
🔥海棠蚀omo:个人主页
❄️个人专栏:《初识数据结构》,《C++:从入门到实践》,《Linux:从零基础到实践》,《Linux网络:从不懂到不会》
✨追光的人,终会光芒万丈
博主简介:

目录
前言:
在上一篇文章《初识 HTTP 协议》中,我们从整体视角认识了 HTTP 的基本概念、请求与响应的宏观结构,对浏览器与服务器之间的通信过程有了初步印象。然而,"知道它是什么"并不等同于"真正理解它是如何工作的"。
本文将在此基础上进一步深入,从 HTTP 报文结构、请求方法、状态码、头字段以及通信细节等方面展开分析,逐步拆解一次 HTTP 请求在网络中的完整生命周期。希望通过系统性的梳理,将零散的知识点串联起来,帮助你从"初识 HTTP"走向"理解 HTTP"。
一.初识状态码
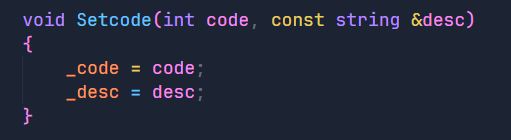
在上一篇初识http协议中,我们在设置状态码的时候,为了便于演示,我们当时是直接传入状态码和状态符描述,但其实状态码和状态符描述一般是一一对应的,下面我们来看:
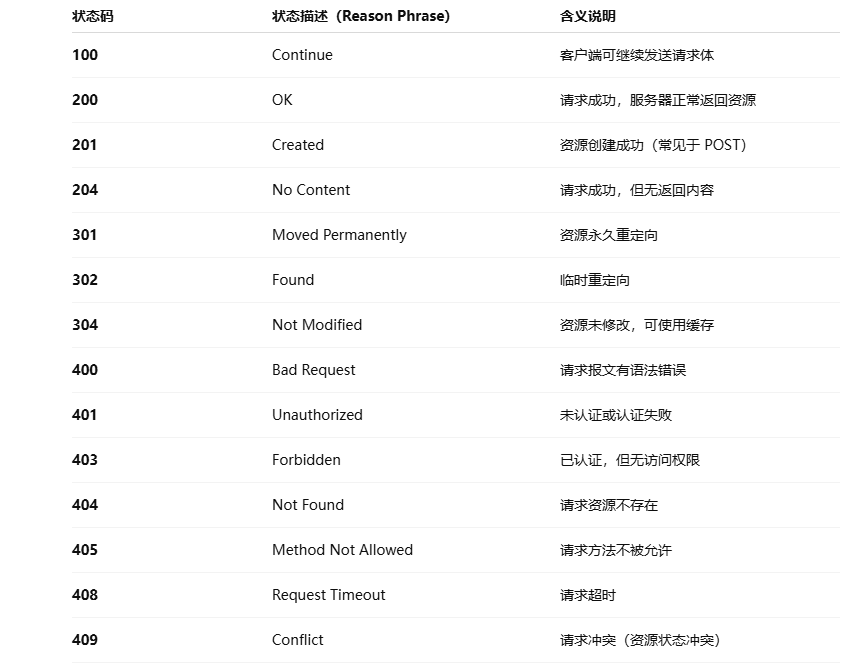

上面这两幅图就展示了不同的状态码所对应的状态符描述,所以我们要对上面的代码进行修改,我们来看:
cpp
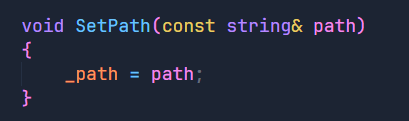
void Setcode(int code)
{
if (code >= 100 && code < 600)
{
_code = code;
_desc = Code2Desc(code);
}
else
{
LOG(LogLevel::FATAL) << "非法状态码" << code;
}
}
cpp
string Code2Desc(int code)
{
switch (code)
{
case 200:
return "OK";
case 400:
return "Bad Request";
case 404:
return "Not Found";
case 301:
return "Moved Permanently";
case 302:
return "See Other";
case 307:
return "Temporary Redirect";
default:
return "";
}
}因为状态码是从1开头到5开头的,所以这里我们对SetCode函数的主体做了一个简单的判断,只要不在100-599这个范围内就属于非法的状态码。
然后我们通过传入不同的状态码,去调用Code2Desc函数来找到与状态码相对应的状态符描述,这里我们不列举全,列举几个即可,用不了那么多。

那么在HandlerRequest函数中的逻辑我们就可以这样来设计,但是我们想一想:既然找到相应的文件资源返回成功有相应的页面,那么未找到相应的文件资源,也就是状态码为404的时候,我们是不是也可以专门来设置一个页面?
这个页面相信我们大家在浏览器访问网页的时候都见过,所以下面我们就来简单的设计一个页面来看看效果:

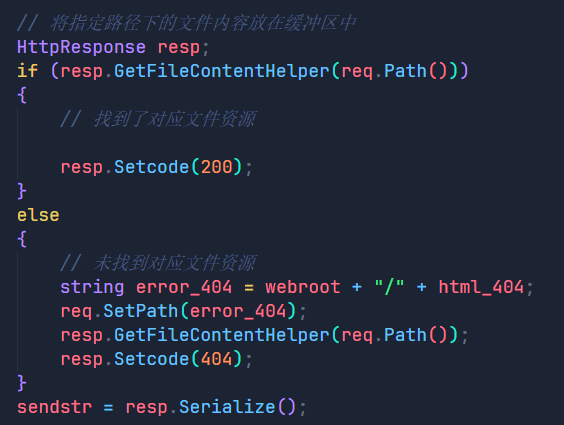

在上面我们通过判断GetFileContentHelper函数的返回结果进行操作,如果返回的是true,说明找到了目标文件资源,那么我们就将状态码设置为200,表示成功。反之如果返回false,则表示未找到目标文件资源,我们就将状态码设置为404,并将正文部分重新设置为404.html文件中的内容,返回给客户端。
最终我们看到的就是上图所示的404页面结果,通过这种方式我们其实就知道了404页面底层的实现原理。
那么状态码的介绍我们就先告一段落,下面我们就来详细介绍报文中的各个字段。
二.HTTP的常见Header
请求报文和响应报文中都有各自的字段,但是请求报文的字段更多,也更全,所以这里我们以请求报文中的字段来进行介绍。
那么首先我们先来实现一个函数,将我们将要设置进报头的字段给设置到_resp_headers中,下面我们来看:

