写在前面:本博客全部基于知乎的大模型课程所做的笔记和整以及和在实操过程中遇到的问题和处理方法,(老师们讲的都很好,解答的也很细致)博主也正在学习中,如果有错误的地方期待和我沟通。大多代码都来自于上课的资料,加入了一些注释和梳理,或者对我没有跑通的代码做了一些修改让他符合我的需求。第一节链接:langchain多任务应用开发
现在的agent层出不穷,有哪些主流ai agent框架?
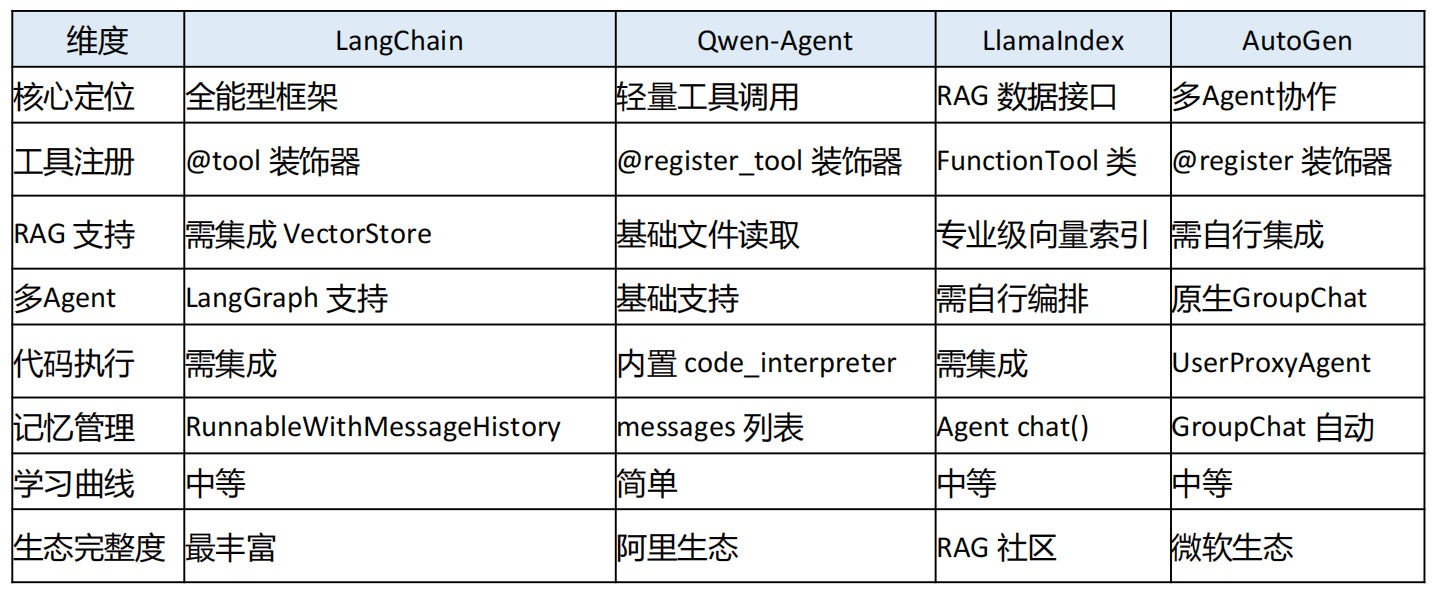
- LangChain: 全能型框架,管道式编排与丰富生态
- Qwen-Agent: 轻量级全能选手,工具调用与代码解释器
- LlamaIndex: 数据驱动的 RAG 专家
- AutoGen: 多智能体协作的
编写一个AI Agent框架,需要解决哪些核心问题?
agent核心问题
1. LLM适配层(大脑):LLM 统一接口与 Prompt 管理
LLM统一接口
Model Adapter (适配器模式)=> 抹平不同模型 (OpenAI, DeepSeek, Qwen) 的 API 差异。
切换模型还能使用同一套代码,统一一些定义,做规范。
| 框架 | LLM封装方式 | 特点 |
|---|---|---|
| LangChain | ChatTongyi/ChatOpenAI类 | 丰富的模型适配器,统一接口 |
| Qwen-Agent | llm_cfg 字典配置 | 配置式,支持多种model_server |
| LlamaIndex | Dashscope/OpenAI类 | 与settings全局配置结合 |
python
# ========== LangChain (v0.3) ==========
from langchain_community.chat_models
import ChatTongyi
llm = ChatTongyi(
model_name="deepseek-v3",#只需要改name
dashscope_api_key=api_key
)
python
# ========== Qwen-Agent ==========
llm_cfg = {#字典存储常见参数
'model': 'deepseek-v3',
'model_server':
'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key':
os.getenv('DASHSCOPE_API_KEY'),
'generate_cfg': {'top_p': 0.8}
}
#加入要换到其他的模型,换成对应模型(moedel_server)的url,保证接口和deepseek v3返回的格式一致即可
python
# ========== LlamaIndex ==========
from llama_index.llms.dashscope import
DashScope
llm = DashScope(
model="deepseek-v3",
api_key=api_key,
temperature=0.7,
)框架层做了一个中间层,把统一的指令(如 invoke("你好"))翻译成特定模型的 API 调用。
LLM 统一接口的作用:
- 统一调用方式
- 统一了参数配置(如 temperature)
- 输出格式(统一转为 Message 对象)
prompt管理(管理提示词模板)
prompt engineering 工程化
system message的动态注入,将人设与上下文解耦。
python
# LangChain 的 PromptTemplate
from langchain_core.prompts import
ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
MessagesPlaceholder(variable_name="history"),#记忆上下文
("human", "{input}")
])
python
# Qwen-Agent 的 system_message
system_instruction = '''你是一个乐于助人的AI助手。
在收到用户的请求后,你应该:
- 首先绘制一幅图像,得到图像的url,
- 然后运行代码下载该图像。
你总是用中文回复用户。'''人设(角色定义)与任务流程(上下文指令)分离,便于复用和维护。
Prompt Template(提示词模板)包括:
1、system prompt(固定的,对于一个agent,你的角色是什么,什么作用,类似于JD)
2、上下文(通过历史history变量)
3、tool的调用
@tools 注册了一个工具 -> prompt当中会体现出name、description、params(参数)等等。模板化
4、自定义提示词模板,直接通过invoke调用
2. 工具注册与调度tool registry(双手)
怎么执行呢?
| 模式 | 框架 | 特点 |
|---|---|---|
| @tool装饰器 | LangChain | 最简洁,docstring自动解析(''' '''注释) |
| @registry_tool + 类 | Qwen-Agent | 显式参数定义,结构清晰 |
| Function Tool封装 | LlamaIndex | 强类型约束,适合复杂工具 |
其中''' '''框起来的就是注释,agent以此来识别tool的作用。自动从 docstring 解析工具描述和参数说明支持类型注解,LLM 自动理解参数类型一行装饰器,零配置即可使用。
python
# ========== LangChain @tool 装饰器 ==========
from langchain_core.tools import tool
@tool
def ping_tool(target: str) -> str:
"""检查本机到指定主机名或IP地址的网络连通性。
参数:
target: 目标主机名或IP地址
返回:
模拟的ping结果
"""
if "unreachable" in target:
return f"Ping {target} 失败"
return f"Ping {target} 成功"千问直接通过description(保留字、固定的)来识别,parameters确定参数格式
python
# ========== Qwen-Agent @register_tool ==========
@register_tool('my_image_gen')
class MyImageGen(BaseTool):
description = 'AI 绘画服务,输入文本描述,返回图像 URL'
parameters = [{
'name': 'prompt',
'type': 'string',
'description': '期望的图像内容的详细描述',
'required': True
}]
def call(self, params: str, kwargs) -> str:#call也是保留字
prompt = json5.loads(params)['prompt']
return json5.dumps({'image_url': f'https://...'})
python
# ========== LlamaIndex FunctionTool ==========
def retrieve_documents(query: str) -> str:
"""从文档中检索相关信息"""
response = query_engine.query(query)
return str(response)
retrieve_tool =
FunctionTool.from_defaults(fn=retrieve_documents)工具的模块化:
我们使用agent关于tool的定义格式,来定义我们的自己的工具
AI会将我们给他的tool写成一段文字进行描述->LLM 给到大模型之后会得到一个response(告诉我要不要调用这个工具,如果要,参数是什么)。
总的来说,LLM是怎么看见工具的呢?
