1.强化学习什么都学不到?
遇到这个问题,首先要确定是否是真的什么都学不到,还是训练不够,看似少量训练什么都学不到。因此进行强化学习过程中,我们最好是使用多环境,多线程同时训练。因为强化学习仿真环境多为cpu运行,因此我们的仿真环境可以是多核环境。
运行的环境数量为 cpu数量。多环境运行,效率拉满,以我本机为例。开了24个进程同时进行数据采集。这么一个方式大大提高了运行效率。
很多小白运行强化学习过程中,可能看到学了几天发现算法不收敛,以为是不work,但可能是因为训练不够,算力不够导致。所以建议强化学习尽量把性能拉满试验。
2.强化学习batch_size和n_steps的关系?
n_steps表示采集的经验数量,如果环境是24,同时采集,那么储存的经验相当于单环境的24倍,就如同鸣人的影分身一样,经验谁着分身数增多,而增大采集。经验池大小:512*24,是batch_size:2048的6倍作用,batch_size增大有利于学习稳定性。
以PPO算法为例:
PPO_PARAMS = {
"n_steps": 512,
"ent_coef": 0.05,
"learning_rate": 0.00025,
"n_epochs":8,#8, # 每个更新周期遍历 10 次
"batch_size": 2048,
"gamma" : 0.95,
"gae_lambda" : 0.95,#0.7,#0.9,
"clip_range" : 0.2
}
3.在面对序列数据的时候,到底是mlp更容易过拟合还是lstm更容易过拟合?
在提取序列数据方面,mlp方面更容易过拟合,因为mlp方面它比较难找出序列先后之间的关系,那么mlp在找不到相关关系,但又想要提高强化学习奖励,往往采用的措施就是把他们通通都记住。所以mlp在处理序列方面比lstm容易过拟合。这也是导致强化学习为什么泛化能力差的主要原因。
4.强化学习泛化能力差?
训练集表现很好,验证集表现很差,这是典型的过拟合。过拟合解决方案1.正则化,2.dropout。但是这两个方法往往效果都不佳。
过拟合解决能力:正则化效果>dropout
强化学习一般不使用dropout。因为加入dropout后效果一般难以收敛,因为不稳定。即使稳定了效果也很一般。
正则化视情况而定,如果效果不好,则不要继续使用。
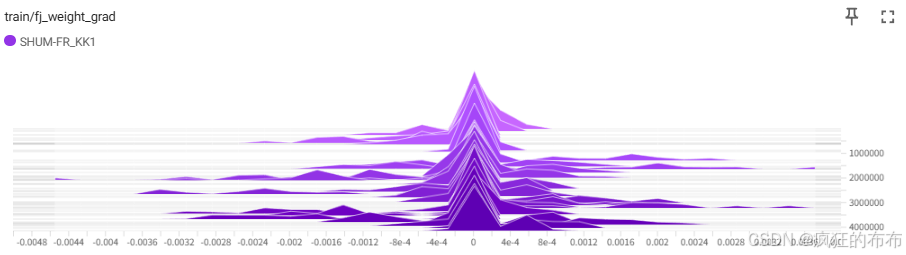
正则化滥用有可能导致欠拟合。我们可以通过监测价值函数的梯度去查看是否是产生了欠拟合。如果价值函数输出都是同一个值且方差为0,说明欠拟合。以下是我打印的价值网络梯度,这是比较好的梯度情况。我没有使用正则化和dropout。所以你会发现有很多分散的小山丘,说明网络有很多神经元都有相应的梯度更新。