目录
- [1. YOLOv1网络结构](#1. YOLOv1网络结构)
-
- [1.1 网络结构](#1.1 网络结构)
- [1.2 参数计算过程](#1.2 参数计算过程)
- [1.3 参数列表和网络结构](#1.3 参数列表和网络结构)
- [2. 模型输出结构解析](#2. 模型输出结构解析)
- [3. 结果解析](#3. 结果解析)
-
- [3.1 x,y,w,h](#3.1 x,y,w,h)
- [3.2 置信度之IOU](#3.2 置信度之IOU)
- [3.3 概率值](#3.3 概率值)
- [3.4 模型输出结果](#3.4 模型输出结果)
- [3.5 类别置信度](#3.5 类别置信度)
- [3.6 非极大值抑制(NMS)](#3.6 非极大值抑制(NMS))
- [3.7 后处理输出结果](#3.7 后处理输出结果)
- [4. Yolov1损失函数](#4. Yolov1损失函数)
-
- [4.1 坐标损失](#4.1 坐标损失)
- [4.2 置信度损失](#4.2 置信度损失)
- [5. 训练过程](#5. 训练过程)
- [6. 总结](#6. 总结)
1. YOLOv1网络结构
1.1 网络结构
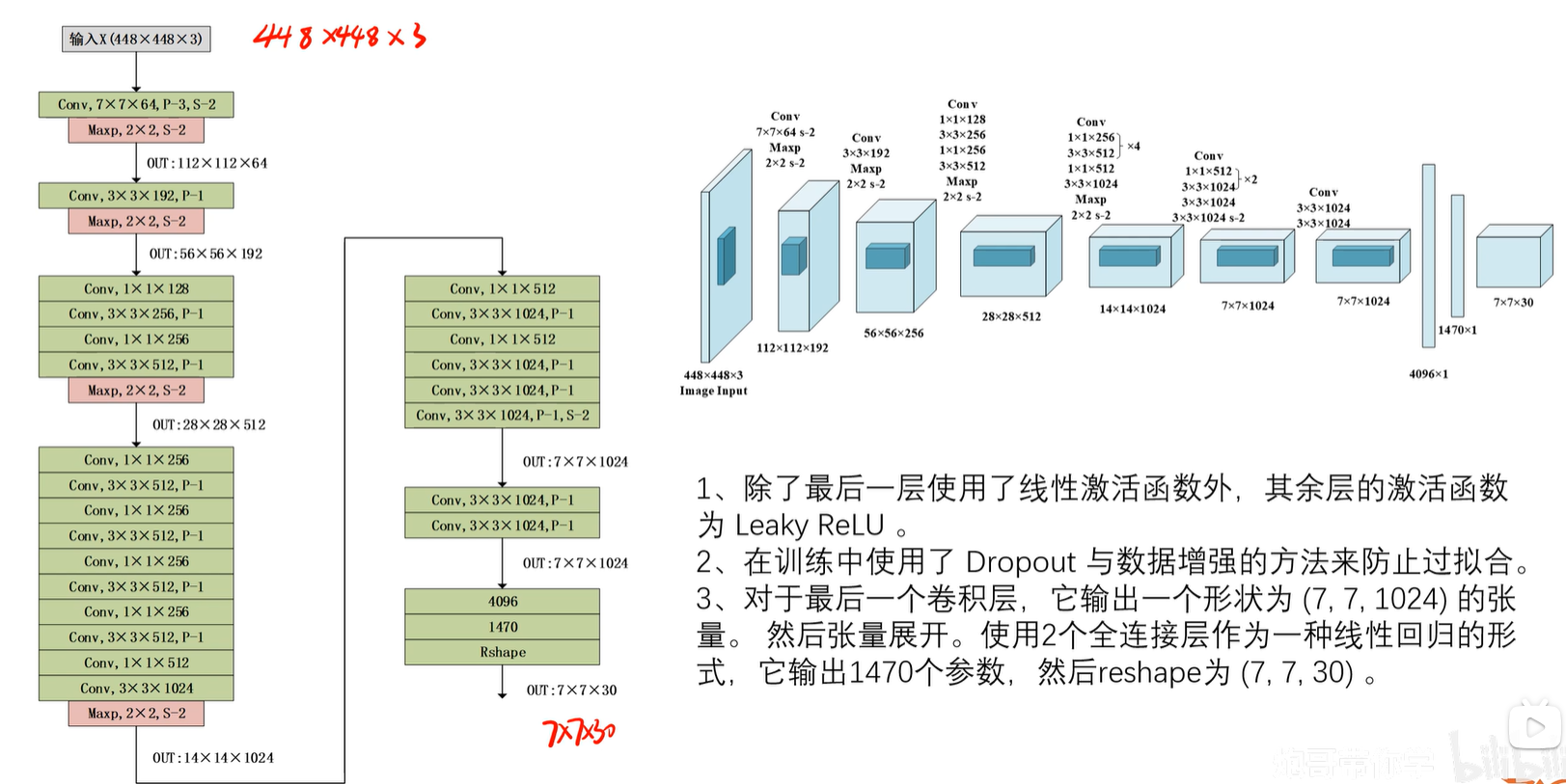
1.2 参数计算过程
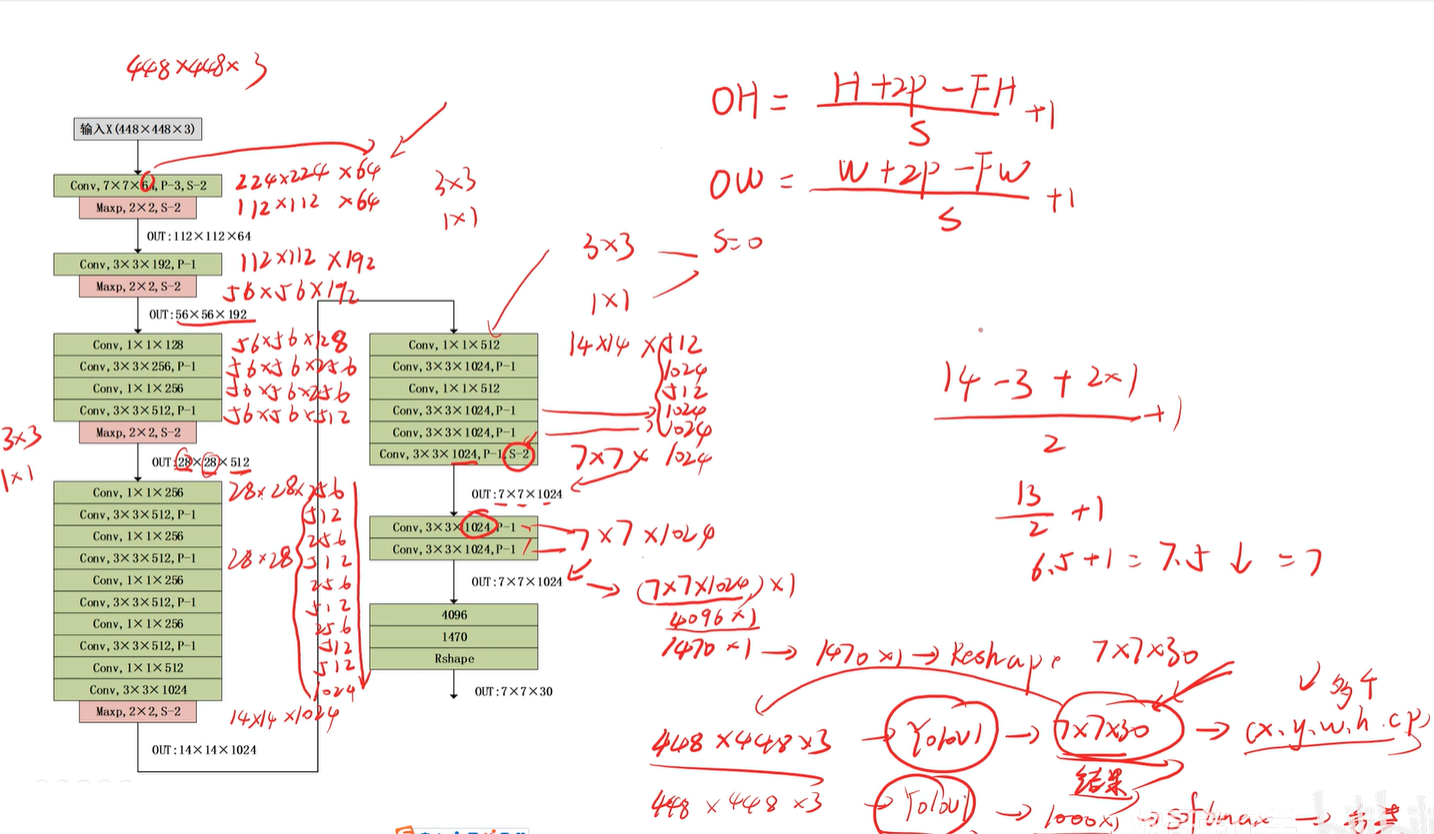
其中计算输出宽高的公式如下:
OH=H+2P-FH/S + 1
OW=W+2P-FW/S + 1
其中P为padding值,FW为卷积核宽,S是卷积核移动步长
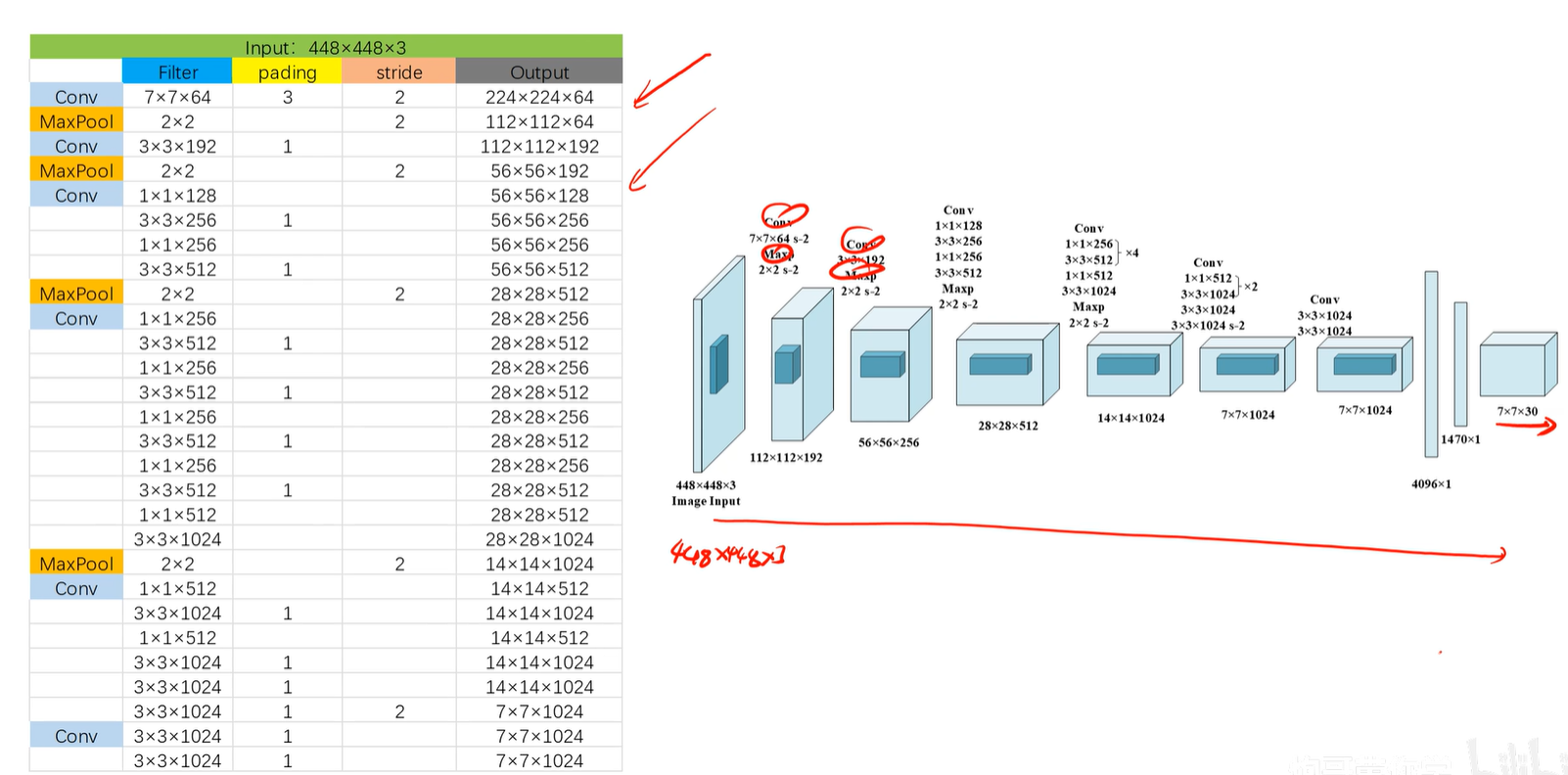
1.3 参数列表和网络结构
2. 模型输出结构解析
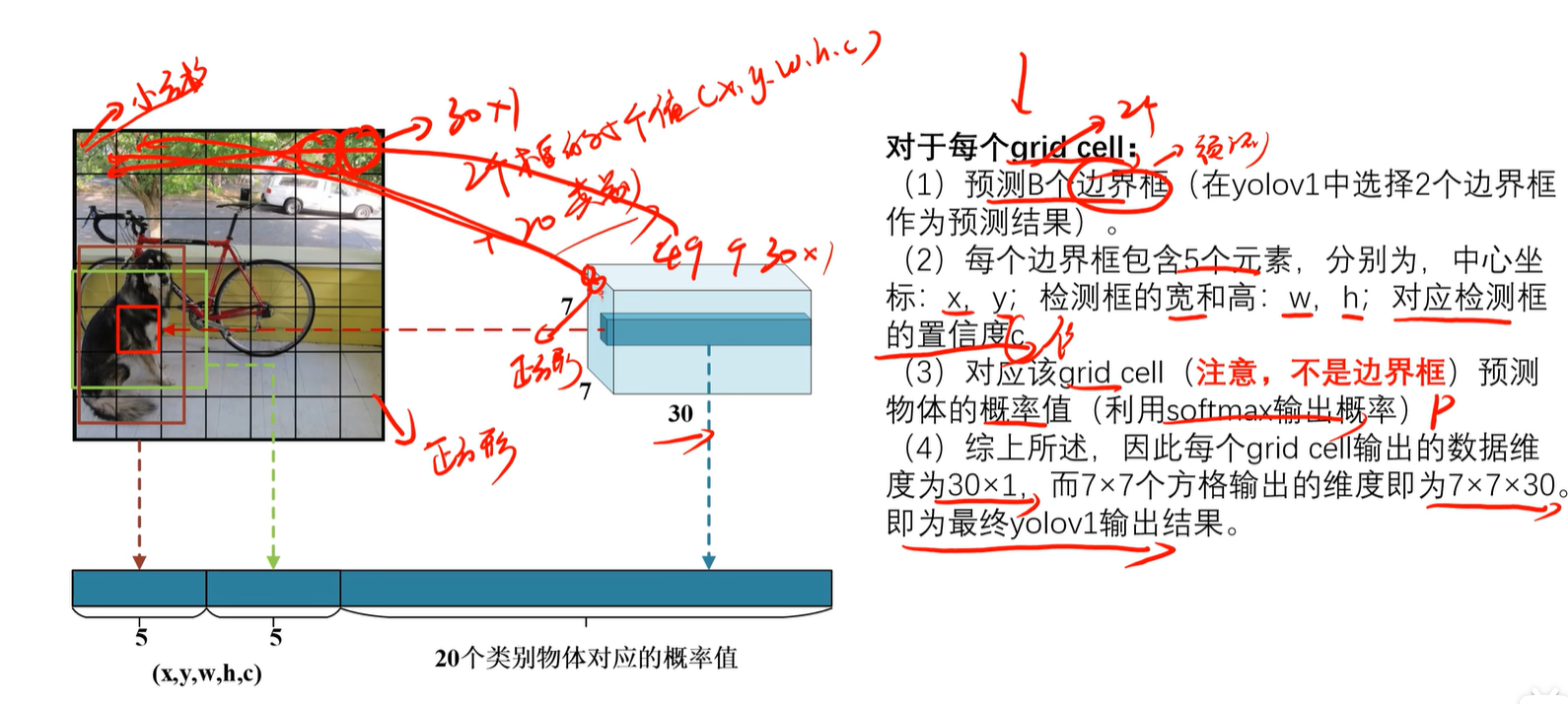
注意:这里每个小方格输出两个框,每个框数据包括(x,y,w,h,c)再加上20个分类的概率=30
