DIET 模型与知识蒸馏全解析
DIET(Dual Intent and Entity Transformer)是 Rasa 团队 2020 年提出的轻量级对话语言理解(NLU)模型,专为「意图分类(Intent Classification)+ 实体识别(Entity Recognition)」双任务设计,是当前开源对话系统中最主流的 NLU 模型之一。
1. 核心背景与解决的问题
传统对话 NLU 模型(如 CNN/RNN)的痛点:
意图分类和实体识别分开训练,无法共享语义特征;
对稀疏特征(如低频实体、长尾意图)建模能力差;
模型参数量大,难以部署在低算力设备(如智能音箱、嵌入式终端)。
DIET 的核心目标:用轻量级 Transformer 实现意图 + 实体的端到端联合学习,在保证精度的同时降低模型复杂度。
2. DIET 完整架构(通俗版)
DIET 的架构可以概括为「输入层 → Transformer 编码器 → 多任务输出头」,全程围绕 "文本语义 + 稀疏特征" 融合设计:
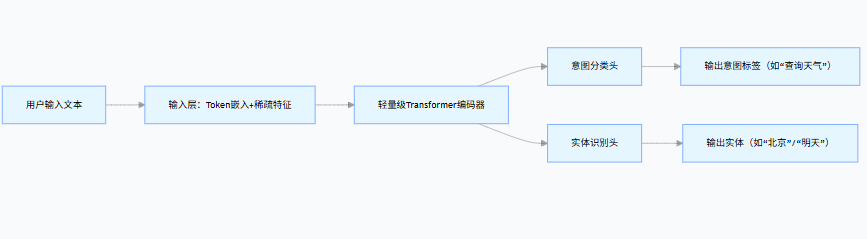
(1)输入层:文本 + 稀疏特征双融合
DIET 的输入不是单纯的文本 Token 嵌入,而是融合了稠密语义特征 和稀疏特征,这是它适配对话场景的关键:
- 稠密语义特征:文本 Token 的预训练嵌入(如 BERT/RoBERTa 嵌入)+ 位置编码(Transformer 必备,保留文本顺序);
- 稀疏特征:词 / 字符级 n-gram 特征(比如 "订机票" 的 n-gram 是 "订""机票""订机票"),解决低频实体 / 意图的 OOV(未登录词)问题;
- 最终输入:将两种特征拼接后投影到统一维度(通常 128/256 维),形成
[batch_size, seq_len, hidden_dim]的输入序列。
(2)Transformer 编码器:轻量级设计
DIET 的 Transformer 不是 ViT/DETR 那样的深层架构,而是极轻量化:
- 层数:通常 2-4 层(远少于 BERT 的 12 层);
- 注意力头数:2-4 头(降低计算量);
- 核心作用:捕捉文本的全局语义依赖(比如 "我想订明天从上海到北京的机票" 中,"上海""北京""明天" 与 "订机票" 意图的关联)。
(3)多任务输出头:意图 + 实体联合预测
DIET 的核心创新是双任务共享编码器,用一套特征同时完成两个任务:
|------|-----------------------------------------------------------------------|---------------------------------------|
| 任务 | 输出头设计 | 损失函数 |
| 意图分类 | 取 Transformer [CLS] token 的特征(全局语义),通过 1 层全连接映射到意图类别数 | 交叉熵损失(Intent Loss) |
| 实体识别 | 取每个 Token 的 Transformer 输出特征,通过 1 层全连接映射到实体标签(BIO 格式:B - 地点、I - 地点、O) | 交叉熵损失(Entity Loss)(或 CRF 损失,提升序列标注精度) |
3. DIET 的核心优势与适用场景
- 优势:轻量级(参数量通常 < 10M)、双任务联合学习精度高、对稀疏 / 低频意图 / 实体鲁棒;
- 适用场景:智能客服、聊天机器人、语音助手的 NLU 模块(比如识别用户说 "查一下明天杭州的天气" 的意图是 "查询天气",实体是 "杭州"(地点)、"明天"(时间))。
二、知识蒸馏在 DIET 上的应用
DIET 本身已经是轻量级模型,但在极致轻量化场景(如嵌入式设备)下,还需要通过知识蒸馏进一步压缩 ------ 核心思路是:用一个 "大而强" 的教师 DIET 模型(或 BERT/NLU 大模型),将知识迁移到 "小而快" 的学生 DIET 模型。
1. DIET 蒸馏的核心适配点
不同于 DETR(视觉检测),DIET 蒸馏需要兼顾意图分类(单标签)+ 实体识别(序列标注) 双任务,因此蒸馏策略要同时覆盖这两个任务的知识。
2. DIET 蒸馏的核心策略
(1)输出层蒸馏(最易实现)
让学生模型的最终预测模仿教师模型的 "软标签",是 DIET 蒸馏的基础策略:
- 意图分类蒸馏 :
- 教师模型输出意图的概率分布(软标签,比如 "查询天气" 概率 0.95、"订机票" 概率 0.03);
- 学生模型输出的意图概率分布向教师对齐,用 KL 散度计算软损失;
- 硬损失:学生模型与真实意图标签的交叉熵损失。
- 实体识别蒸馏 :
- 教师模型输出每个 Token 的实体概率分布(软标签,比如 "杭州" 的 B - 地点概率 0.98、O 概率 0.02);
- 学生模型每个 Token 的实体概率分布向教师对齐,用逐 Token 的 KL 散度计算软损失;
- 硬损失:学生模型与真实实体标签(BIO)的交叉熵损失。
(2)特征层蒸馏(提升精度)
让学生模型的Transformer 中间层特征模仿教师模型,充分迁移语义建模能力:
- 选择教师 / 学生 Transformer 的对应层(比如教师 4 层、学生 2 层,取教师第 2/4 层与学生第 1/2 层对齐);
- 用 MSE 损失计算学生特征与教师特征的差异(若维度不同,加 1 层线性投影对齐维度);
- 优势:迁移教师模型的 "语义理解能力"(比如教师能理解 "杭城"="杭州",学生也能学到)。
(3)注意力蒸馏(可选)
迁移教师 Transformer 的注意力图知识(比如教师对 "杭州" 和 "天气" 的注意力权重高,学生也模仿):
- 计算学生与教师注意力图的余弦相似度损失 / MSE 损失;
- 适合对精度要求极高的场景,缺点是增加计算量。
3. DIET 蒸馏的损失函数设计
总蒸馏损失 = 硬损失(真实标签) + 软损失(教师软标签) + 特征损失(可选):Ldistill=α⋅(Lintent−hard+Lentity−hard)+β⋅(Lintent−soft+Lentity−soft)+γ⋅Lfeature
- α:硬损失权重(通常 0.6);
- β:软损失权重(通常 0.3);
- γ:特征损失权重(通常 0.1);
- 软损失计算:用温度系数T(通常 2-5)平滑软标签,再计算 KL 散度:Lsoft=KL(softmax(Tlogitsstudent)∥softmax(Tlogitsteacher))⋅T2