- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
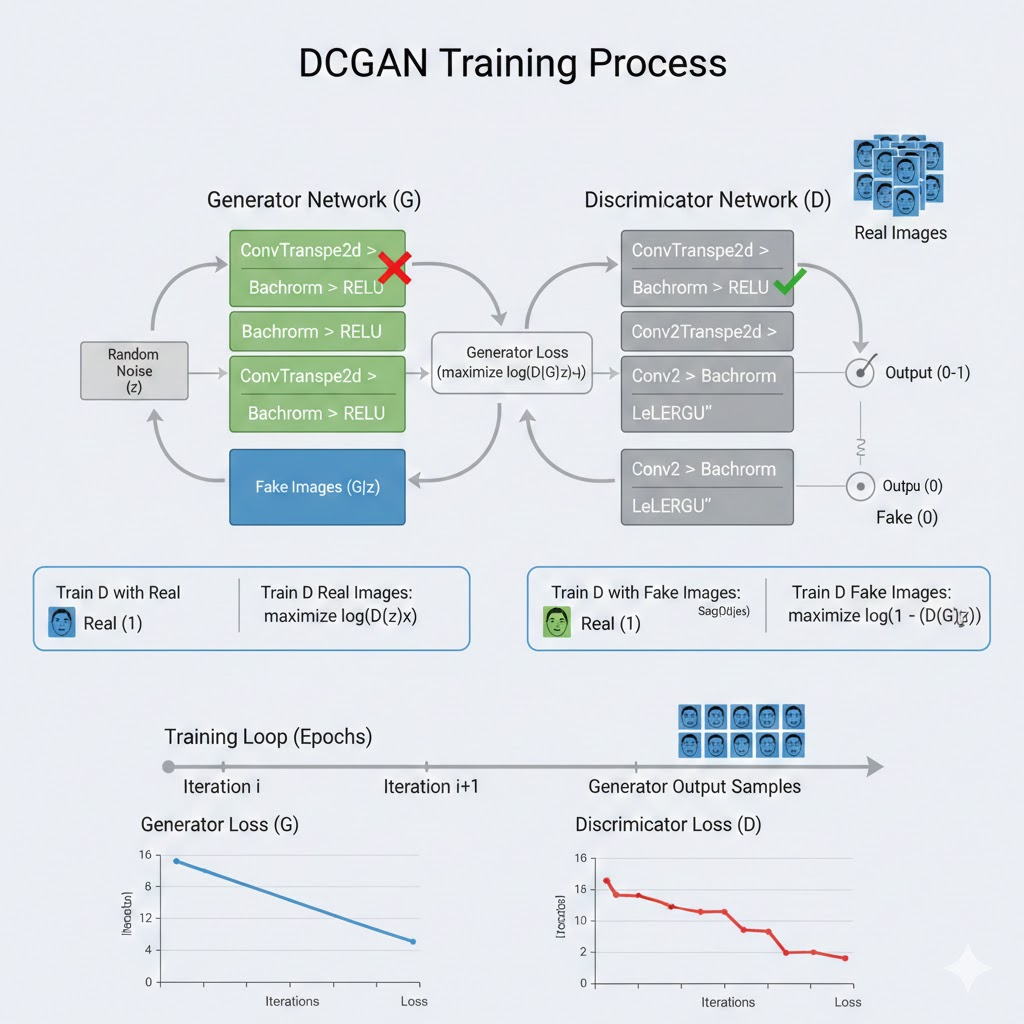
这张图片直观地展示了代码中实现的 DCGAN (深度卷积生成对抗网络) 的整体架构和训练流程。
它主要由三个部分组成,分别对应代码中的不同模块:
- 左侧:生成器 (Generator Network / NetG)
对应代码: class Generator(nn.Module)
输入 (Input): 图片左侧的灰色方块 "Random Noise (z)" 代表输入给生成器的随机噪声向量。在代码中,这就是 nz = 100 的潜在向量。
过程: 绿色的层代表 转置卷积层 (ConvTranspose2d)。正如代码中从 ngf8 到 ngf4 再到最终图像的过程,生成器将低维的噪声不断"放大"和还原(Upsampling),恢复出图像的特征。
输出: 生成了一张"假图像 (Fake Image)",尺寸为 64x64。
- 右侧:判别器 (Discriminator Network / NetD)
对应代码: class Discriminator(nn.Module)
输入: 判别器接收两种输入:
来自生成器的 假图像 (Fake Images)。
来自数据集的 真图像 (Real Images)(右上角的 FaceSample)。
过程: 灰色的层代表 卷积层 (Conv2d)。判别器像一个二分类器,通过卷积层不断提取特征,将图像尺寸从 64x64 压缩到 1x1。
输出 (Output): 最终通过 Sigmoid 函数输出一个 0 到 1 之间的概率值。
越接近 1,表示判别器认为这是真图。
越接近 0,表示判别器认为这是假图。
- 中间与下方的训练循环 (Training Loop & Loss)
对抗过程 (箭头流向):
训练判别器 (Train D): 试图将"真图"识别为 1,将"假图"识别为 0。图片中显示了它在比较 Real 和 Fake 的差异。
训练生成器 (Train G): 图中的红色/绿色标记示意了梯度的反向传播。生成器的目的是让判别器把假图"误判"为真图(即让判别器输出 1)。
底部图表 (Loss Graphs):
这对应了代码末尾 plt.plot(G_losses) 和 plt.plot(D_losses) 绘制的部分。
Generator Loss (G): 随着训练进行,生成器产生的误差(Loss)变化。
Discriminator Loss (D): 判别器的误差变化。
理想状态: 在 GAN 的训练中,两条线通常会处于一种博弈的动态平衡状态,而不是像普通神经网络那样 Loss 一直下降到 0。
总结: 这张图就是 Python 代码的可视化说明书。左边造假钞(生成器),右边验钞机(判别器),两者在训练循环中通过 Loss(损失函数)互相博弈,最终目的是让左边的生成器能造出以假乱真的人脸照片。
思维导图如下:
python
import torch, random, os # 导入核心库(注意:原代码重复导入random,已修正)
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
# ====================== 1. 设置随机种子(确保实验可复现) ======================
manualSeed = 999 # 固定随机种子值(999是任意选择的整数)
print("Random Seed: ", manualSeed)
random.seed(manualSeed) # 设置Python随机数生成器种子
torch.manual_seed(manualSeed) # 设置PyTorch CPU随机数生成器种子
torch.use_deterministic_algorithms(True) # 强制使用确定性算法(避免GPU非确定性操作)
# 注意:在PyTorch 1.7+中,此设置确保相同输入产生相同输出,但可能降低训练速度
# ====================== 2. 通用训练参数配置 ======================
from datetime import datetime # 导入日期时间模块
current_time = datetime.now() # 获取当前时间(精确到微秒级)
# 例如:current_time = datetime(2024, 5, 20, 14, 30, 25, 123456)
dataroot = "FaceSample" # 数据集根目录路径(必须包含子目录如"train")
batch_size = 128 # 每批次处理的图像数量(影响内存占用和梯度更新频率)
image_size = 64 # 输入/输出图像尺寸(64x64像素)
nz = 100 # 生成器输入噪声向量维度(z ~ N(0,1))
ngf = 64 # 生成器特征图数量(输出通道数,随层数增加)
ndf = 64 # 判别器特征图数量(输入通道数,随层数增加)
