UR-Bench: A Benchmark for Multi-Hop Reasoning over Ultra-High-Resolution Images
Authors: Siqi Li, Xinyu Cai, Jianbiao Mei, Nianchen Deng, Pinlong Cai, Licheng Wen, Yufan Shen, Xuemeng Yang, Botian Shi, Yong Liu
Deep-Dive Summary:
UR-Bench: 超高分辨率图像上的多跳推理基准
Siqi Li (^{1,2}) Xinyu Cai (^{2,\dagger}) Jianbiao Mei (^{1,2}) Nianchen Deng (^{2}) Pinlong Cai (^{2}) Licheng Wen (^{2}) Yufan Shen (^{2}) Xuemeng Yang (^{2}) Botian Shi (^{2,*}) Yong Liu ({1,\dagger})({1}) 浙江大学 (^{2}) 上海人工智能实验室
摘要
最近的多模态大型语言模型(MLLMs)在视觉-语言推理方面展现出强大能力,但它们在超高分辨率图像上的表现仍未被充分探索。现有视觉问答(VQA)基准通常依赖中等分辨率数据,视觉复杂度有限。为弥补这一差距,我们引入了超高分辨率推理基准(UR-Bench),旨在评估 MLLMs 在极端视觉信息下的推理能力。UR-Bench 包含两大类别------人文场景和自然场景------涵盖了四种具有独特空间结构和数据来源的超高分辨率图像子集。每个子集中的图像分辨率从数亿像素到十亿像素不等,并配有三级难度的问题,从而能够评估模型在超高分辨率场景中的推理能力。我们进一步提出了一个基于代理的框架,其中语言模型通过调用外部视觉工具来执行推理。此外,我们引入了语义抽象和检索工具,以更有效地处理超高分辨率图像。我们使用端到端 MLLMs 和我们基于代理的框架评估了最先进的模型,证明了我们框架的有效性。
1. 引言
多模态大型语言模型(MLLMs)的最新进展在各种多模态任务中,包括视觉问答(VQA)和推理 5, 21, 24,展现了卓越的性能。然而,尽管取得了这些成功,人们对开发"图像思维"模型 7, 9, 11, 18, 19 的兴趣日益增长,这些模型旨在增强模型显式地对视觉内容进行推理的能力。具体来说,这些方法通常采用代理式范式,其中模型充当中央控制器,可以根据需要调用外部工具,从而实现更灵活和模块化的多模态推理。
尽管取得了这些进展,现有 VQA 基准在视觉复杂性方面仍然受限 3, 13, 14, 17。
尽管一些数据集,如 V*Bench 23 和 HR-Bench 20,声称包含高分辨率图像,但它们通常依赖于中等分辨率数据,其空间尺度和场景密度远低于真实世界的超高分辨率图像。为了全面评估 MLLMs 和"图像思维"方法的能力,并推动多模态推理的界限,我们提出了超高分辨率推理基准(UR-Bench),一个专为超高分辨率图像上的多跳推理量身定制的基准。
UR-Bench 由两大类别和四个超高分辨率图像子集组成,每个子集都由独特的空间结构和数据源定义,如图1所示。人文场景类别包含大规模的中国古代卷轴画,包括叙事卷轴和人物卷轴。自然场景类别涵盖了来自卫星图像和街景图像的广阔景观图像。在所有子集中,图像都异常巨大------通常达到数亿像素或数百兆字节------并展现出丰富的视觉和空间细节,对视觉理解和推理构成了巨大挑战。为了进一步区分推理复杂性,问题被分为三个级别,对应于对空间整合和多步推理日益增长的需求。
UR-Bench 对端到端 MLLMs 提出了重大挑战。直接处理如此巨大的图像通常会超出大多数模型的令牌容量,而简单的压缩或降采样会导致信息丢失和推理性能下降。此外,现有的基于代理的框架,如 OpenThinkIMG 18,难以处理如此超高分辨率的图像。为了克服这些限制,我们提出了一个基于代理的框架,用于超高分辨率图像上的多跳推理。在此框架中,代理本身是一个大型
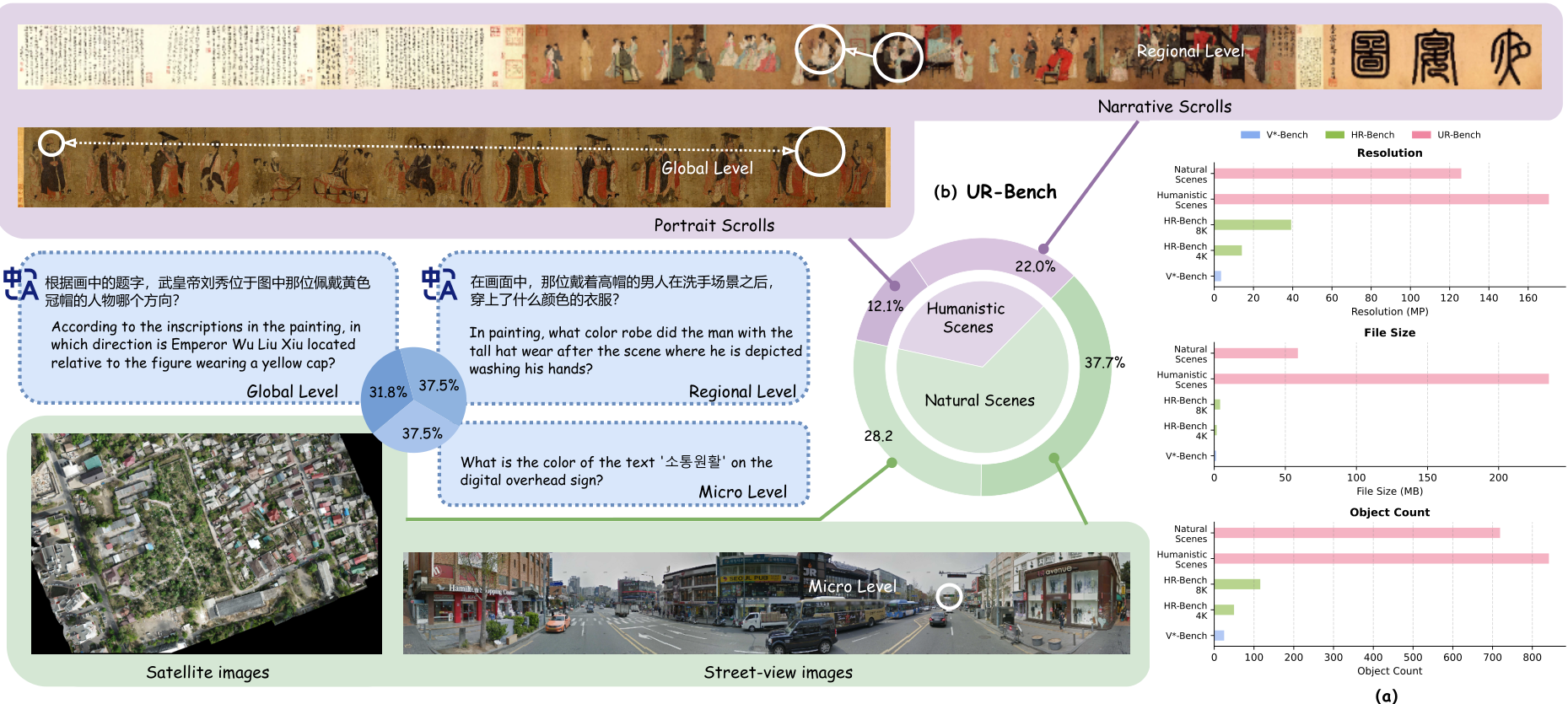
图 1. (a) 高分辨率图像基准的平均分辨率(MP)、文件大小(MB)和对象计数。(b) UR-Bench 的两大类别和四个子集,任务按三个难度级别组织。
语言模型(LLM),它纯粹通过语言与多模态环境交互。它自主规划操作序列并调用专门的视觉工具,以模块化、灵活的方式执行感知和推理任务。与现有代理框架不同,我们的方法包含一个语义抽象和检索工具,该工具在推理过程中将复杂的大规模视觉信息映射到语言空间。这使得能够更有效地处理超高分辨率输入图像并促进多跳推理任务的解决。图 3 展示了此过程的示例。
