在实际业务场景中,尤其是客服质检、语音风控等领域,单纯"听懂语音"远远不够,更重要的是听懂语音背后的意图 。因此,熙瑾会悟采用"语音转文字(ASR)+ 语义分析(NLP)"的组合技术路线,实现从原始语音到意图识别的完整闭环。
一、整体技术架构说明
系统整体分为四个核心模块:
先采集语音,就是用话筒之类的把声音录下来。接着靠ASR自动转文字,再读懂说话人的真实意图,最后判断内容有没有风险,没问题就输出结果,一步步衔接好。

二、语音转文字(ASR)技术实现
在语音正式进入识别模型之前,得先做一轮基础预处理,这些步骤看着不起眼,实则对最终识别准确率影响极大,尤其面对真实通话场景时,作用特别明显。首先是端点检测,简单说就是把长时间的静音部分去掉,避免做无用功、浪费计算资源。然后要处理噪声和回声,像电话录音、免提通话这类场景,背景噪音或回声都不少,这一步能有效过滤干扰。最后还要统一音频参数,比如都调成16kHz采样率、单声道,保证后续模型处理的一致性。
模型选型这块,选的都是成熟且能落地的主流方案,主要分两类。一类是CTC架构的模型,最大优势就是推理速度快,特别适合需要实时识别的场景,常见的像DeepSpeech、Wav2Vec2-CTC都属于这类。另一类是基于Transformer的ASR模型,比如Whisper,它在应对口音差异、复杂噪声还有非标准表达时,适应性更强,容错率更高,很适合离线分析或者对准确性要求高、需要复核的高风险语音场景。
实际部署的时候,采用了"双通道策略"来兼顾效率和准确率。如果是实时通话场景,就优先用CTC模型,确保响应够快,不耽误沟通;要是处理已有的录音文件,就用Whisper模型兜底,把识别精度拉满。这样根据不同场景灵活切换,既能满足实时需求,又能保证关键场景的识别质量,算是比较实用的落地方式。
三、语义分析与意图识别
其实ASR转写出来的文字,只是第一步,算不上最终结果。真正要挖的价值,是透过这些文字,搞懂背后藏着的真实意思------也就是语义层面的理解。
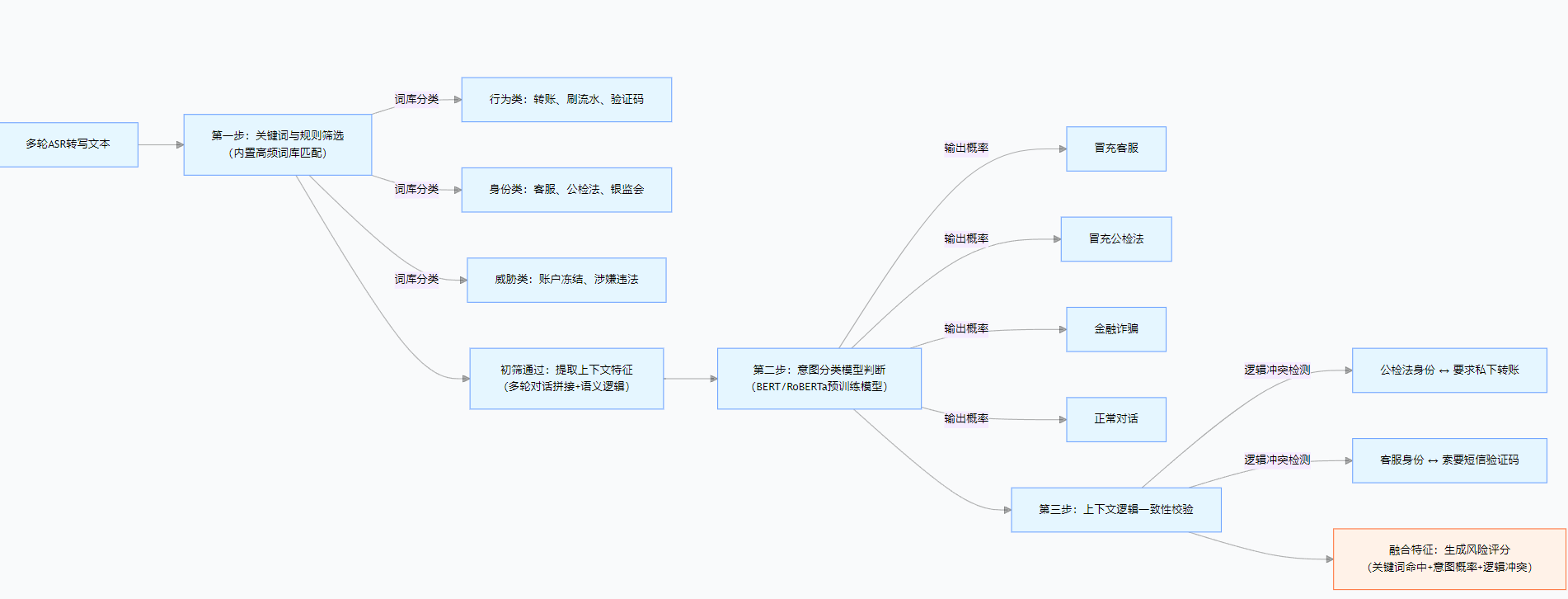
首先是第一道筛选关,靠关键词和固定规则来判断。系统里早就存好了一整套常用的高频词库,分了好几类。比如行为上的,像"转账""刷流水""验证码";身份相关的,比如"客服""公检法""银监会";还有用来威胁人的,像"账户冻结""涉嫌违法"这些。只要文本里命中了这些词,再结合设定好的组合规则,就能快速把那些一眼就有高风险的话筛出来,大大提高整体处理速度。
