1. VLN算法的本质
VLN(Vision-and-Language Navigation,视觉语言导航)的本质是多模态时序决策问题 。
它要求智能体同时理解视觉环境与自然语言指令,在连续的环境中进行一系列导航动作,最终完成指定任务。
1.1 如何理解VLN的本质是"多模态时序决策问题"
把它拆成三个关键词来理解:
- 多模态 :VLN需要同时处理视觉信号 (环境图像)和语言信号 (导航指令),并建立两者的关联。比如指令"在第三个路口左转",智能体需要识别"路口"的视觉特征,同时理解语言中的"第三个""左转"等语义。
LLM VLM VL-Align + 3D 感知 + 识别 理解 + 规划 + 控制调用 = VLN - 时序 :导航是一个连续的过程,每一步动作(前进、转向)都会改变当前状态,且后续决策依赖于历史路径和指令上下文。例如,智能体需要记住"已经走过两个路口",才能正确执行"第三个路口左转"的指令。
上下文窗口长度限制的突破,Laguage 相对性的理解与记忆(一些相对性的概念) - 决策 :在每一个时间步,智能体都需要根据当前视觉、语言和历史信息,选择最优的动作。这是一个动态的决策过程,而非一次性的匹配任务。
-大的任务结构后,每一个小的task的实现与决策组成最后的一个整体任务。
小的task结构成一个动作,动作的执行到位对最终结果的影响。
1.2 如何理解"算法范式"
算法范式可以看作是VLN领域中被广泛验证的底层技术框架,它定义了模型"如何学习导航策略"的核心逻辑。不同的范式对应着不同的学习假设和技术路径,所有论文的创新都是在这些范式基础上的改进或融合。
1.3 三大VLN算法范式的差异、优缺点对比
| 范式类型 | 核心逻辑 | 优点 | 缺点 |
|---|---|---|---|
| 模仿学习 | 学习人类专家的示范路径,以"是否与示范路径一致"为监督信号 | 训练速度快,初期收敛稳定;无需复杂奖励设计 | 依赖高质量示范数据,存在错误累积风险;泛化能力弱,难以应对陌生场景 |
