目录
[一、 为什么传统的语音AI"没脑子"?](#一、 为什么传统的语音AI“没脑子”?)
[二、 Step-Audio-R1.1:把ASR扔进垃圾桶](#二、 Step-Audio-R1.1:把ASR扔进垃圾桶)
[三、 "双脑"架构:一边想,一边说](#三、 “双脑”架构:一边想,一边说)
[四、 权威霸榜:超越谷歌和马斯克](#四、 权威霸榜:超越谷歌和马斯克)
[五、 未来的声音](#五、 未来的声音)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阶跃星辰开源原生语音推理模型Step-Audio-R1.1
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
长久以来,我们对AI语音助手的印象,大约就是个"传话筒"。
当你对它说:"这首歌太悲伤了。" 传统的AI是这么工作的:先把你的声音转成文字"这首歌太悲伤了",然后分析这段文字,回答你:"是的,我也觉得。"
它其实根本没听那首歌。它不知道那首歌是用的小调和弦,不知道歌手的嗓音带着哭腔,也不知道背景里有凄凉的雨声。它只是在处理文字符号。这也导致了一个怪象:很多时候,你对着AI说得越多,它反而越糊涂,因为它丢掉了声音里最丰富的信息。
近日,阶跃星辰开源了一个名为 Step-Audio-R1.1的模型,试图终结这个"传话筒"时代。它号称能直接用"耳朵"思考,听到的不仅是字,更是情绪和场景。

一、 为什么传统的语音AI"没脑子"?
要理解Step-Audio-R1.1的突破,先得看看传统方案错在哪。
传统语音交互通常是"三步走":
**(1)ASR(语音转文字):**把你说的声音变成字。
**(2)LLM(大模型推理):**理解这些字的意思。
**(3)TTS(文字转语音):**把回答变成声音读出来。
这个流程最大的问题是信息丢失。
人类沟通中,只有30%的信息在文字里,剩下70%藏在语气、停顿、音量甚至背景音里。
比如一句"你可真行啊",如果是欢快的语气,是夸奖;如果是阴阳怪气的语调,那就是嘲讽。传统AI把这转化为文字"你可真行啊"之后,原本的嘲讽意味就彻底消失了,AI可能会傻乎乎地谢谢你的夸奖。
这就叫"模态脱节"。传统的语音模型,哪怕接了再强大的GPT-4,只要它依赖转写,它就是个"听力障碍者"。
二、 Step-Audio-R1.1:把ASR扔进垃圾桶
Step-Audio-R1.1 最大的革新,就是实现了"端到端原生推理"。
简单来说,它跳过了"转文字"这个中间商。声音信号进入模型后,直接被编码成特征,送入大脑进行思考。
这意味着:
**(1)它听得懂情绪:**它能感知到你说话时的焦急、愤怒或者是犹豫。
**(2)它听得懂环境:**背景里有猫叫,它知道你在家;背景里有车流声,它知道你在路上。
**(3)它能听出弦外之音:**比如那句"你可真行啊",它能根据语调判断出你在生气,并做出安抚的回应,而不是说谢谢。
在官方给出的案例中,有一段"猫猫吵架"的音频。
传统模型可能会转写出一堆乱码或者沉默,因为它听不懂猫语。
但Step-Audio-R1.1直接分析声学特征:高亢的嘶吼、重叠的叫声、背景里主人喊"别打了"。它不仅判断出这是两只猫在打架,还推断出主人正在劝架。这就叫"基于声学的推理"。
三、 "双脑"架构:一边想,一边说
实时语音交互最怕什么?怕慢。
如果我说完一句话,AI要思考5秒钟再回答,那聊天的感觉就全毁了。
为了解决这个问题,Step-Audio-R1.1 采用了**"双脑(Dual-Brain)"架构**:
(1)推理脑(Formulation Brain):负责深思熟虑,分析逻辑,搞清楚你到底想干嘛。
(2)表达脑(Articulation Brain):负责组织语言,控制嘴巴(输出)。
这两个大脑是并行工作的。就像同声传译员一样,耳朵听着,脑子转着,嘴巴说着。这让它实现了极低的延迟,甚至可以支持**"流式推理"**------你话还没说完,它已经大概知道你要说什么,并准备好回应了。
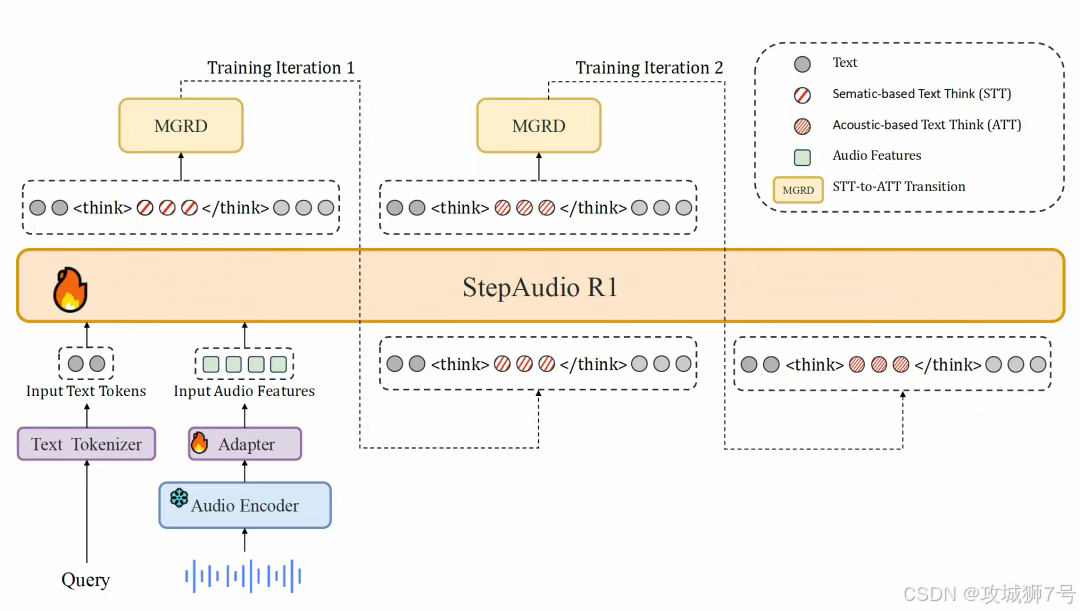
Step-Audio-R1模型架构
四、 权威霸榜:超越谷歌和马斯克
在这个领域,之前的大佬是谷歌的Gemini和马斯克的Grok。
但在最新的Artificial Analysis Speech Reasoning 榜单上,Step-Audio-R1.1 以 96.4% 的准确率登顶全球第一。
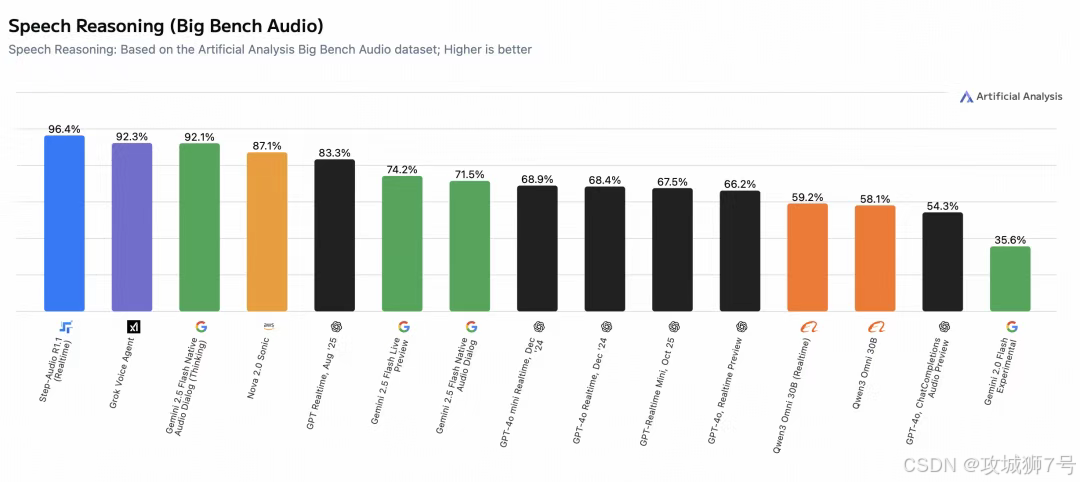
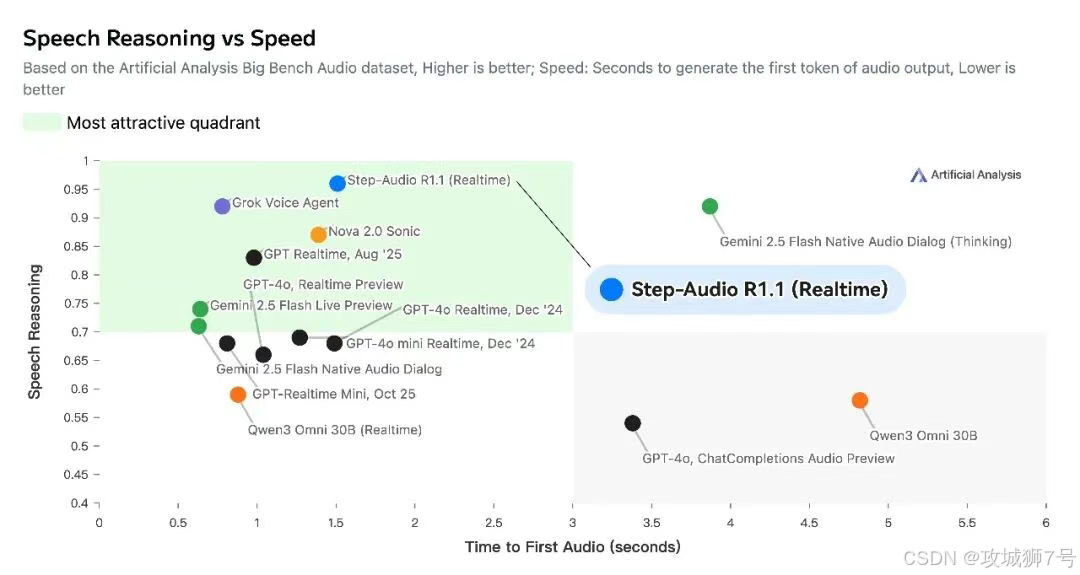
这个榜单专门测"原生语音推理",也就是考那些必须听声音才能做对的题。
比如给一段包含讽刺语气的对话,问说话人真实态度是什么。或者给一段音乐,问这段音乐适合什么场景。在这些测试中,Step-Audio-R1.1 全面碾压了依赖转写的传统模型。
更重要的是,它开源了。
这意味着任何开发者都可以去HuggingFace下载它的权重,把它部署到自己的服务器上。这对于智能客服、车载助手、甚至游戏NPC的开发者来说,是一个巨大的福音。你不需要再忍受云端API的高延迟和高成本,就能拥有一个SOTA级别的语音大脑。
五、 未来的声音
Step-Audio-R1.1 的出现,预示着语音交互正在经历一场质变。
未来的AI耳机、AI音箱,不再是那个只会报天气、定闹钟的傻瓜。
它可能是一个能听出你感冒了提醒你吃药的私人医生;
可能是一个能听出你心情不好给你放首舒缓音乐的知心朋友;
甚至可能是一个能听懂发动机异响告诉你车哪里坏了的维修顾问。
当AI学会了"用耳朵思考",声音世界的数据价值才真正被挖掘出来。而阶跃星辰的这次开源,无疑是把把开启这个新世界的钥匙,交到了所有开发者手中。
Step-Audio-R1.1 权重:
https://huggingface.co/stepfun-ai/Step-Audio-R1.1
体验:
https://www.stepfun.com/studio/audio?tab=conversation
GitHub地址:
https://github.com/stepfun-ai/Step-Audio-R1
魔搭ModelScope:
https://modelscope.cn/studios/stepfun-ai/Step-Audio-R1
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!