目录
[传统调用 vs 流式调用](#传统调用 vs 流式调用)
思考:使用ollma自己在本机部署一个千问大模型,可以运用到项目中吗?这是免费的吗?
一.大模型部署
1.自己部署
两种部署方式没啥区别,我们主要学习本地机器部署,因为比较方便。

自己部署------本地机器部署
先明白一点:公司进行本地机器部署,一般都是在机房里面部署。
由于我们是个人学习者,没有机房,所以就在自己的电脑上部署。
1)如何让大模型跑起来?
我们需要先安装Python解释器,再安装依赖、手动下载模型、编写脚本......光这一个前提操作,就劝退一大部分人了。
此时有人就好奇了,这不是和手动管理项目的依赖没啥区别吗,说白了费力不讨好。
我们之前学过maven可以帮助我们管理项目依赖,那么有没有一款软件,帮我们弄好大模型的基础环境?
答案:有的,它就是ollama。

2)下载ollama
去官网,找对应的操作系统的安装包,安装即可。

当我们桌面(windows操作系统)出现一个羊驼的图标时,就证明安装成功了。
而且ollama安装好以后,会自动配置好环境变量,不用我们操心(如果将来运行命令的时候ollama报错了,可以检查环境变量,然后网上找一下解决方案即可)。

3)使用ollama部署大模型
首先,你要确定部署哪种大模型?(是要部署深度求索的deepseek,还是阿里的千问?部署哪个版本的?)
