分布式事务解决方案
1. XA 两阶段提交协议
两阶段提交协议(Two-phase commit protocol,简称2PC)是一种分布式事务处理协议,旨在确保参与分布式事务的所有节点都能达成一致的结果。此协议被广泛应用于许多分布式关系型数据管理系统,以完成分布式事务。
它是一种强一致性设计,引入一个事务协调者的角色来协调管理各参与者的提交和回滚,二阶段分别指的是准备(投票)和提交两个阶段。
1、准备阶段(Prepare phase)
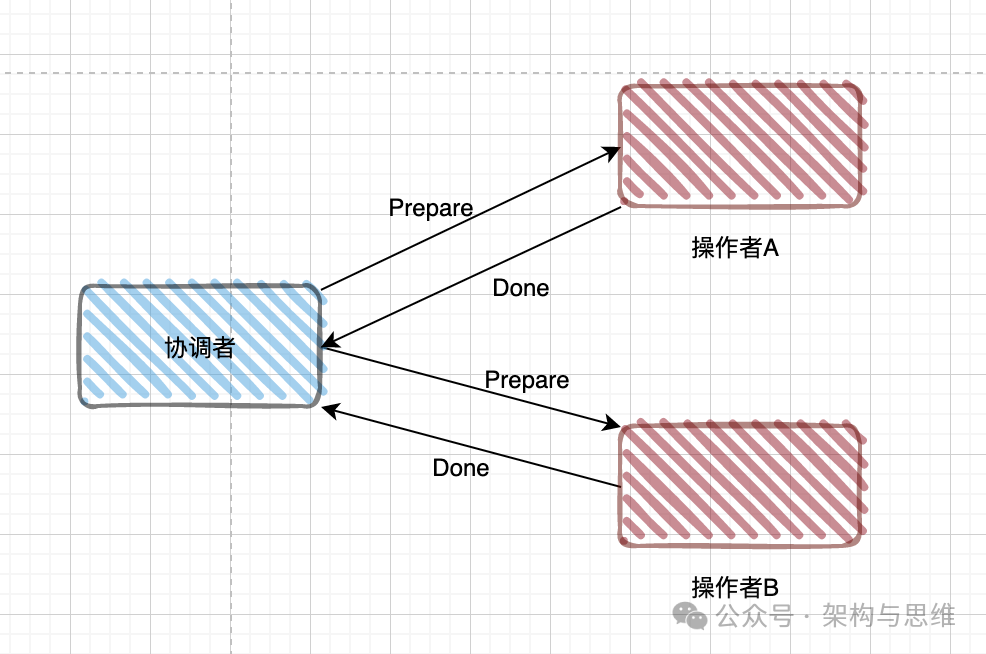
- TM 向所有 RM 发送 prepare 请求
- RM 执行本地事务(但不提交)
- RM:
- 写 Redo / Undo Log
- 锁定资源
- 返回 YES / NO
如果 RM 执行成功,向 TM 返回 Ready;下面是两个参与者都执行成功的结果:
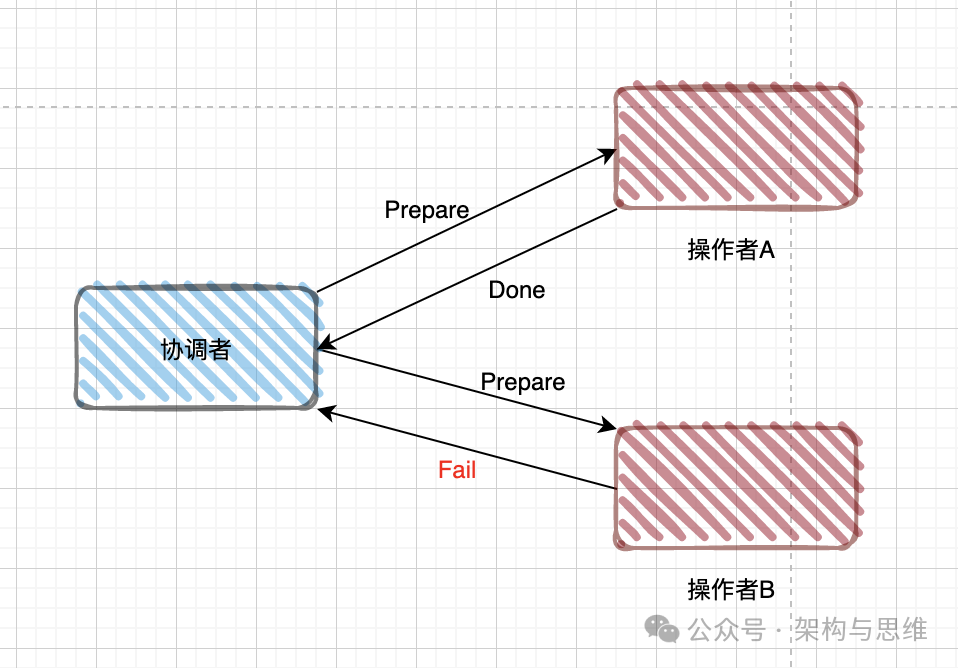
如果 RM 执行成功,向 TM 返回 Ready ;如果失败(如违反约束),返回 Fail。
2、提交阶段(Commit phase)
这一阶段的行为取决于第一阶段的结果:
- 情况 A :全部成功 若所有 RM 都返回
Ready,TM向所有RM发送Commit指令。RM完成提交并释放锁。 - 情况 B :有任何一个失败 若有任何一个
RM返回Fail或超时未响应,TM向所有RM发送Rollback指令。RM利用第一阶段记录的日志进行回滚。
2. XA 三阶段提交
三阶段提交(3PC,Three-Phase Commit)是对二阶段提交(2PC)的改进版。它通过引入超时机制 和预提交阶段 ,主要解决了 2PC 的阻塞问题。
我们将 3PC 拆解为三个阶段:CanCommit 、PreCommit 和 doCommit。
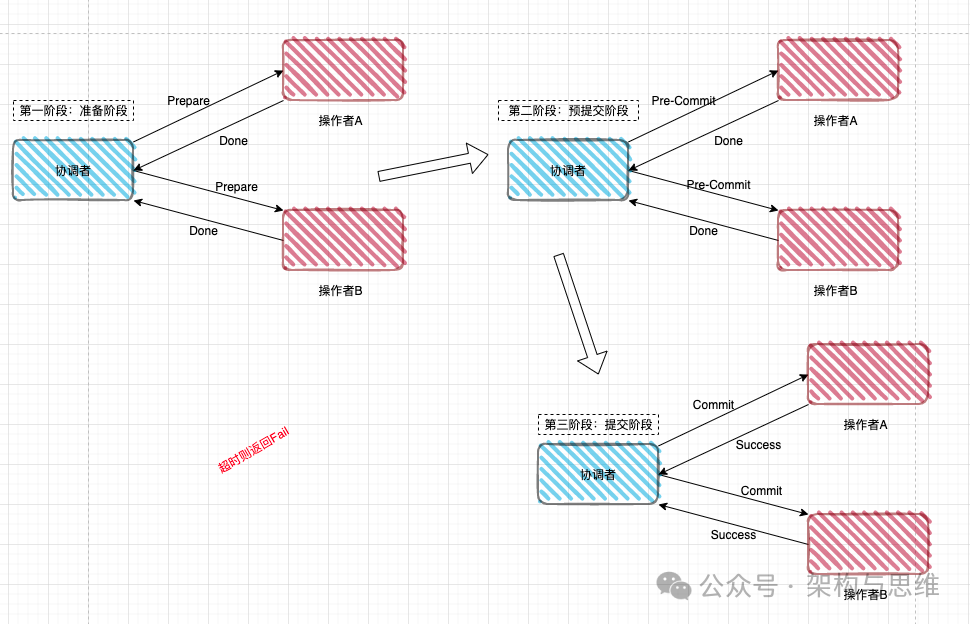
一、 三阶段的具体流程
1. CanCommit (询问阶段)
协调者向参与者发送 CanCommit 请求。
- 协调者:询问参与者,你的状态是否可以执行事务?
- 参与者 :检查自身状态、资源锁情况。如果觉得没问题,返回
Yes,否则返回No。
改进点:这一步不锁资源,只是"轻量级"地确认一下大家是否都活着且有空,减少了后续无谓的资源锁定。
2. PreCommit (预提交阶段)
协调者根据第一阶段的反馈决定。
- 情况 A(全是 Yes) :协调者发送
PreCommit。参与者执行事务操作,并将 Undo/Redo 信息记入日志(锁定资源),但不提交。 - 情况 B(有 No 或超时) :协调者发送
Abort,参与者取消事务。
改进点:此时参与者已经进入了"准提交"状态。
3. doCommit (正式提交阶段)
- 执行提交 :如果协调者收到了所有参与者的 Ack(确认),则发送
doCommit指令。参与者完成事务提交,释放锁。 - 中断事务 :如果协调者收到任何一个
No或者指令超时,则发送Rollback。
二、 3PC 解决的核心痛点
3PC 相比 2PC 最大的两个改进是:
-
引入超时机制:
- 在 2PC 中,如果协调者挂了,参与者会死等,导致资源永久锁定。
- 在 3PC 中,如果参与者在 PreCommit 之后,长时间没收到协调者的 doCommit 指令,参与者会自动触发提交(因为既然到了这一步,说明前两步大家都同意了,提交成功的概率极高)。
-
降低阻塞范围:
- 通过第一阶段的
CanCommit探测,排除了由于参与者挂掉而导致的长时间无效锁定。
- 通过第一阶段的
三、 3PC 依然存在的问题(脑裂)
虽然 3PC 解决了阻塞,但它带来了一个更严重的一致性问题:数据不一致(脑裂)。
- 场景 :进入第三阶段
doCommit时,协调者发出了回滚(Abort)指令。 - 异常 :如果网络出现分区,某个参与者没收到
Abort指令,由于 3PC 的"超时自动提交"机制,这个参与者会在超时后自动提交事务。 - 后果:一部分参与者回滚了,一部分参与者提交了,分布式事务彻底失败,数据不一致。
四、 现实中的选择
在实际的工业级互联网项目中:
- 3PC 极少被使用。因为它增加了通信次数(由 2 次变 3 次),且依然不能完美解决一致性问题。
- 主流方案 :
- Seata AT:基于 2PC 改良,利用 Undo Log 解决了 2PC 的长时间锁表问题。
- Paxos/Raft 算法:通过"多数派"投票机制保证强一致性,比 3PC 健壮得多。
3. TCC 事务
TCC (Try-Confirm-Cancel) 是一种补偿型分布式事务解决方案,它属于业务层面的柔性事务。
与 Seata AT 等"自动"回滚方案不同,TCC 要求开发者手动编写三个阶段的业务逻辑,因此它对代码的侵入性最高,但性能也是最强的。
一、 TCC 的三个阶段
TCC事务是Try、Confirm、Cancel三种指令的缩写,其逻辑模式类似于XA两阶段提交,但是实现方式是在代码层面人为实现。 2PC 和 3PC 都是数据库层面的,而 TCC 是业务层面的分布式事务。
1. Try (尝试阶段)
- 核心逻辑 :完成业务检查,并预留必须的业务资源。
2. Confirm (确认阶段)
- 核心逻辑:执行真正的业务操作。
3. Cancel (取消阶段)
- 核心逻辑:释放 Try 阶段预留的资源,进行业务补偿(回滚)。
二、 TCC 必须解决的"三大异常"
这是面试和实际开发中最重要的三个坑,必须在代码逻辑中规避:
| 异常名称 | 场景描述 | 解决方案 |
|---|---|---|
| 空回滚 (Empty Rollback) | Try 阶段因为网络抖动压根没收到请求,但随后触发了 Cancel 请求。 | Cancel 逻辑中需判断 Try 是否执行过,若没执行过则直接返回成功。 |
| 幂等 (Idempotency) | 由于网络不稳定,Confirm 或 Cancel 指令被多次重复发送。 | 必须记录事务 ID,每次执行前检查该事务是否已处理。 |
| 悬挂 (Hanging) | Cancel 指令比 Try 指令先到达(网络拥堵导致)。当 Cancel 执行完后 Try 才到,此时资源被永久锁定。 | Try 执行前先检查 Cancel 是否已执行过,若已执行则不再执行 Try。 |
四、 TCC 的优缺点总结
优点
- 性能极高:它不需要像 2PC 那样在数据库层面长时间锁行数据。资源锁定是在业务层面完成的。
- 跨数据库/跨语言:只要是能提供 HTTP 或 RPC 接口的服务,都能纳入 TCC,不受底层数据库 ACID 的限制。
缺点
- 开发量翻倍:每个业务逻辑都要写三遍(Try/Confirm/Cancel),维护成本极高。
- 业务耦合重:开发者需要深度参与资源的预留和释放逻辑,对资深开发者的依赖度高。
五、 选型建议
- 什么时候用 TCC? 对并发量要求极高 且资金安全敏感的场景(如:银行转账、秒杀系统余额扣减)。
- 普通业务(如你的岗位权限配置) :
强烈建议不要使用 TCC 。对于这类低频、非高并发的配置业务,使用 Seata AT 或 本地消息表 效率更高,代码也更整洁。
4. 本地消息表(可靠消息最终一致性)
本地消息表(可靠消息最终一致性) 是互联网系统中最常用、最稳妥的一种分布式事务解决方案,本质思想是:
利用了 各系统本地的事务来实现分布式事务, 把"业务操作"和"发消息"放在同一个本地事务里,通过异步 + 重试 + 幂等,保证最终一致性。
🔹 一、 业务服务(生产者)
本地消息表顾名思义就是会有一张存放本地消息的表,一般都是放在数据库中,然后在执行业务的时候,将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的。
🔹 二、 消息投递(异步)
后台定时任务轮询 本地消息 表,将"待发送"的消息发给 MQ。
🔹 三、 消费者处理(幂等)
消费者服务:接收消息,先做幂等校验,执行业务,MQ 返回确认(Ack )后,将本地消息表的状态改为"已完成"或删除。
🔹 四、重试
这时候有可能消息对应的操作不成功,因此也需要重试,重试就得保证对应服务的方法是幂等的,需要有最大重试次数限制。超过次数(如 5 次)后,将状态改为"失败"并触发人工介入或告警。
可以看到本地消息表其实实现的是最终一致性,容忍了数据暂时不一致的情况。
优点:
- 简单可靠:不需要引入复杂的分布式事务中间件(如 Seata)。
- 最终一致性:只要本地事务成功,消息一定能发出去,下游最终一定会处理。
- 性能较好:不需要像 2PC 那样跨服务锁定资源。
缺点/挑战:
- 业务侵入:每个需要一致性的操作都要手动写消息表,代码较杂。
- 数据库压力:高并发下,定时任务轮询消息表会占用数据库 IO。
- 幂等性要求:由于消息可能重发(比如发送成功但更新状态失败),下游服务必须实现幂等校验。
5. 消息事务
RocketMQ 事务消息 是实现分布式事务"最终一致性"的高级方案。它在核心逻辑上与"本地消息表"非常相似,但最巧妙的地方在于:它将消息表的功能内置到了 MQ 内部,从而减轻了应用数据库的压力。
一、 核心流程(三阶段)
RocketMQ 事务消息的实现依赖于 Half Message(半消息) 机制,具体步骤如下:
-
发送半消息:
生产者先发送一条消息到 MQ。此时,MQ 会将消息存入一个特殊的内部队列,但不会投递给消费者(消费者不可见)。
-
执行本地事务:
生产者收到 MQ 的"半消息发送成功"确认后,开始执行本地数据库操作(如:新增岗位)。
-
提交/回滚指令:
- 本地事务成功 :发送
COMMIT指令。MQ 收到后将消息标记为"可投递",消费者开始消费。 - 本地事务失败 :发送
ROLLBACK指令。MQ 直接丢弃该消息。
- 本地事务成功 :发送
二、 兜底机制:事务回查 (Check)
如果生产者在发送 COMMIT/ROLLBACK 指令前宕机了,或者网络抖动导致指令丢失,该怎么办?
RocketMQ 会自动发起回查(Check):
- MQ 发现某条半消息长时间没有指令,会主动询问生产者的一个接口:"这条消息对应的本地事务到底成功了没?"。
- 生产者检查本地数据库状态,再次返回
COMMIT或ROLLBACK。
三、 优缺点总结
优点
- 解耦更彻底:业务库不再需要维护额外的消息表。
- 高并发能力:RocketMQ 能够支撑极高的消息吞吐量。
- 自动重试与回查 :当消费端抛出异常或返回
RECONSUME_LATER时,RocketMQ不会丢弃这条消息,而是将其放入 重试队列 ,保证了极端情况下的最终一致性。如果消息达到了最大重试次数依然失败,它会被移送到 死信队列。
缺点/注意点
- 依赖 MQ:如果 MQ 服务挂了,整个业务的事务性会受影响。
- 开发成本:必须实现回查接口,且需要保证回查逻辑的准确性。
- 幂等性 :和所有异步方案一样,下游消费者必须实现幂等,防止消息重复消费。
总结
在分布式事务(特别是 RocketMQ 事务消息)的架构中,上游执行成功而下游消费失败是一个非常经典的问题。
RocketMQ 的设计原则是:保证消息一定投递到下游,但不保证下游一定能执行成功。 如果下游执行失败,系统通常会通过以下三个层级的防御机制来处理:
对于你正在做的系统:
- 如果你的项目已经是微服务架构且已经引入了 RocketMQ,那么直接用事务消息是最优雅的选择。
- 如果你想快速交付,且不想维护复杂的 MQ 回查逻辑,Seata AT 或者 本地消息表 可能更适合。
你想看一看下游消费者在接收到岗位变更消息时,具体该如何做"幂等校验"的代码示例吗?
什么是分布式 ID?
在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?
这个时候就需要生成分布式 ID了。
分布式 ID 的核心目标是:全局唯一、有序(可选)、高性能、高可用。常见解决方案可以按实现方式分为以下几大类,面试和实际项目里基本都围绕这些展开。
一、数据库类方案
1️⃣ 数据库自增 ID(单库 / 多库)
优点
- 实现简单
- 有序、可读性好
缺点
- 单点瓶颈
- 扩展性差
- 高并发下数据库压力大
2️⃣ 数据库号段(Segment / Hi-Lo)
做法
- 数据库一次分配一段 ID(如 1000 个)
- 应用内存中自增使用
- 用完再向 DB 申请下一段
优点
- DB 访问次数大幅降低
- ID 趋势递增
- 性能高
缺点
- 号段浪费
- 实现略复杂
- 重启可能导致跳号
二、缓存 / 中间件类方案
3️⃣ Redis 原子自增
优点
- 性能极高
- 实现简单
- 原子性有保障
缺点
- 依赖 Redis
- 持久化 / 主从切换要处理好
- 跨 Redis 集群复杂
三、时间 + 机器标识类
4️⃣ UUID
优点
- 本地生成
- 无中心节点
- 理论上绝对唯一
缺点
- 太长(36 位)
- 无序(v4)
- 数据库索引性能差
5️⃣ Snowflake(雪花算法) ⭐⭐⭐⭐⭐
结构(64 位)
| 1bit 符号位 | 41bit 时间戳 | 10bit 机器ID | 12bit 序列号 |优点
- 高性能
- 趋势递增
- 本地生成,无网络依赖
- 分布式友好
缺点
- 依赖时间
- 时钟回拨问题
- 机器 ID 管理复杂
适用场景
- 高并发核心业务
- 订单号、流水号
四、Zookeeper 类方案
7️⃣ Zookeeper 顺序节点
优点
- 强一致
- 天然分布式
缺点
- 性能一般
- 依赖 ZK
- 不适合超高并发
五、综合对比(面试高频)
| 方案 | 有序 | 性能 | 依赖 | 复杂度 |
|---|---|---|---|---|
| DB 自增 | ✔ | ❌ | DB | ⭐ |
| 号段 | ✔ | ✔✔✔ | DB | ⭐⭐⭐ |
| Redis INCR | ✔ | ✔✔✔✔ | Redis | ⭐⭐ |
| UUID | ❌ | ✔✔ | 无 | ⭐ |
| Snowflake | ✔ | ✔✔✔✔✔ | 本地 | ⭐⭐⭐ |
| ZK | ✔ | ✔ | ZK | ⭐⭐⭐ |