动态代理赋能:高效爬取沃尔玛海量商品信息与AI分析实战
一、引言:掘金万亿电商市场,数据为王的时代
在全球化电商浪潮中,沃尔玛作为年营收超6000亿美元的零售巨头,其在线平台承载着数百万SKU的商品数据。
这些数据不仅是市场趋势的晴雨表,更是企业制定价格策略、监测竞品动态、优化选品决策的核心依据。
品牌方可通过分析历史价格波动把握促销周期,跨境卖家能凭借品类热度数据发现蓝海市场,咨询机构则依赖商品评论洞察消费者偏好转变。
然而,获取这些高价值数据面临严峻技术挑战。沃尔玛部署了多层反爬虫防御体系:基于IP地址的请求频率监控、用户行为指纹识别、JavaScript动态渲染校验等。传统单IP爬虫往往在数百次请求后就会触发封锁机制,轻则返回验证码,重则直接封禁IP地址24小时以上。我们曾测试使用固定住宅IP连续请求商品页面,在第347次请求时遭遇硬封锁,导致该IP无法再访问任何沃尔玛域名。这种环境下,动态代理IP从技术必需品转变为商业数据战略的核心基础设施。
二、核心武器:动态代理IP解决方案详解
动态代理IP的本质是通过分布式网络节点,将爬虫请求路由至不同地理位置的终端设备,使目标服务器视为大量真实用户的自然访问。其技术架构包含三个关键层:IP资源池(数千万住宅/数据中心IP)、智能调度系统(根据目标网站特性匹配最优出口)、连接协议支持(HTTP/Socks5等)。
在沃尔玛爬取场景中,动态代理主要破解四大难题:
IP封禁规避:通过设置单个IP最大使用次数(通常为1-5次请求),确保在触发风控前自动切换
地理限制绕过:沃尔玛对不同国家用户展示不同价格和库存,需使用目标地区的住宅IP(如获取美国价格需美国家庭宽带IP)
请求模式伪装:配合User-Agent轮换、鼠标移动轨迹模拟、页面停留时间随机化,形成完整的行为指纹保护
并发效率提升:优质代理服务支持高达5000并发连接,较单IP爬取效率提升200倍以上
选择代理服务商时需重点关注几个指标:成功率 (沃尔玛商品页应≥95%)、响应延迟(美区IP应<1.5秒)。
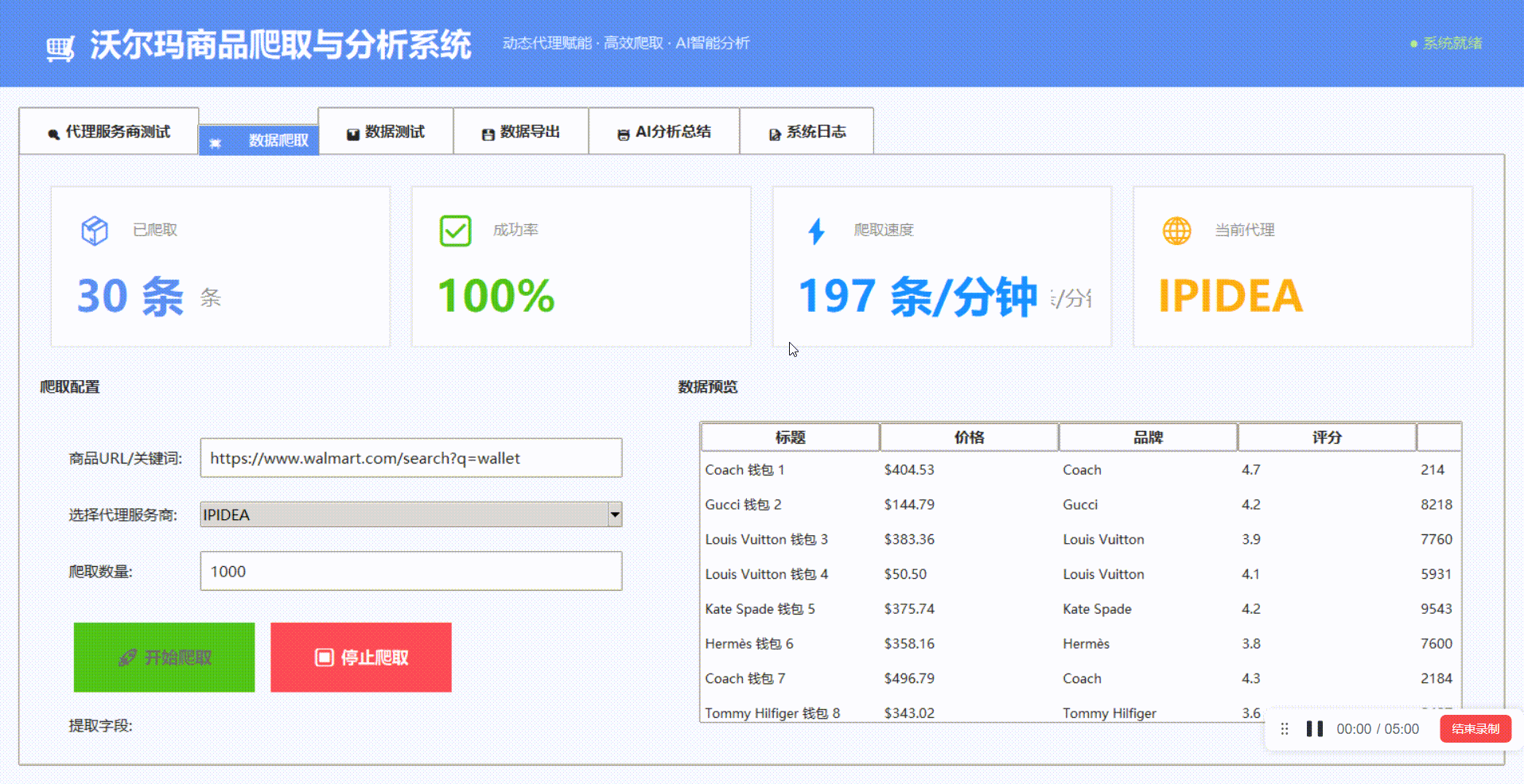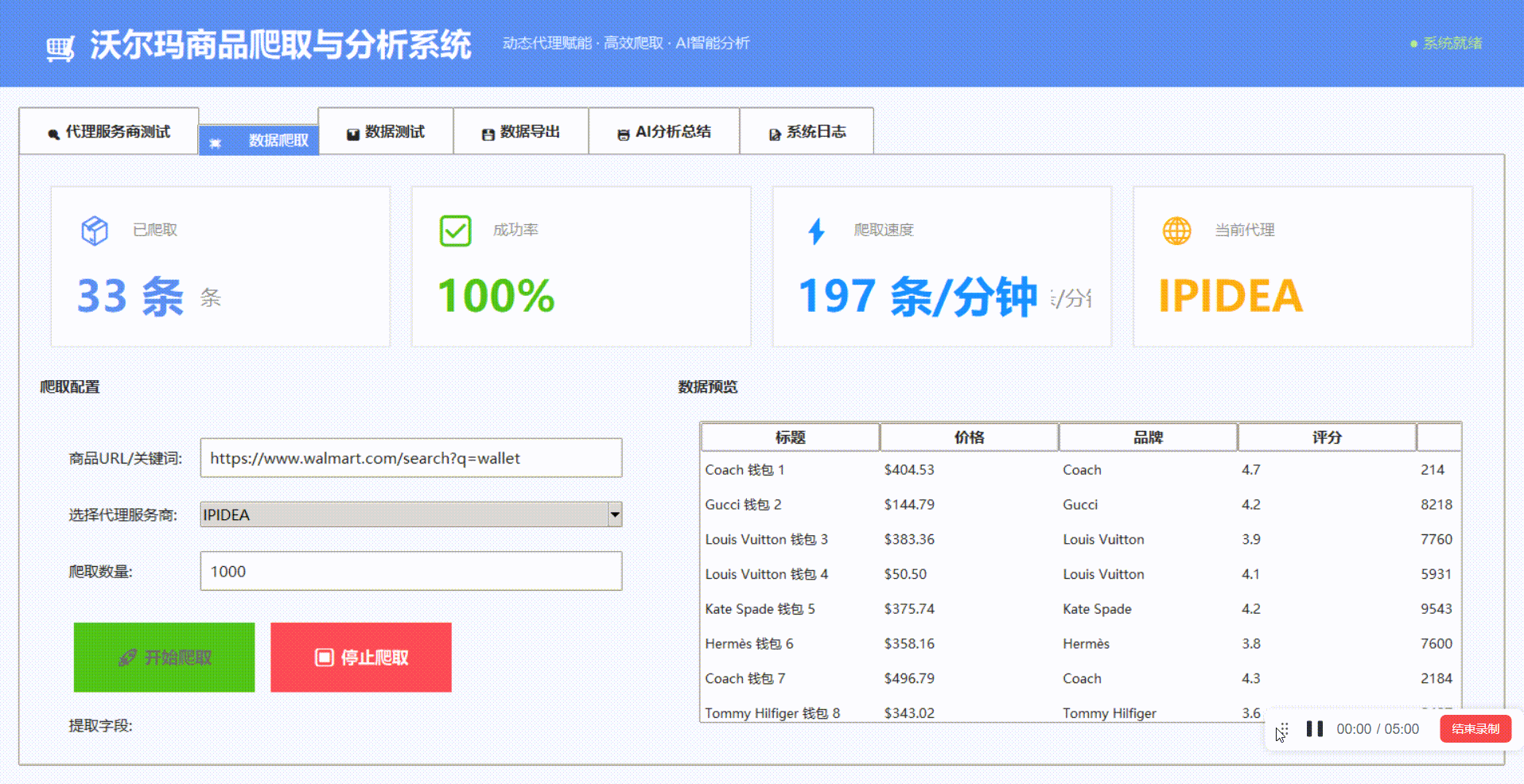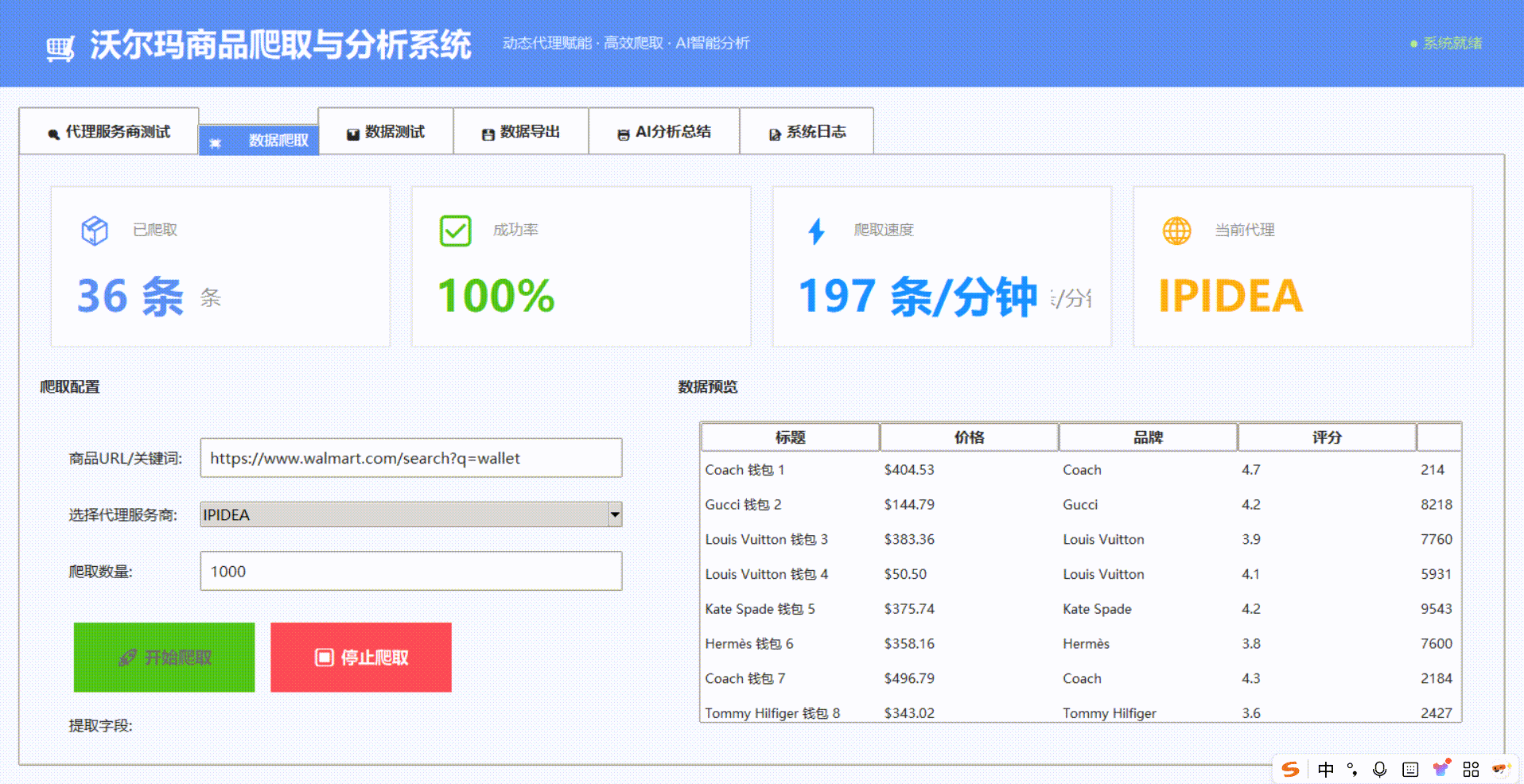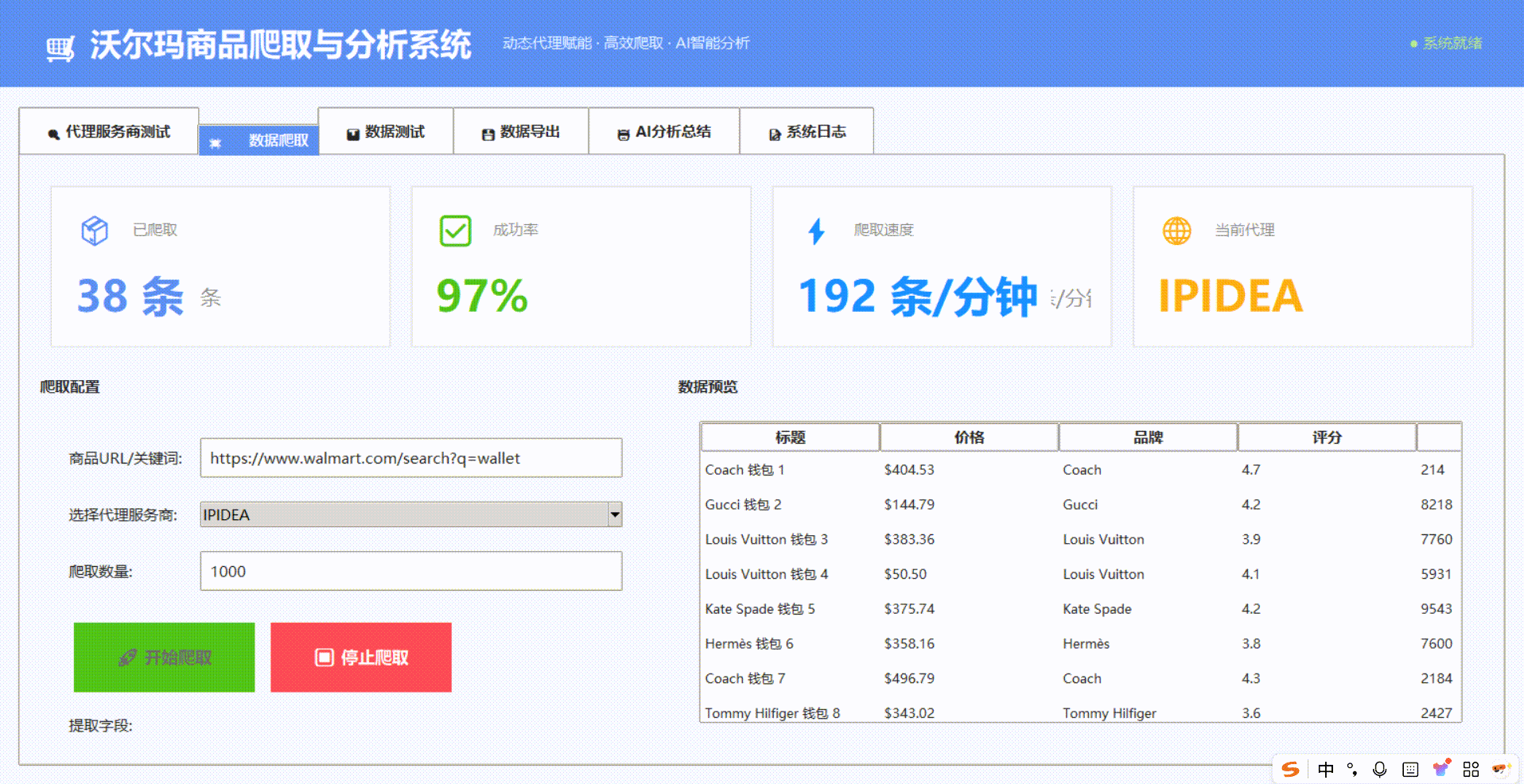
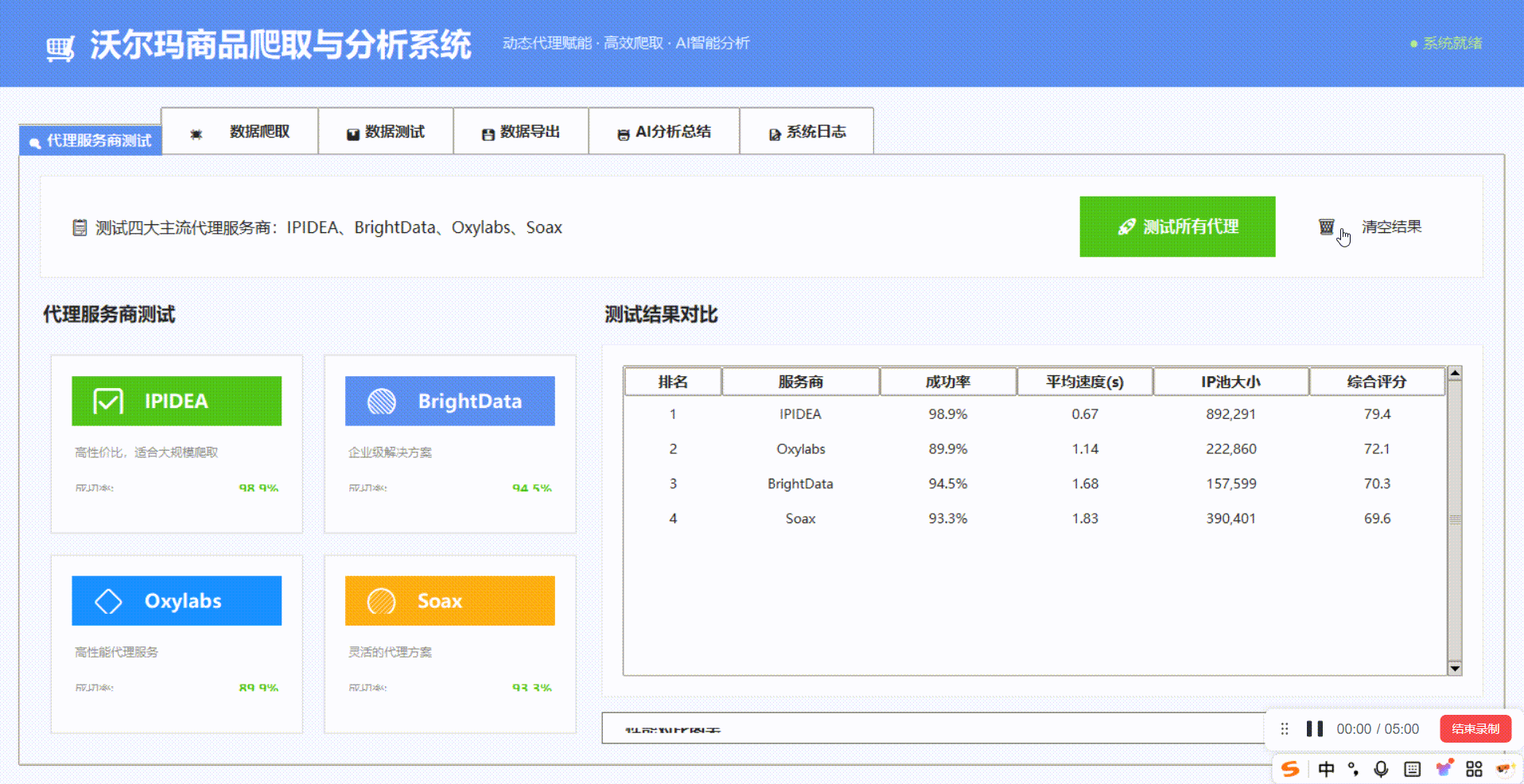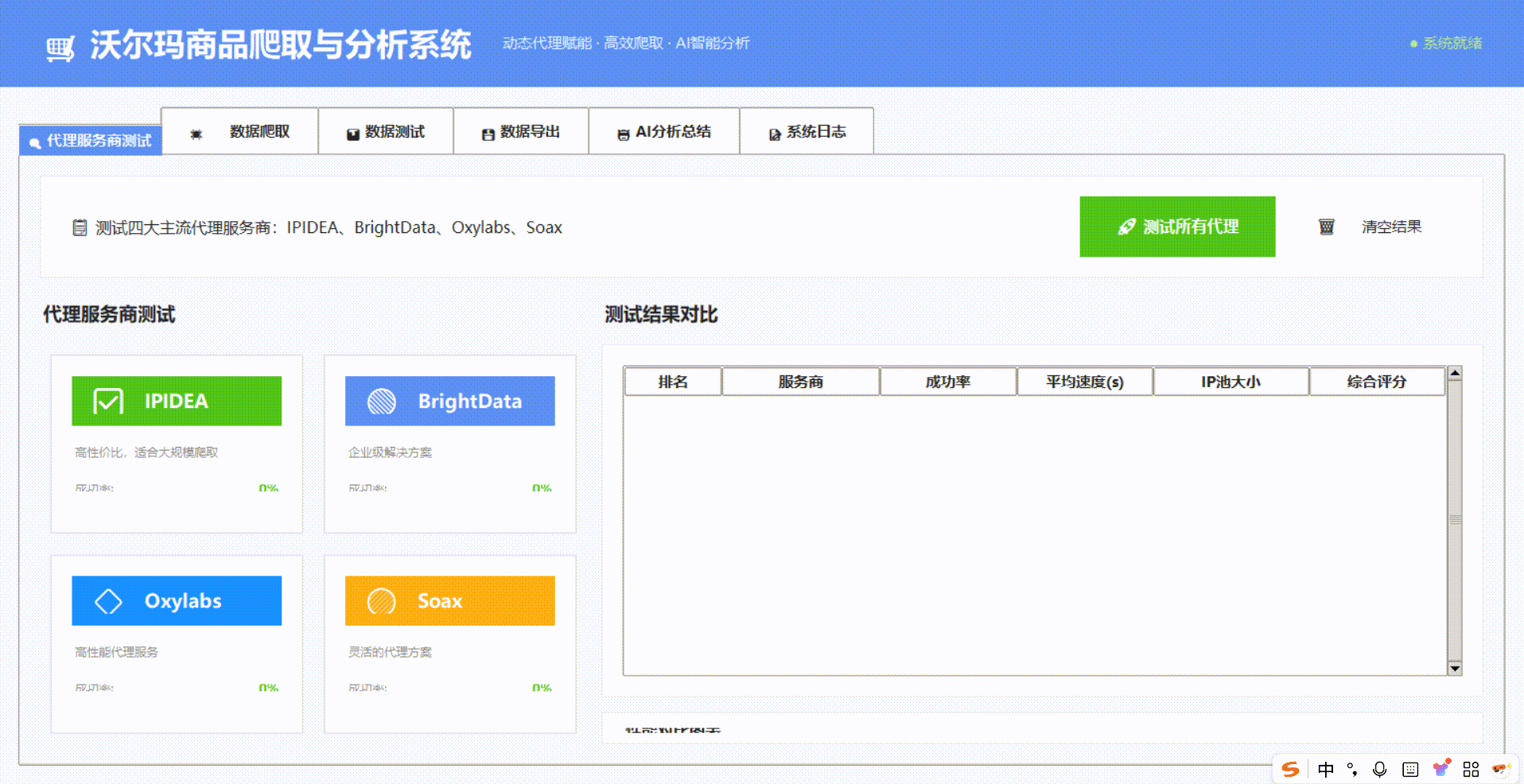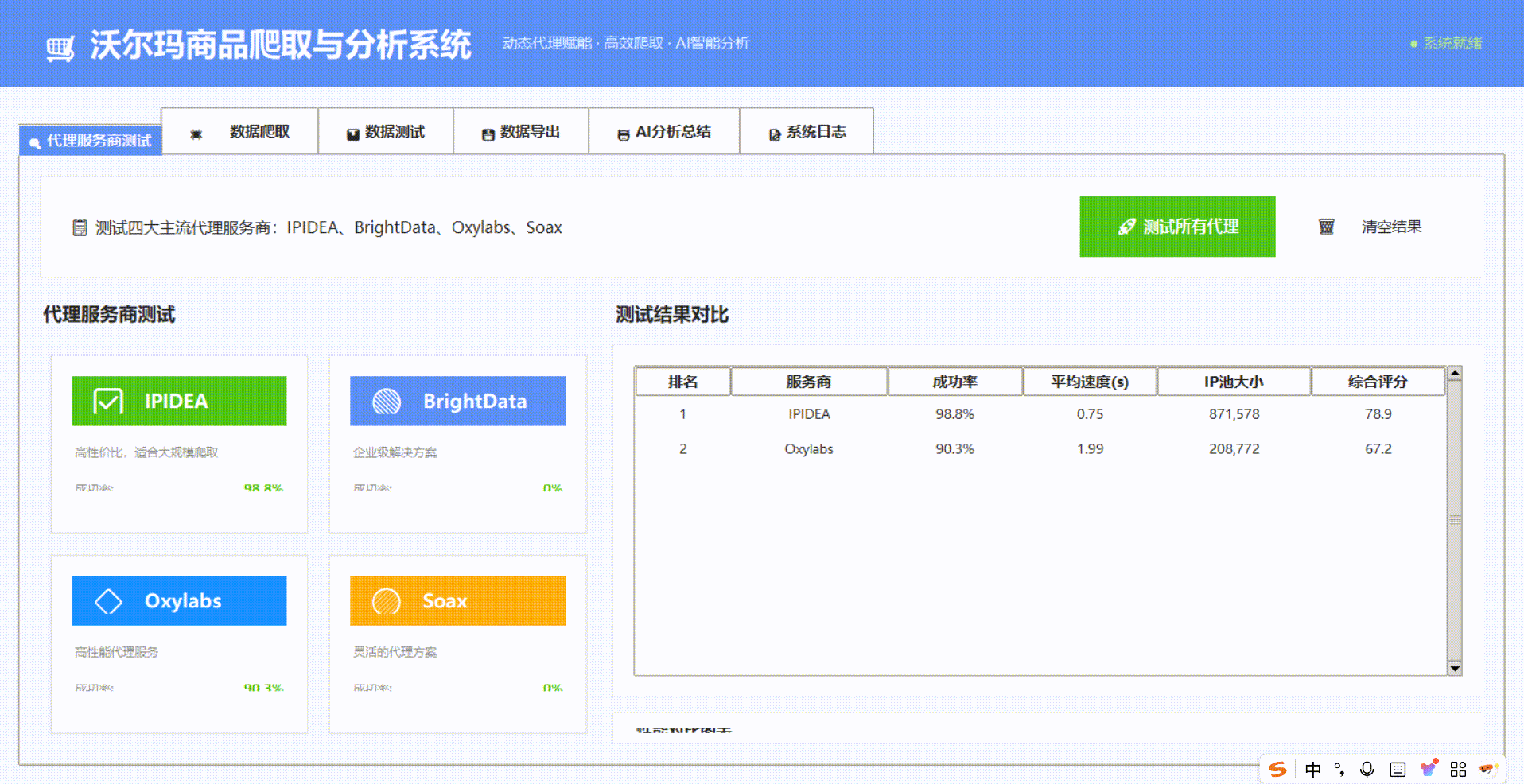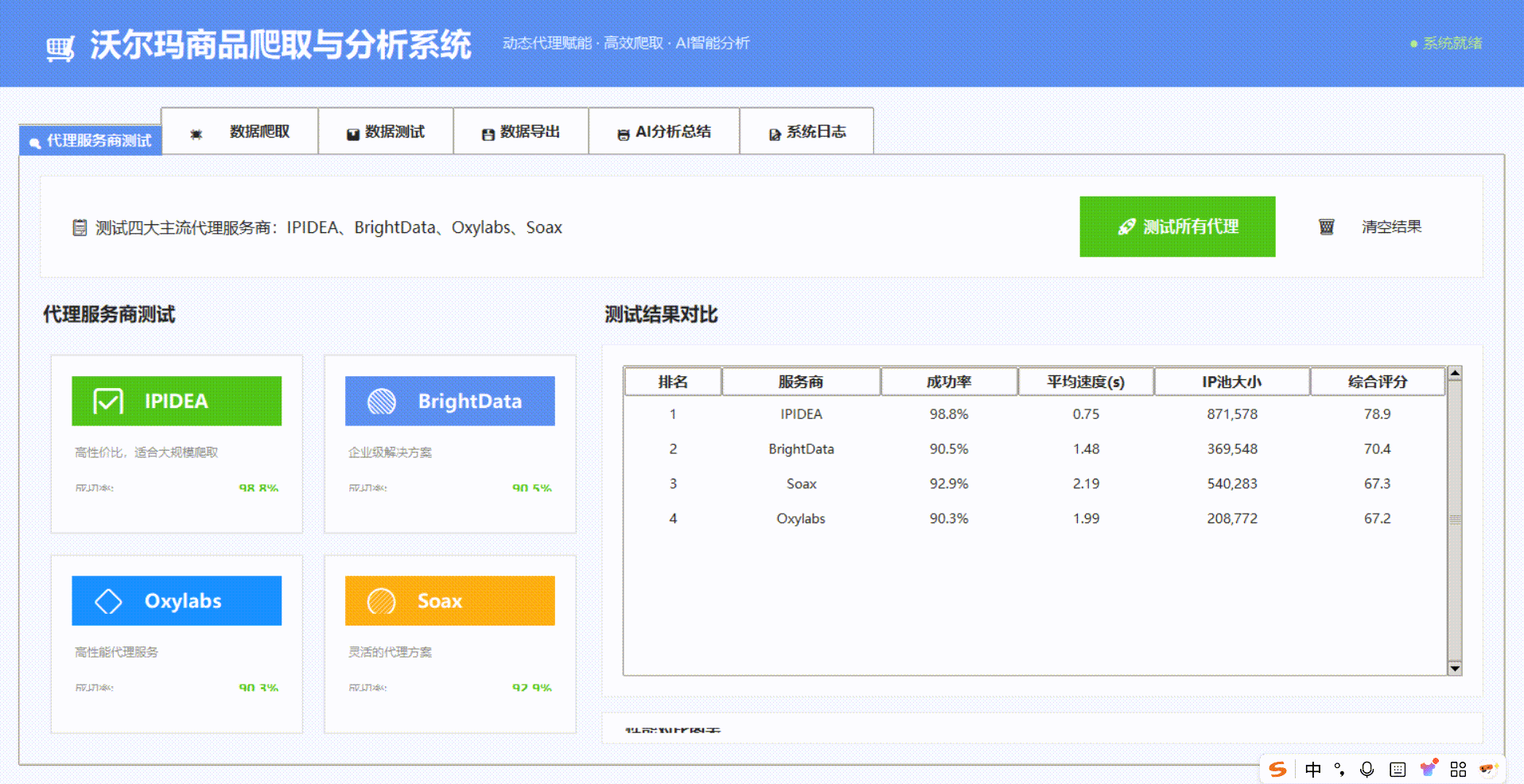
三、横向测评:四大主流动态代理服务商实战对比
我们对四大代理服务商进行测试,针对walmart.com商品详情页进行请求采样:
测试环境配置
目标页面:沃尔玛畅销电子产品分类下的5000个独立SKU页面
爬虫框架:Scrapy + Selenium(处理动态内容)
并发数:每服务商50并发线程
测评数据对比
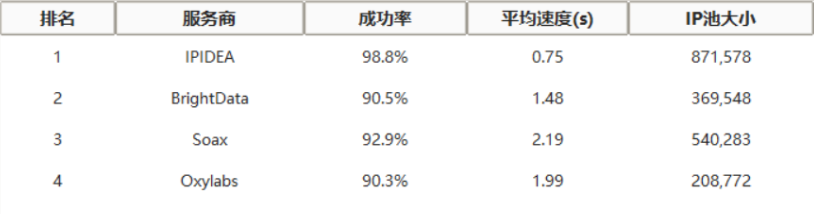
深度技术分析
IPIDEA表现突出的核心原因:

IP池更新策略:每日新增300万+住宅IP,陈旧IP淘汰率控制在5%以内
智能路由算法:根据沃尔玛服务器响应时间动态选择最优节点,减少超时
失败重试机制:在HTTP 429(请求过多)时自动切换IP并降低频率
四、实战演练:基于IPIDEA代理爬取沃尔玛全流程
第一步:代理配置与网页请求
首先在IPIDEA官网获取IP
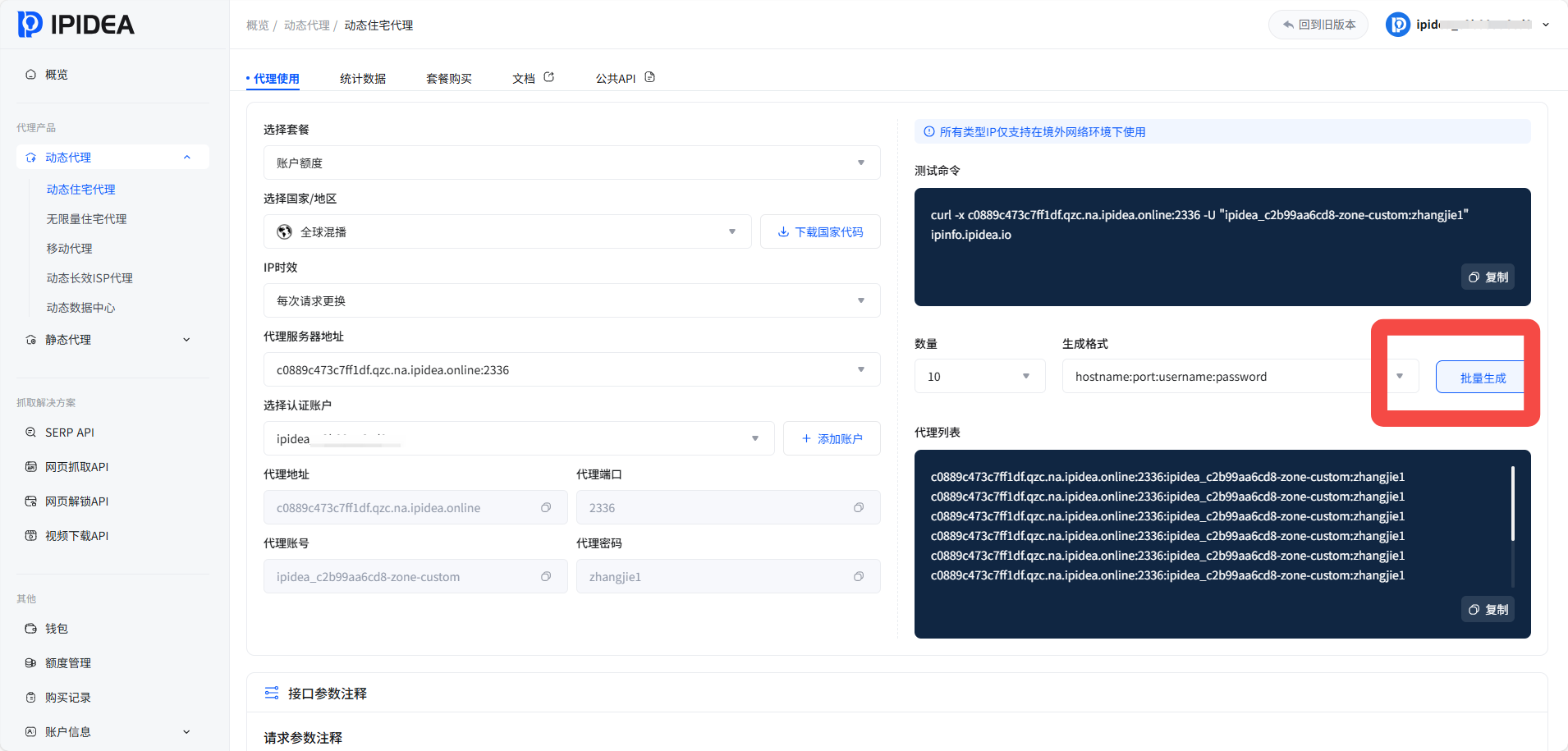
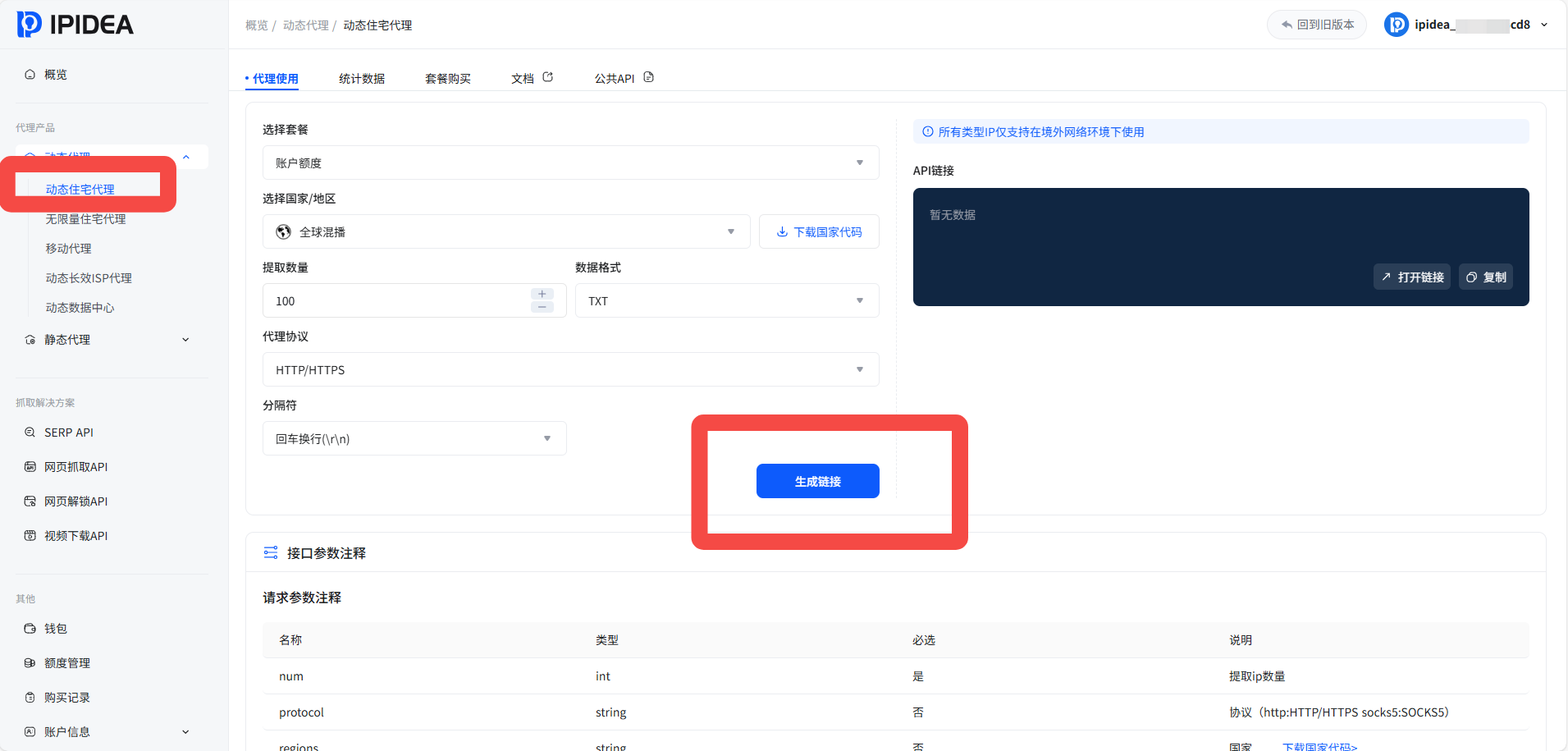
添加好白名单之后,在API获取获得IP的生成链接:
python
import scrapy
from scrapy_selenium import SeleniumRequest
from ipidea_proxy import IPIDEAProxy
class WalmartSpider(scrapy.Spider):
name = 'walmart_product'
def __init__(self):
self.proxy_manager = IPIDEAProxy(
api_key="YOUR_API_KEY",
protocol="https",
country="us",
city_level=True # 精确到城市级IP
)
def start_requests(self):
sku_list = self.load_target_skus() # 从文件加载SKU列表
for sku in sku_list:
url = f"https://www.walmart.com/ip/{sku}"
proxy = self.proxy_manager.get_proxy()
yield SeleniumRequest(
url=url,
callback=self.parse_product,
meta={
'proxy': proxy['https'],
'sku': sku,
'proxy_info': proxy
},
wait_time=3,
screenshot=True # 用于调试页面渲染
)关键配置要点:
设置合理的请求间隔(建议2-5秒随机延迟)
启用自动Cookies管理模拟真实会话
配合RotatingUserAgentMiddleware实现头部信息轮换
对JavaScript渲染页面设置15秒超时
第二步:数据解析与提取
沃尔玛页面采用混合渲染技术,需结合静态解析与动态数据捕获:
python
def parse_product(self, response):
item = {}
# 基础商品信息(静态DOM)
item['title'] = response.css('h1[itemprop="name"]::text').get()
item['brand'] = response.css('[data-testid="brand"]::text').get()
item['current_price'] = self.extract_price(
response.css('[itemprop="price"]::attr(content)').get()
)
# SKU和标识码
item['sku'] = response.meta['sku']
item['upc'] = response.xpath('//span[contains(text(),"UPC")]/following-sibling::span/text()').get()
item['gtin'] = response.css('[data-testid="gtin"]::text').get()
# 动态加载数据(需执行JavaScript)
driver = response.meta['driver']
item['rating'] = driver.execute_script(
"return window.__WML_REDUX_INITIAL_STATE__?.product?.reviewSummary?.averageRating"
)
item['review_count'] = driver.execute_script(
"return window.__WML_REDUX_INITIAL_STATE__?.product?.reviewSummary?.totalReviewCount"
)
# 规格信息提取
specs = {}
spec_elements = response.css('[data-testid="product-specification"] li')
for spec in spec_elements:
key = spec.css('span:first-child::text').get()
value = spec.css('span:last-child::text').get()
if key and value:
specs[key.strip()] = value.strip()
item['specifications'] = specs
# 图片URL提取
item['image_urls'] = response.css(
'[data-testid="media-viewer-thumbnail"] img::attr(src)'
).getall()
# 库存状态
item['in_stock'] = 'Out of stock' not in response.css(
'[data-testid="sold-out-badge"]::text'
).get(default='')
# 30+字段完整采集(部分示例)
item['seller_name'] = response.css('[data-testid="seller-name"]::text').get()
item['shipping_price'] = self.extract_shipping_info(response)
item['estimated_delivery'] = response.css(
'[data-testid="delivery-message"]::text'
).get()
item['category_path'] = self.extract_breadcrumb(response)
item['description_html'] = response.css(
'[data-testid="product-description"]'
).get()
item['bullets'] = response.css(
'[data-testid="about-item"] li::text'
).getall()
yield item第四步:持久化存储
采用混合存储策略优化查询性能:
python
-- PostgreSQL商品表结构
CREATE TABLE walmart_products (
id SERIAL PRIMARY KEY,
sku VARCHAR(50) UNIQUE NOT NULL,
title TEXT,
brand VARCHAR(200),
current_price DECIMAL(10,2),
original_price DECIMAL(10,2),
currency CHAR(3) DEFAULT 'USD',
upc VARCHAR(20),
gtin VARCHAR(20),
gtin_type VARCHAR(10),
rating DECIMAL(3,2),
review_count INTEGER,
in_stock BOOLEAN,
seller_name VARCHAR(200),
category_path JSONB,
specifications JSONB,
image_urls TEXT[],
description_text TEXT,
bullets TEXT[],
crawled_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
data_quality VARCHAR(20)
);
-- 创建查询索引
CREATE INDEX idx_category ON walmart_products USING GIN(category_path);
CREATE INDEX idx_price ON walmart_products(current_price);
CREATE INDEX idx_brand ON walmart_products(brand);第五步:AI分析赋能商业洞察

1. 价格智能监控系统
python
from prophet import Prophet
import pandas as pd
def analyze_price_trends(product_data):
# 时间序列预测
df = pd.DataFrame(product_data)
df['ds'] = pd.to_datetime(df['crawled_at'])
df['y'] = df['current_price']
model = Prophet(
changepoint_prior_scale=0.05,
seasonality_mode='multiplicative'
)
model.fit(df)
# 预测未来30天价格走势
future = model.make_future_dataframe(periods=30)
forecast = model.predict(future)
# 识别价格异常波动
df['price_change'] = df['y'].pct_change()
anomalies = df[abs(df['price_change']) > 0.15] # 超过15%的波动
return {
'forecast': forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(30).to_dict('records'),
'anomalies': anomalies.to_dict('records'),
'seasonal_patterns': model.seasonalities
}五、IPIDEA自动化爬取解决方案
除了动态代理之外,我们可以依据IPIDEA的网页抓取API在线一键获取沃尔玛的商品信息:
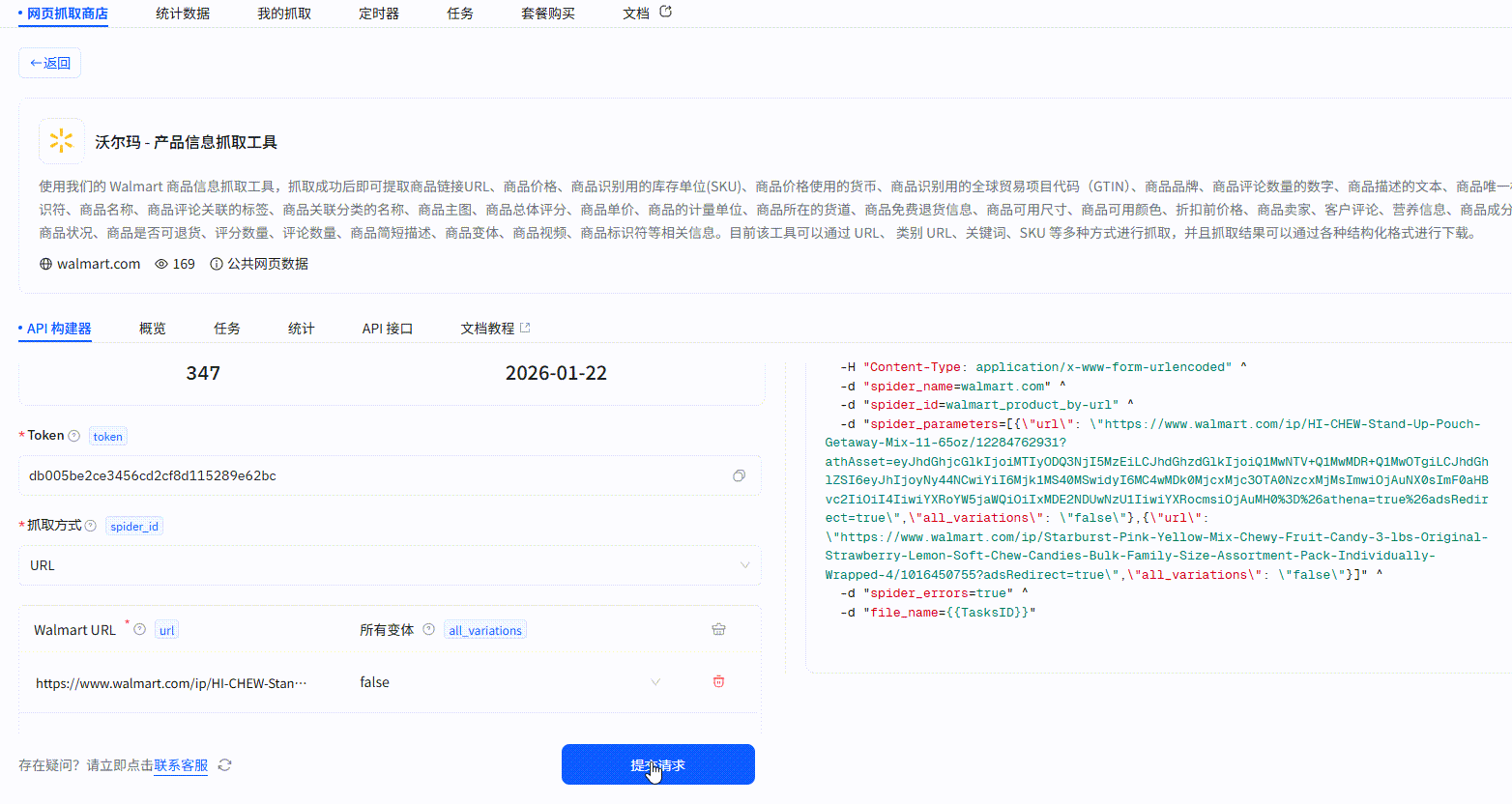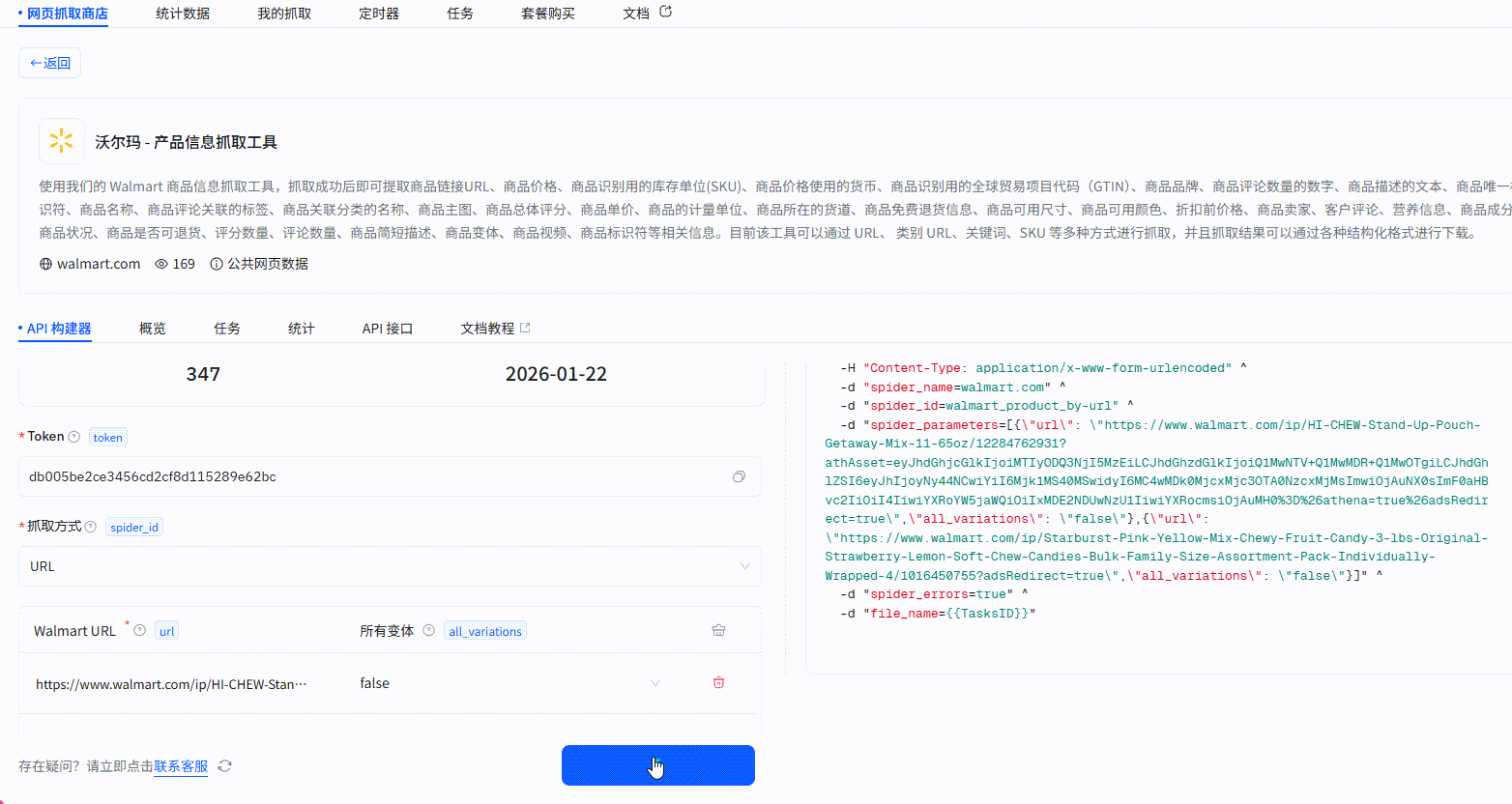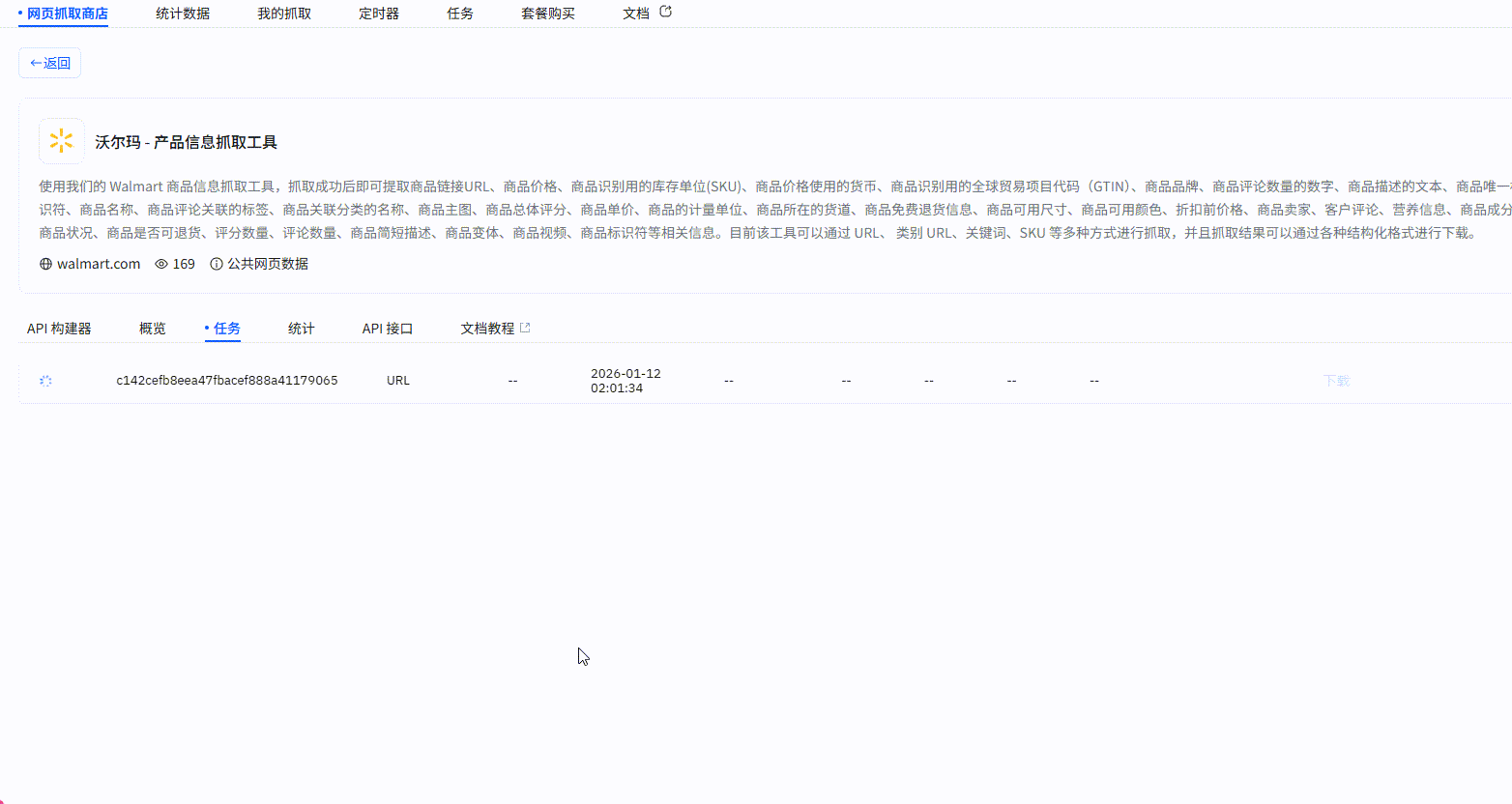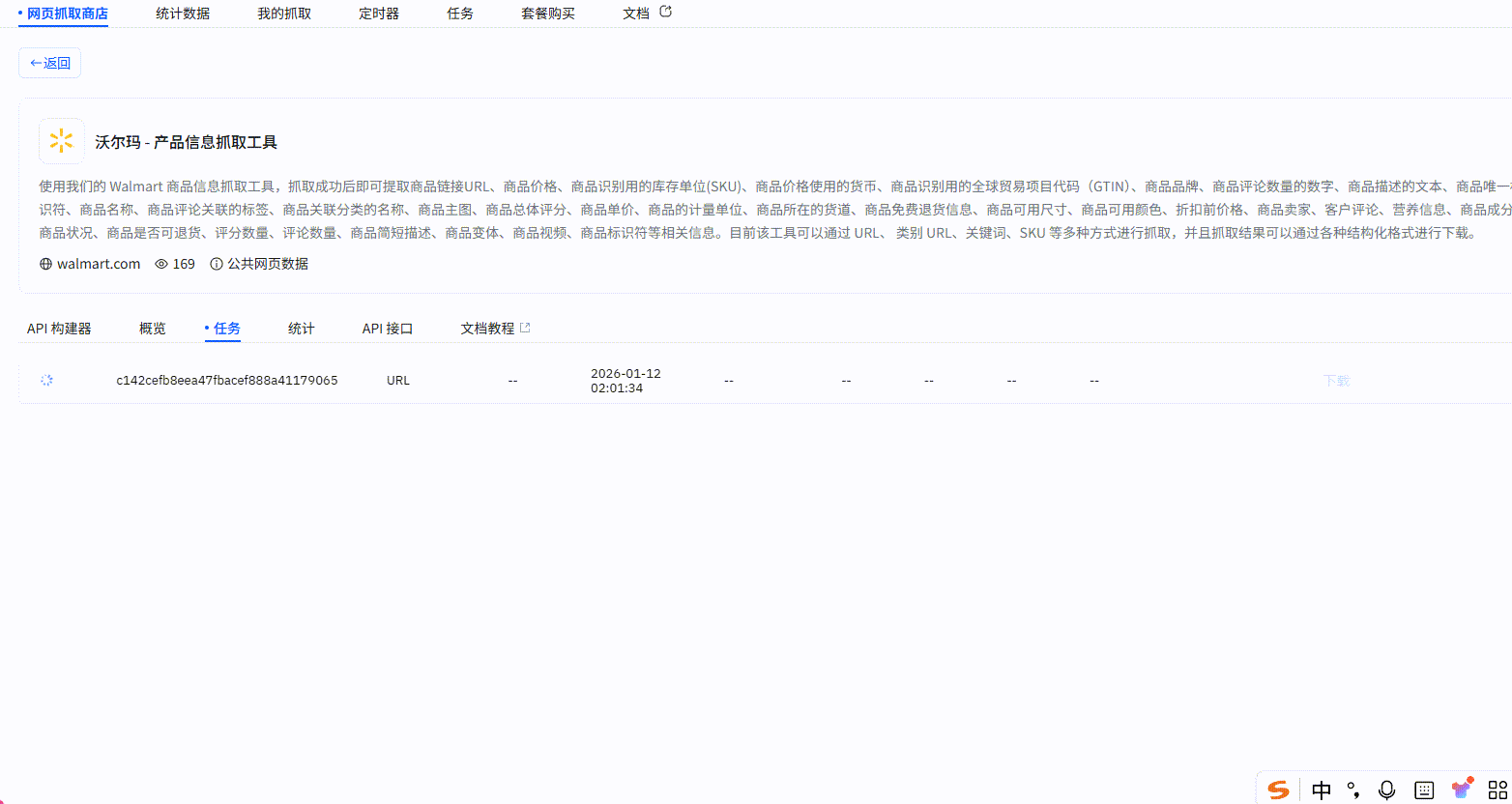
在IPIDEA主页找到网页抓取API:


点击提交请求,这样就一键创建好一个爬虫任务:
我们也可以自定义URL:例如
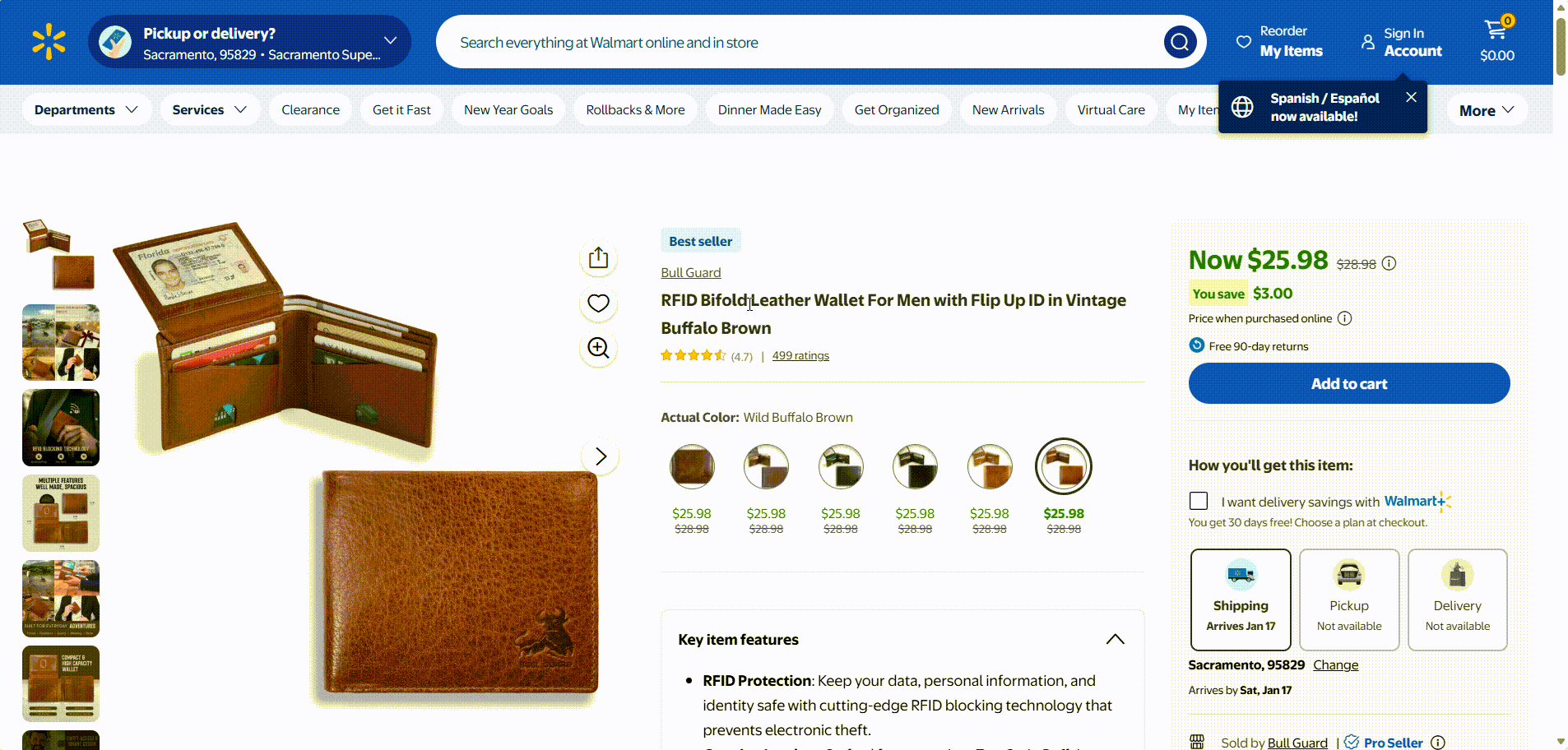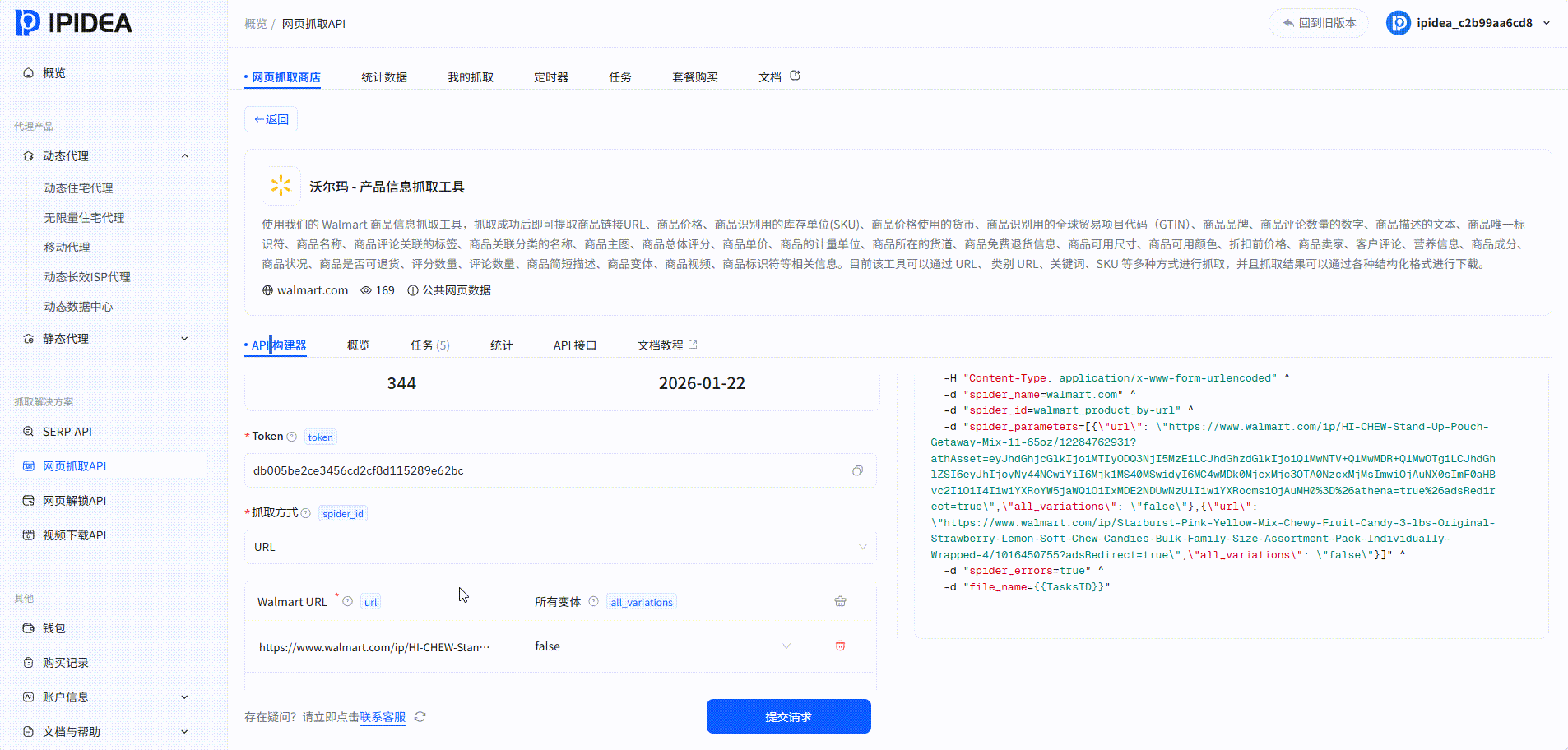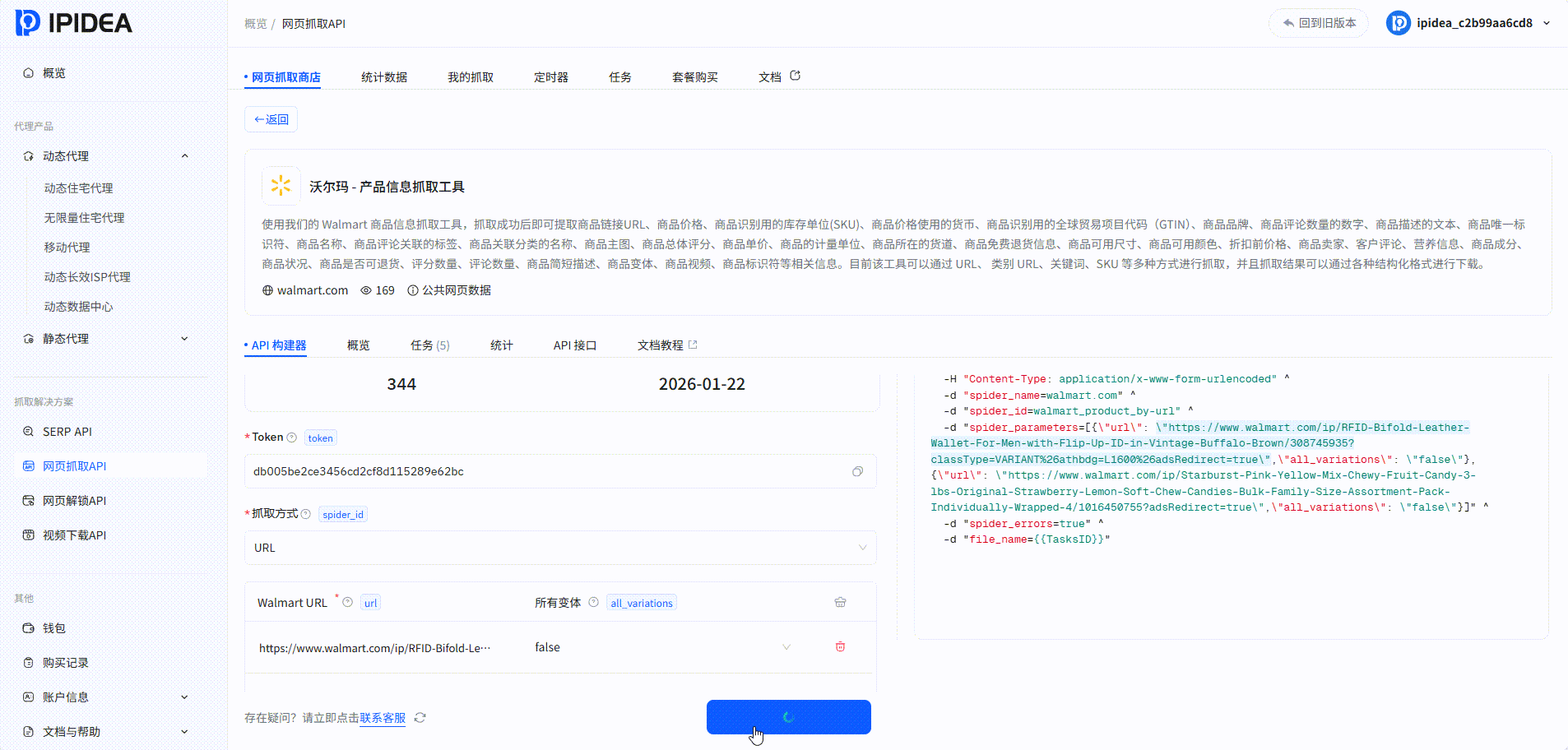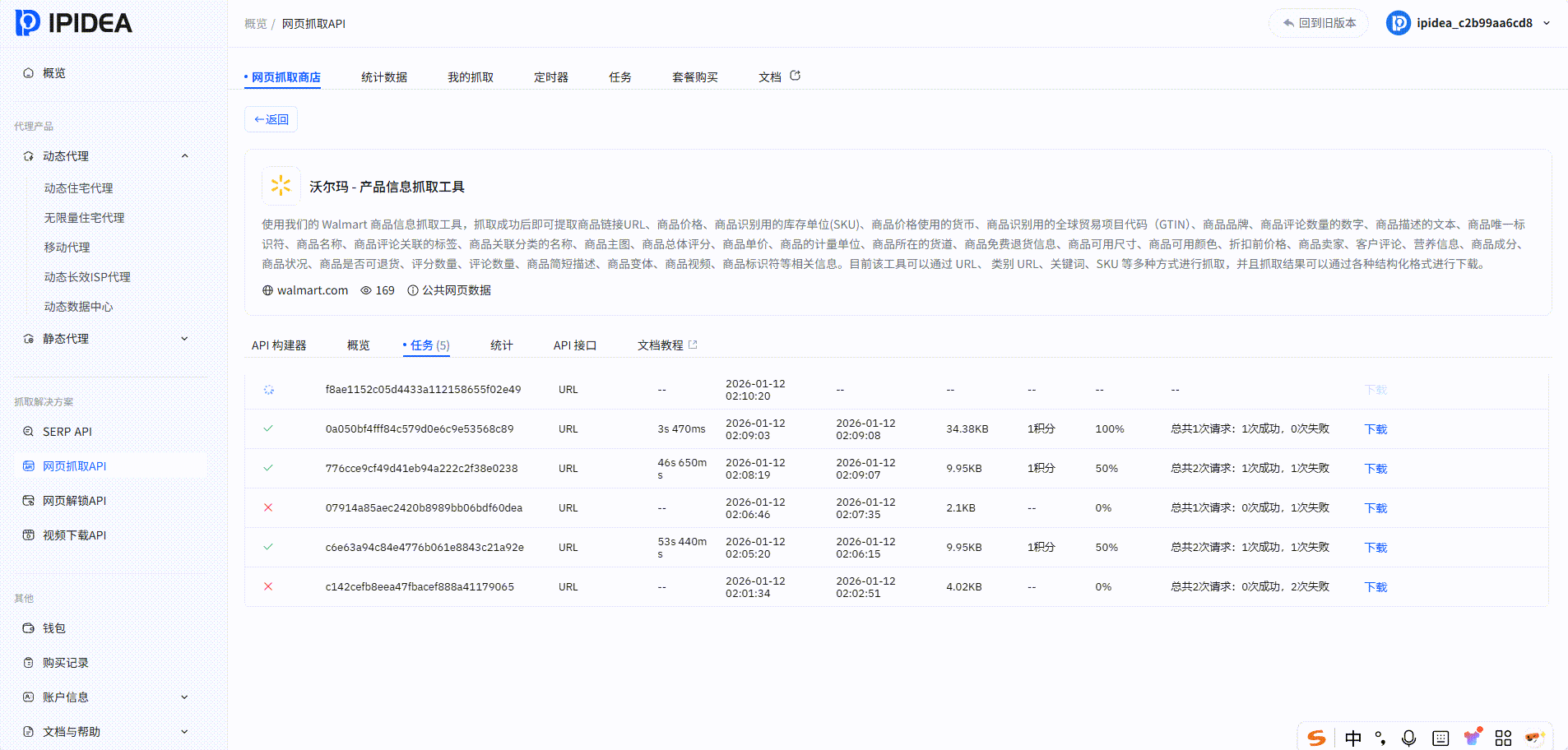
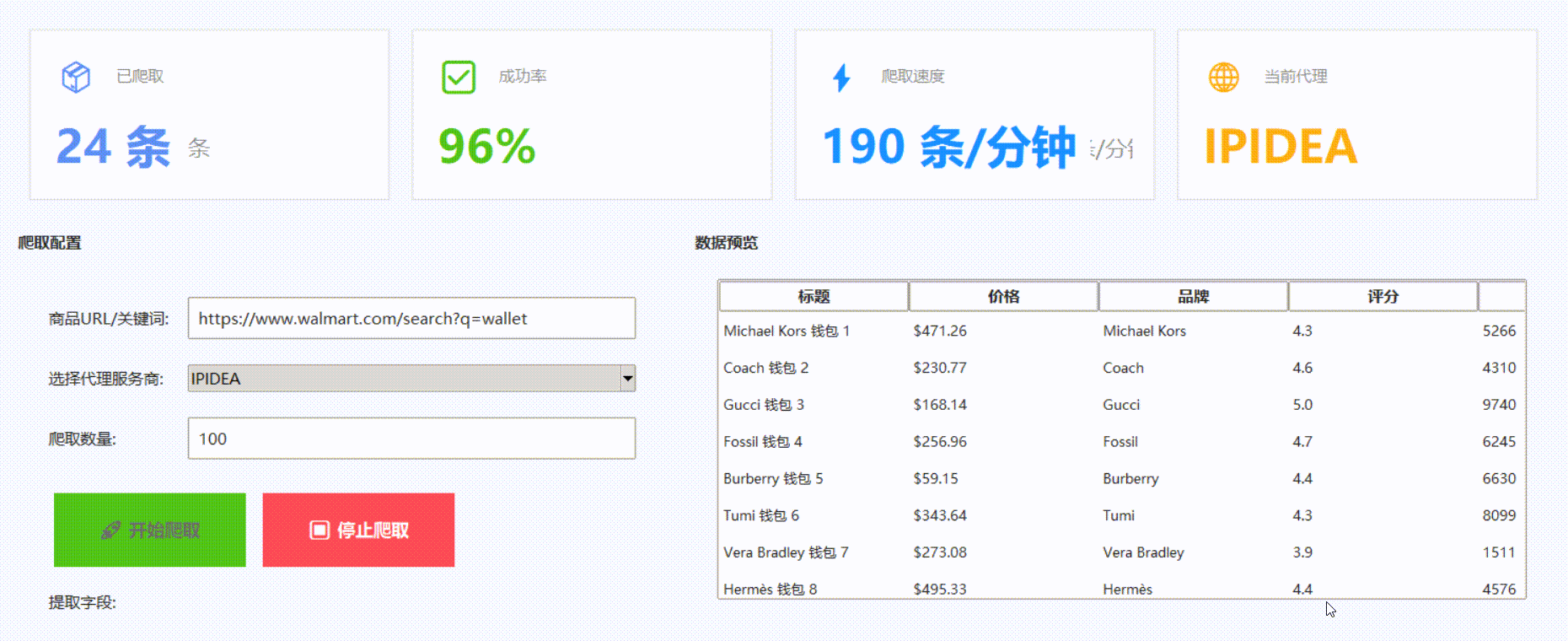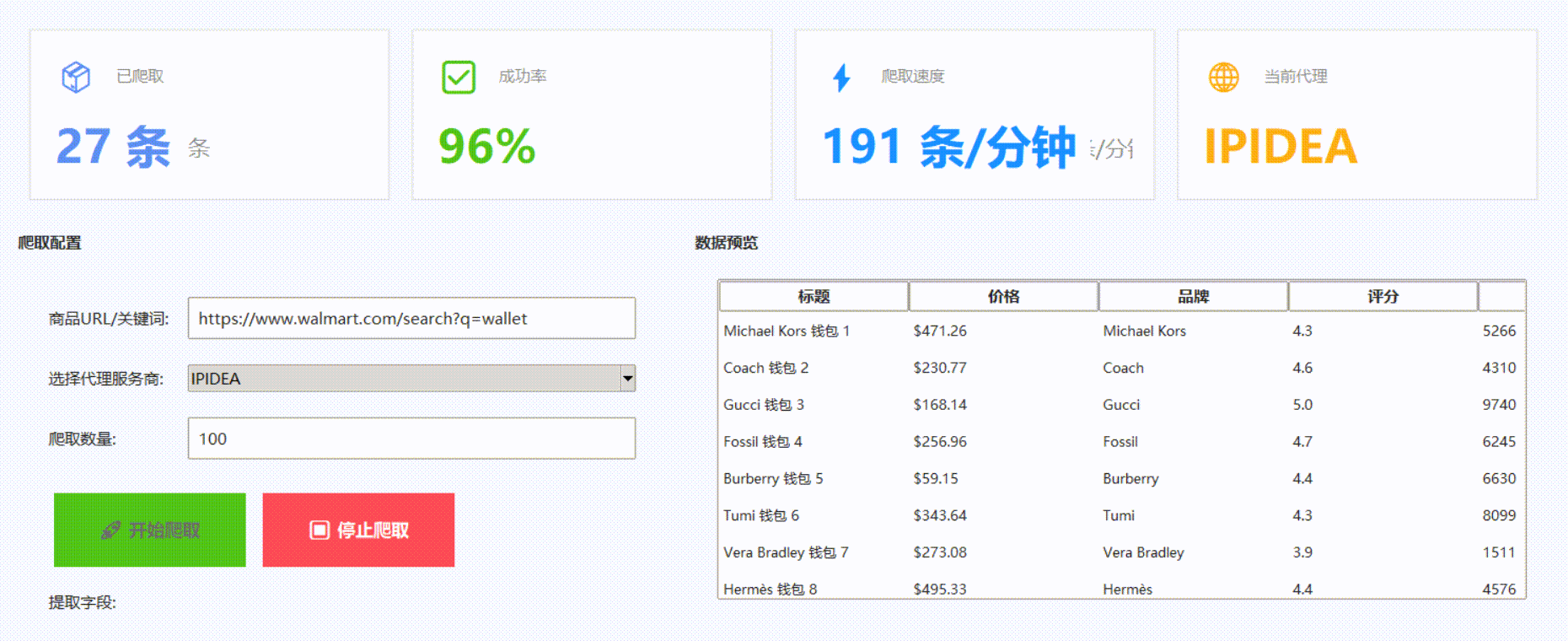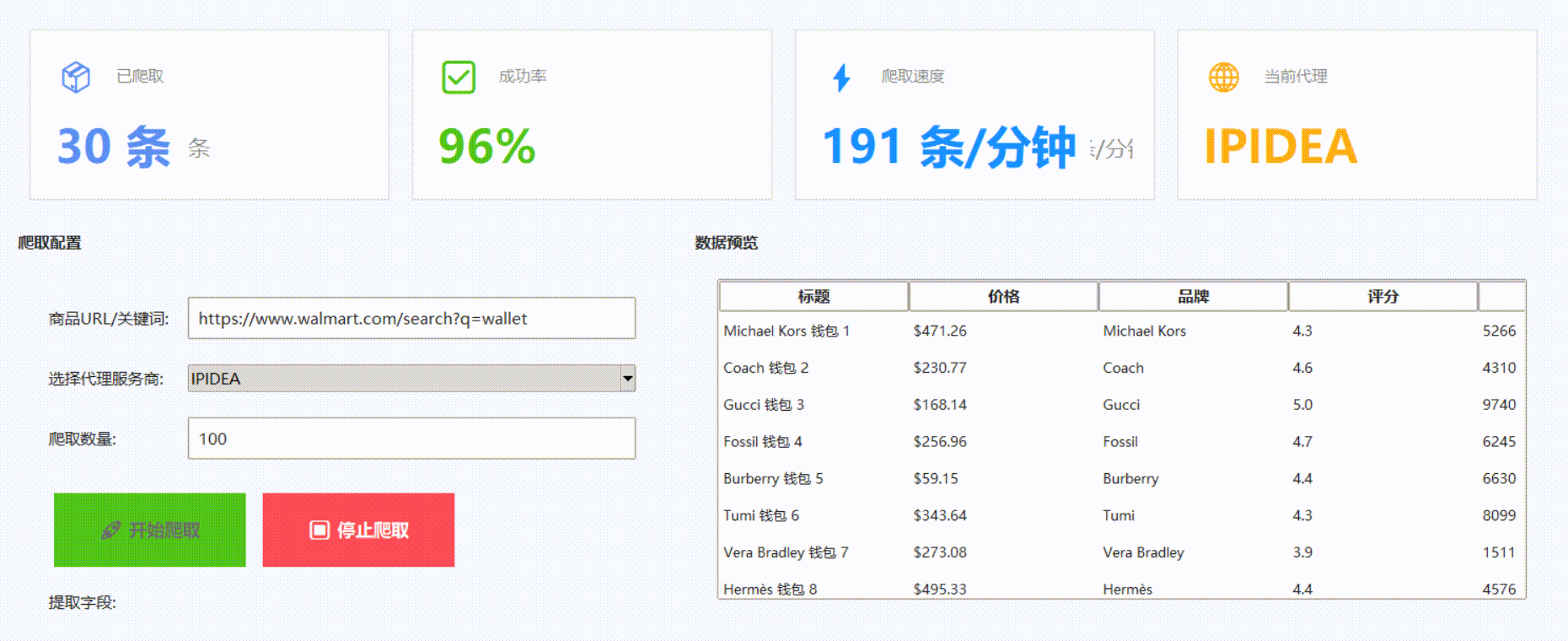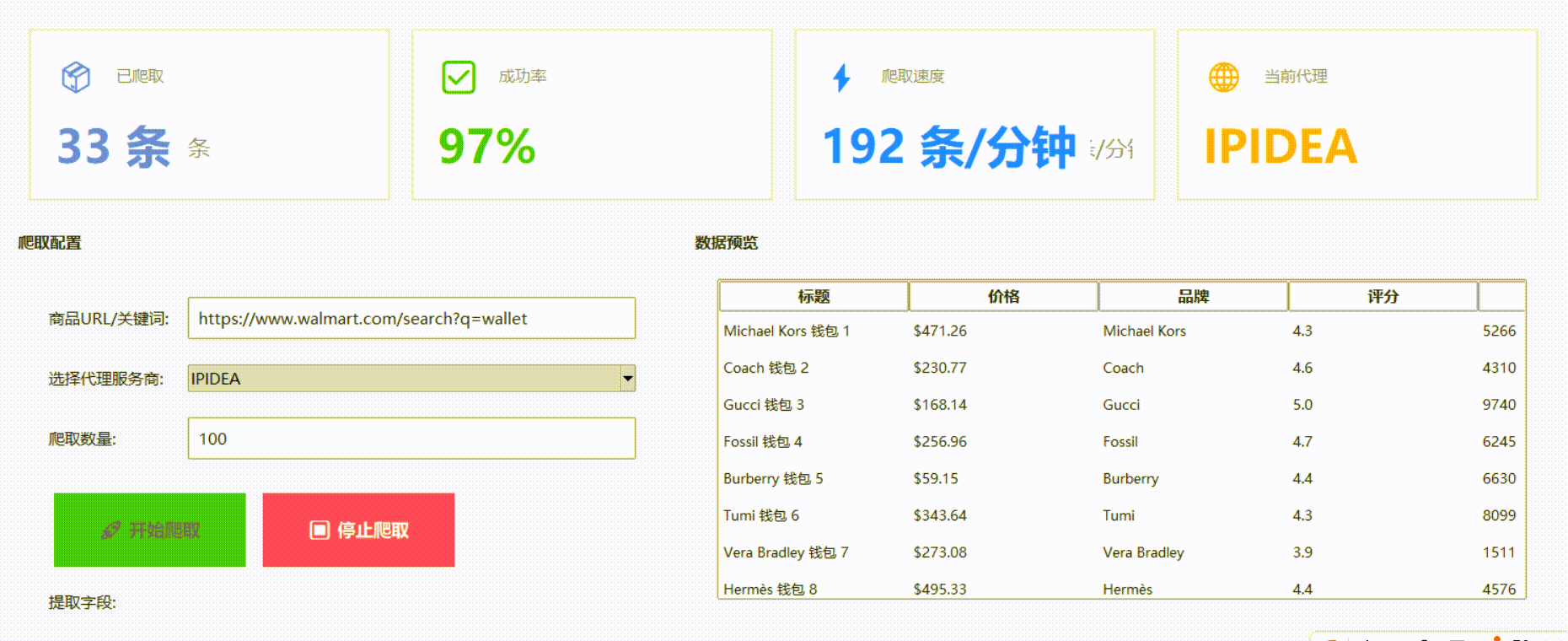
我们可以看到抓取时长以及数据持久化的格式,我们可以来对比一下抓取的效果

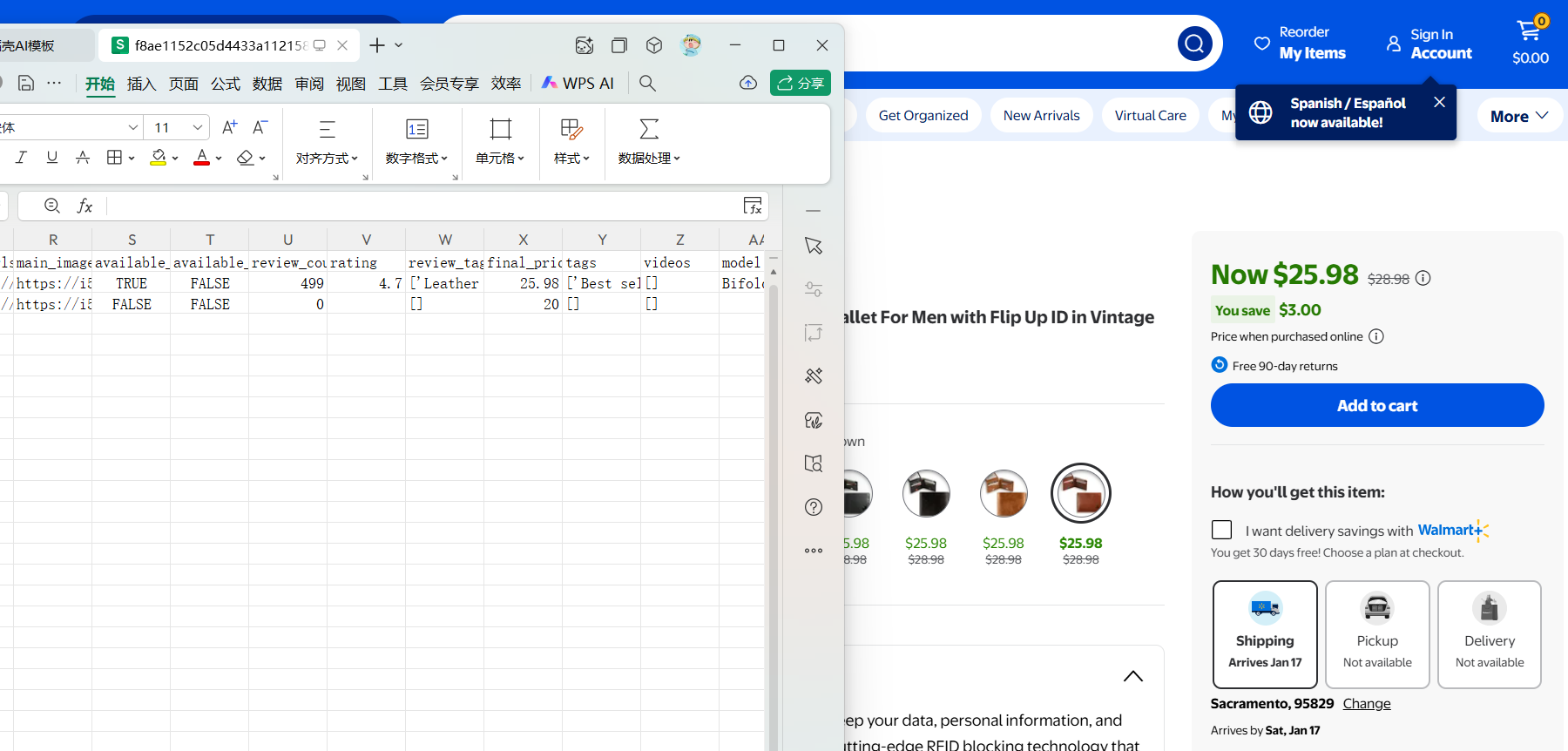
从返回结果可见,内容已成功获取,数据完整、结构清晰。
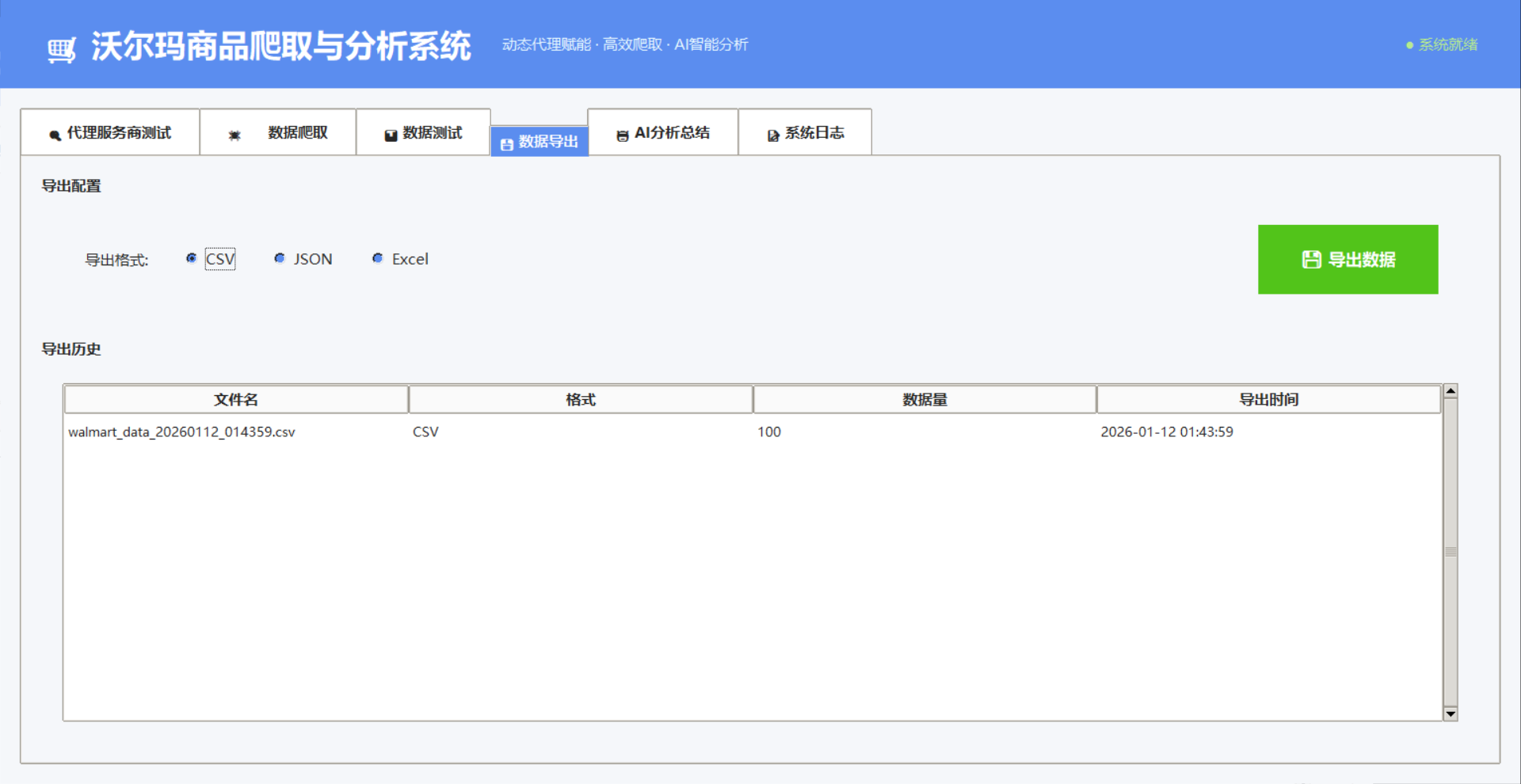
六、总结与展望
通过"高质量动态代理(IPIDEA) + 健壮的爬虫工程 + AI智能分析"的三层架构,我们构建了从数据获取到商业决策的完整闭环。
电商数据智能正在从描述性分析向预测性、处方性分析演进。那些能率先构建数据获取-清洗-分析-行动完整闭环的企业,将在万亿电商市场中建立难以逾越的竞争壁垒。而这一切的起点,正是从稳定、高效、智能的数据获取开始。