背景
Apache Datafusion Comet 是苹果公司开源的加速Spark运行的向量化项目。
本项目采用了 Spark插件化 + Brotobuf + Arrow + DataFusion 架构形式
其中
- Spark插件是 利用 SparkPlugin 插件,其中分为 DriverPlugin 和 ExecutorPlugin ,这两个插件在driver和 Executor启动的时候就会调用
- Brotobuf 是用来序列化 spark对应的表达式以及计划,用来传递给 native 引擎去执行,利用了 体积小,速度快的特性
- Arrow 是用来 spark 和 native 引擎进行高效的数据交换(native执行的结果或者spark执行的数据结果),主要在JNI中利用Arrow IPC 列式存储以及零拷贝等特点进行进程间数据交换
- DataFusion 主要是利用Rust native以及Arrow内存格式实现的向量化执行引擎,Spark中主要offload对应的算子到该引擎中去执行
本文基于 datafusion comet 截止到2026年1月13号的main分支的最新代码(对应的commit为 eef5f28a0727d9aef043fa2b87d6747ff68b827a)
主要分析 CometSparkSessionExtensions 中的向量化规则转换
CometExecRule分析
上代码:
class CometSparkSessionExtensions
extends (SparkSessionExtensions => Unit)
with Logging
with ShimCometSparkSessionExtensions {
override def apply(extensions: SparkSessionExtensions): Unit = {
extensions.injectColumnar { session => CometScanColumnar(session) }
extensions.injectColumnar { session => CometExecColumnar(session) }
extensions.injectQueryStagePrepRule { session => CometScanRule(session) }
extensions.injectQueryStagePrepRule { session => CometExecRule(session) }
}
case class CometScanColumnar(session: SparkSession) extends ColumnarRule {
override def preColumnarTransitions: Rule[SparkPlan] = CometScanRule(session)
}
case class CometExecColumnar(session: SparkSession) extends ColumnarRule {
override def preColumnarTransitions: Rule[SparkPlan] = CometExecRule(session)
override def postColumnarTransitions: Rule[SparkPlan] =
EliminateRedundantTransitions(session)
}
}这里主要是 应用CometExecRule规则 将spark物理规则转换为 Comet native 规则。
这里先说说 Comet 的 Native Shuffle,主要分为两个:
一个是spark.comet.exec.shuffle.mode 为 jvm 情况下的 Columnar Shuffle;
一个是spark.comet.exec.shuffle.mode 为 native 情况下的 Native Shuffle.
这里有两个重要的点 :
一个是Shuffle Manager(对应到Comet中就是org.apache.spark.sql.comet.execution.shuffle.CometShuffleManager),
一个是进行数据拉取的ShuffleExchangeExec(对应到Comet中是CometShuffleExchangeExec)
// TODO
注意:
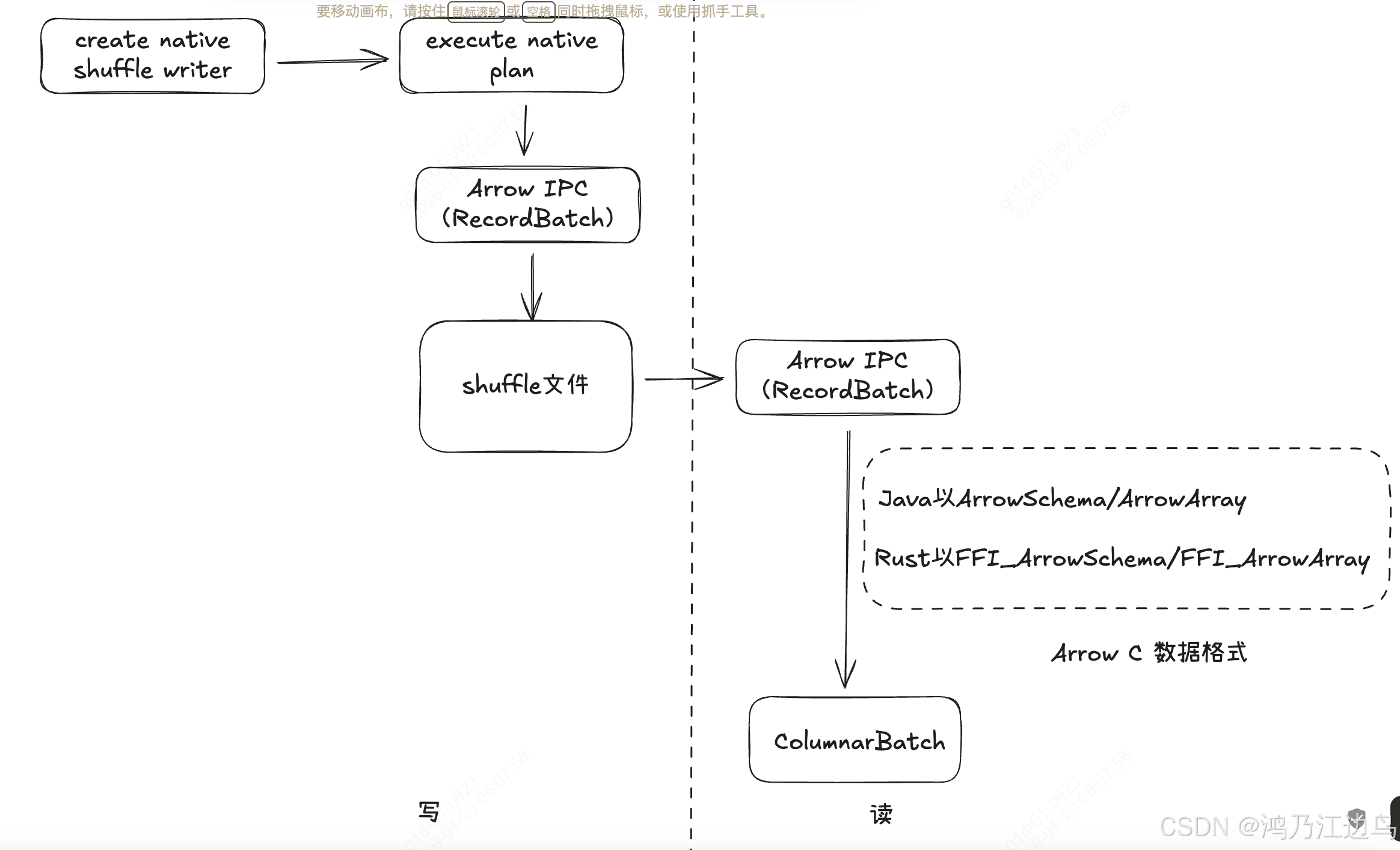
这里说的`Columnar Shuffle`是以`Arrow IPC(RecordBatch)`格式将以前的行格式存储数据,以列存的形式存储到`shuffle`中间文件中。
而读取的时候,会以`ArrowC`格式(java以 ArrowSchema/ArrowArray Rust以FFI_ArrowSchema/FFI_ArrowArray数据结构)jvm以jni的方式调用Rust的方式读取数据,这种就会减少多进程间的序列化和反序列化的开销。以下对CometShuffleManager中涉及到的三种 ShuffleHandle 详细的进行分析
CometBypassMergeSortShuffleHandle
写Shuffle数据: CometBypassMergeSortShuffleWriter
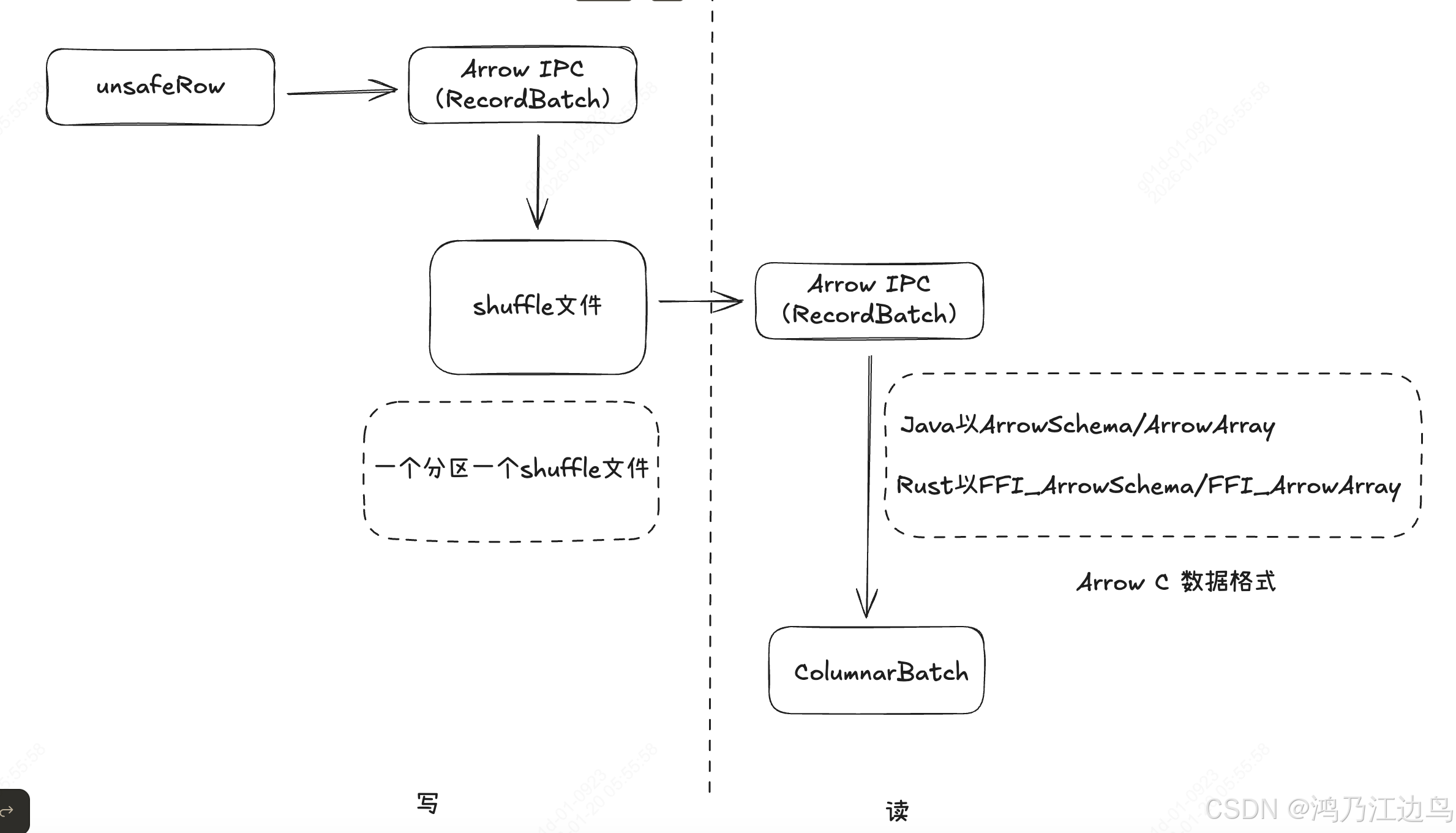
这个基于 BypassMergeSortShuffleWriter,使用DiskBlockArrowIPCWriter 来代替 DiskBlockObjectWriter,将 UnsafeRow的行存数据,以
Arrow IPC(RecordBatch)格式存储到Shuffle中间文件中,数据流如下:
CometBypassMergeSortShuffleWriter.write
||
\/
CometDiskBlockWriter.insertRow
||
\/
ArrowIPCWriter.initialCurrentPage
||
\/
ArrowIPCWriter.insertRecord
||
\/
CometDiskBlockWriter.doSpill
||
\/
ArrowIPCWriter.doSpilling
||
\/
nativeLib.writeSortedFileNative-
CometBypassMergeSortShuffleWriter.write
这里按照每行所属的分区调用对应 CometDiskBlockWriter的insertRow 方法进行数据的写入,这里会直接写入到
byte[]中(对于UnsafeRow来说,只会写value的值,而不会写key的值),这里的数据都会被写到MemoryBlock中,并且把对应一行数据在当前绝对地址存储记录到RowPartition中,便于 Rust获取该数据的地址(通过JNI)操作对应的数据 -
initialCurrentPage
这里会调用
allocator.allocate方法进行进行堆内或者堆外数据的分配,具体的载体为MemoryBlock,具体的可以参考Spark中的堆外和堆内内存以及内部行数据表示UnsafeRow,这里的 MemoryBlock 数据结构如下:public MemoryBlock(@Nullable Object obj, long offset, long length) { super(obj, offset); this.length = length;}
offset 表示的要么是Object中的offset偏移量,要么是 真实的物理地址(暂且这么理解)
-
nativeLib.writeSortedFileNative
这里会调用 Rust的pub unsafe extern "system" fn Java_org_apache_comet_Native_writeSortedFileNative(位于jni_api.rs中),@native def writeSortedFileNative( addresses: Array[Long], rowSizes: Array[Int], datatypes: Array[Array[Byte]], file: String, preferDictionaryRatio: Double, batchSize: Int, checksumEnabled: Boolean, checksumAlgo: Int, currentChecksum: Long, compressionCodec: String, compressionLevel: Int, tracingEnabled: Boolean): Array[Long]
这里 addresses 就是记录了每行数据的物理地址, rowSizes 记录了每行数据的大小
对于 该 Rust的native的实现大致是,通过addresses和rowSizes构造SparkUnsafeRow行数据,之后再转换为Arrow IPC的 RecordBatch 格式数据,之后再写入文件中,具体的后续进行分析
读Shuffle数据:CometBlockStoreShuffleReader
该Reader的大概逻辑为以 Arrow IPC的格式读取序列化的数据,并返回一个ColumnarBatch 类型的迭代器
内部的数据流为:
CometBlockStoreShuffleReader.read
||
\/
NativeBatchDecoderIterator最主要的逻辑在 NativeBatchDecoderIterator这个类中,这是个迭代器,其中fetchNext的方法为:
val batch = nativeUtil.getNextBatch(
fieldCount,
(arrayAddrs, schemaAddrs) => {
native.decodeShuffleBlock(
dataBuf,
bytesToRead.toInt,
arrayAddrs,
schemaAddrs,
tracingEnabled)
})
...
def getNextBatch(
numOutputCols: Int,
func: (Array[Long], Array[Long]) => Long): Option[ColumnarBatch] = {
val (arrays, schemas) = allocateArrowStructs(numOutputCols)
val arrayAddrs = arrays.map(_.memoryAddress())
val schemaAddrs = schemas.map(_.memoryAddress())
val result = func(arrayAddrs, schemaAddrs)
result match {
case -1 =>
// EOF
None
case numRows =>
val cometVectors = importVector(arrays, schemas)
Some(new ColumnarBatch(cometVectors.toArray, numRows.toInt))
}
}可以看到 最主要的方法为native.decodeShuffleBlock,这个会调用 Rust 的Native方法:pub unsafe extern "system" fn Java_org_apache_comet_Native_decodeShuffleBlock,这个方法有几个参数,
dataBuf 是 读取到的 Arrow IPC的数据流的物理起始地址,
arrayAddrs 是java端 Arrow C格式的ArrowArray数据结构,用于和Rust FFI_ArrowArray进行交互
schemaAddrs 是java端 Arrow C格式的ArrowSchema数据结构,用于和Rust FFI_ArrowSchema进行交互
该native方法会读取物理块中的数据,并在方法中将读取到的RecordBatch数据,并将该数据转换为ArrayData(Arrow Data 包下的),再利用
Arrow C(FFI_ArrowArray, FFI_ArrowSchema)把数据回传给java中(以ArrowArray,ArrowSchema数据结构),此次交互不需要进行数据的序列化和反序列化,直接在进程间无隙访问.
