llama
- [1. llama.cpp](#1. llama.cpp)
-
- [1.1 模型转换](#1.1 模型转换)
- [2 llama-cpp-python库](#2 llama-cpp-python库)
- [3. 模型结构](#3. 模型结构)
源码解析:
https://blog.csdn.net/chumingqian/article/details/134259129
1. llama.cpp
运行过程:
bash
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp下面有两种方法: make cmake(个人用cmake能编译通过,通过之后,在build文件夹下会有编译之后的可执行文件)
bash
cmake -B build
cmake --build build --config Release1.1 模型转换
bash
python convert_hf_to_gguf.py /home/qian/Self/model/Llama-3.2-1B --outfile /home/qian/Self/Self_Pro/Llama-1b.gguf2 llama-cpp-python库
bash
pip install llama-cpp-python大概率会报错
bash
(llama) qian@qian-MS-7E06:~/Self/powerInfer/llama$ pip install llama-cpp-python/
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Processing ./llama-cpp-python
Installing build dependencies ... done
Getting requirements to build wheel ... done
Installing backend dependencies ... done
Preparing metadata (pyproject.toml) ... done
Requirement already satisfied: typing-extensions>=4.5.0 in /home/qian/anaconda3/envs/llama/lib/python3.10/site-packages (from llama_cpp_python==0.3.5) (4.11.0)
Requirement already satisfied: numpy>=1.20.0 in /home/qian/anaconda3/envs/llama/lib/python3.10/site-packages (from llama_cpp_python==0.3.5) (1.26.4)
Collecting diskcache>=5.6.1 (from llama_cpp_python==0.3.5)
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/3f/27/4570e78fc0bf5ea0ca45eb1de3818a23787af9b390c0b0a0033a1b8236f9/diskcache-5.6.3-py3-none-any.whl (45 kB)
Requirement already satisfied: jinja2>=2.11.3 in /home/qian/anaconda3/envs/llama/lib/python3.10/site-packages (from llama_cpp_python==0.3.5) (3.1.4)
Requirement already satisfied: MarkupSafe>=2.0 in /home/qian/anaconda3/envs/llama/lib/python3.10/site-packages (from jinja2>=2.11.3->llama_cpp_python==0.3.5) (3.0.2)
Building wheels for collected packages: llama_cpp_python
Building wheel for llama_cpp_python (pyproject.toml) ... error
error: subprocess-exited-with-error
× Building wheel for llama_cpp_python (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [137 lines of output]
*** scikit-build-core 0.10.7 using CMake 3.31.2 (wheel)
*** Configuring CMake...
loading initial cache file /tmp/tmpez4stejk/build/CMakeInit.txt
-- The C compiler identification is GNU 11.4.0
-- The CXX compiler identification is GNU 11.4.0
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/gcc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/g++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found Git: /usr/bin/git (found version "2.34.1")
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD - Success
-- Found Threads: TRUE
-- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- Including CPU backend
-- Found OpenMP_C: -fopenmp (found version "4.5")
-- Found OpenMP_CXX: -fopenmp (found version "4.5")
-- Found OpenMP: TRUE (found version "4.5")
-- x86 detected
-- Adding CPU backend variant ggml-cpu: -march=native
CMake Warning (dev) at CMakeLists.txt:13 (install):
Target llama has PUBLIC_HEADER files but no PUBLIC_HEADER DESTINATION.
Call Stack (most recent call first):
CMakeLists.txt:97 (llama_cpp_python_install_target)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at CMakeLists.txt:21 (install):
Target llama has PUBLIC_HEADER files but no PUBLIC_HEADER DESTINATION.
Call Stack (most recent call first):
CMakeLists.txt:97 (llama_cpp_python_install_target)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at CMakeLists.txt:13 (install):
Target ggml has PUBLIC_HEADER files but no PUBLIC_HEADER DESTINATION.
Call Stack (most recent call first):
CMakeLists.txt:98 (llama_cpp_python_install_target)
This warning is for project developers. Use -Wno-dev to suppress it.