因此,我们可以先去ollama的官网上,查看一下都有哪些大模型供我们选择:
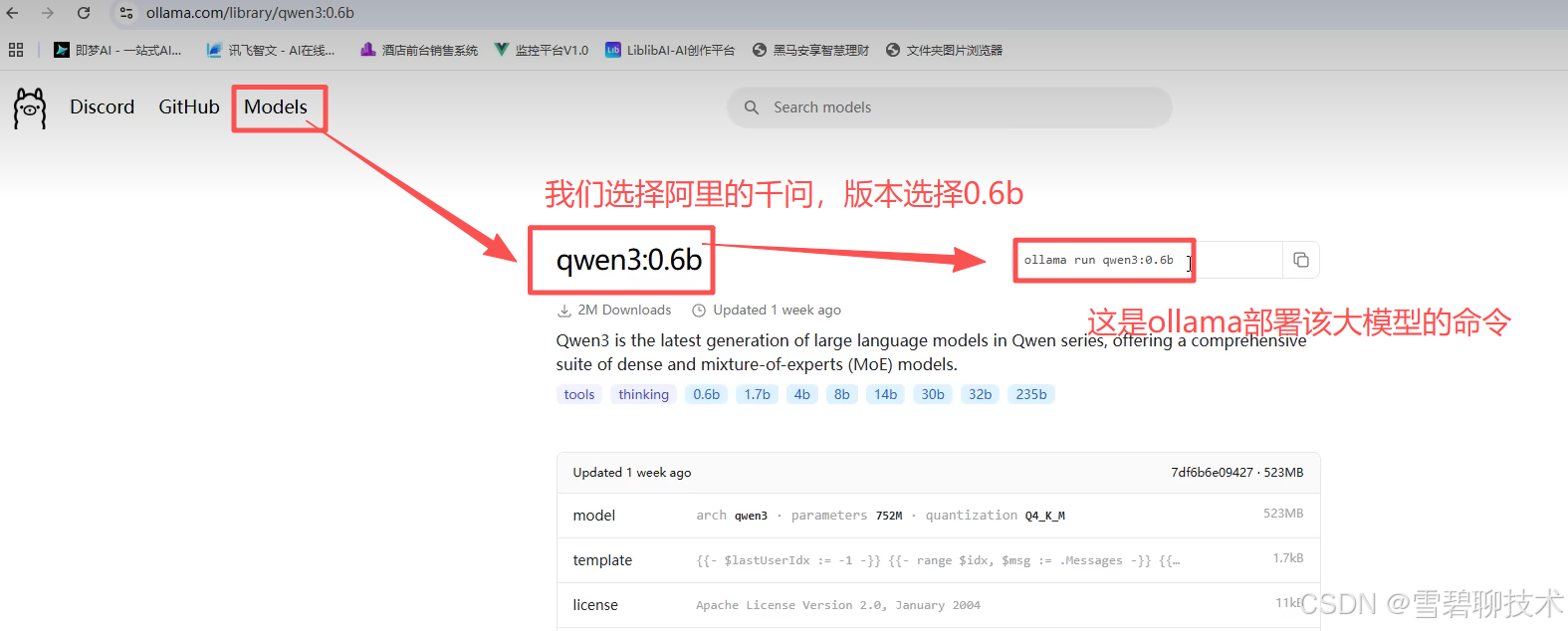
我们之前的文章讲过,这个b是神经网络中的参数的数量,0.6b就是0.6*10亿=6亿个参数。而大模型就是实现了神经网络(本质是一个数学模型)的代码(软件)。
因此数量越多,代表大模型越强大。
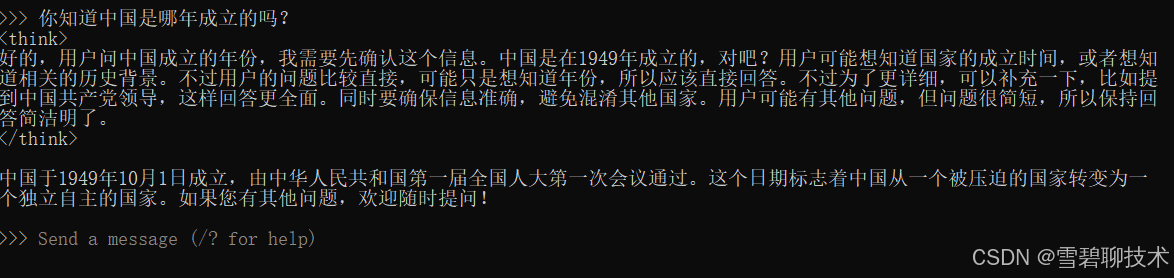
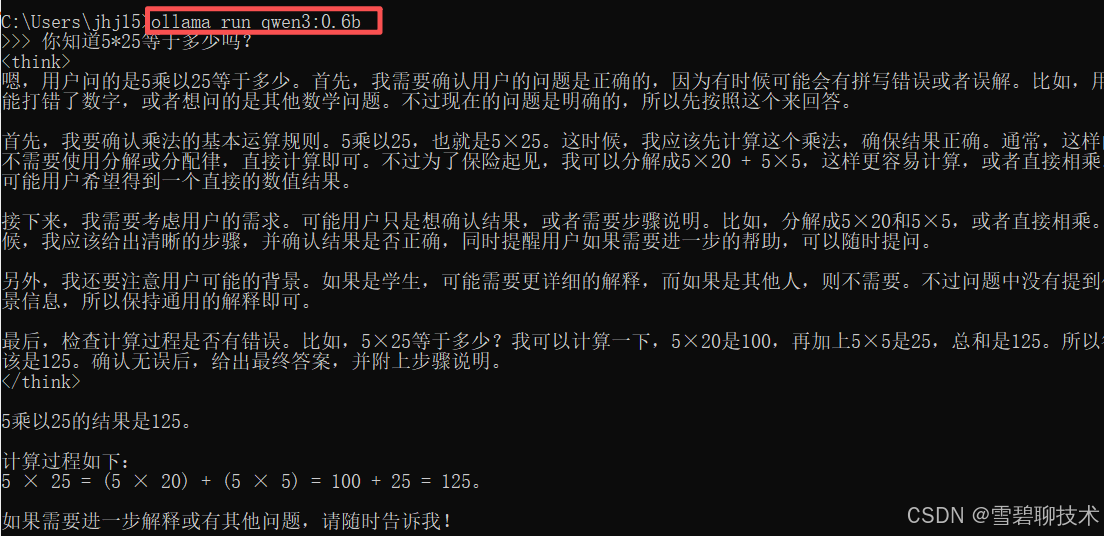
打开黑窗口,执行上述命令ollama run qwen3:0.6b

然后我们部署完以后,敲几个回车,窗口就有反应了,然后就能问大模型问题了,如下:
不想用的时候,敲 /bye 就能关闭大模型。
如果又想用了,怎么打开?再次执行部署命令即可(注意:只有第一次部署时,会下载所需文件到本地,后续就直接打开了)
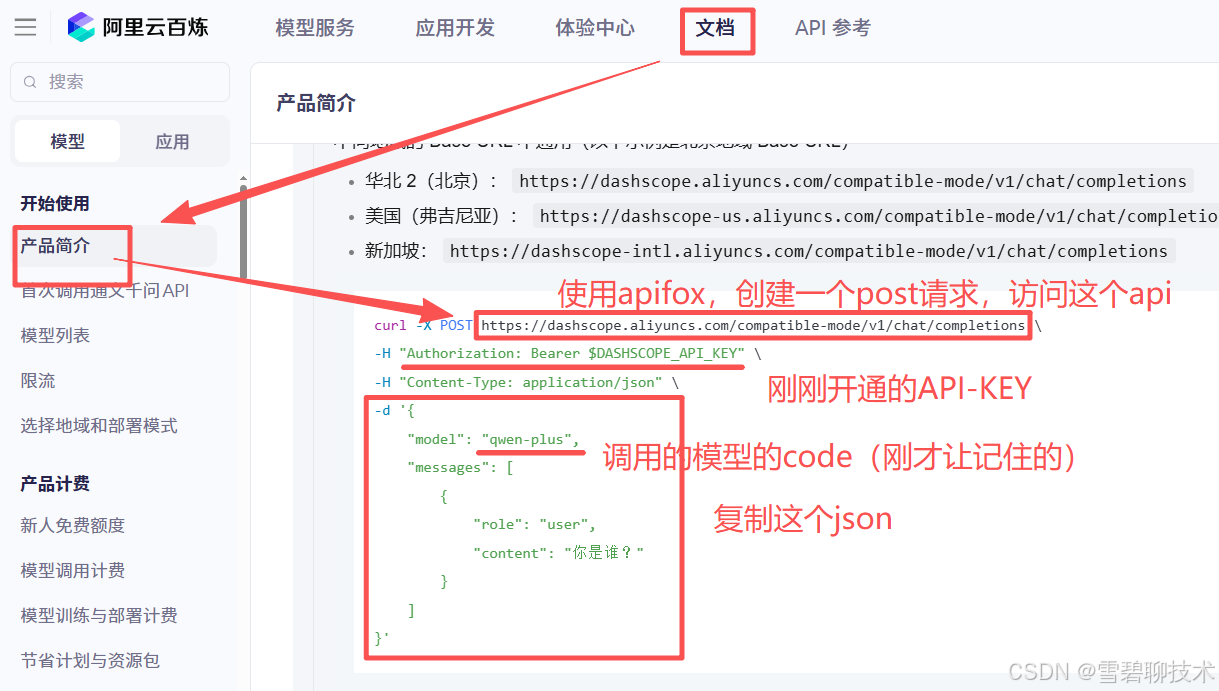
4)使用apifox调用本地大模型
由于上面步骤已经使用ollama将qwen3:0.6b这款大模型部署到我们的本地机了。那么下面就使用apifox的形式去调用一下这个本地大模型吧。
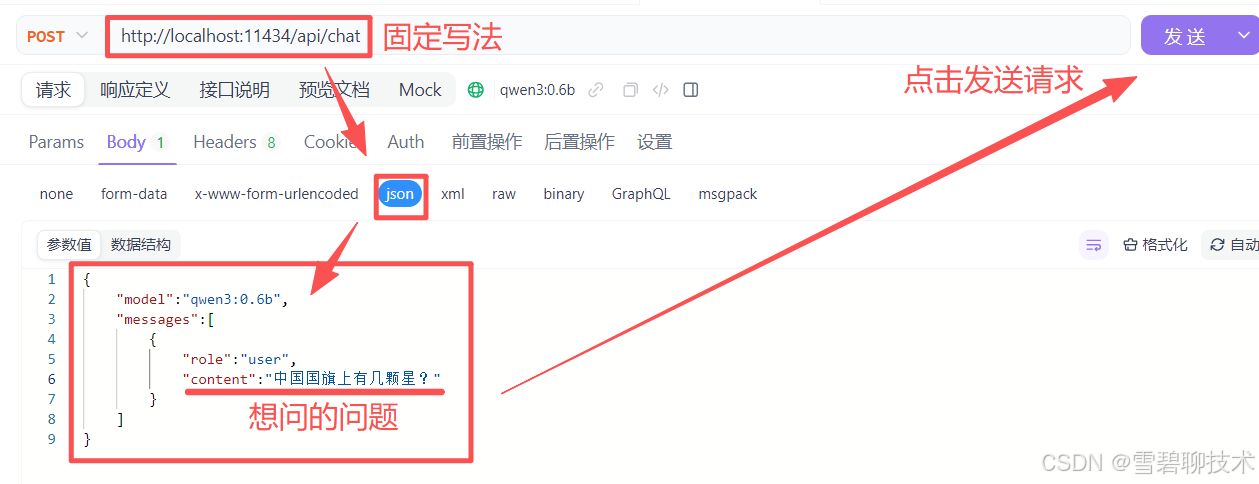
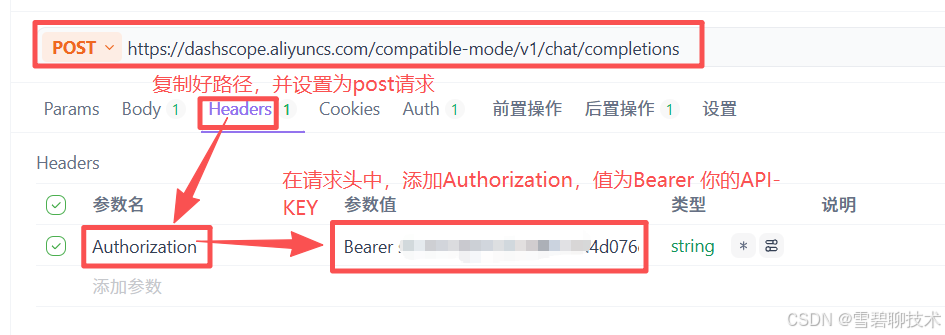