num_epochs = 20 # 训练总轮数(完整遍历数据集的次数)
lr = 0.0002 # 学习率(Adam优化器的初始学习率)
beta1 = 0.5 # Adam优化器的Beta1参数(控制一阶矩估计的衰减率)
# ====================== 3. 数据集预处理与加载 ======================
# 创建图像数据集(ImageFolder自动处理文件夹结构)
dataset = dset.ImageFolder(
root=dataroot, # 数据集根路径
transform=transforms.Compose([
transforms.Resize(image_size), # 调整图像尺寸到64x64
transforms.CenterCrop(image_size), # 中心裁剪确保尺寸一致
transforms.ToTensor(), # 转换为PyTorch张量(像素值范围[0,1])
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 标准化:(x-0.5)/0.5 → [-1,1]
])
)
# 创建数据加载器(支持批量加载、打乱和多线程)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size, # 每批次128张图像
shuffle=True, # 每轮打乱数据(避免训练偏差)
num_workers=2 # 使用2个进程加载数据(0=主线程,推荐=CPU核心数)
)
# ====================== 4. 设备选择(GPU优先) ======================
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用的设备是:", device) # 输出:cuda:0 或 cpu
# ====================== 5. 数据可视化(查看原始图像) ======================
real_batch = next(iter(dataloader)) # 获取第一个批次的图像
plt.figure(figsize=(8,8)) # 创建8x8英寸画布
plt.axis("off") # 关闭坐标轴
plt.title("Training Images") # 标题
# 生成网格图像(24张图像拼接,padding=2像素,归一化到[-1,1])
plt.imshow(np.transpose(vutils.make_grid(
real_batch[0].to(device)[:24], # 取前24张图像
padding=2,
normalize=True
).cpu(), (1,2,0))) # 转换维度顺序:(C,H,W) → (H,W,C)
plt.show()
# ====================== 6. 模型权重初始化(关键!) ======================
def weights_init(m):
"""自定义权重初始化函数(适用于卷积层和批归一化层)"""
classname = m.__class__.__name__ # 获取当前层的类名(如'Conv2d')
# 卷积层初始化(正态分布:均值=0,标准差=0.02)
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
# 批归一化层初始化(权重=正态分布(1,0.02),偏置=0)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
# ====================== 7. 生成器网络(Generator) ======================
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 生成器结构:转置卷积 + 批归一化 + ReLU
self.main = nn.Sequential(
# 输入: nz x 1 x 1 → 输出: ngf*8 x 4 x 4
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 输入: ngf*8 x 4 x 4 → 输出: ngf*4 x 8 x 8
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 输入: ngf*4 x 8 x 8 → 输出: ngf*2 x 16 x 16
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 输入: ngf*2 x 16 x 16 → 输出: ngf x 32 x 32
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 输入: ngf x 32 x 32 → 输出: 3 x 64 x 64