| 强化学习 | 智能体与环境交互试错,以"奖励最大化"为目标优化策略 | 无需示范数据,可自主探索最优路径;具备自我纠错能力 | 数据效率低,训练周期长;奖励函数设计不当易引发"奖励黑客";稀疏奖励下学习困难 |
| 预训练-微调 | 先在大规模多模态数据集上预训练,学习通用的视觉-语言对齐能力,再在VLN任务上微调 | 利用预训练知识提升数据效率;泛化能力更强,可快速适配新场景 | 预训练数据与下游任务存在偏差时,效果会下降;需要大规模计算资源支持预训练 |
训练和与训练决定算法范式上限,微调 lora 技术只是告诉模型该如何优雅的表达,表达的范式 (只起到调节权重作用,并不会增强模型的能力,仅仅是针对性表达,表征的)
2. 如何系统性认识VLN
-
从任务性质拆解
- 视觉理解:识别环境中的物体、场景与空间关系。
- 语言理解:解析指令中的目标、路径约束与语义逻辑。
- 视觉-语言匹配:建立语言描述与视觉场景的对应关系。
- 记忆与决策:记忆已探索路径,结合当前状态预测下一步动作。
-
从算法范式切入
- 可以将现有VLN算法按技术路线分为模仿学习、强化学习、预训练-微调等几大范式。
- 新论文的创新点通常是在这一框架下,针对数据匮乏、泛化能力弱等痛点进行优化。
-
从技术挑战梳理
- 围绕**环境表征、语言交互、数据效率、跨场景泛化等核心难点,**去理解不同算法的解决思路。
-
从落地场景反推
- 结合机器人导航、虚拟场景交互等实际需求,分析算法的性能瓶颈与优化方向。
3. VLN最大的难点和痛点
-
数据匮乏与泛化能力弱
- 现有训练场景和数据有限,模型在训练过的场景中表现较好,但面对陌生场景时导航成功率会大幅下降。
- 很难通过有限数据覆盖真实世界的所有复杂环境。
-
多模态对齐与推理难
- 语言指令的模糊性(如"前面左转")和视觉场景的复杂性(如相似的房间布局),会导致视觉与语言的匹配出现偏差。