我们的主要贡献总结如下:
- 我们引入了 UR-Bench,一个用于超高分辨率多跳推理的基准,其中单个图像文件大小从几兆字节到超过 1 GB 不等,并具有高信息密度。该基准包含三个推理复杂度级别,可以在极端视觉条件下进行细粒度评估。
- 我们提出了一种自动化数据引擎,用于生成超高分辨率图像上的多跳推理问题,能够自动生成不同推理难度级别的问题。
- 我们提出了一个基于代理的框架,使 LLMs 能够自主规划和协调基于工具的操作。该框架强调通过语义抽象和检索工具对超大规模视觉信息进行语义分解,从而实现对超高分辨率图像的有效感知和推理。
2. 相关工作
2.1. 视觉问答基准
已经开发了广泛的视觉问答(VQA)基准,以评估模型在不同视觉和语言环境下的多模态推理能力。ChartQA 12 及相关数据集评估图表中结构化信息的理解。TextVQA 17 强调对场景文本的阅读和推理。DocVQA 13 将此范式扩展到涉及布局感知和多跳推理的文档图像。CharXiv 22 探索学术图表和多页文档,测试细粒度的跨模态推理。然而,它们很少探究 MLLMs 的视觉极限,因为它们的图像仍然较小、简单且信息密度低,对模型在复杂、信息丰富场景中的性能提供有限的见解。为了解决这些限制,新一代高分辨率(HR)和专用基准已被引入,旨在更好地评估细粒度感知和推理------例如 V*Bench 23 和 HR-Bench 20。然而,这些基准的空间尺度和场景复杂性仍然远低于真实世界超高分辨率场景中遇到的情况。
2.2. 图像思维
多模态推理的最新进展强调了"图像思维",其中推理明确地以视觉表示为基础。值得注意的方法包括 Open-ThinkIMG 18,它利用视觉工具强化学习进行图像基础推理;Imagine 9,它在空间布局中可视化中间推理步骤;TACO 11,它通过合成思维-行动链学习多模态行动模型;以及 VisProg 7,它将视觉规划与符号推理相结合。这些工作共同将多模态模型从被动感知转向主动的图像基础推理。然而,它们主要在标准尺寸图像上操作,无法处理涉及超高分辨率图像的 VQA 任务。
3. 基准
3.1. 子集和数据源
UR-Bench 由两大类别和四个子集组成,每个子集都具有独特的空间特征和数据来源的超高分辨率图像,如图1所示。
- 人文场景 此子集包含从维基百科收集的大型中国古代卷轴画。平均分辨率为 48 , 685 × 2 , 821 48,685 \times 2,821 48,685×2,821 像素( ∼ 171 MP \sim 171 \text{MP} ∼171MP),最高分辨率达到 718 MP。它包括两大类别:
- 叙事卷轴 通常以连续的故事叙述或跨多个空间的过渡为特色,描绘城市生活、宫廷活动和神话故事等场景。
- 人物卷轴 通常由一系列独立的形象(或动物)组成,每部分描绘一个独特的主题或图案,作为一个整体按顺序排列。
- 自然场景 此子集结合了大型自然和城市景观图像。图像平均大小为 19 , 443 × 7 , 557 19,443 \times 7,557 19,443×7,557 像素( ∼ 125.95 MP \sim 125.95 \text{MP} ∼125.95MP),最大文件大小达到 432.29 MB 432.29 \text{MB} 432.29MB。
- 卫星图像 源自 SUNet 数据集 16,其中包含城市区域和地形的各种航拍视图。
- 街景图像 通过 Google 街景静态 API 获取,覆盖全球约 90 条繁忙街道,包含丰富的视觉信息。
表 1. 高分辨率图像基准的比较。
| Benchmark | Multilingual | Multi-source | Difficulty Grading |
|---|---|---|---|
| VSTAR-Bench 23 | × | × | × |
| HR-Bench 20 | × | × | × |
| UR-Bench (Ours) | ✓ | ✓ | ✓ |
在所有子集中,UR-Bench 展现出始终如一的超大规模,单个图像文件大小从几兆字节到超过 1 GB 不等。如此巨大的分辨率对基于补丁的推理和多区域视觉理解构成了重大挑战。我们将我们基准中的图像大小与现有高分辨率基准(包括 V*Bench 23 和 HR-Bench 20)中的图像大小进行比较,如图 1 (a) 所示。我们基准中的图像明显大于其他基准中的图像。
除了视觉规模,我们通过引入对象计数指标进一步量化每个数据集的语义丰富性。具体来说,我们采用 GroundingDINO 10 零样本对象检测模型来识别和定位每张图像中所有可检测实体。图 1 (a) 中报告的平均和最大对象计数值反映了每张图像中存在的不同对象实例的数量,这可作为语义密度和视觉混乱的指标。UR-Bench 展现出明显更高的对象计数,表明其视觉环境更复杂且信息更密集。
除了包含多样化的数据源,UR-Bench 还包括多语言问题,并根据难度级别进行分类。表 1 展示了与其他高分辨率基准的比较。
3.2. 任务分类
此外,我们根据所需的推理过程和空间依赖性将基准中的所有问题分为三类:
- 微观级别(Micro Level)。答案可以从图像的单个区域得出,无需跨区域关联或多步推理。尽管不需要复杂的推理,但在超高分辨率图像中定位正确区域仍然具有挑战性,因为空间尺度巨大且相关内容稀疏,使这种类型类似于"大海捞针"式的搜索。
- 区域级别(Regional Level)。这种类型的问题建立在微观级别之上,需要 2-3 个增量视觉推理步骤,才能根据对相邻区域的观察得出答案。它的特点是空间上连续的视觉线索,必须按顺序处理。
- 全局级别(Global Level)。问题涉及整合来自图像中两个或更多遥远、不相邻区域的信息。推理通常依赖于区域间的空间关系或位置比较,反映了更高水平的推理复杂性。
3.3. 数据引擎
UR-Bench 通过一个分层管道构建,该管道集成了图像分区、多模态问答生成、推理级别组合、自动过滤和人工校准,如图 2 所示。
我们首先将每个超高分辨率图像分成多个不重叠的图块,以在视觉-语言模型(VLMs)的输入限制内实现有效处理。然后将每个图块输入 Gemini-2.5-Flash 5,它生成 0-2 个问答(QA)对,描述细粒度的视觉细节,如对象和属性。
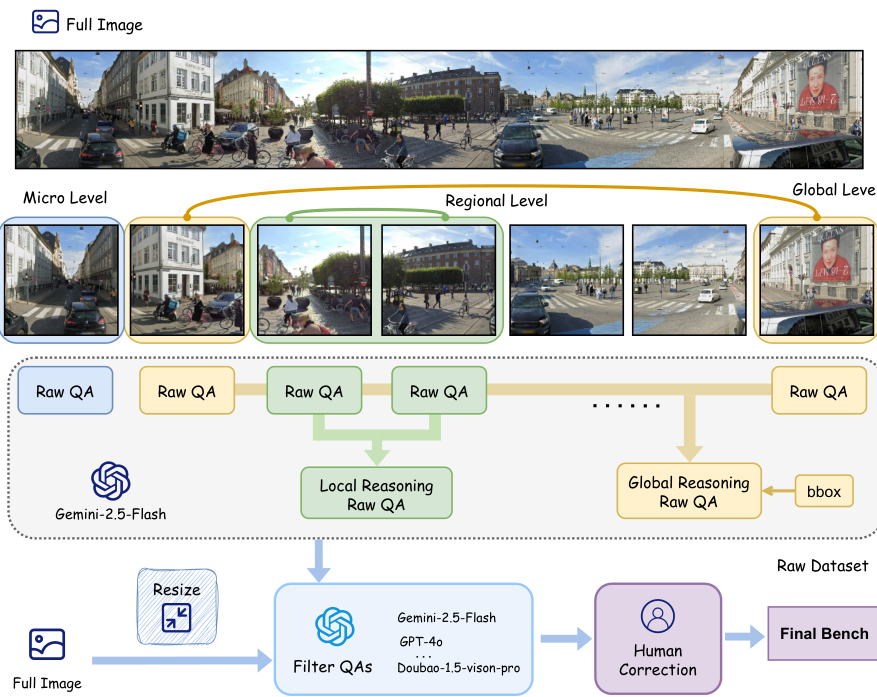
图 2. 数据构建流程概述。
对于区域级别和全局级别问题,为了超越纯粹的局部感知,我们通过联合输入每个图像块、其对应的问答对以及该块在原始图像中的边界框到 Gemini-2.5-Flash 中,构建了更高层次的推理问题。这种设计明确地为模型提供了每个区域的视觉内容及其在整体场景中的空间位置,从而能够生成需要整合多个区域信息或将局部证据与全局上下文关联的局部推理和全局推理问答。
随后,我们使用 MLLMs(例如 GPT-4o)自动过滤生成的原始数据集,以去除过于简单或质量低下的问题。在此阶段,压缩后的图像(大小适合端到端推理)及其对应的问答对会联合输入到大型模型中。最后,人类专家手动验证并完善剩余的问答对,从而得到最终的基准数据集。
4. 方法
UR-Bench 中的超高分辨率图像对端到端推理提出了巨大挑战,因为大多数开源和闭源 MLLMs 的令牌容量有限。直接将如此庞大的图像输入 MLLMs 通常会超出其输入限制,而简单的降采样或压缩不可避免地会导致严重的信息丢失,从而损害感知和推理质量。此外,现有的基于代理的框架,如 OpenThinkIMG 18,也无法很好地处理此类数据,因为它们的决策模型依赖于 VLMs,并且其可用工具缺乏处理如此大规模图像的能力。
表 2. 工具集概览。此表介绍了我们的工具集,详细说明了它们的输入要求和输出格式。
| Tool | Input | Output |
|---|---|---|
| Semantic Abstraction | image + chunk number | json |
| Semantic Retrieval | json + query + topk | top-k retrieved texts |
| VLM | image + prompt | text answer |
| Crop | image + bbox coordinates | cropped image |
| Ground | image + keyword | bbox coordinates |
| Enhance | image + brightness + contrast + sharpness + color | enhanced image |
为了克服这些限制,我们提出了一种基于代理的框架,专为超高分辨率图像上的多跳推理而设计。与其他基于代理的框架不同,我们的决策模型是纯粹基于语言的模型,不直接将图像作为输入;相反,它通过调用一套专门的工具逐步探索和解释复杂的视觉场景。代理利用工具和推理的过程如图 3 所示。
我们的工具集包括两类工具:语义抽象和检索工具以及视觉工具,它们的输入和输出格式总结在表 2 中。
4.1. 语义抽象和检索。
现有视觉检索增强生成(V-RAG)方法 25 在处理超高分辨率图像时面临重大挑战。原始视觉令牌无法直接用于文本检索,因为它们缺乏适用于相似度匹配的紧凑、语义有意义的表示。直接嵌入所有像素会迅速超出模型令牌限制,密集补丁级嵌入会带来沉重的计算和内存成本,而简单的调整大小或平铺通常会丢弃细粒度的语义细节。
为了解决这些限制,我们引入了语义抽象和检索工具,该工具在我们的代理框架中实现了语义级探索,将视觉信息转换为可有效检索的基于语言的表示。
4.1.1. 语义抽象
语义抽象工具首先将超高分辨率输入图像 I I I 分割成由 LLM 代理确定的 N N N 个视觉块 C = { c i } C = \{c_{i}\} C={ci}。
图像被分割成 N N N 个视觉块 C = { c 1 , c 2 , ... , c N } C = \{c_{1},c_{2},\ldots ,c_{N}\} C={c1,c2,...,cN},使得:
I = ⋃ i = 1 N c i ( 1 ) I = \bigcup_{i = 1}^{N}c_{i} \quad (1) I=i=1⋃Nci(1)
每个块 c i c_{i} ci 使用 Qwen2.5-VL-7B 模型 2 转换为语义丰富的描述 ((L_{i})),将视觉数据映射到语言空间 L = { L 1 , L 2 , ... , L N } L = \{L_{1},L_{2},\ldots ,L_{N}\} L={L1,L2,...,LN}。我们表示此转换前后的等效令牌计数为 T r a w ( I ) T_{\mathrm{raw}}(I) Traw(I) 和 T l a n g ( L ) T_{\mathrm{lang}}(L) Tlang(L),最大模型容量为 T m a x T_{\mathrm{max}} Tmax。
由于超高分辨率图像的尺寸限制,原始令牌需求远远超过模型容量 ((T_{\mathrm{raw}}(I) \gg T_{\mathrm{max}})),使得直接处理不可行。然而,生成的语言表示是紧凑的:
T l a n g ( L ) ≪ T r a w ( I ) , T l a n g ( L i ) ≤ T m a x ( 2 ) T_{\mathrm{lang}}(L) \ll T_{\mathrm{raw}}(I), \qquad T_{\mathrm{lang}}(L_i) \leq T_{\mathrm{max}} \quad (2) Tlang(L)≪Traw(I),Tlang(Li)≤Tmax(2)
此过程执行语义抽象,显著减小了表示规模,同时保留了必要的语义信息,从而促进后续基于文本的检索。通过语义抽象工具,代理获取一个 JSON 文件,其中包含一组配对表示 ((c_i, L_i)),其中 i = 1 , ... , N i = 1, \ldots , N i=1,...,N。
4.1.2. 语义检索
给定文本查询 Q Q Q,语义检索工具采用 BGE-M3 嵌入模型 4 在预生成的描述集 L = { L 1 , L 2 , ... , L N } L = \{L_1, L_2, \ldots , L_N\} L={L1,L2,...,LN} 中执行语义相似度匹配。查询和单个描述都首先被编码成嵌入向量, e Q \mathbf{e}Q eQ 和 e L i \mathbf{e}{L_i} eLi。
查询和描述之间的语义相似度使用余弦相似度度量量化:
S ( Q , L i ) = e Q ⋅ e L i ∥ e Q ∥ 2 ⋅ ∥ e L i ∥ 2 . ( 3 ) S(Q,L_{i}) = \frac{\mathbf{e}{Q}\cdot\mathbf{e}{L_{i}}}{\|\mathbf{e}{Q}\|{2}\cdot\|\mathbf{e}{L{i}}\|_{2}}. \quad (3) S(Q,Li)=∥eQ∥2⋅∥eLi∥2eQ⋅eLi.(3)
然后,该工具根据计算出的相似度分数识别并选择最相关的 top- k k k 个描述,表示为 L t o p − k ⊂ L L_{\mathrm{top - }k} \subset L Ltop−k⊂L。
与排名靠前的描述对应的视觉区域被聚合,形成与查询相关的图像区域:其中 c i c_i ci 是生成描述 L i L_i Li 的视觉块。这有效地识别了原始超高分辨率图像中最语义相关的区域。
I r e l e v a n t = ⋃ L i ∈ L t o p − k c i , ( 4 ) I_{\mathrm{relevant}} = \bigcup_{L_i \in L_{\mathrm{top - k}}} c_i, \quad (4) Irelevant=Li∈Ltop−k⋃ci,(4)
通过这种高效的过程,语义检索工具使代理能够直接在语言空间中执行局部推理,促进对超高分辨率图像内容的可扩展和高效探索。
4.2. 视觉工具
此外,我们的工具集还包括以下基本视觉工具,用于执行基本的图像定位、编辑和问答任务。
VLM。基于 Qwen2.5-VL-7B 2 构建的视觉-语言模型,用于在给定查询 q q q 的情况下对局部图像补丁 I I I 执行视觉问答。
Ground。该工具通过文本驱动的对象检测实现语言和视觉的集成感知。利用 GroundingDINO 模型 10,它识别与给定文本输入对应的视觉区域。对于输入图像 I I I 和文本查询 q q q,该工具检测所描述对象的实例并输出其对应的边界框 b b b。
| Method | Portrait Scrolls | Narrative Scrolls | Humanistic Scenes agent framework (Ours) | Satellite images | Street-view images | Natural Scenes | Overall |
|---|---|---|---|---|---|---|---|
| agent framework (Ours) | |||||||
| gpt4o | 32.81 | 27.59 | 29.44 | 39.72 | 41.67 | 40.84 | 36.95 |
| doubao-seed-1-6-thinking | 39.06 | 31.90 | 34.44 | 29.53 | 44.27 | 37.95 | 36.75 |
| Qwen3-235B-A22B-Instruct | 46.88 | 35.34 | 39.44 | 30.70 | 47.40 | 40.25 | 39.97 |
| gemini-2.5-flash-thinking | 31.25 | 25.00 | 27.22 | 25.53 | 27.08 | 26.14 | 26.69 |
| gpt-4.1 (2025-04-14) | 43.75 | 33.62 | 37.22 | 34.75 | 41.67 | 38.71 | 38.20 |
| claude-sonnet-4 (2025-05-14) | 37.50 | 31.03 | 33.33 | 34.04 | 44.79 | 40.19 | 37.85 |
| DeepSeek-R1 | 35.94 | 34.48 | 35.00 | 31.25 | 40.62 | 36.60 | 36.06 |
| end-to-end | |||||||
| gpt4o | 12.50 | 16.52 | 15.08 | 32.88 | 18.59 | 24.71 | 21.43 |
| o3 | 12.50 | 24.35 | 20.11 | 15.28 | 21.32 | 18.73 | 19.20 |
| doubao-seed-1-5-vison-pro | 23.44 | 22.61 | 22.91 | 34.69 | 23.98 | 28.57 | 26.64 |
| grok-2-vision-1212 | 26.56 | 19.83 | 22.22 | 24.49 | 15.58 | 19.39 | 20.35 |
| qwen-2.5-vl-72b | 20.31 | 21.74 | 21.23 | 33.33 | 32.14 | 32.65 | 28.76 |
| qwen-2.5-vl-32b | 26.56 | 20.69 | 22.78 | 31.97 | 26.13 | 28.63 | 26.64 |
| gemini-2.5-flash-thinking | 21.88 | 20.00 | 20.11 | 15.65 | 24.62 | 20.78 | 20.55 |
| claude-sonnet-4 (2025-05-14) | 34.38 | 30.17 | 31.66 | 31.97 | 14.07 | 21.73 | 25.12 |
表 3. UR-Bench 上的准确率得分。结果包括对闭源和开源 MLLMs 的端到端评估,以及我们提出的配备不同决策模型的代理框架的性能。
Crop。该工具根据提供的边界框执行图像裁剪,使代理能够隔离和分析特定的感兴趣区域。给定输入图像 I I I 和相应的边界框 b b b(定义目标区域),它提取指定的矩形子区域并输出裁剪后的图像 I c r o p I_{crop} Icrop。
Enhance。该工具应用图像增强操作------包括亮度、对比度、锐度和色彩调整------以减轻视觉退化,同时保持自然外观。给定输入图像 I I I 和增强参数 b b b、 c c c、 s s s 和 c o l col col(分别对应亮度、对比度、锐度和色彩),该工具处理图像并生成增强输出 I enhance I_{\text{enhance}} Ienhance。
为确保完整性和可复现性,附录中提供了额外的实现细节和工具特定的超参数。
5. 实验
5.1. 实验设置
我们评估了我们基准在广泛的开源和闭源 MLLMs 上的表现。具体来说,我们对以下模型进行了端到端测试:GPT-4o 8、o3 15、Doubao-Seed-1.5-Vision-Pro、Grok-2-Vision、Qwen-2.5-VL-72B 2、Qwen-2.5-VL-32B 2、Gemini-2.5-Flash-Thinking 5 和 Claude-Sonnet-4 (2025-05-14) 1。鉴于我们的基准包含可能超出这些模型令牌限制的超高分辨率图像,我们在推理过程中按比例调整每张图像的大小,以确保其视觉令牌数量与每个模型的最大视觉令牌容量相匹配。
我们进一步评估了我们提出的代理框架,其中推理和决策过程由纯语言模型处理。决策模型包括 GPT-4o 8、Doubao-Seed-1.6-Thinking、Qwen3-235B-A22B-Instruct、GPT-4.1 (2025-04-14)、Claude-Sonnet-4 (2025-05-14)、Gemini-2.5-Flash-Thinking 5 和 DeepSeek-R1 6。在此设置中,代理框架通过模块化感知工具处理视觉环境,并将高级推理和决策委托给语言模型。所有推理均通过官方 API 在一致配置下进行。我们基准中的所有问题都是 4 选项单选题,最终评估指标是准确率,定义为在所有有效回答中正确回答问题的比例。
5.2. 总体结果
我们在表 3 中展示了 UR-Bench 上的主要结果。我们的分析侧重于三个关键观察。
端到端 MLLMs 能力有限。如表 3 中"端到端"结果所示,当前 MLLMs 在面对超高分辨率图像时,其性能仍有显著提升空间。尽管是强大的模型,但像 gpt4o 和 claude-sonnet-4 这样的方法仅取得了 21.43 和 25.12 的低总准确率得分。这种糟糕的性能凸显了这些模型在单次处理千兆像素级图像时固有的挑战,可能导致严重的信息丢失和无法感知细粒度细节。
我们的代理框架实现了卓越的性能。相比之下,我们提出的代理框架表现更好,并在所有类别中展现出显著的性能飞跃。通过系统地分解复杂任务并策略性地处理高分辨率输入,我们的框架始终优于所有端到端基线。例如,在我们的框架中,使用 gpt4o 作为决策模型,其总分达到 36.95,比其端到端对应模型提高了 +15.52 个百分点。我们的框架配备 Qwen3-235B-A22B-Instruct 取得了最高的总分 39.97,在该挑战性基准上建立了新的最先进水平。
子集性能分析。不同子集的详细结果揭示了模型能力的进一步洞察。人文场景子集,以中国古代卷轴画的复杂细致特征为特点,被证明特别具有挑战性。我们的代理框架在该领域表现出色,特别是配备 Qwen3-235B-A22B-Instruct 时,在人物卷轴(46.88)、叙事卷轴(35.34)和聚合类别(39.44)上取得了最高分。这表明我们的框架在解析这些艺术作品中固有的复杂叙事和详细人物方面非常有效。相反,在自然场景子集,结合了大规模航空和地面图像,我们框架中的 gpt4o 展现出特别的优势,在该类别中取得了最高分(40.84),这得益于在卫星图像(39.72)和街景图像(41.67)上的强劲表现。这表明我们的框架在利用不同模型的优势以适应从艺术到地理空间分析等不同视觉上下文方面具有灵活性。
表 4. 模型在微观、区域和全局级别上的性能比较。
| Method | Micro Level | Regional Level | Global Level |
|---|---|---|---|
