Time-R1,DeepVideo-R1,VideoChat-R1,VideoAuto-R1
首先这四篇论文都是聚焦如何超越传统SFT,利用RL来释放视频大语言模型在复杂视频理解任务,更主要是时序推理任务的潜力。他们都建立在GRPO基础上。
一、Time-R1
1、概述
NeuIPS 2025 Poster
motivation:
SFT在时序视频定位任务(Temporal Video Grounding,TVG)上存在致命缺陷:即使模型的预测非常接近真实值(例如预测1.9s, 3.9s,真实值为2s, 4s),SFT的严格损失函数也会施加高额惩罚。这种"惩罚合理预测"的机制严重限制了模型的泛化能力。作者认为,既然TVG有明确的评估指标(IoU),那么直接使用强化学习优化IoU应是更自然、更有效的途径。
Contribution:
(1)Time-R1:从基于模仿的SFT转向基于目标优化的RL,为解决LVLM在TVG任务上的泛化难题开辟了新道路。
(2)Time-RFT:基于给定训练数据集的强化学习微调策略,逐步理解困难样本
(3)TVG-Bench:现有评估指标不好评估TVG,所以建立新的Benchmark,小而全面
2、相关工作
时序视频定位发展有三个发展阶段:VLP->SFT->RL
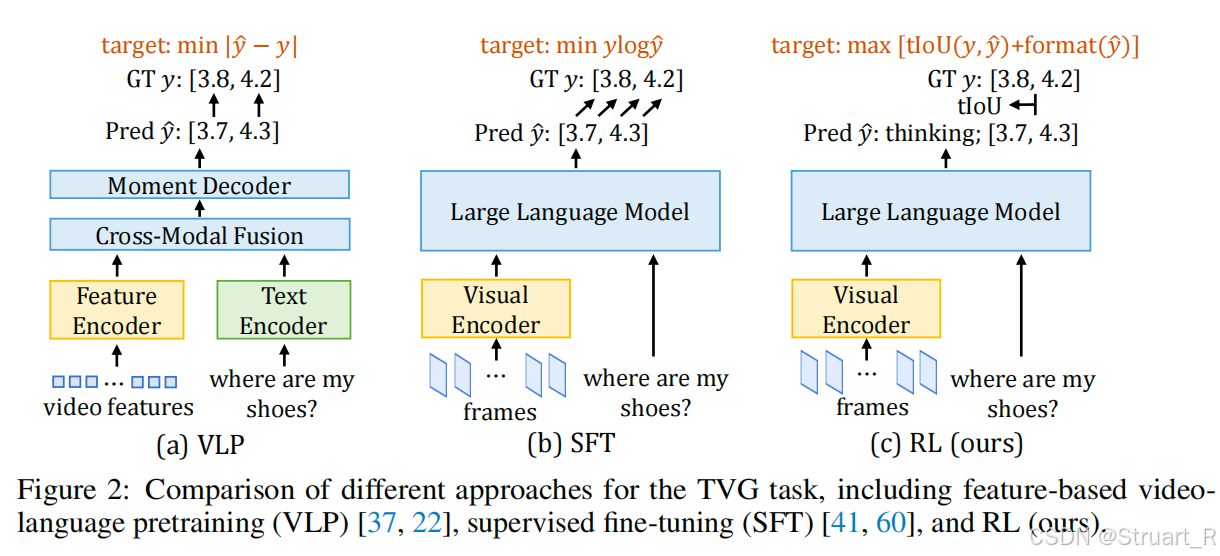
VLP阶段:基于特征的视频语言预训练模型(Feature-based Vision Language Pretraining)。如下图(a),最典型的架构为SnAG模型。具体过程:先输入视频帧到一个视频特征提取器中(比如I3D)得到Video features,在经过一个特定的Feature Encoder进行编码(如ActionFormer)得到Video tokens。文本信息先输入到一个文本编码器中(如BERT),得到Text tokens。 之后经过一个带cross-attn.的融合模块,之后过一个时间解码器获得时间上下界,最后利用最小化L1范数来优化。VLP方法最大的问题在于过分依赖预训练模型,无法端到端,当预训练模型在某一特定OOD下效果很差,那么损失值逐渐累加最终偏离GT。
SFT阶段:比如ChatVTG模型,视频帧过一个Visual Encoder编码,文本信息直接利用LLM的分词器进行编码,输出token生成一个时间戳,然后使用标准的Next token Prediction损失函数来进行SFT训练。SFT的损失函数对时间戳的微小偏差(如预测1.9s, 3.9s,真实值为2s, 4s)也会施加巨大惩罚,导致模型泛化能力差,容易过拟合。
RL阶段:输入部分一致,只修改输出部分。模型在生成answer同时输出一个thinking。训练过程不再使用"一字不差"的SFT损失,而是使用一个奖励函数来评估生成结果的质量。这个奖励结合了时间戳准确性(tIoU奖励)和回答格式正确性(format奖励)。
3、方法
Time-R1的Framework如下,数据驱动训练+benchmark的全流程。
并演示了时序视频定位,长短视频QA的任务,可以看到在定位准确性和准确度上都超过了基础模型和VideoChat-Flash这种上一代的TVG的模型。并且QA任务中有很强大的OCR的能力。(神奇)

3.1 GRPO
回忆一下GRPO:Deepseek-R1中提出,对于给定问题,大模型会生成G个采样响应(也就是回答),奖励函数
会对每一个响应分配奖励分数,产生
,GRPO公式可以最大化加权和奖励
的响应,也就是让奖励分数最高的响应获得更大的比重,从而更容易生成这一响应。
其中为LLM生成
的概率,
为上一轮LLM生成
的概率,后面那一串就是
的奖励
的归一化奖励偏差,然后
为最大化加权和,很好理解。
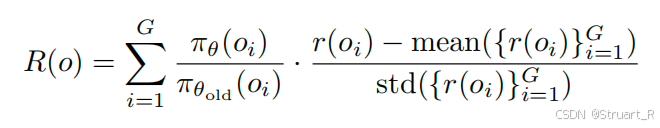
另外保证训练稳定性,引入KL散度正则化,需要在最大加权和奖励上减去一个当前策略概率分布与SFT输出(强化过程输入)策略概率输出
之间的KL散度,KL散度越大相当于越偏离初始的分布,但是我们不想过分偏离原来的输出域中。
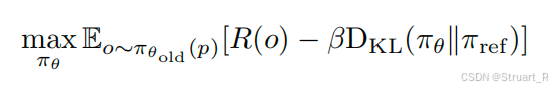
在实际应用中,策略概率输出应该就是一串float值,计算这两个数组之间的散度,PPO的作者提出了一个近似算法,如下:
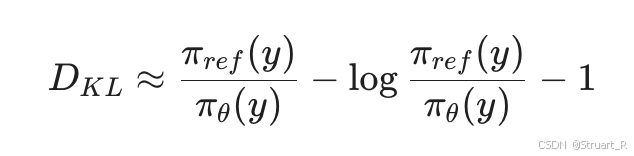
3.2 Time-R1中的奖励函数
TIoU(时间交并比奖励):在标准IoU上添加了对起止时间的严格束缚,对于标准IoU来说,假如GT是0s,30s,对于Answer1:5s,20s,Answer2:15s,45s来说两者的TIoU值都是0.5,但是明显Answer1更好。下面公式为TIoU公式,为真实与预测起始时间点,
为真实与预测终止时间点。
格式奖励:这里只考虑非0即1,格式完全正确则1,其他为0.
3.3 TimeRFT
TimeRFT:时间感知的、强化学习友好的数据集整理与微调技术。
RL-Friendly数据集:339K。数据来源包括YT-Temporal, DiDeMo,QuerYD,InternVid,HowTo100M并用VTG-IT,TimeIT,TimePro ,HTStep,LongVid进行了标注。
RFT过滤:由于简单的样本不用RL训练SFT模型已经学会,太难的训练不稳定。所以筛选中等难度样本,利用Qwen2.5-VL基模进行预测TVG,并计算IoU,抽取高斯分布IoU=0.3,方差=0.2的2.5K个样本构成RL数据集。
RFT训练策略:多轮训练中每轮进行采样评估,提出IoU大于0.7的在RL过程中已学会的简单样本
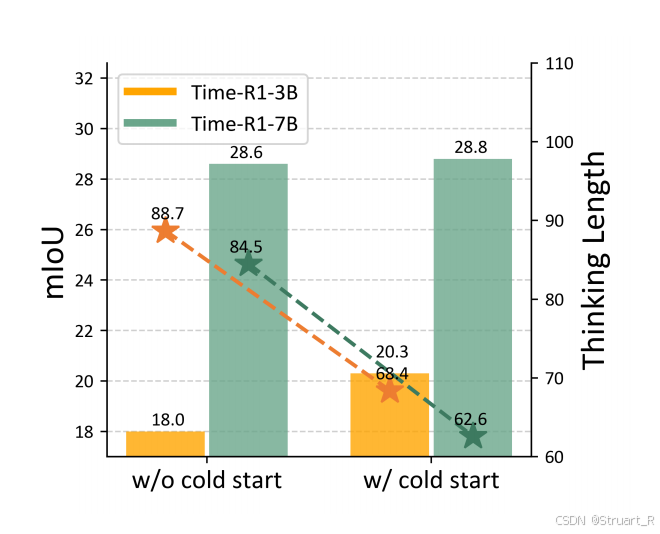
0.3B模型的基于少量CoT冷启动方式:参数量较少是直接进行RL过程会产生幻觉,回答时有严重的格式问题。所以对于0.3B模型先过了一组150个样本的CoT样本对模型进行LoRA微调,这部分仍然是SFT,在论文Appendix中有提到。CoT格式很简单:
另外对于GT数据,包含两个任务,TVG和Video QA,对于Video QA采用了带CoT(推理问题),不带CoT(简单易懂)两个方式,如下图。

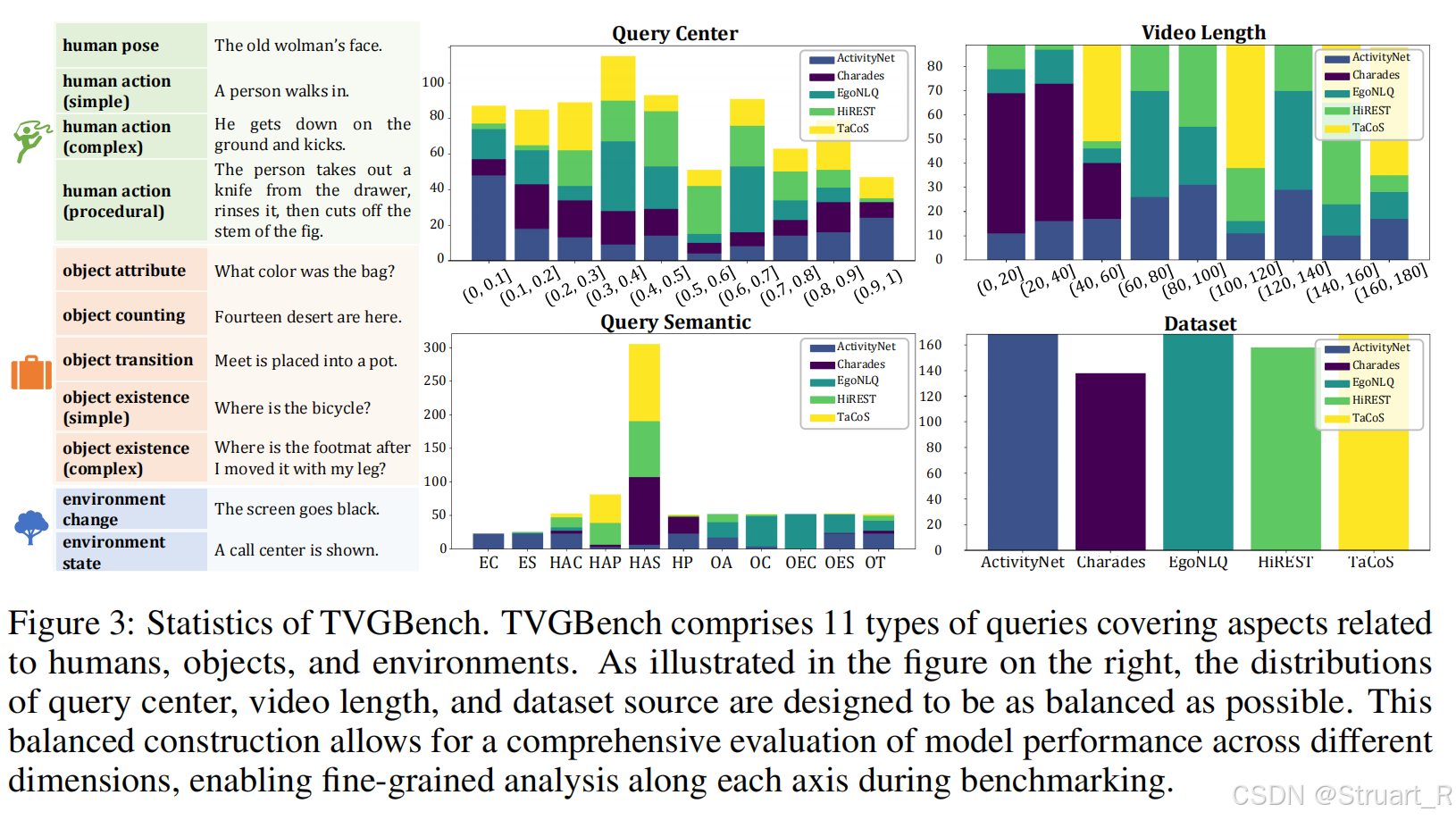
3.4 TVGBench
人类、物品、环境11个类别,包括Charades-STA、ActivityNet-Captions、HiREST、EgoNLQ和TaCoS数据集。
3.5 训练方法
SFT:Qwen2.5-VL基模不训练
RL:GRPO,经过Time-R1改良了奖励函数和RFT,数据2.5K标注视频
4、实验
首先@0.3的意思是,经过强化学习后IoU的值在0.3的百分比,TVGBench就是在新数据集下的eval,其实还是有一定进步空间的。
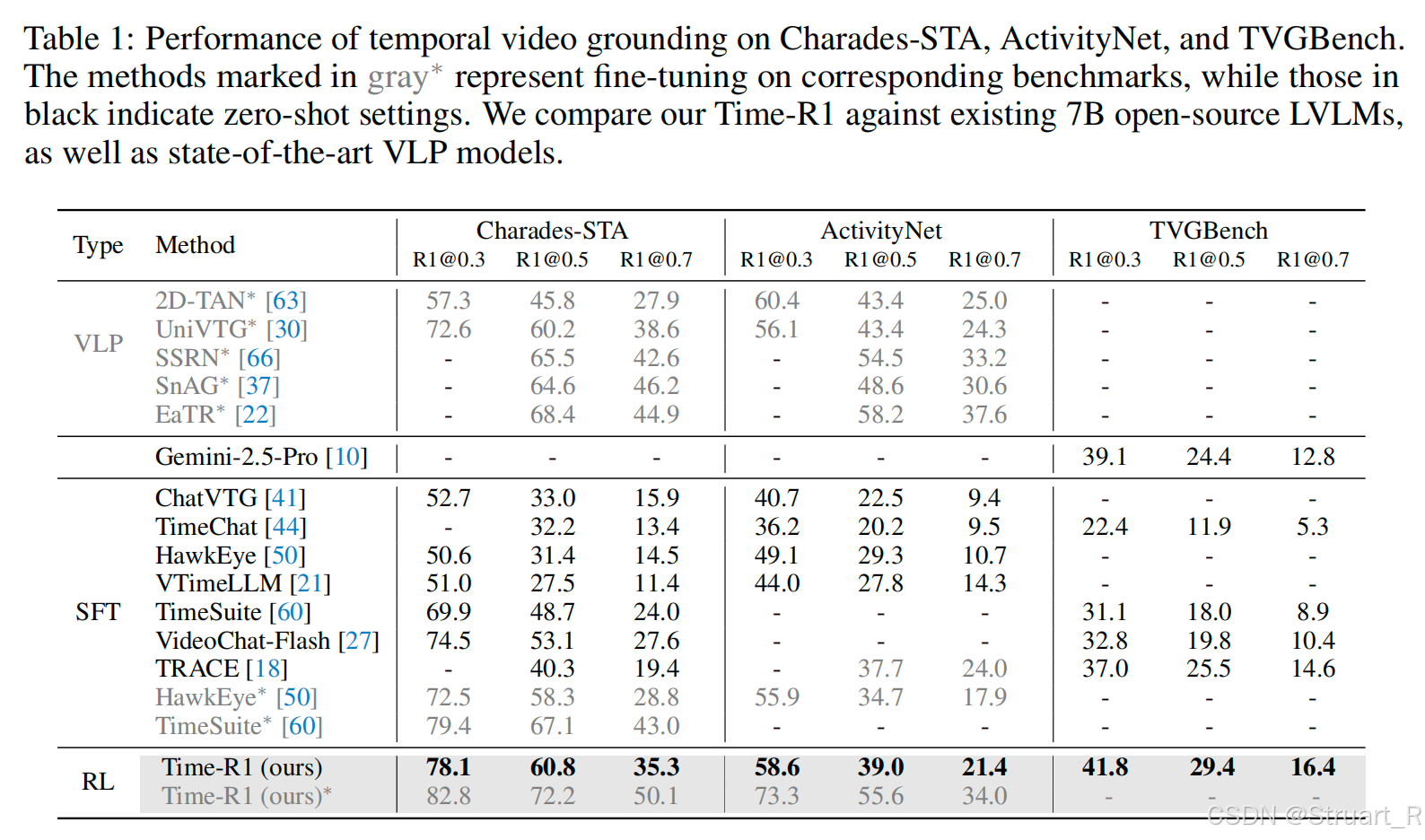
其实RL保证散度正则化,也防止对于QA问题偏离了原来的域,保持原有的性能,并且在TVG上效果更好(因为这个方法就是优化TVG)
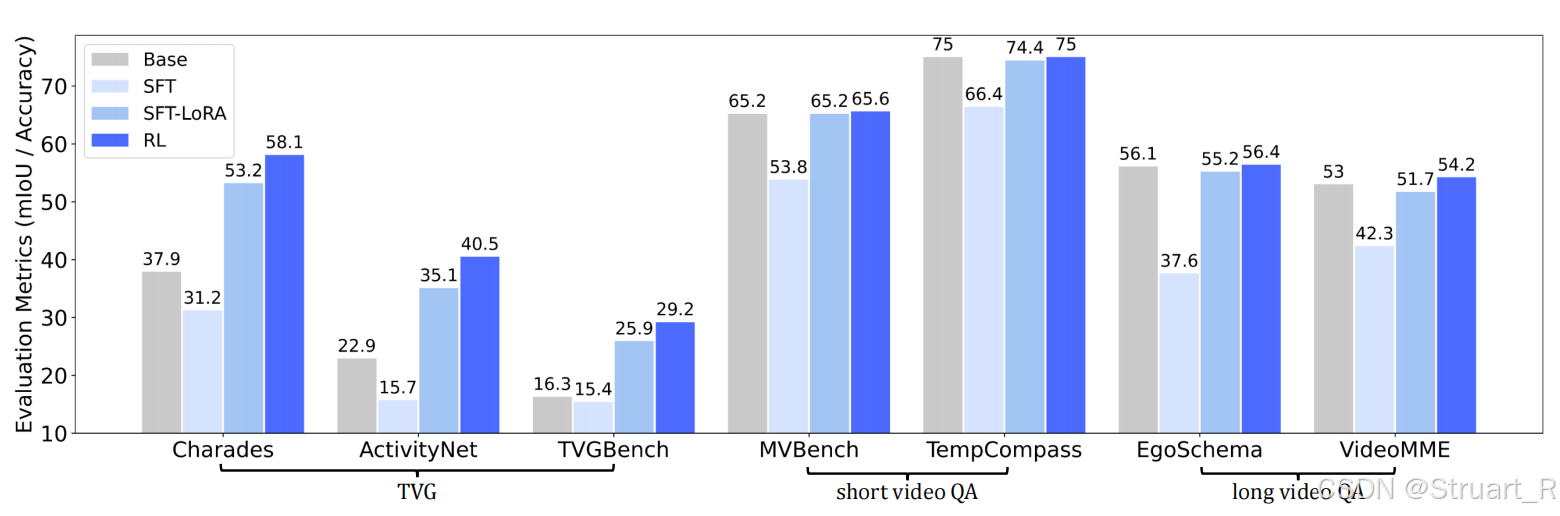
训练策略的消融实验,GF(Gaussian Filter),ME(Multi-epoch),SF(Sample Filter)
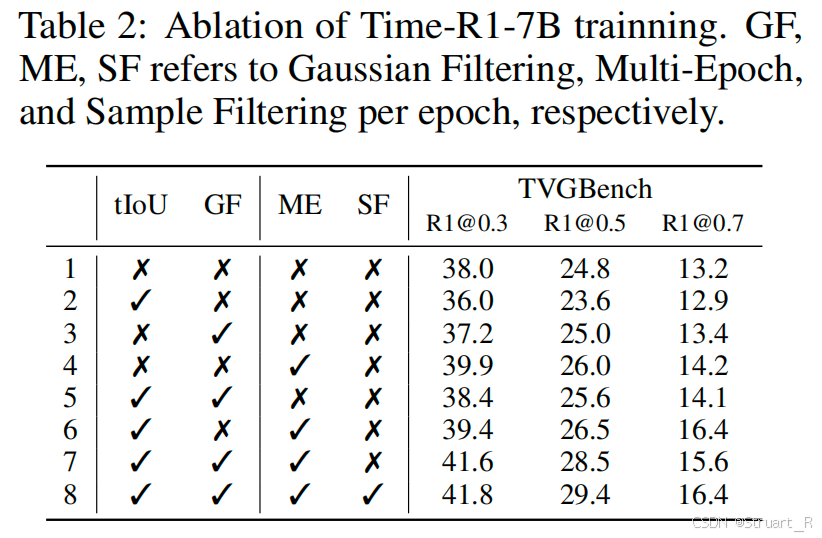
冷启动:小模型下,length更短,IoU更差,通过cold start后有所缓解。
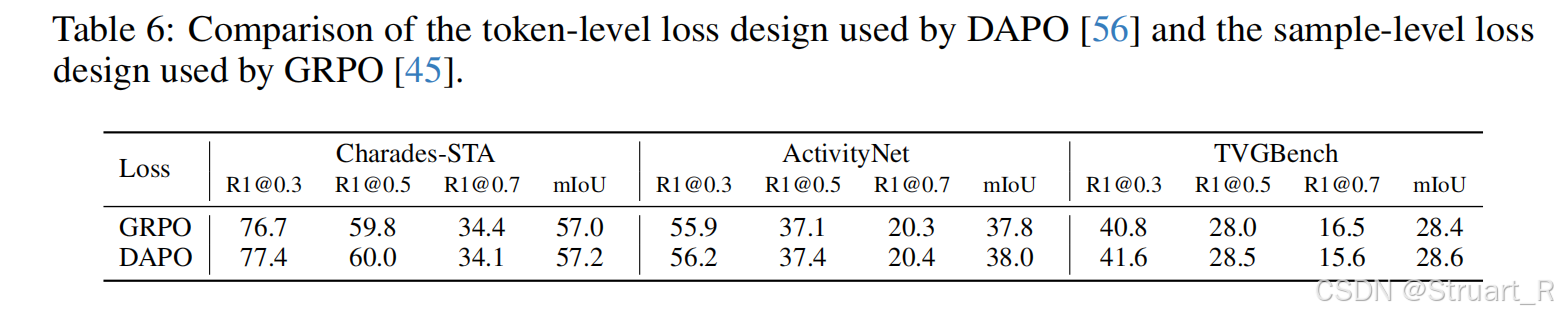
DAPO vs GRPO
这里先不介绍DAPO了,GRPO喜欢更长的句子,DAPO专注更重点的回答,防止过度思考。想象一个包含很长思维链但最终答案正确的响应。在GRPO看来,整个响应是"好"的。但DAPO能更智能地判断:可能是思维链末尾的几个关键token(如正确的时间戳"35 to 75")决定了高奖励,而前面大量的描述性文本可能并非关键。因此,DAPO会给那些关键token分配更高的更新权重,从而引导模型更专注于学习对结果有直接影响的模式。下图在Time-R1中尝试DAPO和GRPO的对比。
二、DeepVideo-R1
1、概述
NeuIPS 2025 Poster
motivation:
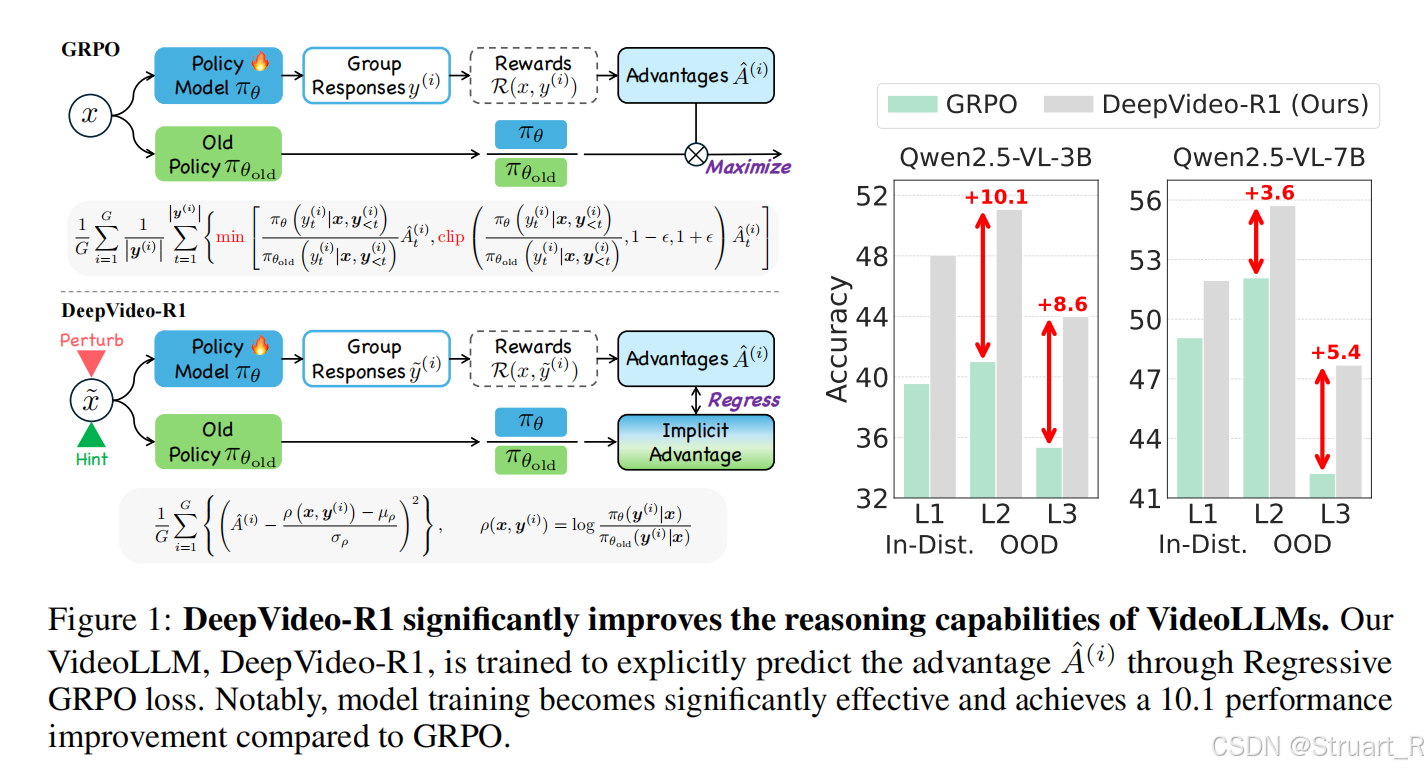
依赖启发式安全措施:GRPO使用min和clip函数作为安全约束,但这些约束会抑制梯度流动,特别是在策略概率比(π_θ/π_old)差异较大时会产生零梯度,阻碍模型有效收敛。
优势消失:当组内所有样本奖励相同时,优势值会变为零,导致模型无法从这些训练样本中获得有效信号。这种情况在样本难度极端(过于简单或困难)时尤为明显。
contribution:
(1)Reg-GRPO:将GRPO目标重新表述为回归任务,直接预测基于组的优势值
(2)Difficulty-aware augmentation:自适应难度调节,对简单的问题进行噪声扰动,对困难样本进行视频线索注入。
其实Reg-GRPO是对泛化性任务的改进不拘泥于Video,Difficulty-aware augmentation是对视频难易程度的优化,提高模型对数据的有效学习能力。
下图为GRPO公式(完全体):
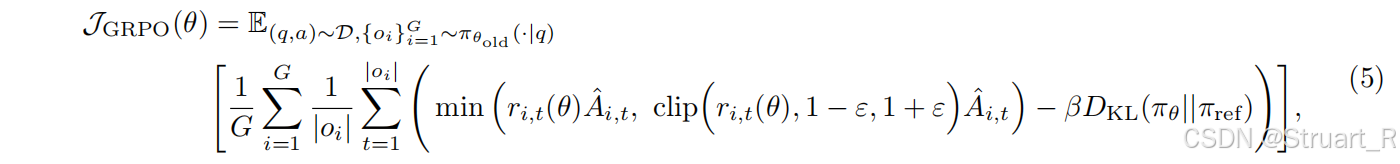
这里注意就是
,
是
,上面Time-R1的GRPO公式是进行了简写。
2、方法
2.1 RegGRPO
RegGRPO(回归组策略优化),把GRPO重新定义为回归问题,移除诸如最小值,和clip裁剪函数。具体来说:
第一是由于clip裁剪的问题,因为防止奖励函数过大或过小,所以设置了一个裁剪函数,如果训练开始时策略的迭代变化很大,那么
就会很大,所以
就容易超过
这个范围最终被裁剪到边界,虽然一定程度上通过每一步更新很小,保证训练稳定,但也会造成问题,由于裁剪而无法回传梯度,因为
这两个值对
求导为0,backward过程中梯度就为0了。
第二是如果采样一组样本的奖励碰巧都相等,当然这很可能,比如两个问题,一个长一个短,都满足了format,都回答对了answer,那么奖励都一样,这样,进而
就会等于0,那么梯度将不会更新,训练停滞不前。
RegGRPO怎么做的呢?
完全排除min和clip,假设我们防止新策略与旧策略之间距离太远,并最大化期望奖励。假设目标如下:
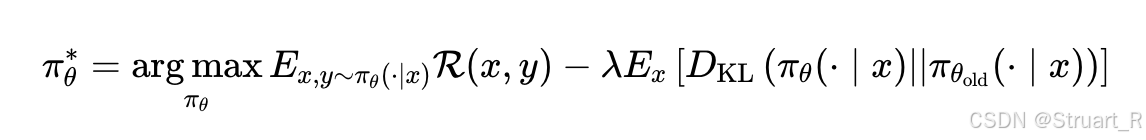
之后计算新策略的闭式解,将max转换成min,并令括号内为0。
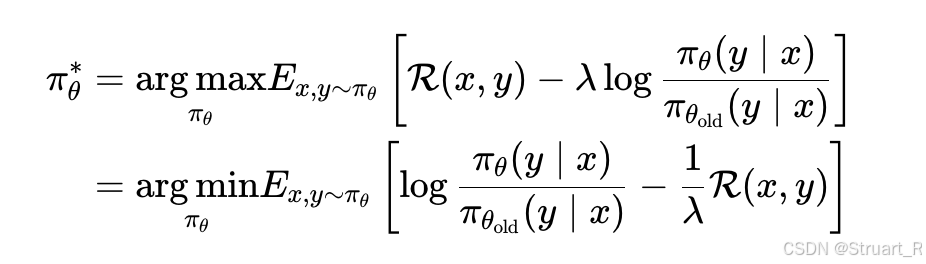
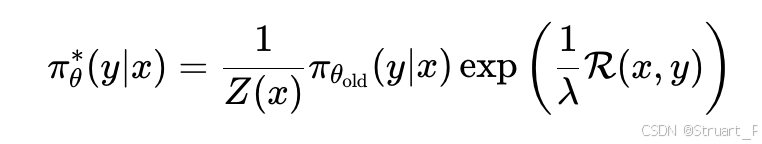
其中。之后根据该等式,求出
的值:
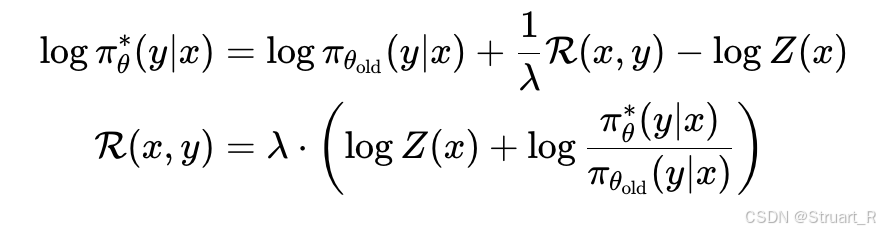
在GRPO中定义归一化奖励(优势值)为,那么把下一步最优策略的奖励带入优势值。注意到:
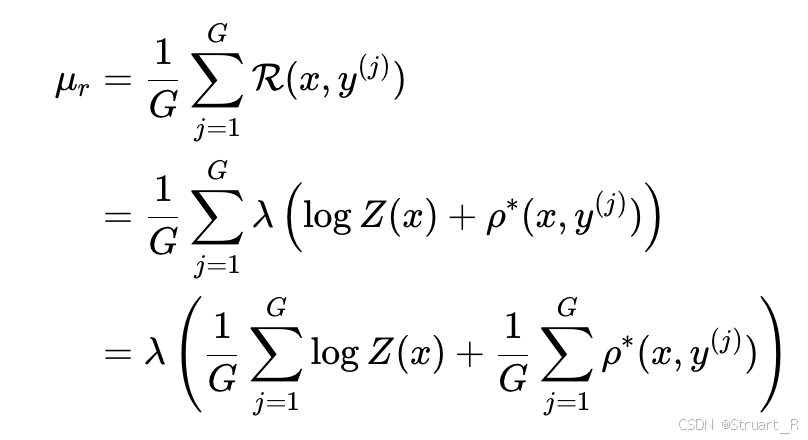
我们令。则
中
可以被消掉。
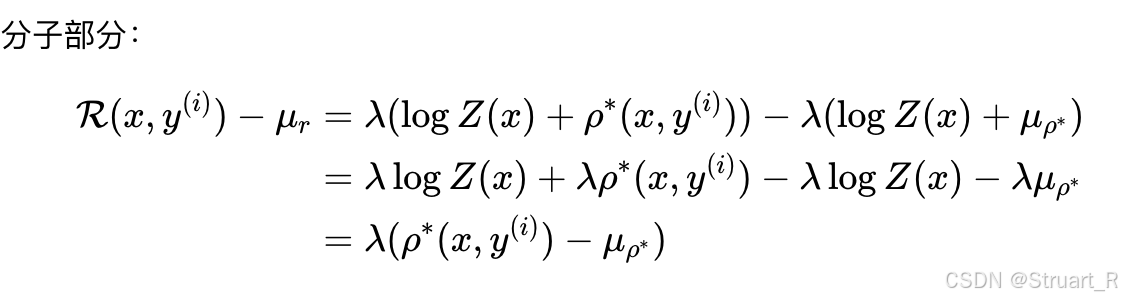
同理分母部分:
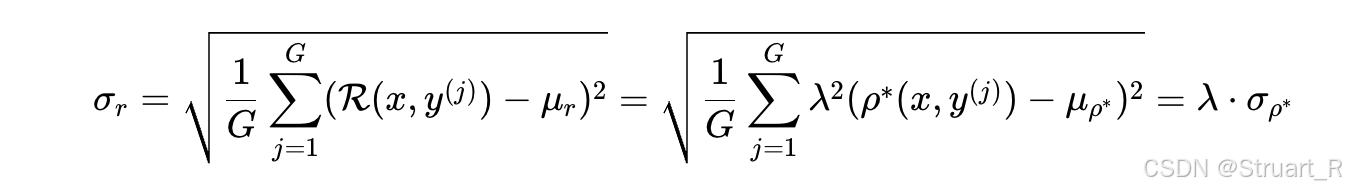
最终结果(其实是理想情况下最好策略所对应的优势值):
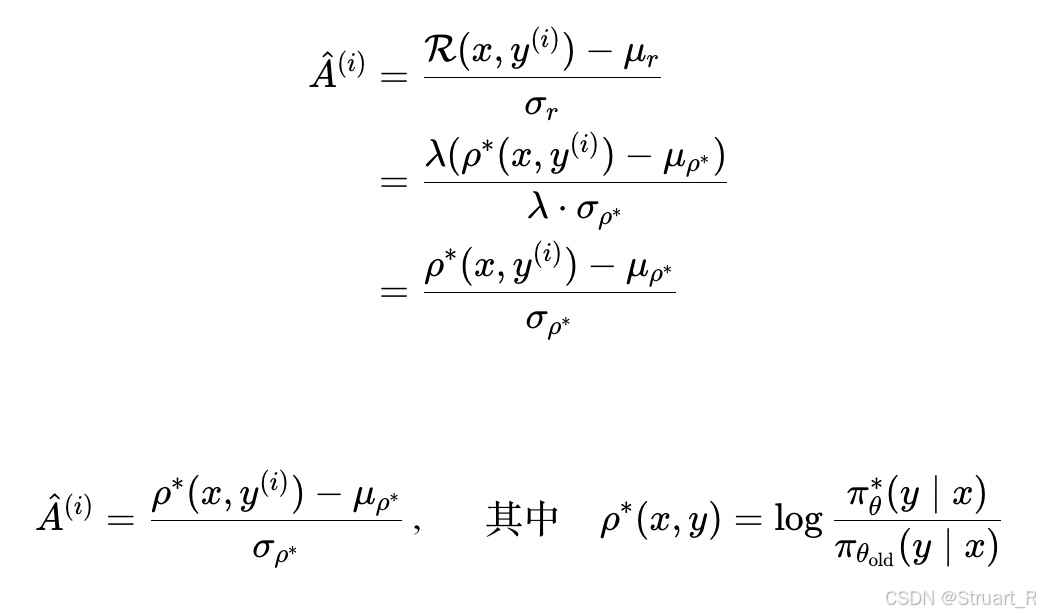
所以定义RegGRPO损失为下式,使得期望的策略所对应的优势值更接近与理想情况的最好策略优势值。
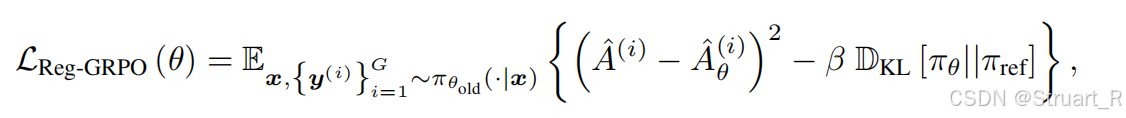
2.2 Difficulty-aware data augmentation
这一部分解决的是当训练样本难度极端化时(过于简单或困难),会导致组内所有响应的奖励值相似,使得优势值为0这一问题。解决方法:难度评估->简单样本提升难度,困难样本提供线索
难度评估机制:对于输入视频和问题,其难度定义为:
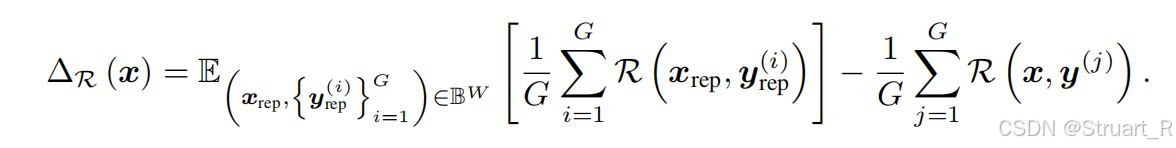
使用历史奖励均值作为难度基准,适应模型能力的持续进化,为包含最近W个训练步骤中样本的回放缓冲区,正
表示样本相对困难,负值表示相对简单。
难度降低增强策略:针对困难样本(评估正值),则在问题给出时,同步给出回答,并让引导VideoLLM生成多个推理路线,并从奖励最高的路线中获得推理thinking,并将推理thinking与原始thinking(也就是LLM推理时的thinking)合并得到增强线索。
难度增加增强策略:针对简单样本(评估负值),添加高斯噪声或屏蔽部分视频帧在保证语义完整性的同时降低感知质量。并且绝对值越大,噪声或屏蔽系数越大。
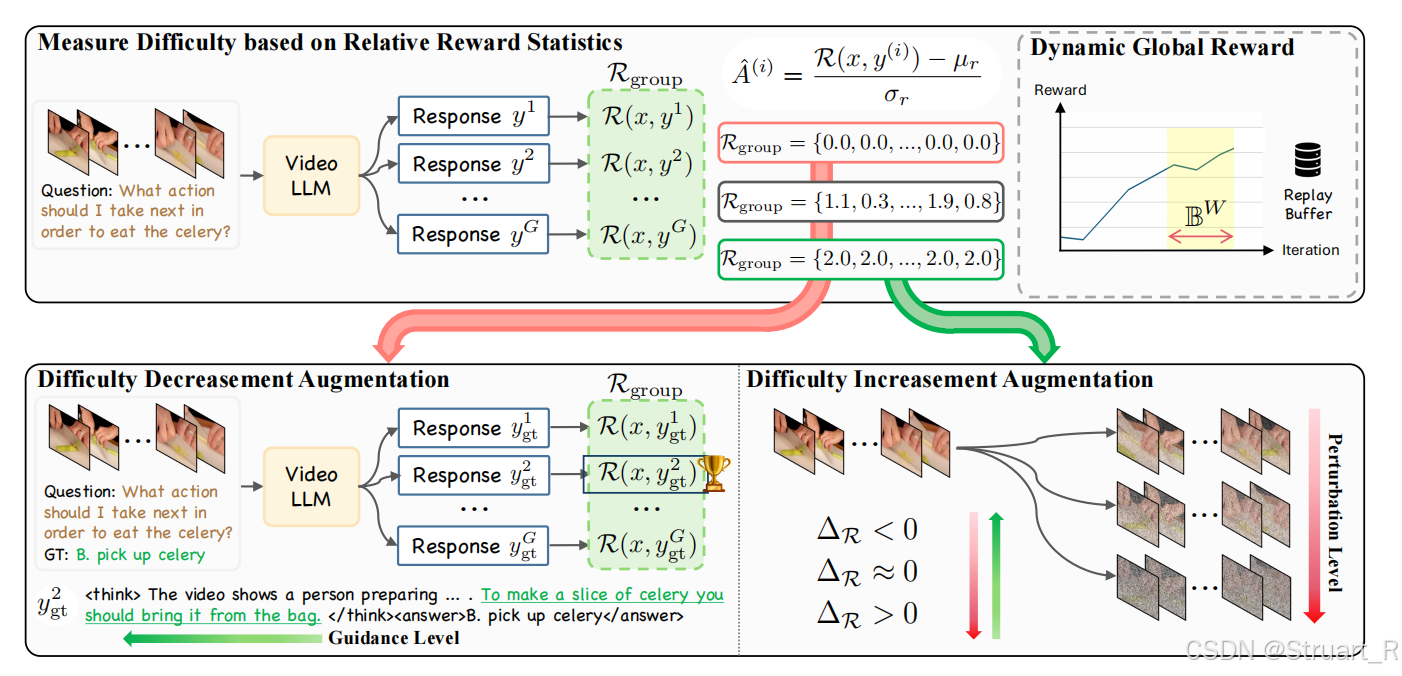
注意:缓冲区的W个样本是随着训练不断更新的,选择最近的W个,并在每一个batchsize后进行评估,并把困难样本+推理线索,简单样本带噪返回到trainset中继续执行RL。
DeepVideo-R1整体思路:
3、实验
模型基模使用Qwen2.5-VL-3B作为VideoLLM。
数据集用的是Video-R1数据集
DeepVideo-R1对比了通用视频理解任务SEED-Bench-R1、VSIBench、Video- MMMU、 MMVU、MVBench、TempCompass、Video- MME,长视频理解任务LongVideoBench,细粒度视频理解任务NExTGQA。
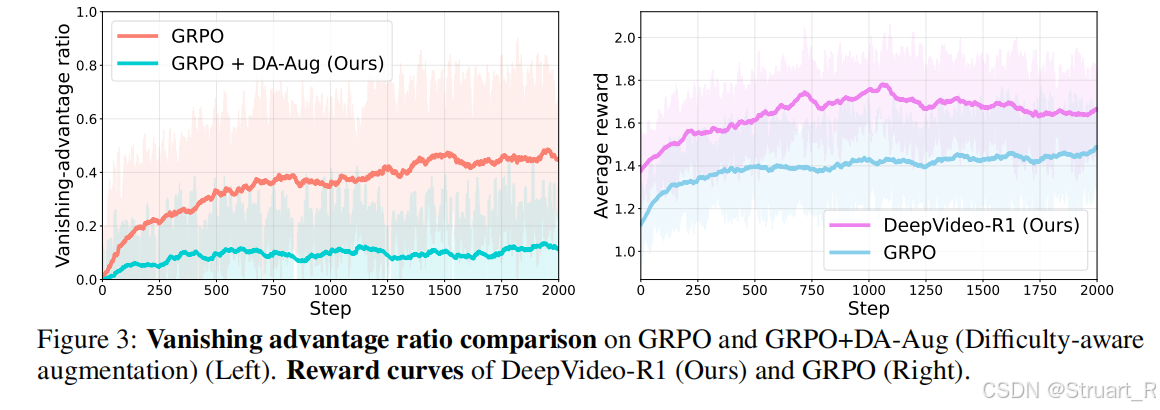
这个图很有趣,左图是随step变化消失的优势值的变化,GRPO有更大的消失优势,也就是有更多,这些值的梯度都不会更新,所以相当于30-40%的训练都是没意义的。
右图是DeepVideoR1能获得更大的奖励,所以训练也更有意义。
参考论文: