天牛须算法优化BP神经网络,支持向量机SVM核和SVR,核极限学习机,预测,分类。
今天,我想和大家分享一个挺有意思的话题------天牛须算法在优化机器学习模型中的应用,特别是它在BP神经网络、支持向量机(SVM)和核极限学习机中的表现。这些模型在预测和分类任务中都有广泛的应用,而天牛须算法作为一种优化算法,能够帮助我们更好地调整这些模型的参数,从而提升性能。
一、天牛须算法简介
天牛须算法(Bee Colony Algorithm,BCA)是一种受自然启发的优化算法,灵感来源于天牛的觅食行为。它的核心思想是通过模拟天牛的觅食过程,找到问题的最优解。相比于传统的优化算法(如遗传算法、粒子群优化等),天牛须算法在某些特定问题上表现得更加高效。
下面是一个简单的天牛须算法伪代码示例:
python
def bca_algorithm(population_size, max_iterations):
# 初始化种群
population = initialize_population(population_size)
for iteration in range(max_iterations):
# 计算适应度
fitness = calculate_fitness(population)
# 找到当前最优解
best_solution = find_best_solution(population, fitness)
# 更新种群
population = update_population(population, best_solution)
return best_solution这段代码展示了天牛须算法的基本框架,包括种群初始化、适应度计算、最优解更新等步骤。实际应用中,我们需要根据具体问题调整算法的参数和细节。
二、优化BP神经网络
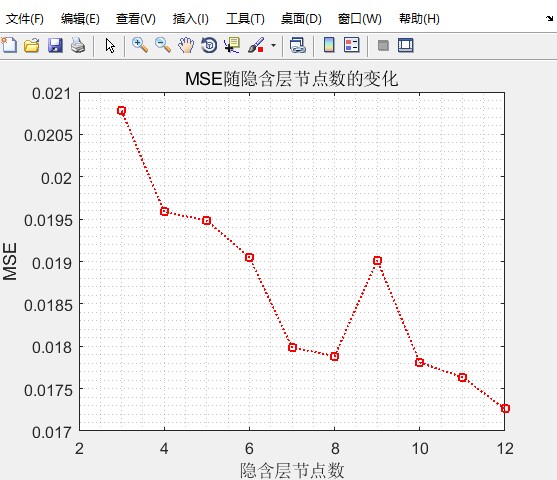
BP神经网络(Backpropagation Neural Network)是一种经典的神经网络模型,广泛应用于分类和回归任务。然而,BP神经网络的性能 heavily depends on 参数的选择,比如学习率、隐层神经元数量等。天牛须算法可以用来优化这些参数,从而提高模型的性能。
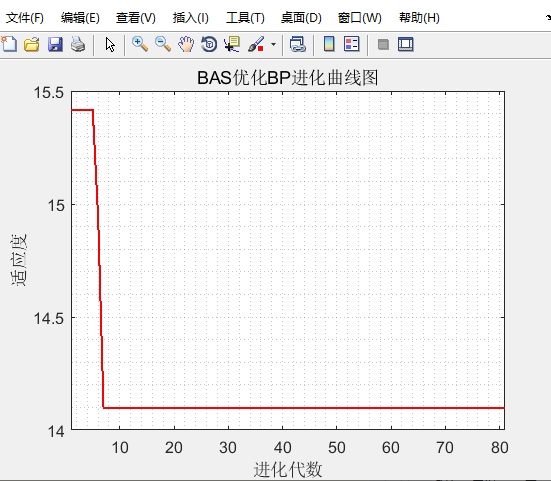
假设我们有一个简单的BP神经网络模型,如下所示:
python
from sklearn.neural_network import MLPClassifier
# 初始化模型
model = MLPClassifier(hidden_layer_sizes=(100, 100), learning_rate='adaptive')如果我们想优化模型的参数,可以使用天牛须算法来搜索最优的hiddenlayersizes和learning_rate。通过这种方式,我们可以让模型在特定数据集上表现得更好。
三、支持向量机(SVM)与SVR
支持向量机(SVM)是一种强大的分类和回归模型,尤其在小样本数据上表现优异。SVR(Support Vector Regression)是SVM在回归任务中的应用。然而,SVM和SVR的性能同样依赖于核函数和正则化参数的选择。
天牛须算法优化BP神经网络,支持向量机SVM核和SVR,核极限学习机,预测,分类。
天牛须算法可以用来优化这些参数。例如,在SVM中,我们需要选择核函数(如RBF核)和参数C和gamma。通过天牛须算法,我们可以找到最优的参数组合。
python
from sklearn.svm import SVC
# 初始化模型
model = SVC(kernel='rbf', C=1.0, gamma='scale')如果我们想优化C和gamma,可以使用天牛须算法来搜索参数空间。这样,模型的分类性能可能会有显著提升。
四、核极限学习机(Kernel Extreme Learning Machine,KELM)
核极限学习机是一种基于极限学习机(ELM)的改进版本,通过引入核函数来提升模型的非线性建模能力。相比于传统的ELM,KELM在处理复杂数据时表现更好。然而,KELM的性能同样依赖于核函数和正则化参数的选择。
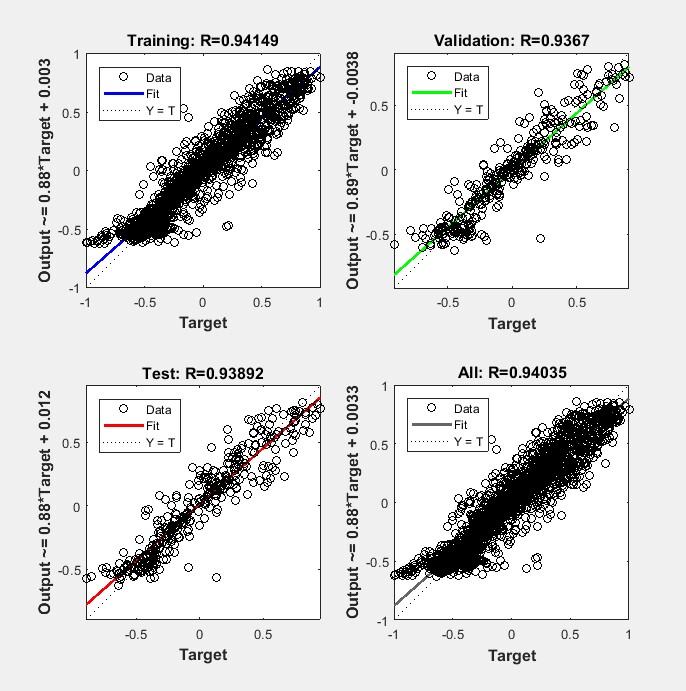
天牛须算法可以用来优化KELM的参数,比如核函数的参数和正则化参数。通过这种方式,我们可以让KELM在特定任务中表现得更好。
python
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
# 初始化模型
model = KELM(kernel='rbf', gamma=0.1, reg=0.1)如果我们想优化gamma和reg,可以使用天牛须算法来搜索最优参数组合。
五、实际应用中的效果
通过天牛须算法优化后的模型,在预测和分类任务中通常能够取得更好的性能。例如,在股票价格预测任务中,优化后的BP神经网络和KELM模型可以提供更准确的预测结果;在分类任务中,优化后的SVM和KELM模型可以实现更高的准确率和更好的泛化能力。
当然,实际应用中还需要根据具体问题调整算法的参数和细节。例如,在优化过程中,我们需要平衡算法的收敛速度和全局搜索能力,避免陷入局部最优。
六、总结
天牛须算法作为一种自然启发的优化算法,在机器学习模型的参数优化中具有重要的应用价值。通过将其与BP神经网络、SVM、SVR和KELM结合,我们可以显著提升模型的性能。希望这篇文章能够帮助大家更好地理解这些算法,并在实际应用中尝试使用它们。
如果你对这些算法感兴趣,不妨尝试自己动手实现一下,相信你一定会有所收获!