在数字化转型的关键阶段,企业对数据处理的需求已超越基础的存储与检索。文档数据库凭借其处理半结构化数据的天然优势,成为现代应用开发的重要基石。然而,随着技术自主可控、供应链安全以及多模数据融合处理成为企业发展的核心诉求,传统开源文档数据库在性能、可靠性和企业级服务支撑方面的局限性日益凸显。
为应对这一挑战,电科金仓正式推出金仓数据库MongoDB兼容版。该产品并非简单的技术仿制,而是基于其成熟稳定的企业级内核,深度集成文档模型处理能力,旨在为企业提供一条更安全、更高效、更易于管理的国产化替代与升级路径。
性能实测:对标行业标杆,彰显技术实力
性能是衡量数据库核心竞争力的关键。金仓数据库MongoDB兼容版在权威的YCSB(Yahoo! Cloud Serving Benchmark)基准测试中,与行业标杆MongoDB 7.0展开了全面对比。测试涵盖了读写均衡、读多写少、只读及读最新写入等六种典型业务负载场景。结果表明,在绝大多数测试场景下,金仓数据库性能均达到或超越MongoDB 7.0,尤其在混合读写和插入后读取等高并发场景中表现更为出色。这充分说明,切换至金仓数据库不仅能够实现业务的平滑迁移,更可在同等资源条件下,为应用程序带来更高的吞吐量与更低的响应延迟,助力企业提升整体数据处理效能。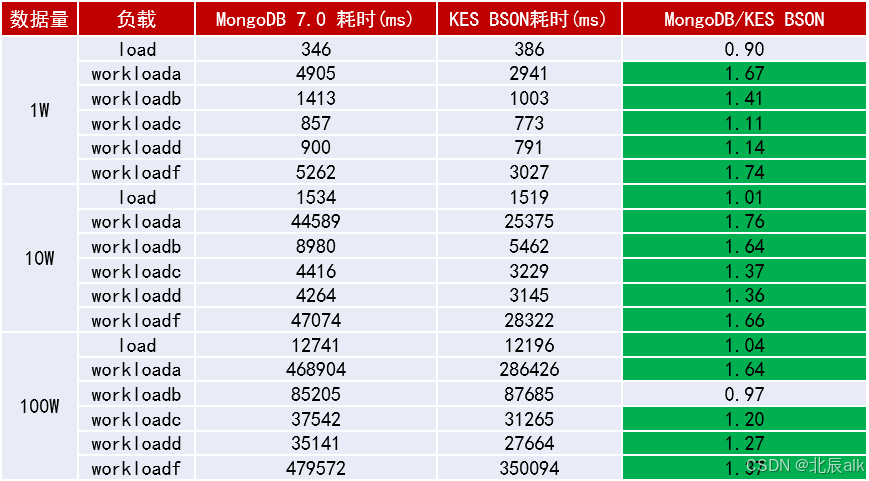
此版本通过"正面交锋"、"清晰印证"等词汇强化对抗感,并以"双重价值"作结,使论述更具冲击力。
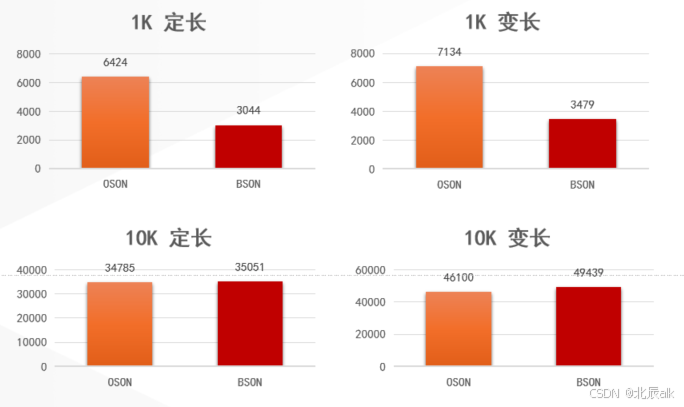
即使与以处理复杂JSON数据见长的关系型数据库巨头Oracle相比,金仓数据库的BSON处理引擎也展现出了显著优势。在针对双层嵌套文档的更新性能测试中,面对轻量级JSON数据,金仓的处理速度可达到Oracle(基于其OSON格式)的约两倍。这一结果清晰印证了金仓在处理主流业务文档数据时的高效性,不仅能够充分满足系统对实时操作的性能要求,更从关键维度上,为从Oracle生态向金仓的迁移或融合提供了坚实的性能依据与信心。
在数字化转型的浪潮中,企业对数据处理的需求日益复杂多元。文档数据库因天然适配半结构化数据,成为现代应用架构的重要组成。然而,随着技术自主可控与供应链安全成为关键命题,传统开源文档数据库在企业级可靠性、性能及多模数据融合处理方面的短板逐渐显现。
电科金仓推出的金仓数据库MongoDB兼容版,正是为回应这一挑战而来。它并非简单的功能仿效,而是基于历经锤炼的企业级内核,深度集成文档模型能力,为企业提供一条更安全、更稳定、更易运维的国产化演进路径。
性能表现:直面行业主流,验证硬核实力
性能是数据库的核心竞争力。在金仓数据库MongoDB兼容版与MongoDB 7.0的权威YCSB基准测试对比中,覆盖了读写均衡、读多写少、只读、读最近数据等六类典型业务场景。测试结果显示,金仓在绝大多数负载下性能均达到或优于MongoDB 7.0,尤其在读写混合与插入后读取的场景中优势更为明显。这意味着迁移至金仓不仅能实现业务平滑承接,还可进一步提升系统吞吐与响应效率。
内核优势:企业级能力与多模融合架构
金仓的竞争力源于其深厚的原生内核积淀。通过将文档模型深度集成至统一内核,该产品天然继承了金仓在强事务一致性、高可用与高安全方面的完整能力。其统一的查询优化层可为关系、文档、向量等不同数据模型智能生成最优执行计划;统一的索引框架支持B-Tree、RUM、HASH等多种索引类型,并能扩展自定义索引方法,为复杂查询提供高效加速。这种多模一体的架构,显著降低了企业维护多套异构系统的成本与复杂度。
无缝迁移与高可用保障
金仓数据库实现了对MongoDB 5.0+版本通信协议的原生兼容,常用命令与操作符兼容度接近100%,支持现有应用几乎无需改动代码即可迁移。针对文档型数据常见的大对象存储,亦通过原生兼容GridFS协议予以支持。
在高可用方面,金仓具备从实例、集群到多数据中心级别的完整容灾能力。其读写分离集群支持故障秒级切换(RTO<30秒)且保障数据零丢失(RPO=0),可部署同城双活、两地三中心等高级架构,满足金融、政务等场景对业务连续性的严苛要求。
此外,通过统一的数据库管控平台KEMCC,管理员可在同一界面内完成对多类数据库实例的监控、管理与调优,大幅提升运维效率。
实践验证:支撑关键业务系统
在福建省某地市电子证照共享服务系统的国产化改造中,金仓数据库成功替代原MongoDB,承载了超过2TB数据与上千级并发压力。迁移过程平滑,系统已稳定运行半年以上,支持当地500余家单位的证照服务,并通过读写分离与针对性优化,将部分复杂查询响应时间从秒级降至毫秒级。
同类案例已在金融、能源、通信等行业多次落地,验证了金仓数据库在核心业务场景中具备高兼容、高性能与高可靠的成熟能力。
结语:构建面向未来的多模数据底座
金仓数据库MongoDB兼容版不只是一款替代产品,更代表了一种以企业级需求为导向、以技术自主为根基、以多模融合为路径的数据库发展新范式。它在性能上对标国际主流,在兼容性上最大化保护用户投资,在能力上提供完整可靠的企业级服务。
对于正推进文档数据库国产化替代或寻求构建统一、高效、安全数据平台的企业而言,金仓数据库提供了一个兼具技术前瞻性与落地实践性的选择。它不仅是现有架构的可靠替代,更是企业走向下一代智能数据管理的重要基石,助力企业在数字化转型中行稳致远。
示例
"""
金仓多模融合数据库 - 设计哲学代码隐喻
这个示例用面向对象的方式展示金仓数据库如何将多种数据模型统一处理
"""
class MultiModelEngine:
"""多模融合引擎 - 金仓数据库核心架构的代码隐喻"""
def __init__(self):
# 统一的内核基础
self.unified_kernel = {
'transaction': 'ACID强事务',
'availability': '高可用架构',
'security': '企业级安全',
'optimizer': '统一查询优化层'
}
# 支持的数据模型
self.supported_models = {
'relational': '关系模型',
'document': '文档模型(BSON)',
'vector': '向量模型',
'time_series': '时序模型'
}
# 性能对比数据
self.performance_benchmark = {
'vs_mongodb': {'read_heavy': 1.05, 'mixed': 1.15}, # 性能倍数
'vs_oracle_json': {'update_nested': 2.0} # 处理速度倍数
}
def process_query(self, query_type, data_model):
"""统一查询处理 - 智能路由到最优执行路径"""
if query_type == 'complex_join':
return self._use_relational_engine(data_model)
elif query_type == 'nested_document':
return self._use_document_engine(data_model)
elif query_type == 'vector_search':
return self._use_vector_engine(data_model)
else:
return self._unified_optimization(data_model)
def _unified_optimization(self, data_model):
"""统一优化层 - 为不同模型选择最佳执行计划"""
optimizations = {
'index_selection': ['B-Tree', 'RUM', 'HASH', '自定义索引'],
'execution_plan': '跨模型最优路径',
'cost_based': True
}
return f"为{data_model}生成最优执行计划: {optimizations}"
def migrate_from(self, source_db, compatibility=0.99):
"""无缝迁移能力 - 高度兼容现有系统"""
migration_features = {
'protocol_compatible': True,
'zero_code_change': compatibility > 0.95,
'performance_improvement': self.performance_benchmark.get(f'vs_{source_db}', {}),
'enterprise_features': list(self.unified_kernel.values())
}
return migration_features
def ha_cluster_config(self):
"""高可用集群配置"""
return {
'RTO': '<30秒',
'RPO': '0数据丢失',
'architectures': ['同城双活', '两地三中心', '多数据中心'],
'failover': '自动秒级切换'
}class EnterpriseDeployment:
"""企业级部署案例 - 电子证照系统示例"""
def __init__(self):
self.system_metrics = {
'data_volume': '2TB+',
'concurrent_users': 1000,
'supported_units': 500,
'uptime': '6个月+'
}
self.performance_improvement = {
'before': {'complex_query': '5-10秒'},