nn.ConvTranspose2d(ngf, 3, 4, 2, 1, bias=False),
nn.Tanh() # Tanh激活:输出范围[-1,1](与数据标准化匹配)
)
def forward(self, input):
return self.main(input) # 生成器前向传播
# 创建生成器实例并移动到设备
netG = Generator().to(device)
netG.apply(weights_init) # 应用权重初始化
print(netG) # 打印模型结构
# ====================== 8. 判别器网络(Discriminator) ======================
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 判别器结构:卷积 + 批归一化 + LeakyReLU
self.main = nn.Sequential(
# 输入: 3 x 64 x 64 → 输出: ndf x 32 x 32
nn.Conv2d(3, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输入: ndf x 32 x 32 → 输出: ndf*2 x 16 x 16
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输入: ndf*2 x 16 x 16 → 输出: ndf*4 x 8 x 8
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输入: ndf*4 x 8 x 8 → 输出: ndf*8 x 4 x 4
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输入: ndf*8 x 4 x 4 → 输出: 1 x 1 x 1
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() # Sigmoid激活:输出概率[0,1]
)
def forward(self, input):
return self.main(input) # 判别器前向传播
# 创建判别器实例并移动到设备
netD = Discriminator().to(device)
netD.apply(weights_init) # 应用权重初始化
print(netD) # 打印模型结构
# ====================== 9. 损失函数与优化器 ======================
criterion = nn.BCELoss() # 二元交叉熵损失(用于区分真假图像)
# 固定噪声向量(用于生成可视化图像)
fixed_noise = torch.randn(64, nz, 1, 1, device=device) # 64个样本,噪声维度nz
real_label = 1. # 真实图像标签(1)
fake_label = 0. # 假图像标签(0)
# Adam优化器(常用优化器,beta1控制动量)
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999)) # 判别器优化器
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999)) # 生成器优化器
# ====================== 10. 训练循环(核心部分) ======================
img_list = [] # 存储生成图像(用于动画)
G_losses = [] # 生成器损失列表
D_losses = [] # 判别器损失列表
iters = 0 # 迭代计数器
print("Starting Training Loop...") # 训练开始提示
for epoch in range(num_epochs): # 遍历每个训练轮次
for i, data in enumerate(dataloader, 0): # 遍历批次
############################
# (1) 更新判别器:最大化 log(D(x)) + log(1 - D(G(z)))
############################
netD.zero_grad() # 清空判别器梯度
# 真实图像处理
real_cpu = data[0].to(device) # 真实图像张量
b_size = real_cpu.size(0) # 批次大小
label = torch.full((b_size,), real_label, dtype=torch.float, device=device) # 创建真实标签向量
# 判别器前向传播(真实图像)
output = netD(real_cpu).view(-1) # 降维为一维向量
errD_real = criterion(output, label) # 计算真实图像损失
errD_real.backward() # 反向传播