3. 结果解析
3.1 x,y,w,h
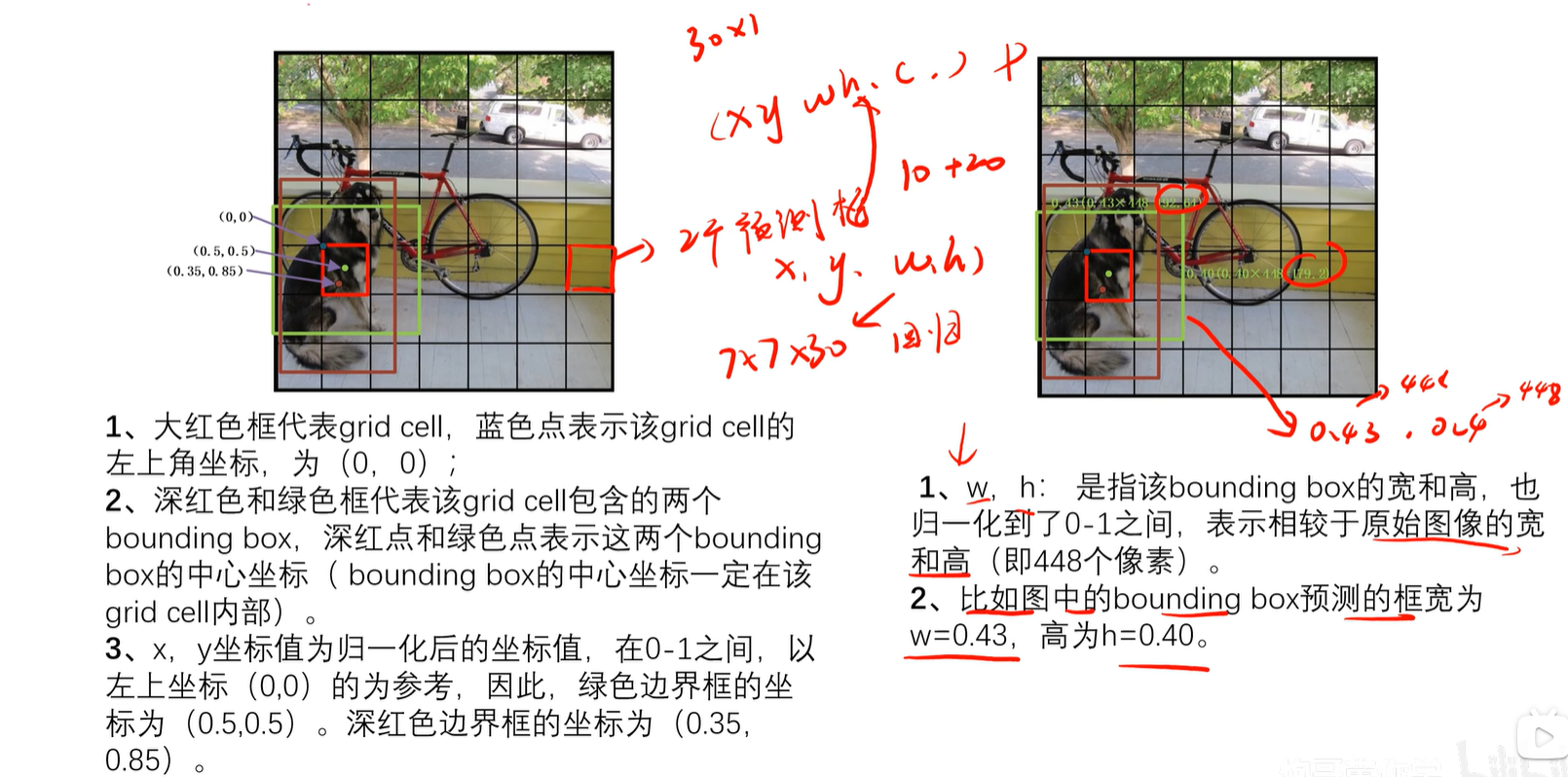
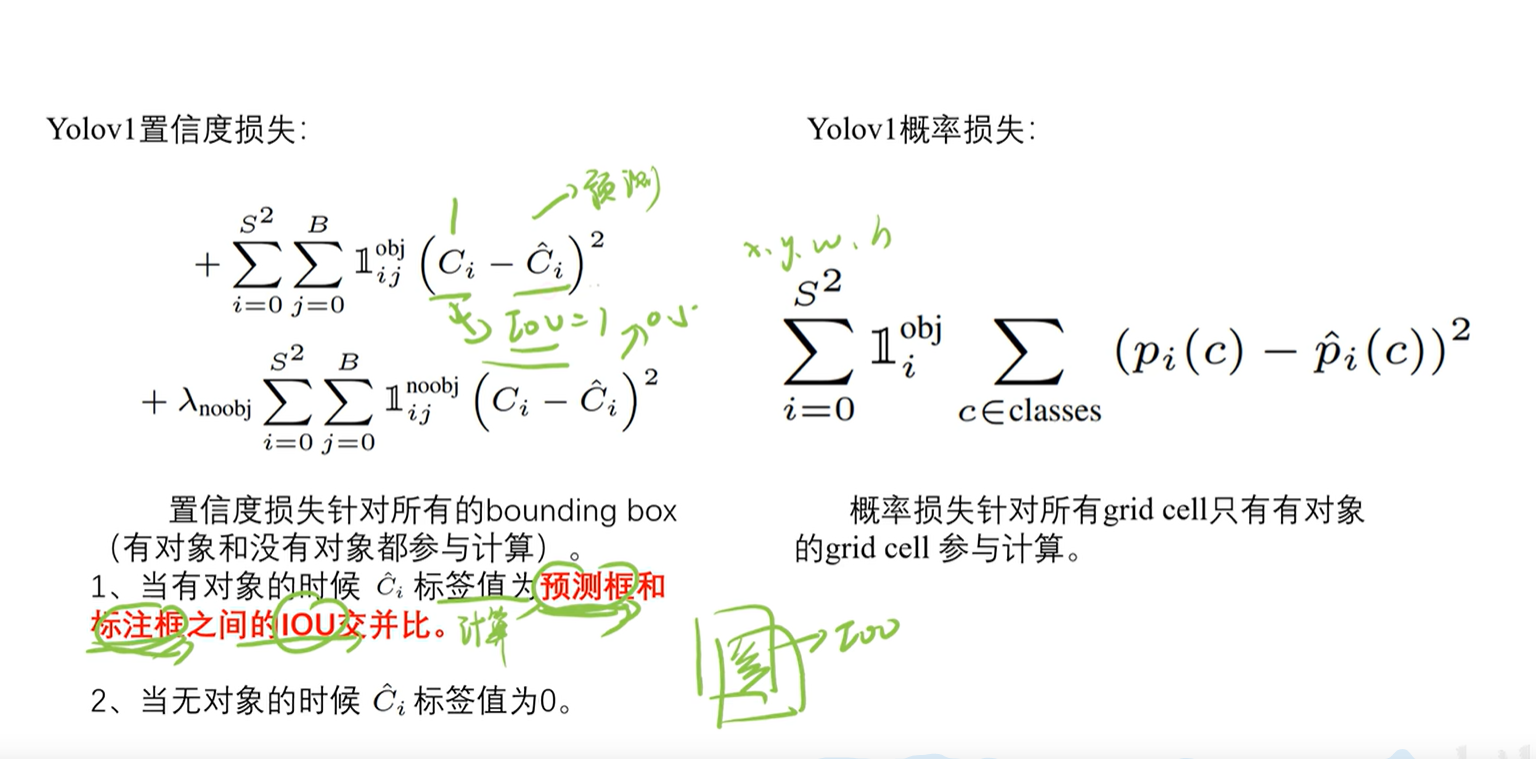
3.2 置信度之IOU

IOU=标注框/预测框
IOU越大预测与标注越接近
置信度

3.3 概率值
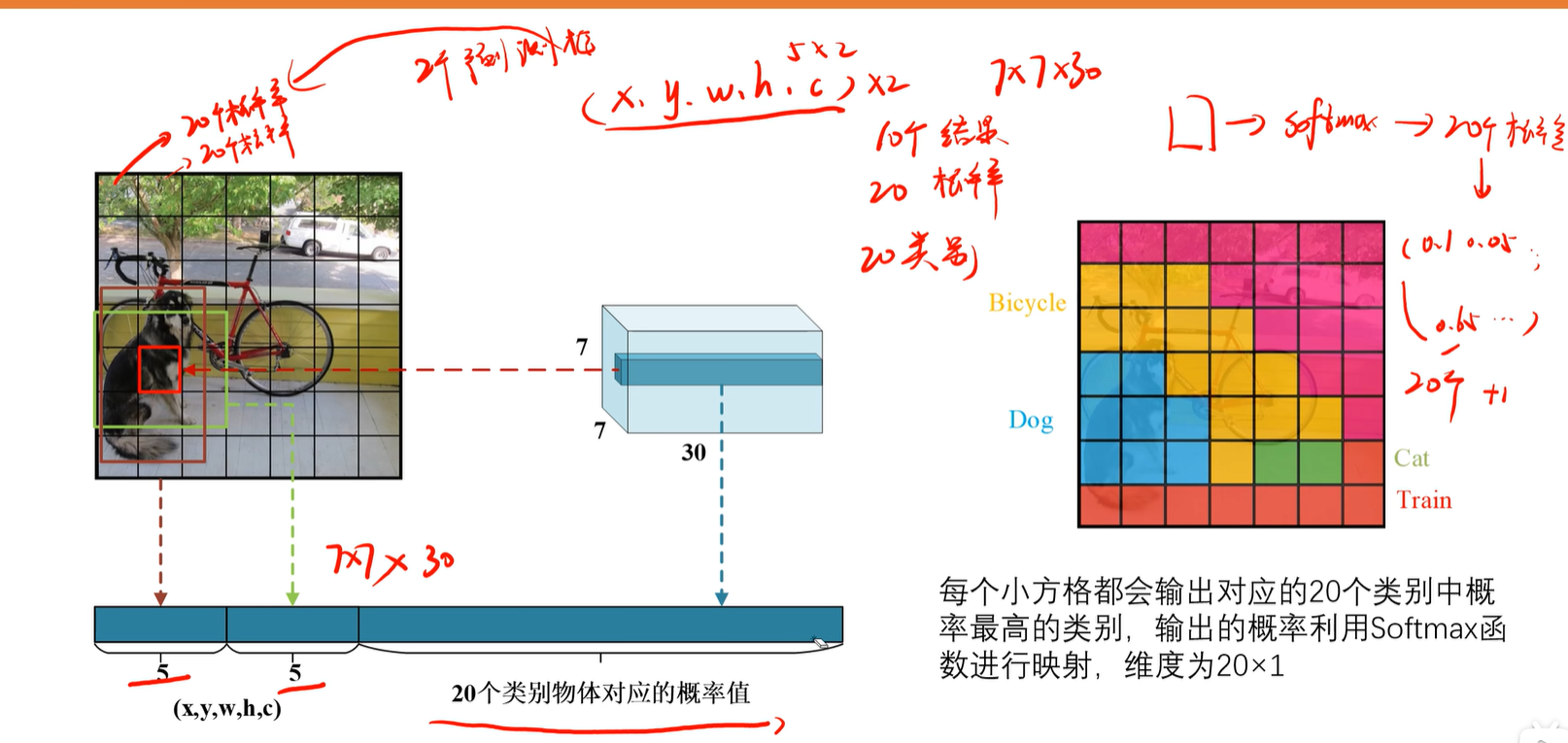
7x7个框,每个框对应20个类别的概率,每个小框有2个候选框,它们共用20个类别的概率
3.4 模型输出结果
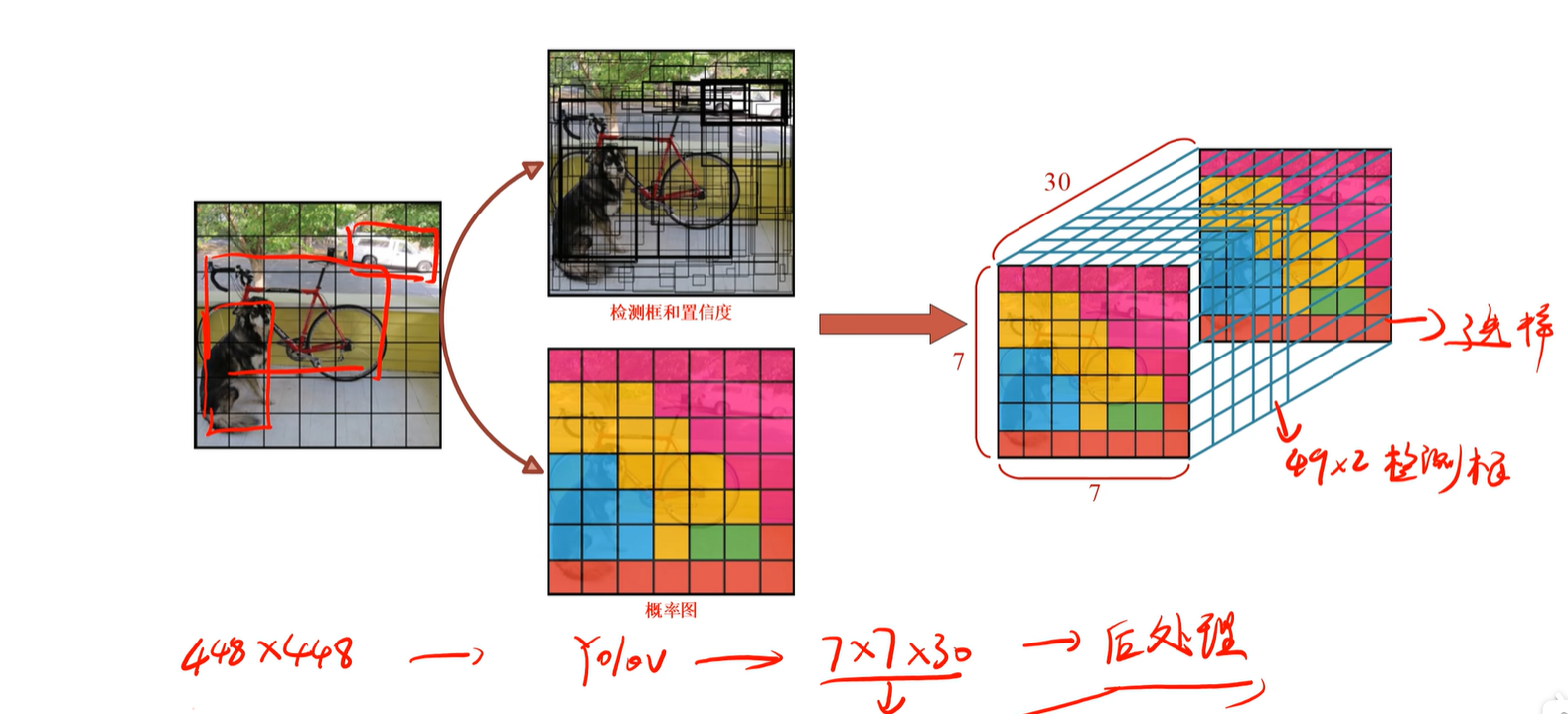
输出49x2个检测框,每个小框有30维向量
3.5 类别置信度

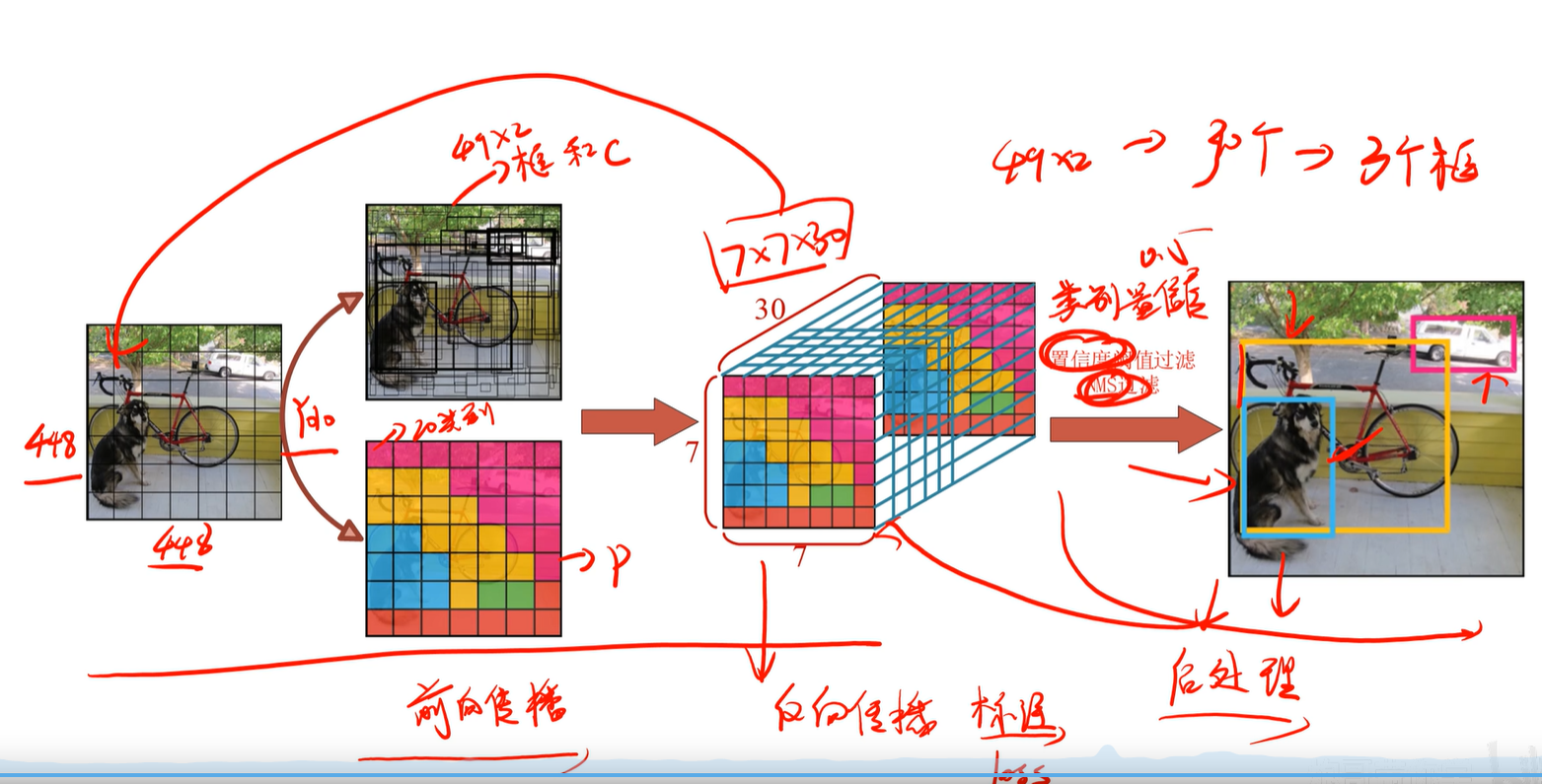
3.6 非极大值抑制(NMS)

3.7 后处理输出结果
4. Yolov1损失函数
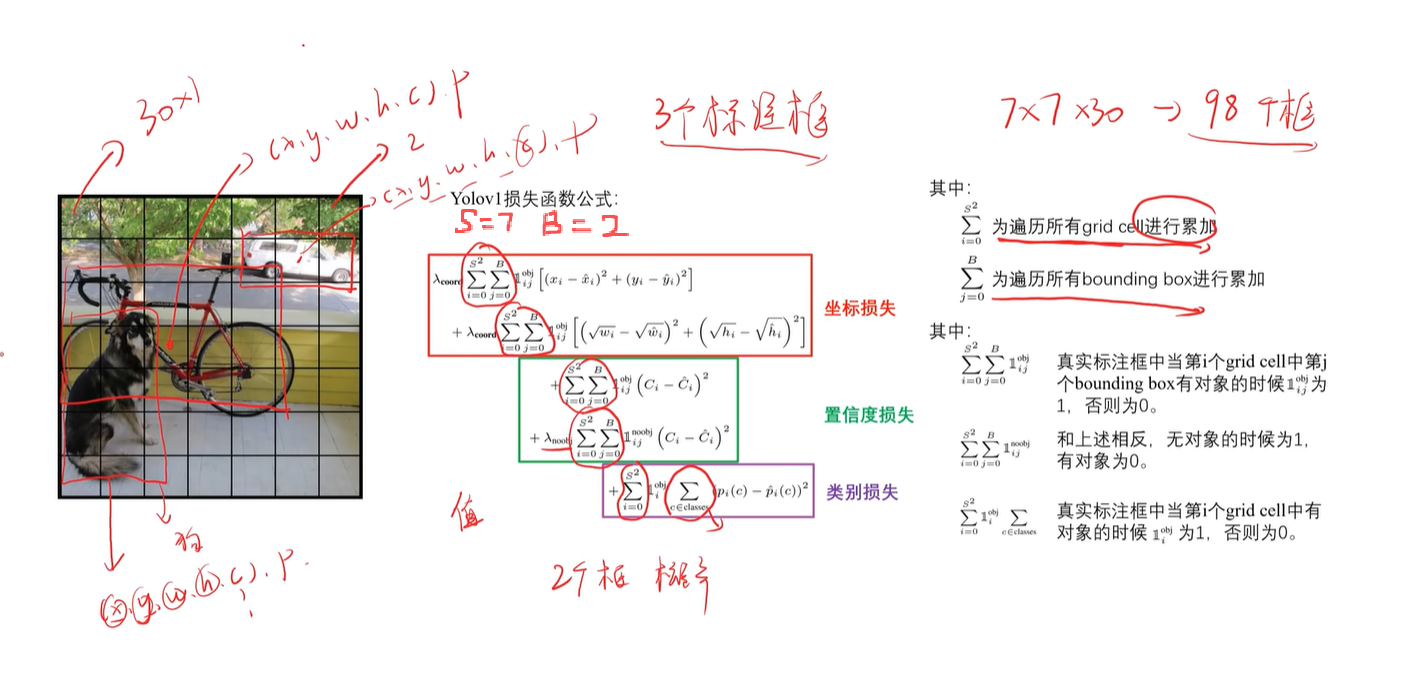
S=7,7x7个小方格
B=2,没个小方格有两个预测框
4.1 坐标损失
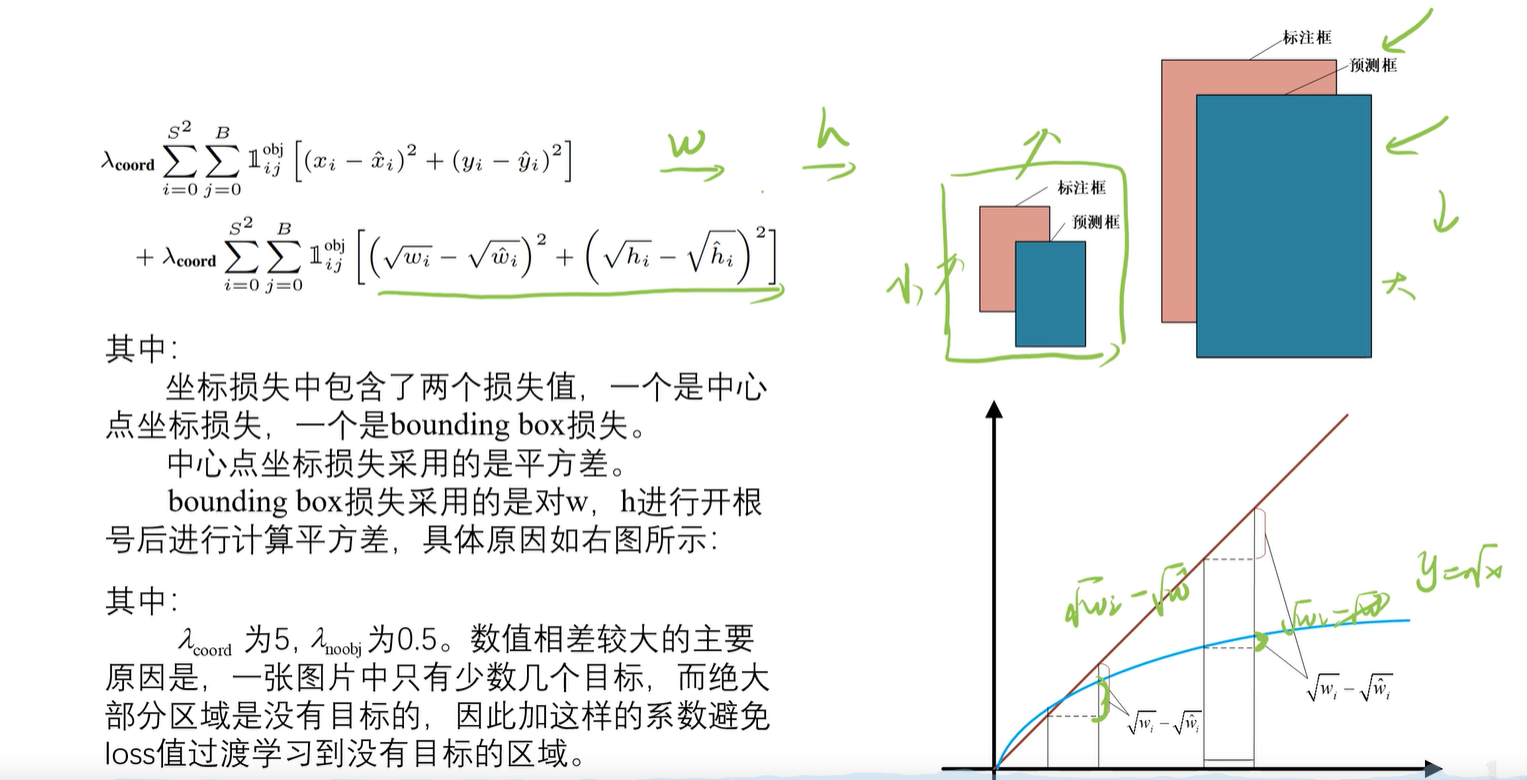
计算wh的时候增加了根号,是由于小物体看起来误差会大一些,大物体会小一些,但是由于小物体的值更小,使得计算出来的误差值比大物体还小,为了解决这样的问题,加上根号再计算,放大小物体的误差,抑制大物体的误差
4.2 置信度损失
5. 训练过程

先训练分类模型再训练检测模型,原因可能是由于当时算力的限制
6. 总结

小物体检测差的原因是,7x7个框,每个框有两个预测框,还共享概率,那么比如小方块中有3个以上小物体,那么一个预测概率只能识别出一个小物体,其他的就漏检了。
检测目标较少的原因是7x7x2=98,2个预测框还公用一个概率因此最多检测出49个目标,当目标多余49个时,就会出现漏检了。