目录
前言
从编程入门到现在,我发现用不同软件打开同一文件时常会出现乱码问题,尤其是中文内容。究其原因,主要是各软件采用的文本编码格式不同所致。这种编码差异在文本处理中尤为常见,本文将系统梳理各类编码格式的特点。
什么是编码格式
简而言之,这是指内容的二进制存储形式。比如这篇文章,虽然我们看到的是中文,但在计算机中实际存储的是二进制代码。每个中文字符都对应特定的二进制编码,这些编码构成了文字的存储格式。计算机通过统一的编码解码标准,就能实现内容的存储与显示。
ASCII
最常用的编码格式,一般只要是能显示内容的芯片都支持该格式。
ASCII特点
- 7位二进制数表示(范围0-127即0x00-0x7F),常用1字节8位存储(最高位不用)
- 95个可打印字符(常见英文标点符号和大小写字母)
- 33个控制字符
- 可拓展为8位(非标准)
GBK
中文简体字符,较早的中文标准,解决ASCII只能存储英文的局限性。
GBK特点
- 英文1字节8位,中文2字节16位
- 汉字支持2万多字符(包括繁体字,生僻字)
- 可拓展,且支持部分日文假名、希腊字母等符号
- 完全兼容GB2312
UTF-8
可表示全球所有字符,txt文件默认编码方式,也是最常见的编码方式之一,但一些低级显示器不支持,仅至此ASCII,如果要显示其它内容需要使用字模软件。
UTF-8特点
- 1-4字节存储
- 可表示全球所有字符
- 完全兼容ASCII
- 兼容性好,空间效率高
因此我们优先推荐使用UTF-8表示,同时需要注意:确保文本存储(保存)与读取(打开)时使用相同的编码格式
对比
|-------|---------|-------------------|---------------------|
| 常见编码方式对比 ||||
| 编码 | 占用位数 | 表示内容 | 特点 |
| ASCII | 7bit/1B | 英文大小写、0~9、常见英文字符 | 默认7bit, 但常用1B 最高位为0 |
| GBK | 1~2B | 大部分汉字(包括生僻字和繁体字) | 可表示希腊字符等 |
| UTF-8 | 1~4B | 全球所有字符 | 兼容ASCII |
应用
解决乱码问题
当打开一个文档,出现乱码大概率就是文档的编码格式和软件的编码格式不一致,特别是同一份文件在某个软件打开正常却在另一个软件打开有乱码时,必然是编码格式问题。
解决此类问题,只需要更改软件打开文档的编码格式,一般途径:设置->工具->编码。可选用自动识别,或者手动更改成目标编码格式。
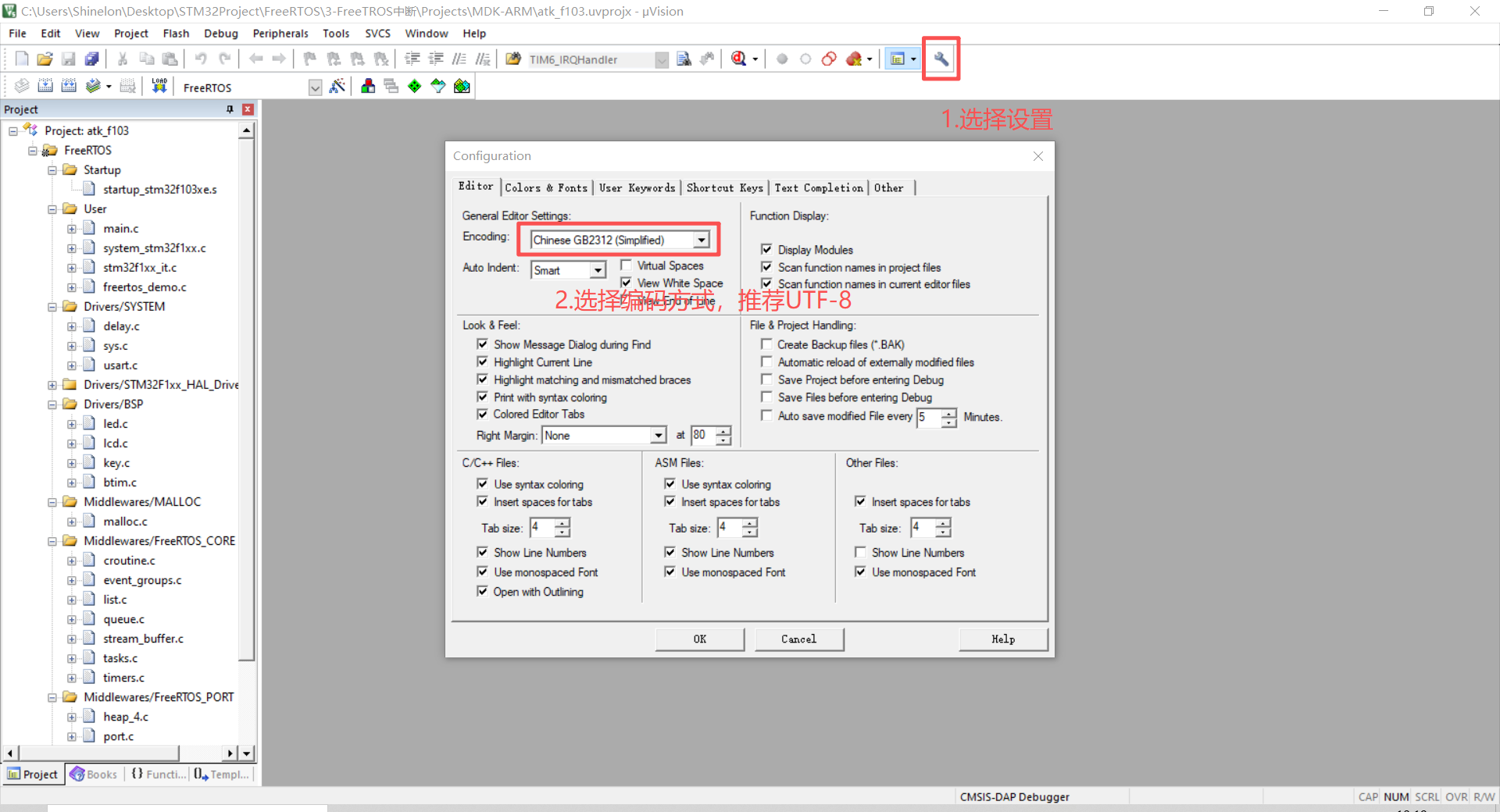
keli
- 点击右上角的设置
- 在Editor->Encoding选择合适的编码方式,与当前文档编码方式一致(推荐UTF-8)
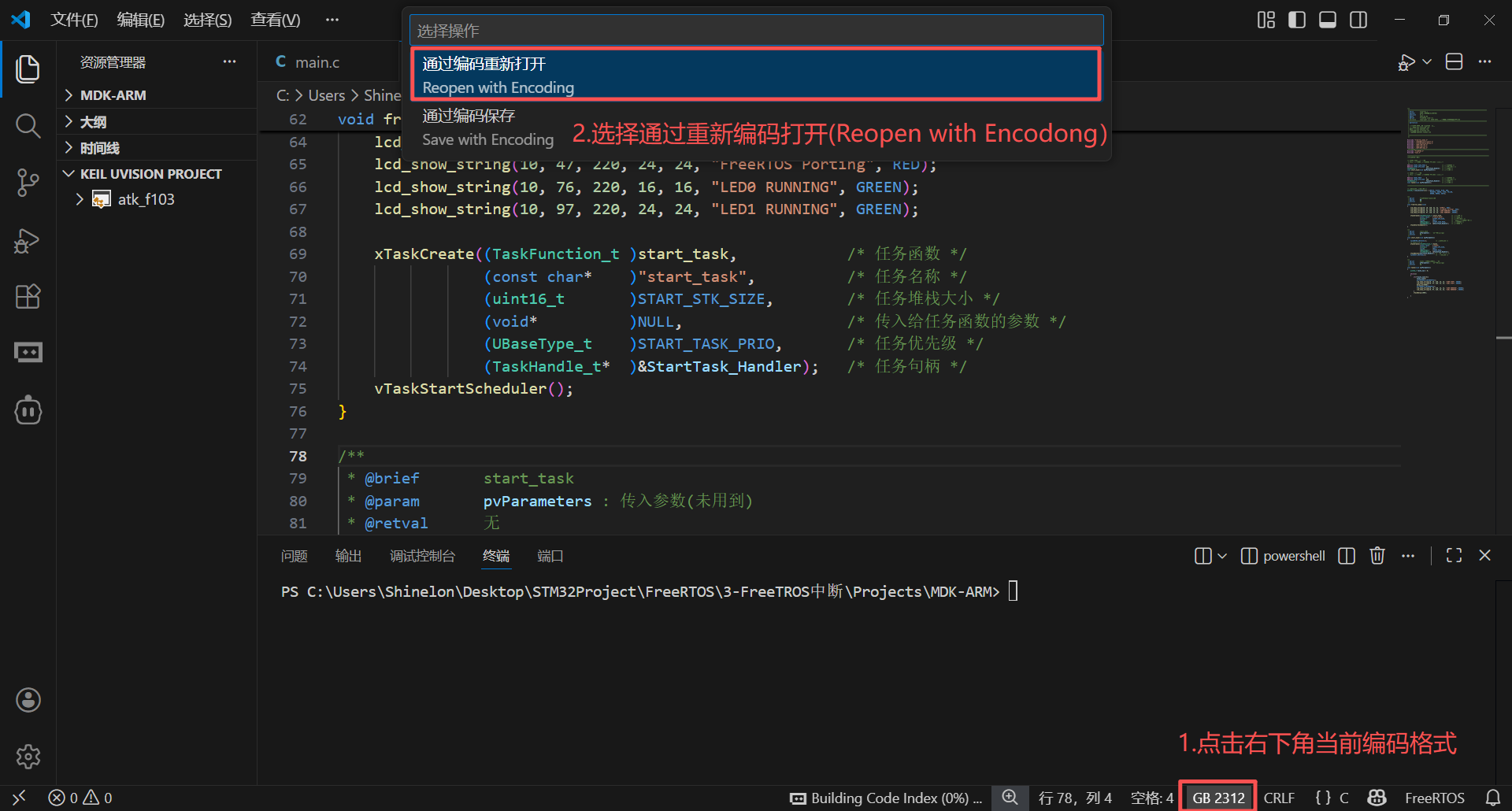
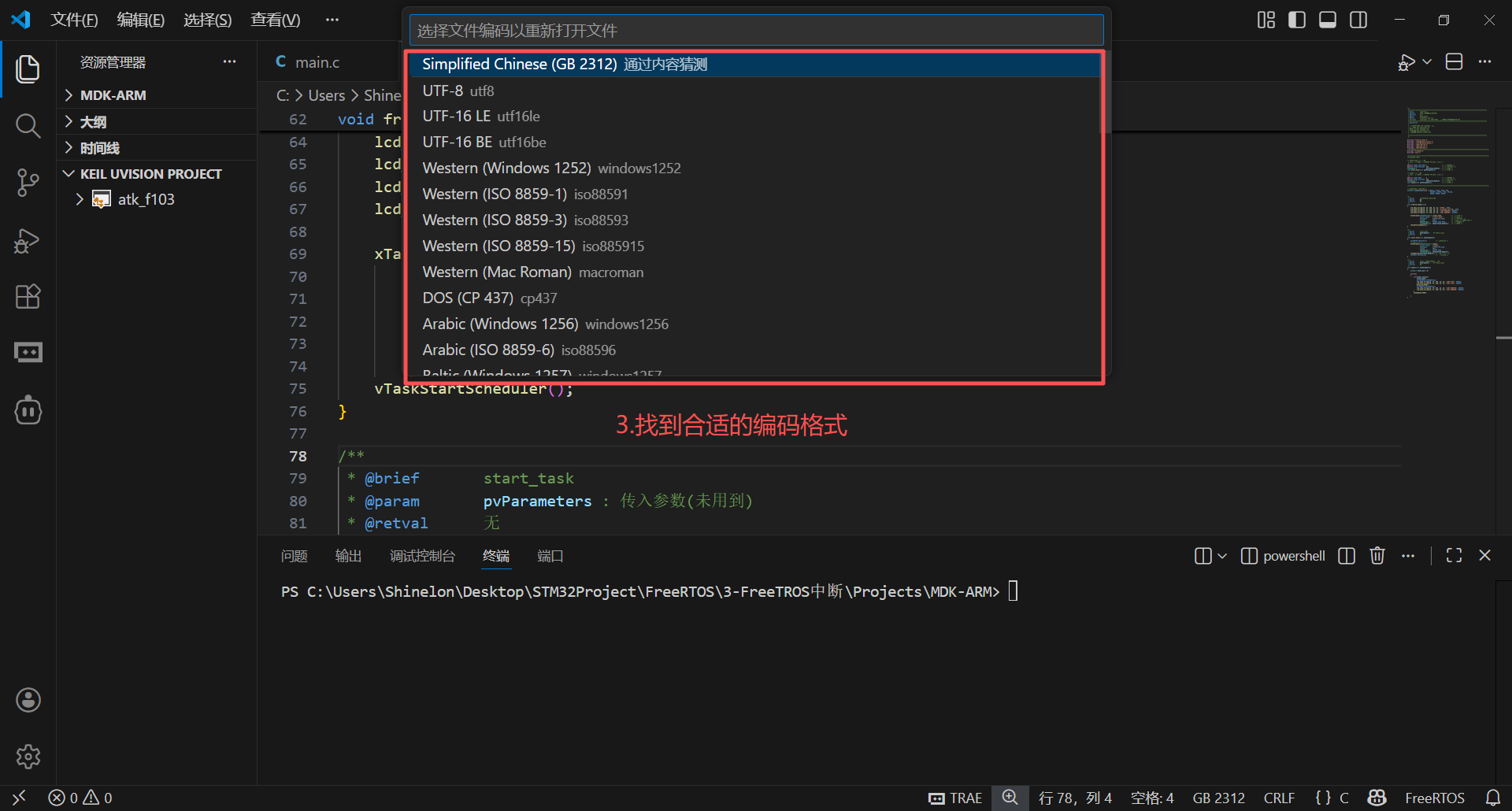
VSCode
- 在主页面点击左下角的当前编码格式(我的是GB2312,你们的可能不一样)
- 点击之后在搜索框中显示选项,选择重新编码打开(没汉化显示英文:Reopen With Encoding)
- 选择合适的编码格式,与文档格式保持一致(