D_x = output.mean().item() # 记录真实图像判别概率均值
# 生成假图像处理
noise = torch.randn(b_size, nz, 1, 1, device=device) # 生成随机噪声
fake = netG(noise) # 生成假图像
label.fill_(fake_label) # 更新标签为假图像
output = netD(fake.detach()).view(-1) # 用detach()避免梯度回传到生成器
errD_fake = criterion(output, label) # 计算假图像损失
errD_fake.backward() # 反向传播
D_G_z1 = output.mean().item() # 记录假图像判别概率均值
# 判别器总损失 = 真实损失 + 假损失
errD = errD_real + errD_fake
optimizerD.step() # 更新判别器参数
############################
# (2) 更新生成器:最大化 log(D(G(z)))
############################
netG.zero_grad() # 清空生成器梯度
label.fill_(real_label) # 假标签视为真实标签(欺骗判别器)
output = netD(fake).view(-1) # 判别器对生成图像的输出
errG = criterion(output, label) # 生成器损失(希望判别器输出1)
errG.backward() # 反向传播
D_G_z2 = output.mean().item() # 生成图像判别概率均值
optimizerG.step() # 更新生成器参数
# 每400批次输出训练状态
if i % 400 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 保存损失用于绘图
G_losses.append(errG.item())
D_losses.append(errD.item())
# 每500次迭代或最后轮次保存可视化图像
if (iters % 500 == 0) or ((epoch == num_epochs - 1) and (i == len(dataloader) - 1)):
with torch.no_grad(): # 禁用梯度计算(节省内存)
fake = netG(fixed_noise).detach().cpu() # 生成固定噪声的图像
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
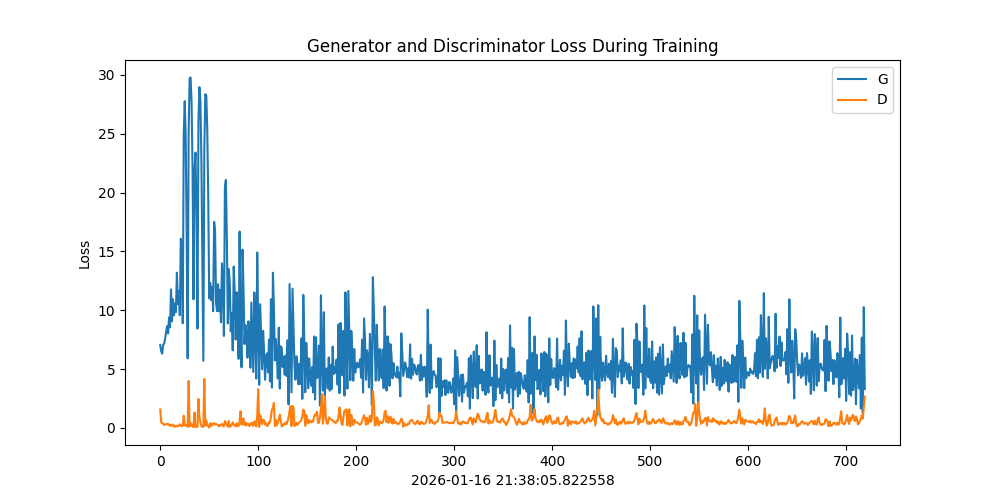
# ====================== 11. 损失曲线可视化 ======================
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G") # 生成器损失
plt.plot(D_losses, label="D") # 判别器损失
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# ====================== 12. 生成图像动画(动态展示训练过程) ======================
fig = plt.figure(figsize=(8, 8))
plt.axis("off")
# 将img_list中的图像转换为动画帧
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml()) # 在Jupyter中显示动画
# ====================== 13. 最终结果对比(真实 vs 生成) ======================
# 获取真实图像批次
real_batch = next(iter(dataloader))
# 显示真实图像
plt.figure(figsize=(15, 15))
plt.subplot(1, 2, 1)
plt.axis("off")
plt.title("Real Images")
plt.xlabel(current_time) # 显示当前时间戳
plt.imshow(np.transpose(
vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),
(1, 2, 0) # 转换维度:(C,H,W) → (H,W,C)
))
# 显示最后生成的图像
plt.subplot(1, 2, 2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1], (1, 2, 0))) # 最后生成的图像
plt.xlabel(current_time) # 显示当前时间戳
plt.show()损失函数如下:
生成的真假图片如下:
