论文标题 : Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models(基于可扩展查找的条件记忆:大型语言模型稀疏性的新维度)
论文主题:提出 Engram 条件记忆模块,为大语言模型引入新的稀疏性维度,与 MoE 形成互补,提升知识检索与推理效率。
论文链接↓↓↓
https://arxiv.org/pdf/2601.07372v1
DeepSeek团队于2026年1月12日最新发布了一篇重要论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,这是一项突破性的研究。
论文系统性地论证了"条件记忆"作为下一代稀疏模型核心建模原型的必要性。Engram模块通过算法-系统协同设计,不仅显著提升了模型在知识、推理、代码和长上下文等多方面的能力,而且通过解耦存储与计算,为突破GPU内存限制、实现极大规模参数扩展提供了切实可行的路径。这项工作为未来高效、高性能的大语言模型架构设计开辟了新的方向。核心是提出Engram条件记忆模块,通过"查算分离"的双稀疏轴设计,将静态知识检索与动态推理计算解耦,既解决了传统Transformer用昂贵计算模拟记忆的低效问题,又为大模型性能与成本优化提供了全新范式。本文将从核心痛点、技术架构、关键发现、性能验证、产业价值与未来方向展开全面解读。(本文内容由AI总结论文原文生成,内容来源网络,进行整合再创作)
一、核心痛点:传统大模型的"记忆-计算"混同困境
当前主流大模型(包括Dense Transformer与MoE架构)均存在一个结构性缺陷:用同一套高成本神经计算,同时承担"静态记忆检索"与"动态组合推理"两类完全不同的任务 ,缺乏原生的"知识查找"机制,导致算力严重浪费与能力瓶颈。
1. 两类任务的本质错配
论文通过"戴安娜王妃(Diana, Princess of Wales)"实体识别案例,直观揭示了这一问题:
- 静态记忆任务 :如实体名、固定短语、公式定理(例:"法国首都是巴黎""水的化学式是H₂O"),本质是"查表",答案固定且重复出现。但传统Transformer需消耗6层网络,逐层拼凑"Wales是英国地区→Princess of Wales是头衔→最终组合为戴安娜王妃",用矩阵乘法(O(d²)复杂度)模拟简单查表(O(1)复杂度),算力浪费达10万倍。
- 动态推理任务:如多步逻辑推导、代码调试、数学证明(例:"解一道微积分题"),本质是"计算",需动态生成答案。但这类任务的算力被静态记忆占用,导致深层推理能力受限。
2. MoE架构的局限性
MoE(混合专家模型)虽通过"条件计算"实现参数稀疏激活(仅激活部分专家),但仅解决了"哪些参数参与计算"的问题,未解决"是否需要计算"的根本矛盾:
- 对静态记忆任务,MoE仍需调用专家网络进行矩阵运算,无法绕开"用计算模拟记忆"的低效路径;
- 长文本处理时,局部依赖(如固定搭配)的重复计算占用注意力容量,导致全局上下文"遗忘"(例:32k上下文下信息召回率不足85%)。
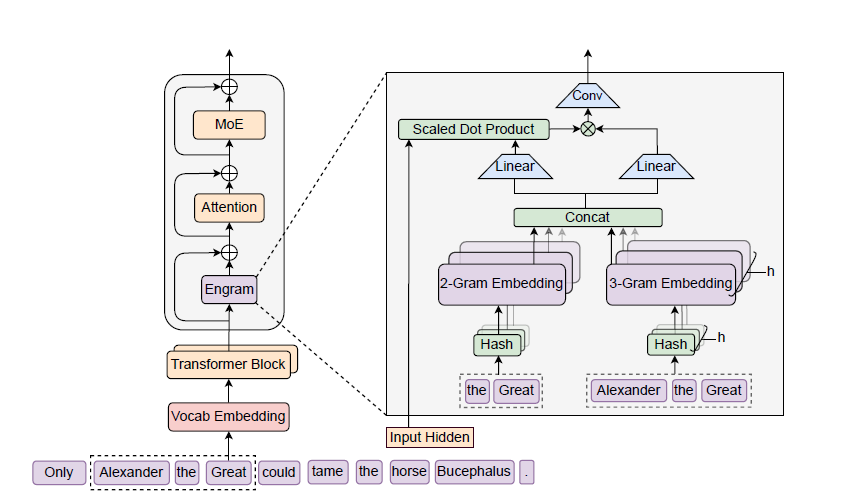
二、技术架构:Engram条件记忆的"查算分离"设计
Engram(神经科学中"记忆痕迹"的含义)是实现"条件记忆"的核心模块,通过现代化改造的N-gram查表机制,与MoE形成"记忆-计算"双稀疏轴,彻底解耦两类任务。其架构可拆解为4个关键环节:
1. 核心设计理念:从"计算模拟记忆"到"直接查表"
Engram的核心逻辑是"该查的不算,该算的专注",类比人脑分工:
- Engram模块:类似"海马体",负责静态知识的存储与O(1)检索;
- MoE/Transformer主干:类似"前额叶皮层",专注动态推理与全局上下文建模。
2. 四大核心组件:解决传统N-gram的两大痛点
传统N-gram因"存储爆炸"(128k词表的3-gram组合达128k³种)与"多义性"(如"Apple"可指水果或公司)被边缘化,Engram通过以下设计实现现代化升级:
|---------|----------------------------------------------------------|-----------------------------------------------------|
| 组件 | 功能描述 | 解决的问题 |
| 分词器压缩 | 通过NFKC规范化、大小写统一,将语义相同但形式不同的Token(如"Apple""apple")映射为同一ID | 词表有效规模缩减23%(128k→98k),降低存储与检索压力 |
| 多头哈希检索 | 对2-gram/3-gram局部上下文,用K个独立哈希函数映射到固定大小的嵌入表,取多头结果拼接 | 实现O(1)常数时间查找,避免存储爆炸(无论N-gram组合多少,表大小固定) |
| 上下文感知门控 | 以当前层隐藏状态为Query,检索到的记忆向量为Key/Value,计算0-1标量门控值(匹配度) | 解决多义性:若记忆与上下文不匹配(如"Apple"在"水果"语境下查"公司"),门控值趋近0,屏蔽噪声 |
| 残差融合 | 将门控后的记忆向量通过残差连接,嵌入Transformer特定层(如第1、15层) | 不破坏原有推理能力,仅补充静态知识,且可灵活插拔 |
3. 系统级优化:CPU主导的"存储-计算"解耦
Engram的确定性查找特性(检索索引仅依赖输入Token,与运行时隐藏状态无关)带来关键工程价值:
- 存储卸载:千亿参数的Engram嵌入表可存于廉价CPU内存(DRAM),而非昂贵GPU显存(HBM);
- 异步预取:GPU计算前序层时,CPU通过PCIe通道异步预取后续层所需记忆向量,通信与计算完全重叠;
- 极低开销:实验显示,即使挂载1000亿参数的Engram表,推理延迟仅增加3%,大幅降低硬件成本。
4.技术实现:三步走
- **分词器压缩与规范化:**分词器压缩与规范化:将原始Token ID映射为"规范ID"(如统一大小写、符号),使128K词表的有效规模减少23.43%,降低N-gram组合复杂度。
- 多头哈希检索:对2-gram、3-gram设置多个哈希头,通过轻量级哈希函数将N-gram序列映射到静态记忆表的索引,实现O(1)复杂度的检索。
- 上下文感知门控:以当前隐藏状态作为动态Query,对检索到的静态记忆进行筛选和调制。门控机制能有效解决多义词问题(如"苹果"指公司还是水果),仅在上下文匹配时激活记忆。
5.生动比喻
- **旧模式:**l考场里一位天才,每次遇到"1+1=?"都要从皮亚诺公理开始推导。
- **新模式:**同一位天才,但被允许带一本《百科全书》进考场。遇到固定知识点直接查阅,将全部智力用于解真正的难题。
- Engram就是这本"百科全书"。
三、关键发现:U型缩放定律------记忆与计算的最优配比
论文最具突破性的结论是稀疏性分配的U型定律:在总参数量与计算预算(FLOPs)固定时,MoE(计算)与Engram(记忆)的参数分配存在最优比例,而非"纯MoE或纯Engram"更优。
1. 实验设计与结果
- 变量:定义分配比例ρ(ρ=MoE稀疏参数占比,1-ρ=Engram稀疏参数占比),从100%(纯MoE)降至40%(Engram主导);
- 结果:验证损失呈现清晰U型曲线------当ρ=75%-80%(即20%-25%稀疏参数分配给Engram)时,损失最低,性能最优。
2. 定律解读:记忆与计算不可替代
- 纯MoE(ρ=100%):模型缺乏专用记忆,被迫用深层网络重建静态模式(如6层识别"戴安娜王妃"),浪费算力;
- 纯Engram(ρ<70%):模型失去条件计算能力,无法处理动态推理(如数学证明),陷入"博闻强记但不会思考"的困境(类比博尔赫斯小说中"能记住所有树叶却无法理解'树'概念"的富内斯);
- 最优配比(ρ=75%-80%):记忆承担静态知识,释放早期层算力;计算专注深层推理,形成互补效应。
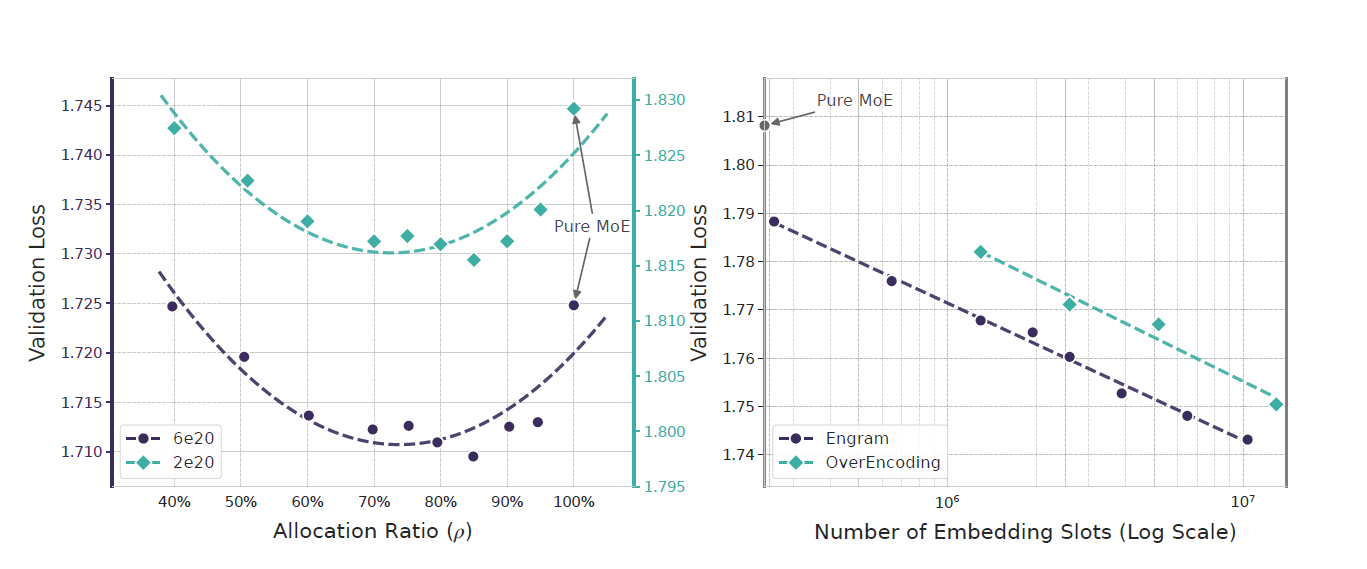
这一规律表明:记忆与计算在架构层面是互补且对立的,必须实现平衡,而非一味堆砌算力。
四、性能验证:27B模型全面超越纯MoE基线
基于U型定律,DeepSeek训练了Engram-27B(总参26.7B,5.7B参数分配给Engram,其余给MoE),并与同等参数/算力的MoE-27B、Dense-4B对比,结果显示"知识、推理、长文本"三维度全面提升。
1.核心任务性能(部分关键数据)
|-----------|-----------|-----------|---------------------------------|
| 任务类型 | 典型基准 | 提升幅度 | 说明 |
| 知识密集型 | MMLU | +3.0分 | 符合预期,记忆模块直接增强了知识储备。 |
| 通用推理 | BBH | +5.0分 | 反直觉提升,说明解放的计算资源显著增强了逻辑推理能力。 |
| 代码生成 | HumanEval | +3.0分 | 反直觉提升,代码理解需要深度组合推理,而非死记硬背。 |
| 数学推理 | MATH | +2.4分 | 反直觉提升,数学解题能力受益于更纯净的计算流。 |
2. 反直觉发现:记忆模块提升推理能力
Engram对推理任务的提升(如BBH+5.0、MATH+2.4)远超预期,核心原因是释放了模型的"有效深度":
- 传统MoE模型中,前6层需处理"实体识别、短语组合"等静态任务;