- 智能体需要具备复杂的时序推理能力,才能理解长指令中的路径逻辑。
-
环境表征与记忆挑战
- 构建准确的环境全局表征,同时高效记忆已探索路径,是避免迷路和重复探索的关键。
- 动态变化的环境(如移动的障碍物)会进一步增加这一难度。
-
奖励函数设计困境
- 在强化学习框架下,稀疏的任务完成奖励会导致学习效率低下。
- 稠密奖励又容易引发"奖励黑客"问题,导致智能体投机取巧而非真正完成导航。
3.1 三大VLN算法范式的差异、优缺点对比
| 范式类型 | 核心逻辑 | 优点 | 缺点 |
|---|---|---|---|
| 模仿学习 | 学习人类专家的示范路径,以"是否与示范路径一致"为监督信号 | 训练速度快,初期收敛稳定;无需复杂奖励设计 | 依赖高质量示范数据,存在错误累积风险;泛化能力弱,难以应对陌生场景 |
| 强化学习 | 智能体与环境交互试错,以"奖励最大化"为目标优化策略 | 无需示范数据,可自主探索最优路径;具备自我纠错能力 | 数据效率低,训练周期长;奖励函数设计不当易引发"奖励黑客";稀疏奖励下学习困难 |
| 预训练-微调 | 先在大规模多模态数据集上预训练,学习通用的视觉-语言对齐能力,再在VLN任务上微调 | 利用预训练知识提升数据效率;泛化能力更强,可快速适配新场景 | 预训练数据与下游任务存在偏差时,效果会下降;需要大规模计算资源支持预训练 |
3.2 为什么要通过技术挑战梳理来理解算法思路
VLN的技术挑战是所有算法设计的出发点和落脚点,不同范式正是为了解决不同痛点而诞生的:
- 环境表征 :模仿学习依赖专家标注的路径 ,本质是用人类的空间认知来替代模型自主构建环境表征; 强化学习 则需要模型通过交互动态更新环境地图,对表征能力要求更高;预训练-微调范式会利用预训练中的视觉特征提取能力,来优化环境表征的质量。
- 语言交互:模仿学习直接匹配示范路径与指令,语言理解停留在表层;强化学习需要模型实时解析指令并生成动作,对语言的时序推理能力要求更高;预训练-微调范式通过大规模文本-图像预训练,能更好地理解复杂指令的语义逻辑。
- 数据效率:模仿学习依赖标注数据,数据效率低;强化学习需要大量交互数据,效率更低;预训练-微调通过迁移通用知识,大幅降低了对下游任务数据的依赖,是目前提升数据效率的主流方案。
- 跨场景泛化:模仿学习泛化能力最差,仅能适应训练场景;强化学习通过交互探索可一定程度泛化,但受限于训练环境;预训练-微调利用预训练中的跨场景知识,能显著提升模型在陌生环境中的导航成功率。
3.3 VLN 算法范式与技术挑战对应清单
这个清单清晰展示了每种算法范式是如何针对性地解决VLN核心痛点的,帮你快速建立技术思路的对应关系。
| 技术挑战 | 模仿学习的解决思路 | 强化学习的解决思路 | 预训练-微调的解决思路 |
|---|---|---|---|
| 环境表征构建 | 依赖人类示范路径的空间标注,用专家的环境认知替代模型自主构建,降低表征难度 | 通过与环境的动态交互,逐步更新全局环境地图,提升表征的动态准确性 | 利用预训练模型的视觉特征提取能力,结合多模态对齐,构建更鲁棒的环境语义表征 |
| 视觉-语言交互 | 直接匹配示范路径与指令文本,通过监督学习实现表层语义对齐 | 实时解析指令并生成动作,结合奖励反馈优化语言推理与动作的关联 | 借助大规模预训练中的跨模态对齐能力,理解复杂指令的时序逻辑与空间关系 |
| 数据效率低 | 依赖高质量标注数据,数据效率本质不高,但训练速度快 | 需大量交互试错,数据效率最低,但可自主生成数据 | 迁移预训练的通用知识,大幅减少下游任务所需数据量,是提升数据效率的核心方案 |
| 跨场景泛化弱 | 仅能适配训练过的场景,泛化能力最差 | 通过自主探索陌生场景,可一定程度泛化,但受限于训练环境的多样性 | 利用预训练数据的跨场景覆盖性,结合微调适配新场景,泛化能力最强 |
| 错误累积风险 | 无法避免,示范中的错误会被模型继承和放大 | 可通过奖励反馈自我纠正,动态调整策略以减少错误累积 | 依赖预训练的通用知识减少底层错误,微调阶段进一步优化策略 |
| 奖励函数设计难 | 无需设计奖励函数,直接以示范路径为监督信号 | 必须设计奖励函数,稀疏奖励下学习效率低,易出现"奖励黑客" | 微调阶段可结合模仿学习或强化学习的监督信号,降低纯强化学习的奖励设计压力 |
4. VLN 背景机器定义
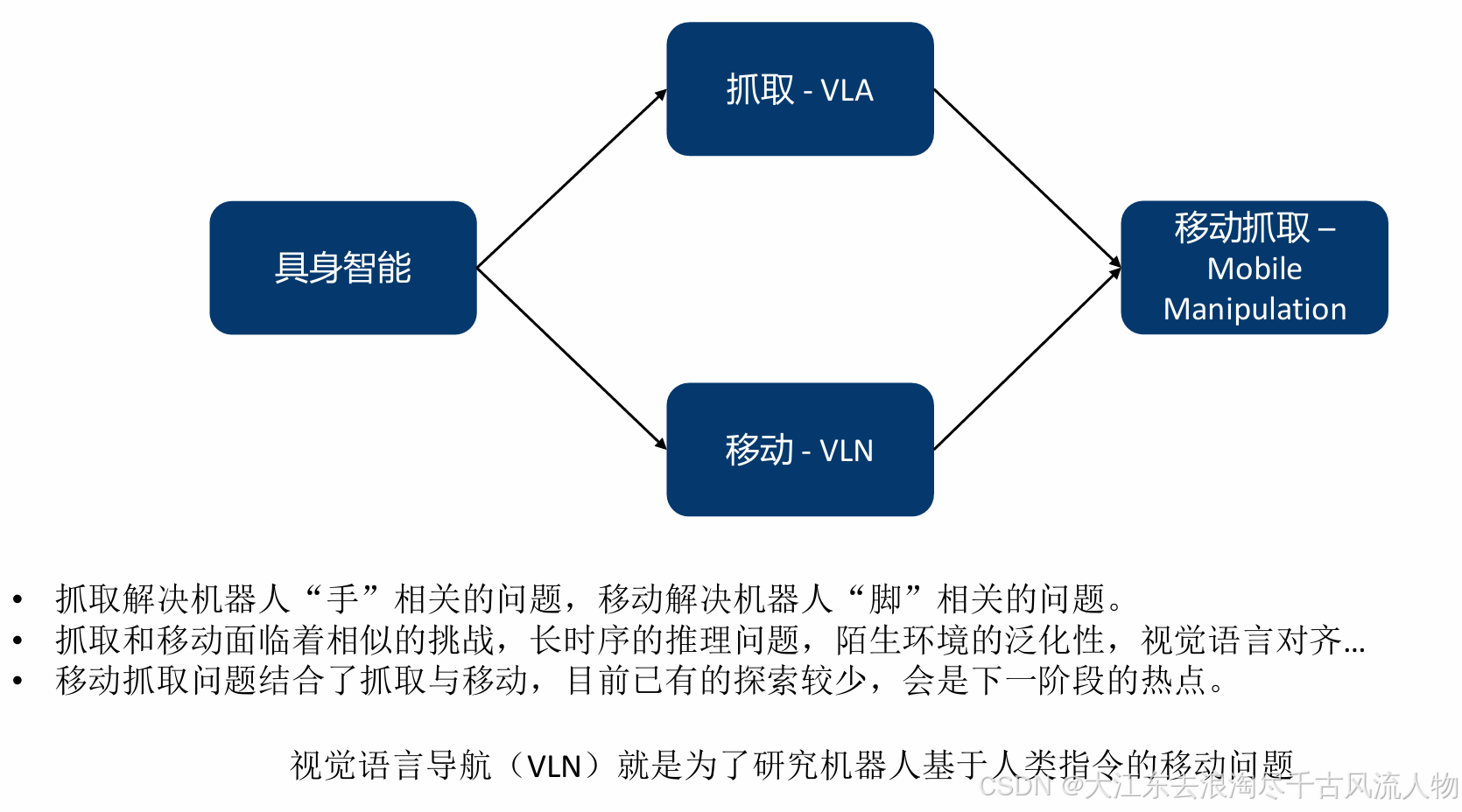
1. 具身智能背景下的VLN
2. 视觉语言导航和传统导航的差异
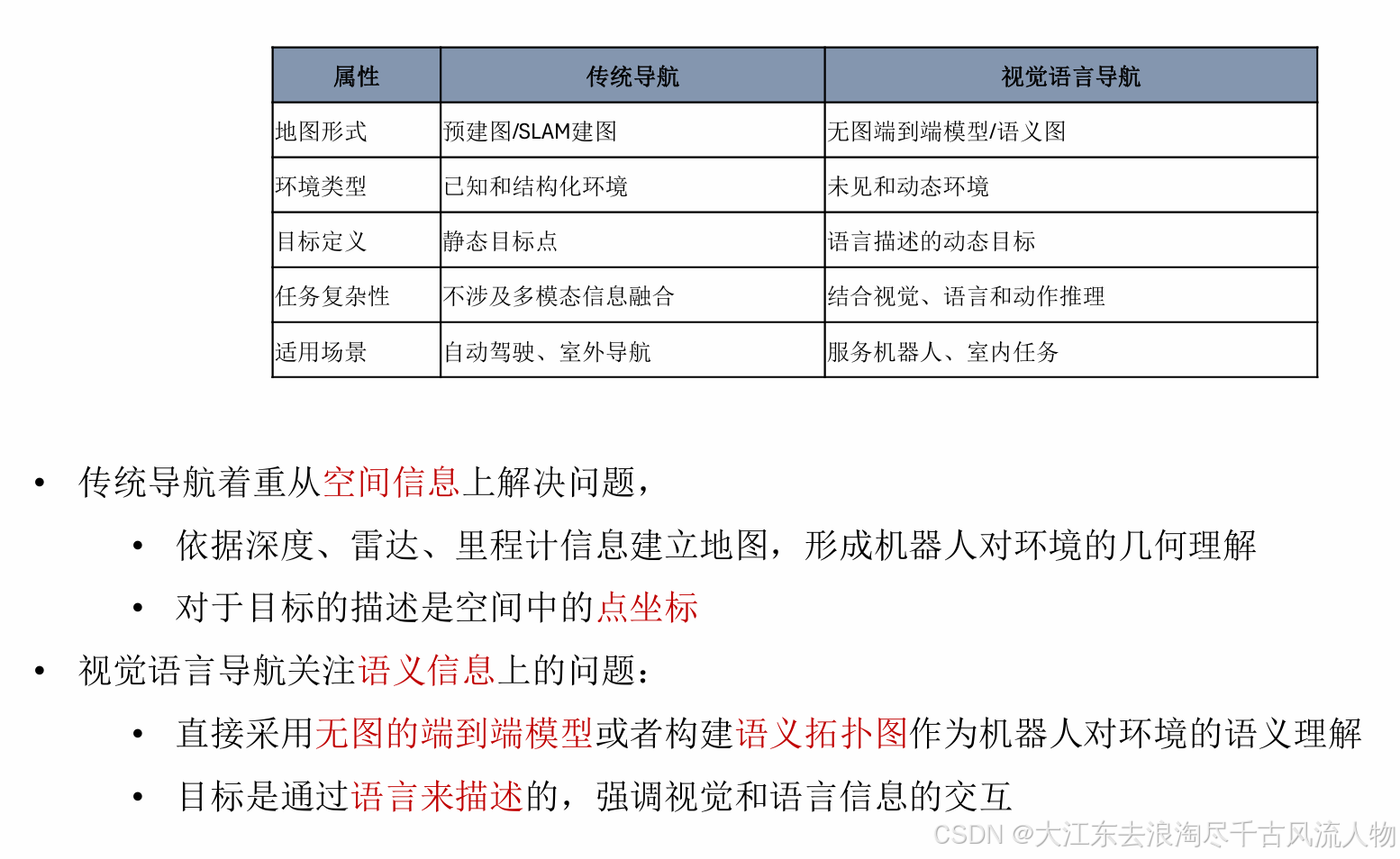
VLN定义:

这个和深度模型的训练大同小异


训练数据集 MP3D 主要训练数据集
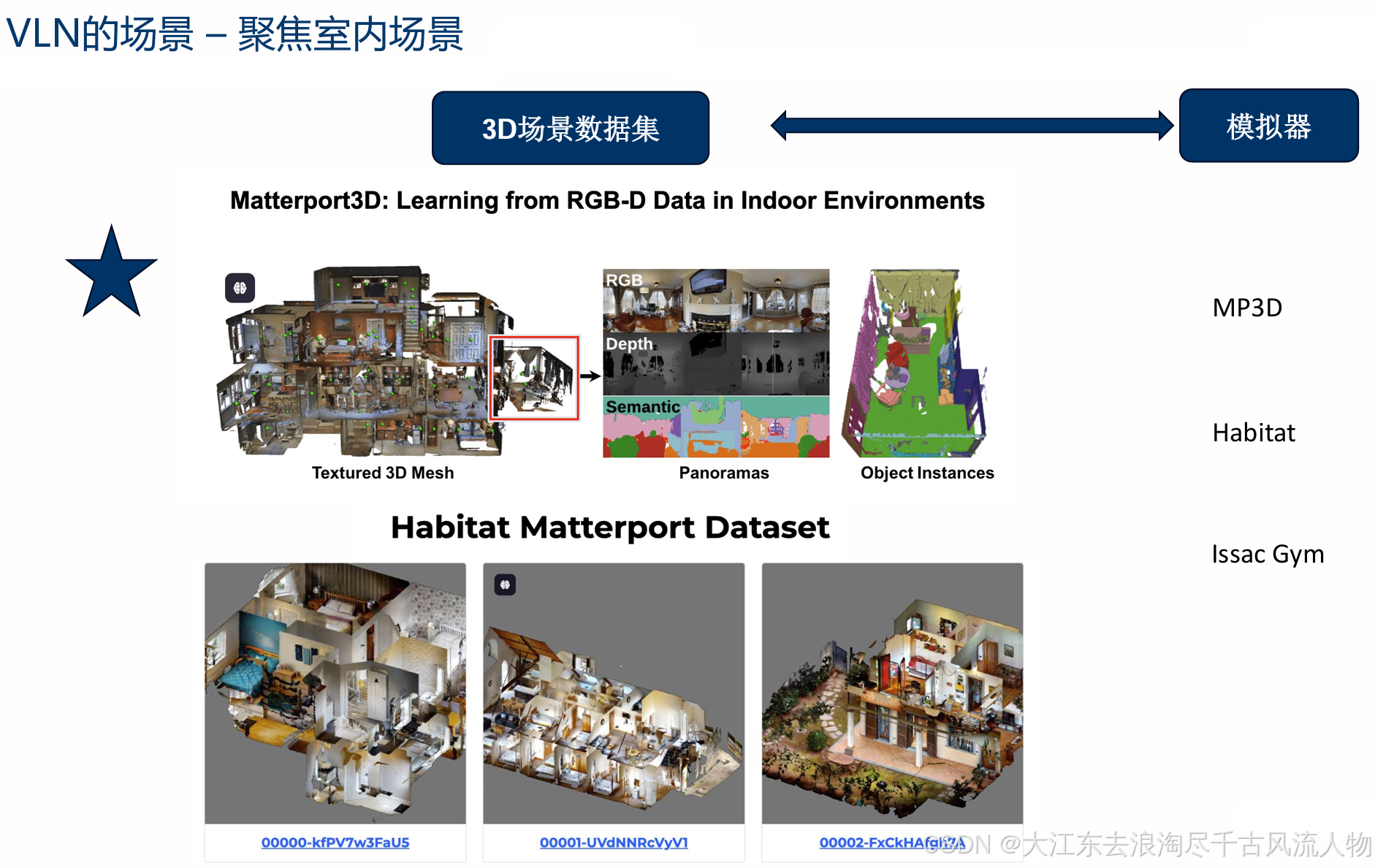
任务描述:一段描述路径的文字,限定了途径点,以及结束的位置。
起始条件: 机器人预先不知道环境的任何信息,从描述的起点出发。
成功条件:机器人到目标点,做出结束动作,即为成功
VLN的Agent -- 以R2R为例:
构型:虚拟的Agent
观测空间:360°RGB 图像,深度图像
动作空间:前进,左转,右转,停止
Agent在空间里遵循预定义的拓扑图运动
人类的视角来完成一次VLN任务

VLN的任务特点
| 类别 | 具体内容 |
|---|---|
| VLN的任务性质 | 1. 视觉的理解、语言的理解、视觉与语言的匹配(对于人类来说,非常简单) 2. 记忆历史信息,走过了哪些地方 3. 预测动作的结果,预测未来信息 4. 执行正确的导航动作 |
| VLN的挑战 | 1. 编码视觉信息,构建环境的表征 2. 编码语言信息,与视觉信息交互 3. 训练场景,训练数据的有限性 4. 泛化到新的场景 |
算法如何学习
| 学习方式 | 具体特点 |
|---|---|
| 模仿学习 | - 需要示范数据:最短路径,人类标注 - 监督信号:是否和示范路径一致 - 训练速度快 - 存在错误的累积风险 |
| 强化学习 | - 通过与环境的交互来学习,获取奖励 - 监督信号:奖励的最大化。巴普洛夫的狗 - 数据效率低 - 可以学习自我纠正 |
3. 模仿学习 vs 强化学习 对比表
模仿学习 小孩子成长过程
强化学习 巴普洛夫的狗
| 对比维度 | 模仿学习 | 强化学习 |
|---|---|---|
| 定义 | 学习人类/专家的示范数据,复刻其行为以完成任务 | 智能体通过与环境交互、试错探索,以最大化奖励信号为目标来学习最优策略 |
| 核心特点 | 直接复用已有经验,复刻示范行为 | 自主探索环境,通过奖励反馈动态调整行为 |
| 适用场景 | 有高质量专家示范数据的场景;任务规则明确、路径固定的场景(如VLN中的人类标注导航) | 无示范数据、环境未知的场景;需要动态适应、自我优化的场景(如复杂游戏、机器人自主导航) |
| 风险 | 存在错误累积风险,示范中的错误会被延续和放大 | 探索过程中可能因试错导致任务失败;奖励函数设计不当易引发策略偏差 |
| 数据依赖 | 高度依赖高质量的人类示范数据(如最短路径标注) | 不需要示范数据,但依赖大量环境交互生成的试错数据 |
| 是否属于监督类型 | 属于监督学习范畴(以示范数据为监督信号) | 不属于监督学习,属于交互学习范畴 |
| 训练数据依赖 | 依赖静态的、已标注的示范数据集 | 依赖动态生成的环境交互数据(奖励信号、状态转移数据) |
目前VLN算法的根本驱动来自于应对数据的匮乏
VLN 是一个 多模态的时序决策问题
• 理解这个范式,你会发现VLN各种论文的算法,创新点,都在这个框架之下
• 课程的内容也依据这个框架进行展开
• 解决看过很多论文,却依然无法形成系统性认知的痛点
• 再阅读新论文时,可以迅速对其进行归类
• 帮助你认识到领域内未解决的问题,构建自己的创新点