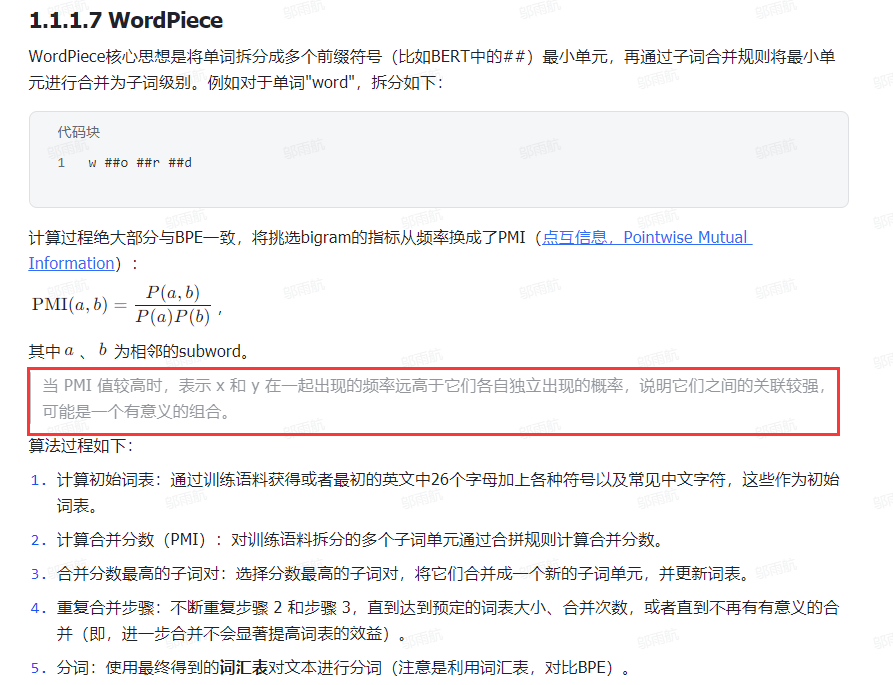
1. 分词的粒度

2. BPE分词
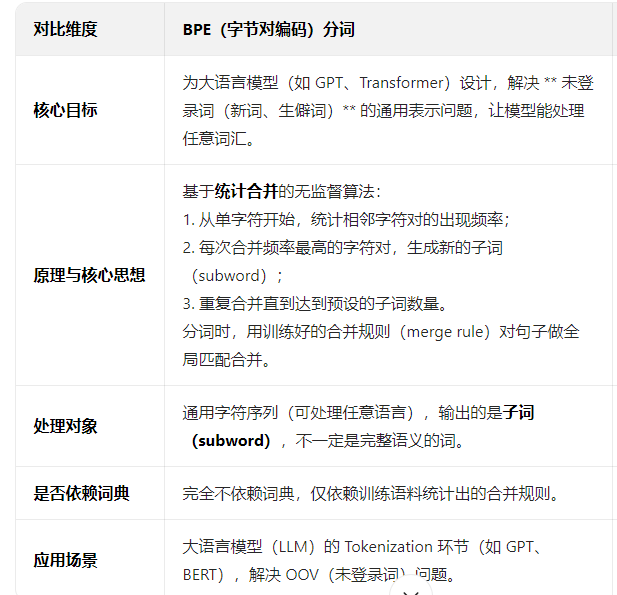
BPE 分词 :会按照训练好的 merge_rule 全局匹配合并,比如先把所有「我 / 是」合并成「我是」,再处理其他规则,最终得到子词序列。
2.1 BPE训练流程:
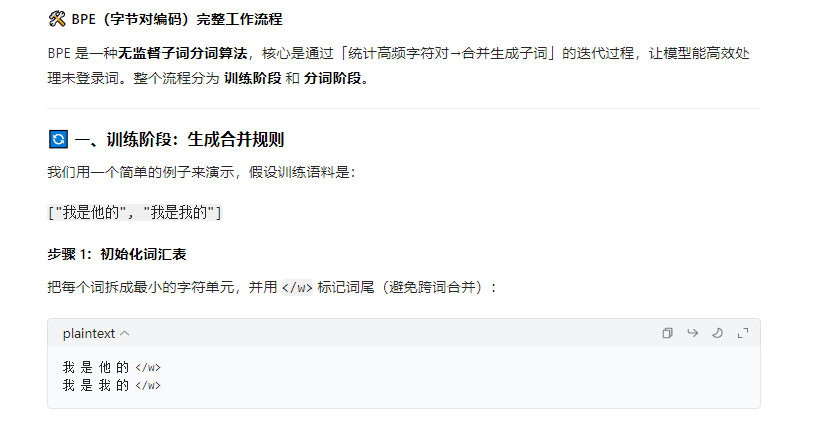
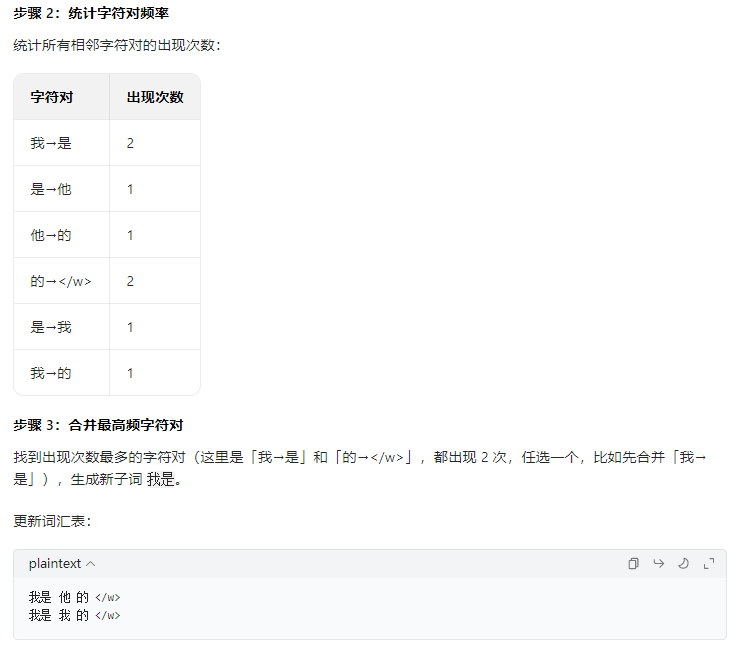
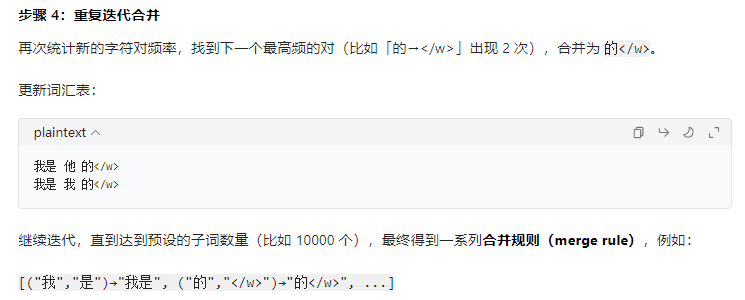
2.2 BPE分词流程
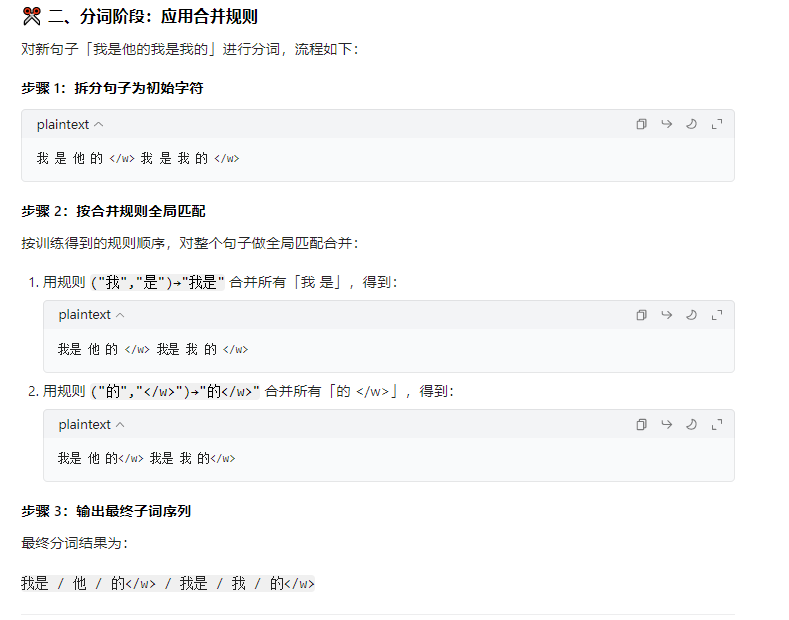

2.3 BPE代码
python
def train_bpe(corpus, target_vocab_size):
"""
训练 BPE(字节对编码)算法,生成合并规则和最终词汇表
:param corpus: 训练语料(列表形式,每个元素是一个单词/短语)
:param target_vocab_size: 目标词汇表大小(包含初始字符+合并后的子词)
:return: vocab(最终词汇表)、merge_rule(合并规则列表)
"""
# ===================== 步骤1:初始化词频字典 =====================
# word_freq: key=切分后的字符串(如 'l o w </w>'), value=出现次数
word_freq = {}
for word in corpus:
# 把每个词拆成单个字符 + 词尾标记</w>(避免跨词合并)
char_list = list(word) + ['</w>']
# 用空格连接字符,作为初始切分形式
word_str = ' '.join(char_list)
# 统计词频(不存在则默认0,再加1)
word_freq[word_str] = word_freq.get(word_str, 0) + 1
# ===================== 步骤2:初始化词汇表 =====================
# 初始词汇表包含所有单个字符 + </w>(自动去重)
vocab = set()
for word_str in word_freq.keys():
vocab.update(word_str.split()) # 拆分字符并加入集合
vocab = list(vocab) # 转成列表方便后续追加
# ===================== 步骤3:初始化合并规则 =====================
merge_rule = [] # 存储合并规则,每个元素是 (原字符对, 新子词),如 (('l','o'), 'lo')
# ===================== 步骤4:迭代合并高频字符对 =====================
while len(vocab) < target_vocab_size:
# 4.1 统计所有相邻字符对(bigram)的频率
bigram_frequency = get_bigram_frequency(word_freq)
# 如果没有可合并的字符对(所有都是单字符),提前终止
if not bigram_frequency:
print("已无可用的字符对可合并,提前终止")
break
# 4.2 找到频率最高的字符对(argmax 逻辑)
best_bigram = max(bigram_frequency, key=bigram_frequency.get)
# 4.3 合并成新子词
new_unigram = ''.join(best_bigram)
# 4.4 更新词频字典:把所有匹配的bigram替换成新子词
word_freq = merge_bigram(best_bigram, new_unigram, word_freq)
# 4.5 记录合并规则(修正原代码的语法错误:-> 换成元组)
merge_rule.append((best_bigram, new_unigram))
# 4.6 把新子词加入词汇表
vocab.append(new_unigram)
return vocab, merge_rule
def get_bigram_frequency(word_freq):
"""
统计所有相邻字符对(bigram)的出现频率
:param word_freq: 词频字典(key=切分后的字符串,value=频率)
:return: bigram_frequency: key=字符对元组,value=频率
"""
bigram_frequency = {}
for word_str, freq in word_freq.items():
# 把字符串拆成列表(如 'l o w </w>' -> ['l','o','w','</w>'])
chars = word_str.split()
# 遍历所有相邻字符对
for i in range(len(chars) - 1):
bigram = (chars[i], chars[i+1])
# 累加频率
bigram_frequency[bigram] = bigram_frequency.get(bigram, 0) + freq
return bigram_frequency
def merge_bigram(best_bigram, new_unigram, word_freq):
"""
把词频字典中所有的 best_bigram 替换成 new_unigram
:param best_bigram: 要合并的字符对(元组),如 ('l','o')
:param new_unigram: 合并后的新子词,如 'lo'
:param word_freq: 原始词频字典
:return: new_word_freq: 更新后的词频字典
"""
new_word_freq = {}
# 把字符对转成空格连接的字符串(如 ('l','o') -> 'l o'),方便替换
bigram_str = ' '.join(best_bigram)
for word_str, freq in word_freq.items():
# 全局替换所有匹配的字符对
new_word_str = word_str.replace(bigram_str, new_unigram)
# 更新新的词频字典
new_word_freq[new_word_str] = new_word_freq.get(new_word_str, 0) + freq
return new_word_freq
# ===================== 测试代码 =====================
if __name__ == "__main__":
# 训练语料(英文示例,也可替换为中文)
train_corpus = ["low", "lower", "newest", "lowest"]
# 目标词汇表大小(初始字符约8个,合并4次后停止)
target_vocab = 12
# 训练BPE
final_vocab, final_merge_rule = train_bpe(train_corpus, target_vocab)
# 打印结果
print("=" * 50)
print("最终词汇表(大小:{}):".format(len(final_vocab)))
print(final_vocab)
print("=" * 50)
print("合并规则(共{}条):".format(len(final_merge_rule)))
for idx, (bigram, new_word) in enumerate(final_merge_rule):
print(f"第{idx+1}条:{bigram} → {new_word}")2.4 BPE的加速


例子:
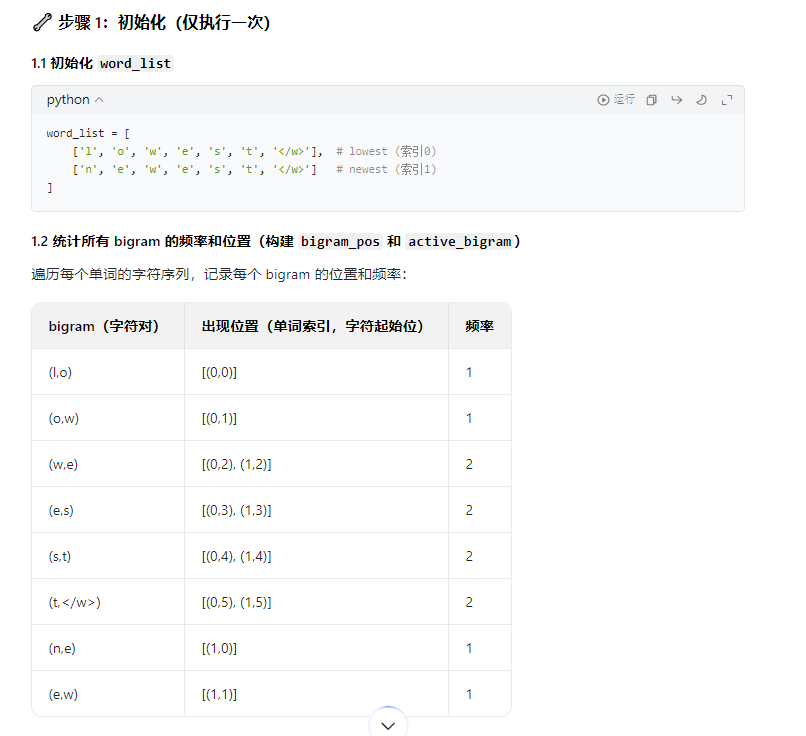
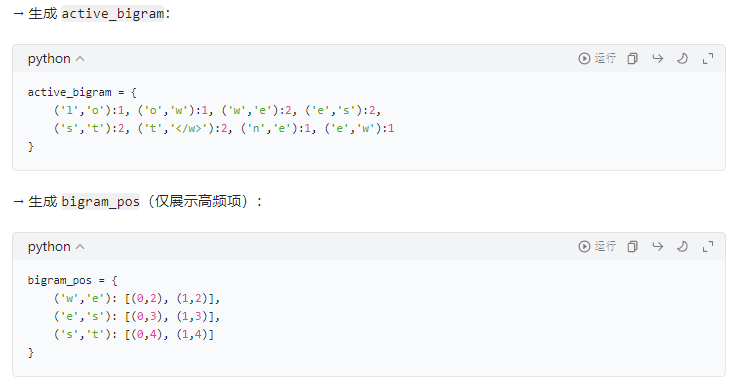
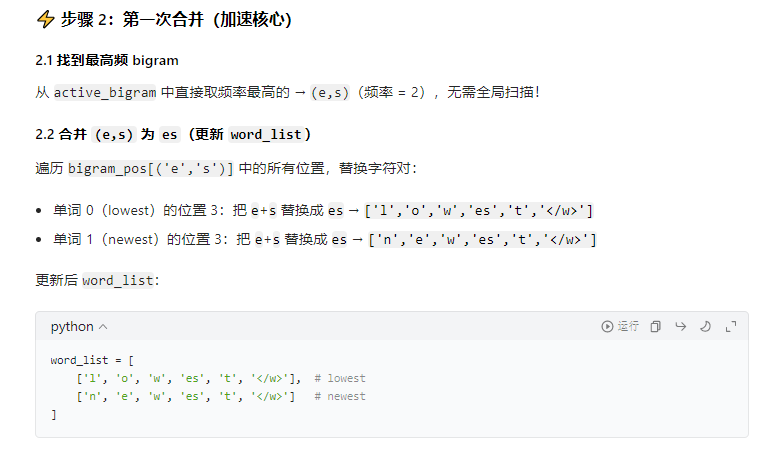
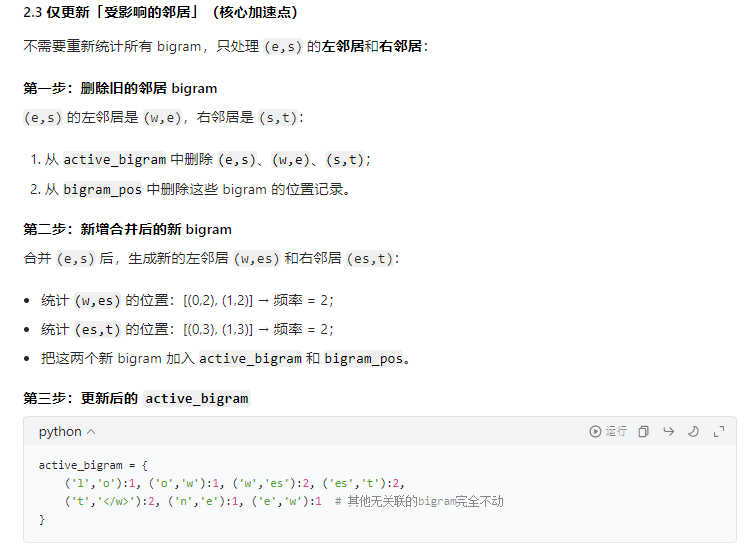
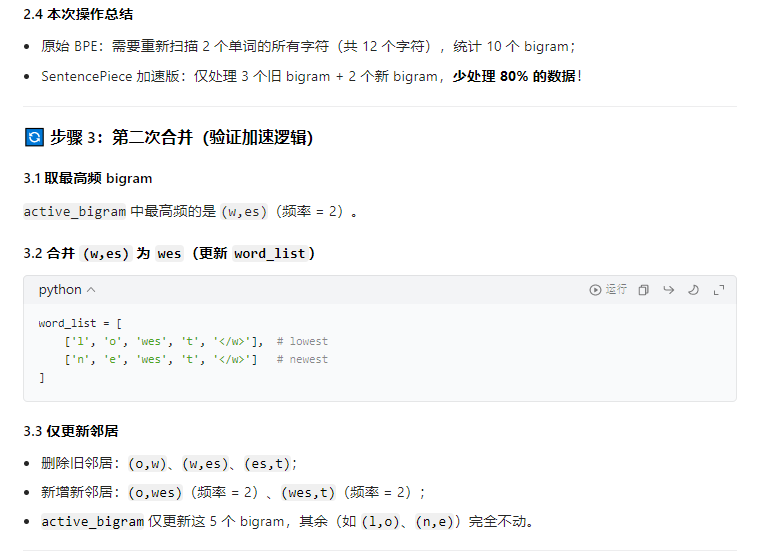
结论:无需遍历与best_gram无关的字符,只需变动与best_gram相关的邻居字符,和增加best_gram即可。
3. jieba 分词



3.1 jieba分词的例子




4. WordPiece 分词