框架会将 Python 函数的 name、docstring (功能描述) 和 type hints (参数类型) 转换成 JSON Schema 喂给 LLM 。
LangChain: 也就是 @tool,主要是在使用 Python 原生特性,最符合直觉 。
Qwen-Agent: @register_tool,使用显式定义,强约束,适合复杂参数 ,更好的拓展。
3. Context管理(记忆)
| 框架 ||| 短期记忆 | 长期记忆 |
| LangChain ||| RunnableWithMessageHistory+session_id | 需集成vectorstore |
| Qwen-Agent ||| messages列表手动管理 | files参数加载文档 |
| LlamaIndex | agent chat()内置 | 专业级vectorstoreindex |
|---|
1)短期记忆 (Window) :设定一个k值(窗口值、昂贵的资源),只记忆上下文里的这么多条消息,不需要单独存储,刚刚说完在内存中还没有释放掉。
• 对话历史截断
• 滑动窗口策略
• 避免 Token 爆炸
2)长期记忆 (RAG) :存在文件系统里的(类似身份、底层数据等固定的长期的东西)
• VectorStoreIndex 向量索引
• 文档分块与 Embedding
• 相似度检索
python
# LangChain 短期记忆 (RunnableWithMessageHistory)
from langchain_core.chat_history import
InMemoryChatMessageHistory
from langchain_core.runnables.history import
RunnableWithMessageHistory
# 会话存储
store = {}
#可以支持多用户并发对话(不同的session)
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
#session类似 页 、对话,不同的页面不同的对话
# 创建带记忆的对话链
conversation = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
# 使用时指定 session_id
config = {"configurable": {"session_id": "user_123"}}
output = conversation.invoke({"input": "Hi!"}, config=config)messageplaceholder自动注入历史到prompt。
python
# === Qwen-Agent 短期记忆 (messages 列表) ===
messages = [] # 对话历史
messages.append({'role': 'user', 'content': query})
for response in bot.run(messages=messages):
pass
messages.extend(response) # 追加响应
#维护message变量
python
# ==== LlamaIndex 长期记忆 (VectorStoreIndex) ====
index = VectorStoreIndex.from_documents(documents)
# 持久化
index.storage_context.persist(persist_dir="./storage")
#文件的检索能力短期记忆:
• Session ID 很重要,它是多用户并发的基础 。
• 滑动窗口策略------只保留最近 N 轮,防止 Token 爆炸。
长期记忆:
• 这是 RAG 的范畴,利用向量数据库进行相关性检索,而非时间顺序回忆 。
4. 控制流/工作流/workflow编排(中枢)
不是一口气说完的,我们要拆解步骤。
| 模式 | 说明 | 使用 |
|---|---|---|
| 管道(链式) | prompt | llm | paraer 链式调用 | 线性处理 |
| 担任(loop) | react循环:思考、行动、观察 | 单agent |
| 多人(DAG) | 接力赛:明确的执行顺序(前后依赖关系) | 流程化任务(投资决策) |
| 多人(chat) | 圆桌会议、自由讨论 | 开放式 |
python
LangChain 管道式编排 (LCEL)
# ========== 管道语法: prompt | llm ==========
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that
makes {product}?",
)
# 使用管道符组合
chain = prompt | llm
# invoke 调用
result = chain.invoke({"product": "colorful socks"})| 管道符:直观链式调用
invoke():统一调用接口(输入输出确定)
支持流式输出、批处理、异步调用
prompt=>LLM=>paraser
python
# ========== Agent 模式: create_agent ==========
from langchain.agents import create_agent
# 定义工具
tools = [ping_tool, dns_tool, calculator]
# 创建 Agent (LangChain 1.x 新写法)
agent = create_agent(llm, tools)
# 使用 messages 格式调用
result = agent.invoke({"messages": [("user", "检查
www.example.com 的连通性")]})
print(result["messages"][-1].content)loop:react(循环)思考、行动、观察、思考......
LangChain - 全能型LLM应用框架
1、LECL管道语法(使用 | 管道符)
LangChain 采用组件化的方式,核心优势是把 Prompt、Model、Memory、Retriever 都做成了标准积木(Runnable)。
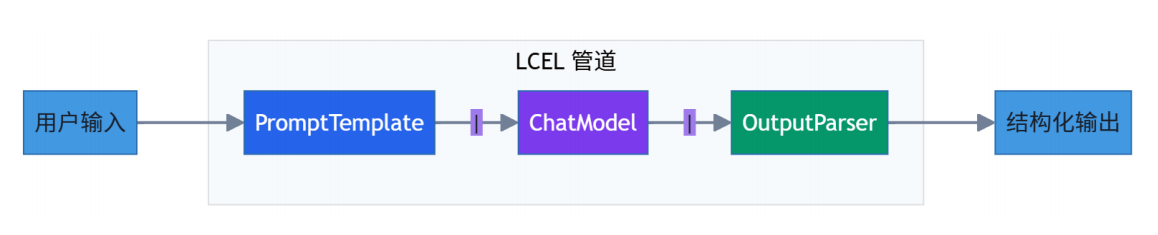
python
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi
# 加载模型
llm = Tongyi(model_name="qwen-turbo",
dashscope_api_key=api_key)
# 创建 Prompt Template
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that
makes {product}?",
)
# 管道语法组合
chain = prompt | llm
# invoke 调用
result = chain.invoke({"product": "colorful socks"})
print(result)2、工具注册:@tool装饰器
LangChain 的 @tool 装饰器是最简洁的工具注册方式,自动从 docstring 解析工具描述:
python
from langchain_core.tools import tool
@tool
def ping_tool(target: str) -> str:
"""检查本机到指定主机名或IP地址的网络连通性。
参数:
target: 目标主机名或IP地址
返回:
模拟的ping结果
"""
if "unreachable" in target:
return f"Ping {target} 失败:请求超时。"
return f"Ping {target} 成功:延迟 20ms。"
@tool
def dns_tool(hostname: str) -> str:
"""解析给定的主机名,获取其对应的IP地址。
参数:
hostname: 要解析的主机名
返回:
模拟的DNS解析结果
"""
if hostname == "www.example.com":
return f"DNS 解析 {hostname} 成功:IP 地址是93.184.216.34"
return f"DNS 解析 {hostname} 失败:找不到主机。"3、创建agent
python
LangChain 1.x Agent 创建方式
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
# 加载模型 (使用 ChatModel 以支持 tool calling)
llm = ChatTongyi(model_name="deepseek-v3",
dashscope_api_key=api_key)
# 定义工具列表
tools = [ping_tool, dns_tool, calculator]
# 创建 Agent (LangChain 1.x 新写法)
agent = create_agent(llm, tools)
# 使用 messages 格式调用
result = agent.invoke({
"messages": [("user", "我无法访问 www.example.com,帮我诊断一下")]
})
# 获取最终回复
print(result["messages"][-1].content)4、带记忆链的对话链
RunnableWithMessageHistory+session_id,支持多用户开发。
LlamaIndex - 数据驱动的RAG 专家
私有数据的强接口,文档问答是首选。(企业知识库、合同审查、学术论文分析等)
GitHub: github.com/run-llama/llama_index
一站式文档处理:加载、分块、向量化、索引、检索
索引持久化:避免重复创建,快速启动
多种检索策略:向量检索、关键词检索、混合检索
与 Agent 无缝集成:FunctionTool 封装查询引擎
1、Index 优先
他更关注数据结构,认为核心在于如何让LLM索引私有数据。

VectorStoreIndex 模块
persist相当于save保存
python
加载文档并创建索引
from llama_index.core import VectorStoreIndex,
SimpleDirectoryReader
# 读取文档目录
reader = SimpleDirectoryReader('./docs')
documents = reader.load_data()
print(f"加载了 {len(documents)} 个文档")
# 创建向量索引
index = VectorStoreIndex.from_documents(documents)
# 持久化索引 (避免重复创建)
index.storage_context.persist(persist_dir="./storage")
python
从存储加载索引
from llama_index.core import StorageContext,
load_index_from_storage
# 检查索引是否已存在
persist_dir = "./storage"
if os.path.exists(persist_dir):
# 从存储中加载索引 (快速启动)
storage_context =
StorageContext.from_defaults(persist_dir=persist_dir)
index = load_index_from_storage(storage_context)
print("从存储加载索引成功")
else:
# 创建新索引
index = VectorStoreIndex.from_documents(documents)2、react和工具集成
将retrieve_tool作为一个函数插到agent上(文档解析)
python
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
# 创建查询引擎
query_engine = index.as_query_engine(similarity_top_k=5)
# 定义检索工具
def retrieve_documents(query: str) -> str:
"""从文档中检索相关信息"""
response = query_engine.query(query)
return str(response)
# 封装为 FunctionTool
retrieve_tool =
FunctionTool.from_defaults(fn=retrieve_documents)
# 创建 ReAct Agent
agent = ReActAgent.from_tools(
tools=[retrieve_tool],
llm=llm,
verbose=True, # 显示思考过程
system_prompt="你是一个乐于助人的AI助手,可以从文档中检索信息",
)3、完整RAG问答流程
有一个向量检索,然后相似度计算匹配的过程,查找rag数据库得到答案。
python
# 配置 LLM 和 Embedding
llm = DashScope(model="deepseek-v3", api_key=api_key)
embed_model = DashScopeEmbedding(model_name="text-embedding-v2", api_key=api_key)
#向量检索,可以做相似度计算
Settings.llm = llm
Settings.embed_model = embed_model
# 加载/创建索引
index = load_documents_and_create_index('./docs')
# 创建 Agent 和检索器
agent, retriever = create_agent(index, llm)
# 查询
query = "介绍下雇主责任险"
# 先展示召回的文档内容
retrieved_nodes = retriever.retrieve(query)
for i, node in enumerate(retrieved_nodes):
print(f"文档片段 {i+1}: {node.text[:200]}...")
print(f"相似度分数: {node.score}")
# 使用 Agent 回答
response = agent.chat(query)
print(response)Qwen-Agent - 轻量级的全能选手
阿里生态亲儿子,对 Tool Use 和 Code Interpreter 支持好,轻量、灵活,适合快速构建工具调用型 Agent。
1、核心概念
指令跟随优化:
Qwen-Agent 是专门为 Qwen 模型(及其强大的 Tool Calling 能力)定制的。
它不如 LangChain 抽象,但跑得快,同时还有长文本优势。
Code Interpreter (沙箱): 这是它的杀手锏。不同于其他框架只调用外部 API,Qwen-Agent 内置了代码执行沙箱,允许LLM 自己写 Python 代码来画图、做数据分析,自我修正错误 。
2、装饰器模式注册工具
@register_tool('name') 一行代码完成注册
description 自动生成工具描述供 LLM 理解
parameters 定义参数约束,LLM 自动解析
3、code interpreter:沙箱代码执行
在一个安全隔离的环境里自动生成python代码,捕获输出、图像、文件,自动修正重试。
配置工具列表
tools = 'my_image_gen', 'code_interpreter'
code_interpreter 是框架自带工具,可以:
- 下载文件 (requests.get)
- 处理图像 (PIL)
- 数据分析 (pandas)
- 绑图展示 (matplotlib)
system_instruction = ''' 你是一个乐于助人的 AI 助手。
在收到用户的请求后,你应该:
- 首先绘制一幅图像,得到图像的 url ,
- 然后运行代码 requests.get 以下载该图像,
- 最后从给定的文档中选择一个图像操作进行图像处理。
用 plt.show() 展示图像。 '''
4、多文档支持
from qwen_agent.agents import Assistant
获取文件夹下所有文件
file_dir = os.path.join('./', 'docs')
files = \[\]
if os.path.exists(file_dir):
for file in os.listdir(file_dir):
file_path = os.path.join(file_dir, file)
if os.path.isfile(file_path):
files.append(file_path)
print('files=', files)创建 Assistant ,传入文件列表
bot = Assistant(
llm=llm_cfg,#大模型定义
system_message=system_instruction,#系统提示词定义
function_list=tools,#工具列表(插件)
files=files # 文档文件列表(对应知识库)
)
#智能体就具备了知识库的能力
bot.run()
query代表用户的问题
(1)先从files里面找到相关的知识chunks(形成一些片段)
(2)system prompt + chunk + tool 说明给到LLM进行推理
5、流式输出对话
python
# 对话历史
messages = []
# 用户查询
query = "介绍下雇主责任险"
messages.append({'role': 'user', 'content': query})
# 流式输出
current_index = 0
for response in bot.run(messages=messages):
# 获取增量内容
current_response = response[0]['content'][current_index:]
current_index = len(response[0]['content'])
print(current_response, end='')
# 添加到对话历史,支持多轮对话
messages.extend(response)GUI用户交互界面
tool里面我们也可以定义工作流,成为一个新tool。tool里面也可以嵌套其他的新接口。
所以怎么选呢?
选 LangChain:如果你要开发通用的 AI 应用,需要灵活控制流程,或者需要切换多种模型。
选 LlamaIndex:如果你主要做 RAG(企业知识库),手里有一堆 PDF/Word/Excel 要处理。
选 Qwen-Agent:如果你主要用 Qwen 模型,需要做数据分析(Code Interpreter)或处理超长文档(1M Context)。
选 AutoGen:如果任务太复杂,一个人(Agent)干不完,需要团队(多角色)吵架/协作才能出结果。
实践:多文件智能问答
我们要搭建一个 保险产品智能问答Agent,用于帮助用户快速了解各类保险产品的详细信息。
用RAG(因为LLM没有私有数据,避免模型幻觉,可追溯来源)
用户问题 -> 向量检索 -> 召回相关文档 -> LLM生成回答
这里用langchain做了一个示例,在每段代码中做了详细的注释。
python
#!/usr/bin/env python
# coding: utf-8
"""
基于 LangChain 的多文件 RAG 应用
支持加载 docs 文件夹下的多种格式文件进行问答
"""
import os
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 获取 API Key
DASHSCOPE_API_KEY = os.getenv('DASHSCOPE_API_KEY')
if not DASHSCOPE_API_KEY:
raise ValueError("请设置环境变量 DASHSCOPE_API_KEY")
# 步骤 1:加载文档并创建索引
def load_documents_and_create_index(file_dir: str = './docs', persist_dir: str = './langchain_storage'):
"""加载文档文件夹中的所有文件并创建向量索引"""
# 创建嵌入模型
#把embedding理解成一种检索语言、规范
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 检查索引是否已存在
if os.path.exists(persist_dir):
try:
# 从存储中加载索引
vector_store = FAISS.load_local(
persist_dir,
embeddings,
allow_dangerous_deserialization=True
)
print("从存储加载索引成功")
return vector_store#(有现成的直接加载现成的,没有的重新添加)
except Exception as e:
print(f"加载索引失败: {e},将重新创建索引")
# 如果索引不存在,创建新索引
if not os.path.exists(file_dir):
print(f"文档目录 {file_dir} 不存在")
return None
# 加载目录下的所有 txt 文件(这里只解析txt,没考虑pdf)
loader = DirectoryLoader(
file_dir,
glob="**/*.txt",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"}
)
documents = loader.load()
print(f"加载了 {len(documents)} 个文档")
if not documents:
print("没有找到任何文档")
return None
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
#颗粒度不是一个文件了,是一个片段chunk,定义片段大小
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
chunks = text_splitter.split_documents(documents)
print(f"文本被分割成 {len(chunks)} 个块")
# 创建向量索引(向量数据库就建好了)
vector_store = FAISS.from_documents(chunks, embeddings)
# 保存索引
os.makedirs(persist_dir, exist_ok=True)
vector_store.save_local(persist_dir)
print(f"索引已保存到 {persist_dir}")
return vector_store
# 步骤 2:创建问答链
def create_qa_chain(llm):
"""创建 QA 问答链 (LangChain 1.x LCEL 写法)"""
# QA Prompt 模板
qa_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个乐于助人的AI助手。
根据以下上下文内容回答用户的问题。如果上下文中没有相关信息,请如实说明。
你总是用中文回复用户。
上下文内容:
{context}"""),
("human", "{question}")
])
# 创建问答链 (LCEL 管道语法)
qa_chain = qa_prompt | llm | StrOutputParser()
return qa_chain
# 步骤 3:主函数
def main():
"""主函数"""
# 配置 LLM
llm = ChatTongyi(
model_name="deepseek-v3",
dashscope_api_key=DASHSCOPE_API_KEY
)
# 加载文档并创建索引
vector_store = load_documents_and_create_index()
if vector_store is None:
print("无法创建索引,程序退出")
return
# 创建问答链
qa_chain = create_qa_chain(llm)
# 执行查询
query = "介绍下雇主责任险"
print(f"\n用户查询: {query}\n")
# 相似度搜索,找到相关文档
docs = vector_store.similarity_search(query, k=5)
# 显示召回的文档内容
print("===== 召回的文档内容 =====")
if docs:
for i, doc in enumerate(docs):
print(f"\n文档片段 {i+1}:")
print(f"内容: {doc.page_content[:200]}...")
print(f"来源: {doc.metadata.get('source', '未知')}")
else:
print("没有召回任何文档内容")
print("===========================\n")
# 格式化上下文(QA提示词模板中空出来的固定参数)
context = "\n\n".join(doc.page_content for doc in docs)
# 执行问答链
print("===== AI 回复 =====")
response = qa_chain.invoke({"context": context, "question": query})
print(response)
print("===================\n")
if __name__ == "__main__":
main()运行结果如下:
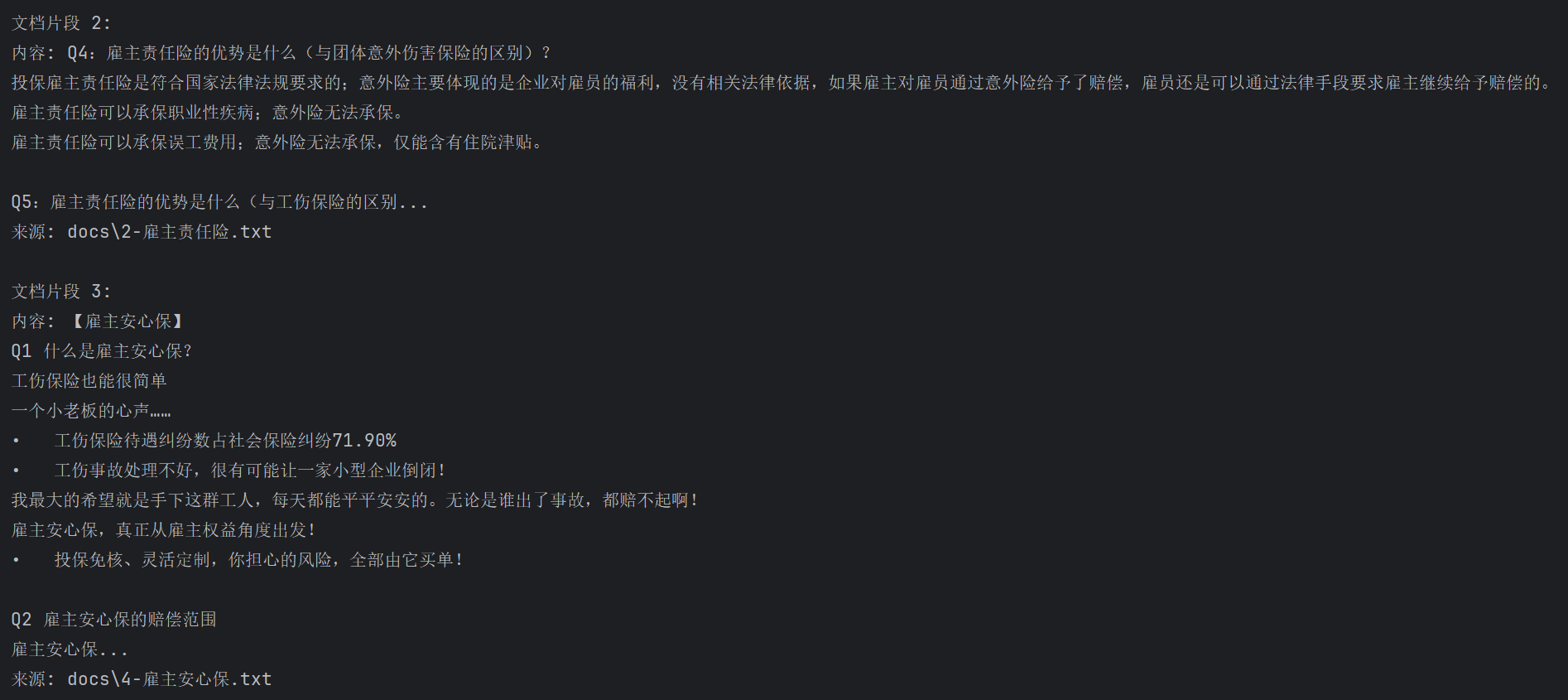
用户问的query是介绍下雇主责任险
根据我们建立的知识库,检索了五个文档片段。每个片段得到一个docs(相似度),从而拼成一个总的context,将query和context给到llm后,得到了AI回复。



我们再用llamaindex来看一下,逻辑是完全一致的
python
#!/usr/bin/env python
# coding: utf-8
import os
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
Settings,
StorageContext,
load_index_from_storage,
)
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
from llama_index.llms.dashscope import DashScope
from llama_index.embeddings.dashscope import DashScopeEmbedding
# 步骤 1:配置 LLM 和 Embedding
def setup_llm_and_embedding():
"""配置 LLM 和 Embedding,使用 DashScope"""
api_key = os.getenv('DASHSCOPE_API_KEY')
if not api_key:
raise ValueError("请设置环境变量 DASHSCOPE_API_KEY")
# 使用 DashScope LLM
llm = DashScope(
model="deepseek-v3",
api_key=api_key,
temperature=0.7,
top_p=0.8,
)
# 使用 DashScope Embedding
embed_model = DashScopeEmbedding(
model_name="text-embedding-v2",
api_key=api_key,
)
return llm, embed_model
# 步骤 2:加载文档并创建索引
def load_documents_and_create_index(file_dir: str = './docs'):
"""加载文档文件夹中的所有文件并创建向量索引"""
# 检查索引是否已存在
persist_dir = "./storage"
if os.path.exists(persist_dir):
try:
# 从存储中加载索引
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
index = load_index_from_storage(storage_context)
print("从存储加载索引成功")
return index
except Exception as e:
print(f"加载索引失败: {e},将重新创建索引")
# 如果索引不存在,创建新索引
if not os.path.exists(file_dir):
print(f"文档目录 {file_dir} 不存在")
return None
# 读取文档
reader = SimpleDirectoryReader(file_dir)
documents = reader.load_data()
if not documents:
print("没有找到任何文档")
return None
print(f"加载了 {len(documents)} 个文档")
# 创建向量索引
index = VectorStoreIndex.from_documents(documents)
# 保存索引
index.storage_context.persist(persist_dir=persist_dir)
print(f"索引已保存到 {persist_dir}")
return index
# 步骤 3:创建智能体
def create_agent(index, llm):
"""创建 ReAct 智能体"""
# 创建检索器
retriever = index.as_retriever(similarity_top_k=5)
# 创建查询引擎(用于检索工具)
query_engine = index.as_query_engine(similarity_top_k=5)
# 定义系统提示词
system_instruction = '''你是一个乐于助人的AI助手。
你可以从给定的文档中检索相关信息来回答用户的问题。
你总是用中文回复用户。'''
# 创建检索工具(用于查询文档)
def retrieve_documents(query: str) -> str:
"""从文档中检索相关信息"""
response = query_engine.query(query)
return str(response)
retrieve_tool = FunctionTool.from_defaults(fn=retrieve_documents)
# 创建智能体
agent = ReActAgent.from_tools(
tools=[retrieve_tool],
llm=llm,
verbose=True,
system_prompt=system_instruction,
)
return agent, retriever
# 步骤 4:主函数
def main():
"""主函数"""
# 配置 LLM 和 Embedding
llm, embed_model = setup_llm_and_embedding()
Settings.llm = llm
Settings.embed_model = embed_model
# 加载文档并创建索引
index = load_documents_and_create_index()
if index is None:
print("无法创建索引,程序退出")
return
# 创建智能体
agent, retriever = create_agent(index, llm)
# 执行查询
query = "介绍下雇主责任险"
print(f"\n用户查询: {query}\n")
# 显示召回的文档内容
print("\n===== 召回的文档内容 =====")
retrieved_nodes = retriever.retrieve(query)
if retrieved_nodes:
for i, node in enumerate(retrieved_nodes):
print(f"\n文档片段 {i+1}:")
print(f"内容: {node.text[:200]}...") # 只显示前200个字符
print(f"元数据: {node.metadata}")
if hasattr(node, 'score'):
print(f"相似度分数: {node.score}")
else:
print("没有召回任何文档内容")
print("===========================\n")
# 使用智能体回答问题
print("\n===== 智能体回复 =====")
response = agent.chat(query)
print(response)
print("======================\n")
if __name__ == "__main__":
main()运行结果如下
python
[nltk_data] Error loading punkt_tab: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
incorrect startxref pointer(1)
加载了 42 个文档
索引已保存到 ./storage
用户查询: 介绍下雇主责任险
===== 召回的文档内容 =====
文档片段 1:
内容: Q4:雇主责任险的优势是什么(与团体意外伤害保险的区别)?
投保雇主责任险是符合国家法律法规要求的;意外险主要体现的是企业对雇员的福利,没有相关法律依据,如果雇主对雇员通过意外险给予了赔偿,雇员还是可以通过法律手段要求雇主继续给予赔偿的。
雇主责任险可以承保职业性疾病;意外险无法承保。
雇主责任险可以承保误工费用;意外险无法承保,仅能含有住院津贴。
Q5:雇主责任险的优势是什么(与工伤...
元数据: {'file_path': 'D:\\学校\\大四下\\ai\\5-AI框架设计与选型\\CASE-多文件智能问答Agent\\docs\\2-雇主责任险.txt', 'file_name': '2-雇主责任险.txt', 'file_type': 'text/plain', 'file_size': 4991, 'creation_date': '2026-02-01', 'last_modified_date': '2026-02-01'}
相似度分数: 0.7164722253539384
文档片段 2:
内容: 【雇主责任险】
Q1 雇员意外事故给企业造成的损害有多大?甚至可能让一家公司倒闭!!
员工出外勤不幸遇到车祸被撞高位截瘫
公司赔偿近一百万
抽干公司流动资金
无力维持生产
走破产程序...
Q2 雇主责任险的保障范围和其他亮点
1. 保障
只要有用工需求的单位,都可以购买雇主责任险。
2. 保障范围:
死亡赔偿金
伤残赔偿金
医疗费用
误工费用(C款不赔)
法律诉...
元数据: {'file_path': 'D:\\学校\\大四下\\ai\\5-AI框架设计与选型\\CASE-多文件智能问答Agent\\docs\\2-雇主责任险.txt', 'file_name': '2-雇主责任险.txt', 'file_type': 'text/plain', 'file_size': 4991, 'creation_date': '2026-02-01', 'last_modified_date': '2026-02-01'}
相似度分数: 0.7163853122787981
文档片段 3:
内容: 可以,根据雇主责任险条款中的释义,雇员是指与被保险人签订有劳动合同或存在事实劳动合同关系,接受被保险人给付薪金、工资,年满十六周岁且不超过65周岁的人员及其他按国家规定审批的未满十六周岁的特殊人员,包括正式在册职工、短期工、临时工、季节工和徒工等。
Q10:雇主责任险的医疗费什么药能赔,什么药不能赔?
非本次事故的既往症用药,需剔除,对于本次事故产生的,需参考保单约定剔除非医保用药。
...
元数据: {'file_path': 'D:\\学校\\大四下\\ai\\5-AI框架设计与选型\\CASE-多文件智能问答Agent\\docs\\2-雇主责任险.txt', 'file_name': '2-雇主责任险.txt', 'file_type': 'text/plain', 'file_size': 4991, 'creation_date': '2026-02-01', 'last_modified_date': '2026-02-01'}
相似度分数: 0.5771123333625413
文档片段 4:
内容: 【雇主安心保】
Q1 什么是雇主安心保?
工伤保险也能很简单
一个小老板的心声......
• 工伤保险待遇纠纷数占社会保险纠纷71.90%
• 工伤事故处理不好,很有可能让一家小型企业倒闭!
我最大的希望就是手下这群工人,每天都能平平安安的。无论是谁出了事故,都赔不起啊!
雇主安心保,真正从雇主权益角度出发!
• 投保免核、灵活定制,你担心的风险,全部由它买单!
Q2 雇主安心保的...
元数据: {'file_path': 'D:\\学校\\大四下\\ai\\5-AI框架设计与选型\\CASE-多文件智能问答Agent\\docs\\4-雇主安心保.txt', 'file_name': '4-雇主安心保.txt', 'file_type': 'text/plain', 'file_size': 2035, 'creation_date': '2026-02-01', 'last_modified_date': '2026-02-01'}
相似度分数: 0.5255419482538756
文档片段 5:
内容: (四)可选责任:住院津贴责任
保险期间内,被保险人因遭受保险单载明的意外伤害事故,并自事故发生之日起一百
八十日内因该事故在符合释义医院进行住院治疗,保险人就被保险人的合理住院天数,按
照保险单载明的意外伤害住院津贴日额计算给付"意外伤害住院津贴保险金"。
被保险人多次遭受保险单载明的意外伤害事故进行住院治疗,保险人均按上述规定分
别给付意外伤害住院津贴保险金,但保险人一次或多次累计给付意外伤害住...
元数据: {'page_label': '2', 'file_name': '平安产险交通出行意外伤害保险(互联网版)产品说明.pdf', 'file_path': 'D:\\学校\\大四下\\ai\\5-AI框架设计与选型\\CASE-多文件智能问答Agent\\docs\\平安产险交通出行意外伤害保险(互联网版)产品说明.pdf', 'file_type': 'application/pdf', 'file_size': 83203, 'creation_date': '2026-02-01', 'last_modified_date': '2026-02-01'}
相似度分数: 0.44410424247370356
===========================
===== 智能体回复 =====
> Running step 3b74fd28-3246-4dac-a3d7-70e4c1ec34b8. Step input: 介绍下雇主责任险
Thought: The current language of the user is: Chinese. I need to use a tool to help me answer the question.
Action: retrieve_documents
Action Input: {'query': '雇主责任险'}
Observation: 雇主责任险是一种保险产品,它为企业提供保障,当雇员在工作过程中遭受意外事故或职业病导致伤残、死亡时,保险公司将根据合同约定承担相应的赔偿责任。这种保险有助于转嫁企业对员工的风险责任,并且符合国家法律法规的要求。相较于团体意外伤害保险和工伤保险,雇主责任险具有以下优势:
- 它可以承保因职业性疾病导致的损失。
- 包含误工费用的赔付。
- 即使企业已经为员工购买了工伤保险或团体意外险,仍然可以选择额外购买雇主责任险来增加保障。
- 该保险覆盖上下班途中及因公外出期间发生的事故。
- 对于没有签订正式劳动合同但存在事实劳动关系的临时工、学徒工等也能提供保障。
此外,雇主责任险还能帮助企业降低用工风险、减少工伤纠纷,并且部分费用可以在税前列支,减轻企业的税收负担。其保费受客户行业类型、雇员工种、赔偿限额以及投保人数等因素影响。
> Running step 3c4b3587-e191-47bd-b30e-48b2c7c00c9c. Step input: None
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: 雇主责任险是一种为企业提供保障的保险产品。当雇员在工作过程中因意外事故或职业病导致伤残、死亡时,保险公司将根据合同约定承担相应的赔偿责任。这种保险有助于转嫁企业对员工的风险责任,并且符合国家法律法规的要求。
相较于团体意外伤害保险和工伤保险,雇主责任险具有以下优势:
- 可以承保因职业性疾病导致的损失。
- 包含误工费用的赔付。
- 即使企业已经为员工购买了工伤保险或团体意外险,仍然可以选择额外购买雇主责任险来增加保障。
- 该保险覆盖上下班途中及因公外出期间发生的事故。
- 对于没有签订正式劳动合同但存在事实劳动关系的临时工、学徒工等也能提供保障。
此外,雇主责任险还能帮助企业降低用工风险、减少工伤纠纷,并且部分费用可以在税前列支,减轻企业的税收负担。其保费受客户行业类型、雇员工种、赔偿限额以及投保人数等因素影响。
雇主责任险是一种为企业提供保障的保险产品。当雇员在工作过程中因意外事故或职业病导致伤残、死亡时,保险公司将根据合同约定承担相应的赔偿责任。这种保险有助于转嫁企业对员工的风险责任,并且符合国家法律法规的要求。
相较于团体意外伤害保险和工伤保险,雇主责任险具有以下优势:
- 可以承保因职业性疾病导致的损失。
- 包含误工费用的赔付。
- 即使企业已经为员工购买了工伤保险或团体意外险,仍然可以选择额外购买雇主责任险来增加保障。
- 该保险覆盖上下班途中及因公外出期间发生的事故。
- 对于没有签订正式劳动合同但存在事实劳动关系的临时工、学徒工等也能提供保障。
此外,雇主责任险还能帮助企业降低用工风险、减少工伤纠纷,并且部分费用可以在税前列支,减轻企业的税收负担。其保费受客户行业类型、雇员工种、赔偿限额以及投保人数等因素影响。
======================
进程已结束,退出代码为 0总体是没有问题的,但是这里出现了一些报错,我们来看一下:
nltk_data\] Error loading punkt_tab: \
nltk_data getaddrinfo failed>
incorrect startxref pointer(1)
1.NLTK 加载 punkt_tab 失败 (Errno 11004 getaddrinfo failed)
- 核心原因 :
nltk库需要下载punkt分词数据集,但你的网络环境无法解析 NLTK 数据服务器的域名(DNS 解析失败),常见于国内网络环境或代理配置问题。 punkt_tab是 NLTK 用于文本分句、分词的核心数据集,llamaindex 的 agent 功能依赖它处理自然语言文本。
2. incorrect startxref pointer(1)
- 核心原因 :这个错误来自 PDF 解析环节(llamaindex 内置的 PDF 解析器),通常是因为:
- PDF 文件损坏、格式不规范(比如部分扫描件、加密 PDF、或生成时的格式错误);
- PDF 解析器(如 PyPDF2)对某些特殊 PDF 兼容性不足。
解决的话只需手动下载 NLTK 的 punkt 数据集以及更换 llamaindex 的 PDF 解析器,使用兼容性更好的 PyMuPDFReader 替代默认解析器。这里因为不太影响最后的结果,我们不做更多的演示,大家后面可以自己试一下。
再来看一下千问的
python
import urllib.parse
import json5
from qwen_agent.agents import Assistant
from qwen_agent.tools.base import BaseTool, register_tool
from qwen_agent.gui import WebUI
import os
# 步骤 1:添加一个名为 `my_image_gen` 的自定义工具。
@register_tool('my_image_gen')
class MyImageGen(BaseTool):
# `description` 用于告诉智能体该工具的功能。
description = 'AI 绘画(图像生成)服务,输入文本描述,返回基于文本信息绘制的图像 URL。'
# `parameters` 告诉智能体该工具有哪些输入参数。
parameters = [{
'name': 'prompt',
'type': 'string',
'description': '期望的图像内容的详细描述',
'required': True
}]
def call(self, params: str, **kwargs) -> str:
# `params` 是由 LLM 智能体生成的参数。
prompt = json5.loads(params)['prompt']
prompt = urllib.parse.quote(prompt)
return json5.dumps(
{'image_url': f'https://image.pollinations.ai/prompt/{prompt}'},
ensure_ascii=False)
# 步骤 2:配置您所使用的 LLM。
llm_cfg = {
# 使用 DashScope 提供的模型服务:
'model': 'deepseek-v3',
'model_server': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key': os.getenv('DASHSCOPE_API_KEY'), # 从环境变量获取API Key
'generate_cfg': {
'top_p': 0.8
}
}
# 步骤 3:定义系统提示词和工具列表
system_instruction = '''你是一个乐于助人的AI助手。
在收到用户的请求后,你应该:
- 首先绘制一幅图像,得到图像的url,
- 然后运行代码`requests.get`以下载该图像的url,
- 最后从给定的文档中选择一个图像操作进行图像处理。
用 `plt.show()` 展示图像。
你总是用中文回复用户。'''
tools = ['my_image_gen', 'code_interpreter'] # `code_interpreter` 是框架自带的工具,用于执行代码。
# 获取文件夹下所有文件
def get_doc_files():
"""获取 docs 文件夹下的所有文件"""
file_dir = os.path.join('./', 'docs')
files = []
if os.path.exists(file_dir):
# 遍历目录下的所有文件
for file in os.listdir(file_dir):
file_path = os.path.join(file_dir, file)
if os.path.isfile(file_path): # 确保是文件而不是目录
files.append(file_path)
print('加载的文件:', files)
return files
# ====== 初始化智能体服务 ======
def init_agent_service():
"""初始化智能体服务"""
try:
# 获取文档文件列表
files = get_doc_files()
bot = Assistant(
#这里可以设置name = "保险智能问答助手",
llm=llm_cfg,
system_message=system_instruction,
function_list=tools,
files=files
)
print("智能体初始化成功!")
return bot
except Exception as e:
print(f"智能体初始化失败: {str(e)}")
raise
def app_tui():
"""终端交互模式
提供命令行交互界面,支持:
- 连续对话
- 文件输入
- 实时响应
"""
try:
# 初始化助手
bot = init_agent_service()
# 对话历史
messages = []
while True:
try:
# 获取用户输入
query = input('\n用户问题: ')
# 输入验证
if not query:
print('用户问题不能为空!')
continue
# 构建消息
messages.append({'role': 'user', 'content': query})
print("正在处理您的请求...")
# 运行助手并处理响应
response = []
current_index = 0
for response in bot.run(messages=messages):
if current_index == 0:
# 尝试获取并打印召回的文档内容
if hasattr(bot, 'retriever') and bot.retriever:
print("\n===== 召回的文档内容 =====")
retrieved_docs = bot.retriever.retrieve(query)
if retrieved_docs:
for i, doc in enumerate(retrieved_docs):
print(f"\n文档片段 {i+1}:")
print(f"内容: {doc.page_content[:200]}...")
print(f"元数据: {doc.metadata}")
else:
print("没有召回任何文档内容")
print("===========================\n")
current_response = response[0]['content'][current_index:]
current_index = len(response[0]['content'])
print(current_response, end='')
# 将机器人的回应添加到聊天历史
messages.extend(response)
print("\n")
except KeyboardInterrupt:
print("\n\n退出程序")
break
except Exception as e:
print(f"处理请求时出错: {str(e)}")
print("请重试或输入新的问题")
except Exception as e:
print(f"启动终端模式失败: {str(e)}")
def app_gui():
"""图形界面模式,提供 Web 图形界面"""
try:
print("正在启动 Web 界面...")
# 初始化助手
bot = init_agent_service()
# 配置聊天界面,列举一些典型问题
chatbot_config = {
'prompt.suggestions': [
'介绍下雇主责任险',
'帮我生成一幅关于春天的图像',
'分析一下文档中的关键信息',
]
}
print("Web 界面准备就绪,正在启动服务...")
# 启动 Web 界面
WebUI(
bot,
chatbot_config=chatbot_config
).run()
except Exception as e:
print(f"启动 Web 界面失败: {str(e)}")
print("请检查网络连接和 API Key 配置")
if __name__ == '__main__':
# 运行模式选择
app_gui() # 图形界面模式(默认)
# app_tui() # 终端交互模式(可选)千问这个代码最大的不同是他的gui交互界面,运行之后会给这么一个结果和一个IP地址。
正在启动 Web 界面...
加载的文件: './docs\\\\1-平安商业综合责任保险(亚马逊).txt', './docs\\\\2-雇主责任险.txt', './docs\\\\3-平安企业团体综合意外险.txt', './docs\\\\4-雇主安心保.txt', './docs\\\\5-施工保.txt', './docs\\\\6-财产一切险.txt', './docs\\\\7-平安装修保.txt', './docs\\\\平安产险交通出行意外伤害保险(互联网版)产品说明.pdf', './docs\\\\平安产险交通工具意外伤害保险(互联网版)条款.pdf', './docs\\\\平安企业团体综合意外险(互联网版)适用条款.pdf', './docs\\\\平安商业综合责任保险(亚马逊).pdf', './docs\\\\平安境内紧急医疗救援服务条款.pdf', './docs\\\\平安附加疾病身故保险条款.pdf'
智能体初始化成功!
Web 界面准备就绪,正在启动服务...
* Running on local URL: http://127.0.0.1:7860
进去之后就是一个简易的和AI对话的web页面
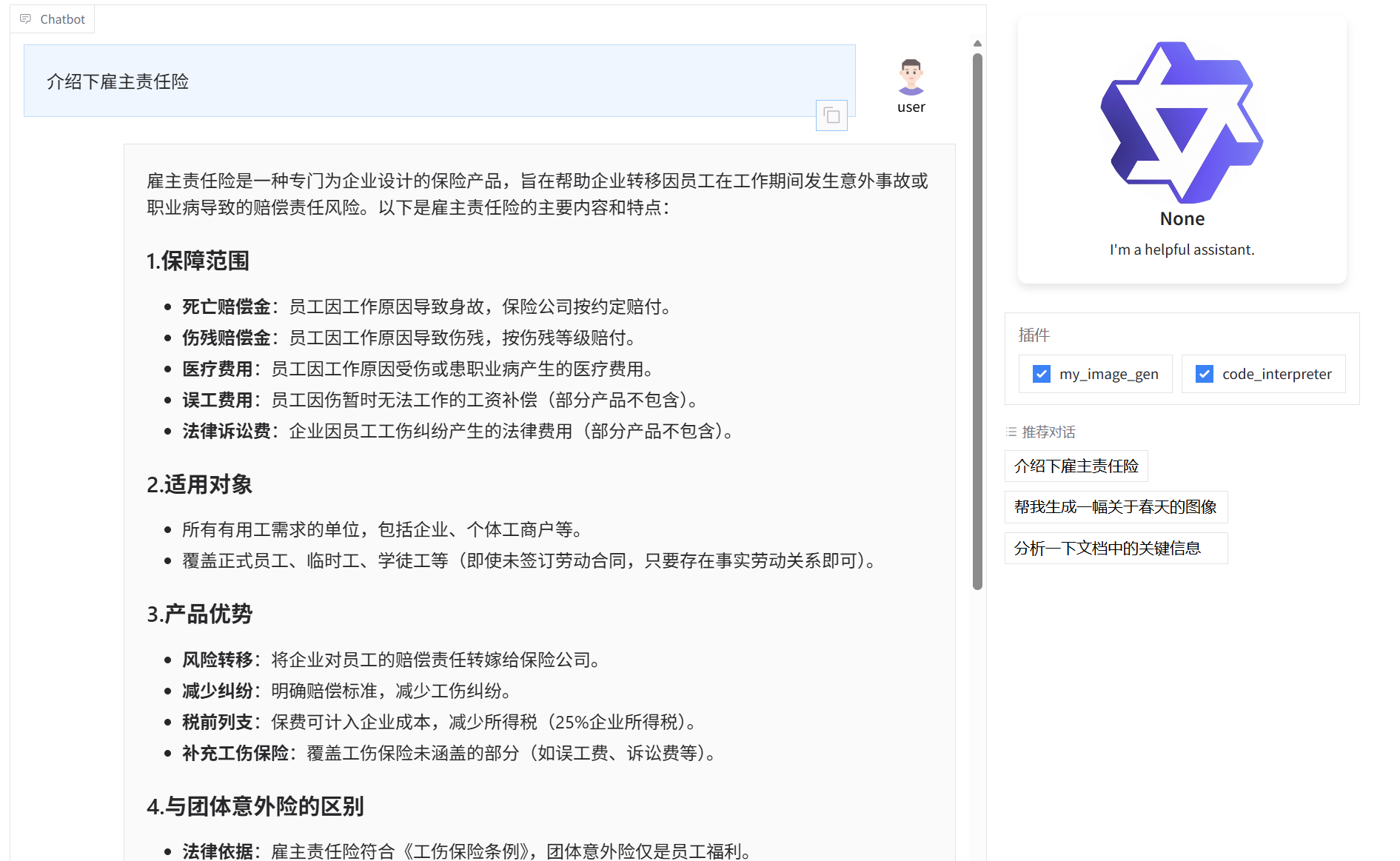
更加的直观了然。千问内置了web UI ,使得相关的web页面展示更加的方便。
| 维度 | langchain | llamaindex | qwen |
| 定位 | 全能型框架 | rag专家 | 轻量级agent |
| 文件加载 | DirectoryLoader | SimpleDirectoryReader | files参数 |
| 向量存储 | FAISS/Chroma等 | VectorStoreIndex | 内置 |
| 问答方式 | LCEL 管道| | ReAct agent | bot.run() |
| 索引持久化 | save_local() | persist() | 无 |
| web UI | 需集成Gradio | 集成 | 内置webUI |
| 代码执行 | 集成 | 集成 | 内置code_interpreter |
|---|
AutoGen 多智能体框架
AutoGen 是微软开源的多智能体对话框架,用于构建多个 AI Agent 协作完成复杂任务。
它的核心理念是让 Agent 之间通过自然语言对话来协作,而非硬编码的函数调用。
2025 年 10 月起,微软将 AutoGen 置为维护模式------仅修漏洞,不再新增功能;所有新特性都做到 Agent Framework 上。 官方文档明确把 Agent Framework 称为下一代 Semantic Kernel 与 AutoGen,鼓励新项目直接迁移
多智能体所以它的基本单元是agent,每个agent具有不同的属性。
像name作为名字标识区分发言者,llm_config确定llm配置包括模型、apikey等参数,tools规定可调用的外部工具函数,扩展agent能力。
常见agent有,conversableagent:基础对话,灵活,完全自定义;assistantagent:助手agent,默认由llm驱动;userproxyagent:用户代理,可执行代码、调用工具、请求人工输入。
相当于一堆agent在一个群聊里面进行协作,groupchat。

python
# __init__.py - InvestmentCommittee.analyze() 方法
from autogen import GroupChat, GroupChatManager
# 创建群聊,设定发言顺序
group_chat = GroupChat(
agents=[
self.data_agent, # 1. 数据员先获取数据
self.analyst_agent, # 2. 分析师进行分析
self.risk_agent, # 3. 风控官评估风险
self.trader_agent # 4. 交易员给出建议
],
messages=[],
max_round=8, # 4个Agent各发言1-2次
speaker_selection_method="round_robin", # 按顺序轮流发言
)
# 创建群聊管理器
manager = GroupChatManager(
groupchat=group_chat,
llm_config=self.data_agent.llm_config,
)
# 发起对话
result = self.data_agent.initiate_chat(
manager,
message="用户查询: 分析一下宁德时代能不能买",
)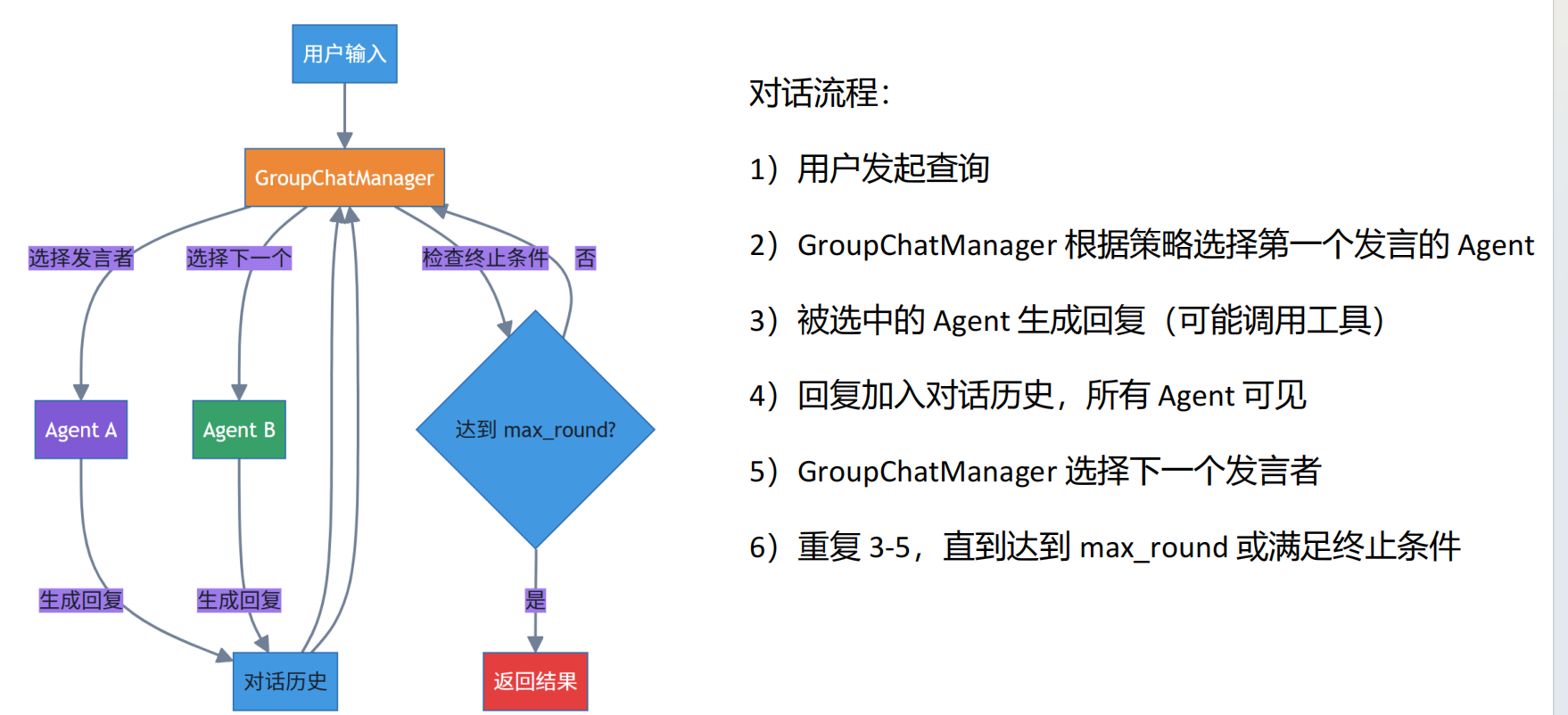
如果你的任务有明确的执行顺序,用 round_robin;如果需要灵活讨论,用 auto。
但很多时候,在企业需求中更追求的是稳定、成熟,所以工作流的使用更常见更频繁。
最后,我们来看一张总结。
|------------|------------|---------------------------------------|
| 企业知识库问答 | llamaindex | 专业文档处理、多项检索策略(向量、关键词、混合)、索引持久化、支持增量更新 |
| 复杂业务流程 | langchain | LCEL、丰富的组件生态、和其他框架组合使用 |
| 快速demo/poc | qwen | 配置简单、内置web UI、无需前端开发、沙箱 |
| 多人协作 | autogen | 多智能体协同对话、支持角色自定义和任务分工、内置群聊管理和执行控制 |
纯粹课堂笔记,有任何侵权,联系我,马上删。