思路很简单,直接借助unordered_map的\[\]的特性即可。
2.1Content-Length
那么首先我们要讲的就是Content-Length,再上一篇初识HTTP协议的时候我们就已经对该字段进行了说明,它表示的就是正文部分的长度,所以下面我们也不废话,直接在我们的报头中加上该字段:
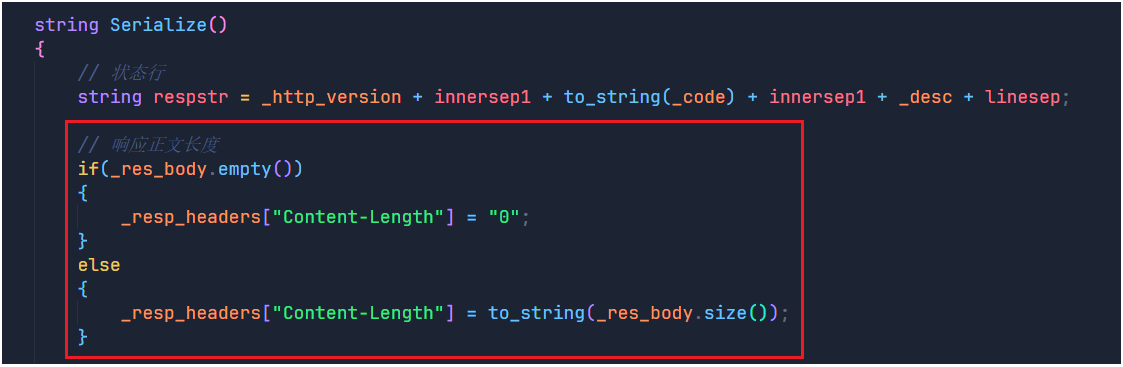
我们直接在Serialize序列化函数中进行判断,如果正文部分为空,那么我们就将该字段的值设置为0,反之就将其设置为正文部分的长度即可。
然后下面的代码就会将_resp_headers中的各种字段添加到报头中,我们不需要做其他的工作。
2.2Content-Type
对于正文部分,不知道大家有没有一种疑惑:我们上面使用了html语言来设计了我们服务器的页面和404页面,那么客户端是怎么知道我们正文部分的类型的,对其进行解析,并呈现给我们的?
答案就是http协议的应答是超文本,是有自己的类型的,这个类型就通过Content-Type字段来表明,但是就和语言中的类型一样,类型是很多的,那我们该如何区分不同的类型呢?
答案就是通过文件后缀来进行区分,下面我们来看:
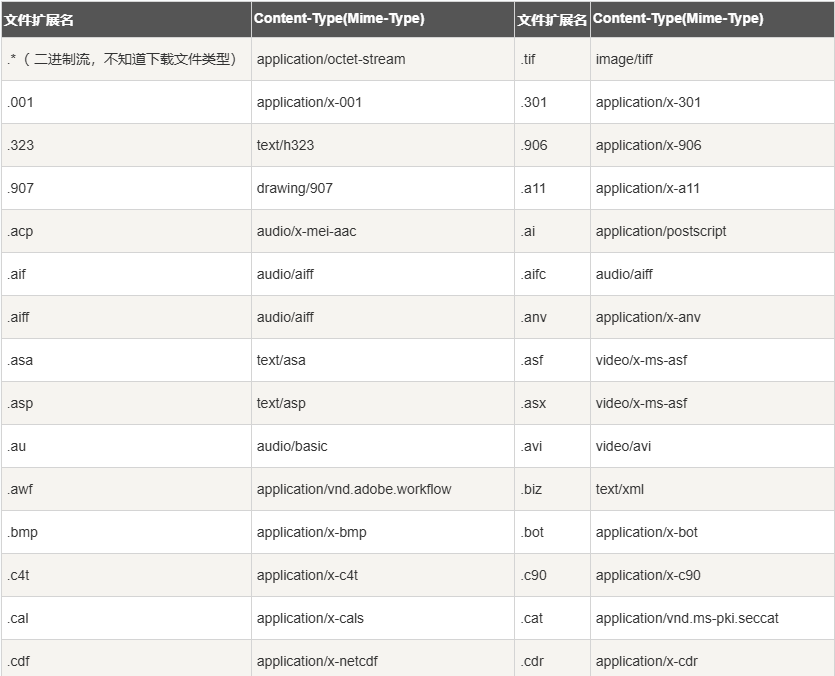
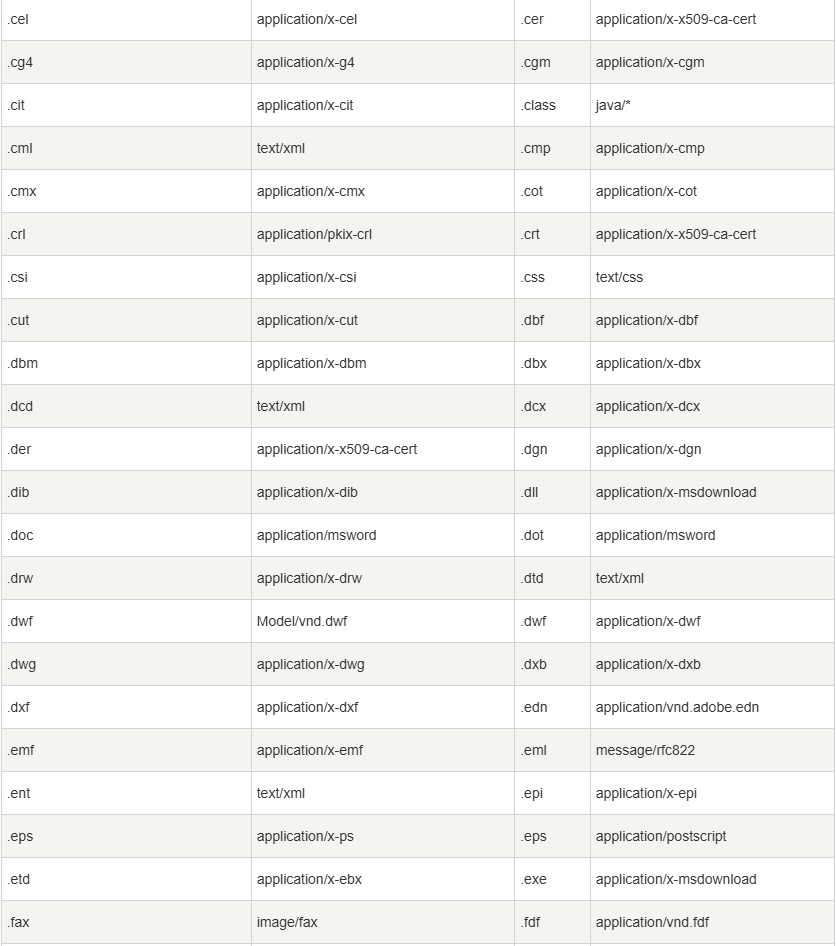
上面我只列举了一部分,而这两幅图就揭示了不同的文件后缀名对应的也是不同的Content-Type,客户端最终就是通过该字段就知道了正文部分的内容是什么类型,进而有针对性地进行解析,解析完成后就有了我们算看到的画面。
那么下面我们就来着手实现添加该字段的工作:
cpp
string Suffix()
{
int pos = _path.rfind('.');
if (pos == string::npos)
{
// 表示没找到后缀名
return string();
}
return _path.substr(pos); // .html
}
cpp
string Suffix2ContentType(const string &suffix)
{
if (suffix == ".html" || suffix == ".htm")
{
return "text/html";
}
else if (suffix == ".css")
{
return "text/css";
}
else if (suffix == ".js")
{
return "application/javascript";
}
else if (suffix == ".jpg" || suffix == ".jpeg")
{
return "image/jpeg";
}
else if (suffix == ".png")
{
return "image/png";
}
else
{
return "application/octet-stream";
}
}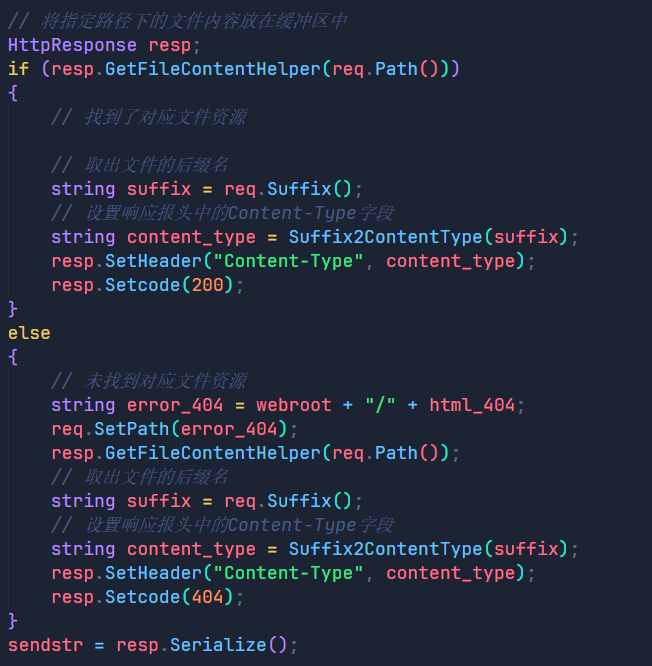
首先我们要通过Suffix函数来取出文件的后缀名,之后我们还要通过Suffix2ContentType函数将不同的文件后缀名设置为相对应的Content-type,最后通过SetHeader函数将该字段设置进去。
那么截止到现在,下面我们就来看看我们的字段是否真的设置到报文中了:
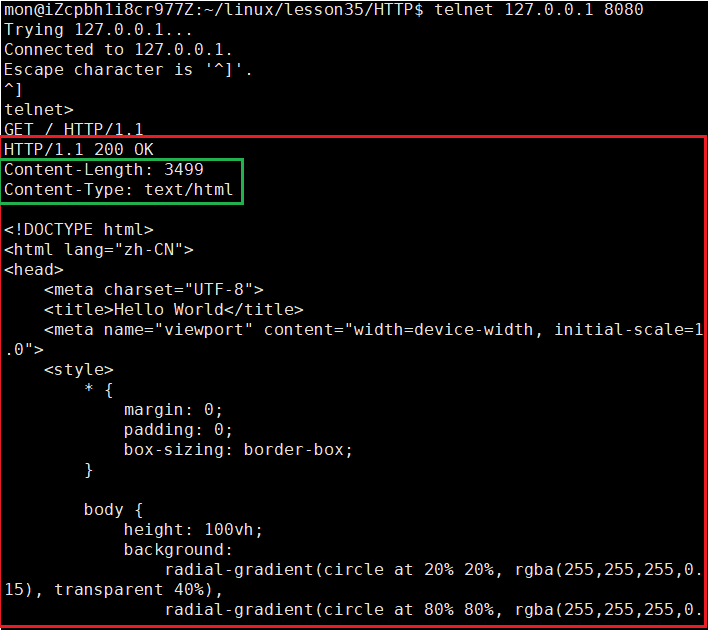
我们可以通过talnet命令来访问我们的服务端,红色方框圈起来的就是我们的响应报文,而在报文中我们通过绿色方框圈起来的内容可以看到我们此时已经将Content-Length和Content-Type设置进报文中了。
2.3Referer
Referer字段简单理解就是表明当前页面是从哪个页面跳转过来的,下面我直接通过例子来展示一下:

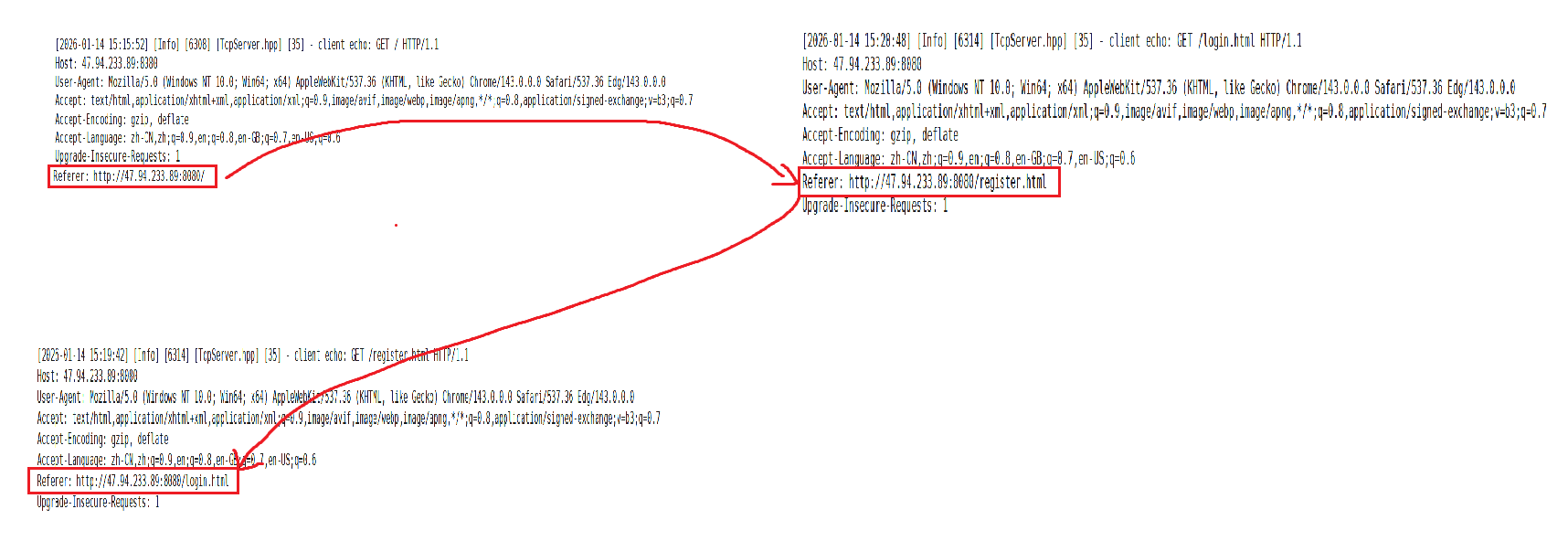
上面我在服务器页面的基础上又添加了两个页面,分别是登录和注册页面,使它们之间能够互相跳转,而在上面我就进行了简单的跳转工作。
从最后一张图中我们可以看到,它们的Referer并不相同,说明它们当前的页面是从不同的页面跳转过来的。
那么该字段有什么作用呢?
那么很明显的就是知道了当前页面是从哪个页面跳转过来的,也就是起到了数据统计的作用,那么如果我不想让你从某个页面跳转到另一个页面,能否做到呢?
当然可以,所以该字段的第二个作用就是可以起到拦截作用!!!
2.4Connection

keep-alive的意思就是期望长连接,其实长连接是什么其实我们在实现网络版计算器的时候就已经见过了,简单理解就是让服务端recv客户端数据的过程长时间进行,而不是recv一次就结束了。
那么它的好处之一我们已经知道了,那就是:可以有效解决http协议的粘包,半包问题。
但是在HTTP/1.0版本的时候并不支持长服务的特性,那个时候http协议就和我们现在实现的是一样的短服务,什么意思呢?
简而言之就是客户端每发来一次请求,我们的服务端就要创建fd,创建子进程,来多个客户端请求,就要创建多个fd,多个子进程,而创建多个fd就意味着要建立多次的TCP连接,后面我们就会知道,一次TCP连接是要进行3次握手的,那么这效率就很低了。
所以后面就要解决这个问题,那么该如何解决呢?
既然客户端每发来一个请求,服务端都要建立TCP连接,创建fd,创建子进程,那么解决方法就是客户端发来多个请求的时候,服务端为每个客户端建立一次TCP连接,创建1个fd,创建1个子进程,但是这个连接是长时间的,可以随时处理客户端发来的请求。
这样做就不需要一个客户端每次发来请求都要建立TCP连接,创建fd,创建子进程,所以长服务的第二个好处就是:可以有效减少TCP连接的次数,提高效率!!!
而这个特性就在HTTP/1.1版本的时候出现了。

2.5Location
这个字段要搭配着3开头的状态码来使用,作用是告诉客户端接下来要去哪里访问,所以下面我们就要再谈状态码,来具体看看3开头的状态码具体是什么作用以及它该如何使用:
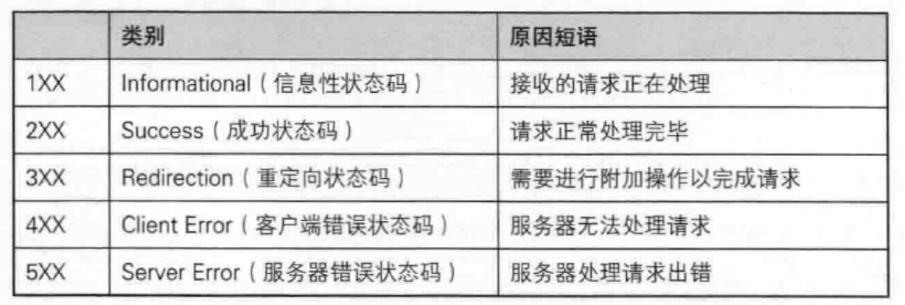
我们可以看这张图,在这张图中表明了以3开头的状态码叫做重定向状态码,那么下面我们来具体看看以3开头的状态码都有哪些:

一般我们常见的就是上图所示的四种状态码,它们中有临时重定向的,也有永久重定向的,虽然我们现在还不理解什么叫做临时重定向,什么叫做永久重定向。
并且这四个状态码中,307和308基本用不到,所以我们下面就将重点放在301和302这两个状态码上。
那么我们首先先了解一下什么叫做重定向,下面我用一个简单的例子来说明:
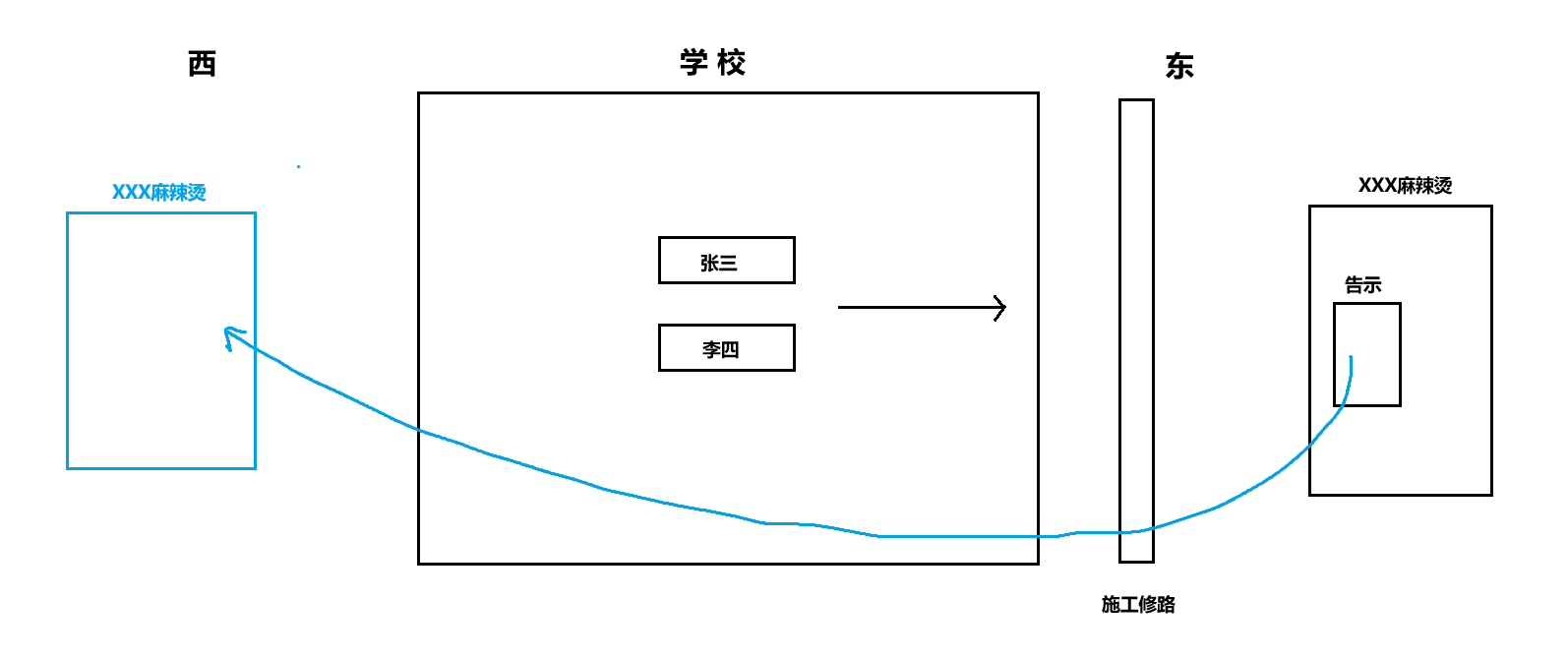
在学校的东边有一家麻辣烫,今天张三和李四两个人约着今天中午去学校外边的麻辣烫吃饭,而你们学校的东边呢现在正在施工修路,然后张三和李四就走到了麻辣烫店门口。
此时张三和李四发现麻辣烫没开门,并且在麻辣烫的门口有张告示,上面写着:" 因门口施工修路,给大家的用餐带来不便,故将店面移至学校西门,望周知"。
然后张三和李四就又从学校东门走到学校西门去吃这家麻辣烫了。
在上面的例子中就是我们生活中一个简单的重定向的操作:要求顾客更改吃饭的地址,去新位置就餐。张三和李四原本去学校东边吃麻辣烫,因施工原因,被重定向到学校西边去吃麻辣烫,那么什么叫做临时重定向?什么叫做永久重定向呢?
**临时重定向:**如果麻辣烫店门口的告示这样写:" 因门口施工原因,给大家的用餐带来不便,故暂时将店面移至学校西门,望周知 "。
" 暂时 "两个字就表明了这其实就是临时重定向,后面还是会移回来的。
**永久重定向:**如果麻辣烫店门口的告示这样写:" 因移到学校西门后生意更加火爆,故店面以后都在学校西门了,望周知 "。
这句话的意思其实就是永久重定向,麻辣烫的店面不会再移至学校东门了。
**临时重定向和永久重定向的本质区别就是:是否影响顾客对地址的认识。**临时重定向并不会影响顾客对于地址的认识,顾客知道后面就会移回来,所以以后还是会去学校东门吃饭。
但是如果是永久重定向,就会改变顾客对于地址的认识,顾客知道店面不会再移至学校东门,以后都在学校西门了,所以后面就不再去学校东门了,而是直接去学校西门。
那么临时重定向和永久重定向是什么我们已经介绍了,那么下面我们就来看看为什么要有临时重定向和永久重定向:
在上面的这张图后面的应用场景中我们其实已经揭晓了它们存在的原因:在用户登录页面的场景中,一般都要用到临时重定向的操作。而在网站更换域名后,想自动跳转到新域名,就要用到永久重定向的操作。
所以它们存在的原因就是因为有相应的应用场景。
那么最后我们就要来谈一谈临时重定向和永久重定向具体是怎么做的:
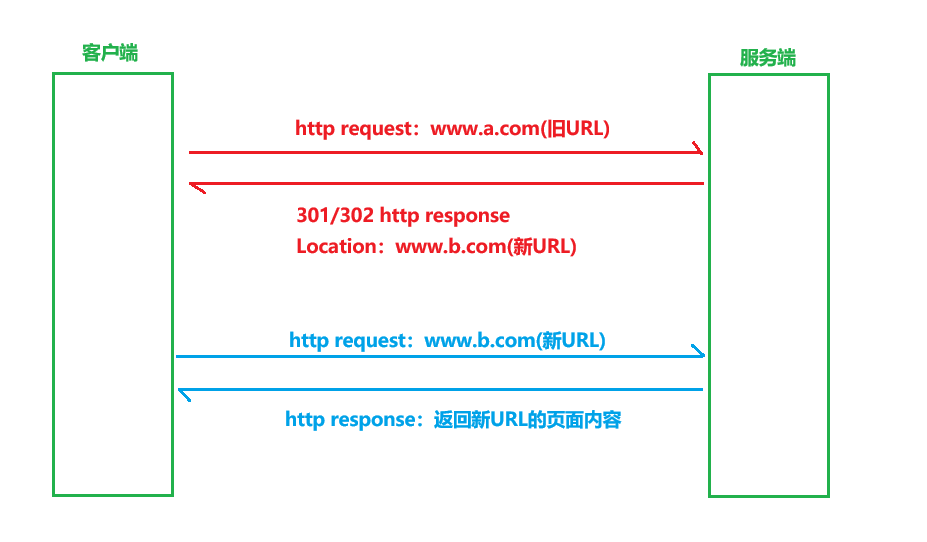
我们先说永久重定向,我们以网站更换域名的场景为例:当客户端拿着旧URL向服务端发起请求时,服务端发现是旧URL,所以会给客户端返回301,而Location这个字段的内容就是新URL,之后客户端在收到服务端的响应报文后,就会拿着新URL再次向服务端发起请求,最后服务端给客户端返回新域名的网页内容。
这就是永久重定向操作的相关思路,不难理解,那么下面我们来看看临时重定向是怎么操作的:

这里我以在视频网站上观看视频为例:当客户端发起观看视频的请求时,服务端发现客户端并未登录,于是返回302临时重定向,Location中就是登陆页面的URL,然后客户端就会先去请求登录页面,也就是向服务端发起登录请求,服务端于是返回登录页面的内容,在客户端完成登陆后,服务端会向客户端返回302临时重定向,Location中就是原视频的URL,最后客户端会再次向服务端发起观看视频的请求,此时服务端发现客户端已经完成了登录,于是返回视频内容。
上面就是我们在视频网站上点击视频,然后登录,最后成功看到视频的完整过程。
有了上面知识的铺垫,我们现在就知道了Location字段的作用:告诉客户端接下来去哪里是什么意思了。
那么讲完了重定向的相关知识,下面我们可以来修改一下我们的代码:

当在服务端没有找到相应的文件资源时,我们可以通过重定向的操作让客户端去请求404.html页面的内容,下面我们来看看效果:


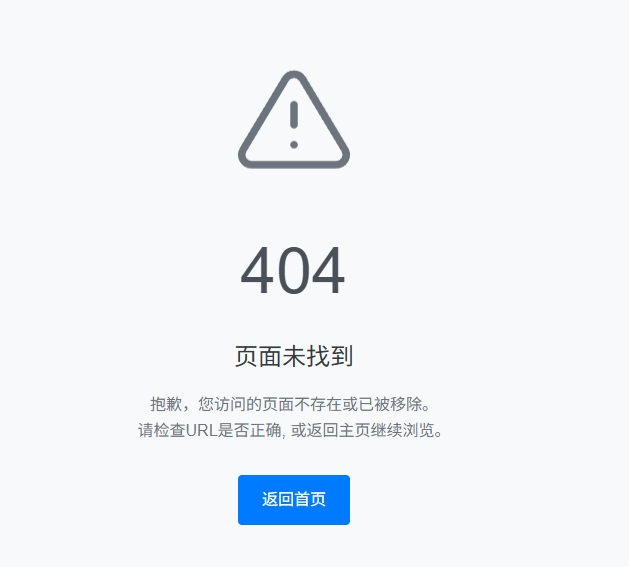
结果如我们所料,当找不到相应的文件资源时,通过重定向的操作同样可以实现返回404页面的内容。
2.6其他字段
那么最后我们再来看一些请求报文中其它字段的一些含义是什么。
1.Upgrade-Insecure-Requests
告诉服务端:如果可以,把不安全的 HTTP 资源升级为 HTTPS 返回给客户端。
2.Accept
告诉服务端:客户端可以接收哪些 MIME 类型的响应内容。
3.Accept-Encodeing
告诉服务端:客户端支持哪些内容压缩算法。
4.Accept-Language
告诉服务器:客户端更偏好的自然语言及优先级。
这些字段的作用我们了解一下即可。
三.HTTP请求方法
下面我们就来看看常见的请求方法都有哪些:
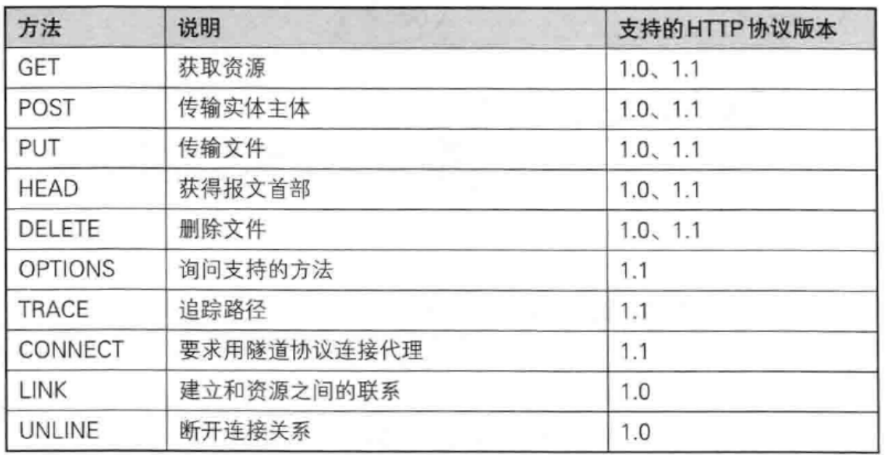
上面这副图中就展示了常见的http请求方法,这里面LINK和UNLINK这两个方法已经被淘汰了,所以这里就不再介绍了。
我们通过http请求一般只有两种行为:
1.从服务端获取内容
2.上传数据到服务端
而我们在实际应用中,绝大部分的情况下只会用GET和POST这两种方法,剩下的如:PUT,HEAD,DELETE,OPTIONS,TRACE等方法其实很多都被服务端禁用了。
就比如DELETE,服务端能让客户端随便删它里面的各种文件资源吗?
服务端肯定不允许啊,再说OPTIONS,服务端想让别人知道它都支持哪些方法吗?
如果别人通过OPTIONS知道服务端都支持哪些方法,其实就暴露了服务端的更多细节,所以服务端一般也不会支持OPTIONS方法。
而在之前我们所看到的请求报文中一般都是GET,我们对于它并不陌生,就是向服务端获取资源的,但是我们还从未见过POST方法。
上面的POST方法的说明比较简单,我们扩展一下,POST方法的作用:向服务端提交数据,请求服务端进行处理。那么POST方法是如何向服务端提交数据的呢?
一般是通过表单提交的,而表单涉及前端知识,所以下面我们要展示的话要通过前后端结合的方式来给进行讲解,下面我们一起来看看吧。
3.1POST方法
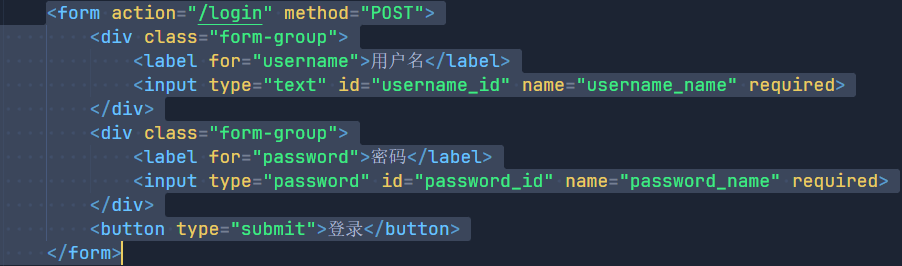

我们先来认识一下表单,上面的两幅图就是表单的代码和它所呈现出来的效果,客户端未来就是通过输入用户名和密码,点击登录,就可以借助POST方法将数据交给服务端进行处理。
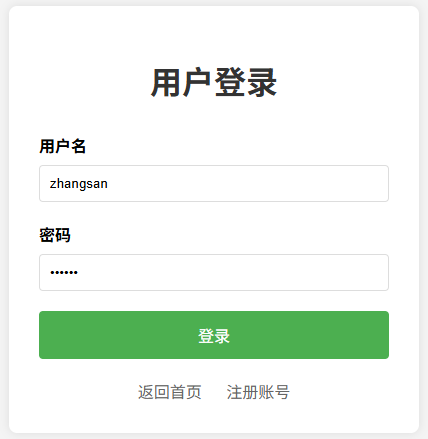


而当我们输入账号和密码后,点击登录,我们观察上方的URL就可以发现,在我们的IP地址后面跟的就是" /login ",它就是表单中action中里面的值。
并且在客户端发来的请求报文中我们也可以看到正文部分就是我们刚才输入的用户名和密码,这就是POST方法所打包的数据。
action的含义是:表单数据提交时,请求要发送到的目标URL,也就是" /login ",但是我们不要认为" /login "就是服务端里面的某个文件资源,虽然它可以是,但是极为少见,大部分情况下都是将action中的URL在后端进行解析,然后将它打包的数据交给相应的模块去进行处理,操作。
通过这种方式HTTP协议就可以完成交互式操作,那么下面我们就根据上面的思路来简单实现一下:
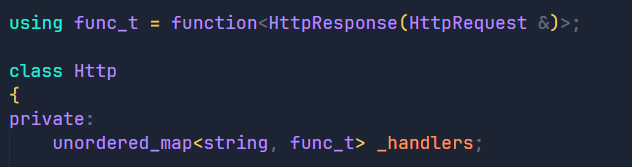
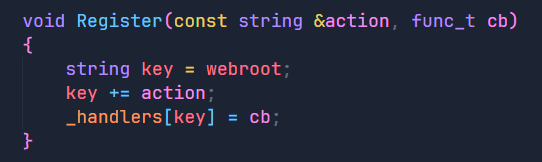
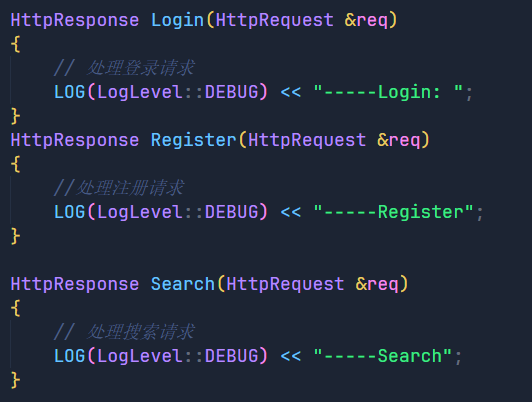
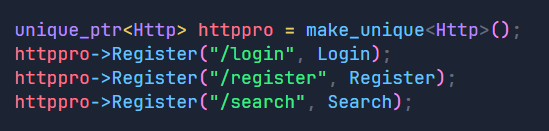
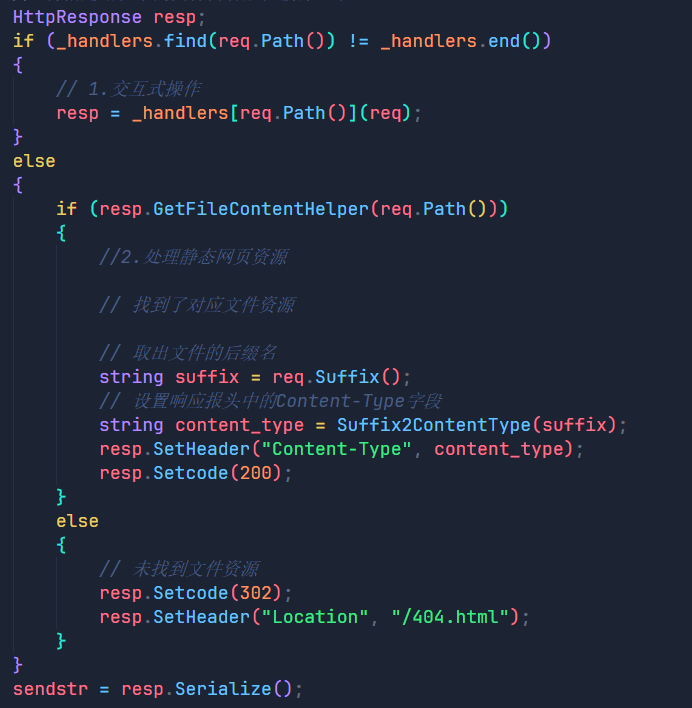
那么我们的思路就是创建一个unordered_map用来存放不同的action所对应的处理模块,之后我们简单向里面填入了登录,注册,查找三个模块。
然后我们在HandlerRequest函数中判断反序列化后的结果,在_handlers中查找客户端是否要进行交互式操作,找到了说明客户端要进行交互式操作,反之则是请求静态网页资源。
如果是交互式操作就执行相应的后端模块,那么后端模块中的具体逻辑我们就不实现了,这不是重点,最后我们来看看效果:
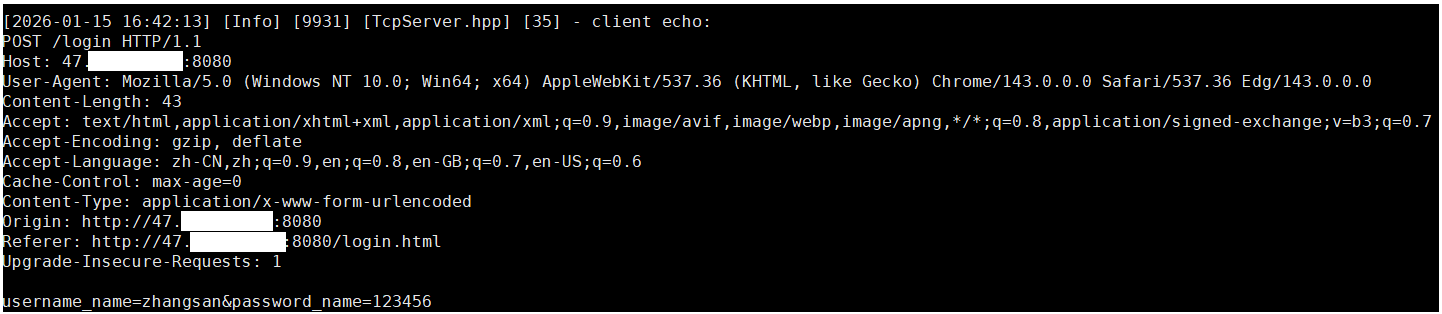
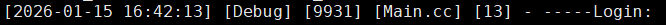
从结果中我们可以看到,登录的时候,客户端向服务端发起了请求,并成功调用了后端我们所写的登录函数。
我们通过这份代码就想说明HTTP协议不仅可以请求静态网页资源,还可以进行交互式操作!!!
3.2补充知识
其实不止可以使用POST方法来向服务端传递数据,GET方法同样可以如此,不过与POST方法不同的是,GET方法传递数据时并不会将数据放在请求报文中的正文部分,而是回显到URL中,下面我们来看一看:
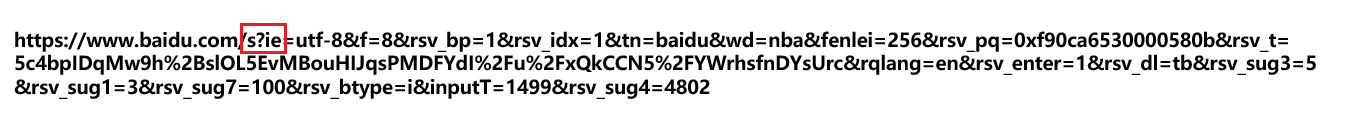
这就是通过GET方法来传递数据时的效果," ? "后面的内容就是要传递的数据,前面的就是action的URL。
其实我们对比GET和POST两种方式,它们都是明文传参,其实都不安全,别人只要能获取到你的请求报文,就可以知道你传递的数据是什么,就比如上面我们所写的用户名和密码,别人就能够知道。
但是POST相对于GET的私密性更好,GET直接就回显到URL中,不需要获取请求报文就能看到数据,POST还得获取请求报文才能看到。
而要解决明文传参的问题,就需要HTTPS协议来解决。
四.Cookie和Session
那么我们最后来讲讲HTTP协议中的Cookie和session。
在上一章初识HTTP协议的时候我们就说过,HTTP协议是一个无连接,无状态的协议,那么这个无连接和无状态该怎么理解呢?
无连接:无连接其实好理解,HTTP协议是应用层协议,而要建立连接的是TCP/UDP协议,它们建立连接,和HTTP协议无关!!!
无状态:简单理解就是服务器不会在请求之间保存客户端的上下文信息,包括客户端的历史请求,和用户行为,不做任何记录。
但是这与我们的生活经验是冲突的,什么意思呢?
我们应该都有这样的经历,我们第一次打开某个视频网站观看VIP视频时,需要登录,然后我们进行了登录,并成功看了第一个VIP视频,但是当我们把页面关闭后,再次打开,发现我们依旧是登录状态,而HTTP协议是无状态的,那么它如何对用户进行状态的保持呢?
如果严格按照无状态来进行操作,那么当我们打开第二个VIP视频的时候,应该还要进行登录操作,来检查当前账户是否是VIP账户,因为是无状态的,服务端根本不知道你是谁,而第三个,第四个都是如此,那么这样看个视频就非常麻烦了,非常的不方便。
所以为了保证能够对用户进行一定程度的状态保持,由服务器+浏览器+HTTP协议(Cokkie+Session)三方合作,共同来完成这个工作。
4.1Cookie
首先我们先来见一见Cookie长什么样子:

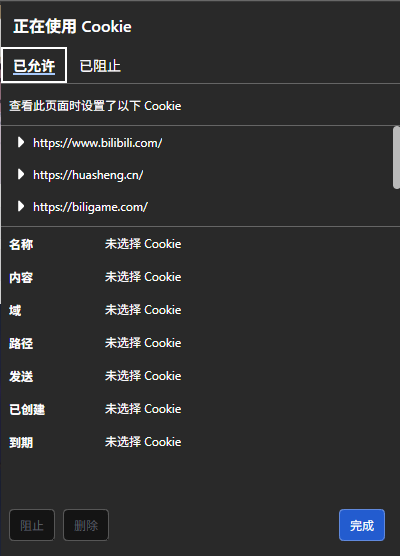
比如现在我们登录了哔哩哔哩网站,然后查看该网站的Cokkie,可以看到在该网站下我们有一些Cokkie文件,在这些文件中就保存了诸如我们的账号和密码等各种信息,那么Cookie是怎么实现的呢?下面我们就来看看:
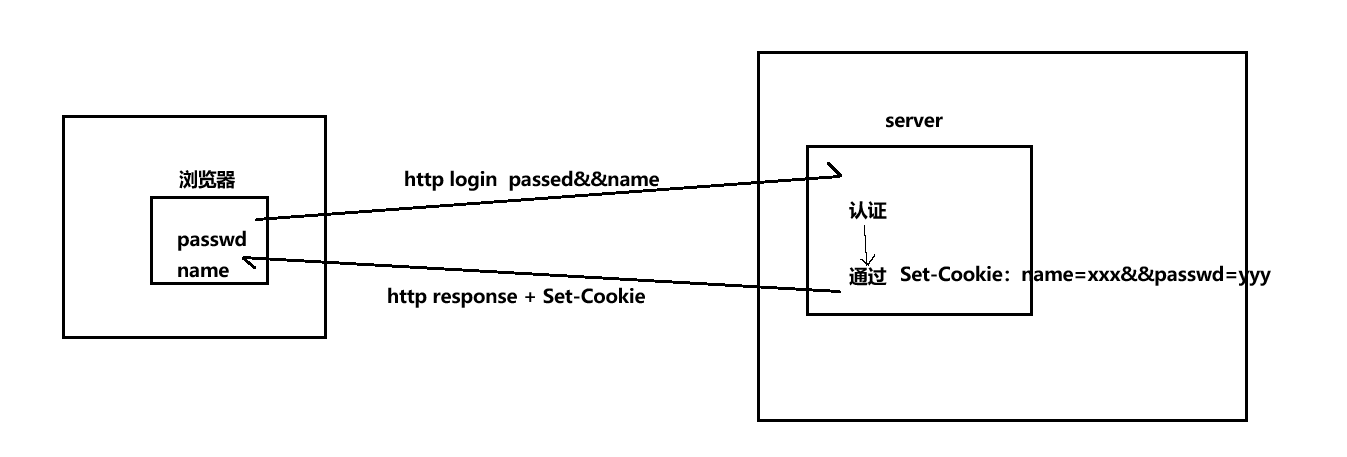
当用户在浏览器登录时,服务端在内部进行认证,认证通过后,服务端就会在发给浏览器的响应报文中加上Set-Cookie这个字段,该字段中就包含了登录时的用户名和密码,而浏览器在接收到服务端的响应报文后,根据Set-Cookie字段,在该网站中就会形成相应的Cookie文件。
所以Cookie技术的第一点就是:是应答的报头属性之一,客户端要自动保存起来Cookie信息,并且Cookie文件分为文件级和内存级。
那么Cookie技术的第二点就是:在浏览器通过Cookie文件保存信息后,从此往后,浏览器再向目标服务器发起请求的时候就会带上Cookie信息,也就是请求报头会自动写入当前保存的Cookie信息:
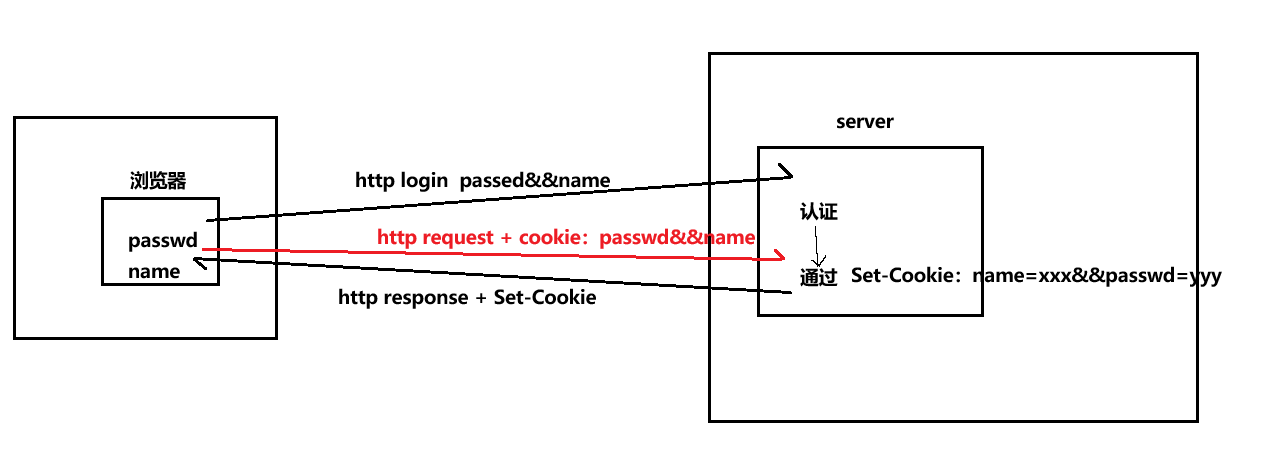
那么说了这么多,该怎么证明呢?下面我们来看:
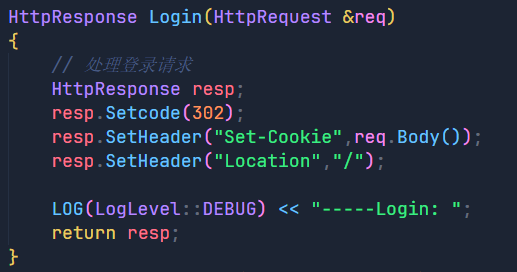
我们的思路就是通过重定向在登录之后返回原页面,并且设置了Set-Cookie字段,那么结果如何呢?我们来看看:
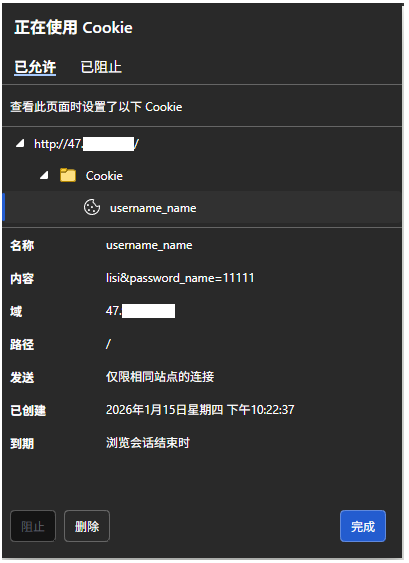

从结果中我们可以看到,在响应报文中设置了Set-Cookie字段后,浏览器确实在该网站生成了Cookie文件,里面就保存了我们的用户名和密码,但是我们这里的Cookie信息的格式不对,不过无伤大雅,我们要的只是是否生成了Cookie文件。
并且因为重定向的操作,浏览器会再次向服务端请求服务器页面,然后在请求报文中我们可以看到确实已经自动添加上了我们的Cookie信息。
通过Cookie技术我们就实现了用户的在线管理和会话保持功能。
我们上面说Cookie分为文件级和内存级,那么该如何区分呢?下面我们来看:

在我们生成的Cookie文件的下面我们可以看到到期时间是浏览会话结束时,这句话的意思其实就是表明我们此时的Cookie文件是内存级的,我们一旦关闭浏览器,结束掉浏览器进程,我们的Cookie文件就会消失了。