CMake Warning (dev) at CMakeLists.txt:21 (install):
Target ggml has PUBLIC_HEADER files but no PUBLIC_HEADER DESTINATION.
Call Stack (most recent call first):
CMakeLists.txt:98 (llama_cpp_python_install_target)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Configuring done (0.3s)
-- Generating done (0.0s)
-- Build files have been written to: /tmp/tmpez4stejk/build
*** Building project with Ninja...
Change Dir: '/tmp/tmpez4stejk/build'
Run Build Command(s): /usr/bin/ninja -v
[1/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-hbm.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-hbm.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-hbm.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/ggml-cpu-hbm.cpp
[2/47] cd /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp && /tmp/pip-build-env-aavk_erd/normal/lib/python3.10/site-packages/cmake/data/bin/cmake -DMSVC= -DCMAKE_C_COMPILER_VERSION=11.4.0 -DCMAKE_C_COMPILER_ID=GNU -DCMAKE_VS_PLATFORM_NAME= -DCMAKE_C_COMPILER=/usr/bin/gcc -P /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/cmake/build-info-gen-cpp.cmake
-- Found Git: /usr/bin/git (found version "2.34.1")
[3/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/build_info.dir/build-info.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/build_info.dir/build-info.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/build_info.dir/build-info.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/build-info.cpp
[4/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_base_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-threading.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-threading.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-threading.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-threading.cpp
[5/47] /usr/bin/gcc -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_base_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu11 -fPIC -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wdouble-promotion -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-alloc.c.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-alloc.c.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-alloc.c.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-alloc.c
[6/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/console.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/console.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/console.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/console.cpp
[7/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-traits.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-traits.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-traits.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/ggml-cpu-traits.cpp
[8/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/speculative.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/speculative.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/speculative.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/speculative.cpp
[9/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../../common -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -O3 -DNDEBUG -fPIC -Wno-cast-qual -MD -MT vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o -MF vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o.d -o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/llava.cpp
[10/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/amx.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/amx.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/amx.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/amx/amx.cpp
[11/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/mmq.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/mmq.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/mmq.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/amx/mmq.cpp
[12/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_base_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-backend.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-backend.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-backend.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-backend.cpp
[13/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/log.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/log.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/log.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/log.cpp
[14/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -Dllama_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode-data.cpp.o -MF vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode-data.cpp.o.d -o vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode-data.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/unicode-data.cpp
[15/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/ggml-cpu.cpp
[16/47] /usr/bin/gcc -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu11 -fPIC -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wdouble-promotion -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-quants.c.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-quants.c.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-quants.c.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/ggml-cpu-quants.c