过了初筛的内容,就会进入核心环节------意图分类判断。这一步靠的是基于BERT、RoBERTa这类预训练模型搭建的识别系统,输入的就是ASR转写好的文字,还能把多轮对话的内容拼起来一起分析。最终会给出几种结果的概率,比如是冒充客服、冒充公检法,还是正常对话。
这里要注意,模型不只是盯着单个关键词,更看重上下文的表达逻辑。就像有人说"我这边是派出所的,你这个案子比较紧急,需要你配合转账核查",这话里没一个"诈骗"字眼,但模型能察觉到不对劲,精准识别出异常意图。
另外,遇到多轮对话时,系统还会简单核对逻辑是否通顺。比如有人自称是公检法,却让私下转账;或是说自己是客服,反而要短信验证码。这种明显的逻辑矛盾,会当成额外的风险信号,助力最终的判断。
图片说明
1.流程起点: 以多轮ASR转写文本为输入,对应实际场景中语音转写后的对话内容。
2.第一道筛选关: 通过三大类高频词库进行匹配,快速过滤明显高风险语句,提升处理效率。
3.上下文特征提取: 对初筛通过的文本,拼接多轮对话内容,挖掘语义层面的核心特征。
4.核心意图判断: 基于 BERT/RoBERTa 模型输出四类结果的概率,重点关注上下文逻辑而非单一关键词。
5.逻辑一致性校验: 检测对话中的矛盾点(如身份与行为不匹配),作为额外风险特征。
**6.最终输出:**融合所有特征生成风险评分,完成意图识别。
四、结果输出与工程落地
等前面所有环节都处理完,系统会把几项关键结果整合到一起做综合判断。包括ASR转写的置信度,也就是转写内容准不准;有没有命中咱们之前说的关键词、命中了多少;意图分类模型给出的各类概率;还有上下文逻辑校验后的评分。
整合完这些信息,不会输出一堆杂乱的数据,而是统一转换成清晰的风险等级,或者直接打上对应的标签,这样后续对接系统的时候就特别方便。
比如能直接连到实时预警系统,一旦检测出高风险,马上就能发出提醒;另外还能接入客服质检系统,帮着排查客服对接过程中遇到的可疑对话。
而且这套方案是模块化设计的,ASR语音转写和NLP语义分析这两部分能各自独立升级、扩展,不用受整体系统的限制。不管企业或者单位已经有了现成的语音平台,都能快速对接上落地使用,不用大动干戈改造原有系统,实用性和灵活性都挺强。