简介
ADALog: 自适应无监督异常检测框架,旨在适用于各种现实环境。与依赖日志解析、严格序列依赖或标注数据的传统方法不同,ADALog 直接作用于单条非结构化日志,提取日志内部的上下文关系,并对正常数据执行自适应阈值设置。采用基于 Transformer 的、预训练的双向编码器,使用掩码语言建模任务,在正常日志上进行微调,从而捕捉复杂环境中异常检测所需的领域特定语法和语义模式。异常通过 标记级别(token-level) 的重构概率进行识别,并聚合为日志级别的评分,使用仅基于正常数据校准的 基于百分位数的自适应阈值 来判断异常。
模型能够动态适应系统行为的演变,增强泛化能力,同时避免传统异常检测方法中常用的启发式阈值所带来的僵化问题。ADALog 具备无序列依赖、自适应和无监督的特点,是一种可扩展、具有弹性且实用的异常检测解决方案,适用于从云基础设施到本地计算环境等多种现代软件系统生态。
ADALog ,一个无监督的异常检测框架 ,无需标注数据、手动日志解析或严格的事件序列连续性。ADALog 通过对预训练的 Transformer 语言模型进行微调,结合基于自注意力机制的掩码语言模型(MLM),直接在原始日志数据上学习领域特定的语法与语义关系,实现对多种日志格式中异常的鲁棒检测。
在检测过程中,ADALog 通过标记级别(token-level)的重构概率 计算并聚合为日志级别评分 ,再采用基于百分位数的自适应阈值机制 来替代传统的启发式方法,提升泛化能力与适应性。利用标记位置热图来提升模型的可解释性,区分正常与异常日志的关键 token 及其位置。
-
提出了一种可直接用于原始未解析系统日志的异常检测框架 ,具有序列无关性,无需复杂的解析流程或严格的时序依赖,从而提升了对多样日志格式的适应性,并简化了部署过程。
-
利用预训练语言模型在领域日志数据上以 MLM 目标进行微调 ,本方法可学习日志中的细粒度语法与语义模式 ,从而实现对稀有或孤立异常的高精度检测,适用于结构复杂、格式多样的日志数据集。
-
提出了一种基于正常日志预测误差的自适应阈值设定方法 ,该方法能够动态适应日志行为的演化与系统结构的多样性,且完全不依赖任何标注数据,具备强泛化性。
-
通过消融研究探索日志中 token 位置对模型决策的影响 ,增强了模型的可解释性,并为无监督异常检测方法的进一步研究提供了新方向。
日志特点
日志通常包含时间戳、错误代码以及描述性信息,但由于日志数据量巨大,且错误本身并不总是代表系统故障,因此仅靠显性信息难以判断系统异常。日志中的上下文含义或隐藏模式需要通过复杂处理才能被提取。同时日志本身具有多样性,可能是标准顺序结构的,也可能是部分甚至完全无结构的序列,有些系统还会生成数值摘要,从而破坏了时间序列的连续性。
系统日志由单独的日志条目组成,每条日志通常包含典型的组成部分,如时间戳(timestamps) 、日志级别(log levels) 、消息 ID(message IDs) 、文件路径(file paths) 、数值(numerical values) ,以及网络或内存地址(network or memory addresses) 。每条日志条目都被表示为一个变长的 token 序列,反映了系统生成数据的异构性,也是异常检测框架的基本处理单元。
为了在不牺牲对未知或变化格式的适应性的前提下,实现对原始日志数据的标准化处理以用于异常检测,ADALog 引入了一种轻量级清洗流程 ,无需依赖日志解析(parsing)。给定一条原始日志条目 ( l ),该日志通常包括如时间戳、日志级别、消息标识符、文件路径、数值以及网络或内存地址等组成部分。
-
移除时间戳 :删除符合时间戳模式的子字符串(例如:
2005-06-09-14.53.14.219998),以消除时序信息对模型造成的偏差(temporal bias)。 -
分割复合 token:连续大写字母组成的 token 会被拆分,以确保统一的 token 化处理。
-
抽象系统路径 :将文件路径替换为通用 token
filepath,抽象出具体系统相关的目录结构。 -
替换数值与地址:
-
将数值(如
3.2143)替换为 tokenfloat; -
将网络或内存地址替换为通用 token
address。
-
基于转换的、有针对性的清洗策略 ,能够在最小化冗余信息和潜在偏差的同时,输出一个去噪后的日志表示,从而增强后续异常检测过程的鲁棒性。
而传统的日志解析工具尝试为原始日志强加结构,但不断变化或种类繁多的日志格式时会失效。因此从日志中实现及时且准确的异常检测仍是一个充满挑战但至关重要的任务,这对于保障实时及离线软件系统的可靠性、稳定性和风险控制具有关键作用。
当前大多数基于机器学习的日志异常检测研究和应用仍依赖日志解析工具,这些工具依赖于预定义的结构,可能导致关键的稀有信息被忽略。同时,这些方法往往应用基于事件顺序的模型,而实际中日志序列常常是不完整或破碎的;此外,许多异常检测系统仍使用启发式阈值设定,从而降低了方法在多样化场景中的泛化能力。
ADALog 训练预测