- Engram通过查表解决这些任务后,前6层可直接聚焦"语义理解、逻辑链构建",相当于"免费增加7层有效深度"(实验显示:Engram-27B第5层的表征,与MoE-27B第12层表征相似度最高)。
为什么一个记忆模块能大幅提升推理能力?DeepSeek的可解释性分析指出:Engram显著增加了模型的"有效深度"(Effective Depth)。
- 在普通模型中,底层网络(如第1-5层)大量精力耗费在重构基础词法和局部模式上。
- 在Engram模型中,这些静态模式被查表操作卸载,底层网络得以"提前"进入更高层次的语义理解和逻辑推演。
- 数据佐证 :Engram模型在第5层达到的"思考深度"相当于普通模型第12层的水平。这相当于免费增加了7层网络深度,让模型能处理更复杂的推理链条。
五、产业价值:重构大模型成本与能力格局
Engram的落地不仅是技术突破,更将对AI产业产生三大关键影响:
1. 成本普惠化:降低大模型部署门槛
- 硬件成本:CPU内存替代部分GPU显存,使30B级模型可在"1卡GPU+大内存CPU"的低成本集群部署,算力成本降至英伟达方案的1/3;
- 训练成本:参考DeepSeek R1模型(训练成本29.4万美元),Engram的"查算分离"可进一步减少训练FLOPs,中小团队也能接入先进架构。
- 问题:GPU显存(HBM)昂贵且有限,如何容纳千亿参数的记忆表?
- 解决方案 :Engram的检索索引仅取决于输入文本,是确定性的。因此,系统可以在计算前一层时,预知 下一层需要哪些记忆向量,并提前从廉价的CPU内存中异步预取。
- 惊人效果 :实验表明,即使将1000亿参数的Engram表放在主机内存 中,推理吞吐量的损失也仅为2%-3%。
- 行业影响:这打破了模型参数规模必须受限于GPU显存的铁律,为在成本可控的条件下运行超大规模模型提供了全新路径。
2. 场景扩容:长文本与垂直领域突破
- 长文本处理:32k上下文下NIAH准确率从84.2%升至97.0%,可支撑法律合同审查(数百页)、大型代码库分析(上万行)、学术论文解读(50页+)等场景;
- 垂直领域落地:医疗(疾病-症状对应表)、法律(法条-判例检索)、教育(公式-定理查表)等知识密集型场景,成本可降1/10,响应速度提升10倍。
3. 架构范式革新:双稀疏轴成为下一代方向
Engram开辟了MoE之外的"第二稀疏轴",未来大模型架构将从"单一条件计算"走向"条件计算+条件记忆"双轴协同:
- 已有信号显示,DeepSeek V4(预计2026年春节发布)将集成Engram与mHC(流形约束超连接),实现"记忆-计算-通信"三位一体优化;
- OpenAI、Anthropic等巨头已开始跟进"查算分离"思路,行业竞争焦点从"参数规模"转向"算力分配效率"。
- 稀疏化进入"双轴时代" :从MoE的条件计算 单一维度,演进为条件计算 + 条件记忆两个互补维度。
- 重新定义"智能" :真正的智能不仅是算得更快,更是知道什么该算、什么该记,实现最优资源分配。
六、局限与未来方向
1. 当前局限
- 多义性处理边界:对高度歧义的短语(如"Java"可指语言、岛、咖啡),门控机制仍可能误判,需结合更细粒度语义编码;
- 记忆更新效率:静态记忆表的增量更新(如新增时事知识)需重新训练,暂不支持实时动态更新;
- 硬件适配依赖:CPU-GPU异步预取需底层驱动优化,部分国产芯片(如昇腾910B)的PCIe带宽可能限制超大记忆库扩展。
2. 未来探索
- 动态记忆卸载:基于任务优先级,将低频记忆自动卸载至硬盘,高频记忆存于CPU/GPU缓存,进一步降低内存占用;
- 多模态记忆扩展:将Engram从文本扩展至图像(如固定物体特征)、语音(如特定人声纹),实现跨模态静态知识检索;
- 与RAG融合:将Engram的本地记忆表与RAG的外部知识库结合,形成"高频知识本地查、低频知识外部拉"的混合记忆体系。
3. DeepSeek V4的预示
综合多方解读,Engram极有可能是DeepSeek V4的核心架构升级之一:
- 时间线索:DeepSeek一贯"先发论文,再发模型"。此次论文发布(1月12日)与V4预计发布时间(2026年春节前后)高度吻合。
- 整合预期 :V4可能整合近期三大技术:Engram(条件记忆) 、mHC(流形约束超连接,优化层间连接) 以及强化学习(R1经验),形成一个在记忆、推理、训练稳定性上全面进阶的架构。
4. 对行业与普通人的机会
- 知识密集型应用爆发:医疗(诊断、药材)、法律(法条、案例)、教育(知识点问答)等领域的AI应用成本和延迟有望大幅下降。
- 长上下文应用成为现实:Engram能高效处理局部依赖,释放全局注意力。在长文档(合同、代码、论文)理解、分析任务上将有质的飞跃。
- 创业与开发门槛降低:基于开源DeepSeek模型,结合特定领域知识库进行微调,可以更低成本打造专业级AI应用。
七、总结:从"暴力计算"到"精密分工"的AI进化
DeepSeek的条件记忆论文,本质是对大模型"智能本质"的重新思考:真正的高效智能,不仅是算得更快,更是知道"什么该算、什么该记"。Engram通过"查算分离"的双稀疏轴设计,既解决了传统架构的算力浪费问题,又为大模型的低成本、规模化落地提供了可复制的技术路径。
对行业而言,这项技术不仅有望在V4中带来性能飞跃,更可能引领行业从纯粹的"算力军备竞赛"转向更加精巧的"算法-架构协同设计"新阶段;对开发者与企业而言,基于Engram的垂直领域优化(如医疗知识查表、长文本合同分析)将成为下一波机会点------毕竟,在AI时代,"用对工具"比"拥有工具"更重要。
参考链接:
原文↓
https://arxiv.org/pdf/2601.07372v1
知乎文章↓
知乎专栏--DeepSeek最新论文:直指Transformer要害,让AI学会翻"字典"了
知乎专栏--梁文锋署名新论文,DeepSeek V4架构首曝?直击Transformer致命缺陷
百度百科-Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
B站视频--DeepSeek V4将发布!梁文锋连发3篇论文,我读完发现一个规律
B站视频--白话解读Engram:DeepSeek又突发论文了
B站视频--新一篇 DeepSeek 论文打破 OpenAI 的规模定律 - Engrams - 前沿级代码能力成本降低 10 倍