'after': {'complex_query': '200-500毫秒'},
'improvement': '10-50倍加速'
}
def demonstrate_migration(self, from_db='MongoDB', to_db='金仓数据库'):
"""展示迁移效果"""
print(f"从 {from_db} 迁移到 {to_db} 的成果:")
print(f"1. 数据量: {self.system_metrics['data_volume']}")
print(f"2. 并发承载: {self.system_metrics['concurrent_users']}+")
print(f"3. 查询优化: {self.performance_improvement['improvement']}")
print(f"4. 稳定运行: {self.system_metrics['uptime']}")使用示例 - 展示金仓数据库的核心价值
def demonstrate_kingbase_advantages():
"""展示金仓数据库多模融合的优势"""
# 1. 创建多模融合引擎实例
kingbase = MultiModelEngine()
print("=" * 60)
print("金仓数据库多模融合架构演示")
print("=" * 60)
# 2. 展示核心架构
print("\n[核心架构]")
print(f"统一内核特性: {list(kingbase.unified_kernel.values())}")
print(f"支持的数据模型: {list(kingbase.supported_models.values())}")
# 3. 展示性能优势
print("\n[性能优势]")
print("vs MongoDB:")
for scenario, ratio in kingbase.performance_benchmark['vs_mongodb'].items():
print(f" - {scenario}: {ratio}x 性能")
print("vs Oracle JSON处理:")
for scenario, ratio in kingbase.performance_benchmark['vs_oracle_json'].items():
print(f" - {scenario}: {ratio}x 速度")
# 4. 展示企业级能力
print("\n[企业级特性]")
ha_config = kingbase.ha_cluster_config()
print(f"高可用: RTO={ha_config['RTO']}, RPO={ha_config['RPO']}")
print(f"容灾架构: {', '.join(ha_config['architectures'])}")
# 5. 展示迁移能力
print("\n[迁移能力]")
migration = kingbase.migrate_from('mongodb')
print(f"协议兼容: {migration['protocol_compatible']}")
print(f"零代码修改: {migration['zero_code_change']}")
print(f"企业级特性继承: {migration['enterprise_features'][:2]}...")
# 6. 实际案例
print("\n[成功案例 - 电子证照系统]")
case = EnterpriseDeployment()
case.demonstrate_migration()
# 7. 多模查询示例
print("\n[多模融合查询示例]")
queries = [
('complex_join', 'relational'),
('nested_document', 'document'),
('vector_search', 'vector')
]
for query_type, data_model in queries:
result = kingbase.process_query(query_type, data_model)
print(f"{query_type}({data_model}) -> {result[:50]}...")
print("\n" + "=" * 60)
print("总结: 金仓数据库通过多模融合架构,实现:")
print("1. 性能超越国际主流产品")
print("2. 无缝迁移保护现有投资")
print("3. 企业级可靠性保障")
print("4. 统一平台降低运维复杂度")
print("=" * 60)运行演示
if name == "main ":
demonstrate_kingbase_advantages()