| agent framework (Ours) | |||
| gpt4o | 41.07 | 33.48 | 38.47 |
| doubao-seed-1-6-thinking | 48.19 | 29.08 | 34.44 |
| Qwen3-235B-A22B-Instruct | 45.59 | 37.48 | 35.21 |
| gemini-2.5-flash-thinking | 28.11 | 20.91 | 31.99 |
| gpt-4.1 (2025-04-14) | 41.27 | 35.89 | 38.81 |
| claude-sonnet-4 (2025-05-14) | 39.97 | 37.80 | 36.07 |
| DeepSeek-R1 | 38.06 | 31.86 | 36.64 |
| end-to-end | |||
| gpt4o | 17.05 | 21.80 | 28.90 |
| o3 | 17.32 | 15.13 | 16.23 |
| doubao-seed-1-5-vison-pro | 25.14 | 21.32 | 33.63 |
| grok-2-vision-1212 | 13.39 | 17.56 | 25.21 |
| qwen-2.5-vl-72b | 24.88 | 26.81 | 33.76 |
| qwen-2.5-vl-32b | 23.20 | 24.71 | 29.67 |
| gemini-2.5-flash-thinking | 20.80 | 19.26 | 17.02 |
| claude-sonnet-4 (2025-05-14) | 21.32 | 19.71 | 30.52 |
5.3. 按推理复杂性分析
表 4 展示了模型在微观、区域和全局级别上的最新性能。总体而言,我们的代理框架在所有推理复杂性方面继续优于端到端模型,突出了显式区域检索和结构化多步推理的优势。例如,gpt4o 在端到端设置中的表现为 17.05/21.80/28.90,而使用代理后提高到 41.07/33.48/38.47。doubao-seed-1-6-thinking 在区域级别上达到 48.19,表明其强大的多步推理能力。在代理框架内,不同模型展现出互补的优势:Qwen3-235B-A22B-Instruct 实现了最高的微观级别准确率(45.59),展示了精确的细粒度感知;claude-sonnet-4 取得了最佳的区域级别准确率(37.80),反映了对相邻区域有效的短范围推理;gpt-4.1 在全局级别上表现最佳(38.81),表明在远距离区域间具有卓越的整合能力。其他代理模型如 DeepSeek-R1 和 gemini-2.5-flash-thinking 也展现出竞争性性能,说明多个模型可以为多级别推理做出贡献。相比之下,端到端模型在所有级别上仍然显著较低,很少超过 34%,这强调了它们在没有代理指导的情况下定位稀疏区域和执行跨区域推理的困难。有趣的是,一些端到端模型在全局级别问题上取得了相对较高的分数(例如 qwen2.5-vl-72b:33.76),这可能是因为对粗略空间关系的推理较少依赖于精确的区域定位。这些结果再次证实,超高分辨率 VQA 从基于代理的分解中受益匪浅,而多级别评估对于捕捉现代 MLLMs 的多样化优势至关重要。
5.4. 工具使用分析
我们分析了六种工具的平均调用次数:语义抽象 (Semantic Abstraction)、语义检索 (Semantic Retrieval)、裁剪 (Crop)、增强 (Enhance)、接地 (Ground) 和 VLM。如图4所示,左侧面板展示了每种工具的使用情况,而右侧面板则呈现了各模型的总体平均工具调用次数。模型表现出不同程度的工具依赖性。doubao-seed-1-6-thinking 显示出最高的总体平均调用次数(约2.0次),其次是 DeepSeek-R1 和 Qwen3-235B-A22B-Instruct,这表明它们在多模态推理中对外部工具的依赖性更强。相比之下,gpt4o、claude-sonnet-4,尤其是 gpt-4.1 等模型的工具使用率较低(低于1.0次),这暗示它们具备更强的内在视觉推理能力。值得注意的是,gemini-2.5-flash-thinking 尽管工具调用次数很少,但其性能较差,如表3所示。这些结果表明模型行为存在明显的分层。语义工具的主导地位进一步说明,语义抽象和检索构成了超高分辨率推理的核心。
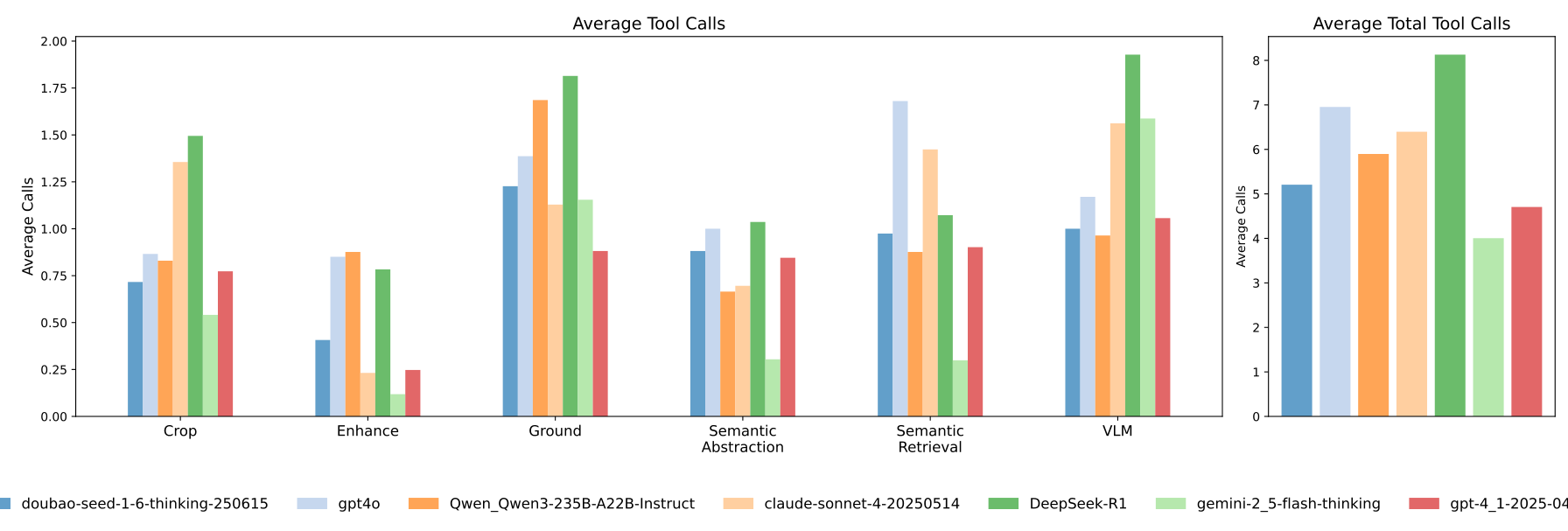
图4. 在街景图像子集下,使用不同模型作为我们代理框架中的决策模型时,工具调用频率的比较。

5.5. 定性分析
图5展示了我们的语义抽象框架如何通过代理引导的块选择 (chunk selection) 来实现对推理粒度的灵活控制。绿色方框显示了代理最终总结的推理结果,其中整合了来自不同抽象层次的证据。右侧的黄色方框显示了代理引用的两个块的标题。值得注意的是,通过将块预算从粗略设置(例如,chunk_num=10)增加到更精细的设置(例如,chunk_num=20),代理获得了更局部化、语义更精确的块,从而使其能够完善解释并得出更准确的判断。这个案例表明,语义抽象提供了一种有效机制来调整视觉信息的语义粒度,使代理能够根据任务复杂性动态调整其推理过程。
6. 结论
我们引入了 UR-Bench,一个针对超高分辨率图像多跳推理的基准,并表明现有的大型多模态语言模型 (MLLMs) 在这种极端视觉条件下遇到了实质性挑战。为了解决这些局限性,我们提出了一种基于代理的框架,该框架利用语义抽象和检索来高效处理和推理大规模视觉内容。实验验证了 UR-Bench 的难度和我们框架的有效性。我们希望这项工作能启发关于工具增强高分辨率多模态理解的研究。
Original Abstract: Recent multimodal large language models (MLLMs) show strong capabilities in visual-language reasoning, yet their performance on ultra-high-resolution imagery remains largely unexplored. Existing visual question answering (VQA) benchmarks typically rely on medium-resolution data, offering limited visual complexity. To bridge this gap, we introduce Ultra-high-resolution Reasoning Benchmark (UR-Bench), a benchmark designed to evaluate the reasoning capabilities of MLLMs under extreme visual information. UR-Bench comprises two major categories, Humanistic Scenes and Natural Scenes, covering four subsets of ultra-high-resolution images with distinct spatial structures and data sources. Each subset contains images ranging from hundreds of megapixels to gigapixels, accompanied by questions organized into three levels, enabling evaluation of models' reasoning capabilities in ultra-high-resolution scenarios. We further propose an agent-based framework in which a language model performs reasoning by invoking external visual tools. In addition, we introduce Semantic Abstraction and Retrieval tools that enable more efficient processing of ultra-high-resolution images. We evaluate state-of-the-art models using both an end-to-end MLLMs and our agent-based framework, demonstrating the effectiveness of our framework.
PDF Link: 2601.08748v1
部分平台可能图片显示异常,请以我的博客内容为准