与此同时在getNextBatch方法中,调用 importVector方法把 返回的数据 转换为 ColumnVector,从而最终转换为ColumnarBatch 类型的数据。
注意在NativeBatchDecoderIterator中有个读取当前Arrow IPC流长度的时候,用的是private val longBuf = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN)小端进行存储。
CometSerializedShuffleHandle
写shuffle数据:CometUnsafeShuffleWriter
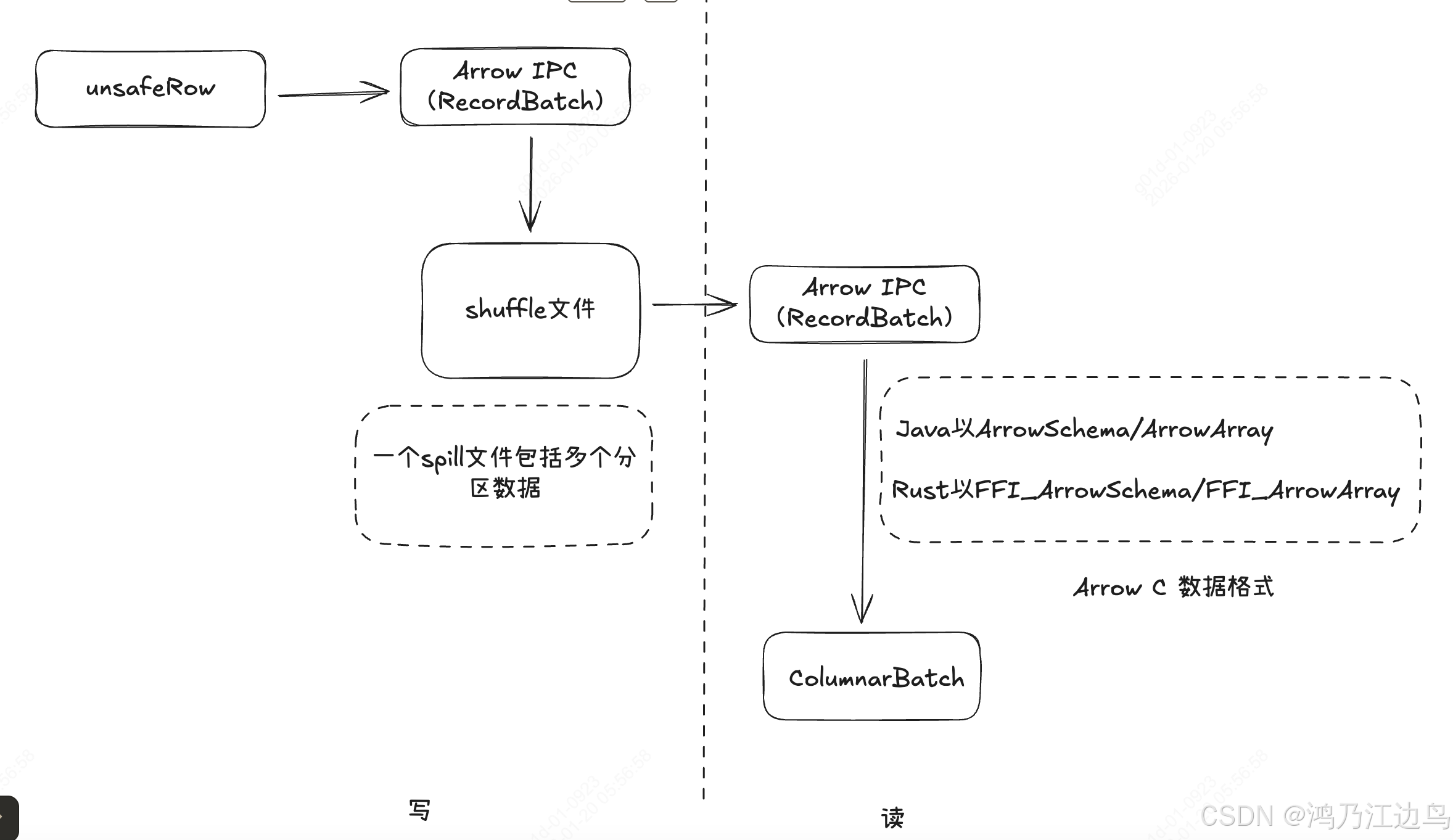
Comet 将通过本地代码对行进行排序。排序基于一个包含压缩分区 ID 和行指针的长数组。行指针是堆外内存中行的地址。排序完成后,Comet 会通过原生代码(必须启用堆外内存)将排序后的行写入溢出文件
数据流为:
CometUnsafeShuffleWriter.write
||
\/
CometUnsafeShuffleWriter.insertRecordIntoSorter
||
\/
CometShuffleExternalSorter.insertRecord
||
\/
SpillSorter.insertRecord
||
\/
ShuffleInMemorySorter.insertRecord
||
\/
ShuffleInMemorySorter.spill
||
\/
SpillSorter.writeSortedFileNative
||
\/
nativeLib.sortRowPartitionsNative
||
\/
SpillSorter.doSpilling
||
\/
Native.writeSortedFileNative- SpillSorter.insertRecord
这里会利用Platform.copyMemory把数据写进对应的 MemoryBlock 物理内存中,并且调用ShuffleInMemorySorter.insertRecord - ShuffleInMemorySorter.insertRecord
这里会 以 LongArray 类型的数据存储 数据(该数据以PartitionId|compressedAddress)的方式存储到对应的 8字节数据 中去, - nativeLib.sortRowPartitionsNative
这里会调用 Rust的pub extern "system" fn Java_org_apache_comet_Native_sortRowPartitionsNative
这个基于parititonId排序,把具有相同分区ID的数据聚合在一起 - SpillSorter.doSpilling
这里会调用 Rust 的native方法pub unsafe extern "system" fn Java_org_apache_comet_Native_writeSortedFileNative进行写数据
读Shuffle数据:CometBlockStoreShuffleReader
流程和之前的一样
CometNativeShuffleHandle
写Shuffle数据:CometNativeShuffleWriter
这个就是纯native的shuffle了,创建native plan,以及执行native plan, 都是通过 JNI去调用Rust代码执行,数据流如下:
CometNativeShuffleWriter.write
||
\/
getNativePlan(tempDataFilename, tempIndexFilename)
||
\/
CometExec.getCometIterator-
getNativePlan
这里会构造一个Shuffle write的 native operator,这个计划会传给
CometExec.getCometIterator -
CometExec.getCometIterator
这里是重点,该方法会返回一个迭代器,所以看对应的next和hasNext方法
override def hasNext: Boolean = { if (closed) return false if (nextBatch.isDefined) { return true } if (prevBatch != null) { prevBatch.close() prevBatch = null } nextBatch = getNextBatch if (nextBatch.isEmpty) { close() false } else { true } }这里的
getNextBatch方法会调用nativeUtil.getNextBatch( numOutputCols, (arrayAddrs, schemaAddrs) => { nativeLib.executePlan(ctx.stageId(), partitionIndex, plan, arrayAddrs, schemaAddrs) }) })而这里的 plan 会调用
Native.createPlan方法(对应Rust Java_org_apache_comet_Native_createPlan)利用JNI创建一个native的计划(也是就是shuffle write计划),并返回包括了该计划执行的ExecutionContext的地址,这里包括了需要执行的所有信息接着会执行
Native.getNextBatch方法,,该方法之前说过,这里就不重复赘述,该方法会调用Native.executePlan方法,用来执行shuffle write。
读Shuffle数据:CometBlockStoreShuffleReader
流程和之前的一样