问题定义:使用 l = (w1, w2, w3,...) 代表一个日志序列,wi 属于集合 V,设 V 是唯一日志键(log key)的集合,令所提出的模型 f 将日志条目 l 分类为 正常(normal)或异常(anomalous)。
训练 :仅使用正常的日志序列 ,采用掩码语言建模(Masked Language Modeling, MLM)。从序列索引集合中选取一个子集,将对应位置的 token 替换为特殊的 [MASK] 标记,生成掩码序列。使用一个基于 Transformer 的双向编码器 ,对每个被掩码的位置预测原始 token ,通过最大化以下条件概率实现训练目标: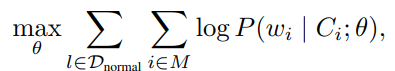 ,Ci代表 wi前后文,Θ道标模型参数。
,Ci代表 wi前后文,Θ道标模型参数。
预测 :模型计算日志条目 ( l ) 的异常分数 ( s(l) ),定义为被掩码 token 的负对数似然(negative log-likelihood)的总和 :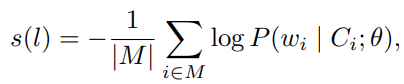 ,应用一个自适应阈值 ( T ),当日志序列的异常分数满足 ( s(l) > T ) 时,该日志序列被判定为异常(anomalous)。
,应用一个自适应阈值 ( T ),当日志序列的异常分数满足 ( s(l) > T ) 时,该日志序列被判定为异常(anomalous)。
ADALog 模型构建于 DistilBERT 架构之上, BERT 的一种轻量化变体,能够在降低计算开销 的同时,捕捉复杂的上下文关系 。整个方法分为三个主要步骤执行,每一步使用正常日志数据的一个不同子集 。在训练、阈值选择和推理阶段分别使用独立的数据集,是保持无监督方法本质的关键。模型在整个训练和校准过程中仅接触正常日志数据 ,从而完全不依赖异常样本或异常标签。
以下是你这段内容的中文翻译,分步骤呈现,语言准确、清晰,适用于学术论文或技术报告中的方法部分。
在正常数据上微调 BERT
ADALog 基于 DistilBERT 模型进行微调,训练数据集为来自正常日志条目 。每条日志可以表示为:l = (w_1, w_2, ...),对于每条日志 15% 的 token 被随机掩码(masked) ,记被掩码的索引集合为 M。模型的目标是利用被掩码 token 周围的上下文 ( C_i ),预测原始 token ( w_i )。对于每个 token ( w_i ),其预测概率通过对整个词汇表 ( V ) 应用 softmax 函数计算: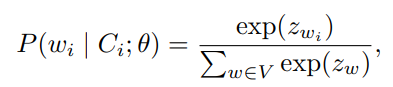 训练目标是最小化每个被掩码 token 的交叉熵损失(cross-entropy loss)
训练目标是最小化每个被掩码 token 的交叉熵损失(cross-entropy loss) 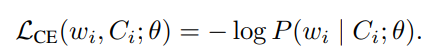 ,并将其在整个训练集上的掩码 token 中聚合,形成整体的 MLM 损失:
,并将其在整个训练集上的掩码 token 中聚合,形成整体的 MLM 损失:
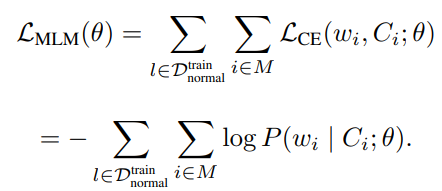
最小化该损失函数后,得到一组适应特定领域的模型参数,能够准确建模正常日志条目的统计分布、语法和语义结构。
预测与阈值选择
在第二阶段,使用上述训练得到的微调模型对一个独立的验证集 进行推理,以生成 token 级别的预测结果,并校准一个自适应阈值(adaptive threshold) 。为了与训练阶段保持一致,验证集上同样采用每条日志随机掩码 15% 的 token 的策略,记这些被掩码的位置为 ( M )。对于每个被掩码 token ( w_i ),模型根据上下文计算其预测概率 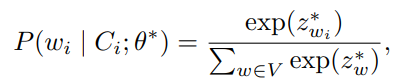 。通过对这些概率的负对数取和,可以得到每条日志的异常分数,用于后续阈值设定,
。通过对这些概率的负对数取和,可以得到每条日志的异常分数,用于后续阈值设定,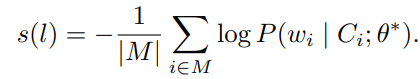
自适应阈值设定与异常检测
假设正常日志的异常分数服从某一分布,自适应阈值 定义为该分布的90百分位数(0.9 分位点):
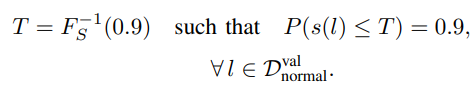
如果 ( f_S(s) ) 是异常分数的概率密度函数(PDF),则 ( T ) 满足如下积分条件: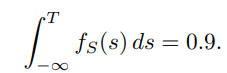
这种基于分位点的阈值设定策略在控制误报率(False Positives)和 保持召回率(Recall)之间实现了良好平衡:将阈值设置在第 90 百分位意味着,只有异常分数最高的 10% 正常日志会处于决策边界附近,从而减少将正常日志误判为异常的风险,同时仍能有效捕捉真正的异常行为。
异常检测阶段
在最后阶段,使用已经微调完成的模型对测试数据集推理,该数据集包含正常与异常日志条目。
对每一条日志使用与训练阶段相同的掩码与聚合策略,计算其异常分数:
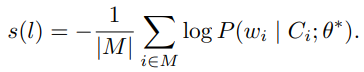
根据第 90 百分位数阈值 ( T ),将日志进行分类
通过在三个阶段中使用相互独立的数据集 :ADALog 框架确保了整个流程是完全无监督的 。该分离策略确保模型校准仅依赖正常日志,使其能够在异常标签稀缺或完全不可用的场景下有效应用。通过在 MLM 训练阶段引入交叉熵损失 、在训练与预测阶段保持一致的批次掩码策略 ,以及基于分位数的严格阈值设定 ,ADALog 为在动态变化的日志环境中进行异常检测提供了坚实的理论基础 和实用价值。
import os
import re
import numpy as np
import torch
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import (
DistilBertTokenizer,
DistilBertForMaskedLM,
DataCollatorForLanguageModeling,
Trainer,
TrainingArguments,
)
from datasets import Dataset
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
project_path = os.getcwd()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def clean_log(log):
log = re.sub(r'\d{4}-\d{2}-\d{2}-:\\.\\d\\s+', '', log)
log = re.sub(r'(/\\w\\-\\.+)+', 'filepath', log)
log = re.sub(r'\b(?:\d{1,3}\.){3}\d{1,3}\b', 'address', log)
log = re.sub(r'0x0-9a-fA-F+', 'address', log)
log = re.sub(r'\d+\.\d+', 'float', log)
log = re.sub(r'\b\d+\b', 'float', log)
return log
def tokenize_function(examples):
return tokenizer(examples"text", truncation=True, padding="max_length", max_length=256)
def prepare_dataset(raw_logs):
cleaned = clean_log(log) for log in raw_logs
dataset = Dataset.from_dict({"text": cleaned})
tokenized_dataset = dataset.map(tokenize_function, batched=False)
return tokenized_dataset
def compute_anomaly_scores(model, dataset):
model.eval()
scores = \[\]
for i in range(len(dataset)):
inputs = tokenizer(dataseti"text", return_tensors="pt", truncation=True, padding="max_length", max_length=128).to(device)
input_ids = inputs"input_ids"
attention_mask = inputs"attention_mask"
Mask 15% of tokens randomly
mask = torch.rand(input_ids.shape).le(0.15).to(device) & (input_ids != tokenizer.cls_token_id).to(device) & (input_ids != tokenizer.pad_token_id).to(device)
labels = input_ids.clone()
input_idsmask = tokenizer.mask_token_id # mask token
with torch.no_grad():
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss.item()
scores.append(loss)
return np.array(scores)
def plot_score_distribution(scores, threshold, save_path="score_plot.png"):
sns.set(style="whitegrid")
plt.figure(figsize=(8, 5))
sns.histplot(scores, bins=50, kde=True, color="skyblue", label="Anomaly Scores")
plt.axvline(x=threshold, color="red", linestyle="--", label=f"Threshold = {threshold:.4f}")
plt.xlabel("Anomaly Score")
plt.ylabel("Frequency")
plt.title("Log Anomaly Score Distribution")
plt.legend()
plt.tight_layout()
plt.savefig(save_path)
print(f"+ Saved anomaly score plot to: {save_path}")
if name == "main":
model_path = project_path + "/models/base_model/distilbert-base-uncased"
tokenizer = DistilBertTokenizer.from_pretrained(model_path)
Replace below with your own datasets
train_logs = "Error at module A: value 3.14", "System start at /home/logs", "Connected to 192.168.0.1" * 100
val_logs = "Error at module B: value 2.71", "Cache flushed /var/cache", "Ping to 10.0.0.2" * 20
test_logs = "Error at module A: value 3.14", "Exception occurred in line 42", "Hacked at 255.255.255.255" * 10
test_labels = 0, 1, 1 * 10 # Ground-truth labels for evaluation (0 = normal, 1 = anomaly)
train_dataset = prepare_dataset(train_logs)
train_dataset = train_dataset.remove_columns("text") # 删除原始文本字段,避免 Trainer 传给模型时报错
print(train_dataset0)
val_dataset = prepare_dataset(val_logs)
test_dataset = prepare_dataset(test_logs)
model = DistilBertForMaskedLM.from_pretrained(model_path)
model = model.to(device)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
training_args = TrainingArguments(
output_dir=project_path + "/models/adalog_model",
eval_strategy="no",
per_device_train_batch_size=16,
num_train_epochs=20,
save_total_limit=1,
logging_steps=10,
logging_dir=project_path + '/logs',
remove_unused_columns=False
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=data_collator
)
trainer.train()
model = DistilBertForMaskedLM.from_pretrained(project_path + "/models/adalog_model/checkpoint-380")
model = model.to(device)
val_scores = compute_anomaly_scores(model, val_dataset)
T = np.percentile(val_scores, 90) # Adaptive threshold
test_scores = compute_anomaly_scores(model, test_dataset)
predictions = (test_scores > T).astype(int)
precision, recall, f1, _ = precision_recall_fscore_support(test_labels, predictions, average="binary")
accuracy = accuracy_score(test_labels, predictions)
print("\n=== Evaluation Metrics ===")
print(f"Threshold T: {T:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1-score: {f1:.4f}")
print(f"Accuracy: {accuracy:.4f}")
参考: