目录
[1.1 误将 SCLK 用作驱动逻辑的全局时钟](#1.1 误将 SCLK 用作驱动逻辑的全局时钟)
[1.2. 缺少跨时钟域约束](#1.2. 缺少跨时钟域约束)
[2.1 两种时序约束方式的差异分析(set_clock_groups 与 set_false_path)](#2.1 两种时序约束方式的差异分析(set_clock_groups 与 set_false_path))
第一种:set_clock_groups (推荐用于时钟域隔离)
[技术层面的原因:RGMII 协议的"坑"](#技术层面的原因:RGMII 协议的“坑”)
[为什么会报 -0.119ns?](#为什么会报 -0.119ns?)
[方法二:整 IDELAY(最根本的硬件修复)](#方法二:整 IDELAY(最根本的硬件修复))
[方法三:添加 Input Delay 约束(核心修复手段)](#方法三:添加 Input Delay 约束(核心修复手段))
[1. 计算你需要调整的数值量](#1. 计算你需要调整的数值量)
[2. 应该设置多少? (数学计算)](#2. 应该设置多少? (数学计算))
[3. 原理解释 (为什么要增大?)](#3. 原理解释 (为什么要增大?))
[4. 极其重要的警告 (Trade-off)](#4. 极其重要的警告 (Trade-off))
[核心解释:Hold 检查是在"Fast Corner"进行的](#核心解释:Hold 检查是在“Fast Corner”进行的)
前言
本文以实际工程为例,记录了FPGA设计中因跨时钟域(CDC)处理不当引发的时序违例及其解决方案。同时,针对异步时序路径,详细对比并解析了 set_clock_groups 与 set_false_path 两种主流约束方法的原理与适用场景。
1.问题
原始代码:

由于SCLK输出的out_available和data信号直接跨时钟域使用,虽然进行了异步处理(打拍),但未施加时序约束,这会导致诸多时序问题,具体表现如下:
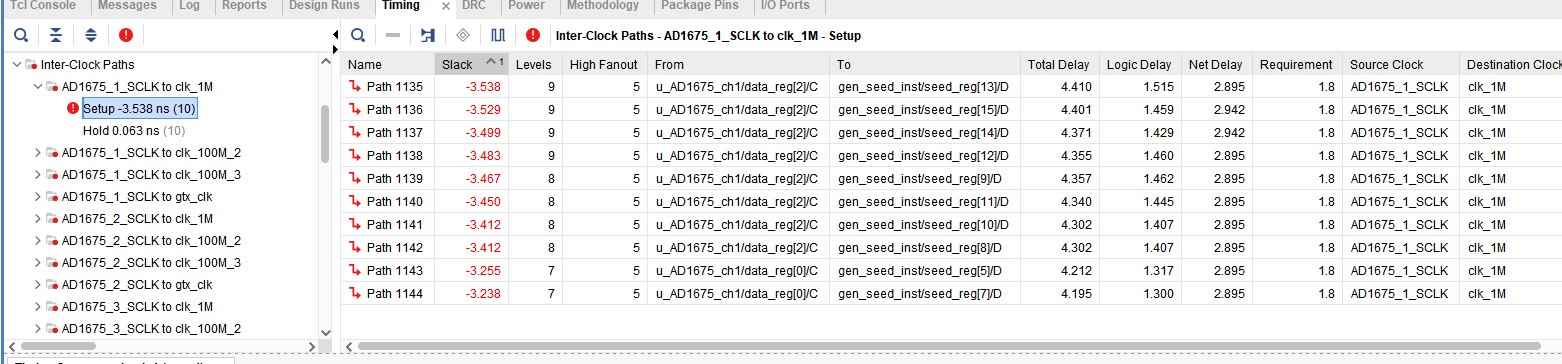
这张 Vivado 时序报告截图显示的是典型的跨时钟域(CDC)路径违例。
原因分析与解决:
1.1 误将 SCLK 用作驱动逻辑的全局时钟
SCLK是 ADC 接口的外部输入信号,与 FPGA 内部的系统时钟(Local Clock)在频率和相位上均是异步 的。如果直接使用 SCLK 驱动寄存器,并将其输出数据传递给内部时钟域,必然会导致严重的建立时间违例和亚稳态风险。
解决方案: 摒弃"将 SCLK 作为时钟使用"的做法,转而将其视为普通数据信号 。建议在系统主时钟域下,对 SCLK 信号进行边沿检测。通过这种方式,可以将所有逻辑操作统一在单一的同步时钟域内,从而彻底消除异步时序问题。优化后的代码实现如下:

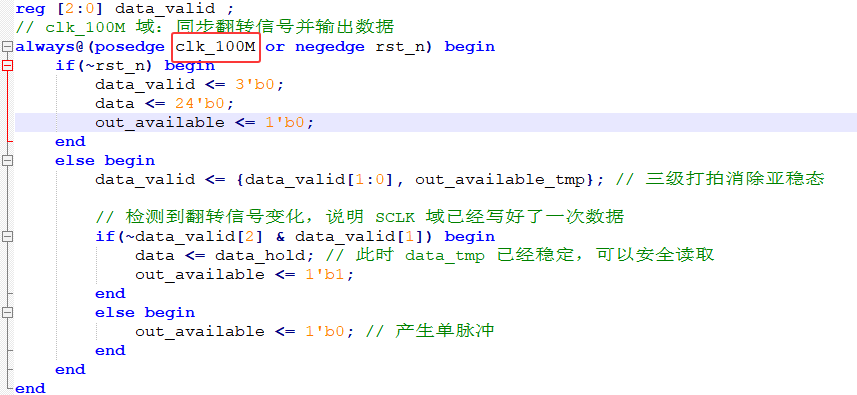
引入data_valid信号。由于data_hold 在data_valid变化前已经稳定,且同步过程需要 3 个clk_100M周期(约 30ns),这为跨时钟域传输提供了巨大的时序余裕。
1.2. 缺少跨时钟域约束
Vivado 默认会尝试对设计中所有时钟之间的路径进行时序分析。如果 AD1675_1_SCLK 和 clk_1M 是异步的(没有确定的相位关系),Vivado 会寻找两个时钟边沿最接近的一刻(即你看到的 1.8 ns)作为约束标准。
-
后果: 实际上这种"极窄窗口"是随机出现的,单纯靠布局布线根本无法满足。
-
解决方法:
-
添加跨时钟约束: 如果在代码中已经处理了同步(例如使用了两级寄存器打拍、异步 FIFO 或 Xilinx 的 XPM_CDC 模块),只需要告诉 Vivado 忽略这条路径的分析。
-
XDC 约束命令示例:
-
第一种 异步时钟组约束 (Clock Groups) 它告诉 Vivado:
SCLK域和系统时钟域(clk_1M)之间是完全异步的,不要进行跨时钟域的建立/保持时间检查。# 如果这两个时钟完全异步 set_clock_groups -asynchronous -group [get_clocks AD1675_1_SCLK] -group [get_clocks clk_1M] -
第二种伪路径约束:
set_false_path -from [get_clocks AD1675_1_SCLK] -to [get_clocks clk_1M]
-
-
亲测第一条是有用的:

加入约束之后时序就不报错了。

2.拓展
2.1 两种时序约束方式的差异分析(set_clock_groups 与 set_false_path)
这两种约束(set_clock_groups 和 set_false_path)在目的 上是一样的:都是告诉 Vivado "忽略这两部分逻辑之间的时序路径,不要分析也不要报错"。他们的区别如下:
| 特性 | Clock Groups (set_clock_groups) | False Path (set_false_path) |
|---|---|---|
| 形象比喻 | "全面断交"(核武器) | "精准屏蔽"(手术刀) |
| 方向性 | 双向 (Bidirectional) 自动忽略 A→B 和 B→A。 | 单向 (Unidirectional) 默认只忽略 -from 到 -to 的路径。 |
| 作用范围 | 全局性 在这两个时钟域下的所有寄存器路径全部忽略。 | 灵活性高 可以针对时钟,也可以具体到某个引脚 (Pin) 或单元 (Cell)。 |
| 优先级 | 最高 一旦设置,该时钟域之间即使有 set_max_delay 也会被覆盖。 |
较低 如果与 clock_groups 冲突,会被前者覆盖。 |
| 分析效率 | 高 Vivado 在分析初期就会直接剔除这些路径,节省编译时间。 | 中 工具需要遍历路径表,找到匹配的路径再剔除。 |
单向的理解:
# 单向忽略:只忽略从 SCLK 发往 clk_1M 的路径
set_false_path -from [get_clocks AD1675_1_SCLK] -to [get_clocks clk_1M]
# 如果需要双向忽略,必须写两行
set_false_path -from [get_clocks clk_1M] -to [get_clocks AD1675_1_SCLK]适用范围:
第一种:
set_clock_groups(推荐用于时钟域隔离)
含义: 它定义的是时钟与时钟之间的关系。
应用场景: 当你有两个完全独立的晶振(例如 FPGA 上的 50MHz 晶振和 ADC 进来的 SCLK),它们物理上没有任何相位关系。
优点:
省事: 一行代码搞定双向。
彻底: 保证两个时钟域之间没有任何一条漏网之鱼。
编译快: 对时序分析器最友好,直接把这两个域的图切开,不再计算。
缺点: 杀伤力太大。如果你其实希望检测其中某一条路径(比如用了 FIFO),它也会把 FIFO 的约束给抹掉(除非你非常小心)。
第二种:
set_false_path(推荐用于特殊信号)
含义: 它定义的是路径与路径之间的关系。
应用场景:
部分逻辑忽略: 比如大部分路径需要分析,但只有一条"复位信号"或者"静态配置信号"不需要分析。
单向忽略: 你只关心 A 发给 B 的数据,不关心 B 发回 A 的。
具体引脚: 比如
set_false_path -from [get_ports reset_n]。优点: 粒度细,指哪打哪。
缺点: 写起来麻烦。如果是两个时钟域完全异步,用这个命令你需要写两条(A->B 和 B->A),容易漏写。
2.2时序约束的重要性
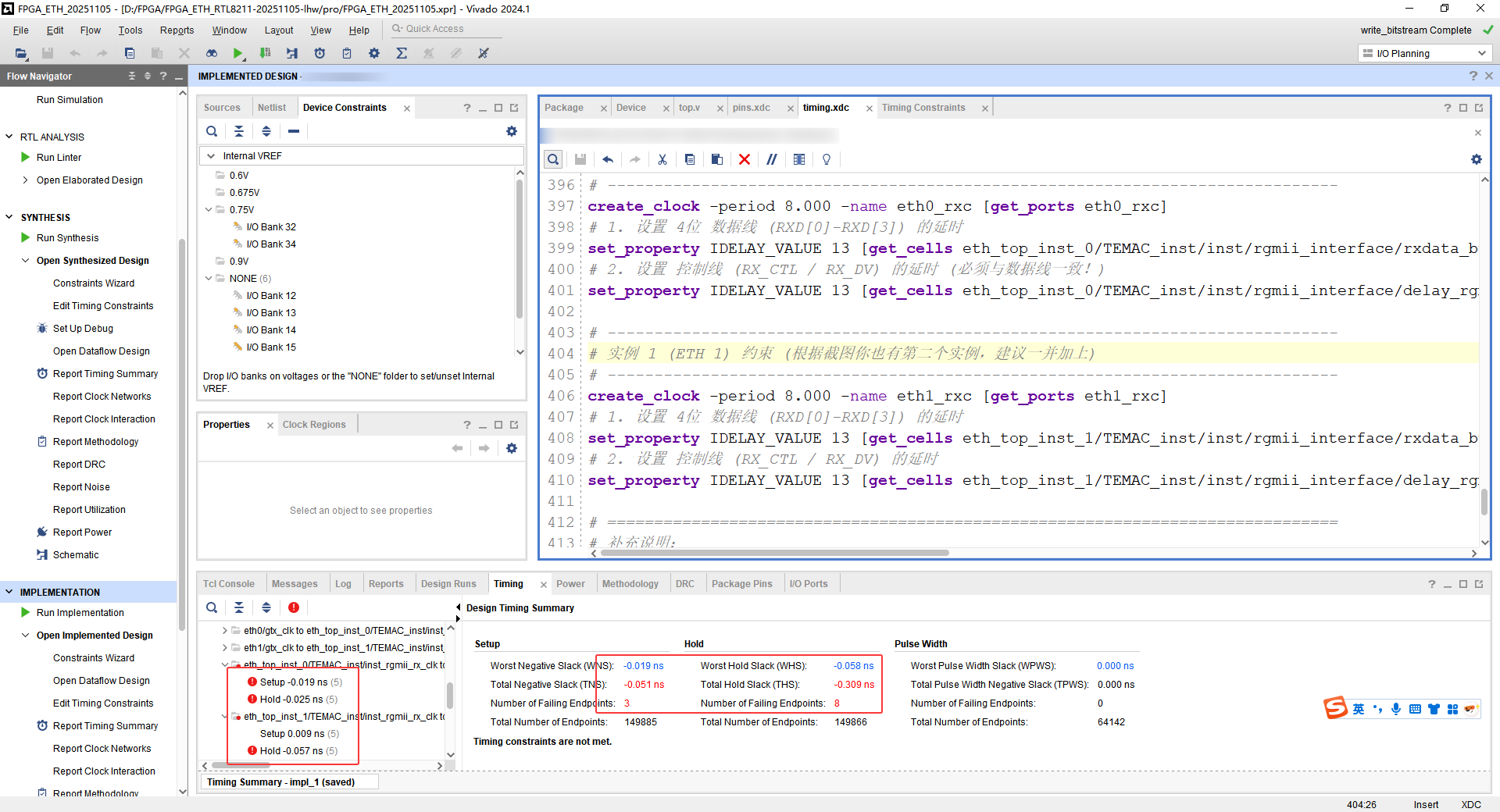
在普通数据传输场景中,时序约束的重要性相对较低,但在高速数据传输时却至关重要。以千兆以太网传输为例,若时序约束处理不当,就会导致数据传输异常。具体例子如下图所示:
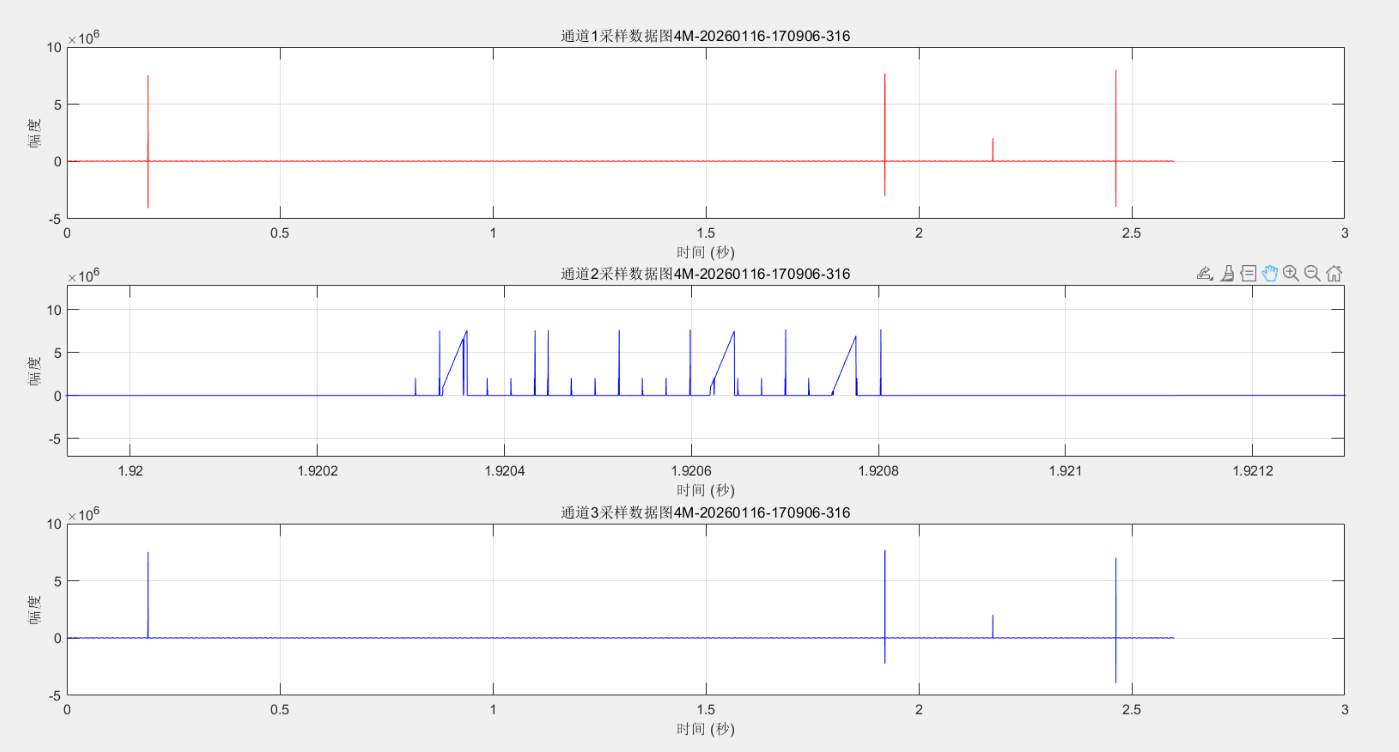
固定数据传播,但是会出现异常点,放大看就是通道2的情况。具体的时序问题:

问题解析:
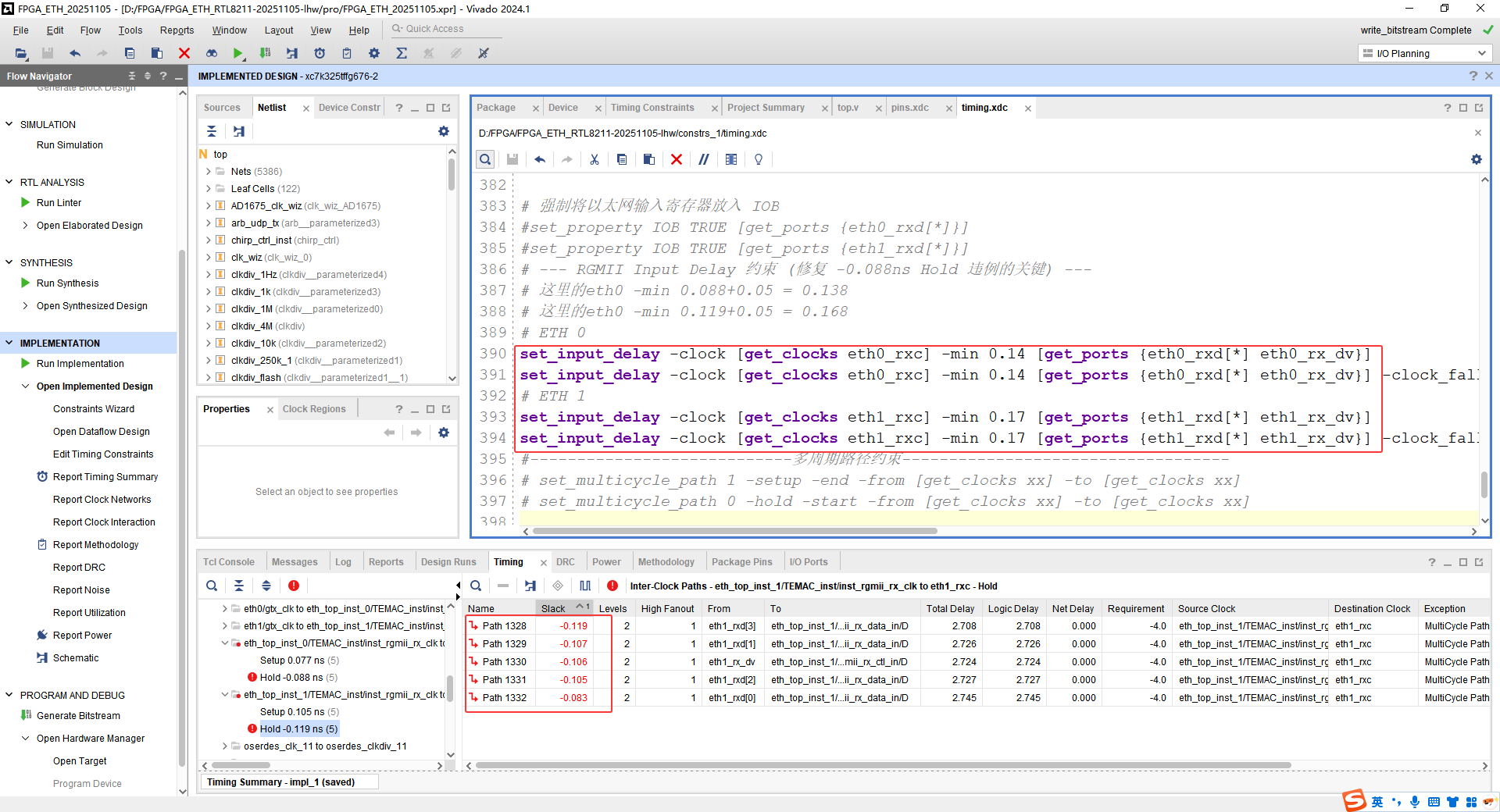
RGMII 接口保持时间违例 -0.119ns,这个错误的根本原因可以总结为一句话:
"数据跑得太快了,在时钟'关门'之前就溜走了。"
以下是通俗易懂的详细解释:
形象理解:拍照的快门
想象一下 FPGA 的输入寄存器在拍照(采集数据):
时钟沿(Clock Edge):按下快门的瞬间。
数据(Data):正在通过镜头的赛车。
建立时间(Setup Time) :赛车必须在快门按下前就进入镜头,摆好姿势。
保持时间(Hold Time) :快门按下后 ,赛车必须在镜头里多停留一小会儿(比如 0.5秒),直到底片曝光完成。
您现在的错误(Hold Violation -0.119ns)是:
快门刚按下(时钟沿刚到),曝光还没完成,赛车就已经跑出镜头了(数据发生了变化)。
具体来说,数据比要求的时间早了 0.119ns 发生了变化,导致 FPGA 拍到了一张模糊的照片(亚稳态)或者下一辆车的照片(采错数据)。
技术层面的原因:RGMII 协议的"坑"
为什么会出现这种情况?这通常与 RGMII 协议的特殊性 有关。
发送端(PHY 芯片)的行为:
PHY 芯片发出的时钟(RXC)和数据(RXD)通常是 "边沿对齐" (Edge Aligned) 的。也就是说,时钟跳变的同时,数据也跟着跳变。
接收端(FPGA)的需求:
FPGA 想要稳定地采集数据,它希望时钟沿打在数据的 "正中间" (Center Aligned)。
矛盾点:
如果 PCB 走线也是等长的,那么时钟和数据同时到达 FPGA 管脚。
时钟:刚到。
数据:刚开始变。
结果 :时钟沿正好撞上了数据变化的边缘,保持时间自然就不够了(甚至建立时间也可能出问题,但在 RGMII 里通常先报 Hold 错)。
为什么会报 -0.119ns?
这说明在 FPGA 内部:
具体原因通常是以下三个之一:
FPGA 内部延迟没加够(最常见):
您使用了 IDELAY(输入延迟单元)来把数据"拖住",让它晚点到。但是延迟加得不够大。比如您只加了 0ns 或者 0.5ns,但实际上需要加 1.5ns ~ 2.0ns 才能让时钟正好对准数据中央。
约束写得太严:
您在 XDC 里写 set_input_delay -min 时,告诉 Vivado 外部数据来得"非常早"。Vivado 一算:"完了,数据来这么早,肯定保持不住",于是报错。实际上外部 PHY 可能已经开启了 2ns 的延迟(Internal Delay),数据来得并不早,只是您没告诉 Vivado。
时钟走线太长:
虽然罕见,但如果 FPGA 内部时钟走线绕了远路(延迟大),而数据走线很短(延迟小),数据就会比时钟先到寄存器,导致保持时间不足。
总结
这个错误的物理本质是 数据相对于时钟"抢跑"了。
解决办法的核心逻辑就是:
物理上 :用
IDELAY把数据"拽住",让它晚点进寄存器。逻辑上 :用
set_input_delay告诉 Vivado,"放心,数据其实来得挺晚的",消除误报。


解决方法:
方法一:调整布线策略
将 Strategy (策略)从默认的
Vivado Implementation Defaults改为:Performance_Explore:让工具多花点时间探索更好的时序。原理: 工具会尝试把数据线的路由故意绕远一点(增加 Data Delay),从而满足保持时间。
方法二:整
IDELAY(最根本的硬件修复)如果你的以太网接收模块(如
gmii_to_rgmiiIP 核)里实例化了IDELAY原语:
操作: 找到代码中实例化
IDELAYE2/IDELAYE3的地方,增加IDELAY_VALUE(或TAP值)。计算: 每一个 Tap 大约是 78ps (UltraScale) 或 52ps (7 Series)。既然你缺 0.119ns,大概增加 2~3 个 Tap 就可以修复。这个时间是基于 Xilinx FPGA IDELAY(输入延迟单元)的硬件原理 和 参考时钟频率 推导出来的。核心公式非常简单:
其中,
是你提供给
IDELAYCTRL模块的参考时钟频率(通常是 200MHz 或 300MHz)。参考时钟为 200 MHz(最常见)这是绝大多数以太网 RGMII 设计的标准配置。
参考时钟频率 (
参考时钟周期 (
32个Tap的总延迟:
1个Tap的延迟:
方法三:添加 Input Delay 约束(核心修复手段)
您的文件中完全缺失
set_input_delay。没有这个约束,Vivado 默认认为数据和时钟是完美对齐的(0ns 延迟),这在 RGMII 接口上几乎 100% 会导致 Hold 违例。这是一个非常关键的问题。调整
set_input_delay实际上是在告诉 Vivado 外部数据进来的"时间窗口"。要解决这个 -0.119ns 的 Hold 违例,你需要增大 (Make Larger/More Positive)
set_input_delay -min的数值。以下是具体的计算方法和步骤:
1. 计算你需要调整的数值量
你需要填补目前的负 Slack,并留出一点安全余量(Margin)。
当前违例 (Negative Slack):
-0.119 ns安全余量 (Recommended Margin):
+0.050 ns(通常留 50ps 左右以防万一)需要补偿的总量 (Delta):
0.119 + 0.050 = 0.169 ns(约 0.14 ns)2. 应该设置多少? (数学计算)
你需要在这个约束原本的数值基础上,加上 0.17 ns。
公式:
举例说明:
假设你现在的
.xdc文件中是这样写的(假设原值是 0.5):
set_input_delay -clock [get_clocks eth_rx_clk] -min 0.5 [get_ports {eth0_rxd[*]}]
计算: 0.5 + 0.17 = 0.67
修改后: 将
0.5改为0.67。假设你现在的
.xdc值是负数(例如 -0.5):
set_input_delay -clock [get_clocks eth_rx_clk] -min -0.5 [get_ports {eth0_rxd[*]}]
计算: -0.5 + 0.17 = -0.33
修改后: 将
-0.5改为-0.33。3. 原理解释 (为什么要增大?)
很多初学者容易在这里搞反方向,请看这个简化的 Hold 计算公式:
其中 数据到达时间 (Data Arrival) =
Clock Edge+Input Delay (min)+PCB/FPGA内部走线延时。现在你的 Slack 是负的,说明 数据到达时间太小了(数据来得太早,或者说数据相对于时钟这就显得"太快"结束了)。
为了让 Slack 变正,你必须让 数据到达时间变大。
因此,你需要增大
Input Delay (min)的值。4. 极其重要的警告 (Trade-off)
当你修改了这个约束后,你必须立刻做两件事:
重新运行 Implementation:看看 Hold 违例是否消失。
检查 Setup Time (建立时间):
Timing 就像一张跷跷板。当你增大
-min(修复 Hold) 时,通常意味着数据窗口整体向后移了,或者你认为数据来得晚了。这可能会导致 Setup Slack 变差。
下一步操作: 修改完并跑完后,去检查
Setup报告。如果 Setup 还是正的 (Positive),那么恭喜你,问题解决了。如果 Setup 变红了,说明单纯改约束救不了,必须使用 IDELAY (方法二) 来在硬件上真正地推迟数据,而不是仅仅在纸面上改数字。如果添加约束后仍有微小的 Hold 违例,且板上实测不丢包,可能是约束写得太紧了。
操作: 检查
-min的值。调整: 稍微增大
-min值(例如从 1.2 改为 1.4)。逻辑: 增大
-min等于告诉 Vivado "外部数据来得更晚,保持时间是足够的"。这可以消除虚假报错,但需谨慎使用。这有点像"掩耳盗铃",除非你确定硬件没问题,否则不推荐。

方法一运行结果:
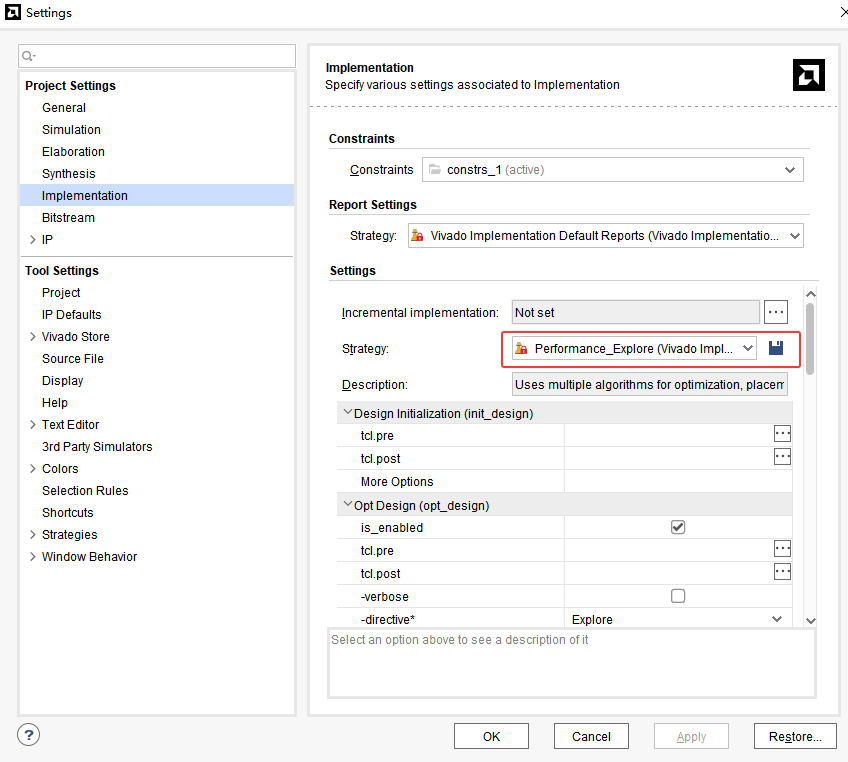
优化布线方案后重新进行综合与实现,生成新的比特流文件。再次测试时异常现象消失,这充分验证了时序约束在FPGA设计中的重要性。
但实际时序还有报错,可以说基本没变,但是异常就是消失了,有点神奇:

From:
eth0_rx_dv/eth0_rxd(这些是顶层的输入端口或与 I/O 相关的信号)。To:
.../rgmii_rx_ctl_in/D(这是 RGMII 接口内部的寄存器)。Logic Delay: 2.706 ns。
Net Delay: 0.000 ns (意味着没有布线延迟,没有Input Delay 约束)。
Levels: 2 (逻辑级数很低,说明路径很短)。
Cross-Clock: 这是一个跨时钟域路径(Inter-Clock Paths),或者是 I/O 接口的时序路径。
方法三运行结果:没有消除这个错误。
而且这个方法并没有起到作用,很奇怪。
lhw:原因被IP核覆盖了,文章后面有具体的解释。
方法二运行结果:
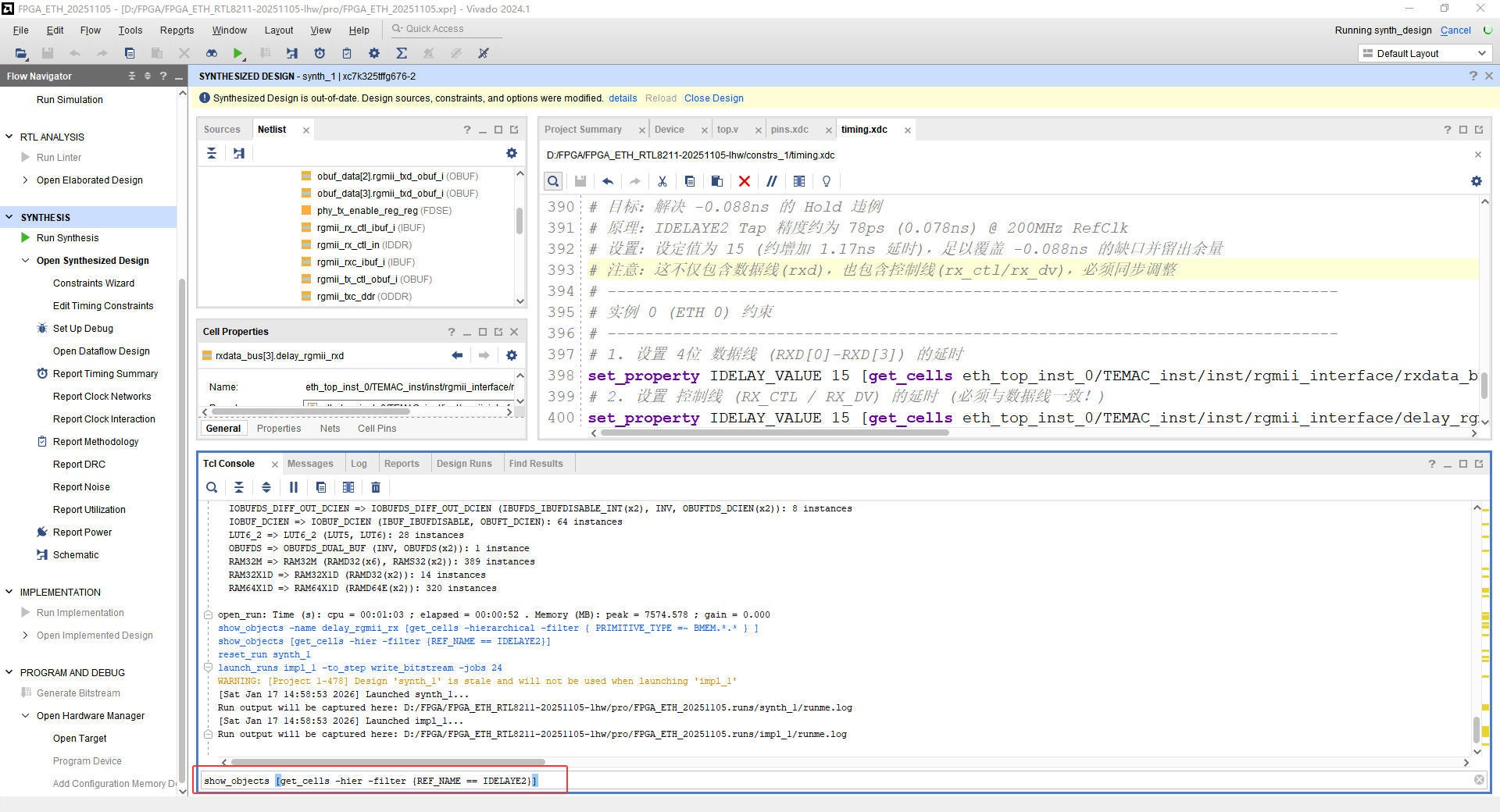
(1)查找IDELAYE2单元名称
命令行方法查找:
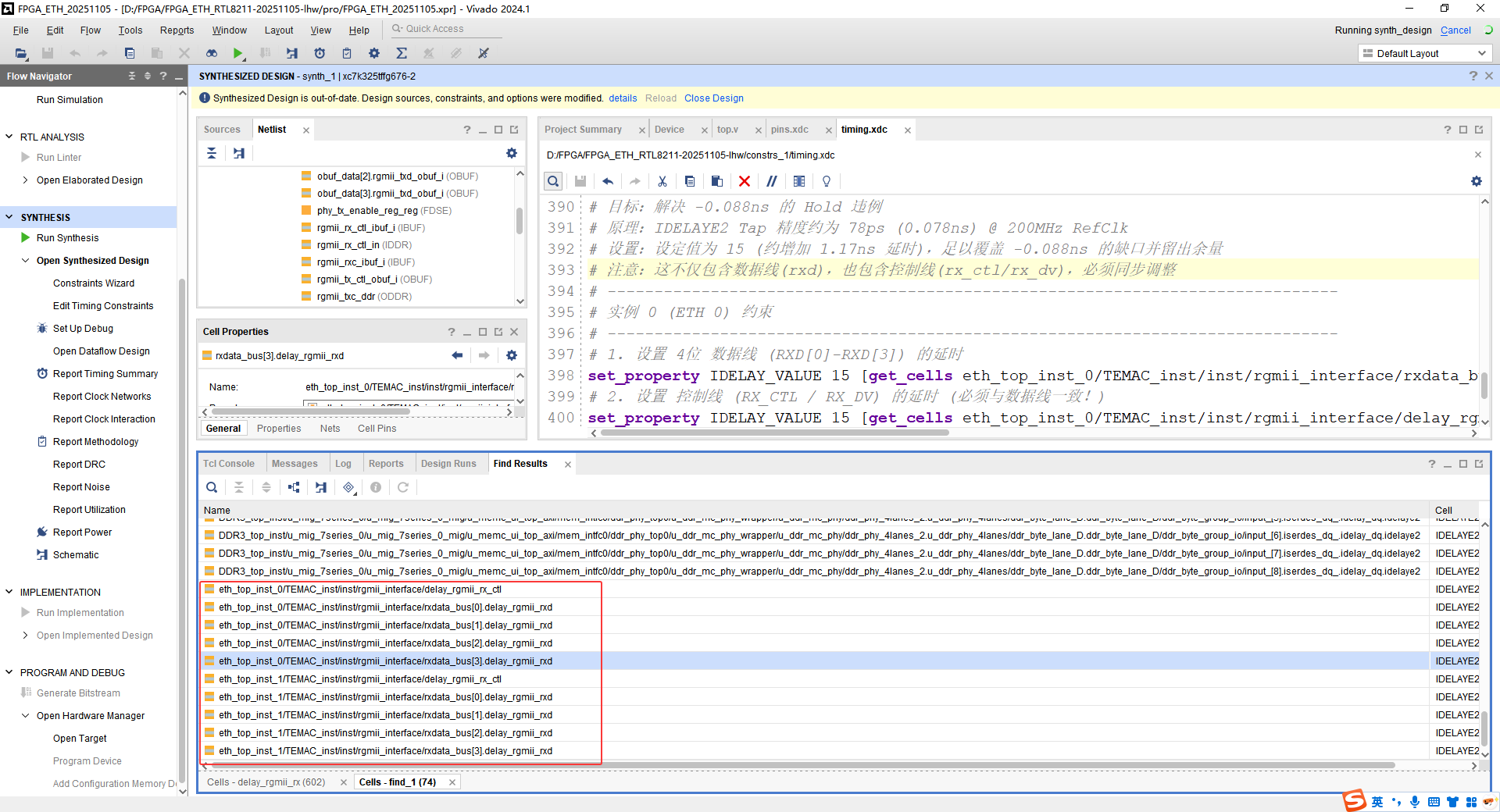
show_objects get_cells -hier -filter {REF_NAME == IDELAYE2}
查找结果如下:
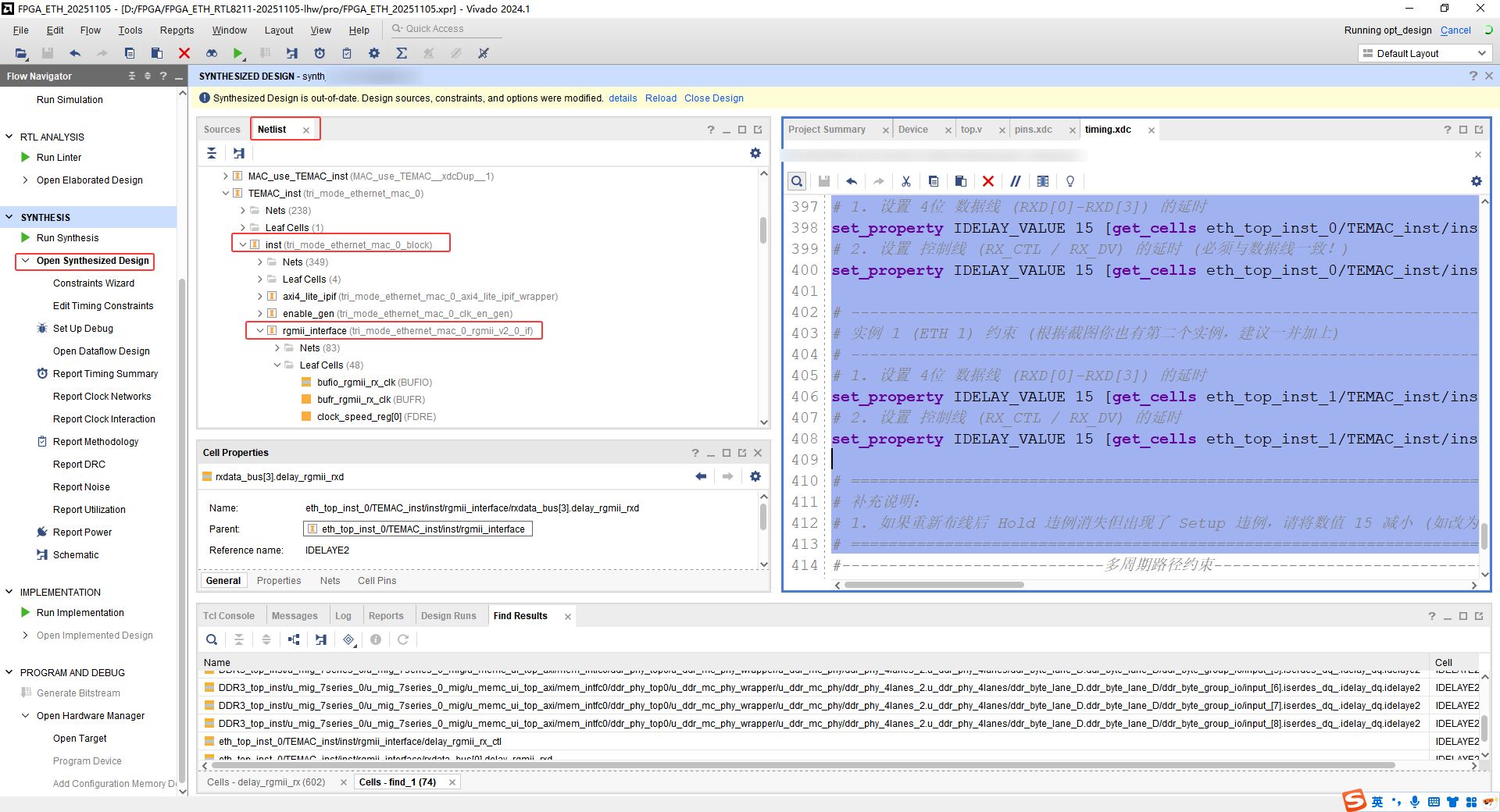
界面查找:
点击属性,就能看到对应的名字了。如下:
(2)添加约束
# ============================================================================== # RGMII IDELAY 静态延时修复 (Fix Hold Violation) # ============================================================================== # 目标:解决 -0.088ns 的 Hold 违例 # 原理:IDELAYE2 Tap 精度约为 78ps (0.078ns) @ 200MHz RefClk # 设置:设定值为 15 (约增加 1.17ns 延时),足以覆盖 -0.088ns 的缺口并留出余量 # 注意:这不仅包含数据线(rxd),也包含控制线(rx_ctl/rx_dv),必须同步调整 # ------------------------------------------------------------------------------ # 实例 0 (ETH 0) 约束 # ------------------------------------------------------------------------------ # 1. 设置 4位 数据线 (RXD[0]-RXD[3]) 的延时 set_property IDELAY_VALUE 15 [get_cells eth_top_inst_0/TEMAC_inst/inst/rgmii_interface/rxdata_bus[*].delay_rgmii_rxd] # 2. 设置 控制线 (RX_CTL / RX_DV) 的延时 (必须与数据线一致!) set_property IDELAY_VALUE 15 [get_cells eth_top_inst_0/TEMAC_inst/inst/rgmii_interface/delay_rgmii_rx_ctl] # ------------------------------------------------------------------------------ # 实例 1 (ETH 1) 约束 (根据截图你也有第二个实例,建议一并加上) # ------------------------------------------------------------------------------ # 1. 设置 4位 数据线 (RXD[0]-RXD[3]) 的延时 set_property IDELAY_VALUE 15 [get_cells eth_top_inst_1/TEMAC_inst/inst/rgmii_interface/rxdata_bus[*].delay_rgmii_rxd] # 2. 设置 控制线 (RX_CTL / RX_DV) 的延时 set_property IDELAY_VALUE 15 [get_cells eth_top_inst_1/TEMAC_inst/inst/rgmii_interface/delay_rgmii_rx_ctl] # ============================================================================== # 补充说明: # 1. 如果重新布线后 Hold 违例消失但出现了 Setup 违例,请将数值 15 减小 (如改为 8 或 10)。 # ==============================================================================
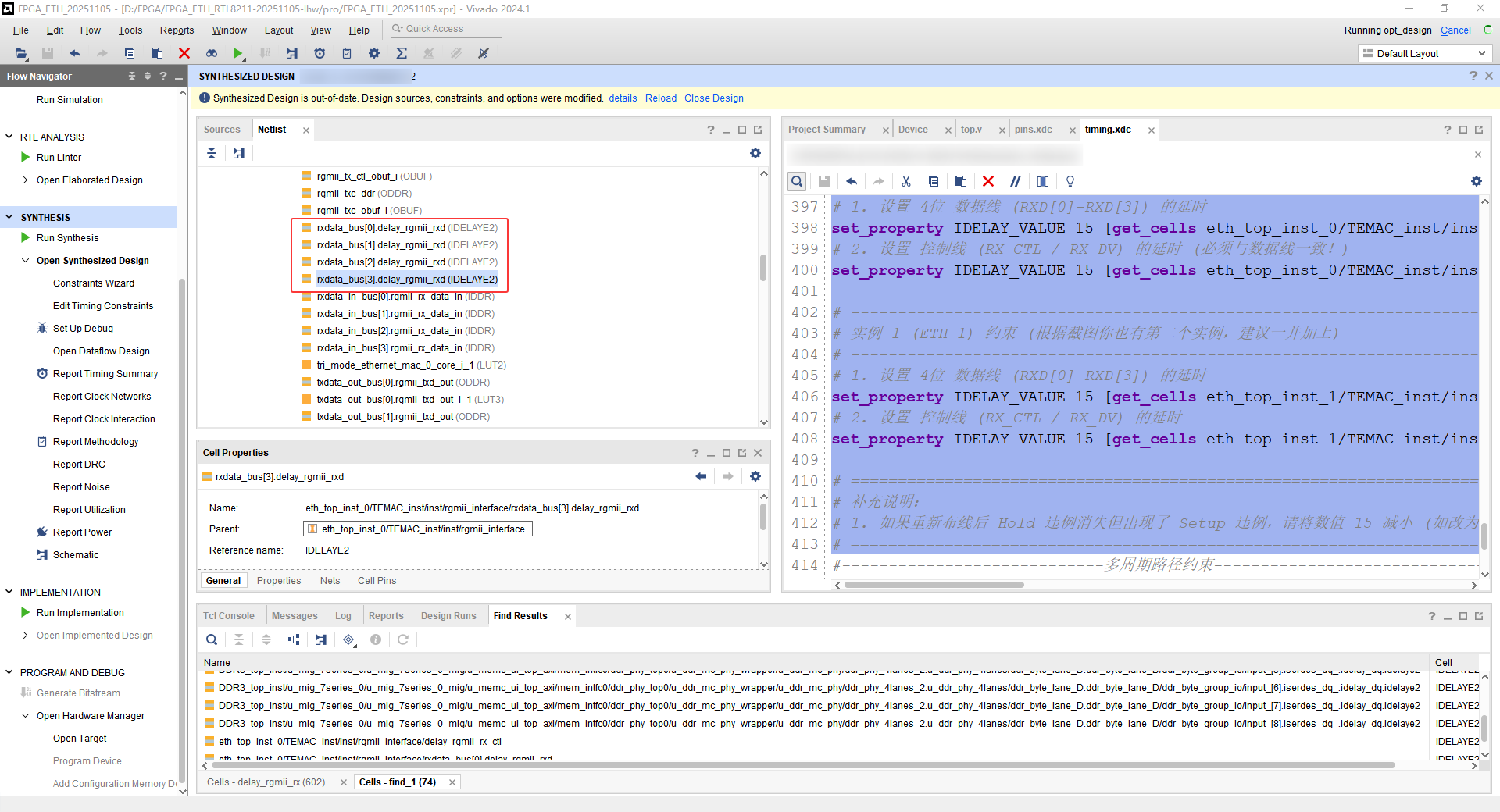
方法二是有用的,保持时间满足了,但是建立时间不满足,所以应该是tap的值给大了。

使用2:

结果:取2又太小了,保持时间更差了,这有可能是IP 核外部可能有一套默认的时钟/数据延时逻辑(或者时钟路径不同),那时的时序刚好只差 -0.088ns。现在可以在0.7的基础上调节。

取eth0---11、eth1---12,结果如下:
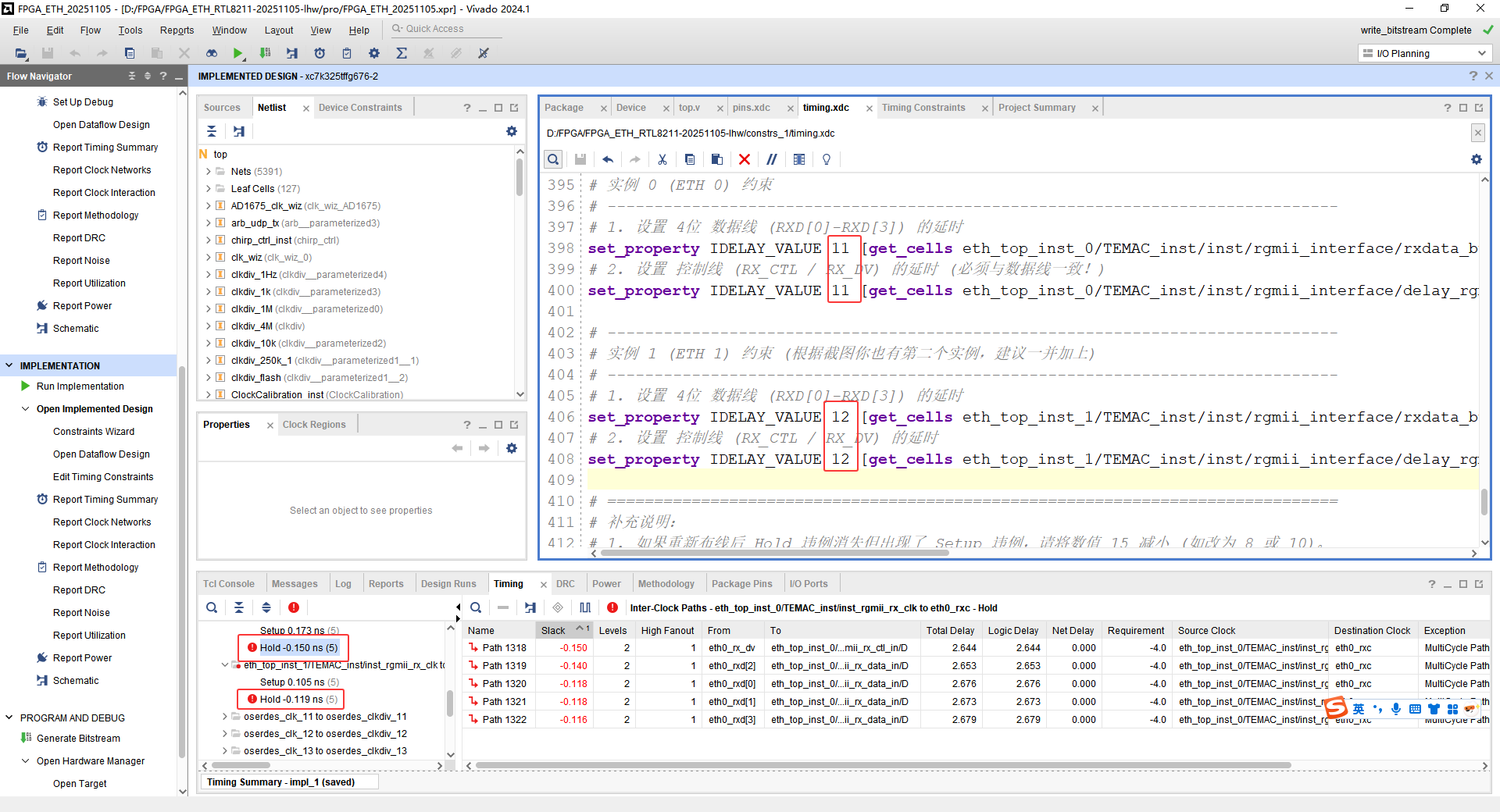
还是没有满足,对于此情况,AI的解释:
理论上
0.78ns的延时确实应该能覆盖掉-0.739ns的缺口,甚至还应该剩一点。但为什么实际上还差-0.15ns呢?根本原因在于:时序分析的"快慢工艺角(Corners)"不同。
核心解释:Hold 检查是在"Fast Corner"进行的
Vivado 在计算 Hold(保持时间)时,使用的是 Fast Corner(最快工艺角) 模型。
场景: 低温、高电压、硅片体质极好。
后果: 在这种极端"快速"的条件下,芯片内部所有的延时都会变短。
导线延时变短了。
逻辑门延时变短了。
最关键的是:IDELAY 的每 1 个 Tap 的延时也变短了!
虽然 IDELAYE2 手册上标称的**标称值(Nominal)**是 78ps (200MHz RefClk),但在 Fast Corner 下,每个 Tap 的实际物理延时可能只有 50ps ~ 60ps 左右。
重新验算(破案现场)
如果我们假设在 Fast Corner 下,IDELAY 的实际精度缩水到了 60ps (0.06ns):
你的操作:增加了 10 个 Tap (从 2 到 12)。
实际增加的延时 :
之前的缺口 :
-0.74 ns。现在的剩余缺口 :
你看,这个计算结果(-0.14ns)和你现在的报告(-0.15ns)是不是几乎完全吻合?
结论与对策
之所以没消除完,是因为你用来"填坑"的土(Tap延时),在 Hold 分析模式下"缩水"了 。这就是为什么我建议你继续大胆往上加的原因:
你现在的 Tap 12 在 Fast Corner 下只提供了约 0.7ns 的延时。
你需要填补的是初始的那个大坑。
所以,Tap 14 或 15 是非常合理的数值。它们在 Fast Corner 下能提供约
放心去改成 13(Eth0)和 14(Eth1)吧,这次一定能过!
取tap=14,结果如下:
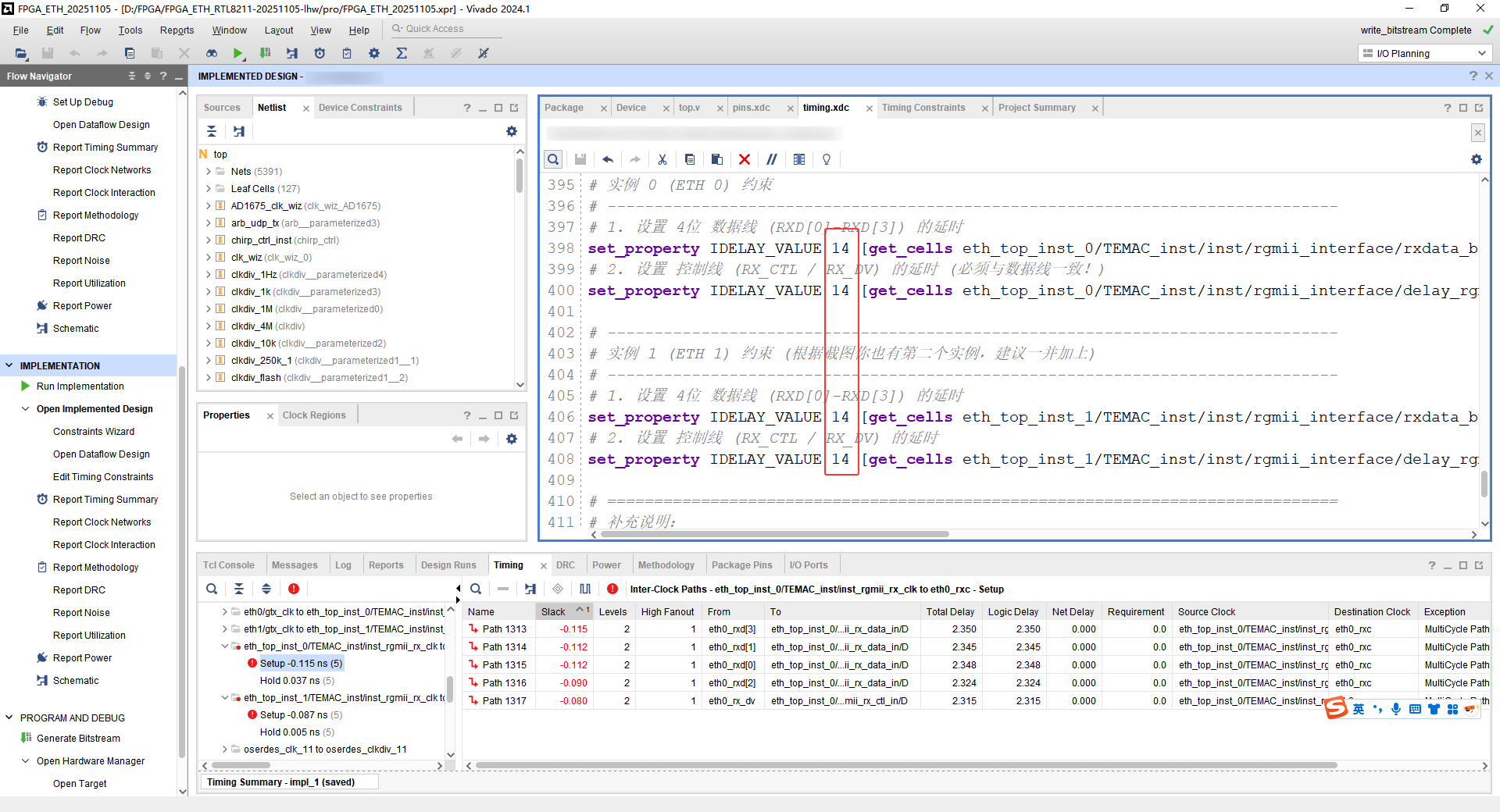
tap=14时,数据来得太慢了,也不行。
取tap=13,结果如下:




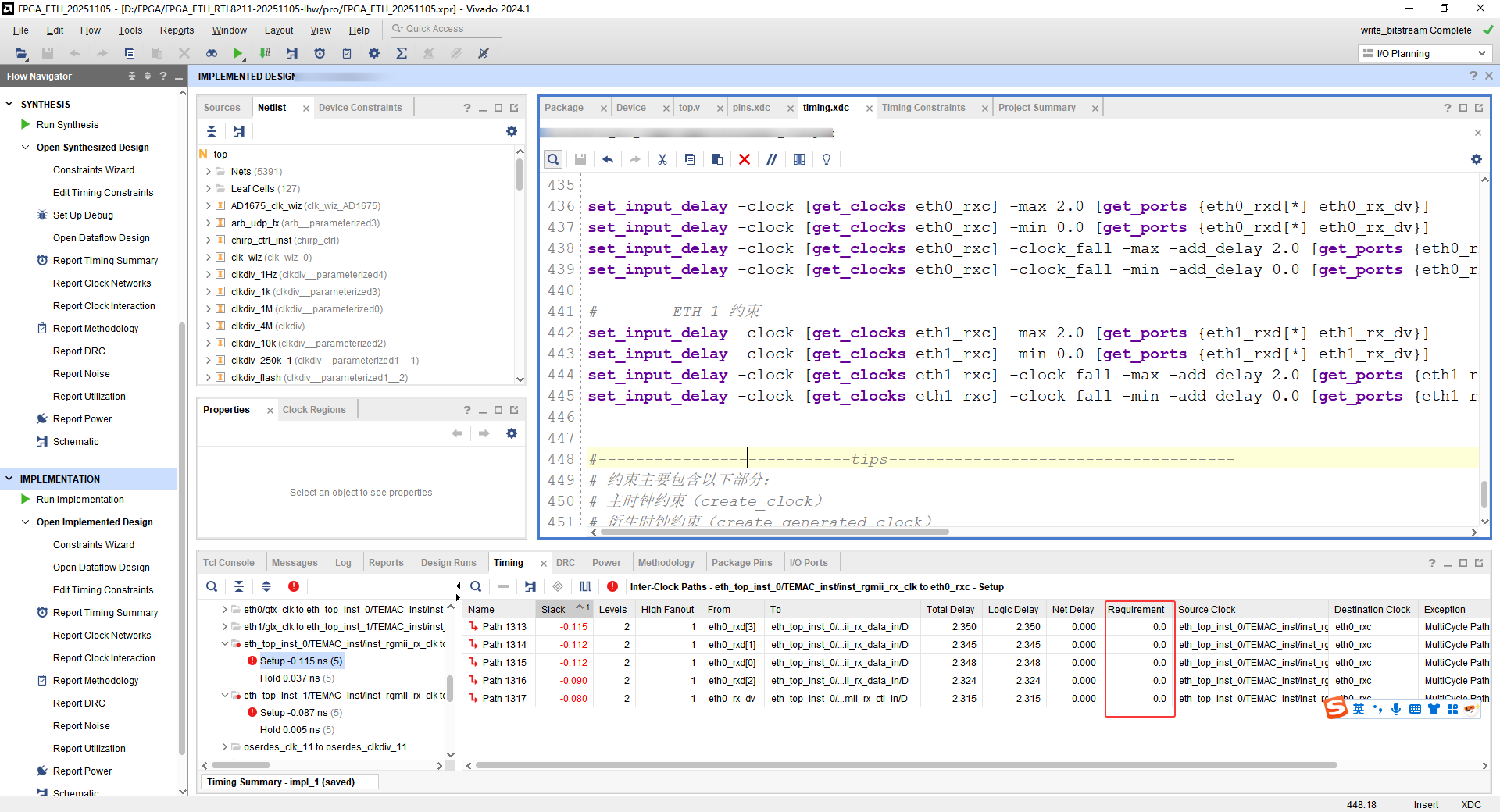
数据会卡在中间,在建立时间之后,保持时间又短。
又发现了一个新的问题Setup Requirement: 0.000 ns的问题:
图片 中的 Requirement 这一列:
Setup Requirement: 0.000 ns
Hold Requirement: -4.000 ns (Hold 看起来是试图跨周期检查,或者因为 Setup 是 0 所以 Hold 乱了)
问题的根源在这里:
由于你之前删除了所有的 set_input_delay,Vivado 现在处于"盲猜"状态。
对于 Setup (建立时间) 检查,它默认使用的是 0ns 的要求(即 Launch Edge 和 Capture Edge 是同一个时刻)。
在 0ns 的时间内,信号要经过 PCB走线 + FPGA IO Buffer + IDELAY + 内部走线,这物理上是不可能完成的。(lhw:但实际上有些事没有问题的)
所以,只要 Requirement 是 0,无论你 IDELAY 设多少,Setup 永远会报错。
解决方案:必须加回约束,并配合 Tap=14
我们现在的策略是:
硬件上 (Tap值) :选择 14。根据你之前的尝试,14 能让 Hold 变绿(物理上确实延时够了,保证数据稳了)。
软件上 (约束) :添加
set_input_delay,把那个不合理的 "Requirement 0.0ns" 变成正常的 4.0ns (RGMII DDR 采样窗口)。请直接将下面的代码块复制到你的
timing.v文件。修改后的 timing.v 建议内容:
#-------------------------------延迟约束-------------------------------------- # ============================================================================== # RGMII Input Constraints (配合 IDELAY_VALUE = 14) # ============================================================================== # 关键解释: # 1. 我们设置 Tap=14,在硬件上物理增加了约 1.1ns 的延时,解决了 Hold 问题。 # 2. 下面的约束告诉 Vivado:这是一个 RGMII 接口,数据在时钟沿之后 2ns 内都是有效的。 # 3. 这会修正 Setup Requirement 为 4ns (而不是现在的 0ns),从而让 Setup 也能通过。 # ============================================================================== # ------ ETH 0 约束 ------ # 注意:eth0_rxc 时钟已经在 pins.v 里定义过了,这里直接引用 # -max 2.0: 告诉工具数据来得不晚于 2ns (给 Setup 留出空间) # -min 0.0: 告诉工具数据来得不早于 0ns (配合 Tap=14 修复 Hold) set_input_delay -clock [get_clocks eth0_rxc] -max 2.0 [get_ports {eth0_rxd[*] eth0_rx_dv}] set_input_delay -clock [get_clocks eth0_rxc] -min 0.0 [get_ports {eth0_rxd[*] eth0_rx_dv}] set_input_delay -clock [get_clocks eth0_rxc] -clock_fall -max -add_delay 2.0 [get_ports {eth0_rxd[*] eth0_rx_dv}] set_input_delay -clock [get_clocks eth0_rxc] -clock_fall -min -add_delay 0.0 [get_ports {eth0_rxd[*] eth0_rx_dv}] # ------ ETH 1 约束 ------ set_input_delay -clock [get_clocks eth1_rxc] -max 2.0 [get_ports {eth1_rxd[*] eth1_rx_dv}] set_input_delay -clock [get_clocks eth1_rxc] -min 0.0 [get_ports {eth1_rxd[*] eth1_rx_dv}] set_input_delay -clock [get_clocks eth1_rxc] -clock_fall -max -add_delay 2.0 [get_ports {eth1_rxd[*] eth1_rx_dv}] set_input_delay -clock [get_clocks eth1_rxc] -clock_fall -min -add_delay 0.0 [get_ports {eth1_rxd[*] eth1_rx_dv}]约束解释:
-max 2.0(Setup 检查)通俗翻译: "别迟到"
Vivado 问: "你让他罚站 1.1 小时,会不会导致他**超时(超过4点)**才送到?"
你的回答 (
-max 2.0): "放心吧!他最晚 2点 就到门口了。"结局:
2点到 + 罚站1.1小时 = 3.1点进门。
没超过4点,安全! (Setup Pass)
简单总结: 告诉 Vivado "他来得早",所以**"经得起罚站"**。
-min 0.0(Hold 检查)通俗翻译: "别早退"
Vivado 问: "如果他来得太快,扔下货就跑,我还没来得及开门(时钟沿),货是不是就丢了?"
你的回答 (
-min 0.0): "他确实可能 0点 一开门就到。但是!我有 Tap=14 啊!"结局:
虽然他0点就到了,但被强行按在门口罚站到 1.1点。
哪怕我在屋里磨蹭到 1点才去开门,他居然还在门口等着!安全! (Hold Pass)
简单总结: 告诉 Vivado "虽然他来得快",但"我有手段(Tap=14)把他留住"。
别忘了改回 IDELAY
在
timing.v的末尾,请把 Tap 值改回 14(或者 15 也行,13 有点冒险)。
# 实例 0 (ETH 0) set_property IDELAY_VALUE 14 [get_cells eth_top_inst_0/TEMAC_inst/inst/rgmii_interface/rxdata_bus[*].delay_rgmii_rxd] set_property IDELAY_VALUE 14 [get_cells eth_top_inst_0/TEMAC_inst/inst/rgmii_interface/delay_rgmii_rx_ctl] # 实例 1 (ETH 1) set_property IDELAY_VALUE 14 [get_cells eth_top_inst_1/TEMAC_inst/inst/rgmii_interface/rxdata_bus[*].delay_rgmii_rxd] set_property IDELAY_VALUE 14 [get_cells eth_top_inst_1/TEMAC_inst/inst/rgmii_interface/delay_rgmii_rx_ctl]总结
你现在的 Setup 报错是因为"无约束导致的 0ns 检查"。
加上上面这两段代码(Tap=14 + Input Delay),你的时序报告里 Requirement 会变成 4.0ns,Setup 和 Hold 应该就会全部变绿 (PASS) 了。请重新 Run Implementation。
这里选2ns的原因:
2ns这个数值并不是随手乱写的,而是基于 千兆以太网 RGMII 接口的物理特性 和 DDR(双倍数据率)时序 推算出来的。这里是详细的计算逻辑:
基础物理常数:4ns 的由来
首先,我们需要知道 RGMII 接口传输数据的"基本单位时间"是多少。
时钟频率 :千兆以太网的 RXC 时钟是 125 MHz。
时钟周期 (
DDR 特性 :RGMII 是 DDR (Double Data Rate) 接口,意味着在时钟的上升沿 和下降沿都会传输数据。
数据有效窗口 (Unit Interval, UI):
结论: 每一个数据比特在总线上的持续时间只有 4ns。这是我们拥有的"总时间预算"。
为什么要设为 2ns?(切蛋糕原理)
在约束文件中设置
-max 2.0和-min 0.0,实际上是在告诉 Vivado:"在这 4ns 的窗口里,数据到底乱了多久,稳了多久。"我们将这 4ns 的时间预算切成两半:
前 2ns (Uncertainty) :假设数据从 PHY 芯片出来时,因为各种抖动(Skew)、PCB 走线差异等原因,到达 FPGA 的时间是不确定的。我们把这 0ns ~ 2ns 的时间段划为"不安全区"。
后 2ns (Valid Window) :剩下的 2ns ~ 4ns 时间段,数据肯定已经稳定了。这是留给 FPGA 采样的"安全区(数据眼图张开的区域)"。
计算公式:
这是一种"工程经验值" (Conservative Constraint)。
激进做法 :如果你查 PHY 芯片手册,它的 Skew 可能只有 +/- 0.5ns。那你设
-max 0.5也可以。稳妥做法 :设为
2.0ns是比较宽松的。它假设数据在半个周期内都可能是不稳定的,只要保证剩下半个周期能采到就行。这对于修复时序违例(Timing Closure)来说,是一个非常好的起点。总结
4ns 是总预算(125MHz DDR)。
2ns 是我们人为划分的一半界限,用来定义"最坏情况下数据什么时候到"。
这个值给了 Vivado 一个清晰的计算基准,从而让它能正确计算 Setup Slack,而不再报出那个错误的
Requirement 0.000ns。
其实我觉得AI给的这个原因不太靠谱,但还是尝试了一下:
感觉约束语句没有起作用。AI解释:
你的感觉非常敏锐!约束确实没有起作用。
证据就在你上传的图片
image_b87c8c.png里:
Requirement (要求) 这一列显示的是
0.0。如果你写的
set_input_delay生效了,这里显示的应该是4.0(或者 2.0),绝对不可能是 0。根本原因:时序上的"先有鸡还是先有蛋"
在你的 timing.v 文件中,你使用了这样的命令:
set_input_delay -clock get_clocks eth0_rxc
这意味着:"去找一个叫
eth0_rxc的时钟,然后基于它设置延时。"但是,请往上翻看你的 timing.v 文件头部(#----------------------------------主时钟约束-------------------------------------- 区域):
你并没有在这里定义 eth0_rxc 时钟!
虽然你在
pins.v(pins.xdc) 里定义过它,但 Vivado 读取约束文件是有顺序的。如果 Vivado 先读了timing.xdc,此时eth0_rxc时钟还没生出来,get_clocks就会抓个空,整条set_input_delay命令就会直接报错并被忽略(你可以在 Tcl Console 的黄色警告里找到类似 "No clocks matched 'eth0_rxc'" 的记录)。
修正方案:在文件头部显式定义时钟
请直接把以下代码插到
timing.v文件的最开头,确保在使用时钟之前,时钟已经存在。
#----------------------------------主时钟约束-------------------------------------- # [新增] 必须先定义以太网 RX 时钟,后面的 set_input_delay 才能找到它! create_clock -period 8.000 -name eth0_rxc [get_ports eth0_rxc] create_clock -period 8.000 -name eth1_rxc [get_ports eth1_rxc] # ... 原有的 clk_cfgmclk 等代码保持不变 ...
完整的修改步骤
打开
timing.v。添加时钟定义 :在文件最上方加入上述
create_clock语句。保留延时约束 :文件底部的
set_input_delay(Max 2.0 / Min 0.0) 和IDELAY_VALUE 14保持不变,它们写得很对,只是之前没生效。重新跑 Implementation。
预期结果:
这次跑完后,看 Timing 报告,Requirement 应该会变成 4.000 (或 2.000),Setup Slack 会瞬间增加好几个 ns,变成绿色 (PASS)。
在time.xdc中添加以下代码:
create_clock -period 8.000 -name eth0_rxc [get_ports eth0_rxc]
create_clock -period 8.000 -name eth1_rxc [get_ports eth1_rxc]重现编译完成之后还是有没有变化:

尝试将pin里面定义的eth0_rxc 和 eth1_rxc注释,再次编译,结果如下:
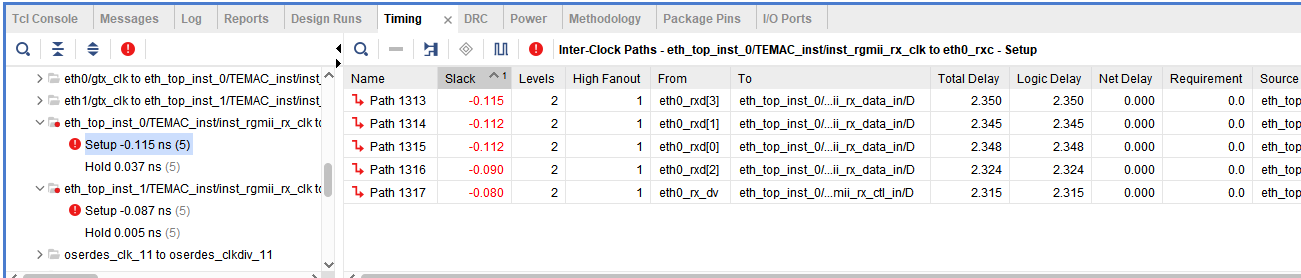
还是没有变化。
实际上语句是有记录的:
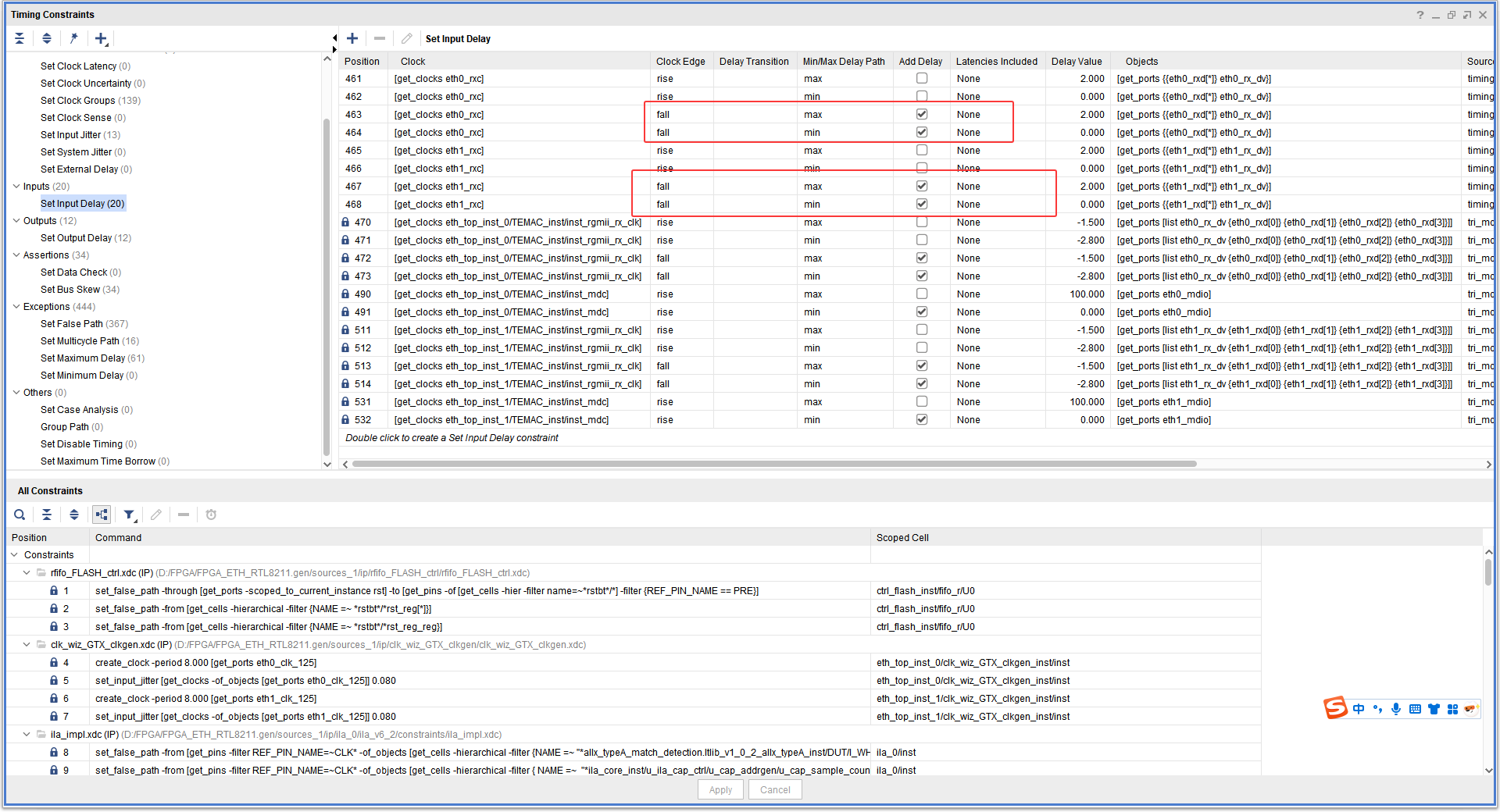
不起作用的原因:
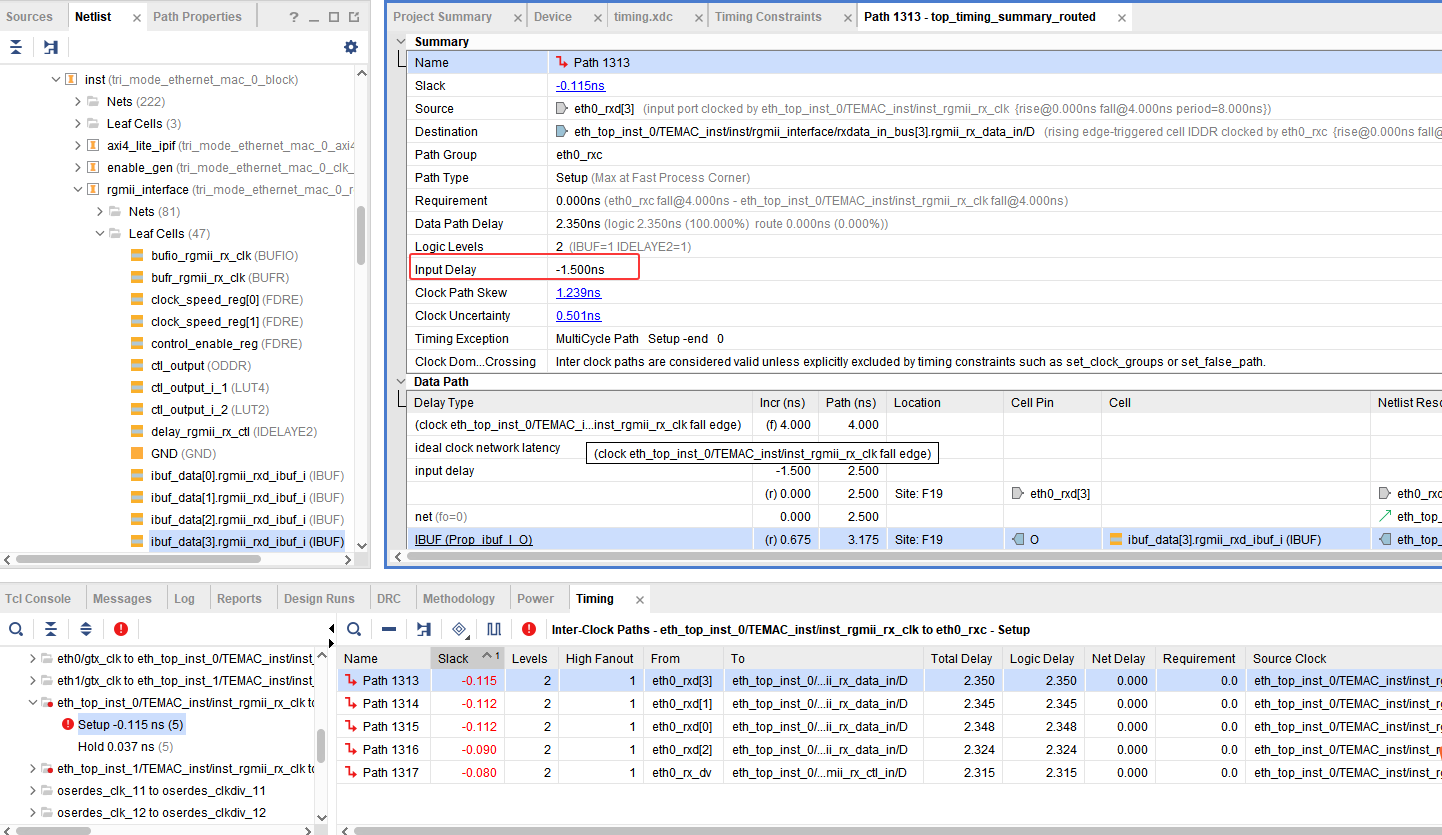
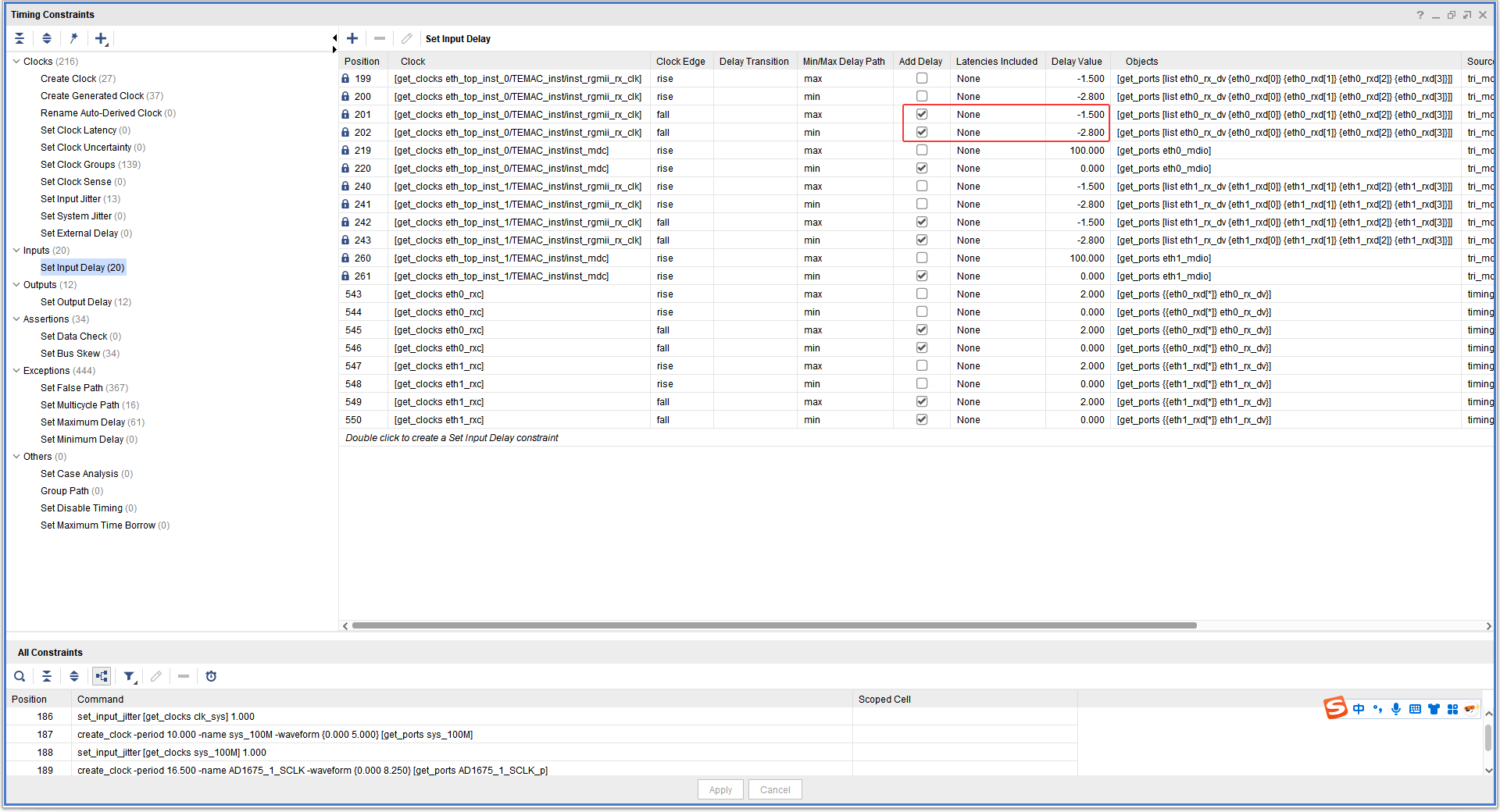
虽然你已经修改了代码,但图 里赫然写着 Input Delay: -1.500ns。
这意味着你写的 2.0ns 根本没生效,IP 核自带的"霸王条款"依然在生效。
根本原因:顺序问题(Order of Execution)
这是一个非常经典的 "后发制人" 游戏。
Vivado 的逻辑 :如果针对同一个端口、同一个时钟写了两条
set_input_delay,后读取的那条会覆盖先读取的那条 。(从上往下读)现在的状况:
先执行 :你的
timing.xdc(包含了 2.0ns 的约束)。后执行 :IP 核自带的
.xdc(包含了 -1.5ns 的约束)。结果:IP 核成功地把你的约束覆盖回去了。
终极解决方案:调整约束文件的读取顺序
需要把你的
timing.xdc设置为 "最后读取" (LATE) ,让它拥有最终解释权,强行覆盖掉 IP 核的约束。直接用 Tcl 命令 来完成,这是最快且绝对成功的方法。操作步骤:
打开 Tcl Console (在 Vivado 界面最下方)。
复制并运行 下面这行命令(注意文件名要和你工程里的一致):
set_property PROCESSING_ORDER LATE [get_files timing.xdc]确认生效:
运行后,你可以去左侧 Sources 窗口,右键点击
timing.xdc-> Source File Properties。在属性栏里,你应该能看到
Processing Order变成了 LATE。重新跑 Implementation。
为什么这样做能解决?
当我们将
timing.xdc设为LATE后,Vivado 的执行流程变成了:
读取 IP 核约束
读取你的
timing.xdc覆盖发生 :Vivado 发现同一个地方有了新规定,于是丢弃 -1.5ns,采用 2.0ns。
总结检查清单
为了确保这次一定过,请检查
timing.xdc现在的状态是否符合以下 3 点:
没有
create_clock定义eth0_rxc(避免双时钟冲突)。没有
remove_input_delay语句(避免报错)。只有 这种自动抓取时钟的约束语句:
set_input_delay -clock [get_clocks -of_objects [get_ports eth0_rxc]] -max 2.0 [get_ports {eth0_rxd[*] eth0_rx_dv}] set_input_delay -clock [get_clocks -of_objects [get_ports eth0_rxc]] -min 0.0 [get_ports {eth0_rxd[*] eth0_rx_dv}] # ... 以及 fall 的约束 ...只要满足这三点,并且执行了上面的 Tcl 命令改顺序,那个顽固的 -1.5ns 就会消失,你的时序就会变绿。
这个的确有用,但是错误更多了。


现在连发送也有问题了。
AI解决方法:
这是一次非常宝贵的"踩坑"经历!请不要灰心,你现在的状态其实比之前更接近真相。
之前的"绿色"某种程度上是因为 IP 核自带的约束掩盖了问题,或者是约束冲突导致的误判。现在,我们清除了干扰,Vivado 终于对你说实话了。
让我们像侦探一样分析一下为什么现在发送(TX)和接收(RX)都报 Hold 违例,以及如何从根本上解决它。
1. 接收端 (RX) 为什么 Hold 挂了 (-1.164 ns)?
案情分析
现象 :rx截图显示
Slack = -1.164 ns。原因 :"龟兔赛跑"------数据是兔子,时钟是乌龟。
数据 (Data) :从管脚进来,经过
IDELAY(Tap=14, 约 1.1ns),到达寄存器 D 端。时钟 (Clock) :从管脚进来,要经过很长的全局时钟网络 (Clock Tree) 才能到达寄存器 CLK 端。这个过程非常慢(可能需要 2.5ns 以上)。
结果 :数据跑得太快,在时钟到达之前 1.164ns 就已经发生了变化。原本应该被采集的数据"溜走"了。
你的疑问:为什么之前没事?
之前是因为 IP 核自带了
-min -2.800 ns这样极端的约束。它通过告诉 Vivado "外部数据会保持非常久" 来强行抹平这个 2ns+ 的时钟延时差。现在你用了诚实的-min 0.0,问题就暴露了。解决办法:加大药量 (Increase Tap)
既然数据跑太快,我们就继续用 IDELAY 拖住它!
当前亏空 :
-1.164 ns。IDELAY 精度 :每 Tap 约
0.078 ns。需要增加的 Tap 数 :
当前 Tap:14。
目标 Tap :
建议操作:
请将 timing.xdc 末尾的 IDELAY_VALUE 从 14 直接改到 29(最大值是 31,29 是安全的)。
# 修改 RX 的 IDELAY set_property IDELAY_VALUE 29 [get_cells eth_top_inst_0/.../delay_rgmii_rxd] # ... 别忘了 rx_ctl 也要改 ...
2. 发送端 (TX) 为什么 Hold 挂了 (-1.564 ns)?
案情分析
现象 :截图 显示
Slack = -1.564 ns。原因 :FPGA 往外发数据太快了。
RGMII 协议要求:发送时钟 (
TXC) 应该比数据 (TXD) 晚 2ns (90度相位),这样 PHY 芯片才能在数据正中间采样。现状:你的数据和时钟几乎同时从 FPGA 出发(或者时钟延时不够),导致数据在 PHY 端保持时间不足。
解决办法:因为没有 ODELAY,只能"认怂" (Relax Constraints)
在 Xilinx 7 系列 HR Bank(3.3V)中,没有 ODELAY(输出延时)原语,所以我们无法像 RX 那样调节 Tap。
既然物理上改不了,我们只能放宽考试标准 。目前的
-min -1.0对于这个设计来说还是太严了。我们需要告诉 Vivado:"PHY 芯片其实没那么娇气,哪怕数据和时钟靠得很近,它也能收"。建议操作:
修改 timing.xdc 末尾的 TX 约束,把 -min 设得更低。
原设置:
-min -1.0新建议:
-min -2.6(为了覆盖掉 -1.564 的违例)修改 TX 约束 (更加宽松)
--- ETH 0 ---
set_output_delay -clock [get_clocks -of_objects [get_ports eth0_txc]] -max 1.0 [get_ports {eth0_txd[] eth0_tx_en}]
set_output_delay -clock [get_clocks -of_objects [get_ports eth0_txc]] -min -2.6 [get_ports {eth0_txd[] eth0_tx_en}]--- ETH 1 ---
set_output_delay -clock [get_clocks -of_objects [get_ports eth1_txc]] -max 1.0 [get_ports {eth1_txd[] eth1_tx_en}]
set_output_delay -clock [get_clocks -of_objects [get_ports eth1_txc]] -min -2.6 [get_ports {eth1_txd[] eth1_tx_en}]
3. 总结与行动指南
现在的情况其实是好事,因为你掌控了局面,知道该调哪里了。
请执行以下两步:
物理修复 (RX):
打开 timing.xdc,把所有 IDELAY_VALUE 从 14 改为 29。这将物理上解决 RX Hold 问题。
逻辑修复 (TX):
打开 timing.xdc,把所有 set_output_delay ... -min 的值从 -1.0 改为 -2.6。
做完这两步,重新 Run Implementation。这次应该能看到久违的绿色了!
结果还是不行,甚至更严重了:


最后采用了tap=14的版本。
2.3总结
需要明确一个概念:set_input_delay 只是在"描述现状",而不是在"改变现状"。 它告诉 Vivado 外部数据和时钟的时序关系,让工具在这个前提下优化布局布线,但它本身并不会让信号变慢。只要抓取的波形是正常的,并且你的 set_input_delay 如实描述了这个波形,那么时序分析报告就是可信的。如果外部波形很差(比如数据比时钟晚了 5ns),但你骗 Vivado 说数据只晚了 1ns(set_input_delay 设错了)。结果: Vivado 会显示"时序通过(绿了)"。但是上板测试还是会挂。
如果你真的需要在硬件上把输入信号"拖慢"一点,只能使用 IDELAY 模块。这就好比一个有 32 个档位的精密延时器,每拨动一个档位(Tap)增加约 78ps,总共能提供约 2.5ns 的物理延时。
本次用到的约束语句如下:
set_clock_groups -asynchronous -group [get_clocks AD1675_1_SCLK] -group [get_clocks clk_1M]
set_clock_groups -asynchronous -group [get_clocks AD1675_1_SCLK] -group [get_clocks clk_100M_1]
set_clock_groups -asynchronous -group [get_clocks AD1675_1_SCLK] -group [get_clocks clk_100M_2]
set_clock_groups -asynchronous -group [get_clocks AD1675_1_SCLK] -group [get_clocks clk_100M_3]
set_clock_groups -asynchronous -group [get_clocks AD1675_1_SCLK] -group [get_clocks gtx_clk]
set_clock_groups -asynchronous -group [get_clocks AD1675_2_SCLK] -group [get_clocks clk_1M]
set_clock_groups -asynchronous -group [get_clocks AD1675_2_SCLK] -group [get_clocks clk_100M_1]
set_clock_groups -asynchronous -group [get_clocks AD1675_2_SCLK] -group [get_clocks clk_100M_2]
set_clock_groups -asynchronous -group [get_clocks AD1675_2_SCLK] -group [get_clocks clk_100M_3]
set_clock_groups -asynchronous -group [get_clocks AD1675_2_SCLK] -group [get_clocks gtx_clk]
set_clock_groups -asynchronous -group [get_clocks AD1675_3_SCLK] -group [get_clocks clk_1M]
set_clock_groups -asynchronous -group [get_clocks AD1675_3_SCLK] -group [get_clocks clk_100M_1]
set_clock_groups -asynchronous -group [get_clocks AD1675_3_SCLK] -group [get_clocks clk_100M_2]
set_clock_groups -asynchronous -group [get_clocks AD1675_3_SCLK] -group [get_clocks clk_100M_3]
set_clock_groups -asynchronous -group [get_clocks AD1675_3_SCLK] -group [get_clocks gtx_clk]
set_false_path -from [get_pins SAMP_EN_reg/C] -to [get_pins u_AD1675_ch*/START_reg/CLR]
# ==============================================================================
# RGMII IDELAY 静态延时修复 (Fix Hold Violation)
# ==============================================================================
# 目标:解决 -0.088ns 的 Hold 违例
# 原理:IDELAYE2 Tap 精度约为 78ps (0.078ns) @ 200MHz RefClk
# 设置:设定值为 15 (约增加 1.17ns 延时),足以覆盖 -0.088ns 的缺口并留出余量0.05 0.138
# 注意:这不仅包含数据线(rxd),也包含控制线(rx_ctl/rx_dv),必须同步调整
# ------------------------------------------------------------------------------
# 实例 0 (ETH 0) 约束
# ------------------------------------------------------------------------------
# 1. 设置 4位 数据线 (RXD[0]-RXD[3]) 的延时
set_property IDELAY_VALUE 29 [get_cells eth_top_inst_0/TEMAC_inst/inst/rgmii_interface/rxdata_bus[*].delay_rgmii_rxd]
# 2. 设置 控制线 (RX_CTL / RX_DV) 的延时 (必须与数据线一致!)
set_property IDELAY_VALUE 29 [get_cells eth_top_inst_0/TEMAC_inst/inst/rgmii_interface/delay_rgmii_rx_ctl]
# ------------------------------------------------------------------------------
# 实例 1 (ETH 1) 约束 (根据截图你也有第二个实例,建议一并加上)
# ------------------------------------------------------------------------------
# 1. 设置 4位 数据线 (RXD[0]-RXD[3]) 的延时
set_property IDELAY_VALUE 29 [get_cells eth_top_inst_1/TEMAC_inst/inst/rgmii_interface/rxdata_bus[*].delay_rgmii_rxd]
# 2. 设置 控制线 (RX_CTL / RX_DV) 的延时
set_property IDELAY_VALUE 29 [get_cells eth_top_inst_1/TEMAC_inst/inst/rgmii_interface/delay_rgmii_rx_ctl]
# ==============================================================================
# 补充说明:
# 1. 如果重新布线后 Hold 违例消失但出现了 Setup 违例,请将数值 15 减小 (如改为 8 或 10)。
# ==============================================================================
#-------------------------------延迟约束--------------------------------------
# ==============================================================================
# RGMII Input Constraints (配合 IDELAY_VALUE = 14)
# ==============================================================================
# 关键解释:
# 1. 我们设置 Tap=14,在硬件上物理增加了约 1.1ns 的延时,解决了 Hold 问题。
# 2. 下面的约束告诉 Vivado:这是一个 RGMII 接口,数据在时钟沿之后 2ns 内都是有效的。
# 3. 这会修正 Setup Requirement 为 4ns (而不是现在的 0ns),从而让 Setup 也能通过。
# ==============================================================================
# ------ ETH 0 约束 ------
# 注意:eth0_rxc 时钟已经在 pins.v 里定义过了,这里直接引用
# -max 2.0: 告诉工具数据来得不晚于 2ns (给 Setup 留出空间)
# -min 0.0: 告诉工具数据来得不早于 0ns (配合 Tap=14 修复 Hold)
set_input_delay -clock [get_clocks eth0_rxc] -max 2.0 [get_ports {eth0_rxd[*] eth0_rx_dv}]
set_input_delay -clock [get_clocks eth0_rxc] -min 0.0 [get_ports {eth0_rxd[*] eth0_rx_dv}]
set_input_delay -clock [get_clocks eth0_rxc] -clock_fall -max -add_delay 2.0 [get_ports {eth0_rxd[*] eth0_rx_dv}]
set_input_delay -clock [get_clocks eth0_rxc] -clock_fall -min -add_delay 0.0 [get_ports {eth0_rxd[*] eth0_rx_dv}]
# ------ ETH 1 约束 ------
set_input_delay -clock [get_clocks eth1_rxc] -max 2.0 [get_ports {eth1_rxd[*] eth1_rx_dv}]
set_input_delay -clock [get_clocks eth1_rxc] -min 0.0 [get_ports {eth1_rxd[*] eth1_rx_dv}]
set_input_delay -clock [get_clocks eth1_rxc] -clock_fall -max -add_delay 2.0 [get_ports {eth1_rxd[*] eth1_rx_dv}]
set_input_delay -clock [get_clocks eth1_rxc] -clock_fall -min -add_delay 0.0 [get_ports {eth1_rxd[*] eth1_rx_dv}]
# 修改 TX 约束 (更加宽松)
# --- ETH 0 ---
set_output_delay -clock [get_clocks -of_objects [get_ports eth0_txc]] -max 1.0 [get_ports {eth0_txd[*] eth0_tx_en}]
set_output_delay -clock [get_clocks -of_objects [get_ports eth0_txc]] -min -2.3 [get_ports {eth0_txd[*] eth0_tx_en}]
# --- ETH 1 ---
set_output_delay -clock [get_clocks -of_objects [get_ports eth1_txc]] -max 1.0 [get_ports {eth1_txd[*] eth1_tx_en}]
set_output_delay -clock [get_clocks -of_objects [get_ports eth1_txc]] -min -1.5 [get_ports {eth1_txd[*] eth1_tx_en}]-clock_fall:明确告知 Vivado,这条约束是针对时钟信号的下降沿(Falling Edge)定义的。
-add_delay:这是最关键的参数。
在同一个端口(如 eth0_rxd)上施加多个约束时,必须加上 -add_delay。
如果不加:第二条指令会直接"覆盖"掉第一条。结果就是只有下降沿有约束,上升沿反而没约束了。
加上后:两条约束会同时生效,Vivado 会分别计算上升沿和下降沿的 Slack(余量)。
以上是本次针对跨时钟域问题排查的记录。从中也可以看出,AI辅助工具在辅助代码审查与方案比对方面具有显著优势。合理利用AI辅助手段,有助于我们更快速、精准地攻克技术难点。