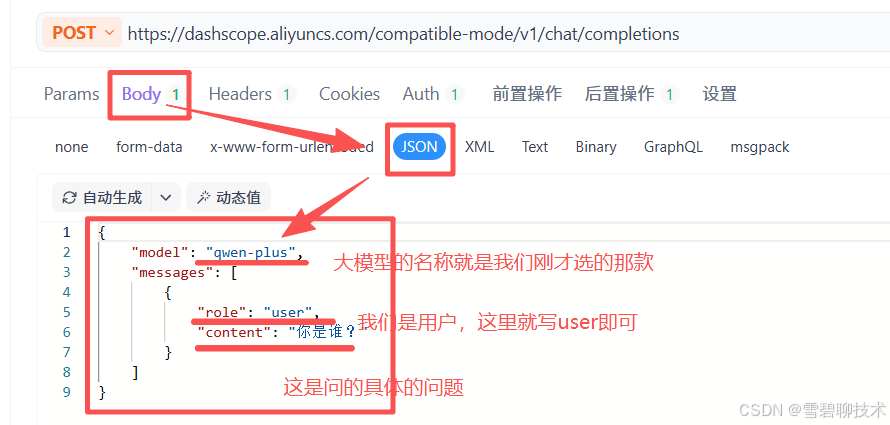
打开apifox,新建一个post请求(因为一般我们访问大模型的请求都是post),内容如下:由上图可知道的几点:
①ollama的端口默认为11434
②大模型的调用基本都用post请求
③请求体的JSON格式和内容,具体去ollama官网上找就行。
④请求体解读
model:要调用哪个大模型(前提是已经使用ollama将该款大模型部署到了本机)
role:user表示用户要用大模型,也就是我们
content:我们想问的具体问题
⑤还有其他很多入参,只是我们目前只用到了这几个而已
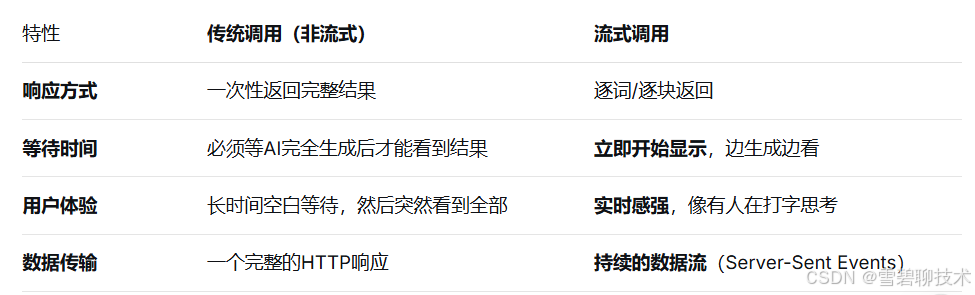
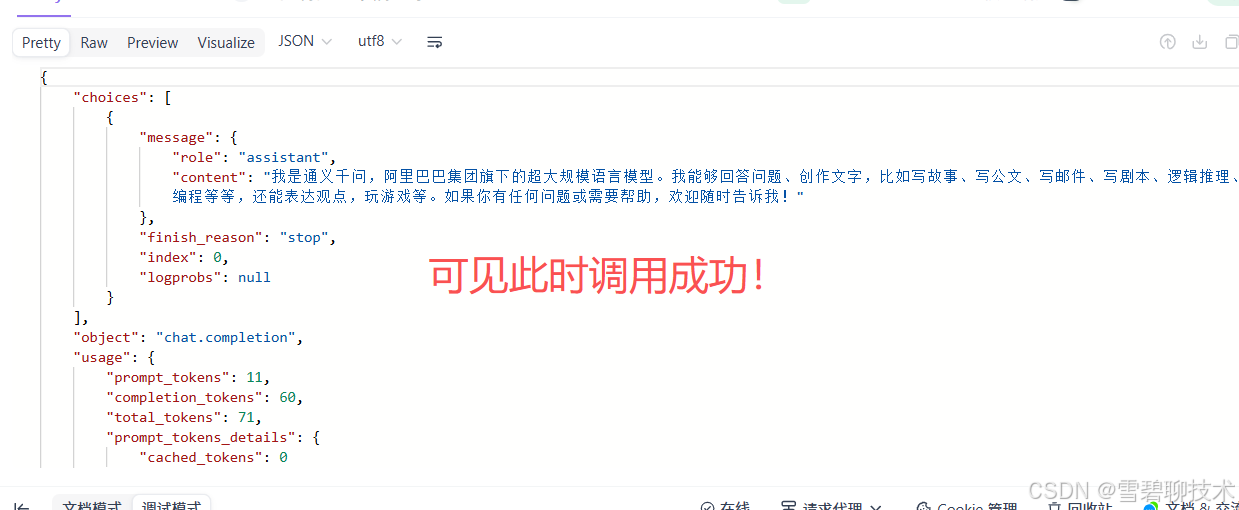
发送请求以后,看看响应参数:由上图可见,我们能理解"自动合并"下的响应内容,和我们平时使用deepseek没区别。但是这个"分条展示"下的这么多内容是啥?这就是"流式调用",说白了就是一点一点给你回答,像打字那样,给人一种实时的效果。
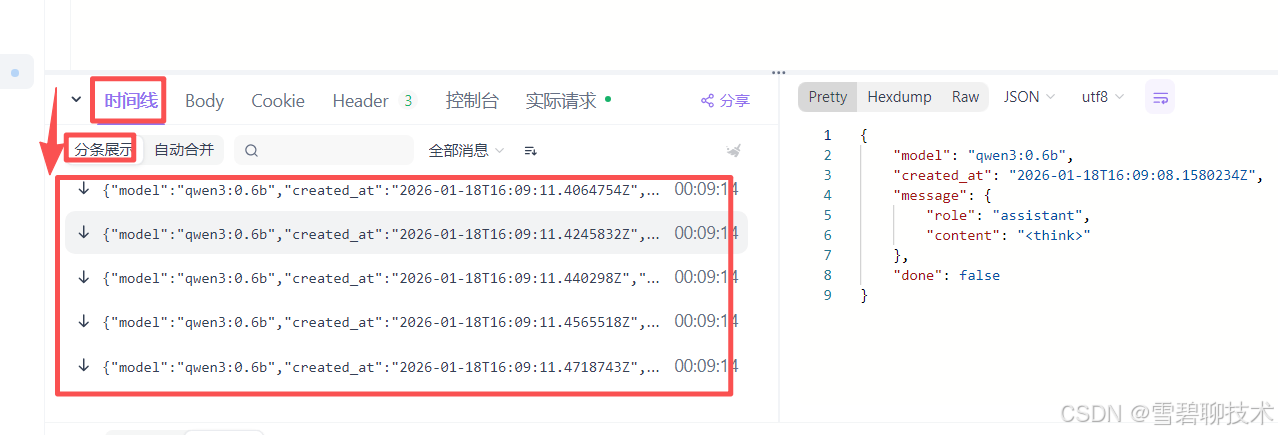
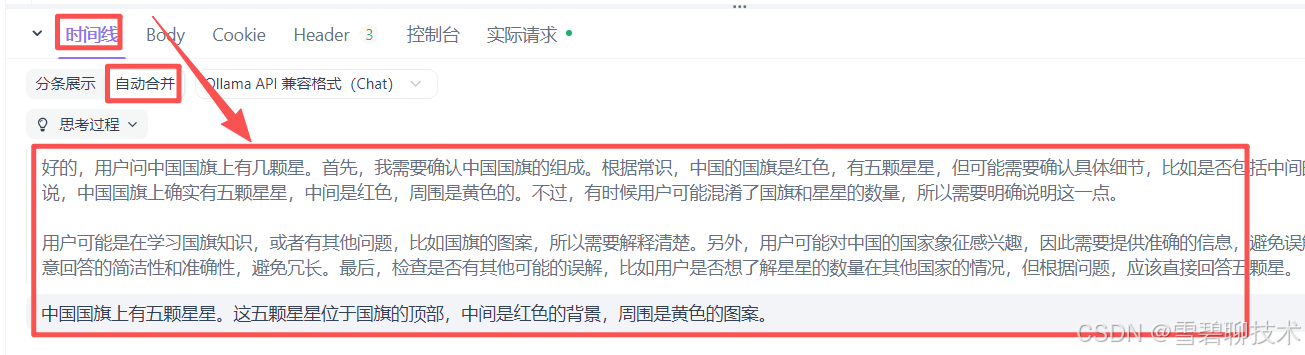
传统调用 vs 流式调用
思考:使用ollma自己在本机部署一个千问大模型,可以运用到项目中吗?这是免费的吗?
