在计算机网络面试和后端开发中,TCP 协议不仅是传输层的基础,更是高频考点。本文将从 TCP 的五层模型定位出发,详细解析其如何通过复杂的机制保证可靠传输,并探讨由此引出的"粘包/拆包"问题及其解决方案。
一、 网络分层模型
首先明确 TCP 在网络体系中的位置(五层模型):
-
应用层:直接为用户程序服务。
- 典型协议:FTP、HTTP、WebSocket、Protobuf。
-
传输层:负责端到端的数据传输。
- 核心协议 :TCP (可靠)、UDP(不可靠)。
-
网络层:负责数据的路由和寻址。
- 核心协议:IP。
-
数据链路层:处理链路上的帧传输。
-
物理层:传输比特流。
二、 TCP 如何保证可靠性?
TCP(传输控制协议)通过以下五大核心机制,确保数据"不丢、不乱、不错"。
1. 序列号与确认机制 (Sequence & ACK)
-
序列号 (Seq) :TCP 将发送的每个字节都分配一个唯一的序列号,用于标识数据的顺序,解决乱序问题。
-
确认号 (Ack):接收方通过 ACK 告知发送方"我已经收到了哪些数据"。
- 机制 :如果接收方收到序列号
1-1000的数据,它会回复ACK = 1001,表示期望接收的下一个字节序列号是 1001。
- 机制 :如果接收方收到序列号
2. 超时重传机制
- 如果发送方在规定时间内没有收到接收方的 ACK,会认为数据包丢失,从而触发重传,确保数据最终到达。
3. 连接管理
-
通过 三次握手 确保连接的可靠建立(同步初始序列号)。
-
通过 四次挥手 确保连接的可靠关闭(双方均释放资源)。
4. 流量控制 (Flow Control)
-
目的 :防止发送方 发太快,把接收方的缓冲区撑爆。
-
实现 :通过 TCP 头部的 窗口大小 (Window Size) 字段。接收方实时告知自己缓冲区的剩余空间,发送方据此调整发送速率。
5. 拥塞控制 (Congestion Control)
-
目的 :防止过多的数据注入网络,导致网络链路拥塞。
-
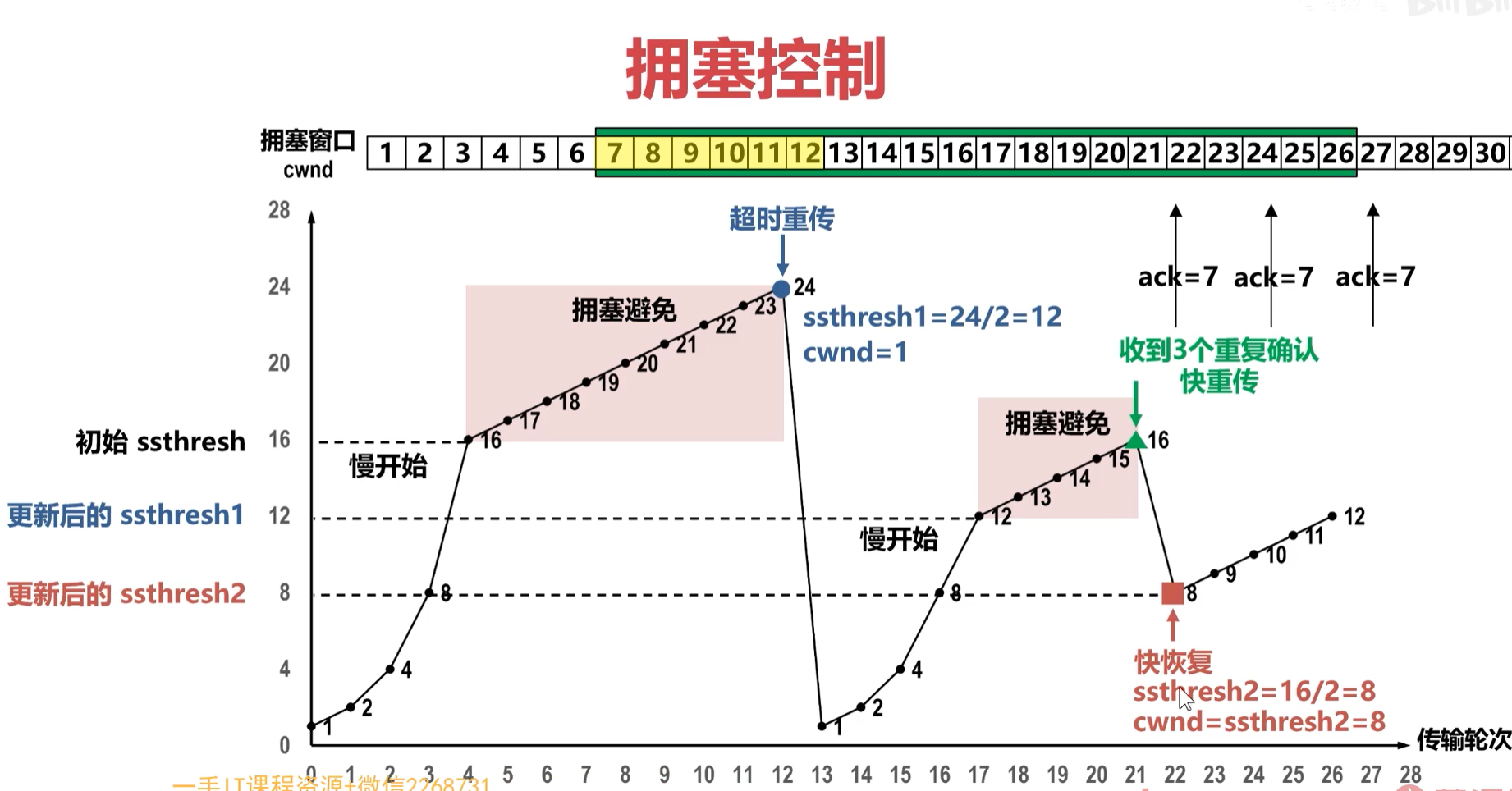
过程详解:
-
慢开始(指的是开始的起点比较小):拥塞窗口初始为 1。每经过一个 RTT(往返时间),窗口大小 x2(指数增长)。
-
拥塞避免:当达到"慢启动门限"后,改为线性增长(每经过一个 RTT,窗口 +1)。
-
拥塞发生(丢包处理):
-
情况 A 轻微拥塞(快速重传/快速恢复) :如果发送方连续收到 3个重复 ACK。
-
判断网络轻微拥塞,不等待超时,直接重传丢失的包。
-
调整:拥塞窗口减半 (÷2),然后进入拥塞避免(线性增长)。
-
-
情况 B 严重拥塞(超时重传):如果迟迟没收到 ACK,触发超时。
-
判断网络严重拥塞。
-
调整:拥塞窗口重置为 1,重新进入慢启动(指数增长)。
-
-
-
发送窗口的大小 = min(拥塞窗口,接收窗口)
三、 TCP 的"副作用":粘包与拆包(半包)
由于 TCP 是面向字节流的协议,它不像 UDP 那样有天然的消息边界,这导致了应用层在读取数据时会出现特殊现象。
1. 问题定义
-
粘包:接收方一次读取到了多个数据包连在一起。
- 原因:发送方为了减少网络开销(Nagle 算法),将多个小包合并发送;或接收方处理不及时,缓冲区积压了多个包。
-
拆包:一个完整的数据包被拆成了多段。
- 原因:数据包超过了最大报文长度 (MSS),发送方必须拆分发送。
2. 本质原因
-
TCP:面向字节流,无消息边界。
-
UDP:面向数据报,每个数据报独立且有边界(因此 UDP 没有粘包拆包问题)。
-
结论 :无论是粘包还是拆包,根源在于应用层协议未正确处理消息边界,而非 TCP 本身的缺陷。
四、 解决方案
简单来说就是(定长,\n,头部标识)。
应用层必须自行设计协议来"切分"消息。常见的有三种方案:
1. 定长方案 (Fixed Length)
-
原理:发送方和接收方约定每个包固定长度(如 1024 字节)。
-
发送方:不足 1024 字节用特定字符补齐(Padding)。
-
接收方:每次只读 1024 字节。
-
-
优缺点:实现简单,但无法处理动态数据,且浪费带宽(补齐的字符无意义)。
2. 分隔符方案 (Delimiter)
-
原理 :在数据包末尾添加特殊字符(如
\r\n)。- 接收方:读到分隔符就切分出一个包。
-
应用案例:FTP 协议。
-
缺点:若数据内容本身包含分隔符,需要转义处理。
3. TLV 方案 (Type-Length-Value) ------ 最推荐
-
原理 :将消息结构化为
[类型][长度][内容]。-
Type:标识报文类型。
-
Length :关键字段,明确告知接收方后面的 Value 有多少个字节。
-
Value:实际数据。
-
-
流程 : 即数据流是:
[T1][L1][V1][T2][L2][V2]接收方先读头部获取L1,根据长度读取V1,读完后自然就知道V1结束了,后面紧接着就是T2。 -
应用案例:
-
HTTP 1.1 的
Content-Length头。 -
Protobuf。
-
WebSocket。
-