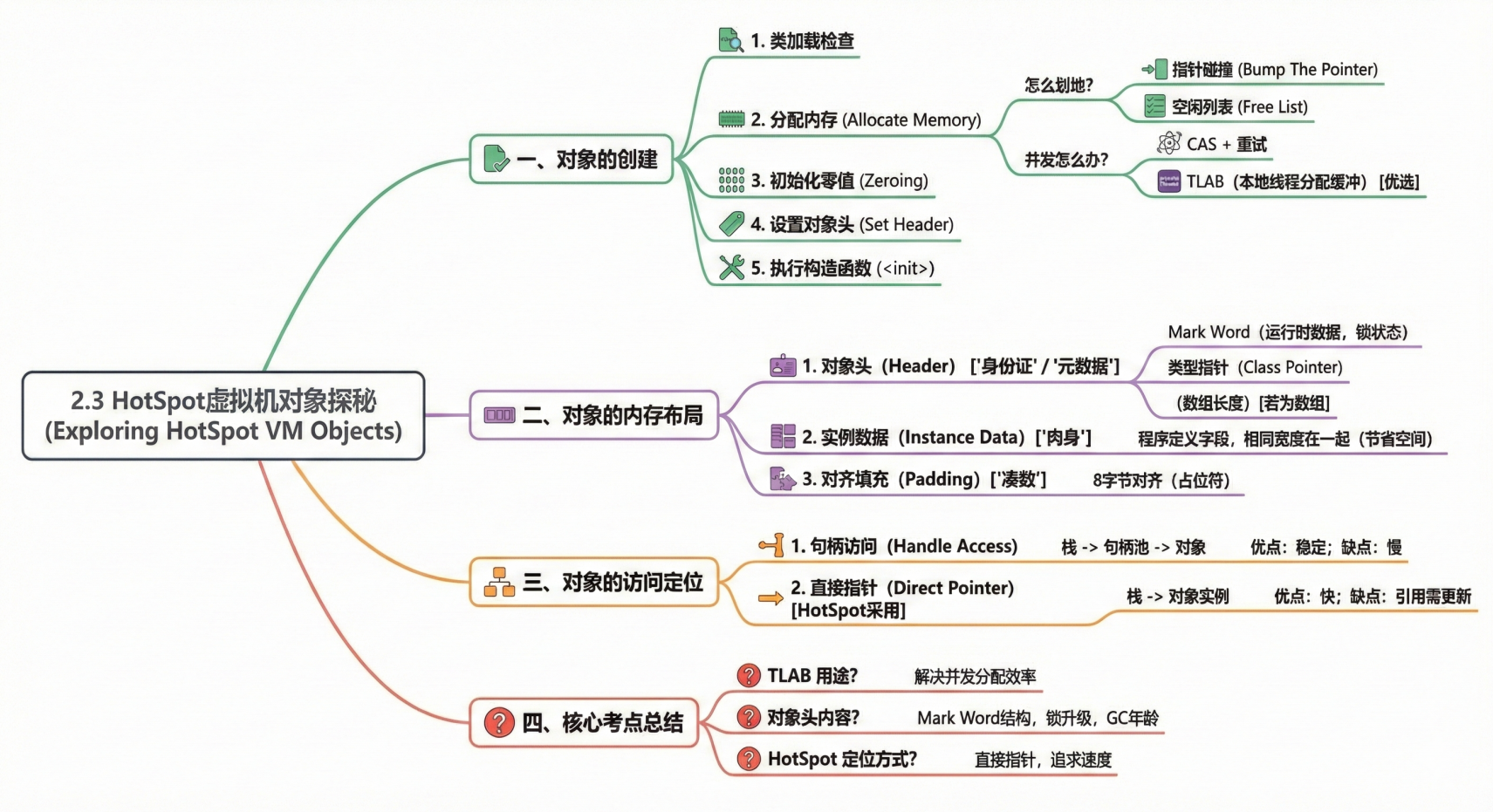
我们可以把这节内容拆解为三个核心步骤来理解:
第一步:对象的创建 (Object Creation)
当你在代码里写下 new Object() 时,JVM 内部发生了一系列复杂的操作:
-
类加载检查 (Class Load Check)
-
JVM 遇到
new指令,先去检查:这个类加载了吗?解析了吗?初始化了吗? -
如果没有,必须先执行类加载(这是第7章的内容)。
-
-
分配内存 (Allocate Memory)
-
对象所需的大小在类加载完成后就是确定的。JVM 需要从 Java 堆中划出一块地给它。
-
怎么划地? 取决于堆内存是否规整(即垃圾收集器是否带有压缩整理功能):
-
指针碰撞 (Bump The Pointer):如果内存规整(用过的在一边,没用的在另一边),中间有个指针。分配内存就是把指针往空闲那边挪一下。简单高效。(适用于 Serial, ParNew 等收集器)。
-
空闲列表 (Free List):如果内存乱糟糟的(已用和空闲交错),JVM 就得维护一张表,记录哪块地是空的。分配时查表找一块够大的。(适用于 CMS 这种基于清除算法的收集器)。
-
-
并发怎么办? 很多人同时
new对象,抢地盘怎么办?-
CAS + 重试:原子操作,失败了就重试,保证更新指针的安全性。
-
TLAB (本地线程分配缓冲):这是优选方案。给每个线程在堆里预先开一个小灶(私有缓冲区),线程要创建对象先在自己的小灶里分配,不用抢。用完了才去争抢公共堆空间。
-
-
-
初始化零值 (Zeroing)
-
内存分好了,JVM 会先把这块内存(不含对象头)全部刷成 0。
-
这就是为什么 Java 类的字段可以不赋初值就能直接使用(int 是 0,boolean 是 false)。
-
-
设置对象头 (Set Header)
-
给对象贴标签:它是哪个类的?它的哈希码是多少?它的 GC 年龄是几岁?
-
此时,从 JVM 视角看,对象已经创建完毕了。
-
-
执行构造函数 (<init>)
- 从 Java 程序视角看,才刚刚开始。执行构造方法,按照程序员的意愿把对象组装好。
第二步:对象的内存布局 (Memory Layout)
在 HotSpot 虚拟机中,一个对象在内存中主要分为三部分:
-
对象头 (Header): 对象的"身份证"和"元数据"。
-
Mark Word:存储运行时数据。比如 HashCode、GC分代年龄、锁状态(轻量级锁、偏向锁等)。这部分非常精妙,它是一个动态结构,根据对象状态不同,里面存的内容也不同,以此来节省空间。
-
类型指针 (Class Pointer):指向它的类元数据,表明"我是谁的实例"。
-
(如果是数组,还会记录数组长度)。
-
-
实例数据 (Instance Data): 对象的"肉身"。
-
就是你在类里定义的各种字段(int a, String b...)。
-
存储规则:为了节省空间,相同宽度的字段会放在一起(比如 long 和 double 放一起,int 放一起)。这也是为什么父类的变量可能出现在子类变量之前。
-
-
对齐填充 (Padding): 凑数的。
- HotSpot 要求对象的大小必须是 8字节的整数倍。如果不够,就得填充空白字节补齐。就像打包快递,盒子必须是标准尺寸,装不满就塞泡沫。
第三步:对象的访问定位 (Access Positioning)
我们在栈上(Stack)只有一串引用(Reference),怎么通过这个引用找到堆(Heap)里的对象实体?主流有两种方式:
-
句柄访问 (Handle Access)
-
机制:堆里划分一块"句柄池"。Reference -> 句柄 -> (对象实例地址 + 对象类型地址)。
-
优点 :稳定。对象被 GC 移动时(这在 Java 中很常见),只需要改句柄里的地址,栈上的 Reference 不用动。
-
缺点 :慢。多了一次指针定位的开销。
-
-
直接指针 (Direct Pointer) ------ HotSpot 采用的方式
-
机制:Reference -> 对象实例。
-
优点 :快。少了一次中转。
-
缺点:对象移动时,Reference 必须跟着改。
-
总结
这一节的核心考点通常在于:
-
TLAB 是做什么的?(解决并发分配内存的效率问题)
-
对象头里有什么?(Mark Word 的结构,锁升级会用到)
-
HotSpot 怎么定位对象?(直接指针,追求速度)