是的,完全免费!你可以在本地使用Ollama部署千问大模型并应用于项目。
千问的开源版本(如Qwen2.5)可免费商用,并已加入Ollama官方模型库。只需安装Ollama后,通过命令行拉取并运行对应模型即可。本地部署能保障数据隐私和安全。
项目集成可通过调用Ollama提供的本地API接口实现。
硬件方面,0.5B参数版本可在CPU上运行,适合简单任务;7B版本需8GB以上内存,是性能与资源消耗的平衡选择;14B以上版本需要16GB以上显存,适合专业场景。
建议从7B版本开始测试,如需节省资源可选择量化版本。生产部署前应进行充分测试以确保满足项目需求。
总结:千问大模型可免费在本地部署并用于商业项目,技术成熟,集成方便。
2.他人部署

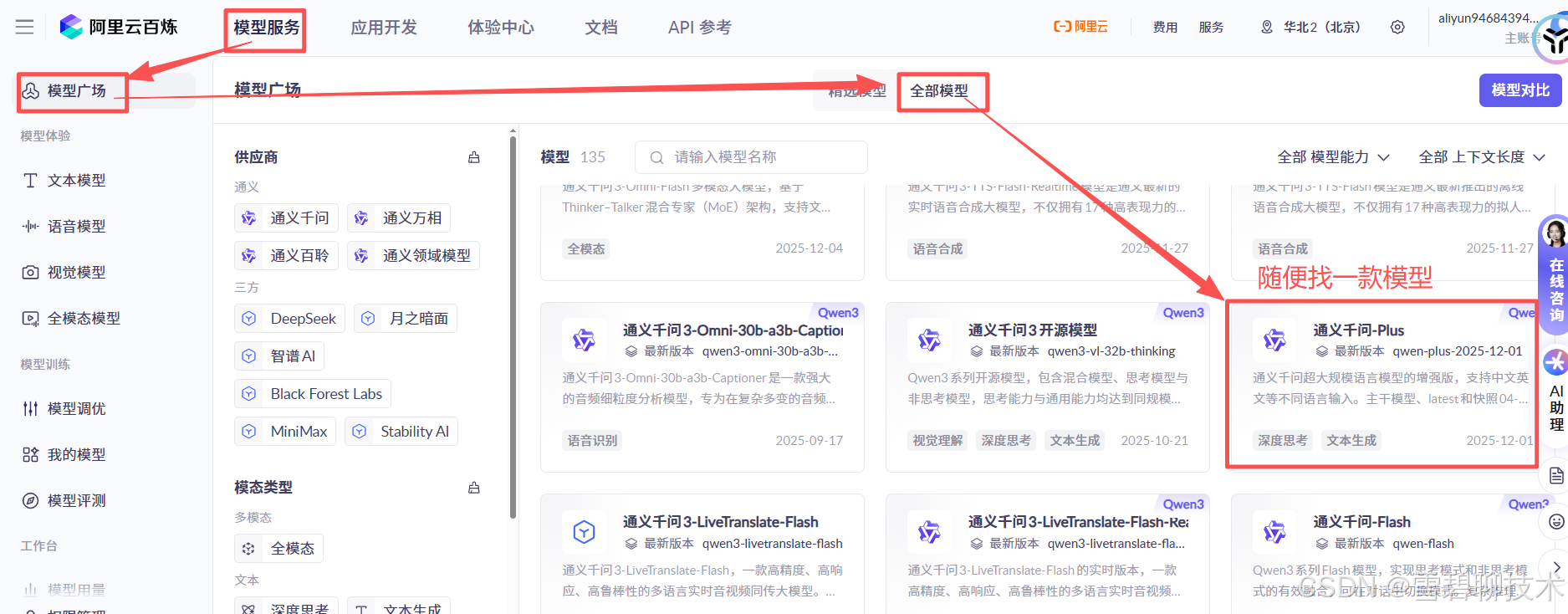
1)登录阿里云http://www.aliyun.com/
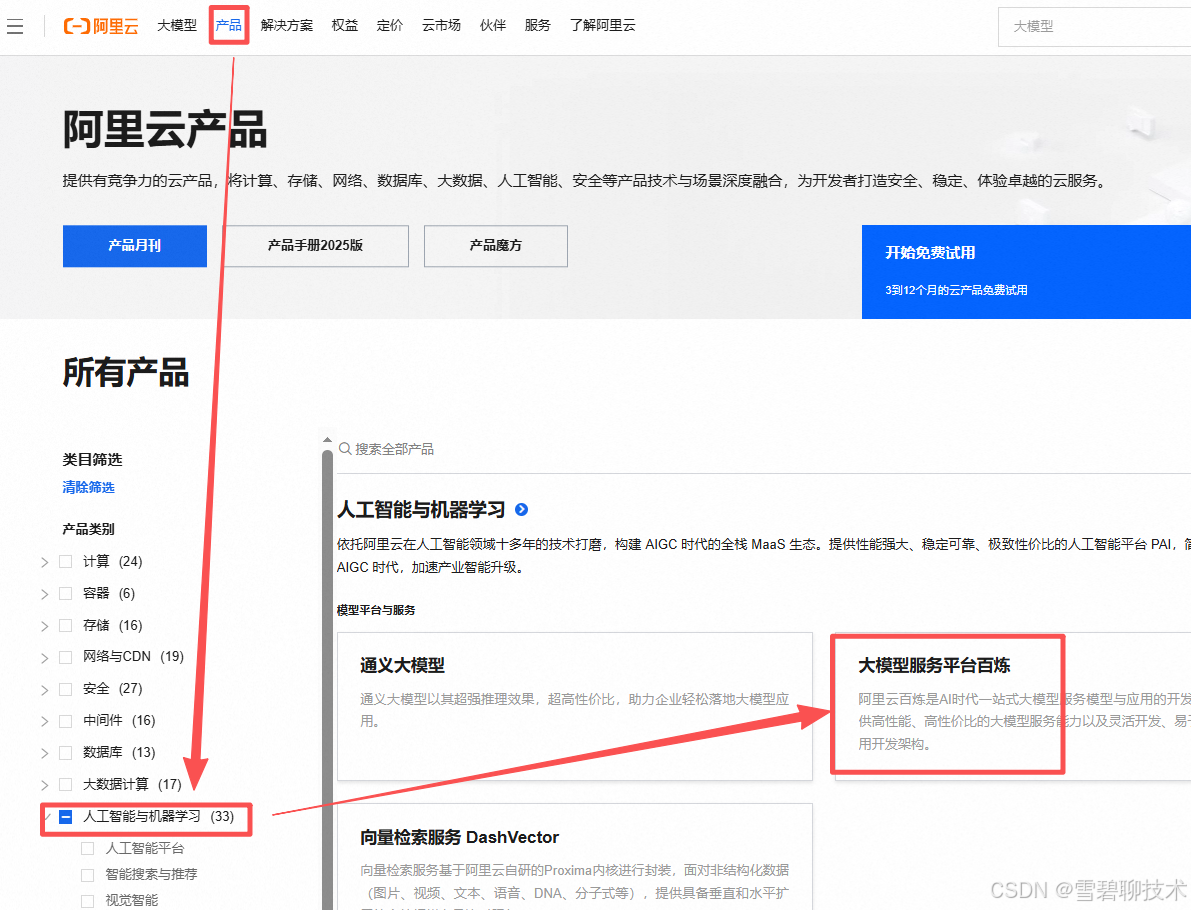
2)开通【大模型服务平台百炼】服务
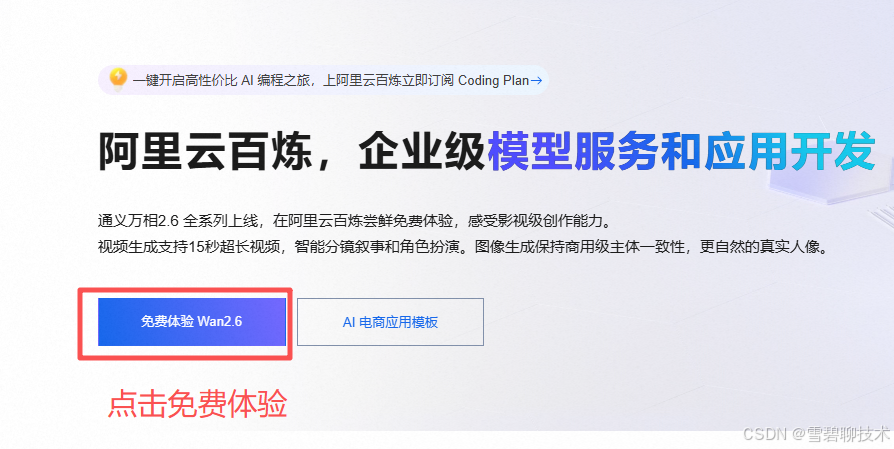
3)申请百炼平台API-KEY
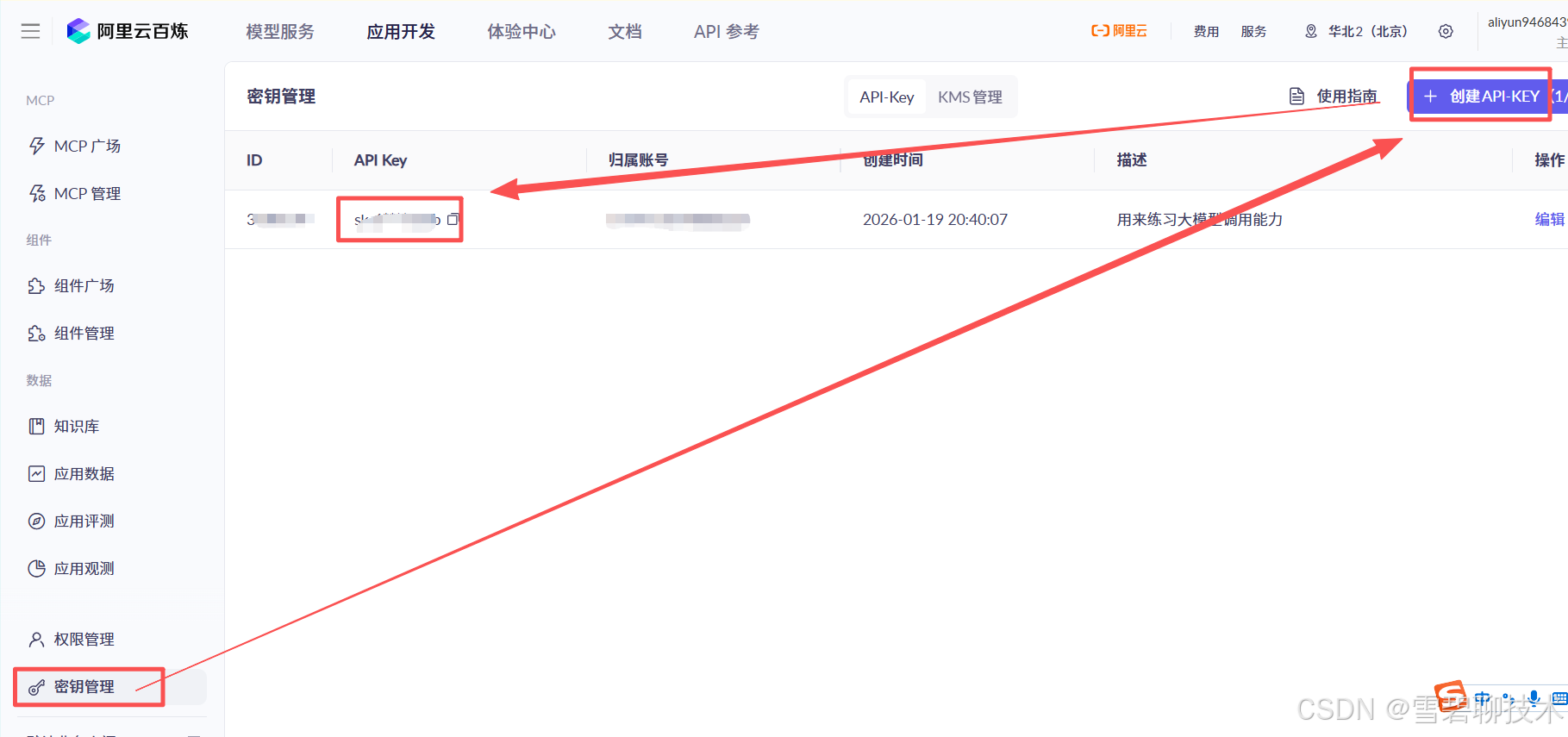
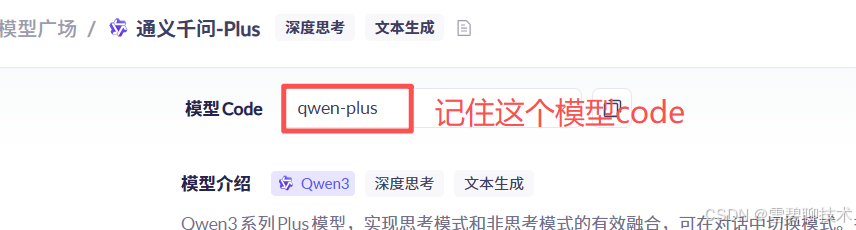
4)选择模型并使用
点击发送,查看响应结果:
至于响应结果里面都是些什么具体的内容,我们在【二】中详细讲解。
二.大模型调用
1.常见参数

1)model
告诉阿里云平台,你要调用哪个模型。
2)message
发送给模型的数据,模型会根据这些数据做出合适的响应。
①content
要问的问题(消息)。
②role
消息类型(角色)。
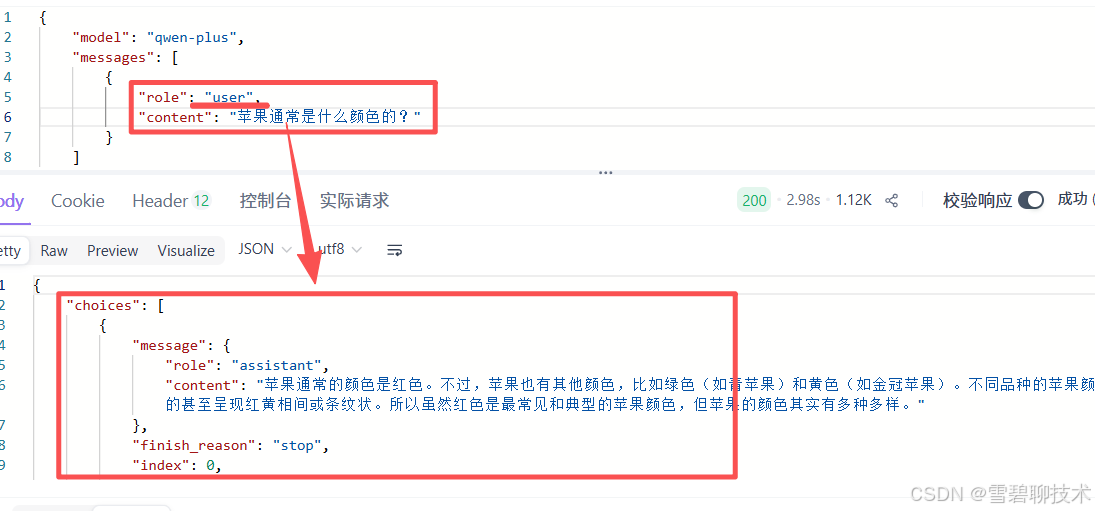
- user:用户消息(和我们平时使用deepseek没啥区别,就正常问)
- system:系统消息(用于给系统设定某些信息)
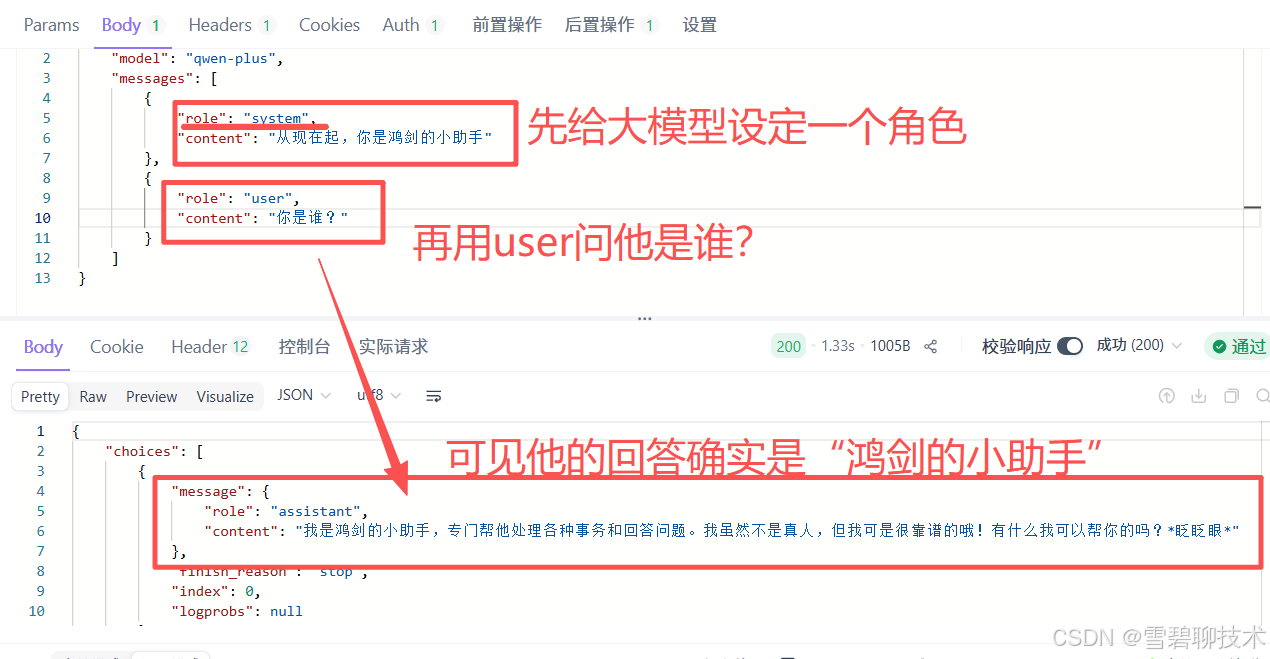
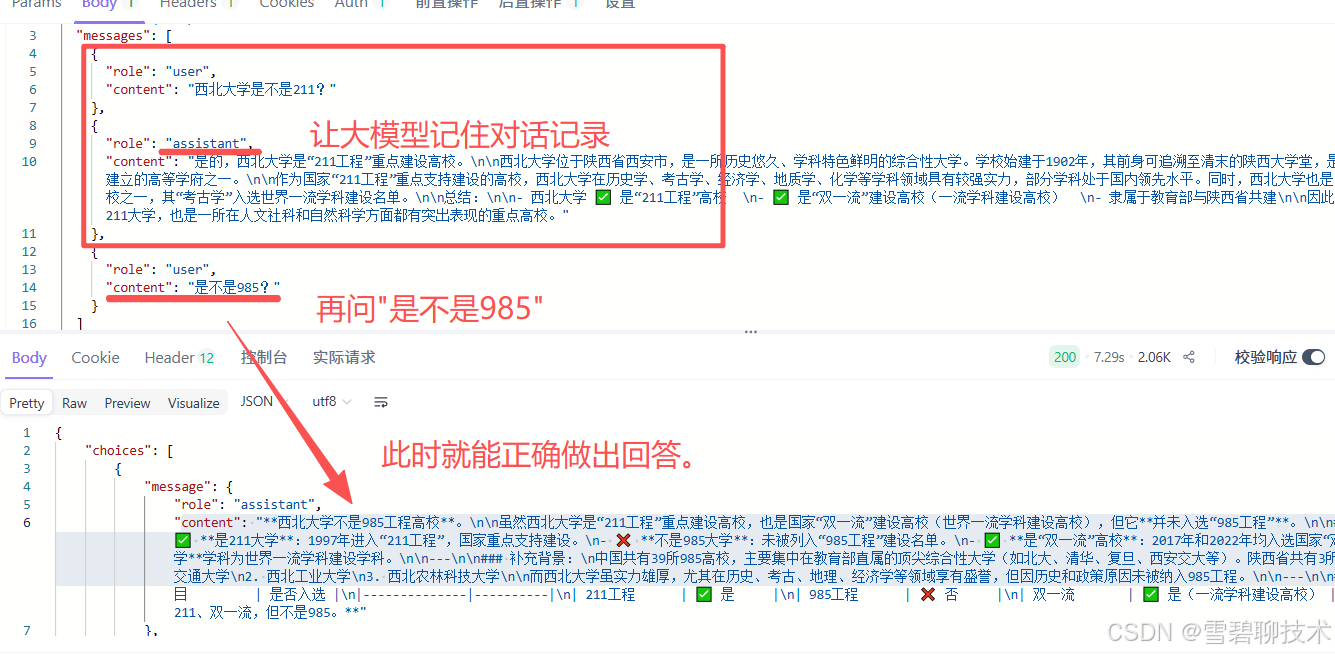
- assistant:模型响应消息(可以令本没有记忆功能的大模型,记住对话的上下文)
先来个反例:先问"西北大学是不是211",然后再问"是不是985"
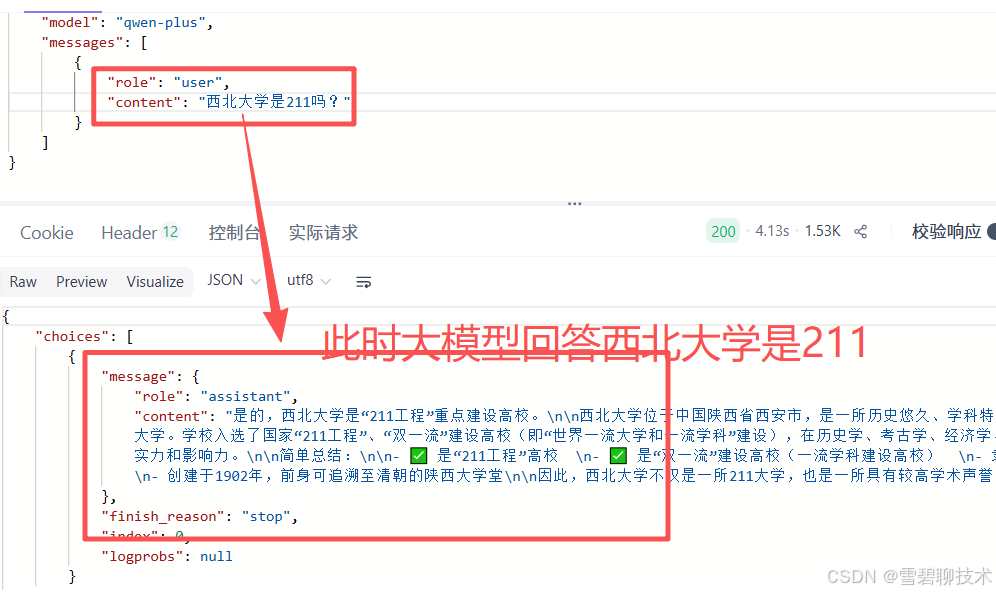
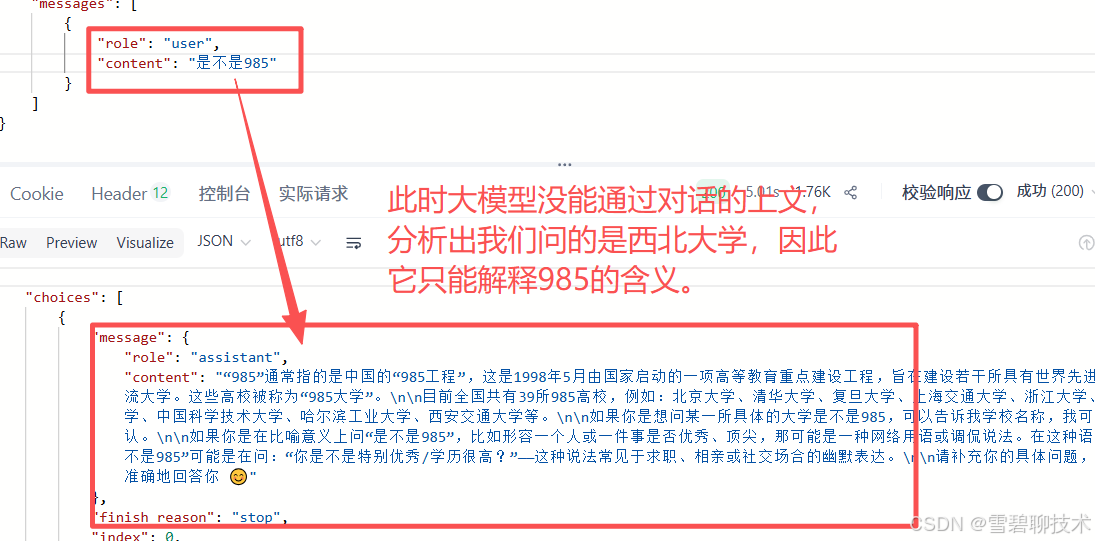
下面改进一下:
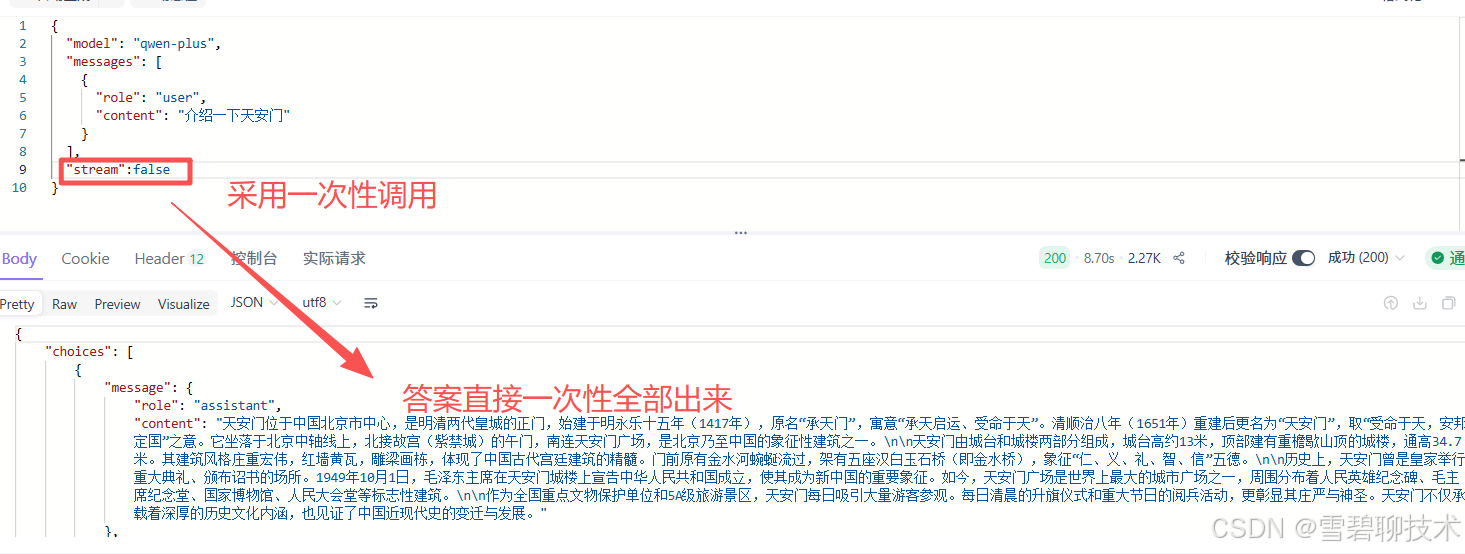
3)stream
- true:非阻塞调用(流式调用)
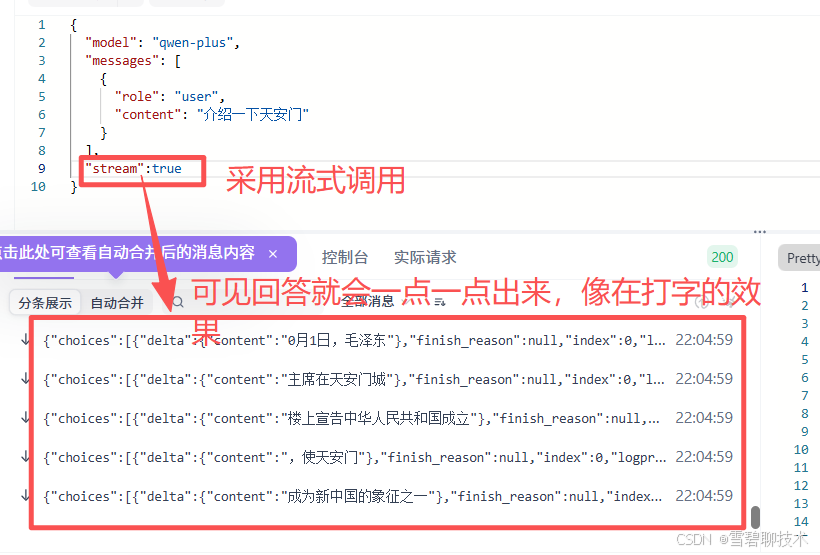
