先带大家简单快速了解一下前置知识:
一、核心要点(先记住这 5 个核心)
| 核心模块 | 作用 | 关键技术 / 工具 |
|---|---|---|
| 文档处理 | 把本地 txt/md 文件拆分成小文本块(避免过长),做清洗去重 | 正则清洗、固定长度拆分(带重叠) |
| 向量构建 | 把文本块转成机器能理解的向量,用 FAISS 存储(首次构建,后续复用) | M3E 嵌入模型、FAISS 向量库 |
| 语义检索 | 把用户问题转成向量,在 FAISS 里找最相似的文本块(按相似度阈值过滤) | 向量相似度计算、Top-K 召回 |
| 大模型调用 | 基于检索到的本地内容,调用智谱 GLM-4 生成回答(保证回答不脱离本地文档) | 智谱 API、提示词工程 |
| 交互逻辑 | 提供命令行交互入口,支持持续问答、退出等操作 | 循环输入、结果可视化 |
- 核心逻辑:本地文档→文本块→向量索引→语义检索→大模型回答,全程围绕 "基于本地内容回答" 展开;
- 技术核心:用 M3E 做文本嵌入、FAISS 做向量检索、GLM-4 做回答生成,纯 CPU 运行,无需 GPU;
- 使用关键:先把文档放到 docs 文件夹,替换有效的智谱 API Key,即可启动使用,输入问题就能检索本地内容并生成回答。
完整代码如下:
python
# 基础库
import os
import re
import json
import numpy as np
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from pathlib import Path
# 关闭警告
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 文本嵌入 + 向量检索
from sentence_transformers import SentenceTransformer
import faiss
# ========== 全局配置(按需修改) ==========
KNOWLEDGE_BASE_DIR = "docs" # 本地文档文件夹
M3E_MODEL_PATH = "moka-ai/m3e-base" # 文本嵌入模型
FAISS_INDEX_PATH = "./local_index.bin" # 向量索引文件
ZHIPU_CONFIG = {
"api_key": "记得替换成你的apikey,可以去官网申请~~~~",
"url": "https://open.bigmodel.cn/api/paas/v4/chat/completions"
}
# 检索配置
RETRIEVE_TOP_K = 3 # 召回最相关的3条内容
SIMILARITY_THRESHOLD = 0.7 # 相似度阈值(低于则不返回)
CHUNK_SIZE = 500 # 文档拆分长度(按字符)
CHUNK_OVERLAP = 50 # 拆分重叠长度(保证语义连贯)
# ========== 1. 自动加载并拆分本地文档 ==========
def load_and_split_documents(doc_dir: str) -> list:
"""
核心功能:
1. 遍历docs文件夹下所有txt/md文件
2. 按语义拆分成长度适中的文本块(避免过长/过短)
3. 返回干净的文本块列表(用于构建索引)
"""
all_chunks = []
doc_dir_path = Path(doc_dir)
# 检查文件夹
if not doc_dir_path.exists():
doc_dir_path.mkdir(parents=True, exist_ok=True)
print(f"✅ 创建文档文件夹:{doc_dir}")
return all_chunks
# 支持的文件类型
supported_ext = [".txt", ".md"]
files = [f for f in doc_dir_path.iterdir() if f.suffix.lower() in supported_ext and f.is_file()]
if not files:
print(f"⚠️ {doc_dir} 文件夹下无txt/md文件,请放入需要检索的文档")
return all_chunks
# 遍历所有文件
for file in files:
try:
# 读取文件内容
with open(file, "r", encoding="utf-8") as f:
content = f.read().strip()
# 清理无效字符
content = re.sub(r"\s+", " ", content) # 合并多余空格/换行
content = re.sub(r"[^\u4e00-\u9fff\w\s,。?!;:()【】《》]", "", content) # 保留中文+基本符号
# 按固定长度拆分(重叠部分保证语义连贯)
chunks = []
for i in range(0, len(content), CHUNK_SIZE - CHUNK_OVERLAP):
chunk = content[i:i + CHUNK_SIZE].strip()
if len(chunk) > 50: # 过滤过短的无效块
chunks.append(f"【{file.name}】{chunk}") # 标记来源文件
all_chunks.extend(chunks)
print(f"✅ 加载 {file.name}:拆分出 {len(chunks)} 个文本块")
except Exception as e:
print(f"❌ 加载 {file.name} 失败:{str(e)}")
# 去重
all_chunks = list(dict.fromkeys(all_chunks))
print(f"\n📚 本地文档加载完成:共 {len(all_chunks)} 个文本块")
return all_chunks
# ========== 2. 构建/加载向量索引 ==========
def build_or_load_index(doc_chunks: list) -> tuple[SentenceTransformer, faiss.Index]:
"""
核心功能:
1. 加载M3E嵌入模型
2. 为文本块生成向量,构建FAISS索引
3. 已存在索引则直接加载(首次构建,后续复用)
"""
# 加载模型
print("\n🔧 加载文本嵌入模型...")
model = SentenceTransformer(
M3E_MODEL_PATH,
trust_remote_code=True,
device="cpu" # 无需GPU,CPU足够
)
# 构建索引
if not doc_chunks:
print("⚠️ 无文本块,创建空索引")
index = faiss.IndexFlatIP(768) # M3E模型输出768维向量
return model, index
# 检查是否已有索引(避免重复构建)
if os.path.exists(FAISS_INDEX_PATH):
print("📌 加载已存在的向量索引...")
index = faiss.read_index(FAISS_INDEX_PATH)
return model, index
# 生成向量
print("🔨 生成文本向量(首次构建,稍等)...")
embeddings = model.encode(
doc_chunks,
normalize_embeddings=True, # 归一化,提升检索精度
show_progress_bar=False
)
embeddings = np.array(embeddings, dtype=np.float32)
# 创建索引并保存
index = faiss.IndexFlatIP(embeddings.shape[1])
index.add(embeddings)
faiss.write_index(index, FAISS_INDEX_PATH)
print(f"✅ 向量索引构建完成:共 {index.ntotal} 个向量")
return model, index
# ========== 3. 精准检索本地内容 ==========
def retrieve_local_content(query: str, model: SentenceTransformer, index: faiss.Index, doc_chunks: list) -> list:
"""
核心功能:
1. 生成查询向量
2. 检索相似度≥阈值的文本块
3. 返回去重后的相关内容
"""
if not query.strip() or not doc_chunks or index.ntotal == 0:
return []
# 生成查询向量
query_embedding = model.encode(
[query],
normalize_embeddings=True,
show_progress_bar=False
).astype(np.float32)
# 检索
distances, indices = index.search(query_embedding, RETRIEVE_TOP_K)
# 过滤结果(相似度≥阈值 + 去重)
relevant_chunks = []
seen = set()
for idx, score in zip(indices[0], distances[0]):
if score >= SIMILARITY_THRESHOLD and 0 <= idx < len(doc_chunks):
chunk = doc_chunks[idx]
if chunk not in seen:
seen.add(chunk)
relevant_chunks.append({
"content": chunk,
"similarity": round(score, 3)
})
return relevant_chunks
# ========== 4. 基于本地内容调用大模型回答 ==========
def answer_with_local_content(query: str, relevant_chunks: list) -> str:
"""
核心功能:
1. 有本地内容:基于内容生成回答(不编造)
2. 无本地内容:告知并返回通用回答
"""
# 配置请求重试(避免网络问题)
session = requests.Session()
retry_strategy = Retry(
total=2,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504]
)
session.mount("https://", HTTPAdapter(max_retries=retry_strategy))
# 构建提示词
if relevant_chunks:
# 拼接本地内容
context = "\n\n".join([f"【相似度:{c['similarity']}】{c['content']}" for c in relevant_chunks])
prompt = f"""请严格基于以下本地文档内容回答问题,不要添加任何文档外的信息:
本地参考内容:
{context}
用户问题:{query}
回答要求:
1. 只使用上述本地内容回答,不要编造;
2. 内容准确、简洁,符合问题要求;
3. 如果本地内容不足以回答,明确说明"本地内容未提及相关信息"。
"""
else:
prompt = f"""回答以下问题:
{query}
注意:本地文档中未检索到相关内容,此回答仅基于通用知识。"""
# 调用智谱API
payload = {
"model": "glm-4-plus",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.1, # 低温度保证准确
"max_tokens": 1500
}
headers = {
"Content-Type": "application/json; charset=utf-8",
"Authorization": f"Bearer {ZHIPU_CONFIG['api_key']}"
}
try:
response = session.post(
ZHIPU_CONFIG["url"],
headers=headers,
data=json.dumps(payload, ensure_ascii=False).encode("utf-8"),
timeout=60,
verify=False
)
response.raise_for_status()
result = response.json()
return result["choices"][0]["message"]["content"].strip()
except Exception as e:
error_msg = f"❌ 回答生成失败:{str(e)}"
if "401" in str(error_msg):
error_msg += "\n⚠️ 请检查API Key是否有效!"
return error_msg
# ========== 主函数(交互入口) ==========
def main():
print("=" * 80)
print("📖 本地文档检索问答系统")
print("=" * 80)
# 步骤1:加载并拆分本地文档
doc_chunks = load_and_split_documents(KNOWLEDGE_BASE_DIR)
# 步骤2:构建/加载向量索引
model, index = build_or_load_index(doc_chunks)
# 步骤3:交互问答
print("\n💡 系统就绪!输入问题即可检索本地文档(输入exit退出)")
print(" 示例:"界面新闻老板是谁?""道德经第一章内容?"\n")
while True:
query = input("请输入你的问题:")
if query.lower() == "exit":
print("\n👋 退出系统,再见!")
break
if not query.strip():
print("❌ 问题不能为空,请重新输入!\n")
continue
# 步骤4:检索本地内容
print("\n🔍 正在检索本地文档...")
relevant_chunks = retrieve_local_content(query, model, index, doc_chunks)
# 步骤5:显示检索结果
print("\n📚 本地检索结果:")
if relevant_chunks:
print(f"✅ 找到 {len(relevant_chunks)} 条相关内容:")
for i, chunk in enumerate(relevant_chunks, 1):
print(f" {i}. 相似度:{chunk['similarity']} | 内容:{chunk['content'][:100]}...")
else:
print("❌ 本地文档中未检索到相关内容")
# 步骤6:生成回答
print("\n🤖 正在生成回答...")
answer = answer_with_local_content(query, relevant_chunks)
# 步骤7:显示最终回答
print("\n" + "=" * 80)
print("💡 最终回答:")
print(answer)
print("=" * 80 + "\n")
if __name__ == "__main__":
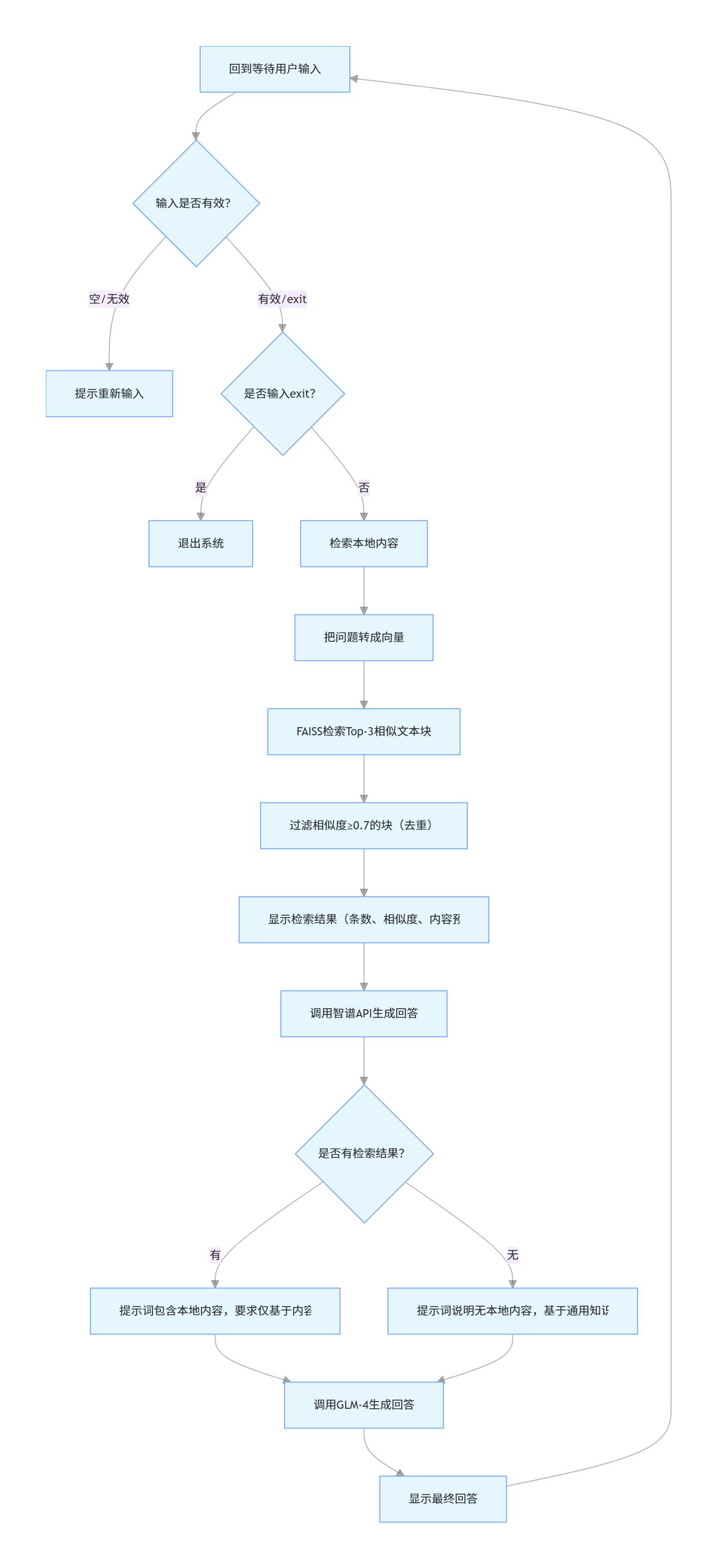
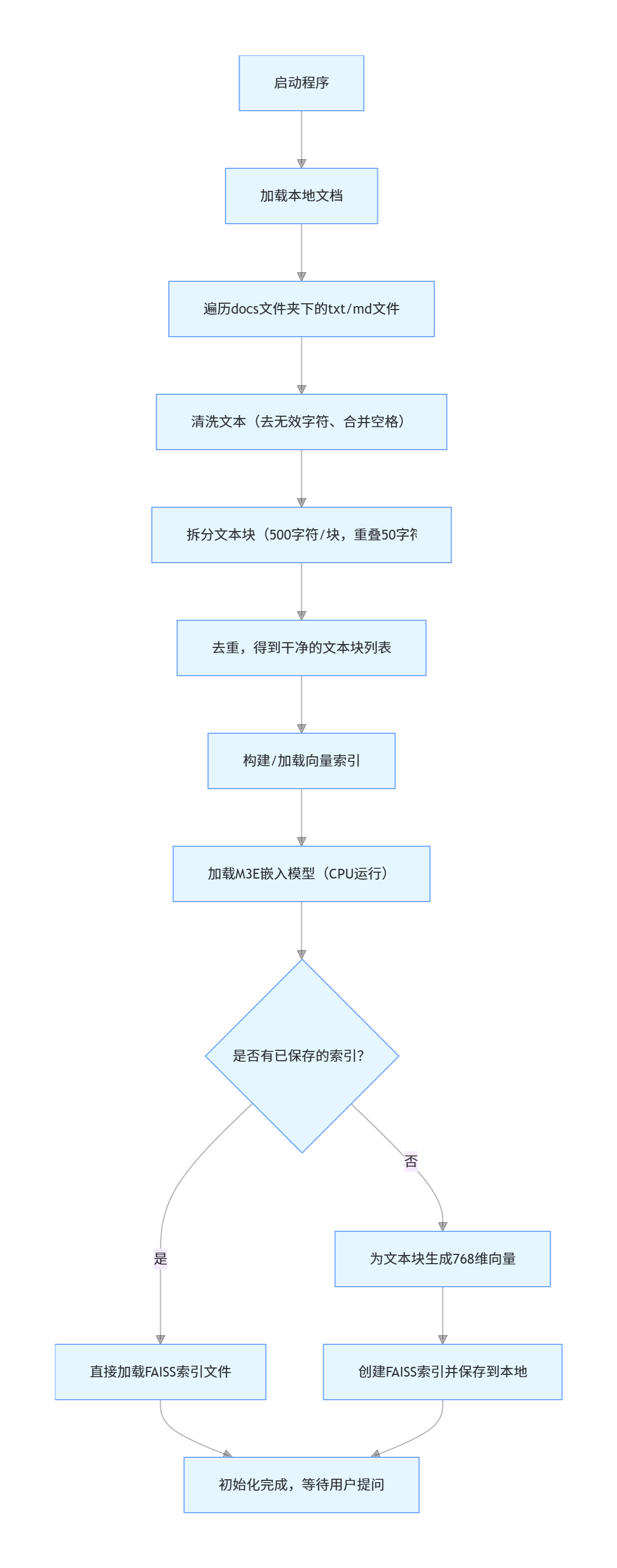
main()下面让豆包梳理了一下业务流程图(很清晰),供大家理解:
初始化(程序启动时执行,只做一次):
问答交互(用户输入问题后循环执行):