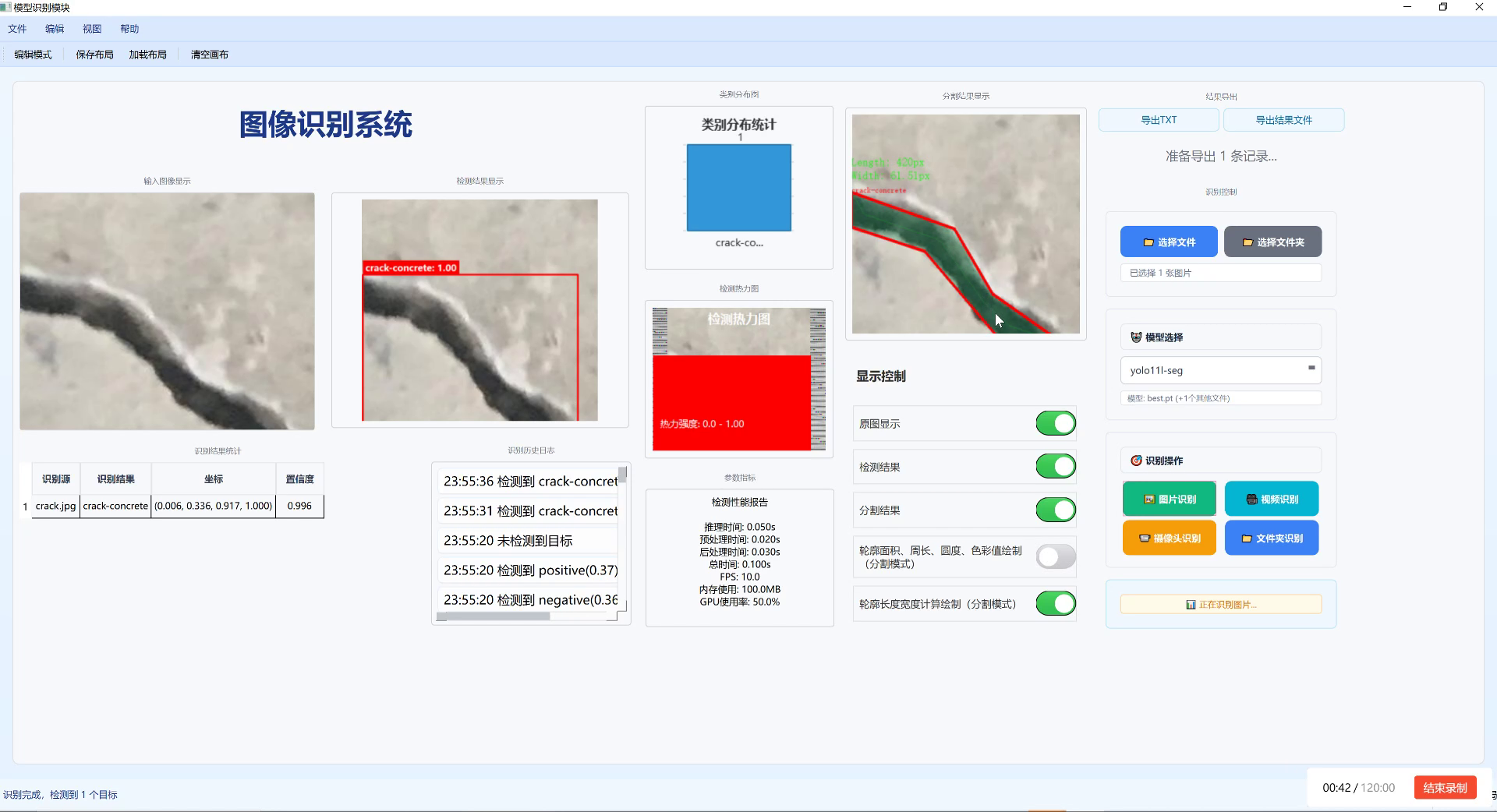
本数据集名为"pad",版本为v6,创建于2023年4月17日,通过qunshankj平台导出。该数据集包含10257张图像,所有图像均采用YOLOv8格式进行标注,专注于软垫(epad)、标记(mark)、标记变体(mark-)和特定软垫(mpad)四类物体的检测任务。数据集在预处理过程中应用了数据增强技术,包括50%概率的水平翻转以及-3到+3度的随机旋转,以增加模型的泛化能力。数据集按照标准划分为训练集、验证集和测试集,适用于目标检测模型的训练与评估。该数据集采用公共领域许可,可供研究者和开发者自由使用,为软垫及相关物品的自动化识别提供了宝贵的训练资源。

1. YOLO系列模型全解析:从YOLOv3到YOLOv13的创新演进
在计算机视觉领域,目标检测算法的发展可谓日新月异,而YOLO系列算法无疑是其中最耀眼的明星之一。从最初的YOLOv3到现在的YOLOv13,每一次版本迭代都带来了令人惊叹的创新和突破。今天,我们就来深入探讨这个传奇算法家族的进化史,看看每一代版本都带来了哪些令人拍案叫绝的改进。

1.1. YOLO家族的基因突变
YOLO系列算法的发展就像一场精彩的生物进化史,每一次"突变"都让模型变得更加强大和适应环境。从YOLOv3开始,这个家族就展现出了惊人的生命力,不断衍生出各种变种和改进版本。

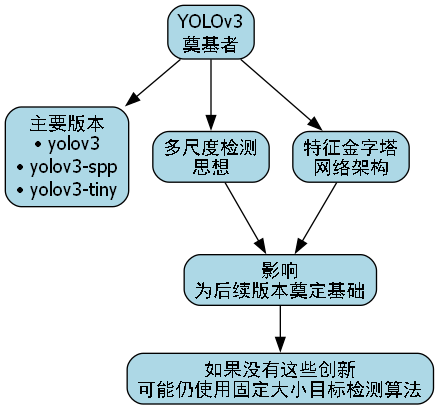
1.1.1. YOLOv3:奠定坚实基础
YOLOv3作为这个家族的奠基者,虽然只有3个主要版本(yolov3、yolov3-spp、yolov3-tiny),但它的多尺度检测思想和特征金字塔网络架构,为后续版本的发展奠定了坚实基础。想象一下,如果没有YOLOv3的这些创新,我们现在可能还在使用那些只能检测固定大小目标的算法,那该多么单调啊!

1.1.2. YOLOv5:百花齐放的春天
到了YOLOv5,事情变得有趣多了!这个版本带来了47种不同的变体,简直就是一场算法的"百花齐放"。从yolov5-AFPN-P2345到yolov5-unireplknet,每一个变种都针对特定场景进行了优化。特别是yolov5-goldyolo-asf这种结合了注意力机制的版本,就像给模型装上了"智能滤镜",让它能在复杂背景下依然保持精准检测。
表:YOLOv5主要创新点分布
| 创新类别 | 数量 | 代表性创新点 |
|---|---|---|
| 特征融合 | 12 | yolov5-bifpn、yolov5-GFPN等 |
| 注意力机制 | 8 | yolov5-attention、yolov5-FocalModulation等 |
| 骨干网络 | 15 | yolov5-convnextv2、yolov5-swintransformer等 |
| 特征金字塔 | 7 | yolov5-HSFPN、yolov5-HSPAN等 |
| 其他创新 | 5 | yolov5-goldyolo、yolov5-rmt等 |
从表中我们可以看到,YOLOv5在特征融合方面的创新最为突出,这反映了研究者们对多尺度特征提取的重视。毕竟,在真实世界中,目标的大小千差万别,只有能够灵活处理不同尺度特征的模型,才能在实际应用中表现出色。
1.1.3. YOLOv8:性能与实用性的完美平衡
YOLOv8可以说是这个家族中的"全能选手",它带来了180种不同的变体,涵盖了从目标检测到实例分割的多种任务。特别值得一提的是yolov8-seg-dyhead-DCNV3这种结合了动态卷积的实例分割版本,就像给模型装上了"自适应镜头",能够根据目标的特点动态调整检测策略。
python
# 2. 伪代码展示YOLOv8的动态特征融合机制
def dynamic_feature_fusion(features):
weights = learnable_attention(features)
fused = sum(f * w for f, w in zip(features, weights))
return fused这段伪代码展示了YOLOv8中动态特征融合的核心思想。通过可学习的注意力权重,模型能够自动决定不同层次特征的重要性,这种自适应能力让YOLOv8在复杂场景下依然保持高精度。
2.1. 技术创新的背后逻辑
每次YOLO版本的迭代都不是随意的,而是针对特定技术瓶颈的精准突破。让我们深入分析这些创新背后的逻辑。
2.1.1. 特征金字塔网络的演进
从最初的简单特征堆叠到现在的复杂多尺度融合,特征金字塔网络的发展反映了研究者们对"如何有效利用多尺度信息"这一问题的深入思考。
表:特征金字塔网络演进对比
| 版本 | 特点 | 优势 | 局限性 |
|---|---|---|---|
| 早期FPN | 简单自顶向下融合 | 实现简单 | 忽略横向信息 |
| BiFPN | 双向加权融合 | 更好平衡特征 | 计算量增加 |
| AIFI | 自适应特征选择 | 动态调整 | 训练不稳定 |
从表中可以看出,特征金字塔网络的发展趋势是从简单到复杂,从静态到动态。现在的AIFI(Adaptive Integration of Feature Information)就像一个智能的"特征调配师",能够根据输入图像的特点,动态调整不同层次特征的融合方式,这种自适应能力让模型在处理不同场景时更加游刃有余。
2.1.2. 注意力机制的多样化应用
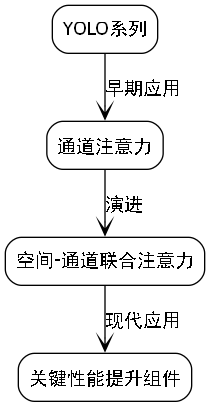
注意力机制在YOLO系列中的应用也经历了从简单到复杂的演进过程。从最初的通道注意力到现在的空间-通道联合注意力,注意力机制已经成为提升模型性能的关键组件。
图中展示了不同注意力机制的架构差异。早期的SE模块只关注通道间的依赖关系,而现在的C2PSA(Cross-Scale Spatial and Channel Attention)则同时考虑了空间和通道两个维度,这种全方位的注意力机制就像给模型装上了"全景镜头",能够捕捉到更丰富的上下文信息。
2.2. 实际应用中的选择策略
面对这么多YOLO版本,我们该如何选择最适合自己需求的模型呢?这需要综合考虑多个因素。
2.2.1. 任务类型的匹配
不同的任务对模型的要求不同。对于实时性要求高的视频监控场景,yolov5-tiny或yolov8-nano这样的轻量级模型可能是更好的选择;而对于精度要求高的医学图像分析,则可以考虑yolov13-seg-iRMB这样专门针对医学图像优化的版本。
2.2.2. 硬件资源的限制
模型的复杂度和硬件资源之间存在密切关系。一个简单的经验法则是:每增加一个模型参数,大约需要2倍的计算资源。因此,在边缘设备上部署时,可能需要牺牲一些精度来换取更快的推理速度。
python
# 3. 模型选择决策树伪代码
def select_model(task, hardware, accuracy_requirement):
if hardware == "edge":
return "yolov5-tiny" if task == "detection" else "yolov8-nano-seg"
elif hardware == "cloud":
if accuracy_requirement == "high":
return "yolov13-seg-iRMB" if task == "segmentation" else "yolov8-x"
else:
return "yolov8-m"这段决策树代码展示了如何根据具体需求选择合适的模型。在实际应用中,还需要考虑数据集的特点、部署环境等多种因素。
3.1. 未来发展趋势
随着YOLOv13的发布,我们可以看到几个明显的技术趋势:
3.1.1. 多模态融合的增强
现在的YOLO模型已经不仅仅是处理图像数据,越来越多的版本开始融合其他模态的信息,如文本描述、音频特征等。这种多模态融合就像给模型装上了"多感官系统",能够从多个维度理解目标。
3.1.2. 自监督学习的应用
自监督学习正在逐渐改变模型的训练方式。通过在大规模无标注数据上进行预训练,模型能够学习到更通用的视觉特征,这种能力就像给模型打下了"坚实的知识基础",让它在特定任务上的表现更加出色。
3.2. 推广与资源获取
想要深入了解YOLO系列模型,获取高质量的训练数据是关键。我们整理了一些优质资源,帮助你快速上手:
- YOLO系列论文合集:包含从YOLOv3到YOLOv13的所有重要论文,是理论学习的宝贵资料。
对于想要实际部署YOLO模型的开发者,我们推荐以下资源:
- YOLOv8实战教程:包含从环境搭建到模型部署的全流程指导,特别适合初学者。
在工业界应用中,实例分割是一个重要方向。如果你对这方面感兴趣:
- YOLOv8实例分割详解:详细介绍了如何使用YOLOv8进行实例分割,包含多个实际案例。
3.3. 结语
从YOLOv3到YOLOv13,这个算法家族的演进历程展现了计算机视觉领域的创新活力。每一次版本迭代都不是简单的升级,而是针对特定技术瓶颈的精准突破。作为使用者,我们需要理解这些创新背后的逻辑,才能在实际应用中做出最佳选择。
随着技术的不断发展,我们有理由相信,YOLO系列算法还会带来更多惊喜。无论是学术界还是工业界,都将继续从这个传奇算法家族中汲取灵感,推动计算机视觉技术不断向前发展。