[17/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_base_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-opt.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-opt.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-opt.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-opt.cpp
[18/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/ngram-cache.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/ngram-cache.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/ngram-cache.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/ngram-cache.cpp
[19/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../../common -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/include -O3 -DNDEBUG -MD -MT vendor/llama.cpp/examples/llava/CMakeFiles/llama-llava-cli.dir/llava-cli.cpp.o -MF vendor/llama.cpp/examples/llava/CMakeFiles/llama-llava-cli.dir/llava-cli.cpp.o.d -o vendor/llama.cpp/examples/llava/CMakeFiles/llama-llava-cli.dir/llava-cli.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/llava-cli.cpp
[20/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml.dir/ggml-backend-reg.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml.dir/ggml-backend-reg.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml.dir/ggml-backend-reg.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-backend-reg.cpp
[21/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../../common -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/include -O3 -DNDEBUG -MD -MT vendor/llama.cpp/examples/llava/CMakeFiles/llama-minicpmv-cli.dir/minicpmv-cli.cpp.o -MF vendor/llama.cpp/examples/llava/CMakeFiles/llama-minicpmv-cli.dir/minicpmv-cli.cpp.o.d -o vendor/llama.cpp/examples/llava/CMakeFiles/llama-minicpmv-cli.dir/minicpmv-cli.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/minicpmv-cli.cpp
[22/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../../common -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/include -O3 -DNDEBUG -MD -MT vendor/llama.cpp/examples/llava/CMakeFiles/llama-qwen2vl-cli.dir/qwen2vl-cli.cpp.o -MF vendor/llama.cpp/examples/llava/CMakeFiles/llama-qwen2vl-cli.dir/qwen2vl-cli.cpp.o.d -o vendor/llama.cpp/examples/llava/CMakeFiles/llama-qwen2vl-cli.dir/qwen2vl-cli.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/qwen2vl-cli.cpp
[23/47] /usr/bin/gcc -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_base_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu11 -fPIC -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wdouble-promotion -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml.c.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml.c.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml.c.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml.c
[24/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/sampling.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/sampling.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/sampling.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/sampling.cpp
[25/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-aarch64.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-aarch64.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-aarch64.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/ggml-cpu-aarch64.cpp
[26/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -Dllama_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-sampling.cpp.o -MF vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-sampling.cpp.o.d -o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-sampling.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/llama-sampling.cpp
[27/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -Dllama_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-grammar.cpp.o -MF vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-grammar.cpp.o.d -o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-grammar.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/llama-grammar.cpp
[28/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -Dllama_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-vocab.cpp.o -MF vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-vocab.cpp.o.d -o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-vocab.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/llama-vocab.cpp
[29/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/common.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/common.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/common.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/common.cpp
[30/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu++17 -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/llamafile/sgemm.cpp.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/llamafile/sgemm.cpp.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/llamafile/sgemm.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/llamafile/sgemm.cpp
[31/47] /usr/bin/gcc -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BUILD -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_base_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu11 -fPIC -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wdouble-promotion -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-quants.c.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-quants.c.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-quants.c.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-quants.c
[32/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -fPIC -O3 -DNDEBUG -shared -Wl,-soname,libggml-base.so -o vendor/llama.cpp/ggml/src/libggml-base.so vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml.c.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-alloc.c.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-backend.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-opt.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-threading.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-base.dir/ggml-quants.c.o -Wl,-rpath,"\$ORIGIN" -lm && :
[33/47] /usr/bin/gcc -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_BUILD -DGGML_BACKEND_SHARED -DGGML_SCHED_MAX_COPIES=4 -DGGML_SHARED -DGGML_USE_CPU_AARCH64 -DGGML_USE_LLAMAFILE -DGGML_USE_OPENMP -D_GNU_SOURCE -D_XOPEN_SOURCE=600 -Dggml_cpu_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -std=gnu11 -fPIC -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wdouble-promotion -march=native -fopenmp -MD -MT vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.c.o -MF vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.c.o.d -o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.c.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/ggml-cpu/ggml-cpu.c
[34/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -fPIC -O3 -DNDEBUG -shared -Wl,-soname,libggml-cpu.so -o vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.c.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-aarch64.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-hbm.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-quants.c.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/ggml-cpu-traits.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/amx.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/amx/mmq.cpp.o vendor/llama.cpp/ggml/src/CMakeFiles/ggml-cpu.dir/ggml-cpu/llamafile/sgemm.cpp.o -Wl,-rpath,"\$ORIGIN" vendor/llama.cpp/ggml/src/libggml-base.so /usr/lib/gcc/x86_64-linux-gnu/11/libgomp.so && :
[35/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -fPIC -O3 -DNDEBUG -shared -Wl,-soname,libggml.so -o vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/CMakeFiles/ggml.dir/ggml-backend-reg.cpp.o -Wl,-rpath,"\$ORIGIN" -ldl vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
[36/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -Dllama_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode.cpp.o -MF vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode.cpp.o.d -o vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/unicode.cpp
[37/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/json-schema-to-grammar.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/json-schema-to-grammar.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/json-schema-to-grammar.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/json-schema-to-grammar.cpp
[38/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../.. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/../../common -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -O3 -DNDEBUG -fPIC -Wno-cast-qual -MD -MT vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o -MF vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o.d -o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/examples/llava/clip.cpp
[39/47] : && /tmp/pip-build-env-aavk_erd/normal/lib/python3.10/site-packages/cmake/data/bin/cmake -E rm -f vendor/llama.cpp/examples/llava/libllava_static.a && /usr/bin/ar qc vendor/llama.cpp/examples/llava/libllava_static.a vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o && /usr/bin/ranlib vendor/llama.cpp/examples/llava/libllava_static.a && :
[40/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_SHARED -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/common/CMakeFiles/common.dir/arg.cpp.o -MF vendor/llama.cpp/common/CMakeFiles/common.dir/arg.cpp.o.d -o vendor/llama.cpp/common/CMakeFiles/common.dir/arg.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/common/arg.cpp
[41/47] /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -DGGML_BACKEND_SHARED -DGGML_SHARED -DGGML_USE_CPU -DLLAMA_BUILD -DLLAMA_SHARED -Dllama_EXPORTS -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/. -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/../include -I/home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/ggml/src/../include -O3 -DNDEBUG -fPIC -Wmissing-declarations -Wmissing-noreturn -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-array-bounds -Wextra-semi -MD -MT vendor/llama.cpp/src/CMakeFiles/llama.dir/llama.cpp.o -MF vendor/llama.cpp/src/CMakeFiles/llama.dir/llama.cpp.o.d -o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama.cpp.o -c /home/qian/Self/powerInfer/llama/llama-cpp-python/vendor/llama.cpp/src/llama.cpp
[42/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -fPIC -O3 -DNDEBUG -shared -Wl,-soname,libllama.so -o vendor/llama.cpp/src/libllama.so vendor/llama.cpp/src/CMakeFiles/llama.dir/llama.cpp.o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-vocab.cpp.o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-grammar.cpp.o vendor/llama.cpp/src/CMakeFiles/llama.dir/llama-sampling.cpp.o vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode.cpp.o vendor/llama.cpp/src/CMakeFiles/llama.dir/unicode-data.cpp.o -Wl,-rpath,"\$ORIGIN" vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
[43/47] : && /tmp/pip-build-env-aavk_erd/normal/lib/python3.10/site-packages/cmake/data/bin/cmake -E rm -f vendor/llama.cpp/common/libcommon.a && /usr/bin/ar qc vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/common/CMakeFiles/build_info.dir/build-info.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/arg.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/common.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/console.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/json-schema-to-grammar.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/log.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/ngram-cache.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/sampling.cpp.o vendor/llama.cpp/common/CMakeFiles/common.dir/speculative.cpp.o && /usr/bin/ranlib vendor/llama.cpp/common/libcommon.a && :
[44/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -fPIC -O3 -DNDEBUG -shared -Wl,-soname,libllava.so -o vendor/llama.cpp/examples/llava/libllava.so vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o -Wl,-rpath,"\$ORIGIN" vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
[45/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llama-llava-cli.dir/llava-cli.cpp.o -o vendor/llama.cpp/examples/llava/llama-llava-cli -Wl,-rpath,/tmp/tmpez4stejk/build/vendor/llama.cpp/src:/tmp/tmpez4stejk/build/vendor/llama.cpp/ggml/src: vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
FAILED: vendor/llama.cpp/examples/llava/llama-llava-cli
: && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llama-llava-cli.dir/llava-cli.cpp.o -o vendor/llama.cpp/examples/llava/llama-llava-cli -Wl,-rpath,/tmp/tmpez4stejk/build/vendor/llama.cpp/src:/tmp/tmpez4stejk/build/vendor/llama.cpp/ggml/src: vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
/home/qian/anaconda3/envs/llama/compiler_compat/ld: warning: libgomp.so.1, needed by vendor/llama.cpp/ggml/src/libggml-cpu.so, not found (try using -rpath or -rpath-link)
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_barrier@GOMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_parallel@GOMP_4.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `omp_get_thread_num@OMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_single_start@GOMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `omp_get_num_threads@OMP_1.0'
collect2: error: ld returned 1 exit status
[46/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llama-qwen2vl-cli.dir/qwen2vl-cli.cpp.o -o vendor/llama.cpp/examples/llava/llama-qwen2vl-cli -Wl,-rpath,/tmp/tmpez4stejk/build/vendor/llama.cpp/src:/tmp/tmpez4stejk/build/vendor/llama.cpp/ggml/src: vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
FAILED: vendor/llama.cpp/examples/llava/llama-qwen2vl-cli
: && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llama-qwen2vl-cli.dir/qwen2vl-cli.cpp.o -o vendor/llama.cpp/examples/llava/llama-qwen2vl-cli -Wl,-rpath,/tmp/tmpez4stejk/build/vendor/llama.cpp/src:/tmp/tmpez4stejk/build/vendor/llama.cpp/ggml/src: vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
/home/qian/anaconda3/envs/llama/compiler_compat/ld: warning: libgomp.so.1, needed by vendor/llama.cpp/ggml/src/libggml-cpu.so, not found (try using -rpath or -rpath-link)
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_barrier@GOMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_parallel@GOMP_4.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `omp_get_thread_num@OMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_single_start@GOMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `omp_get_num_threads@OMP_1.0'
collect2: error: ld returned 1 exit status
[47/47] : && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llama-minicpmv-cli.dir/minicpmv-cli.cpp.o -o vendor/llama.cpp/examples/llava/llama-minicpmv-cli -Wl,-rpath,/tmp/tmpez4stejk/build/vendor/llama.cpp/src:/tmp/tmpez4stejk/build/vendor/llama.cpp/ggml/src: vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
FAILED: vendor/llama.cpp/examples/llava/llama-minicpmv-cli
: && /usr/bin/g++ -pthread -B /home/qian/anaconda3/envs/llama/compiler_compat -O3 -DNDEBUG vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/llava.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llava.dir/clip.cpp.o vendor/llama.cpp/examples/llava/CMakeFiles/llama-minicpmv-cli.dir/minicpmv-cli.cpp.o -o vendor/llama.cpp/examples/llava/llama-minicpmv-cli -Wl,-rpath,/tmp/tmpez4stejk/build/vendor/llama.cpp/src:/tmp/tmpez4stejk/build/vendor/llama.cpp/ggml/src: vendor/llama.cpp/common/libcommon.a vendor/llama.cpp/src/libllama.so vendor/llama.cpp/ggml/src/libggml.so vendor/llama.cpp/ggml/src/libggml-cpu.so vendor/llama.cpp/ggml/src/libggml-base.so && :
/home/qian/anaconda3/envs/llama/compiler_compat/ld: warning: libgomp.so.1, needed by vendor/llama.cpp/ggml/src/libggml-cpu.so, not found (try using -rpath or -rpath-link)
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_barrier@GOMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_parallel@GOMP_4.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `omp_get_thread_num@OMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `GOMP_single_start@GOMP_1.0'
/home/qian/anaconda3/envs/llama/compiler_compat/ld: vendor/llama.cpp/ggml/src/libggml-cpu.so: undefined reference to `omp_get_num_threads@OMP_1.0'
collect2: error: ld returned 1 exit status
ninja: build stopped: subcommand failed.
*** CMake build failed
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for llama_cpp_python
Failed to build llama_cpp_python
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (llama_cpp_python)
bash
sudo apt-get install libomp-dev # 先安装了这个,还报错官网提供的解决办法之一,也不好用
bash
pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cpu从头来:
- 先去github上,下载llama-cpp-python源码: https://github.com/abetlen/llama-cpp-python
- vendor文件夹下,是llama.cpp的源码,需要把llama.cpp的源码拉下来放到这个文件夹里 : https://github.com/ggerganov/llama.cpp/
- 然后在 pip install ,嗯,又!报错了
最后找到的解决方案:
bash
# 先安装这个东西
sudo apt update
sudo apt install libomp-dev
# 再找到libgomp.so.1这个文件在那(选择那个 /usr/...的目录就好)
find / -name libgomp.so.1 2>/dev/null
locate libgomp.so.1 #或者用这个命令找,可能需要安装locate, sudo apt install plocate
# 再,设置环境变量,能找到libgomp.so.1这个东西
printenv LD_LIBRARY_PATH # 查看已有环境变量,然后追加
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:/usr/lib/x86_64-linux-gnu/ #这个命令好像只针对这一个终端有用
# 最后再,安装,就,通过了
pip install llama-cpp-python/ 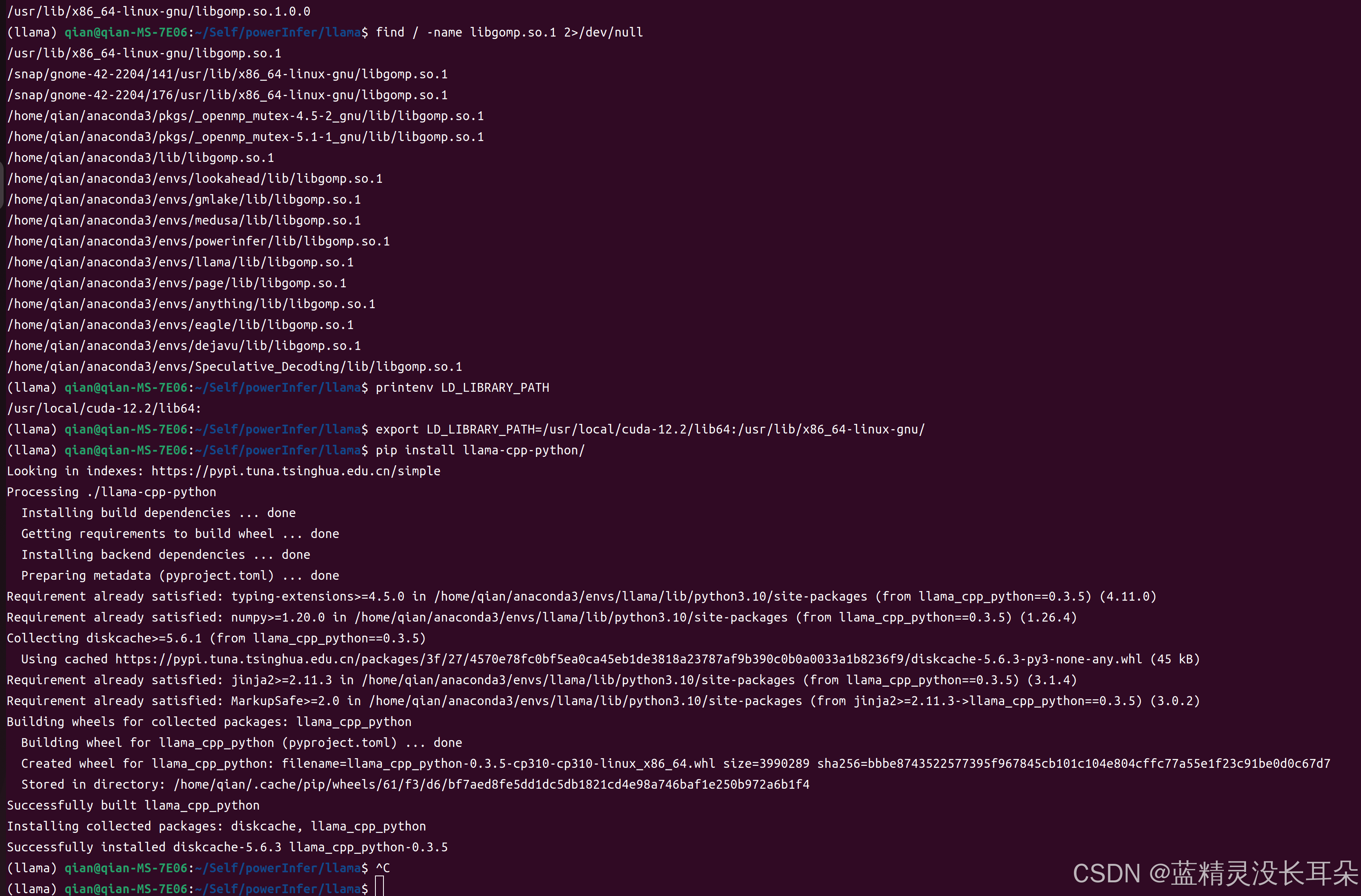
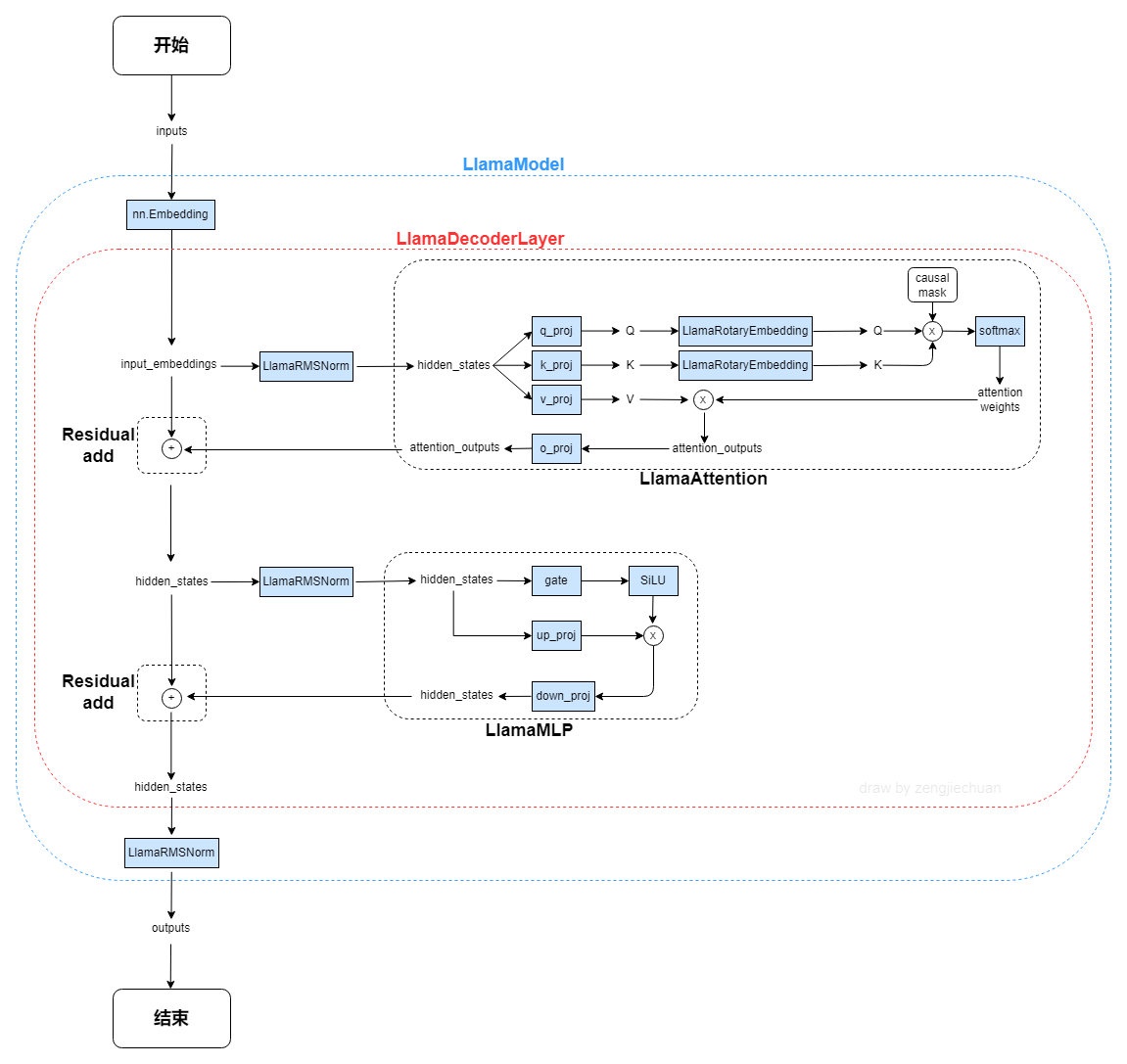
3. 模型结构