而如果到期时间是一个具体的时间,就如上图所示,那么就说明此时的Cookie文件是一个文件级的,只要没有到它所规定的时间,即使我们关闭了浏览器,再打开后,我们的Cookie文件依旧还在。
4.2Session
那么我们来思考一个问题,我们的信息保存在浏览器中,它安全吗?
其实是不安全的,我们来看:
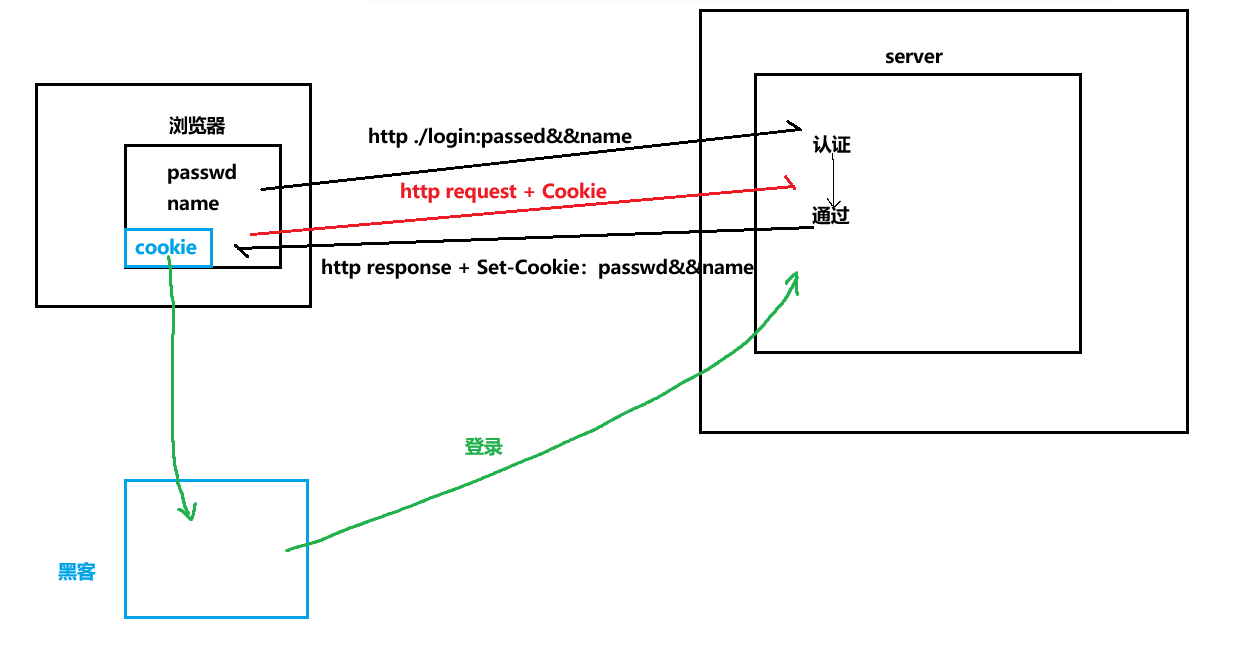
如果有一个黑客通过某种手段获取了你浏览器中保存的Cookie信息,这里面包含了你的账号密码等信息,那么后果是什么呢?
后果就是黑客就拿着你的Cookie信息直接就可以直接登上你的号了,这不就是我们常说的盗号吗?
并且不只是账号被盗,我们的个人信息也会因此泄露,所以信息保存在浏览器是不安全的,那么该如何做来解决上面的情况呢?
答案就是将我们的信息保存在服务端,那么该如何做呢?我们来看:
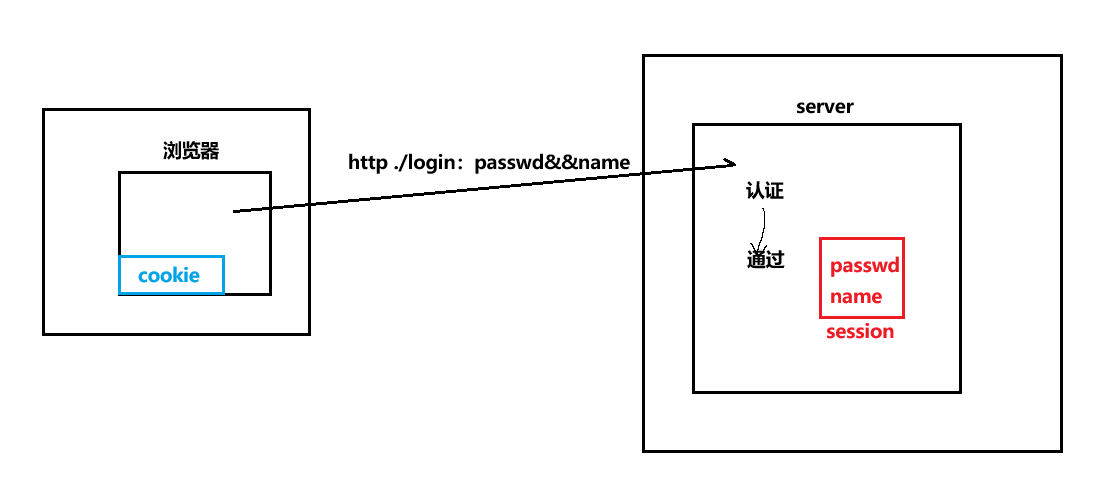
做法就是当浏览器向服务端发送请求时,在服务端会形成一个session文件,我们的信息就会保存在这个session文件中。
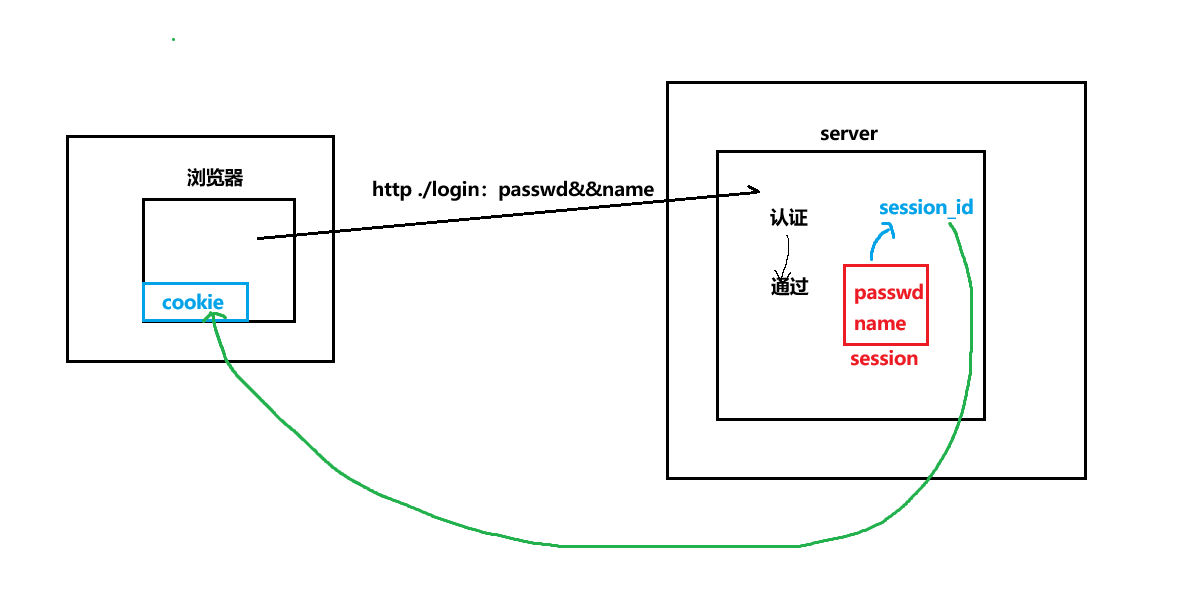
但是我们知道,未来是有很多客户端会向该服务端发送请求的,所以我们为了区分不同的客户端的session,我们要对session进行编码,也就是每个session文件都有一个对应的session_id,而未来只需要拿着session_id就可以进行登录认证操作。
而未来浏览器的Cookie文件中就只会保存session_id,那么这种做法可以解决上面的那个问题呢?
但就是个人信息泄露的问题,我们的信息保存在服务端,黑客获取浏览器中的Cookie信息,里面只包含了session_id,不会包含我们的个人信息。
那么可能有人会问:那黑客会不会去攻击服务端来获取我们的信息呢?
我们反向思考一下:你听说过有黑客去攻击支付宝,腾讯等企业的服务器吗?
所以这种问题基本不存在,那么我们只说了能解决个人信息暴露的问题,那么盗号的问题呢?
这个问题暂时没有办法解决,只能够缓解,都已经21世纪了,相信我们大家也会听到周围有谁的账号被盗了,盗号这个问题到现在还是存在的,黑客还是可以拿着你的session_id去登录的。
我们在实际应用中是Cookie+session两种方式共同使用的。
以上就是从初识到深入:一次完整的 HTTP 协议系统性理解之旅的全部内容。