- false:阻塞调用(一次性响应),这是默认值
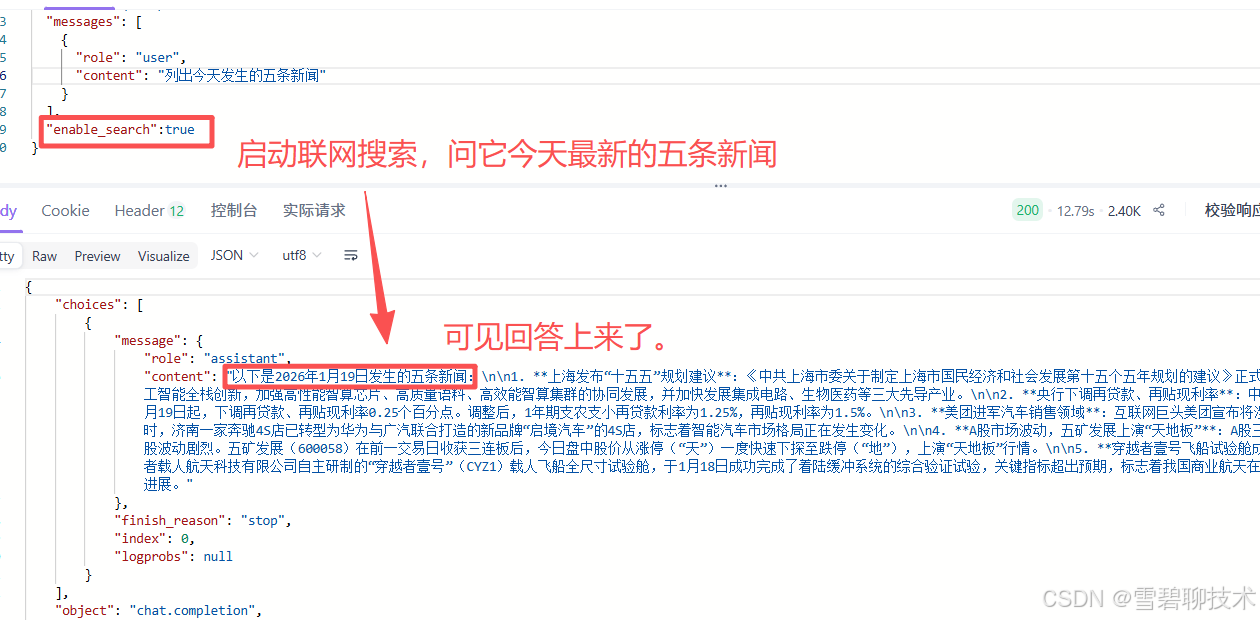
4)enable_search
是否启用联网搜索,启用后,模型会将搜索结果作为回答时的参考信息。
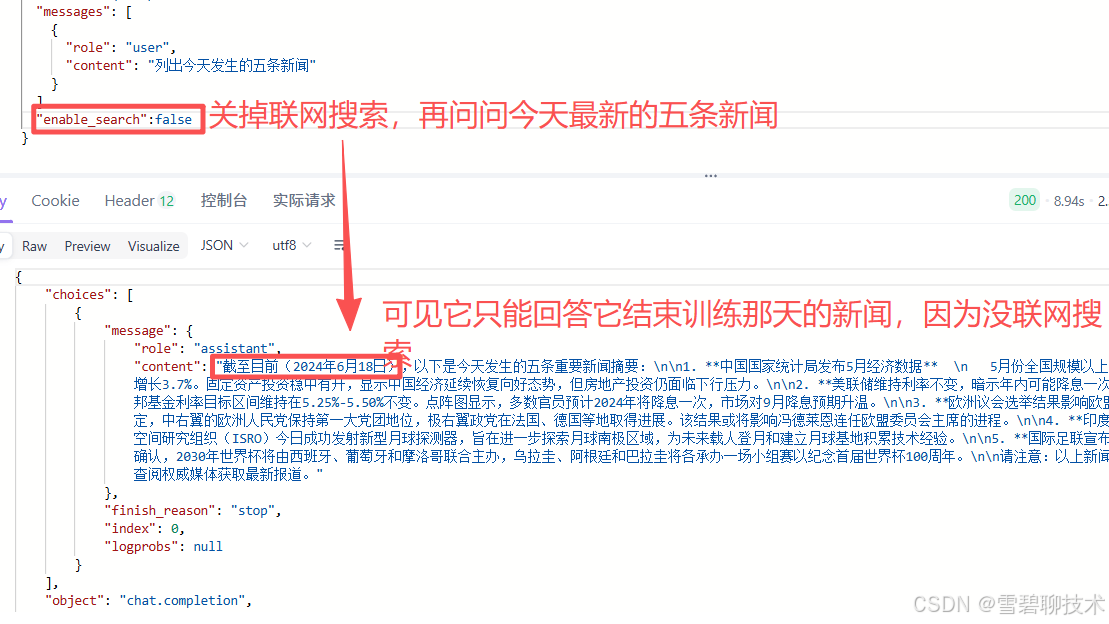
这个功能很有必要,因为大模型在结束训练的那一刻,永远都不会在接受新的知识了,因此根据联网搜索的结果,可以帮助大模型回答它不知道的一些最近发生的事情。
- true
- false
2.响应数据
重点关注红框部分即可。

以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~